标题
Asynchronous parallel surrogate optimization aided neural network design with variable evaluation runtime for streamflow and pollutant forecast
背景
作者
Wei Xia , Wei Lu , Chi Zhang , Christine A. Shoemaker
期刊来源
Journal of hydrology
DOI
10.1016/j.jhydrol.2025.134378
摘要
深度学习模型(例如,递归神经网络,RNN)越来越多地用于水文预测。然而,为这些模型确定合适的超参数仍然是一个具有挑战性的问题。我们的研究表明,水文预测中深度学习模型的超参数优化(HPO)是高度多模态的,不同超参数组合的评估运行时可能会有很大变化。这使得传统方法(如随机搜索)在寻找全局最优解方面效率低下,同步并行优化方法在使用并行计算资源方面效率低下。为了解决这些挑战,我们提出了一种新的异步并行代理全局优化方法(ASONN),该方法结合了先进的代理采样策略,以提高采样质量和并行运行效率。我们的新方法通过在优化采样中使用代理模型的估计评估精度和估计评估运行时来考虑运行时变化,从而在保持解决方案质量的同时最大限度地提高计算资源利用率。我们将该方法应用于四种不同的水流和污染物预测问题(即,总溶解磷(TDP),颗粒磷(PP),总悬浮固体(TSS))。结果表明,全局优化方法在效率和求解精度方面明显优于随机搜索,HPO后的RNN预测使用全局优化方法得了较高的KGE (KGE)目标函数值(流量预测0.8795,TDP 0.8475, PP 0.7545)。TSS为0.6728)。与以前的异步方法相比,ASONN可以将HPO过程加快60%。
研究区域以及数据来源
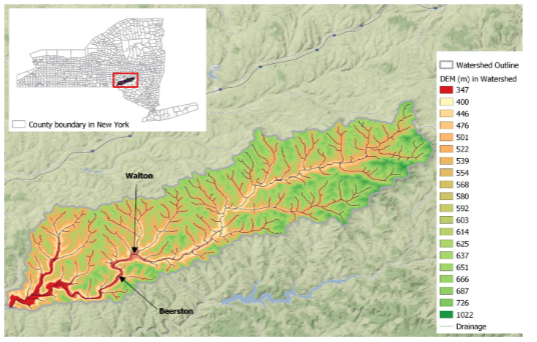
Cannonsville流域位于纽约州北部,面积1178平方公里,是纽约市最大的饮用水水库之一。它最初在Tolson和Shoemaker (2007a)中进行了研究,并用于演示拟议的ASONN。图5显示了流域的总体地图和溪流布局,这是一个主要由森林(占土地面积的59%)、农业草地(26%)和农田(10%)覆盖的农村地区。城镇地区占比不足0.5%,为土地面积。自Tolson和Shoemaker (2007a)建立Cannonsville流域水土评估工具(SWAT)模型以来,原始模型被前人广泛采用和修改,以满足各种建议。
算法
超参优化
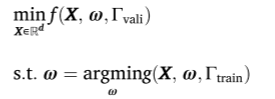
