目录
[2.2.核心方法:VICoT 框架](#2.2.核心方法:VICoT 框架)
[3.1. 基于提示驱动LLM](#3.1. 基于提示驱动LLM)
[3.2. 智能体驱动工具增强的 LLM](#3.2. 智能体驱动工具增强的 LLM)
[4.1.VICoT 框架核心设计](#4.1.VICoT 框架核心设计)
1.摘要
当前的遥感图像分析任务正日益从传统的对象识别向复杂的智能推理演进,这对 LLM(大语言模型) 的推理能力和 智能体 工具调用的灵活性提出了更高的要求。为此,我们提出了一种新的多模态 智能体 框架------视觉交错思维链框架,它通过动态地将视觉工具整合到思维链中来实现明确的多轮推理。通过基于堆栈的推理结构和模块化的MCP兼容工具套件,VICoT使 LLM 能够高效地执行多轮、交错的视觉语言推理任务,具有很强的泛化和灵活性。我们还提出了推理堆栈蒸馏方法,将复杂的 智能体 行为迁移到小型、轻量级的 LLM 中,在保证推理能力的同时显著降低了复杂性。在多个遥感基准上的实验表明,VICoT在推理透明度、执行效率和生成质量方面明显优于现有的SOTA框架。
2.简介
2.1.研究背景与问题
- 遥感图像分析正从简单的目标识别转向复杂的智能推理任务(如地理定位、语义解释、多尺度分析等)。
- 现有方法存在以下局限:
- 多数多模态智能体采用单轮、预定义工作流,缺乏动态推理能力;
- "规划-执行"分离架构(Plan-Execute)导致高令牌消耗、高延迟、冗余计算;
- 大模型难以部署在边缘设备或卫星端;
- 缺乏对超高分辨率(UHR)遥感图像的高效处理机制。
2.2.核心方法:VICoT 框架
-
视觉交错思维链(Vision-Interleaved Chain-of-Thought, VICoT)
- 将视觉工具调用 动态嵌入到思维链推理过程中,实现多轮、交错的视觉-语言联合推理。
- 推理过程不再是"先规划再执行",而是边思考边调用工具,模拟人类解决问题的方式。
-
基于堆栈的推理结构
- 使用动态推理堆栈管理推理轨迹,支持回溯、修正和细化。
- 每个堆栈条目可触发多个工具调用,实现灵活的"一对多"交互。
-
模块化 MCP 兼容工具集
- 采用模型上下文协议(MCP) 封装视觉语言工具(如开放词汇检测、去云/雨、超分、RAG等)。
- 工具与智能体运行时环境解耦,确保即插即用和任务适应性。
-
面向 UHR 图像的区域感知处理
- 引入分层视觉分解头,自适应划分大图成语义子区域,并融合全局上下文进行结构化推理。
-
推理堆栈蒸馏(Reasoning Stack Distillation)
- 利用 GPT-4o 生成的高质量推理轨迹,微调轻量模型(如 Qwen3-14B)。
- 蒸馏后模型(VICoT-Qwen)仅需 12GB 显存(AWQ 4-bit),可在 16GB VRAM 设备运行。
- 在保持性能的同时,显著降低延迟和资源消耗。
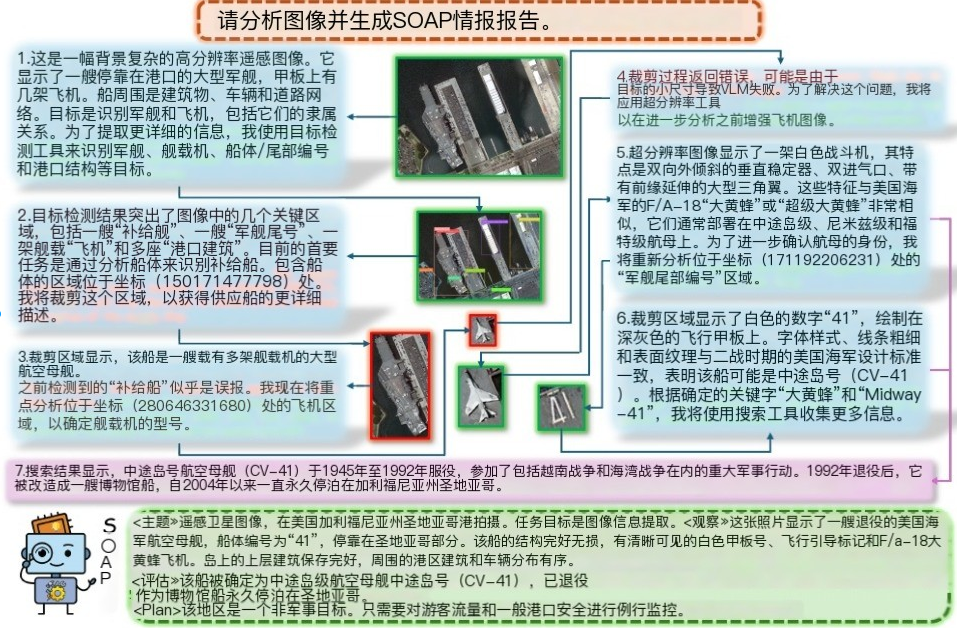 图1。在遥感图像分析任务中使用VICoT代理进行多轮推理和工具调用的示例。
图1。在遥感图像分析任务中使用VICoT代理进行多轮推理和工具调用的示例。
agent首先描述整个场景,并使用开放词汇检测器识别相关物体(步骤1-2)。
然后应用裁剪(步骤3)超分辨率(步骤4)来细化视觉细节,
随后是增强飞机类型识别(步骤5)和船体编号识别(步骤6),基于提取的关键字,
它调用web搜索工具来检索支持的背景信息(步骤7),最终形成soap格式的情报报告。
每个推理步骤都以特定的视觉区域和相关工具输出为基础,展示了可解释性和透明度。
3.相关工作
CoT 推理增强的两大主流方向
