图例
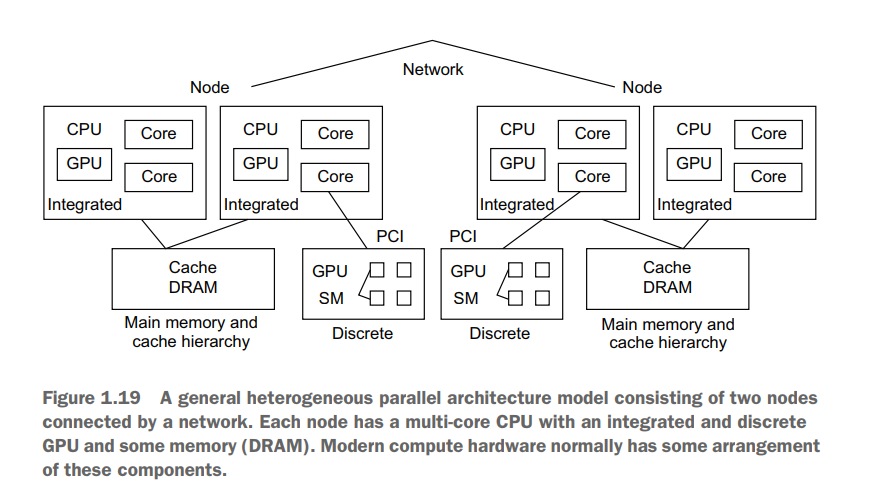
这是一个非常典型现代异构高性能计算(HPC)集群节点架构。它结合了多种计算单元和复杂的内存层次,旨在最大化计算能力和能效
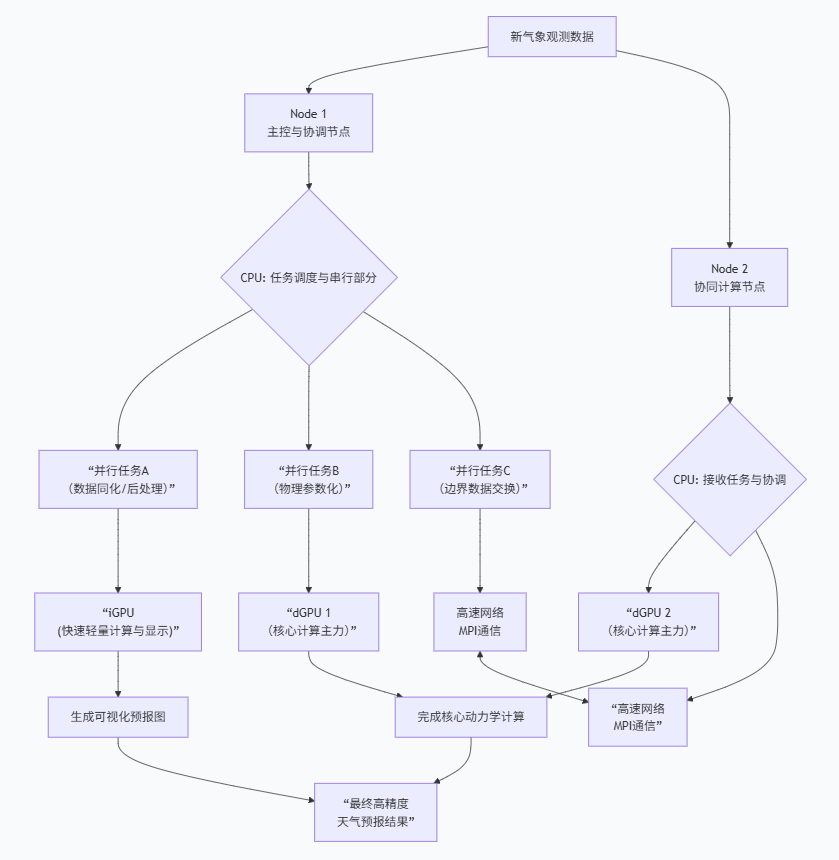
示例:实时天气预测系统
假设我们正在为一个大城市(如北京) 构建一个高精度的,未来6小时的天气预测系统
这个系统需要处理海量的气象数据(卫星云图、雷达数据、地面观测站数据等),并运行复杂的流体动力学模型
我们有两个如图所示的计算节点,它们通过高速网络(如 InfiniBand) 连接,共同组成一个小型集群
任务分解:
一个完整的天气模拟周期包括:
- 数据同化: 将实时观测数据与背景场融合
- 核心动力学计算: 求描述大气运动的偏微分方程(计算最密集的部分)
- 物理参数化: 计算云、降水、辐射等物理过程
- 后处理与可视化: 生成降雨图、风速图
架构组件如何协同工作
1. 节点级别(网络连接)
作用:两个节点共同承担整个北京的模拟任务。为了加速计算,我们将北京的模拟区域(三维网格)在水平方向上一分为二(例如,以中轴线为界,东区和西区)。
协作:Node 1 计算西区,Node 2 计算东区。每个时间步计算完成后,它们必须通过高速网络交换边界处的气象数据(如压力、温度、风速),因为东区的计算需要西区边界的最新数据,反之亦然。这种通信使用 MPI(消息传递接口) 库完成。
挑战:网络带宽和延迟是瓶颈。如果通信太慢,一个节点会空闲等待另一个节点的边界数据,造成资源浪费。
2. 节点内部:CPU与核心
作用:CPU是任务的"大脑"和"调度员"。
主控核心:其中一个CPU核心运行主进程,负责:
- 从存储服务器读取初始气象数据。
- 启动和管理MPI通信,与Node 2交换数据
- 将最核心、计算量最大的动力学计算部分(任务B)调度到独立GPU(dGPU)上执行。
- 将一些轻量级的物理参数化计算(任务A)分配给其他CPU核心并行执行。
其他核心:多个CPU核心通过多线程(如OpenMP)并行处理任务A,比如同时计算不同高度层的辐射传输过程。
3. 节点内部:集成GPU vs 独立GPU
这是异构计算的关键。
独立GPU:
- 角色 :计算主力。它的SM(流多处理器)包含成百上千个核心,专为大规模并行计算设计。
- 任务 :执行
核心动力学计算。这个任务非常适合GPU:需要对数百万个网格点执行相同的数学运算(数据并行)。CPU会将这个任务(内核函数)和数据"卸载"到dGPU。 - 代价:数据必须通过PCIe总线从主内存复制到GPU显存,有传输开销。
集成GPU:
- 角色 :协处理器和显示引擎。它与CPU共享主内存,访问延迟低,但计算核心较少,性能较弱。
- 任务 :
- 处理后处理与可视化:在动力学计算间隙,快速生成预览图,供气象学家实时监控。
- 处理一些对延迟敏感、但计算量不大的任务
- 优势:无需通过PCIe复制数据,适合处理CPU正在操作的数据。
4. 节点内部:内存与缓存层次
DRAM(主内存):存放整个模拟区域的所有数据,包括当前时刻和下一时刻的温度、气压、湿度等全场数据。它是CPU和iGPU的"工作台"。
GPU显存:存放dGPU负责计算的那部分网格数据。是dGPU的"工作台"。
缓存:
- CPU缓存:CPU核心频繁访问的数据(如某个循环变量)会放在L1/L2/L3缓存中,比访问DRAM快百倍。
- GPU缓存/SRAM:同样,GPU的SM也有自己的缓存和共享内存,用于加速线程对数据的访问。
数据流 :在每一个模拟时间步中,数据可能在 DRAM -> PCIe -> GPU显存 -> GPU缓存 -> 计算核心 -> GPU显存 -> PCIe -> DRAM 这条路径上流动。优化这个数据流是提升性能的关键。
为什么设计成这样?------ 设计哲学与权衡
1. 专核专用,提升能效
CPU核心:擅长处理复杂的逻辑、分支判断和串行任务(如任务调度、I/O)。我们用它们做"管理工作"。
GPU核心:擅长对海量数据做相同的简单操作(单指令多数据流,SIMD)。我们用它们做"体力活"。
让合适的硬件做合适的事,整体能效最高。这呼应了之前提到的向量化能效优势。
2. 内存分层,平衡速度与容量:
缓存最快但容量小(MB级),DRAM/显存较慢但容量大(GB级)。通过智能的数据放置和访问预测,让最需要的数据待在最快的地方
3. 集成与离散的互补:
iGPU延迟低,适合与CPU紧密协作的轻量任务和显示。
dGPU吞吐量高,适合大规模数值计算。这种组合提供了灵活性。
4. 横向扩展
当一个问题(如模拟全中国的天气)单个节点无法承受时,可以通过网络连接更多节点。这就是超级计算机的基本构建块。
总结与启示
这张图描绘的不仅是硬件,更是现代计算任务的执行地图。以我们的天气预测为例:
并行发生在多个维度:
- 进程级:跨节点(MPI),分割空间网格。
- 线程级:节点内多CPU核心。
- 向量级:CPU的AVX指令、GPU的SIMT架构。
编程挑战巨大:程序员需要使用 MPI + OpenMP + CUDA/OpenCL 等多种技术的混合编程模型,并精心设计数据布局和通信,才能让这个复杂架构高效运转。
性能瓶颈可能在任何地方:可能是网络带宽、PCIe带宽、内存带宽,或者某个GPU核心的计算速度。优化是一个系统工程。