
| 🔭 个人主页: 散峰而望 |
|---|
《C语言:从基础到进阶》《编程工具的下载和使用》《C语言刷题》《算法竞赛从入门到获奖》《人工智能》《AI Agent》
愿为出海月,不做归山云
🎬博主简介



【算法竞赛】树
- 前言
- [1. 树的相关概念](#1. 树的相关概念)
-
- [1.1 树的定义](#1.1 树的定义)
- [1.2 树的基本术语](#1.2 树的基本术语)
- [1.3 有序树和无序树](#1.3 有序树和无序树)
- [1.4 有根树和无根树](#1.4 有根树和无根树)
- [2. 树的存储](#2. 树的存储)
-
- [2.1 孩子表示法](#2.1 孩子表示法)
- [2.2 实现方式一:vector 数组实现](#2.2 实现方式一:vector 数组实现)
- [2.3 实现方式二:链式前向星](#2.3 实现方式二:链式前向星)
- [2.4 总结](#2.4 总结)
- [3. 树的遍历](#3. 树的遍历)
-
- [3.1 深度优先遍历 - DFS](#3.1 深度优先遍历 - DFS)
-
- [3.1.1 vector 数组存储](#3.1.1 vector 数组存储)
- [3.1.2 链式前向星存储](#3.1.2 链式前向星存储)
- [3.2 宽度优先遍历 - BFS](#3.2 宽度优先遍历 - BFS)
-
- [3.2.1 vector 数组存储](#3.2.1 vector 数组存储)
- [3.2.2 链式前向星存储](#3.2.2 链式前向星存储)
- 结语
前言
树是数据结构中一种重要的非线性结构,广泛应用于计算机科学的各个领域。从文件系统的目录结构到数据库的索引设计,从网络路由算法到人工智能的决策模型,树的概念无处不在。理解树的基本概念、存储方式以及遍历方法,对于掌握更复杂的数据结构和算法至关重要。
本文将系统介绍树的相关概念,包括树的定义、基本术语以及有序树与无序树的区别。同时,详细探讨树的两种主要存储方式------孩子表示法和链式前向星,并分析它们的实现细节和适用场景。最后,深入讲解树的深度优先遍历(DFS)和宽度优先遍历(BFS)算法,分别针对不同的存储结构提供实现方法。
