参考文:Cao B, Xia Y, Ding Y, et al. Predictive Dynamic FusionJ. arXiv preprint arXiv:2406.04802, 2024.2406.04802 Predictive Dynamic Fusion
一、论文中的主要模型
论文原文用于对比的模型主要有三个,分别是:1.传统静态晚期融合模型Late Fusion;2.动态多模态融合DynMM;3.质量感知多模态融合QMF
1.传统静态晚期融合模型Late Fusion
传统静态晚期融合是一种多模态信息融合方法,通常在模型预测阶段进行融合。各模态数据独立训练模型,生成各自的预测结果(如分类概率或回归值),最终通过加权平均、投票或学习融合策略(如逻辑回归)整合结果。典型应用包括多模态分类任务(如音频+文本的情感分析)。
总的来说,就是各个模态各自预测完以后再用加和的方法直接加到一起得结果。
相对应的还有中期和早期融合。
中期融合(Intermediate Fusion)
中期融合在模型中间层进行交互,如通过交叉注意力机制或共享隐层交换模态信息。典型代表是多模态Transformer。
总的来说,就是各个模态的注意力头进行交叉,共享各个模态的特征进行训练。
早期融合(Early Fusion)
早期融合在输入或特征层面直接合并多模态数据,如拼接文本TF-IDF特征与图像CNN特征,输入单一模型处理。
总的来说,就是各个模态的向量嵌入阶段就把各个向量化的模态拼到一起,然后统一输入一个编码器进行训练。