低级优化问题通常是耗时的,特别是对于具有大型网络架构和使用大型数据集训练的深度学习模型。模型参数通常用随机优化器(例如,随机梯度体面)来解决。现在深度学习模型的这个训练过程很容易需要几分钟到几小时甚至几天的时间来运行。此外,由于优化方法的随机性,使用相同的超参数集X和训练数据集Γtrain两次求解底层优化问题可能会导致不同的学习模型参数ω,从而导致不同的验证误差f(*)。因此,在实践中,对于给定的超参数集X,低级优化问题可能需要求解多次才能更好地估计给定X的f(*)。这种重复可能会进一步增加HPO问题的计算时间。在例子中,对于给定的X,解决了5次低级优化,并使用了性能最好的模型。
同步和异步并行
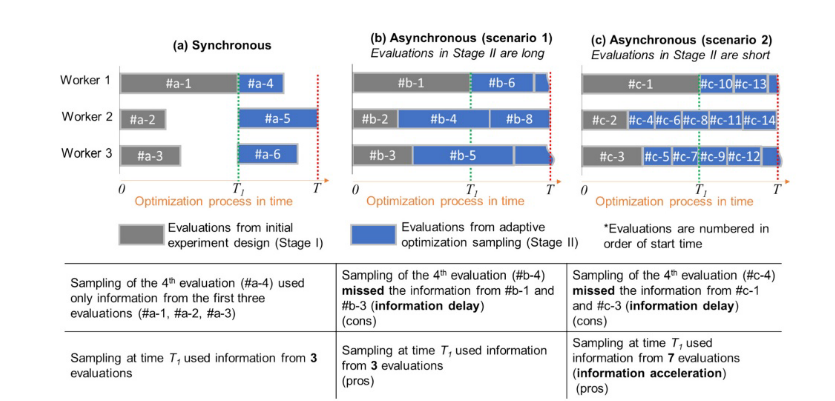
同步和异步并行优化采用两种不同的并行化方法实现,但目标相同,即加快总体计算时间并获得更好的性能。在迭代优化中,同步并行优化涉及一系列称为迭代或代的计算段。每次迭代或代内,在每个处理器上计算求值。
异步并行代理优化框架:ASONN
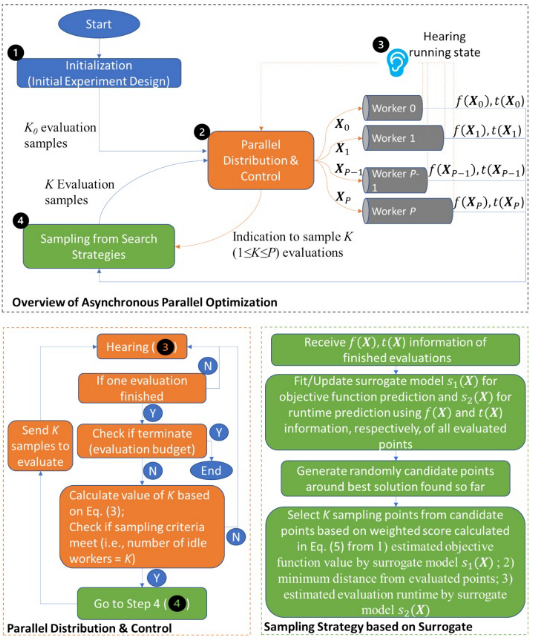
异步并行代理优化框架(ASONN)给出了异步并行优化框架的概述)并行分布与控制,听取待处理评估(正在运行的评估)的运行状态,以及下一个评估点的采样策略。许多异步并行优化方法的通用图,而使异步并行方法不同的是并行分布和控制以及采样策略步骤。
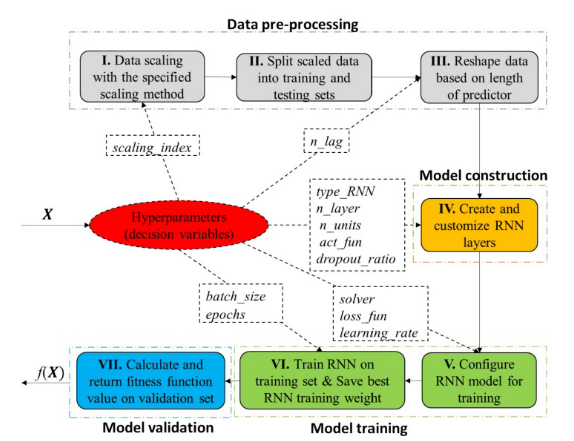
递归神经网络和超参数
在提出候选点(即一组超参数)之后,将对原始数据集进行缩放并拆分为训练/测试集。然后通过预测器的长度进一步重塑这两个集。模型构建涉及最多类型的超参数,如n_layer(堆叠RNN层数)、type_RNN。。模型训练涉及5个超参数:solver(求解较低级优化问题的优化器),loos_fun(用于较低级优化的模型权重学习的损失函数,例如均方误差和平均绝对误差),learning_rate(求解器的学习率),batch_size(批大小,单个批训练中包含的训练样本数量),以及epochs(训练模型的epoch数)。保存训练集上最佳历元的RNN层权值,并将其用于预测验证数据集上的目标时间序列(即流量或污染物负荷),并计算适应度值。每个点评价完成后,将目标函数(即验证数据上的适应度函数值)返回给优化算法进行上层优化。
除了这些超参数之外,还有一些提高模型性能的模型训练设置。为了不同优化方法之间比较的公平性,对所有实验使用相同的模型训练设置。具体来说,在RNN的训练过程中使用了以下回调:
a)模型检查点,只保存RNN网络在验证集上损失最小的最佳epoch的权值;
b) early - stop,用于在连续5个epoch的验证损失停止改善时终止训练过程。这可以帮助防止网络过度拟合;
c) Reduce-LR-On-Plateau,用于当验证损失在两个连续的epoch中未能改善时,每次将学习率降低20%。这通常可以加速训练过程的收敛;
d)Terminate-On-NaN,用于在遇到无限大的损失值时终止训练。这允许我们在训练的早期阶段丢弃任何不可行的候选点;
结果分析
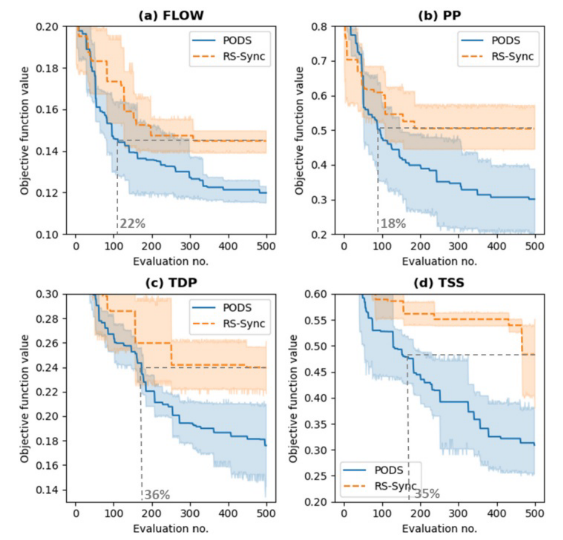
校准进度图显示了每次迭代获得的平均最佳目标函数值,以及95%的置信区间。我们的分析表明,DYCORS通过为目标函数值生成明显更好的解决方案,始终优于随机搜索。采用配对双样本t检验在显著性水平0.05下的统计分析证实,对于所有四个HPO问题,DYCORS 500次评价找到的最佳解决方案明显优于随机搜索。有趣的是,在FLOW和PP问题中,DYCORS分别只需要随机搜索预算的22%和18%,而在TDP和TSS问题中,DYCORS分别只需要随机搜索预算的36%和35%。因此,在FLOW和PP问题中,DYCORS比随机搜索快约5倍,在TDP和TSS问题中快约2.8倍。
ASONN在PODS上实现的隆升比RS-Async在RS-Sync上实现的隆升更大。与ASONN相比,DYCORS-Async实现的提升要低得多。如上所述,DYCORS异步实现的效率不仅受到计算资源使用效率的影响,还受到搜索行为的影响。结果表明,在抽样选择中使用代理评估运行时预测确实有助于减少优化过程运行时。此外,ASONN采用半异步实现,随着迭代的增加从同步调度切换到异步调度。在优化的早期,算法采用同步并行调度,随着迭代的增加,同步的限制动态减少,因此算法在优化搜索结束时变得完全异步。这种机制允许算法在没有足够的评估点的早期阶段对下一次评估进行抽样时使用更多的信息,并且在优化进展之后,有足够的评估,因此不需要等到所有待定的评估完成后再对下一次评估点进行抽样。这种机制提高了优化的信息使用,有助于实现更好的解决方案。除了FLOW HPO问题外,ASONN在所有四个HPO问题上的解总体上都优于DYCORS-Async,在所有四个问题上的解都略优于PODS。
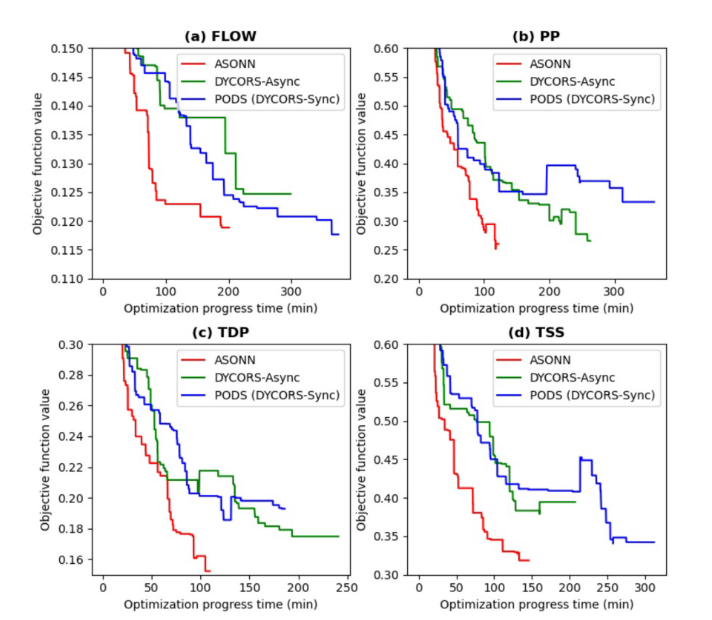
总体而言,全局代理优化是优化径流和水质污染物预测超参数的有效方法。此外,提出的异步并行代理优化方法可以显著提高优化过程的效率,这对于需要快速优化的应用可能是有益的。提出的方法具有通用性,可应用于水文学或其他领域的其他HPO问题。