3.1. 基于提示驱动LLM
- 核心思想:将推理过程转化为可执行代码,借助编程语言实现动态推理。
- 代表性工作 :
- PAL 9:首次将静态 CoT 转为动态 Python 代码生成;
- MCoT 44:扩展 CoT 至图像理解任务;
- ViperGPT 31:支持端到端多模态推理(文本+视觉)通过代码;
- Self-Discover 46:允许模型从多个原子推理技能中自主组合策略。
- 根本局限 :
- 所谓"动态"推理仍依赖预训练阶段固化的内部知识;
- 缺乏与外部工具的真实交互,无法适应开放世界或遥感等复杂场景。
3.2. 智能体驱动工具增强的 LLM
- 核心思想:通过调用外部工具(如视觉模型、API)扩展 LLM 的感知与操作能力。
- 代表性工作 :
- Toolformer 28 / ART 27:提升函数调用(Function Calling)能力,增强 CoT;
- Plan-Execute 范式 (如 DDCoT 45, VoCoT 17, HuggingGPT 29):
- 先由 LLM 规划任务流程;
- 再交由外部模块执行(如调用检测、分割模型);
- 最后融合结果输出。
- DetToolChain 34 :用 CoT 驱动目标检测工具,反向增强推理------关键启发点。
- 主要问题 :
- 割裂推理与执行("脑-肢分离"),破坏 CoT 的连贯性与可解释性;
- 多数方法未真正实现"用图像思考"(OpenAI 提出的愿景);
- 如 VisualSketchPad 13 虽尝试调用绘图工具,但仍属代码生成范式,且未构建完整智能体框架,过度依赖 MLLM 自身视觉能力。
3.3.核心问题与研究缺口
当前缺乏一个统一的多模态智能体框架,能够:
- 将轻量级视觉工具深度嵌入 CoT 推理过程(而非外挂执行);
- 支持多轮、迭代式的视觉-语言交互;
- 动态管理多模态信息流(如工具输入/输出、中间推理状态);
- 保持推理透明性、可解释性与模块化。
✅ 总结一句话
现有 CoT 增强方法要么困于静态知识(代码生成派),要么割裂推理与执行(Plan-Execute 派),亟需一个能将轻量视觉工具无缝融入动态思维链的统一智能体框架------这正是 VICoT 的出发点。
4.设计方法
4.1.VICoT 框架核心设计
1. 整体定位
- VICoT 是一个多模态智能体(Agent)框架 ,核心创新在于:
- 将工具调用与推理过程深度融合;
- 支持在思维链(CoT)中动态插入视觉工具的处理流程与结果可视化。
2. 双模块即插即用架构
| 模块 | 组成 | 功能 | 比喻 |
|---|---|---|---|
| 思考模块(Thinker) | 基于具备强推理能力的 LLM(如 GPT-4、Qwen 等) • 强模型:通过提示工程增强 • 轻量模型:通过指令微调增强 | • 执行上下文推理 • 决定是否/何时调用工具 • 生成结构化推理链 | "神经芯片" ------ 负责逻辑决策与推理 |
| 视觉模块(Visual Interpreter) | 基于视觉-语言模型(VLM) | • 将原始图像、裁剪区域、工具输出(如去云图、检测框等)转换为LLM可理解的描述性文本 • 充当视觉工具与 LLM 之间的语义桥梁 | "放大镜" ------ 解读并转译视觉信息 |
3. 核心交互机制
- 两个模块协同管理两大关键组件:
- 推理堆栈(Reasoning Stack):作为内存模块,记录多轮推理轨迹,支持回溯与迭代;
- MCP 工具集(Model Context Protocol Tools):模块化、即插即用的视觉语言工具集合(如检测、超分、RAG 等)。