通过本文的学习,读者将能够全面理解树的基本原理,掌握其存储和遍历的核心技术,为进一步学习二叉树、平衡树等高级数据结构奠定坚实基础。
1. 树的相关概念
1.1 树的定义
树型结构是一类重要的非线性数据结构,是 n(n >= 0) 个节点的有限集,n = 0 时为空树。
- 树是由根节点 和子树组成的。
- 有一个特殊的节点,称为根节点,根节点没有前驱节点。
- 除根节点外,其余节点被分成 N 个互不相交的集合 T1、T2 ... Tm ,其中每一个集合 T 又是一棵树,称这棵树为根节点的子树。
因此,树是递归定义的。
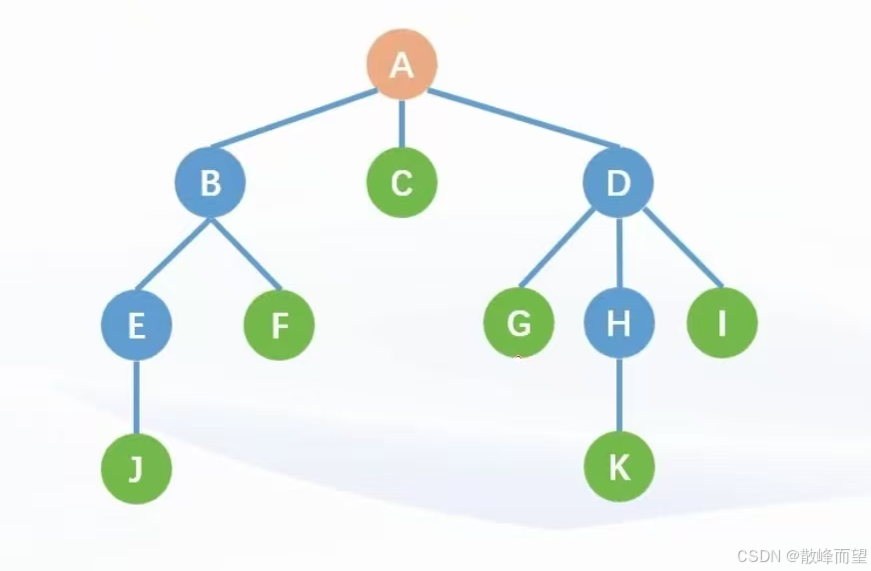
1.2 树的基本术语
- 节点的度: 树中一个节点孩子的个数称为该结点的度。
- 树的度: 树中结点最大的度数称为树的度。
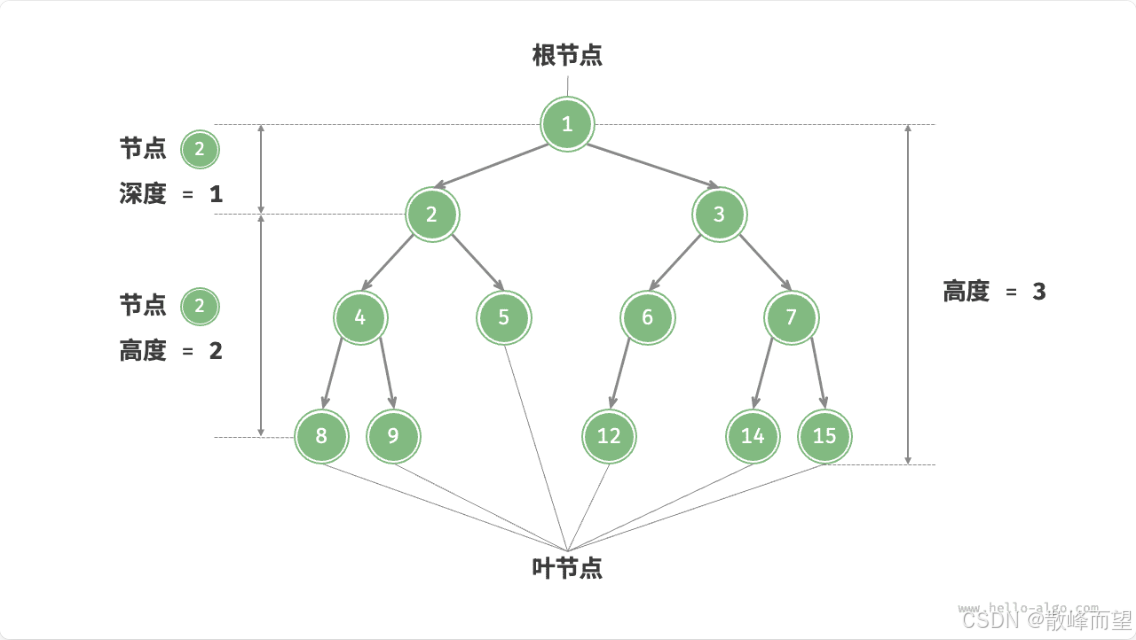
- 树的高度(深度): 树中结点的最大层数称为树的高度(深度)。
- 路径: 树中两个结点之间的路径是由这两个结点之间所经过的结点序列构成的,路径长度为序列中边的个数。
- 根节点: 位于树顶层的节点,没有父节点。
- 叶节点: 没有子节点的节点 。
- 边: 连接两个节点的线段,即节点引用(指针)。
- 节点所在的层: 从顶至底递增,根节点所在层为 1 。
- 节点的深度: 从根节点到该节点所经过的边的数量。
- 节点的高度: 从距离该节点最远的叶节点到该节点所经过的边的数量。
- 父节点: 直接前驱。
- 孩子节点: 直接后驱。
1.3 有序树和无序树
- 有序树:结点的子树按照从左往右的顺序排列,不能更改。
- 无序树:结点的子树之间没有顺序,随意更改。
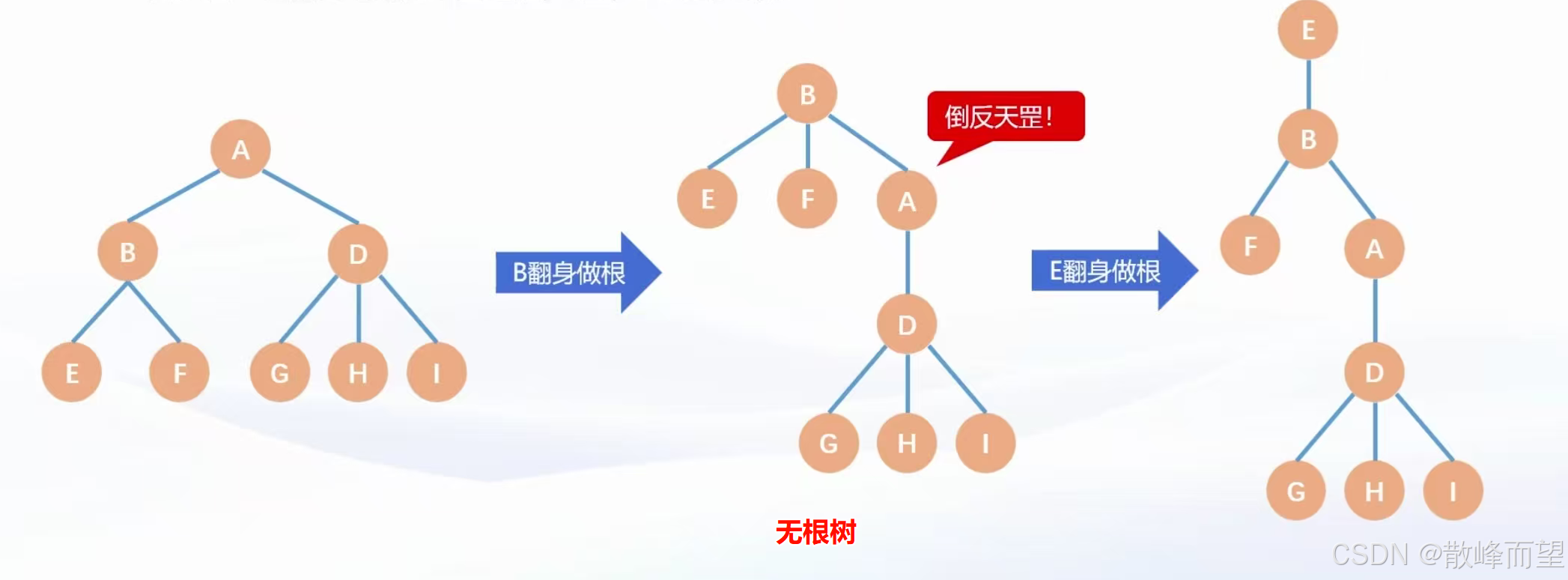
1.4 有根树和无根树
- 有根树:树的根节点已知,是固定的。
- 无根树:树的根节点未知,谁都可以是根结点。
这个主要会影响我们对于树的存储。在存储树结构的时候,我们最重要的就是要存下逻辑关系。
无根树会导致父子关系不明确,在存储的时候要注意,算法竞赛中遇到的树基本上是无根树。即使是有根树,也会当作无根树处理。
2. 树的存储