对比
| 融合方式 | 融合阶段 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 早期融合 | 输入/特征层 | 捕获细粒度交互;端到端高效 | 需严格对齐;缺失模态适应性差 | 模态同步且高相关 |
| 中期融合 | 模型中间层 | 动态交互;灵活调整模态权重 | 计算复杂;需大量数据 | 需部分模态互补信息 |
| 晚期融合 | 预测层 | 模块化;容错性强;支持异构模型 | 忽略早期交互;性能依赖融合策略 | 模态异步或独立性高 |
2.动态多模态融合DynMM
参考:论文阅读2-《Dynamic Multimodal Fusion》 - 技术栈
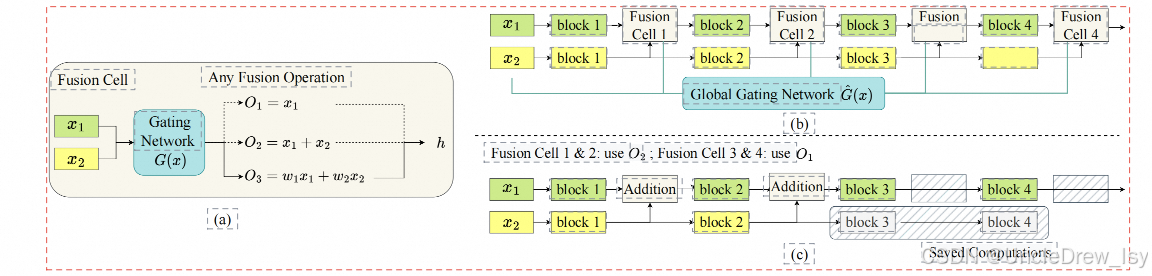
动态多模态融合(Dynamic Multimodal Fusion, DynMM)是一种针对多模态数据的自适应融合方法,旨在根据输入数据的动态特性(如模态质量、相关性或任务需求)调整融合策略,以提升模型性能。传统多模态融合通常采用静态权重或固定架构,而DynMM通过引入动态机制(如注意力、门控或路由)实现更灵活的模态交互。
总的来说,分两方面进行调优:
1、训练多个专家网络,不同网络纳入不同的模态组合,然后用一个门函数来根据当前各个模态的特征参数(比如图像清晰度,文本连贯性等等)选择专家网络。
2、把选中的专家网络的计算消耗纳入损失函数,来进行训练。
3.质量感知多模态融合QMF