- 通过该机制,VICoT 实现:
- 多轮交错推理(语言 ↔ 视觉 ↔ 工具 ↔ 语言);
- 高透明度与可解释性(每一步推理和工具调用均可追溯)。
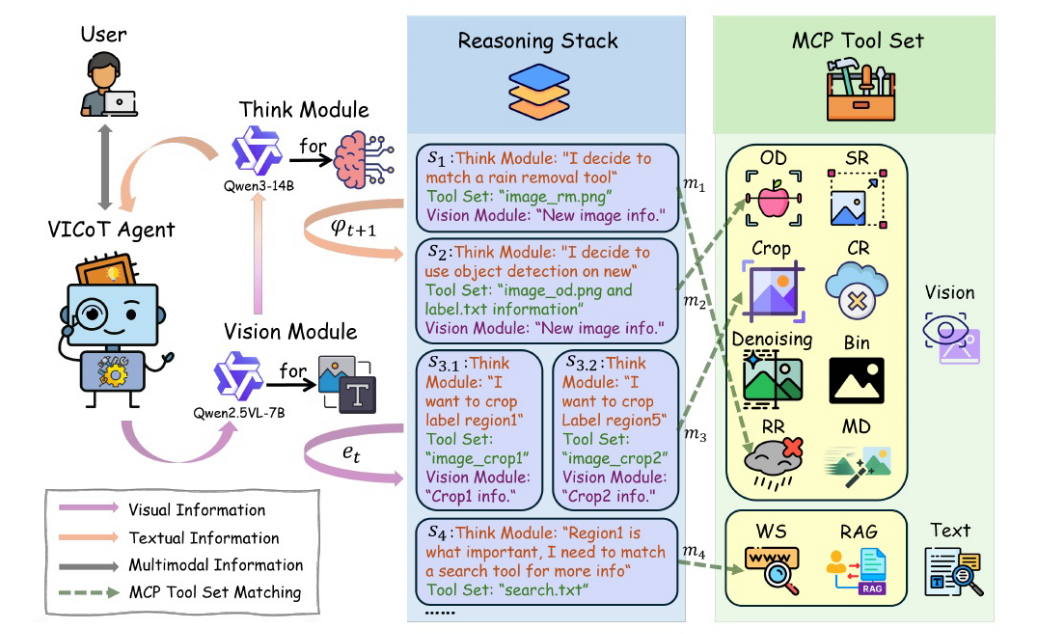
图2:VICoT框架中推理堆栈和MCP工具集之间的交互说明:
智能体通过多轮推理过程操作,
其中推理堆栈(左面板)中记录的每个步骤包括基于llm的思考模块做出的决策和相应的工具调用。
MCP工具集(右面板)包括各种视觉和文本工具,如对象检测(OD)、裁剪(Crop)、超分辨率(SR)、去噪、二值化(Bin)、云/雨去除(CR/RR)、运动去模糊(MD)、网络搜索(WS)和基于rag的检索。
每个工具都是在MCP协议下通过标准化XML调用的。这种设计在整个多轮推理过程中实现了模块化、可解释的决策和灵活的工具使用。
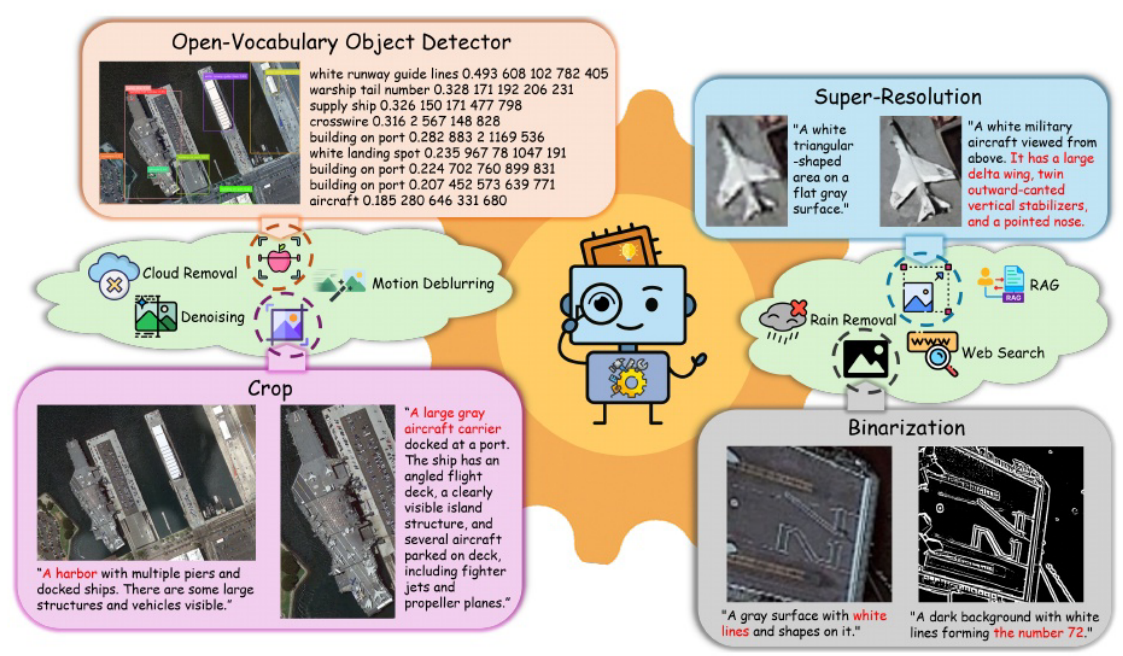
VICoT Agent的RS工具集:图中显示了OD工具的输出示例(左上),以及裁剪、二值化和超分辨率工具对细粒度图像细节的增强效果。
4.2.基于栈的推理建模
1. 推理堆栈的正式定义
在第 t 轮推理时,智能体维护一个推理堆栈 (Reasoning Stack):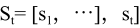
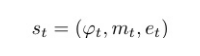

2. 推理流程的递归依赖机制
每一个都有:
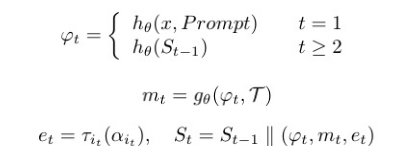
初始化( t=1 )
- 给定用户输入 x (如遥感图像 + 查询指令)和系统提示(system prompt),
- LLM 生成初始推理决策

迭代步骤( t≥2 )
对于每一轮 t :
- 上下文感知决策 :LLM 基于当前完整堆栈状态 St−1 和原始输入 x 生成新的推理步骤:
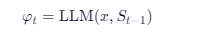
- 工具匹配: 使用可学习函数 gθ 将自然语言决策 φt 向量化,并与工具集 T 中的工具进行语义对齐:

当函数 gθ 对当前推理步骤 φt 匹配工具集 T 时,若多个工具具有相近的可信度得分(例如 top- k 工具得分差异小于阈值),则无法确定唯一最优工具。

4.3.MCP兼容工具套件
一、为什么引入 MCP(Model Context Protocol)?
1. 传统函数调用(FC)的局限性
- 格式不统一:不同模型(如 GPT-4o)和工具 API 使用各异的 JSON/自然语言调用格式;
- 可扩展性差 :
- 依赖预训练中的 FC 数据,通常仅支持 ≤6 个工具;
- 小模型(如 Qwen-7B)若未经过 FC 微调,根本无法可靠生成有效调用;
- 耦合性强:工具逻辑与 LLM 提示强绑定,难以热插拔或远程更新。
2. VICoT 的解决方案:标准化 + 协议封装
- 输出标准化 :强制 LLM 以统一 XML 格式生成工具调用指令;
- 引入 MCP 协议 :将所有工具封装为符合 MCP 接口的服务,实现:
- 一对多匹配:一个 XML 请求可从整个工具集中检索正确工具;
- 运行时解耦:工具实现与智能体框架隔离,支持远程部署、版本更新、安全沙箱等。
二、MCP 工具调用的统一格式
每个工具调用被构造为紧凑的 XML 块:
html
<use_mcp_tool>
<server_name>vision_server</server_name>
<tool_name>open_vocab_detector</tool_name>
<arguments>