树结构相对线性结构来说就比较复杂。存储时,既要保存值域,也要保存结点与结点之间的关系。实际中树有很多种存储方式:双亲表示法,孩子表示法、孩子双亲表示法以及孩子兄弟表示法等。
现阶段,我们只用掌握孩子表示法 ,学会用孩子表示法存储树,并且在此基础上遍历整棵树。后续会在并查集中学习双亲表示法。至于其它存储形式,算法竞赛阶段不要求掌握。
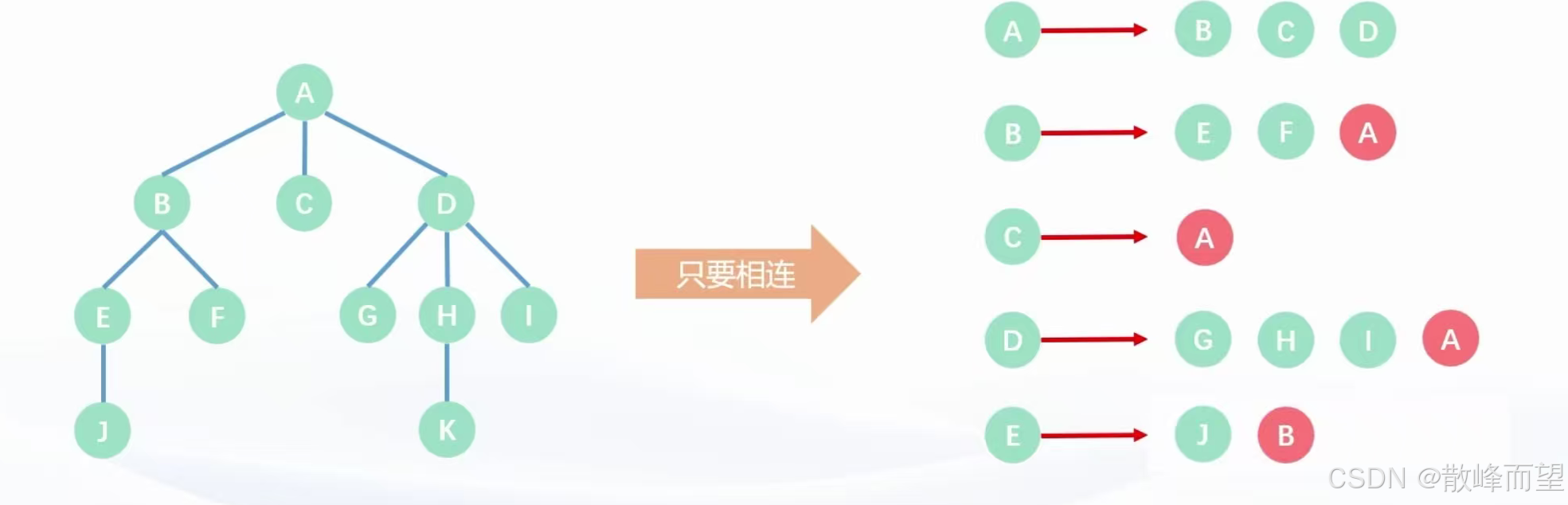
2.1 孩子表示法
孩子表示法是将每个结点的孩子信息存储下来,只关心孩子。
如果是在无根树中,父子关系不明确,我们会将与该结点相连的所有的点都存储下来。
2.2 实现方式一:vector 数组实现
案例:
题目描述:
给定一棵树,该树一共有 n 个结点,编号分别是 1 ~ n 。
输入描述:
第一行一个整数 n ,表示 n 个结点。
接下来 n - 1 行,每行两个整数 u, v ,表示 u 和 v 之间有一条边。
输入格式:
9
3 1
1 2
4 1
2 5
6 2
7 4
4 8
4 9
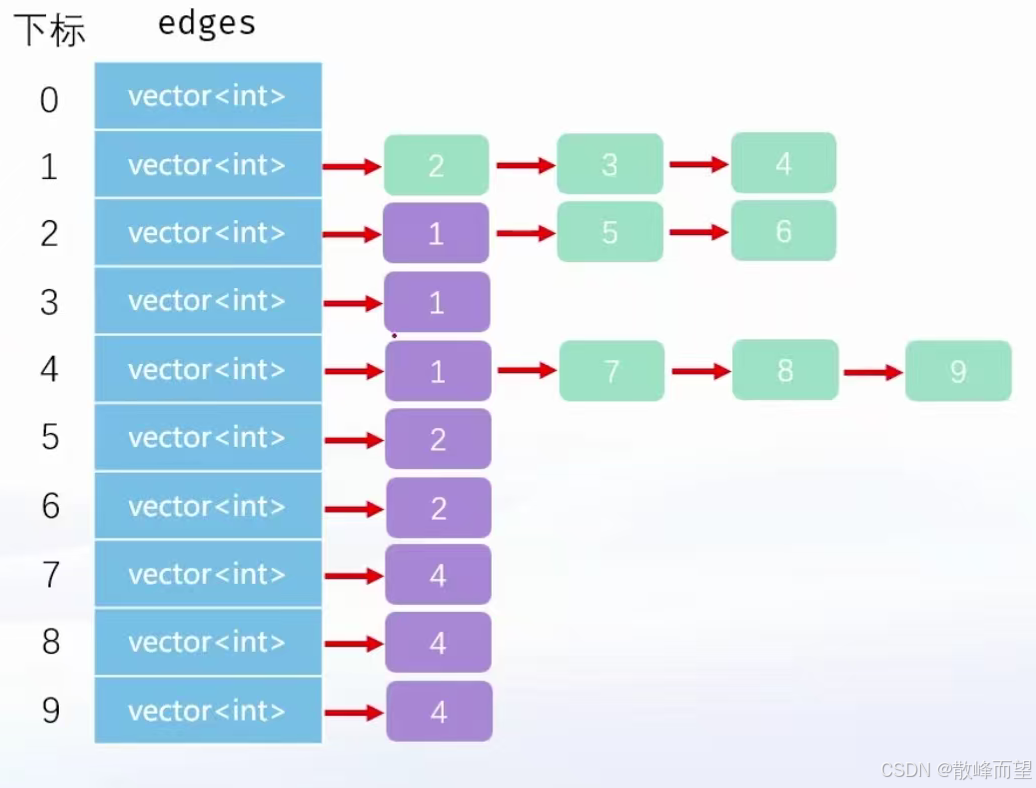
vector 是可变长数组,如果只涉及尾插,效率还是可以的。而树结构这种一对多的关系,正好可以利用尾插,把所有的关系全部存起来。
- 因此可以创建一个大小为 n ~ 1 的 vector 数组
edges[n + 1] - edgesi 里面存着 i 号节点所连接的节点
- 对于 i 的孩子,直接
edges[i].push_back即可
cpp
#include <iostream>
#include <vector>
using namespace std;
const int N = 1e5 + 10;
int n;
vector<int> edges[N];
int main()
{
cin >> n;
for(int i = 1; i < n; i++)
{
int a, b; cin >> a >> b;
//a和b之间有一条边
edges[a].push_back(b);
edges[b].push_back(a);
}
return 0;
} 2.3 实现方式二:链式前向星
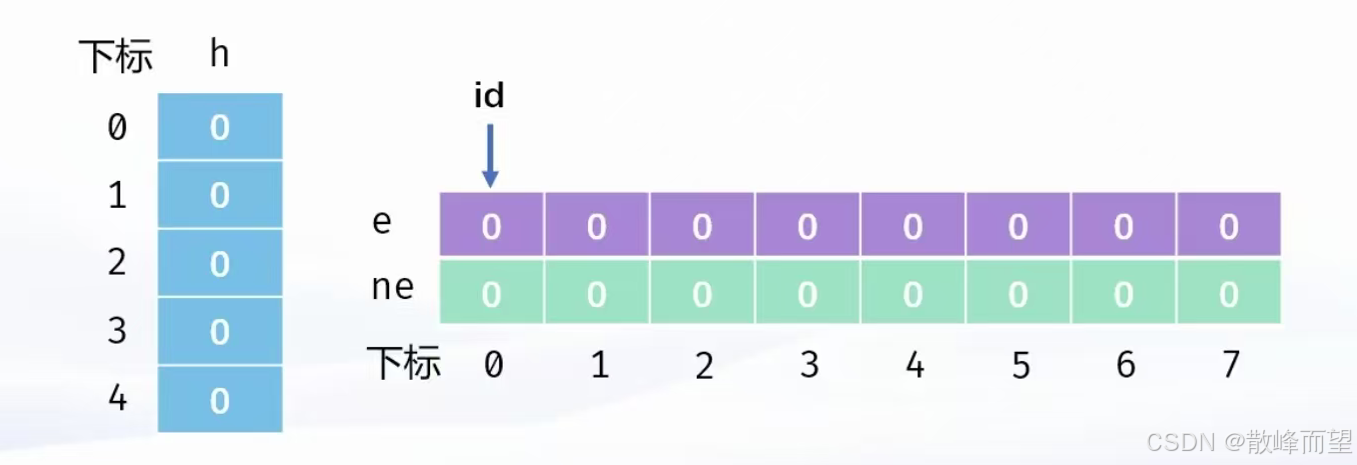
链式前向星的本质就是用数组来模拟链表。因此,一定要先把【算法竞赛】链表和 list文章中用数组模拟实现链表这个操作搞懂。
- 创建一个足够大的数组 h ,作为所有节点的哨兵位
- 创建两个足够大的数组 e 和 ne ,一个作为数据域一个作为指针域
- 一个变量指针,标记新来节点的存储位置
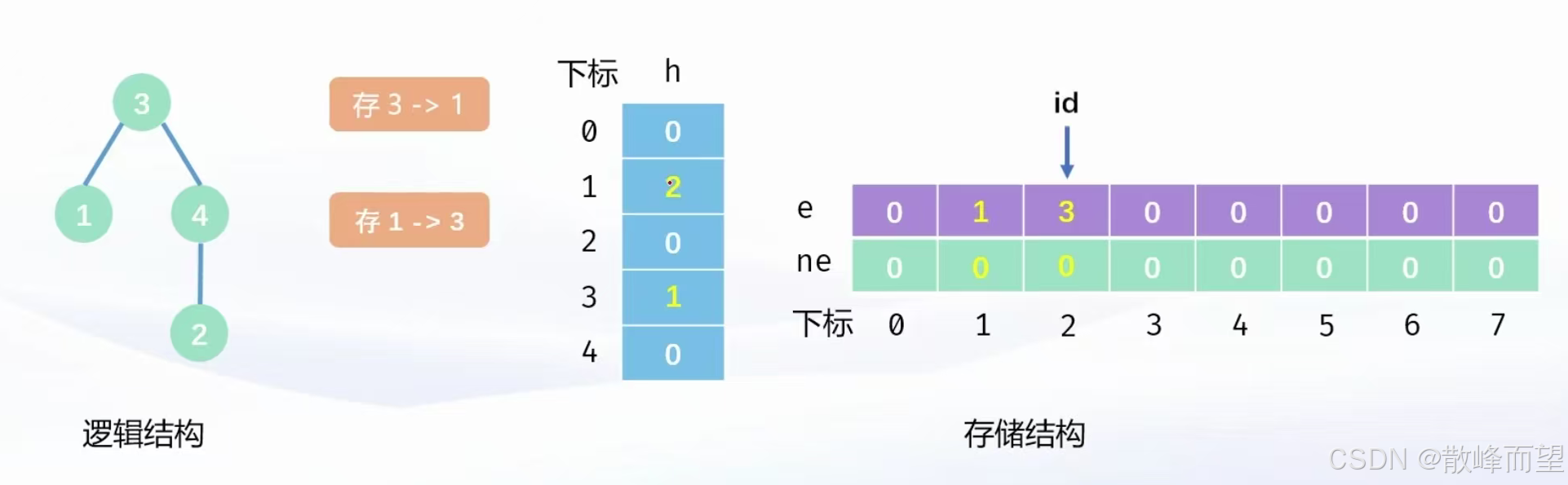
当 x 有一个孩子 y 的时候,就把 y 头插到 x 的链表中
id++; e[id] = y; ne[id] = h[x]; h[x] = id
相关的操作就类似下面这张图这种,然后以此类推:
cpp
#include <iostream>
using namespace std;
const int N = 1e5 + 10;
int h[N], e[N * 2], ne[N * 2], id;
int n;
void add(int x, int y)
{
id++;
e[id] = y;
ne[id] = h[x];
h[x] = id;
}
int main()
{
cin >> n;
for(int i = 1; i < n; i++)
{
int a, b; cin >> a >> b;
//a和b之间有一条边
add(a, b);
add(b, a);
}
return 0;
}2.4 总结
关于 vector 数组以及链式前向星:
- 前者由于用到了容器 vector ,实际运行起来相比较于后者更耗时,因为 vector 是动态实现的。
- 但是在如今的算法竞赛中,一般不会无聊到卡这种常数时间。也就是vector虽然慢,但不会因此而超时。
那么,在做题的时候,选择一种自己喜欢的方式即可。
3. 树的遍历
树的遍历就是将树中所有的点都扫描一遍。
在之前学过的线性结构中,遍历就很容易,直接从前往后扫描一遍即可。但是在树形结构中,如果不按照一定的规则遍历,就会漏掉或者重复遍历一些结点。因此,在树形结构中,要按照一定规则去遍历。常用的遍历方式有两种,一种是深度优先遍历 ,另一种是宽度优先遍历。
3.1 深度优先遍历 - DFS