参考:ICML 2023 | 可证明的动态多模态融合框架:一个简单而有用的理论_方法_问题_分类器
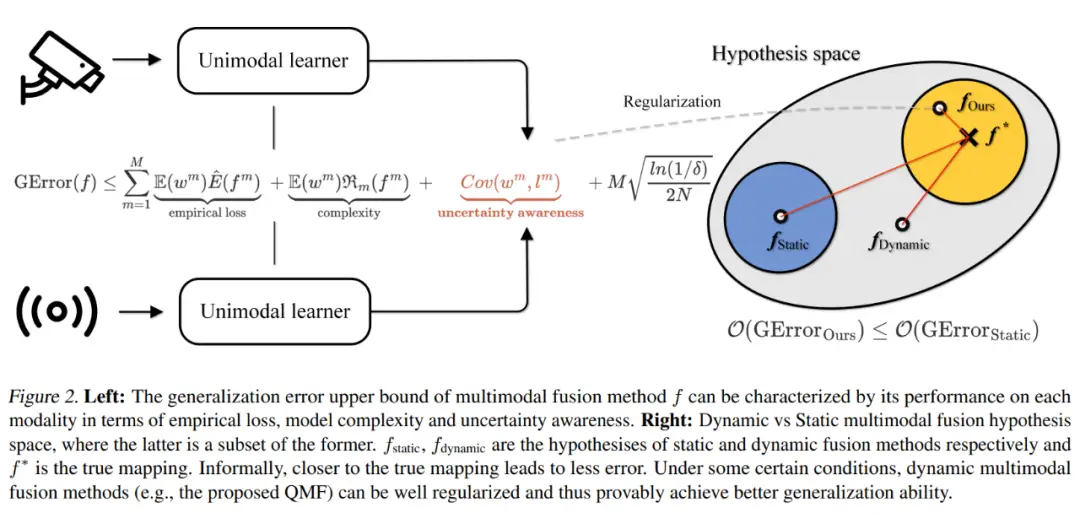
一种针对多模态数据(如文本、图像、音频等)融合的框架,特别关注处理模态间质量不平衡或低质量输入的情况。其核心思想是通过动态评估各模态的质量权重,自适应调整融合策略,提升模型在真实场景中的鲁棒性。
总的来说,分两方面进行调优:
1、不训练那么多专家网络了,只需要训练一个质量评估网络评估各个模态的质量。
2、以质量为标准,使用门函数或者注意力机制或者神经网络什么的来生成合成权重。
二、论文代码中的可调用的基础模型
论文代码用于测试或者底层调用的模型主要有三个,分别是:1.词袋模型bow;2.文本encoder-bert;3.图像encoder-resnet;4.mmbt;以及他们的各种混合。
1.词袋模型bow
词袋模型(Bag of Words, BOW)是一种用于自然语言处理的文本表示方法,将文本视为无序的词汇集合,忽略语法和词序,仅关注词频或是否存在。
词汇表构建:从所有文档中提取唯一词汇构成词汇表。
向量化表示:每篇文档表示为固定长度的向量,维度与词汇表一致,值可以是词频(Count)或二进制(0/1表示是否存在)。
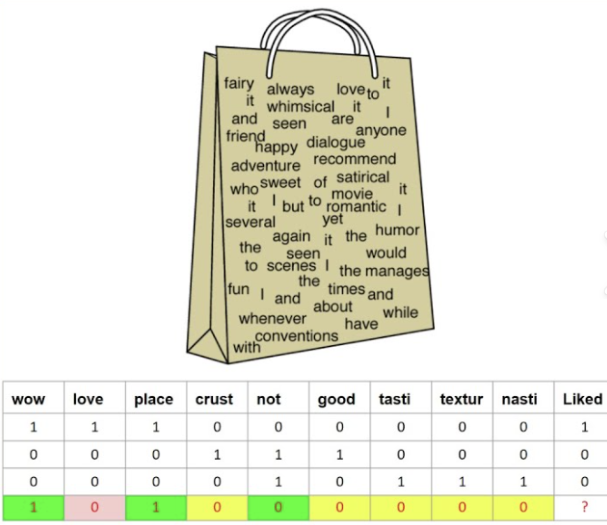
其实就是:先把词按目标(比如情感)分类,然后统计词频,哪一种情感的频率高就输出哪一种情感。
2.文本encoder-bert