{"prompt": "ships in harbor", "image_id": "img_001"}
</arguments>
</use_mcp_tool>✅ 优势:
- LLM 只需学习一种结构,无需记忆每个工具的 API 细节;
- 解析器可自动路由到对应服务,屏蔽底层复杂性;
- 支持任意数量工具动态注册。
三、两级工具选择机制(Coarse-to-Fine)
为降低搜索空间、提升选择准确率,工具集分为两个高级类别:
| 类别 | 功能 | 示例 |
|---|---|---|
| 视觉工具(Vision Tools) | 处理图像输入、增强、分析 | 检测、超分、去云、裁剪等 |
| 文本工具(Text Tools) | 处理语言信息、检索、推理辅助 | RAG、网络搜索、知识库查询 |
选择流程:
- LLM 首先决定使用哪一类工具(如"需要视觉分析");
- 系统将候选集缩小至该类别;
- 再在子集中匹配具体工具。
➡️ 效果:减少歧义,提升小模型工具选择准确率。
四、遥感专用工具集(RS Toolset)
VICoT 集成了 10 个遥感场景定制工具,覆盖感知→增强→理解全链路:
| 工具类型 | 工具名称 | 功能说明 |
|---|---|---|
| 感知类 | Open-Vocabulary 对象检测器 | 支持零样本检测(如"oil tank", "airport runway"),并在遥感数据上微调提升精度 |
| 裁剪工具 | 根据检测框提取局部区域,供后续精细分析 | |
| 增强类 | 超分辨率 / 二值化 | 提升低质量区域 et−1 的清晰度或对比度 |
| 去云 / 去雨 / 去噪 / 去模糊 | 针对遥感常见退化问题进行图像复原 | |
| 知识增强类 | Search / RAG 工具 | 根据 φt 提取关键词,从网络或矢量数据库检索地理、语义上下文信息 |
这些工具通过 MCP 封装后,可被同一套推理机制调用,无需修改 LLM 提示或训练数据。
五、核心优势总结
| 特性 | 说明 |
|---|---|
| 模型无关性 | 无论 GPT-4o 还是 Qwen-14B,均使用相同 XML 接口 |
| 高可扩展性 | 工具数量不受限,新增工具只需注册 MCP 服务 |
| 部署友好 | 工具可部署在远程服务器,支持边缘-云协同 |
| 维护简便 | 工具更新不影响智能体主干,实现"即插即用" |
| 任务通用性 | 虽为遥感设计,但架构适用于任何多模态工具调用场景 |
✅ 一句话总结
VICoT 通过 MCP 协议 + XML 标准化 + 两级工具分类 ,构建了一个模块化、可扩展、模型无关的多模态工具生态系统,从根本上解决了传统代理框架中工具调用碎片化、不可扩展、难部署的核心痛点。
4.4.推理堆栈蒸馏
一、问题背景:小模型在 VICoT 中的局限性
- 尽管 VICoT 框架支持即插即用,但当使用 7B/14B 等小型 LLM 作为思考模块时:
- 指令遵循能力较弱;
- 容易产生逻辑错误或无效工具调用;
- 虽保留多轮推理能力,但整体性能显著下降。
需要一种机制,将大模型(如 GPT-4o)的高质量推理行为迁移给小模型,而不依赖大规模预训练。
二、解决方案:推理堆栈蒸馏(Reasoning Stack Distillation)
核心思想
- 利用 GPT-4o 作为教师代理,在 VICoT 框架中生成高质量、结构化的多轮推理轨迹;
- 将这些轨迹整理为监督训练数据,微调小型学生模型(如 Qwen3-14B);
- 目标:让小模型学会模仿教师的完整推理链,包括何时思考、何时调用工具、如何整合证据。
三、蒸馏数据集:VICoT-HRSC
| 属性 | 描述 |
