近年来,随着生成式AI技术的突破,世界模型(World Models) 已成为自动驾驶与具身智能领域的核心研究方向。从文本直接生成驾驶视频,到可控的4D动态场景合成,当前模型已经能够产出视觉上足以"以假乱真"的驾驶画面。
然而,一个根本性问题长期被行业忽视:
这些"看起来很真实"的生成内容,真的"像一个世界"吗?
它们是否保持了多视角的几何一致性?是否遵循物理规律与运动学约束?能否支持稳定、可靠的决策与控制?
一、当前评测体系的局限
目前大多数世界模型的评估,仍然依赖于 LPIPS、FVD 等基于感知相似度的指标,或是人工评判视频是否"清晰""流畅"。这些方法主要关注画面像不像真视频,却几乎不检验:
-
不同摄像头视角之间是否几何对齐
-
场景结构能否被稳定重建为3D/4D表示
-
在生成的世界中,规划器能否"正常开车"
-
人类是否认为生成的行为是安全、合理的
这种评测的局限直接导致了能力割裂:
-
有的模型纹理极其逼真,但几何完全错乱
-
有的模型几何相对稳定,却频繁出现违反物理规律的行为
-
不同论文使用不同指标,结果无法直接比较、结论难以复现
二、WorldLens:一套全光谱世界模型评估框架
为了系统性地填补这一评估空白,WorldBench团队提出了 WorldLens------一套统一、可解释、覆盖多维度能力的评估体系。

相关资源
项目主页: https://worldbench.github.io/worldlens
论文地址: https://arxiv.org/abs/2512.10958
该框架不再只问"生成得像不像",而是全面检验一个世界模型是否真正理解并建模了世界。
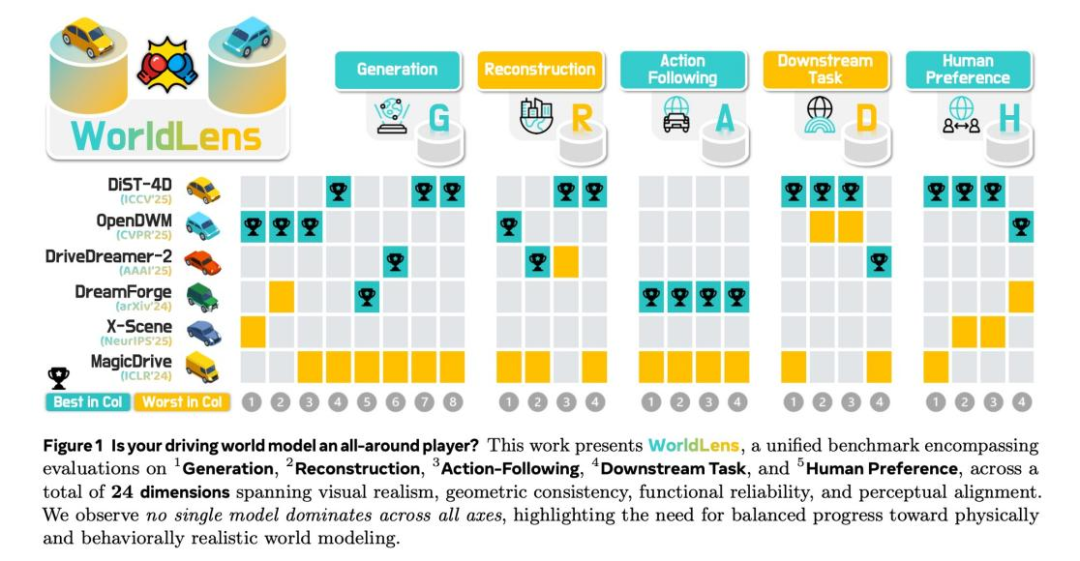
WorldLens 将评估分解为 5 个核心方面,涵盖 24 个可解释维度:
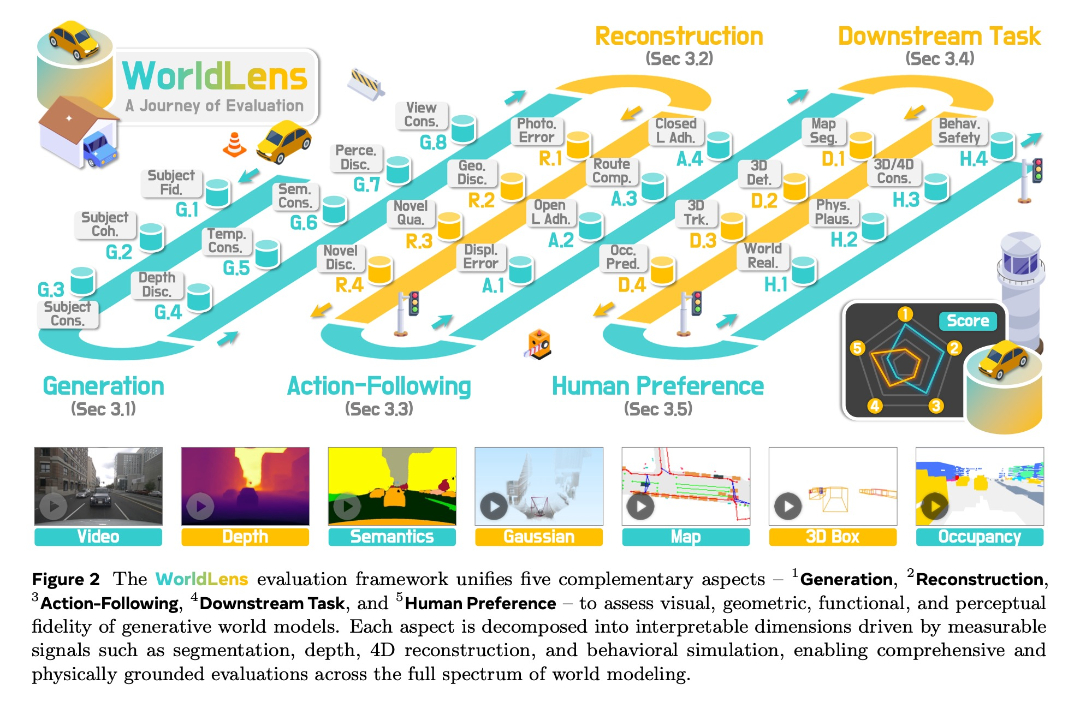
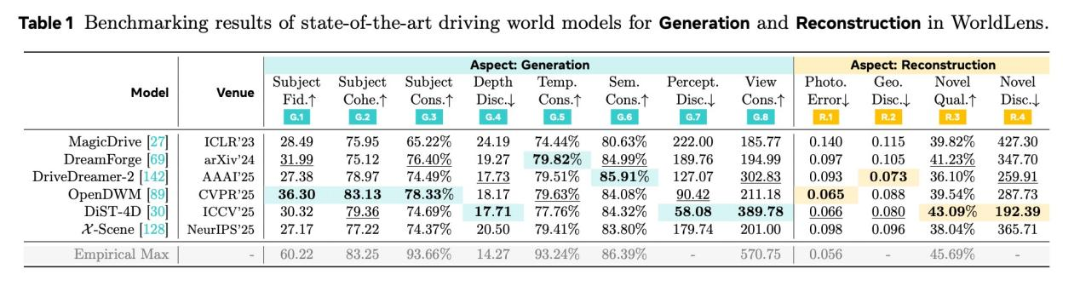
生成(Generation)------不只是"好看"
突破传统视频生成评测,从多个层面拆解生成质量:
对象真实性:使用分类器判断生成的车辆、行人是否具备真实语义属性
对象一致性:通过ReID与DINO特征评估对象在时间上的身份稳定性,避免"闪烁"或变形
几何平滑性:基于单目深度估计检验深度场在时间上的连续性
多视角一致性:评估相邻摄像头之间的几何与光度对齐程度
实验发现,许多模型在对象一致性上存在严重问题------同一物体在连续帧中"像是不同实体"。
重建(Reconstruction)------能否还原一个4D世界?
如果一个模型真正理解了空间结构,那么从它生成的视频应能重建出稳定的4D场景。

WorldLens 将生成视频重建为 4D Gaussian Field,并评估:
-
原视角重建精度
-
与真实世界的几何差异
-
新视角合成质量
一个普遍现象是出现大量 "悬浮物"(floaters)------在新视角下暴露出不连续、无物理支撑的几何碎片。这清晰表明:感知真实 ≠ 几何真实。
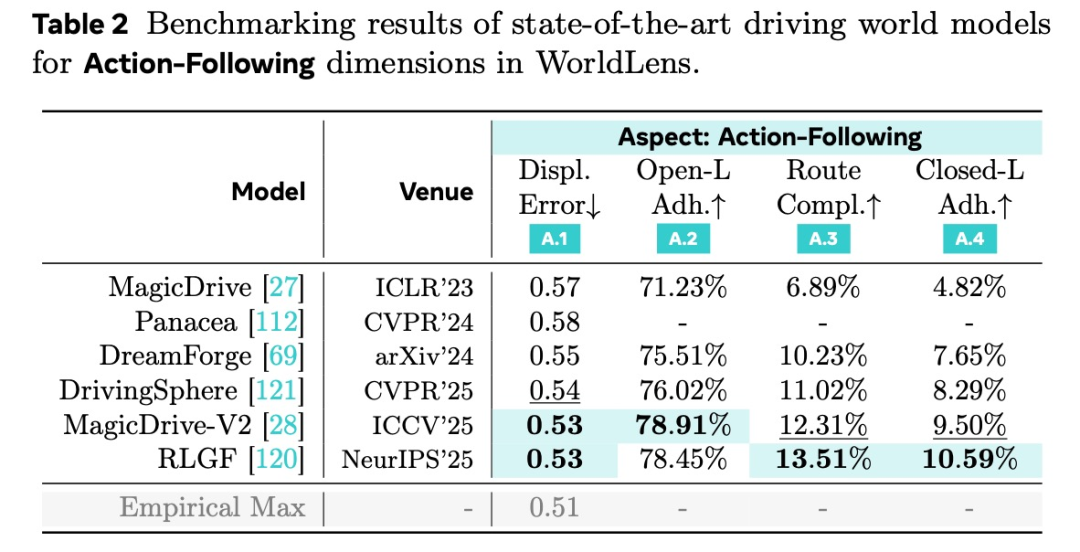
指令跟随(Action-Following)------在这个世界里能"开车"吗?
WorldLens 将生成视频输入预训练自动驾驶规划器,进行开环与闭环仿真,评估:
-
轨迹预测误差
-
开环驾驶稳定性
-
闭环任务完成率
-
综合安全得分
结果令人警醒:几乎所有模型在闭环条件下都会快速失败,出现碰撞、越界等不合理行为。

这说明,缺乏真实物理约束的"视觉世界",无法支持可靠决策。
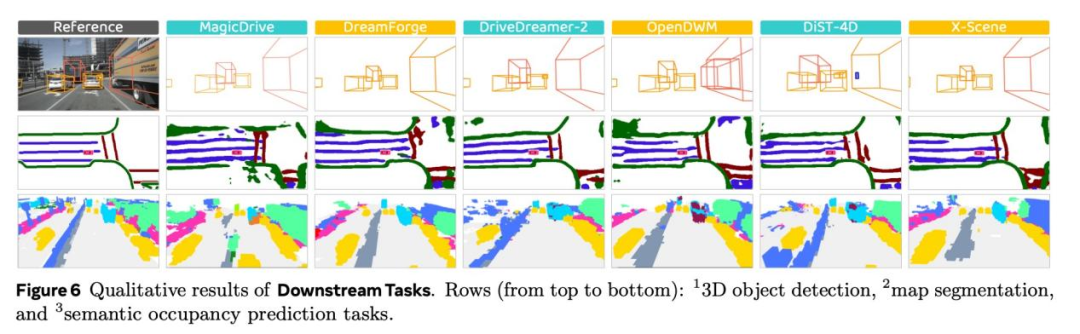
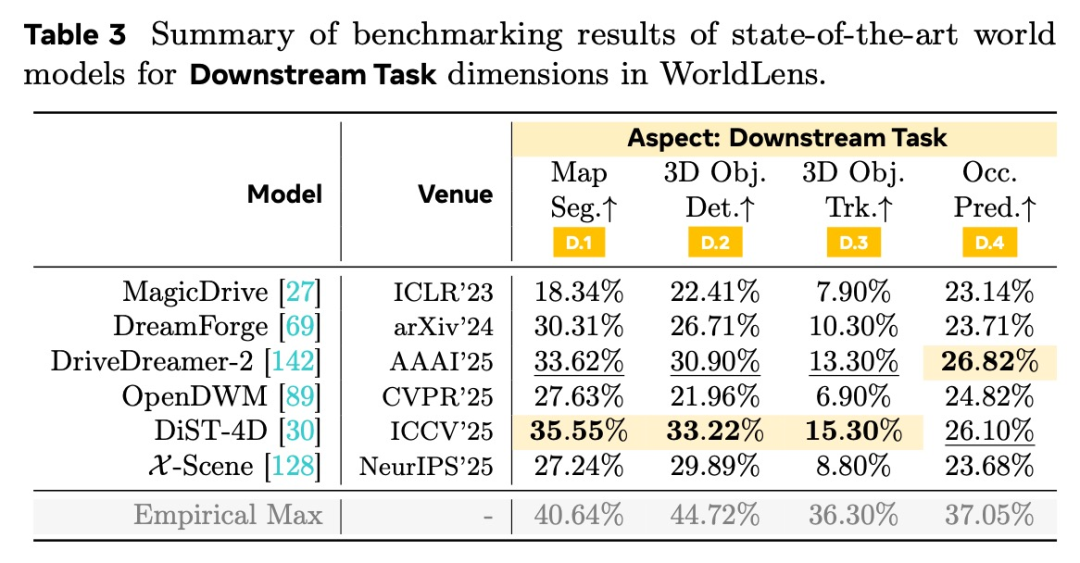
下游任务(Downstream Task)------生成数据是"助力"还是"噪声"?
直接测试:用生成数据训练感知模型,性能会提升还是下降?
评测任务包括:
-
BEV地图分割
-
3D目标检测与跟踪
-
语义Occupancy预测
某些视觉质量很高的模型,在下游任务上性能下降高达30--50%。数据分布的偏移与时序不稳定,比画面清晰度影响更大。
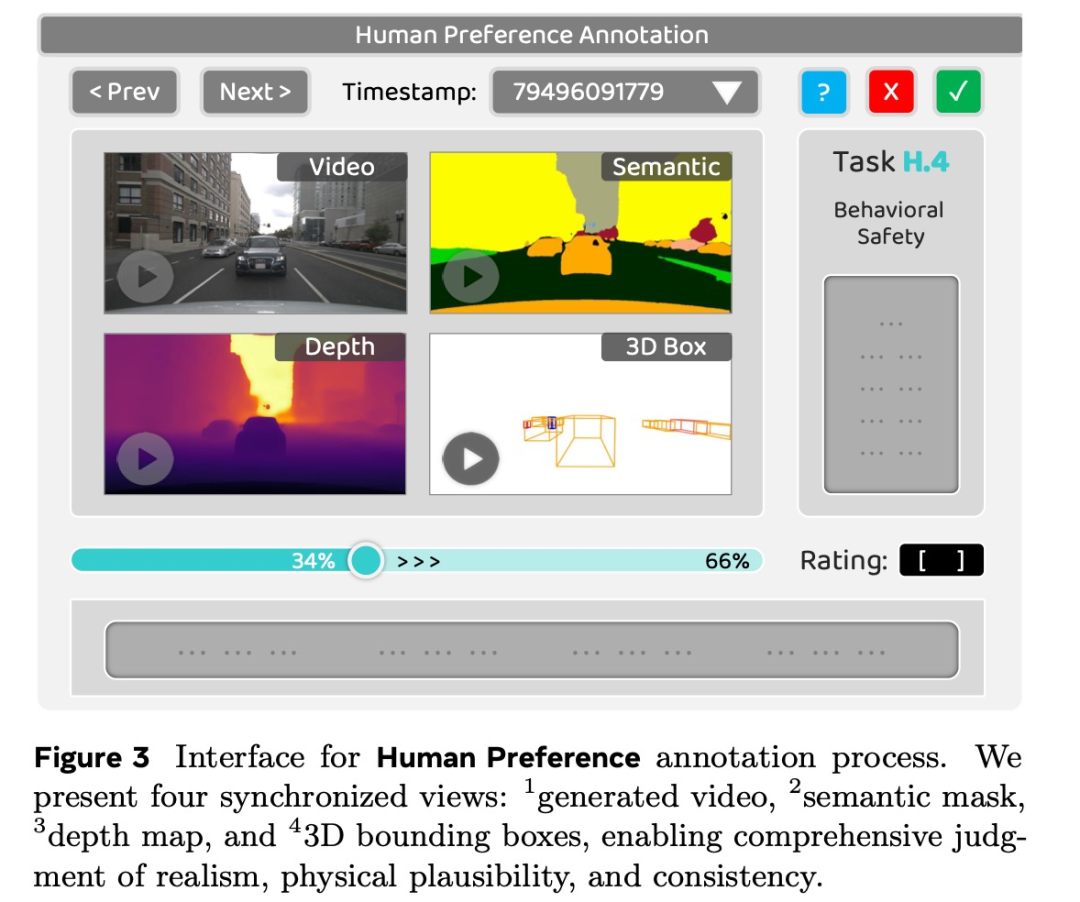
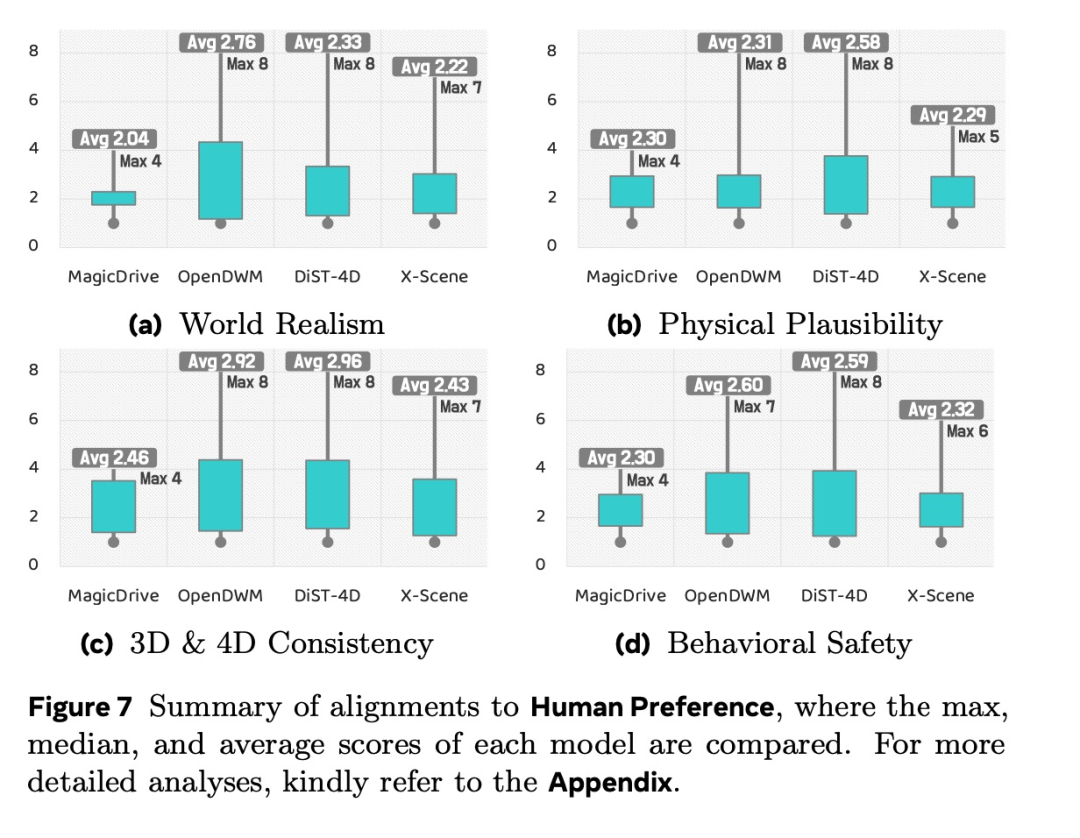
人类偏好(Human Preference)------算法指标之外的真实判断
构建了包含 26,808 条样本的 WorldLens-26K 人工评测数据集,涵盖:
-
对世界真实感、物理合理性的评分(1-10分)
-
对应的自然语言解释
人类往往能综合察觉出算法指标未能捕捉的"不自然感"与"安全隐患"。

三、关键发现与启示
通过对多类主流驾驶世界模型的系统评测,WorldLens 揭示了若干重要结论:
不同能力维度存在显著"断层"
在生成、重建、行为、下游任务与人类偏好之间,不存在可以"以一概全"的替代指标。一个模型可能在视觉质量上领先,却在几何重建中严重失真;在开环测试中表现尚可,却在闭环中迅速崩溃。
几何与时序稳定性是"共同瓶颈"
深度不一致性较大的模型,在4D重建中往往产生大量悬浮碎片;重建不稳定的模型,在闭环驾驶中也更容易失败。几何与时序一致性是贯穿多个评估维度的基础前提。
闭环评测会放大模型缺陷
在开环条件下,许多模型还能维持相对合理的轨迹;一旦进入闭环交互,微小的不一致会持续累积,最终导致任务失败。这说明,若世界模型目标服务于决策与控制,闭环评测必不可少。
"好看"不等于"好用"
视觉质量最高的生成数据,未必能提升下游感知模型的性能,甚至可能因分布偏移而产生负迁移。世界一致性约束比画面逼真度更为关键。
人类偏好与算法指标互为补充
人类能综合判断生成世界的"可信度",其自然语言反馈常直接指向几何异常、物理不合理等具体问题,为模型改进提供了明确方向。
总结与展望
当我们谈论"世界模型"时,我们期待的不仅是它能生成逼真的画面,更是它能够建模一个具有几何一致性、物理合理性、行为可执行性的动态世界。

WorldLens 的提出,标志着世界模型评估从感知驱动迈向认知与功能驱动的新阶段。它为未来研究指出了明确方向:
-
从帧级真实走向对象级、时序级与几何级真实
-
从单视角生成走向多视角与4D一致性建模
-
从离线合成走向闭环交互与行为可执行性验证
在世界模型逐渐成为自动驾驶与具身智能核心组件的今天,如何评估"世界是否真的像一个世界",已变得与如何生成这个世界同等重要。只有建立全面、严谨的评估体系,我们才能确保生成的世界不仅"看起来真实",更能"用起来可靠"。