bert的初步功能其实可以理解成transformer的词嵌入那一层的作用;但是比传统的词嵌入更加精确,会剔除词汇不属于句子表达中的含义。在该任务里可以看作是把词汇真实意思嵌入后,再放到分类层或者说分类模型里做分类。
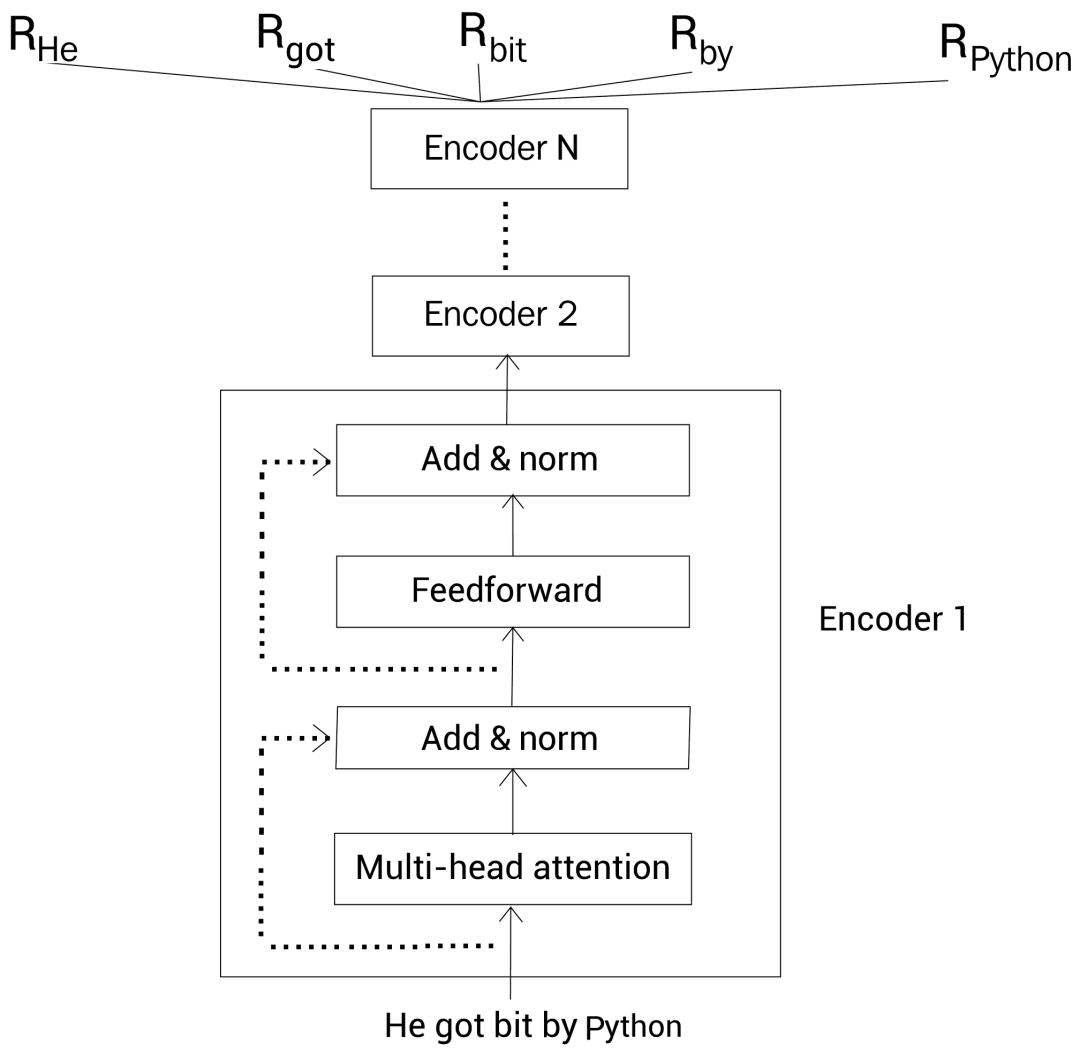
参考:一文读懂 BERT 模型:从原理到实际应用,看这一篇就够了!-CSDN博客
与传统单向语言模型(如 GPT)不同,BERT 通过掩码语言模型(MLM)和下一句预测(NSP)两项预训练任务,实现了对文本的双向上下文建模。MLM 随机掩盖输入文本中的部分词汇,迫使模型根据上下文预测被掩盖的词,类似于 "完形填空";NSP 则判断两个句子是否为连续文本,强化模型对语义连贯性的理解。这种双向编码能力使 BERT 能够更精准地捕捉词汇的语义关联。
3.图像encoder-resnet

图像输入encoder的流程:1.把图像划分成小块->2.把各个小块输入到resNet->3.取某一隐藏层作为token的嵌入向量输入transformer结构->4.再全连接划分情感
1、图像分块处理
将输入图像划分为固定大小的非重叠小块(如16x16像素),每个小块视为一个局部区域。分块后通过线性投影或卷积操作将像素值转换为向量形式,形成初始的token序列。
2、ResNet特征提取