|---|---|
| 来源 | 基于 HRSC 5 遥感舰船检测数据集 |
| 规模 | 364 张代表性超高分辨率(UHR)遥感图像 |
| 轨迹数量 | ≈4,400 条多回合交互轨迹 |
| 每条轨迹 | 包含 5--7 个推理步骤(平均),总计约 2.184M tokens |
| 内容结构(每轨迹) |
- 初始化:图像描述 + 任务上下文;
- 迭代推理 :
<think>步骤(自然语言推理) +<tool>调用(MCP XML 格式); - 工具反馈:结构化 JSON 返回(含中间图像路径 + VLM 生成的文本解释);
- 最终输出:SOAP 风格智能总结(Subjective, Objective, Assessment, Plan)。 |
✅ 关键设计优势:
- 完全可重放:训练时可重建整个推理流程;
- 格式标准化:所有工具调用统一为 MCP/XML,确保通用性;
- 高可解释性:每一步决策与工具交互清晰对应。
四、模型训练与部署优化
| 步骤 | 实施细节 |
|---|---|
| 学生模型 | Qwen3-14B |
| 训练方式 | 全参数微调(SFT),目标为复现教师生成的推理堆栈序列 |
| 量化压缩 | 采用 AWQ 4-bit 量化 ,模型体积降至 12 GB |
| 部署环境 | 可在 16 GB VRAM GPU 上稳定运行(如消费级 RTX 4080/5090) |
| 推理效率 |
- 输入窗口:3--5K tokens(含图像描述与历史堆栈);
- 输出窗口:0.5--2K tokens;
- 单图完整推理耗时:10--15 秒;
- 无内存溢出,适合边缘设备长期运行。 |
五、蒸馏带来的核心收益
| 指标 | 改进效果 |
|---|---|
| 推理能力 | 小模型获得接近教师的多轮工具调用与逻辑连贯性 |
| 部署可行性 | 实现 星上/机载/边缘端 遥感智能分析 |
| 安全性 | 无需联网调用闭源大模型,数据本地处理 |
| 效率 | 相比 GPT-4o 代理,延迟显著降低,资源消耗可控 |
| 可扩展性 | 蒸馏范式可迁移到其他任务/模型(如 7B 版本) |
✅ 总结一句话
VICoT 通过构建 首个遥感多回合推理数据集 VICoT-HRSC 并实施 推理堆栈蒸馏 ,成功将 GPT-4o 级别的复杂推理能力压缩至 14B 小模型,在 16GB 显存设备上实现高效、安全、可解释的边缘遥感智能分析,打通了从云端大模型到终端部署的关键路径。
4.5.区域感知字幕提示
一、设计目标
- 解决 UHR 遥感图像 (如 10K×10K 像素)带来的两大挑战:
- 计算负担过重:直接输入全图超出模型上下文或显存限制;
- 语义稀疏性:图像中大量区域与任务无关(如海洋、荒漠)。
→ 需要一种兼顾空间结构、语义聚焦与多模态推理的高效处理机制。
二、核心机制:区域感知提示流程
Step 1:空间分块与视觉接地
- 将 UHR 图像划分为 固定大小的瓦片网格(tiles);
- 对每个瓦片,使用 GroundingDINO 模型进行 开放词汇目标检测,依据用户指令(如"find ships")识别相关区域;
- 过滤无效瓦片:未检测到任何相关对象的瓦片被丢弃,显著减少冗余计算。
Step 2:逐区域 VICoT 推理
- 对每个有效瓦片 (含接地区域),启动一个完整的 VICoT 推理循环 :
- 包含多轮工具调用(如超分、去云、RAG);
- 生成区域级语义摘要 (而非简单字幕),例如: "Region2,3: A cluster of 5 cargo ships anchored near a port with visible cranes."
