note
文章目录
- note
- [一、Can LLMs Clean Up Your Mess](#一、Can LLMs Clean Up Your Mess)
- [二、Scaling Synthetic Instructions to Pre-Training Scale](#二、Scaling Synthetic Instructions to Pre-Training Scale)
- Reference
一、Can LLMs Clean Up Your Mess
【大模型数据工程进展】主要讲的故事是大模型增强型数据准备展开系统性综述,围绕数据清洗、数据集成、数据增强三大任务,分析从传统基于规则的方法向提示驱动、上下文感知、智能体为核心的范式转变。Can LLMs Clean Up Your Mess? A Survey of Application-Ready Data Preparation with LLMs,https://arxiv.org/pdf/2601.17058,
解决当前的问题:
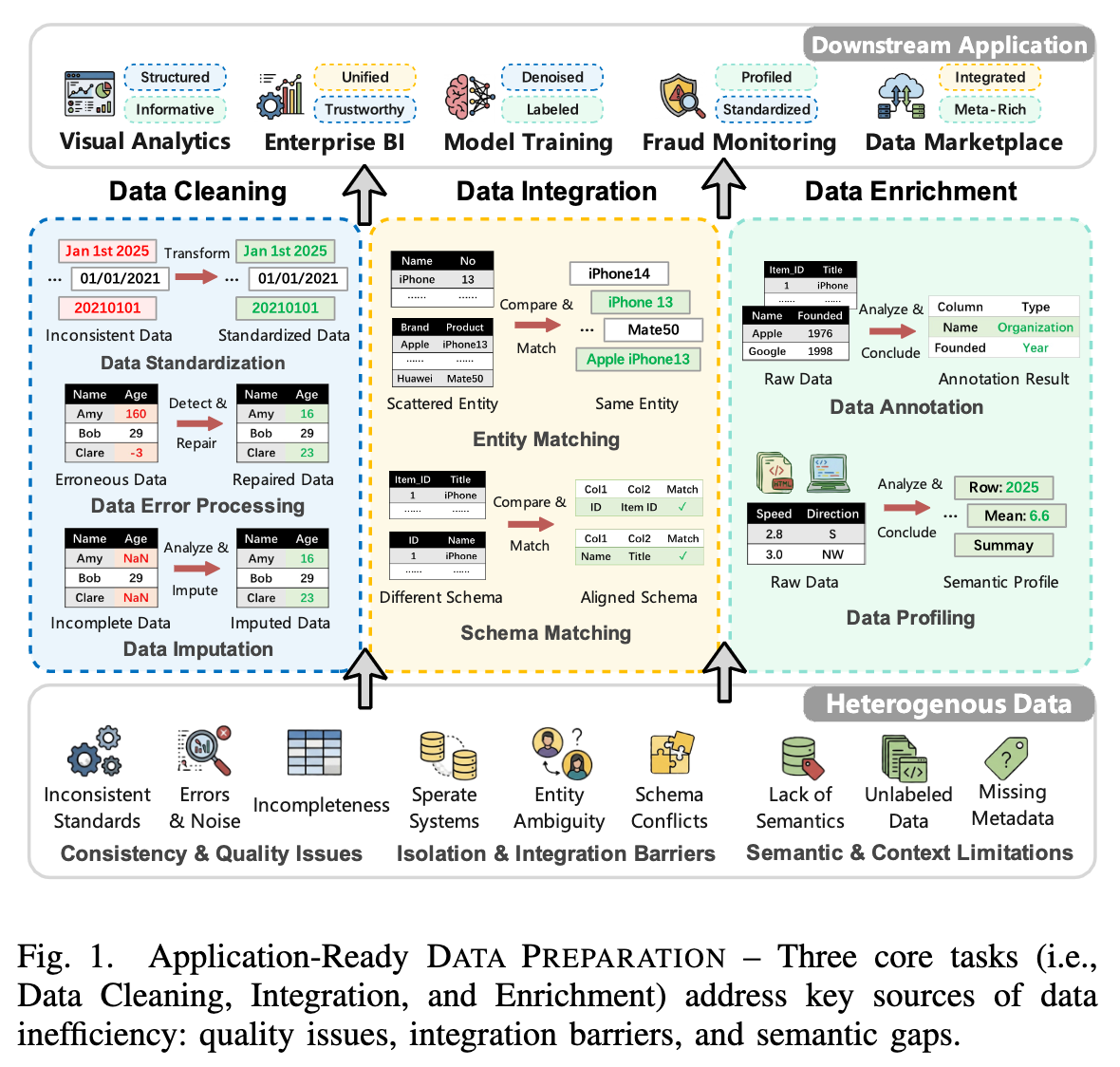
主要数据处理的步骤:
1)数据清洗【数据标准化:统一数据格式,基于提示端到端(LLM-GDO)、代码生成(Evaporate)、智能体辅助(CleanAgent);数据错误处理:检测并修复错误值,提示端到端(IterClean)、函数合成(LLMClean)、任务自适应微调(GIDCL)、混合LLM-ML(ZeroED);数据填补:填充缺失值,提示端到端(CRILM)、检索引导(RetClean)、模型优化(LLM-REC)】;