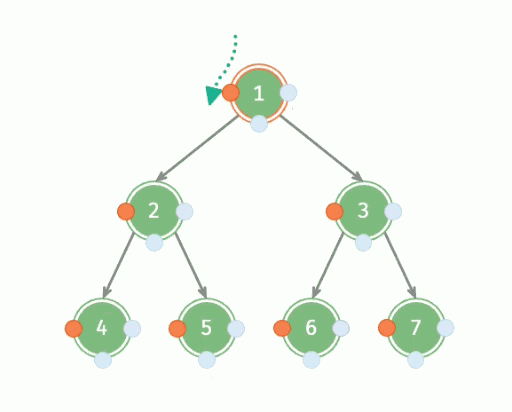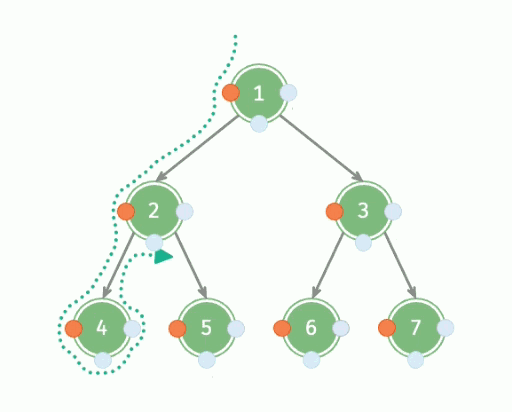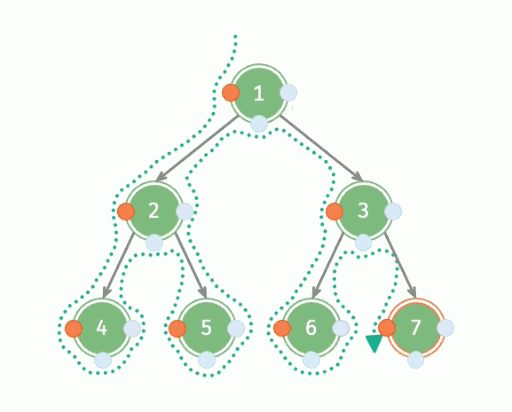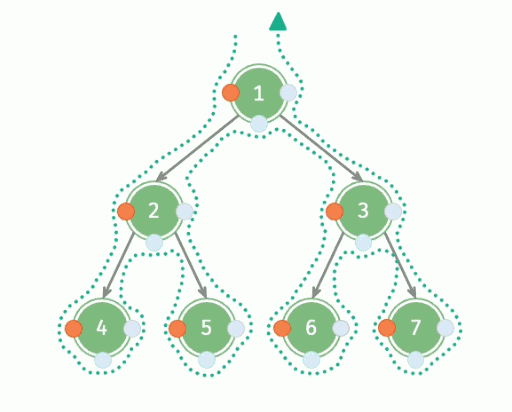
深度优先遍历,英文缩写为 DFS,全称 Depth First Search ,中文名是深度优先搜索,是一种用于遍历或搜索树或图的算法。所谓深度优先,就是说每次都尝试向更深的节点走,也就是一条路走到黑。
具体流程:
- 从根节点出发,依次遍历每一棵子树;
- 遍历子树的时候,重复第一步。
因此,深度优先遍历是一种递归形式的遍历,可以用递归来实现。
案例:
题目描述:
给定一棵树,该树一共有 n 个结点,编号分别是 1 ~ n 。
输入描述:
第一行一个整数 n ,表示 n 个结点。
接下来 n - 1 行,每行两个整数 u, v ,表示 u 和 v 之间有一条边。
输入格式:
11
1 3
7 3
3 10
1 5
4 5
2 1
11 2
6 11
11 8
11 9
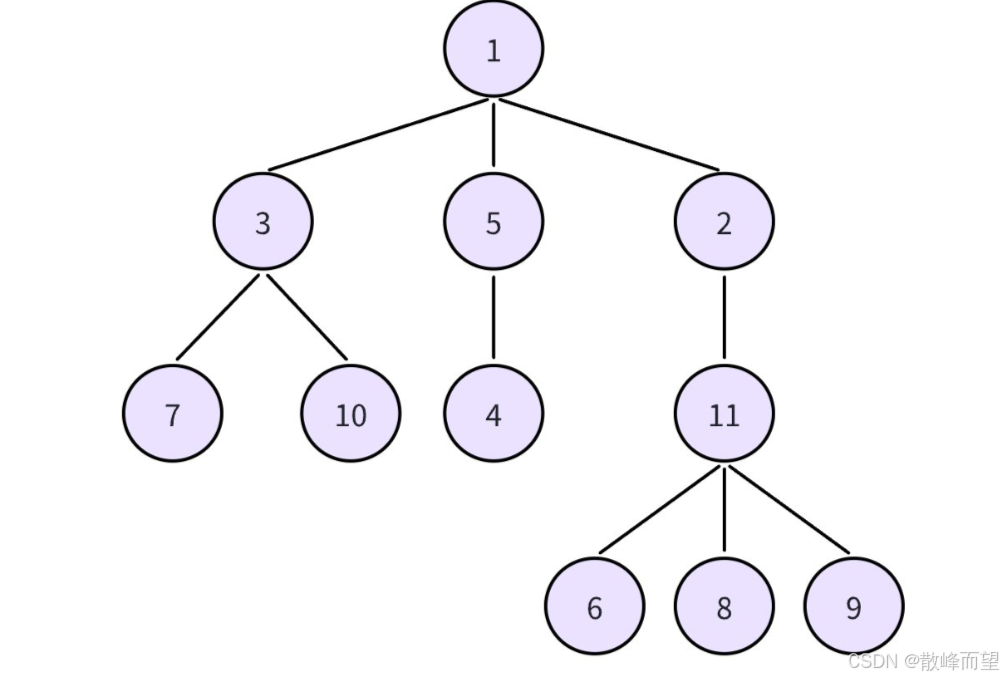
3.1.1 vector 数组存储
存储树结构的时候,会把相邻的所有结点都存下来,这样在扫描子树的时候会直接扫描到上一层,这不是我们想要的结果。
因此,需要一个 st 数组来标记,哪些结点已经访问过,接下来 dfs 的时候,就不去遍历那些点。
cpp
#include <iostream>
#include <vector>
using namespace std;
const int N = 1e5 + 10;
int n;
vector<int> edges[N]; //edges[i]保存着i号节点相连的所有点
bool st[N];//标记已经遍历过的节点
//遍历到u这个树
void dfs(int u)
{
cout << u << " ";
st[u] = true;//标记已经访问过
//访问子树
for(auto v : edges[u])
{
if(!st[v]) dfs(v);
}
}
int main()
{