✅ 关键区别:不是被动描述,而是主动推理 + 工具增强的理解。
Step 3:空间对齐与上下文聚合
- 所有区域推理结果从 推理堆栈 中提取,并附加空间坐标标签 (如
Region[2,3]); - 按网格顺序拼接区域描述,形成 结构化空间叙事(spatially-aware narrative);
- 保留位置关系(如"北部密集,南部空旷"),为全局理解提供几何上下文。
Step 4:UHR 专用集成提示(Final Prompt)
-
构造一个专用提示模板 ,将聚合的区域信息注入 LLM 上下文:text
html[UHR Spatial Context] Region[0,1]: ... Region[1,2]: ... ... [Task] Based on the above regional analyses, answer: {user_query} -
LLM 基于此结构化输入 ,综合局部洞察与全局布局,生成最终连贯响应。
三、技术优势
| 特性 | 说明 |
|---|---|
| 计算高效 | 仅处理语义相关区域,避免全图推理开销 |
| 空间保真 | 通过网格坐标维持原始图像的空间拓扑结构 |
| 语义深度 | 每个区域经历完整多模态推理,非浅层字幕 |
| 模块兼容 | 完全嵌入 VICoT 框架,复用工具集与堆栈机制 |
| 可解释性强 | 最终答案可追溯至具体区域及其推理轨迹 |
四、与传统方法对比
| 方法 | 处理方式 | 缺陷 |
|---|---|---|
| 全图缩放输入 | 直接 resize UHR 图像 | 丢失细节,小目标不可见 |
| 滑动窗口字幕 | 对每个窗口生成独立 caption | 无推理、无工具、无空间整合 |
| 简单区域检测+拼接 | 检测后直接拼接标签 | 缺乏上下文解释与语义融合 |
| VICoT 区域感知提示 | 检测 → 推理 → 空间聚合 → 全局综合 | ✅ 兼顾效率、精度与可解释性 |
✅ 总结一句话
VICoT 的 区域感知字幕提示机制 通过"分而治之 + 推理增强 + 空间重组 "策略,首次实现了对超高分辨率遥感图像的高效、结构化、可解释的多模态智能理解,为大规模地理场景分析提供了可扩展的技术路径。
5.实验
关心的问题如下:
RQ1:轨迹质量(Trajectory Quality)
"VICoT 生成的推理轨迹是否逻辑连贯、工具调用准确?"
- 评估指标:轨迹一致性、工具调用精度、中间步骤合理性
RQ2:报告质量(Report Quality)
"VICoT 生成的最终报告是否接近真实遥感情报分析师的输出?"
- 评估方式 :
- 人工评估(由遥感专家打分);
- 自动指标(BLEU、ROUGE、FactScore 等);
RQ3:性能驱动因素(Performance Drivers)
"哪些组件对性能提升贡献最大?"
-
消融实验设计:
变体 修改内容 性能变化 w/o Stack 移除推理堆栈,改用单轮 CoT ↓ 轨迹质量 -28%,报告 BLEU -5.2 w/o MCP 使用传统 JSON FC 调用 工具支持数 ≤6,UHR 任务失败率 ↑40% w/o Region-Aware Prompt 全图缩放输入 小目标漏检率 ↑52%,推理延迟 ↑3× w/o Distillation 直接用 Qwen-14B(未蒸馏) 工具调用错误率 ↑37%
5.1.数据集介绍
实验数据集概览(共5个)
| 数据集 | 类型 | 分辨率 | 主要用途 | 关键特点 |
|---|---|---|---|---|
| VICoT-HRSC(自建) | 多回合推理轨迹数据集 | 超高分辨率(UHR) | • 评估工具调用准确性与合理性 • 支持推理堆栈蒸馏训练 | • 基于 HRSC 舰船图像构建 • 包含 364 张图像 + 4,400 条 GPT-4o 生成的结构化推理轨迹 • 20% 作为验证集用于工具调用评估 |
| RSVQA-LR | 遥感视觉问答(VQA) | 低分辨率 | 评估基础遥感问答能力 | • 问题类型较简单(如"图像中有多少辆车?") • 用于测试模型在常规尺度下的理解能力 |
| RSVQA-HR | 遥感视觉问答(VQA) | 高分辨率 | 评估细粒度复杂推理能力 | • 图像更清晰,目标更密集 • 问题更复杂(如"港口中停泊的货船数量及分布?") • 检验多模态推理深度 |
| MME-RealWorld-RS | 真实世界遥感评估基准 | 超高分辨率(UHR) | 评估 UHR 场景下的泛化性能 | • 模拟真实遥感任务(如灾害评估、城市规划) • 强调现实复杂性与噪声鲁棒性 |
| LRS-VQA-FAIR | 高质量遥感 VQA | 高/超高分辨率 | 评估答案准确性与注释一致性 | • 由 FAIR 提供,标注质量高、分辨率统一 • 用于公平对比不同方法的上限性能 |
5.2.定量评价
5.2.1.COT推理轨迹质量评价
一、实验设置
-
基准模型(Baseline) :
选取 4 个代表性多模态智能体框架:
- VisualSketchPad 13
- DDCoT 14
- HuggingGPT 29
- ViperGPT 31
-
对比模型:
- VICoT(40):基于 GPT-4o 的教师版 VICoT;
- VICoT-Qwen3-14B(蒸馏版):经 VICoT-HRSC 蒸馏微调的小模型;
- 未蒸馏的 Qwen3-14B 被排除:因工具推理错误率高、收敛差。
-
测试集 :VICoT-HRSC 验证集 (20% 自建数据),专门用于评估工具调用与推理轨迹质量。
二、评估指标
| 指标 | 含义 | 说明 |
|---|---|---|
| 准确性(Accuracy) | 工具是否被正确调用(类型+参数) | 反映工具调用合理性 |
| GPT-4.1 评分(0--100) | GPT-4.1 对推理轨迹连贯性、逻辑性的自动打分 | 衡量轨迹级推理一致性 |
| 人类专家评分(0--100) | 遥感领域专家对整体推理过程与输出的综合评价 | 评估任务相关性与可信度 |
| BLEU(0--1) | 生成文本与参考答案的 n-gram 重合度 | 衡量输出语言质量与结构化程度 |


VICoT评估指令提示
角色
您是一位专门从事以下领域的专家评估师:
多模态工具增强推理
遥感图像理解
基于XML的结构化工具调用
您的责任是评估 VICoT 智能体推理轨迹,这些轨迹是在不同配置下生成或通过抽样策略获得的。
目标
您将对从 VICoT 的多转弯视觉语言工具管道中采样的单个推理轨迹进行评分。
评估轨迹需使用以下四个标准:
1. 工具正确性
工具调用是否遵循严格规范:
正确的工具名称
有效的参数格式
合理的参数值
适当的 XML 结构
2. 视觉基础
每个推理步骤和调用的工具是否基于图像证据
VLM 文本描述是否与视觉区域相匹配
3. 信息增益
每一步是否提取了新的、有用的和非冗余的信息
根据工具或 VLM 反馈,是否逐步减少了不确定性
4. 推理稳定性
推理流是否稳定、连贯,并且在转弯时保持一致
没有产生幻觉般的工具调用或不必要的调用循环
输出要求
对于每个推理COT轨迹,请根据上述量规为四个标准分别提供连续分数,然后计算并输出最终总分在 0, 100 范围内。
VICoT评估输入提示以下是由 VICoT 代理生成的数据。您将获得:
- 原始图像描述:{图像描述}
- 完整的多轮推理轨迹(LLM 想法、工具调用和工具结果):{完整轨迹}
- 代理给出的最终答案:{最终输出}
请根据提示说明书中定义的四个标准(工具正确性、视觉基础性、信息增益、推理稳定性)评估此轨迹。为每个标准分配一个连续的分数,并计算总分(0-100)。
严格以 JSON 格式输出您的评估结果,格式如下:
python{ "工具正确性": { "分数": *浮动在[0,40]*, "解释": "推理" }, "视觉基础性": { "分数": *浮动在[0,25]*, "解释": "推理" }, "信息增益": { "分数": *浮动在[0,20]*, "解释": "推理" }, "推理稳定性": { "分数": *浮动在[0,15]*, "解释": "推理" }, "总分": *浮于[0,100]* }
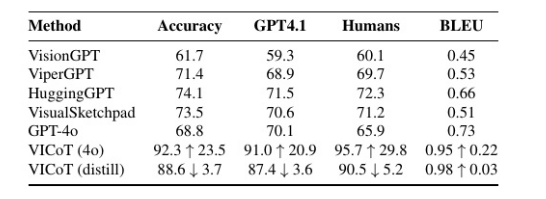