2)数据集成,整合不同来源数据,【实体匹配:关联同一现实世界实体的记录,提示端到端(MatchGPT)、任务自适应微调(FTEM-LLM)、多模型协同(COMEM);模式匹配:对齐不同数据集的列或属性,提示端到端(LLMSchemaBench)、检索增强(KG-RAG4SM)、模型优化(TableGPT2)、智能体引导(Agent-OM)】;
3)数据增强,扩充数据集语义信息【数据标注:为数据分配标签或类型,提示端到端(CHORUS)、RAG上下文增强(RACOON)、微调(OpenLLMAnno)、混合模型(CanDist)、智能体辅助(STAAgent);数据剖析:生成语义画像与元数据,提示端到端(AutoDDG)、RAG上下文增强(LLMDap)】。
二、Scaling Synthetic Instructions to Pre-Training Scale
【大模型训练数据合成工具进展】讲的故事是将互联网规模预训练文档转化为大规模合成指令-答案对的方法,通过挖掘~1800万真实用户查询生成指令模板,结合语义匹配与高斯池化技术将模板与预训练文档配对,生成10亿+高质量指令-答案对,验证 "预训练直接用指令 - 答案对" 的可行性。FineInstructions: Scaling Synthetic Instructions to Pre-Training Scale,https://arxiv.org/pdf/2601.22146,代码在https://huggingface.co/fineinstructions。看核心思路:
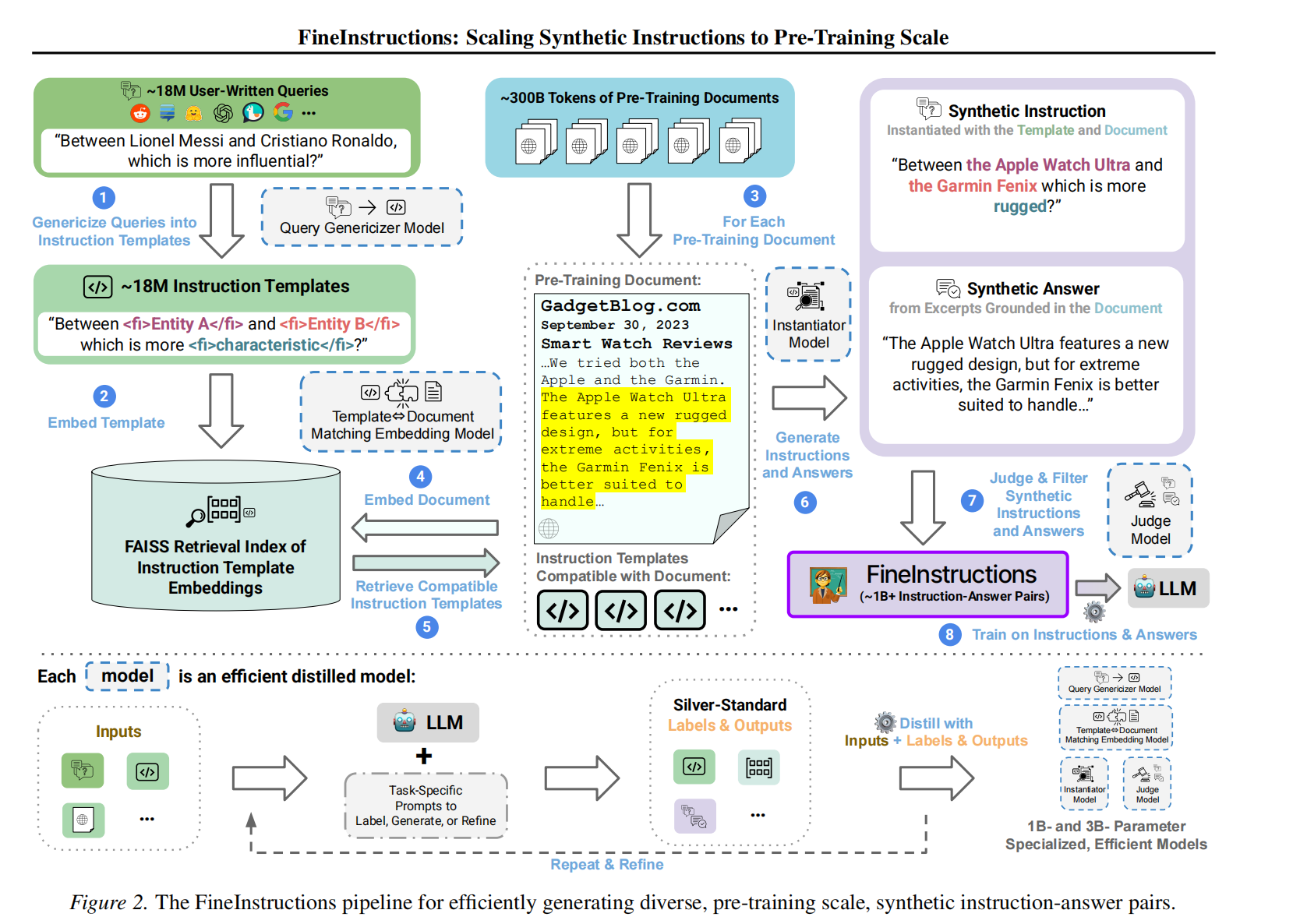
1)指令模板生成【step1.收集18M真实用户查询(含论坛、搜索引擎、prompt库)->step2.过滤有害查询(OpenAIModerationAPI)+去基准污染;->step3.Llama-3.21B模型将查询转为带标签的通用模板】;
2)文档-模板匹配【step1.BGE-M3嵌入模板的"兼容文档描述",构建FAISS索引->step2.文档转为知识描述并嵌入,检索5个候选模板->step3.两阶段微调BGE-M3(余弦相似度损失),支持高斯池化】;
3)指令-答案生成【step1.蒸馏Llama-3.23B模型,基于模板+文档实例化指令->step2.答案要求:文档片段占比≥80%,减少生成式幻觉->step3.过滤:FlowJudge模型(3.8B参数量)按5分制筛选,保留≥4分数据,每文档平均生成3个指令-答案对,总数据量1B+】
Reference
1 Can LLMs Clean Up Your Mess? A Survey of Application-Ready Data Preparation with LLMs,https://arxiv.org/pdf/2601.17058
2 FineInstructions: Scaling Synthetic Instructions to Pre-Training Scale,https://arxiv.org/pdf/2601.22146,代码在https://huggingface.co/fineinstructions