//建图
cin >> n;
for(int i = 1; i < n; i++)
{
int a, b; cin >> a >> b;
edges[a].push_back(b);
edges[b].push_back(a);
}
//深度优先遍历
dfs(1);
return 0;
}运行结果:
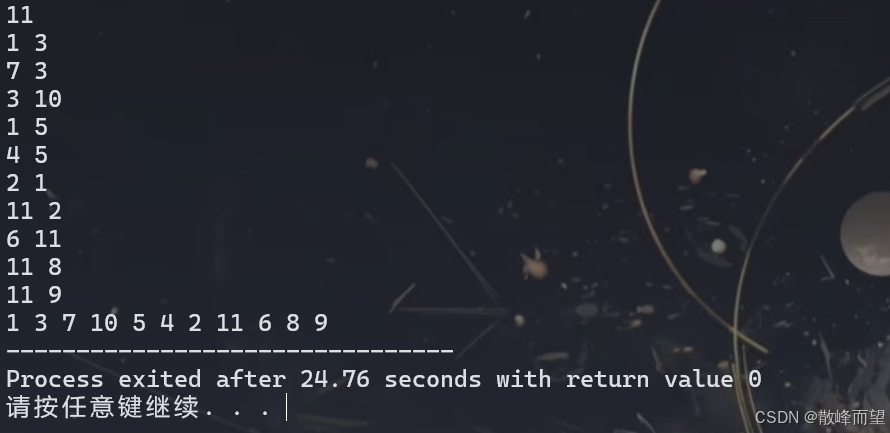
3.1.2 链式前向星存储
cpp
#include <iostream>
using namespace std;
const int N = 1e5 + 10;
int h[N], e[N * 2], ne[N * 2], id;
int n;
bool st[N];
void add(int x, int y)
{
id++;
e[id] = y;
ne[id] = h[x];
h[x] = id;
}
void dfs(int u)
{
cout << u << " ";
st[u] = true;
for(int i = h[u]; i; i = ne[i])
{
int v = e[i];
if(!st[v]) dfs(v);
}
}
int main()
{
cin >> n;
for(int i = 1; i < n; i++)
{
int a, b; cin >> a >> b;
add(a, b);
add(b, a);
}
dfs(1);
return 0;
} 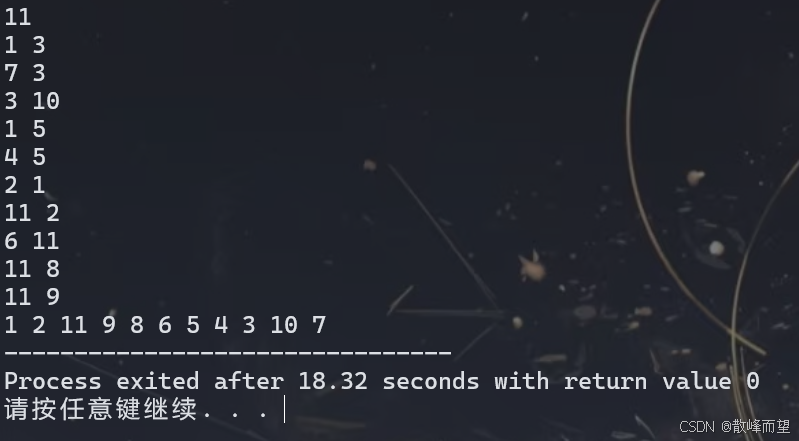
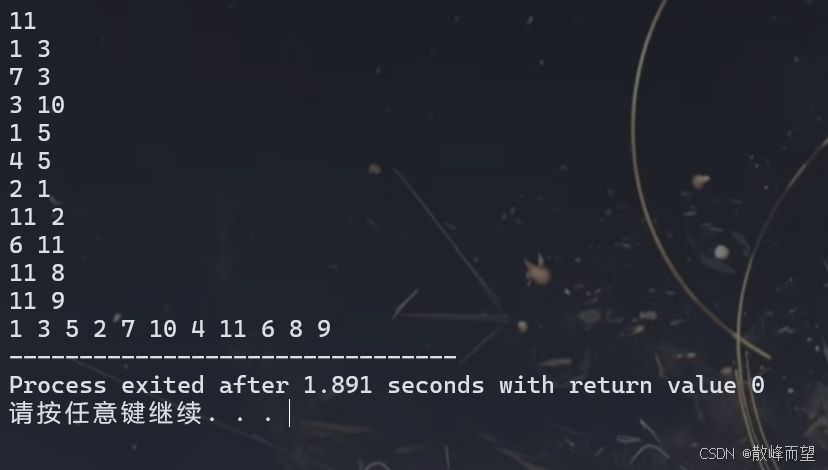
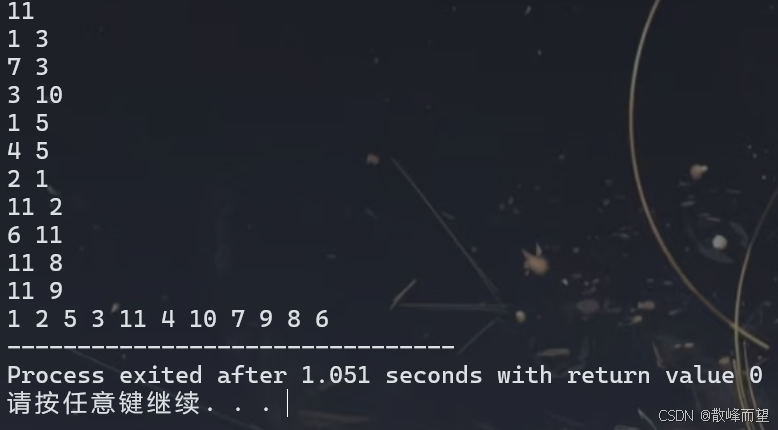
vector 数组存储和链式前向星存储之所以打印结果不一样,是因为 vector 数组存储时尾插操作,而链式前向星存储是头插操作。
时间复杂度:
简单估计一下,在 dfs 的整个过程中,会把树中所有的边扫描量两遍。边的数量为 n - 1,因此时间复杂度为 O(N)
空间复杂度:
最差情况下,结点个数为 n 的树,高度也是 n ,也就是变成一个链表。此时递归的深度也是 n ,此时的空间复杂度为 O(N)
3.2 宽度优先遍历 - BFS
宽度优先遍历,英文缩写为 BFS,全称是 Breadth First Search ,也叫广度优先遍历。也是一种用于遍历或搜索树或图的算法。所谓宽度优先。就是每次都尝试访问同一层的节点。如果同一层都访问了,再访问下一层。
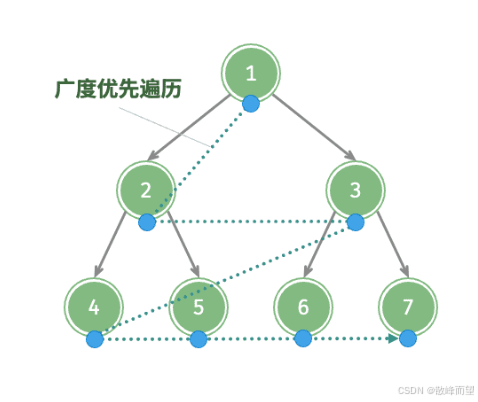
实现方式:借助队列
- 初始化一个队列;
- 根节点入队,同时标记该节点已经入队;
- 当队列不为空时,拿出队头元素,访问,然后将队头元素的所有孩子入队,同时打上标记;
- 重复 3. 过程,直到队列为空。
案例:
题目描述:
给定一棵树,该树一共有 n 个结点,编号分别是 1 ~ n 。
输入描述:
第一行一个整数 n ,表示 n 个结点。
接下来 n - 1 行,每行两个整数 u, v ,表示 u 和 v 之间有一条边。
输入格式:
11
1 3
7 3
3 10
1 5
4 5
2 1
11 2
6 11
11 8
11 9
3.2.1 vector 数组存储
cpp
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
const int N = 1e5 + 10;
int n;
vector<int> edges[N];
bool st[N];
void bfs()
{
queue<int> q;
q.push(1);
st[1] = true;
while(q.size())
{
//队列不为空时,拿出对头元素
auto u = q.front(); q.pop();
cout << u << " ";
//让孩子入队
for(auto v : edges[u])
{
if(!st[v])
{
q.push(v);
st[v] = true;
}
}
}
}
int main()
{
cin >> n;
for(int i = 1; i < n; i++)
{
int a, b; cin >> a >> b;
edges[a].push_back(b);
edges[b].push_back(a);
}
bfs();
return 0;
} 运行结果:
3.2.2 链式前向星存储
cpp
#include <iostream>
#include <queue>
using namespace std;
const int N = 1e5 + 10;
int n;
int h[N], e[N * 2], ne[N * 2], id;
bool st[N];
void add(int a, int b)
{
id++;
e[id] = b;
ne[id] = h[a];
h[a] = id;
}
void bfs()
{
queue<int> q;
q.push(1);
st[1] = true;
while(q.size())
{
auto u = q.front(); q.pop();
cout << u << " ";
for(int i = h[u]; i; i = ne[i])
{
int v = e[i];
if(!st[v])
{
q.push(v);
st[v] = true;
}
}
}
}
int main()
{
cin >> n;
for(int i = 1; i < n; i++)
{
int a, b; cin >> a >> b;
add(a, b);
add(b, a);
}
bfs();
return 0;
} 运行结果:
时间复杂度:
所有结点只会入队一次,然后出队一次,因此时间复杂度为 O(N)
空间复杂度:
最坏情况下,所有的非根结点都在同一层,此时队列里面最多有 n - 1个元素,空间复杂度为 O(N)
结语
树作为一种基础且强大的非线性数据结构,在计算机科学中扮演着核心角色。从文件系统到数据库索引,从网络路由到人工智能决策模型,树的应用几乎无处不在。
理解树的存储与遍历是掌握更复杂结构(如二叉树、堆、图)的前提。通过孩子表示法或链式前向星等存储方式,可以高效地操作树结构;而 DFS 和 BFS 两种遍历策略,则为解决路径搜索、层次分析等问题提供了通用框架。
实际应用中,需根据场景选择存储与遍历方法。例如,链式前向星适合稀疏树,而DFS 更适合回溯类问题。掌握这些基础技术,将为后续学习更高级的算法(如动态规划、贪心算法)奠定坚实基础。
愿诸君能一起共渡重重浪,终见缛彩遥分地,繁光远缀天。