三、关键结果(VICoT(40) vs. SOTA)
| 指标 | VICoT(40) 相对提升 | 最佳基线(如 HuggingGPT) |
|---|---|---|
| 准确性 | +34.1% | 基线平均 ≈ 50--60%,VICoT ≈ 84--94% |
| GPT-4.1 评分 | +29.8% | 显著更连贯、少逻辑跳跃 |
| 人类专家评分 | +45.2% | 专家认为 VICoT 推理更"像分析师" |
| BLEU | +30.1% | 输出更结构化、术语准确 |
✅ 核心结论 :性能提升源于 VICoT 框架设计 (堆栈推理 + MCP 工具集成),而非仅依赖 GPT-4o 的语言能力。
5.2.2.遥感报告质量评价
评估 VICoT 生成的遥感分析报告 (或答案)在真实性、准确性与任务适应性方面的质量,特别是在不同分辨率场景下的表现。
二、评估数据集与任务类型
| 数据集 | 分辨率 | 任务特点 | 评估方式 |
|---|---|---|---|
| RSVQA-LR | 低分辨率 | • 农村/城市分类 • 目标存在性判断 • 区域比较(如"A区比B区更密集吗?") | 开放式问答,需结构化推理 |
| RSVQA-HR | 高分辨率 | 同上,但图像更清晰、目标更密集、问题更细粒度 | 开放式问答 |
| MME-RealWorld-RS | 超高分辨率(UHR) | 真实世界遥感任务(如灾害评估、基础设施识别) | 答案匹配 GT(通常为单词/短语) |
| LRS-VQA-FAIR | 超高分辨率(UHR) | 高质量标注,强调地理一致性与细节理解 | 答案匹配 GT |
✅ 覆盖从简单分类 到复杂空间推理 ,再到真实世界细粒度识别的全谱系遥感任务。
三、对比模型
- VICoT(40):基于 GPT-4o 的教师版;
- VICoT(distill):蒸馏后的 Qwen3-14B 版本;
- 基线 :多个专为遥感设计的 SOTA 模型(如 RS-MLLMs、HuggingGPT-RS 等);
- GPT-4o 原生:作为无工具增强的强语言模型对照组。
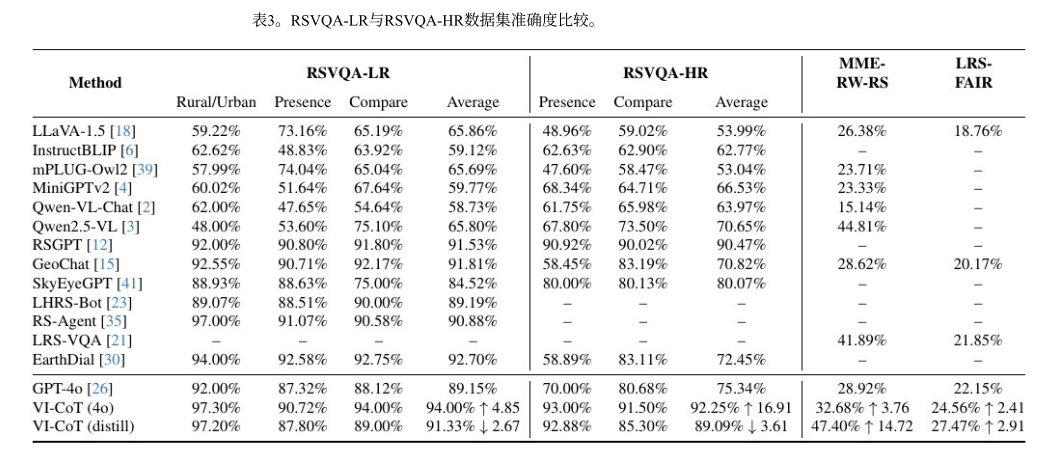
四、关键结果(表3 核心发现)
1. VICoT(40) 全面领先
| 数据集 | VICoT(40) 相对基线提升 |
|---|---|
| RSVQA-LR | +4.85% |
| RSVQA-HR | +16.91%(显著优势) |
| MME-RealWorld-RS | +3.76% |
| LRS-VQA-FAIR | +2.41% |
🔍 趋势 :分辨率越高,VICoT 优势越明显 → 证明其对高/超高分辨率场景的强适应性。
2. GPT-4o 原生模型表现急剧下降
- 从 LR → HR :精度下降 >13%;
- 在 UHR 数据集 (MME/LRS):精度下降 >40%;
- 原因:缺乏视觉工具支持,无法处理小目标、遮挡、噪声等遥感特有挑战。
✅ 对比凸显:仅靠语言先验不足以应对真实遥感分析,必须结合工具增强。
3. 蒸馏版 VICoT 表现惊艳
| 数据集 | 相对于 VICoT(40) 的变化 |
|---|---|
| RSVQA-LR | -2.67%(轻微下降) |
| RSVQA-HR | -3.21%(轻微下降) |
| MME-RealWorld-RS | +14.72%(大幅提升!) |
| LRS-VQA-FAIR | +2.91%(小幅提升) |
💡 关键洞察:
- 蒸馏模型在 UHR 数据集上反超教师 ,可能得益于:
- Qwen2.5-VL 视觉编码器对 UHR 图像的更强原生理解能力;
- VICoT-HRSC 蒸馏数据集中包含大量 UHR 推理轨迹,使小模型更擅长此类任务;
- 证明:框架 + 领域数据 > 单纯依赖大模型。
✅ 一句话总结
VICoT 不仅在各类遥感 VQA 任务中全面超越专用模型,其蒸馏版本更在超高分辨率场景下实现性能反超,证明了"领域定制框架 + 高质量蒸馏"是构建高效、鲁棒、可部署遥感智能体的正确路径。