分块后的图像区域(或整张图像)输入ResNet backbone。ResNet通过残差结构逐层提取多层次特征,通常选择中间某层的输出(如Stage-3或Stage-4的卷积层输出)作为局部特征的编码表示。对于全局特征,可能使用最终的平均池化层输出。
3、隐藏层特征选择
从ResNet的指定隐藏层提取特征图,将其展平为空间token序列。例如,若选择Layer3的输出(尺寸为H×W×C),可将其重塑为N×C的矩阵(N=H×W),每个C维向量对应一个空间位置的token嵌入。
4、情感分类结构
token序列可直接输入Transformer进行全局关系建模,或与全局平均池化特征拼接。最终通过全连接层映射到情感类别空间,配合Softmax输出概率分布。部分实现会先用Transformer聚合token信息,再通过MLP头分类。
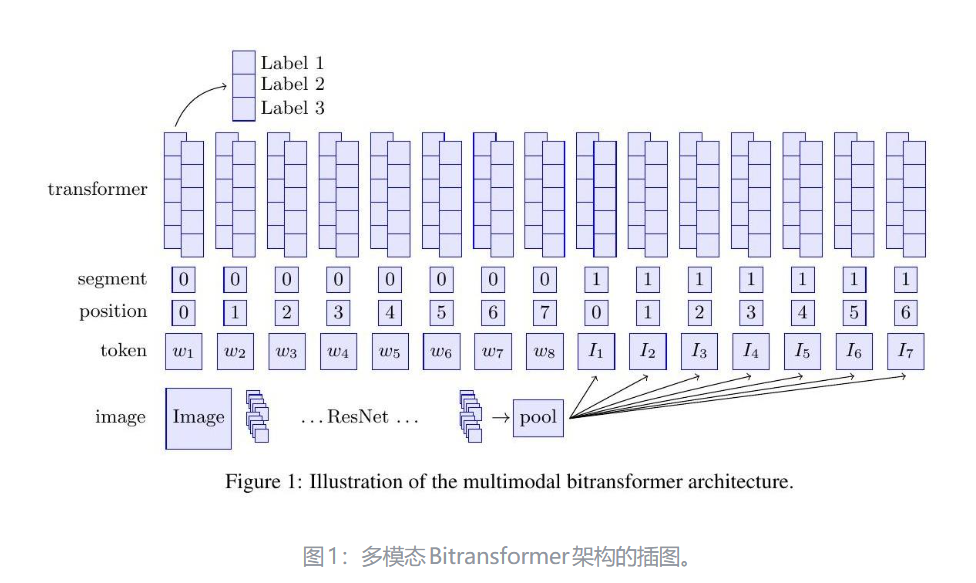
4.用于图像和文本分类的有监督多模态双向Transformer-mmbt
参考:MMBT: 用于图像和文本分类的有监督多模态双向Transformer - 知乎
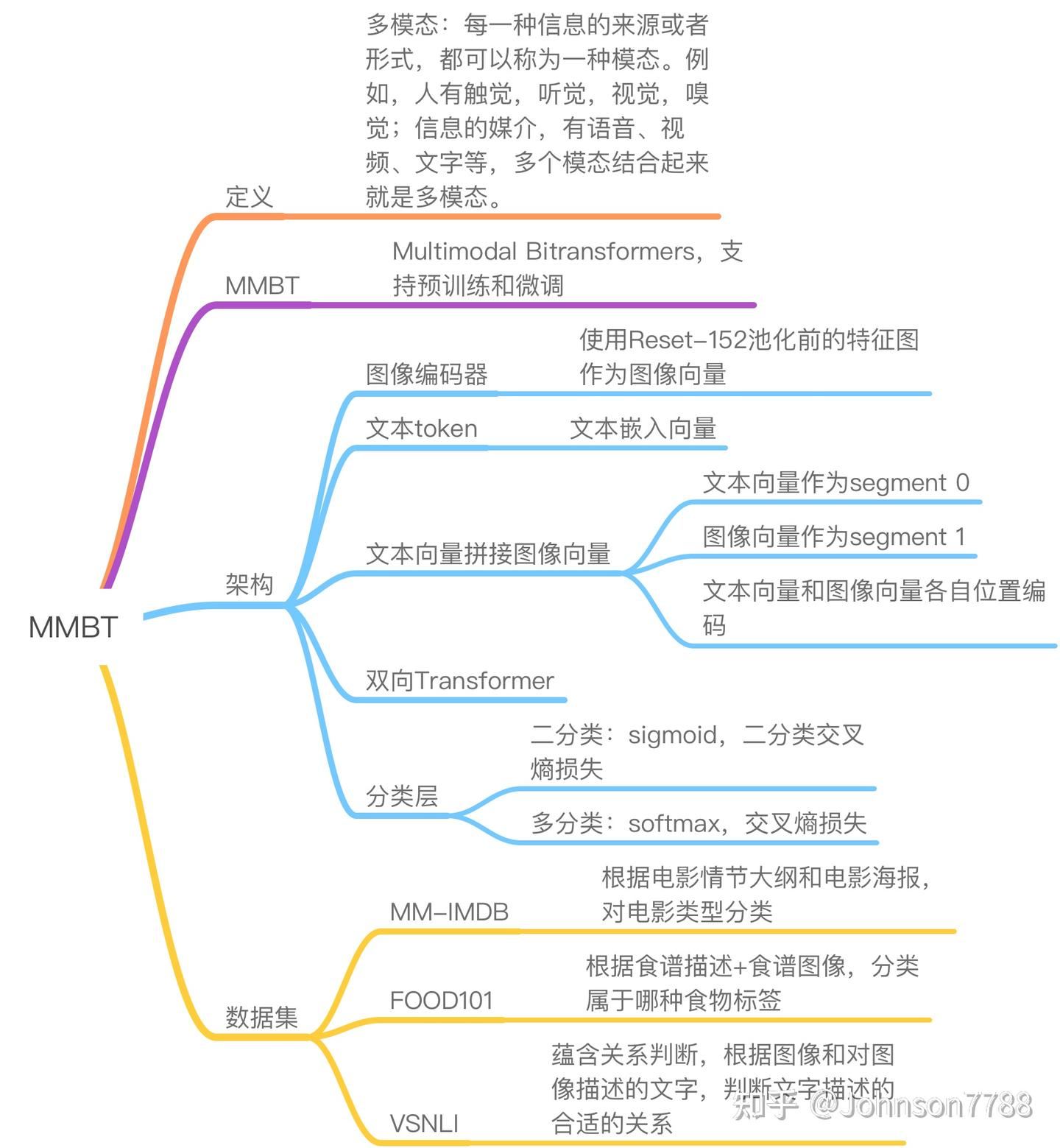
MMBT是一种结合图像和文本数据进行分类的有监督多模态模型,基于Transformer架构实现跨模态信息交互。其核心思想是通过双向注意力机制融合视觉和文本特征,提升分类任务的性能。
用我的理解来说就是:一种固定了各个模态结构的综合架构 。模态融合大概可以分为早期模态融合:**Early Fusion。**因为各个模态在输入注意力头之前就拼接过了,拼接方式大概如下: