核心结论:用 PyTorch 搭建神经网络主要有两种方式,自定义模型灵活适配复杂需求,Sequential 快速搭建简单顺序结构,关键是明确层结构、初始化参数和查看模型信息。
一、核心概念:模型是 "层的组合"
神经网络的核心是把不同功能的层(比如全连接层、激活层)按顺序拼起来,就像搭积木。PyTorch 里所有模型和层都基于**Module**类,只要继承它并实现两个核心方法,就能自定义模型。
二、两种搭建方式
1. 自定义模型(灵活款)
适合复杂结构(比如多分支、特殊逻辑),需要手动定义层和数据流向。
- 步骤:
- 继承
torch.nn.Module,在__init__里定义各层(比如全连接层、激活层),并初始化权重(比如 Xavier 适配 Tanh,He 适配 ReLU)。 - 在
forward里写数据传播路径:输入→第一层→激活函数→第二层→...→输出。
- 继承
- 优势:想怎么改就怎么改,支持各种复杂逻辑。
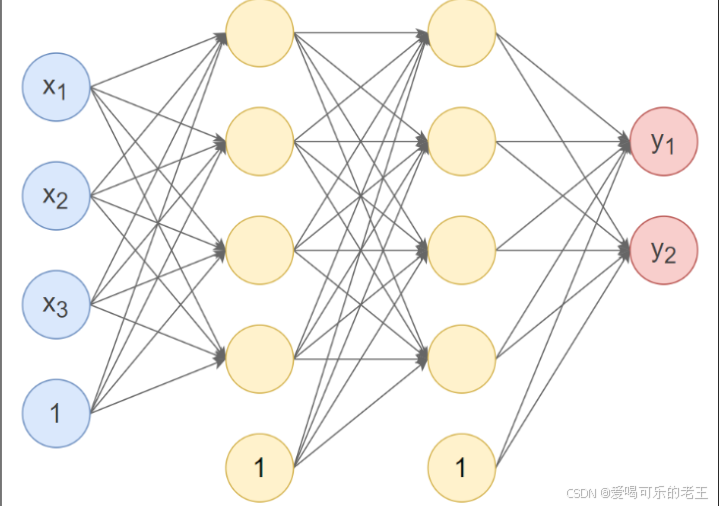
根据上图的神经网络Pytorch代码实现:
-
第1个隐藏层:使用Xavier 正态分布初始化权重,激活函数使用 Tanh。
-
第 2个隐藏层:使用 He正态分布初始化权重,激活函数使用ReLU。
-
输出层:按默认方式初始化,激活函数使用 Softmax。
#自定义模型
import torch
import torch.nn as nnclass Model(nn.Module):
def init(self):
super(Model,self).init() #继承父类初始化
self.linear1 = nn.Linear(3,4) #第一个隐藏层,输入3个特征,输出4个特征
nn.init.xavier_normal_(self.linear1.weight) #初始化权重
self.linear2 = nn.Linear(4,4) #第二个隐藏层,输入4个特征,输出4个特征
nn.init.kaiming_normal_(self.linear2.weight) #第二个隐藏层,输入4个特征,输出4个特征
self.linear3 = nn.Linear(4,2) #输出层,输入4个特征,输出1个特征,默认使用He初始化def forward(self,x): x = self.linear1(x) #经过第一个隐藏层 x = torch.relu(x) #激活函数 x = self.linear2(x) #经过第二个隐藏层 x = torch.relu(x) #激活函数 x = self.linear3(x) #输出层 x = torch.softmax(x,dim=1) #激活函数 return xmodel = Model()
output = model(torch.randn(10,3))
print("输出:\n",output)
print()#使用named_paremeters()查看各层参数
print("模型参数:")
for name,param in model.named_parameters():
print(name,":",param.size())
print()#使用state_dict()查看各层参数
print("模型参数:\n",model.state_dict())
查看模型结构与参数数量:
可使用 torchsummary.summary 来查看模型结构与参数数量。需要先安装torchsumm库:
pip install torchsummary
#模型结构和参数查看
from torchsummary import summary
# input_size:特征数,batch_size:样本数
summary(model, input_size=(3,), batch_size=10, device="cpu")
2. Sequential 搭建(快捷款)
适合简单的 "顺序结构"(一层接一层,无分支),直接按顺序传入层即可。
-
步骤:
- 把要用到的层按顺序放进
nn.Sequential()里,自动按顺序执行。 - 用
apply()方法批量初始化各层参数(比如给所有全连接层初始化权重)。
- 把要用到的层按顺序放进
-
优势:代码简洁,不用写
forward,快速搭建基础模型。#构建模型
model = nn.Sequential(
nn.Linear(3,4),
nn.Tanh(),
nn.Linear(4,4),
nn.ReLU(),
nn.Linear(4,2),
nn.Softmax(dim=1)
)#初始化参数
def init_weights(m):
"""判断当前层是否为线性层(全连接层)。
如果是,则执行下面的初始化操作;
如果不是(例如卷积层、RNN层),则跳过。"""
if type(m) == nn.Linear:
nn.init.xavier_normal_(m.weight) #初始化权重
m.bias.data.fill_(0.01) #填充0.01偏置model.apply(init_weights)#apply会遍历所有子模块依次调用函数
output = model(torch.randn(10,3))
print("输出:\n",output)
三、关键操作:查看模型信息
搭好模型后,需要确认结构和参数是否正确:
- 查看参数:用
named_parameters()或state_dict(),能看到每一层的权重、偏置数值。 - 查看结构和参数数量:用
torchsummary.summary(),输入输入数据的形状,就能看到每层的输出形状、参数个数,避免结构出错。
四、通俗总结
- 简单任务用 Sequential,几行代码搞定;复杂任务用自定义模型,灵活适配需求。
- 初始化权重有讲究:ReLU 配 He 初始化,Tanh/Sigmoid 配 Xavier 初始化,避免模型 "学不动"。
- 搭完必看结构和参数,确认每层输出符合预期,不然训练时容易报错。