从 0 到 1 构建企业智能体平台:openJiuwen 实现ChatBI工作流实战
引言
如果你在最近一年里认真做过大模型相关的项目,大概率都会有一个共同感受: "模型是越来越强了,但系统反而越来越难做了。"
当我们真正尝试把大模型引入企业核心流程时,很快就会遇到一些现实问题。这些问题的本质,并不在模型本身,而在于缺少一个"Agent 级别的工程平台"。
换句话说,企业真正需要的,已经不是"再强一点的大模型",而是一个能把 Agent 当作一等公民来管理、编排和运行的平台。为什么我们选择从「智能体平台」开始,而不是直接做一个 Agent?这是一个很关键的设计取舍。
如果只是做一个 Demo,一个智能客服 Agent 当然可以"硬写"出来;但一旦你考虑的是:后续还会不会有更多 Agent?不同业务线能否复用能力?Agent 行为是否需要被约束和评估?那答案往往只有一个:
必须先有平台,再有 Agent。
这也是本文想要分享的核心思路------不是"做一个智能客服",
而是先构建一个企业可控、可扩展、可复现的 Agentic AI 开源平台 ,
然后在这个平台之上,去落地一个真实可用的企业级智能客服智能体。
文章会尽量避免空泛的概念描述,而更侧Agent 抽象如何落地、客服场景如何拆解为多 Agent 协作、工程层面如何做到可复现、可演进。
在进入正文之前,也简单介绍一下我自己。
我是 Fanstuck,致力于将复杂的技术知识以易懂的方式传递给读者,
热衷于分享大模型、Agentic AI 以及企业级智能系统的真实落地实践。
如果你对大模型的创新应用、AI 技术发展,尤其是**"从 Demo 到工程化落地"**这一阶段的问题感兴趣,欢迎关注 Fanstuck。
第 1 章|openJiuwen 在整个 Agentic AI 技术栈中的位置
在开始搭建 Agent 平台之前,有一个问题必须先厘清:
openJiuwen 在整个 Agentic AI 系统中,到底应该放在什么位置?
这个问题之所以重要,是因为 Agent 项目一旦复杂起来,失败往往不是因为模型不行,而是因为系统边界不清。很多团队在实践中都会经历类似的过程:一开始只是写几个 Agent 脚本,用 Prompt 串一串工具调用;但随着业务演进,Agent 数量增加、流程变复杂、系统开始需要长期运行,原本"还能凑合用"的实现方式迅速失效。
问题并不出在 Agent 本身,而是出在Agent 缺少一个真正意义上的运行环境。
1.1 从完整 Agentic AI 技术栈看问题
在企业级场景中,一个完整的 Agentic AI 系统,至少可以拆分为以下几类技术层次(自下而上):
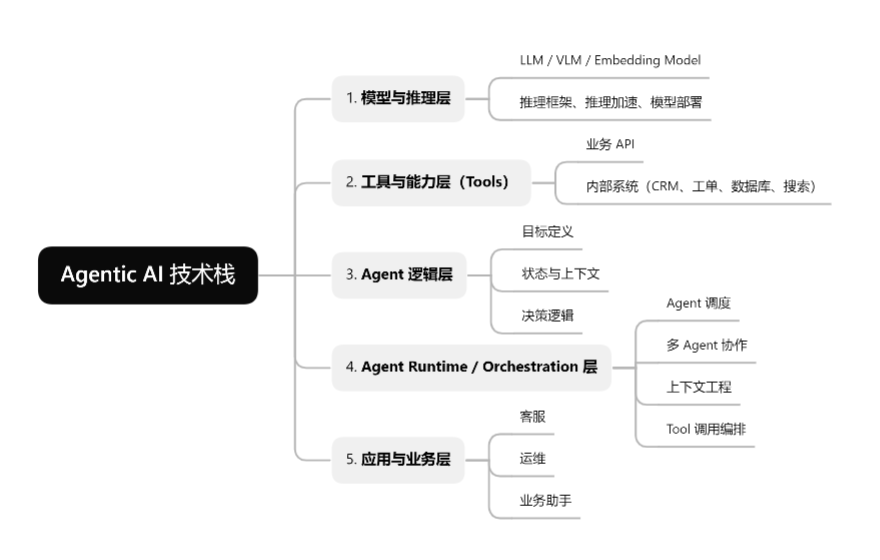
如果从完整的 Agentic AI 技术栈来看,openJiuwen 并不试图覆盖所有层面。它不提供模型,也不限定你使用哪一种推理框架;它同样不内置任何具体业务 Agent,客服、运维、分析这些角色,都需要由使用者自己定义。
openJiuwen 真正关注的,是Agent 在系统中如何被运行、被编排、被管理。
当 Agent 数量从一个变成多个,从简单问答变成复杂流程时,系统必须能够明确地回答一些问题:这个 Agent 什么时候执行?它依赖哪些上下文?它调用工具的权限和方式是什么?执行失败之后如何处理?这些问题如果没有统一的运行机制,只能靠经验和约定维持,而这在企业级系统中是不可接受的。
openJiuwen 的定位,正是为这些问题提供一个稳定的中间层。
1.2 结合架构图理解 openJiuwen 的分层设计
下面这张图,是 openJiuwen 官方给出的整体架构视图,可以通过官网进一步了解:https://gitcode.com/openJiuwen?utm_source=csdn,它本身就是一个非常"工程化"的分层表达:
从架构上看,openJiuwen 并不是一个单体系统,而是由三部分组成:
- openJiuwen Studio(开发与设计层)
- openJiuwen Core(Agent Runtime 核心)
- openJiuwen Ops(治理与运维层)
这三部分,几乎完整覆盖了 Agent 的全生命周期。
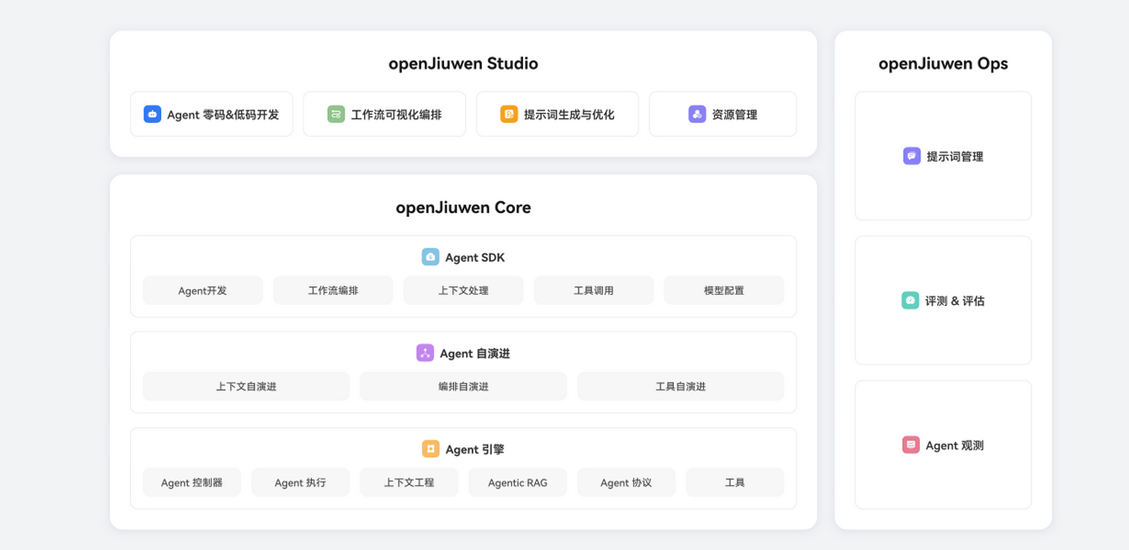
最上层的 Studio,并不是运行系统,而是一个面向开发者的设计环境。它的作用,是把 Agent 和 Workflow 从"隐式代码逻辑"中抽离出来,变成可以被显式描述和管理的工程对象。Agent 的角色定义、能力边界、流程关系在这一层被明确下来,为后续运行打下结构基础。
中间的 Core,才是 openJiuwen 的技术核心。无论是 Agent SDK、上下文处理,还是工具调用和执行引擎,本质上都在解决同一件事:让 Agent 具备一个稳定、可控的运行时环境。在这个环境中,Agent 不再是一次性执行的逻辑,而是一个可以被系统调度、被组合、被持续运行的实体。
而 Ops 层的存在,则明确了 openJiuwen 并非为 Demo 而生。Agent 的行为需要被观察、评估和治理,这些能力并不是附加功能,而是企业级系统的基本要求。只有当 Agent 的执行过程是可追踪、可回放的,它才有资格进入真实业务。
1.3Agent SDK:把 Agent 从"代码片段"变成"系统对象"
在 openJiuwen Core 中,Agent SDK 承担了一个非常关键但常被忽略的角色。
它的意义不在于"封装接口",而在于明确 Agent 的工程边界。当 Agent 的输入、输出、上下文演化方式、工具调用路径和模型配置都通过统一抽象固定下来之后,系统才能真正理解这个 Agent 在做什么,也才能围绕它建立调度、协作和治理机制。
如果没有这样的抽象,Agent 永远只是嵌在代码里的逻辑分支;而一旦有了明确的边界,Agent 才能被组合、被复用,并参与到更复杂的多 Agent 协作之中。这不是为了追求形式上的规范,而是为了让系统在规模扩大之后依然保持可控。
1.4 openJiuwen工程定位
综合架构设计和工程实践,可以给 openJiuwen 一个非常清晰的定位:
它不在模型层,也不在应用层,而是位于 Agent 的设计、运行、编排与治理之间的中间平台层。它解决的不是"Agent 能不能回答问题",而是"Agent 能不能作为系统的一部分长期存在"。
理解这一点非常重要,因为接下来的所有设计------无论是平台架构、Agent 拆分,还是智能客服工作流------都将围绕这一定位展开。
下一章,我们将基于这一定位,进一步拆解:如果从零开始设计一套企业级 Agent 平台,整体架构应该如何落位。
第2章 |openJiuwen部署及使用
我们可以使用Docker方式也可以本地部署,我这里展示两种方式,一种为Windows进行本地部署,Docker部署的方式熟悉的基本也是差不多使用方式。第二种为适用国产化操作系统完全替换方案使用Huawei Cloud EulerOS 2.0 标准版 64位形态来进行部署。
2.1环境要求
首先确保我们的本地机器满足以下要求:
- 硬件:
- CPU:最低 2 核,推荐 4 核及以上
- RAM:最低 4GB,推荐 8GB 及以上
- 操作系统:Windows10及以上
- 软件
- Git 2.40及以上
- Node.js 20.0及以上
- npm 9.0及以上
- Python 3.11.4及以上
- uv 0.5.0及以上
- MySQL 8.0及以上
- Milvus 2.6.2及以上
进行正式安装前需先完成依赖的安装,常见的python和mysql这里就不过多安装进程,Milvus 在 Windows 本地最常见的方式是:**Docker Desktop(WSL2 后端)**来跑容器(最稳、最接近生产)。官方 Windows 安装页也是按这个路线写的。因此不推荐在Windows系统上装Milvus ,要玩的话用云原生Linux的主机玩。快速部署并体验 openJiuwen 基础功能,可直接跳过安装Milvus 。
2.2Milvus安装
大家想要体验记忆功能可以参考Docker部署:
Windows 上运行 Docker Desktop 推荐使用 WSL 2(Windows Subsystem for Linux 2) 作为虚拟化后端,相比 LinuxKit 兼容性更好、资源占用更低,且能避免已知的僵尸容器 Bug。
对于符合条件的 Windows 系统,仅运行 wsl --install就能一键配置、下载并安装默认的 Linux 发行版。
- 按下 Windows + S,输入 PowerShell 进行搜索。
- 在搜索结果中,右键点击 Windows PowerShell,选择 以管理员身份运行。
- 在 PowerShell 执行如下命令,然后重新启动计算机。
- wsl --install
而旧版本 Windows 不支持这个一键命令的完整自动化功能
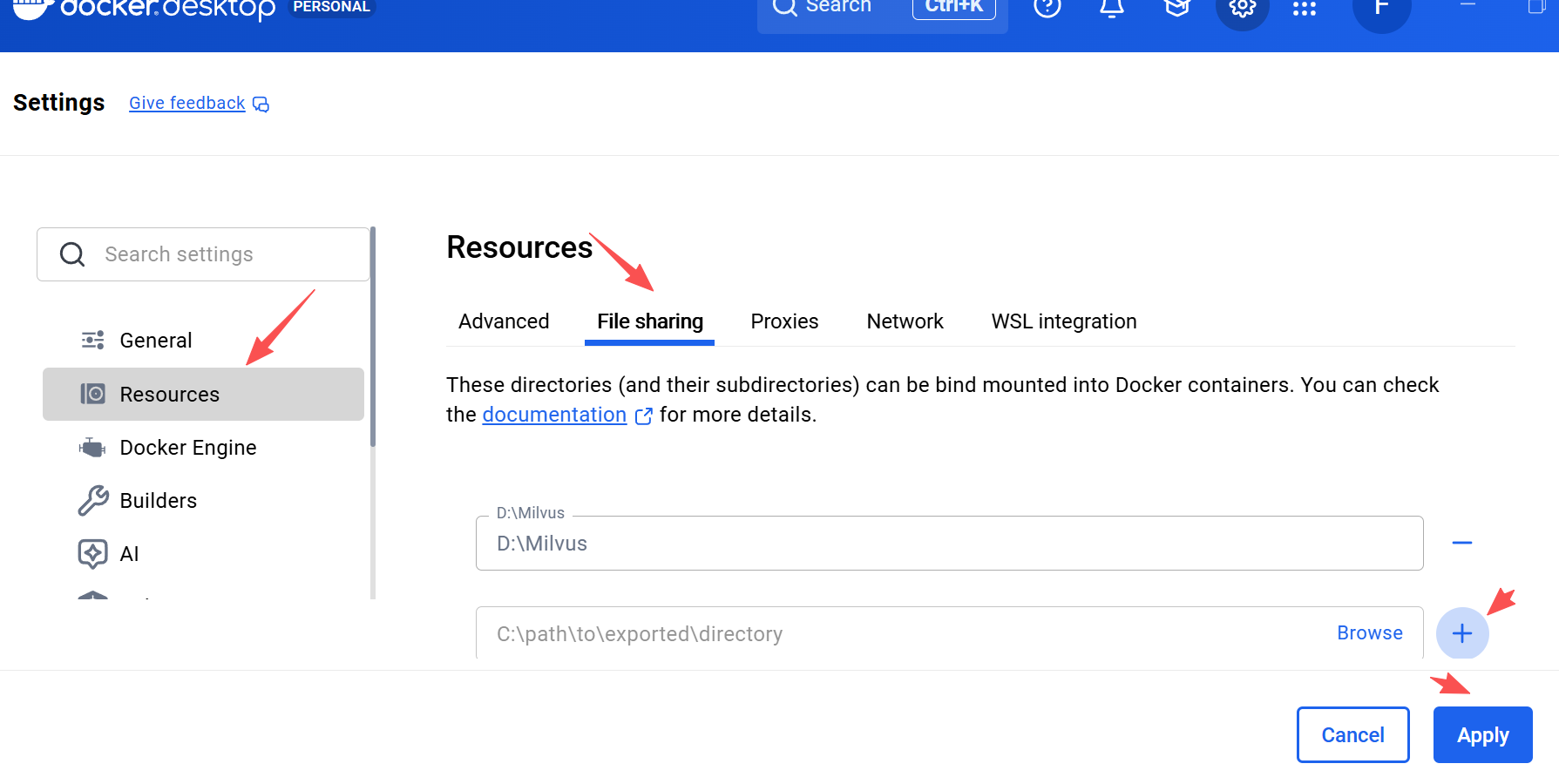
- 新建 Milvus 本地安装目录(建议存放至 D 盘,示例路径:D:Milvus);
- 打开 Docker Desktop,按照图示步骤,在序号 4 处输入 Milvus 安装目录 (例如:D:Milvus);
- 点击 "Apply & restart" 重启 Docker Desktop。
以管理员身份打开 PowerShell,先切换至 Milvus 本地安装目录,再执行以下命令保存 "standalone.bat" 脚本:
bash
cd D:Milvus # "D:Milvus" 是 Milvus 本地安装目录
Invoke-WebRequest https://raw.githubusercontent.com/milvus-io/milvus/refs/heads/master/scripts/standalone_embed.bat -OutFile standalone.bat在 "PowerShell" 执行以下命令拉取镜像:
bash
# x86 架构
docker pull swr.cn-north-4.myhuaweicloud.com/openjiuwen/milvusdb/milvus-amd64:v2.6.2- 将 "standalone.bat" 文件内的 milvus 官方镜像名(比如: milvusdb/milvus:v2.6.9) 内容修改为 对应的镜像名(X86机器镜像名:swr.cn-north-4.myhuaweicloud.com/openjiuwen/milvusdb/milvus-amd64:v2.6.2`)。
- 修改完成后,在 "PowerShell" 执行以下命令运行 standalone.bat,将 Milvus 作为 Docker 容器启动:
- ./standalone.bat start
启动后,输入 docker ps -a 命令可查看到名为 Milvus-standalone 的 docker 容器在 19530 端口启动。

- 若要停止 Milvus,请执行以下命令
- ./standalone.bat stop
2.3openJiuwen 安装
2.3.1Windows下部署
打开openJiuwen的源码仓:https://atomgit.com/openJiuwen/agent-studio
点击项目clone获取克隆信息:
新建一个openJiuwen目录然后git克隆下来:
之后我们在源码根目录打开 "PowerShell",复制 .env 文件:copy .env.example .env。
使用文本编辑器打开 .env 文件,根据实际情况修改文件中以下变量的值(勿覆盖其他变量):
配置数据库(样例)
bash
DB_HOST=localhost
DB_PORT=3306
DB_USER=your_user_name
DB_PASSWORD=your_password| 变量名 | 变量说明 | 配置样例 |
|---|---|---|
| DB_HOST | 数据库的主机地址 | localhost |
| DB_PORT | 数据库的端口号 | 3306 |
| DB_USER | 数据库的用户名 | your_user_name |
| DB_PASSWORD | 数据库的密码 | your_password |
| MILVUS_HOST | Milvus服务的主机地址 | 127.0.0.1 |
| MILVUS_PORT | Milvus服务的端口 | 19530 |
| MILVUS_COLLECTION_NAME | Milvus服务的数据库名 | memory_vector |
| EMBED_API_BASE | 向量模型的接口地址 | https://example.com/embedding_model |
| EMBED_MODEL_NAME | 向量模型的名称 | text-embedding-model |
| EMBED_API_KEY | 向量模型的API密钥 | sk-xxx |
| EMBED_TIMEOUT | 向量模型的最大等待时间 | 5 |
| EMBED_MAX_RETRIES | 向量模型请求失败时的最大重试次数 | 1 |
| 在源码根目录下打开 "PowerShell",运行以下命令启动后端服务,并耐心等待: |
bash
cd backend
uv venv
uv sync
安装完毕之后运行:
mkdir logs
mkdir logsrun
进入虚拟环境,如在 "命令提示符" 中请执行: .venvScriptsactivate
...venvScriptsActivate.ps1
启动
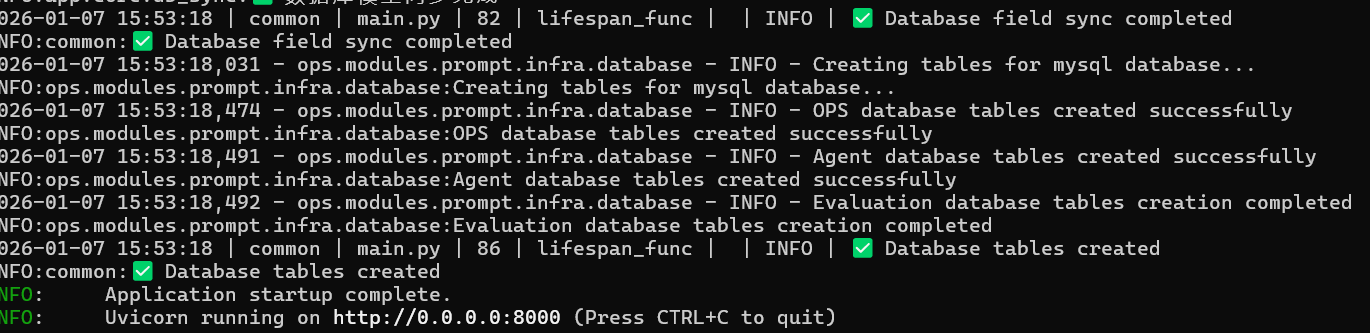
python main.py
启动成功后,会输出 "Application startup complete"。
在源码根目录下再打开一个 "PowerShell",运行以下命令安装依赖:
bash
cd frontend
pnpm install
pnpm dev安装的话会有比较多的坑,出现什么问题交给AI分析解决会更高效。我这里遇到了
bash
symlink '...packagesapi-client' -> '...node_modules@test-agentstudioapi-client'
EISDIR illegal operation on a directory在 frontend 目录执行:
bash
pnpm config set inject-workspace-packages true然后清理重装:
bash
rd /s /q node_modules
del pnpm-lock.yaml
pnpm install然后需要注意Windows安装,Semi 这套包在 ESM 子路径导入里大量用"无后缀 / 导入目录",而 Vite 6(esbuild)在有 exports 的情况下变得非常严格,不再帮你自动补 .js 或自动落到 index.js。先把 Vite 降到 5,之后修改 package.json(两行)
把这两项改成 Vite 5 的版本(直接改,不要留 ^6):
bash
"devDependencies": {
...
"@vitejs/plugin-react": "4.3.4",
"vite": "5.4.11"
}Windows 下你的 build 脚本也有问题
现在 build 用的是:
bash
"build": "NODE_OPTIONS='...' vite build ..."这个写法是 Linux bash 的,Windows cmd 下会不生效/报错。
建议改成跨平台(需要装 cross-env):
bash
pnpm add -D cross-env然后把脚本改成:
bash
"build": "cross-env NODE_OPTIONS=--max-old-space-size=8192 --max-semi-space-size=256 vite build --mode production"然后最大的问题是Vite 的依赖预构建(optimizeDeps)用的是 esbuild,它会严格遵守 package.json 的 exports,并且不会帮 Semi 这种"无后缀 / 导入目录"的写法自动补 .js 或 /index.js。
Semi 这套包(semi-ui → semi-foundation)内部确实有一堆这种写法,靠手动 alias 一条条补会累死。正确做法是:在 Vite 的 optimizeDeps/esbuild 阶段加一个 resolver 插件,一网打尽。
清一下 Vite 缓存并重启:
bash
rd /s /q node_modules.vite
rd /s /q .vite
pnpm run dev打开进入页面效果如下:
我们输入空间名称(任意邮箱格式)即可进入:
2.3.2openEuler下部署
采取openEuler部署大多是国企和单位,完全符合信创要求,要体验最新openEuler的系统推荐上华为云选择购买弹性云服务器,可以选择openEuler镜像:
实例选择符合我们软件部署要求的最低 2 核,推荐 4 核及以上.

在 Linux 系统采用 Docker 方式安装 openJiuwen比较方便,
进入到系统之后,首先运行指令:
删除所有docker相关的CentOS仓库文件
bash
sudo rm -rf /etc/yum.repos.d/*docker*.repo 清理dnf缓存
bash
sudo dnf clean all
sudo rm -rf /var/cache/dnf/*删除无效的docker.repo文件先清理加载失败的配置文件,避免干扰::
bash
sudo rm -f /etc/yum.repos.d/docker.repoopenEuler 中没有yum-utils,但dnf-utils是其等效工具,且device-mapper-persistent-data已被thin-provisioning-tools替代:
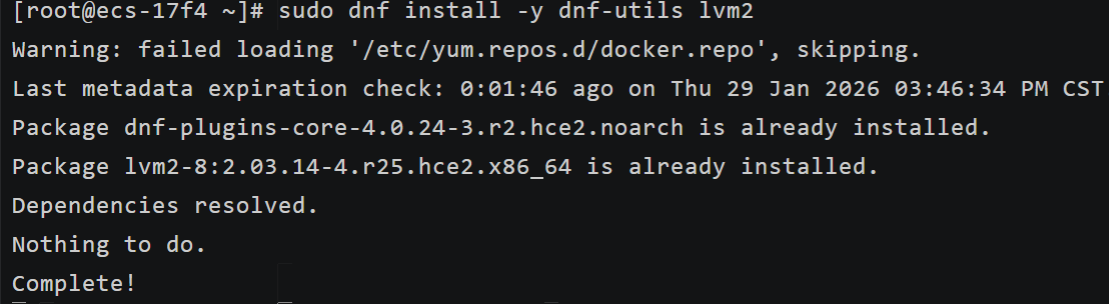
安装dnf-utils(替代yum-utils),并确认lvm2已装
bash
sudo dnf install -y dnf-utils lvm2执行后会看到lvm2提示已安装,dnf-utils会正常安装 ------ 这就完成了原命令中依赖的替代。
openEuler 不推荐直接装docker-ce,而是用官方适配的docker包(或通过容器引擎替代):
安装openEuler适配的docker包
bash
sudo dnf install -y docker启动并验证 Docker/containerd:
bash
sudo systemctl start docker
sudo systemctl enable docker
docker --version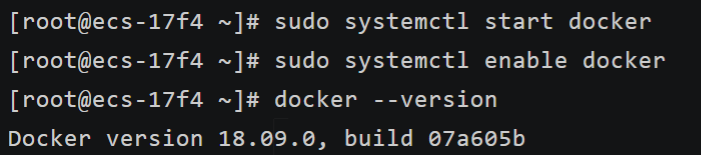
下载版本包openJiuwen- x86_64 架构版本包
bash
wget https://openjiuwen-ci.obs.cn-north-4.myhuaweicloud.com/agentstudio/deployTool_0.1.3_amd64.zip安装 unzip 工具
bash
sudo dnf install -y unzip执行以下命令解压文件,并进入解压后的目录:
bash
# 解压amd64架构的安装包
unzip deployTool_0.1.3_amd64.zip
# 查看解压后的目录名(确认名称,通常是deployTool_0.1.3_amd64)
ls -l
# 进入解压后的目录(请确认目录名和解压结果一致)
cd deployTool_0.1.3_amd64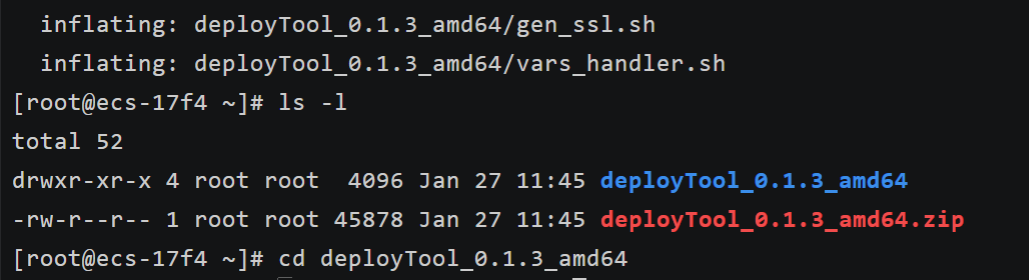
适配 openEuler 配置 Docker:openEuler 的 Docker 有 seccomp 内核安全机制限制,必须先处理,否则部署会失败:
验证Docker状态(确保输出 active (running))
bash
sudo systemctl status docker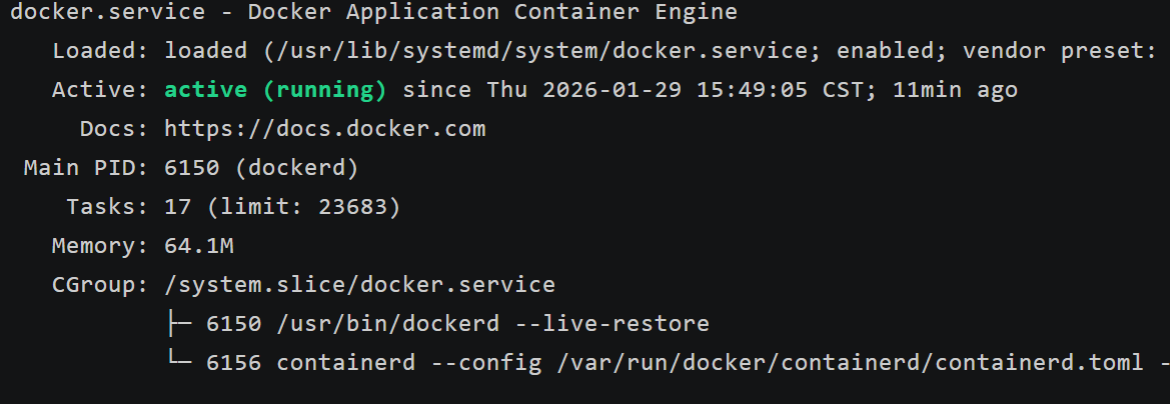
在 openEuler 中安装 Docker Compose,openEuler 可以通过两种方式安装,优先选择二进制包:
bash
[root@ecs-17f4 deployTool_0.1.3_amd64]# sudo curl -L "https://github.com/docker/compose/releases/download/v2.24.7/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 58.6M 100 58.6M 0 0 231k 0 0:04:19 0:04:19 --:--:-- 189k
[root@ecs-17f4 deployTool_0.1.3_amd64]# sudo chmod +x /usr/local/bin/docker-compose
[root@ecs-17f4 deployTool_0.1.3_amd64]# sudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
[root@ecs-17f4 deployTool_0.1.3_amd64]# docker-compose --version
Docker Compose version v2.24.7下载完成后,配置权限和全局软链接
bash
# 1. 给下载的二进制包添加执行权限(openEuler必需)
sudo chmod +x /usr/local/bin/docker-compose
# 2. 创建全局软链接,让系统能全局识别docker-compose命令
sudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
# 3. 验证安装结果(关键!必须输出Compose版本)
docker-compose --version
修改conf/docker-jiuwen.template.yml文件:
# 进入配置目录(确保在deployTool_0.1.3_amd64目录下执行)
cd conf
# 编辑docker-jiuwen.template.yml文件,添加seccomp配置
sudo vi docker-jiuwen.template.yml
在文件中找到**每个容器的配置段**(如 mysql、milvus、etcd 等),为每个容器添加security_opt配置(以 milvus 为例,其他容器同理)。
启动 openJiuwen 服务
# 回到openJiuwen根目录
cd /root/deployTool_0.1.3_amd64
# 启动服务
sudo ./service.sh up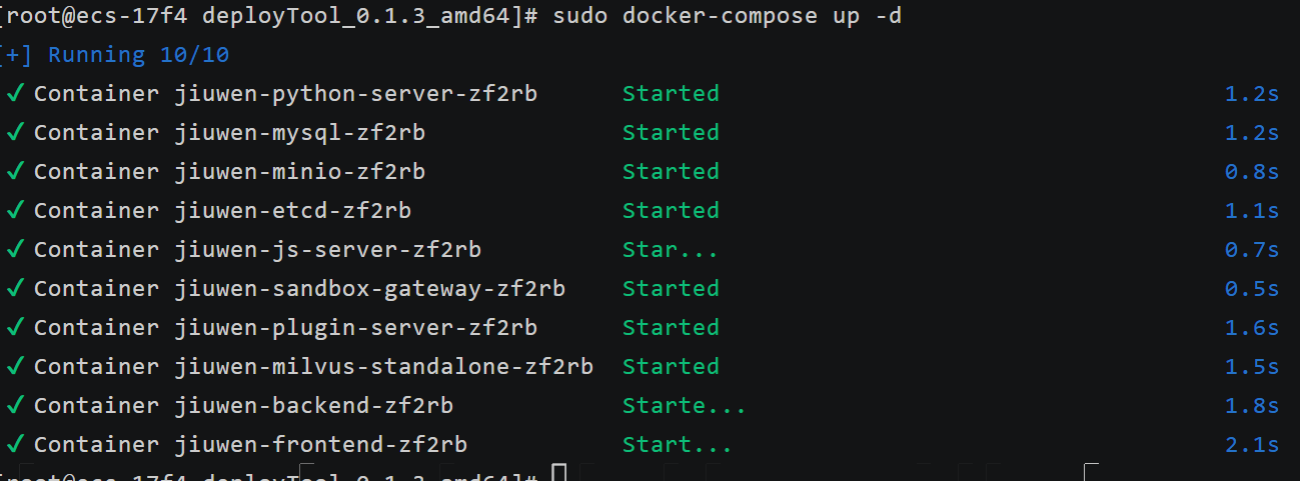
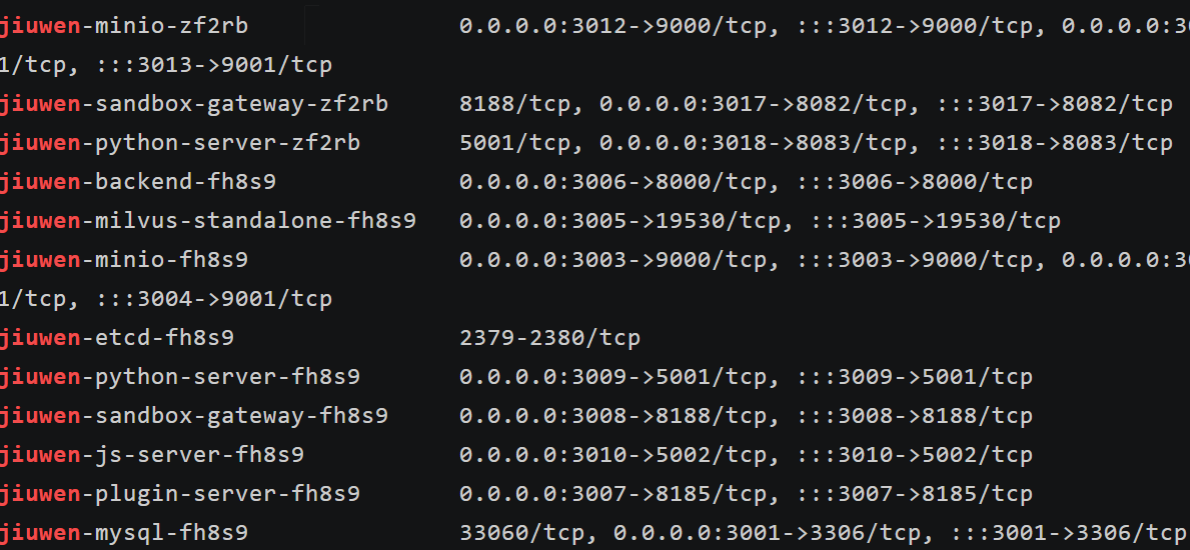
第3章|ChatBI 智能问数工作流实战:从自然语言到可执行 SQL
在许多业务场景中,用户最关心的是如何快速获取最终的数据结果,而不是去理解数据是如何被提取和处理的。学习数据获取的复杂过程往往是一个高成本的障碍,而降低这一成本直接关系到产品的吸引力和用户的转化率。对于我们技术人员而言,尽管研发思维是核心,但我们开发的服务最终还是为了更好地服务于业务需求。随着技术的进步,自然语言到SQL(NL2SQL)转化已成为数据开发的未来趋势,它让用户能够用最少的学习成本获取他们所需的数据。ChatBI正是这一趋势的具体体现,它不仅降低了技术门槛,还显著提升了用户体验和产品竞争力,使数据分析变得更加直观和高效。
3.1 场景目标与边界
在实际工程中,用户提问经常不是一个明确的 SQL 需求,而是一个"带业务语气的模糊意图"。
"最近内窥镜用超声诊断设备贵不贵?"
"哪个品牌更贵?"
"是不是有医院采购得特别多?"
如果你让模型直接生成 SQL,它一定能生成------但它生成的 SQL 不一定是你敢执行的 SQL。因为企业里真正麻烦的不是"写不出 SQL",而是:
- SQL 的范围不受控:可能一口气扫两年全表
- SQL 的口径不受控:"最近"到底是 7 天还是 90 天
- SQL 的行为不受控:你无法保证不会出现危险语句
- SQL 的结果不受控:跑出来结果不可信也没人兜底
换句话说,Text2SQL 的问题不是准确率,而是不稳定性带来的工程风险。
openJiuwen 在这里的设计选择,是把问数拆成几段"可隔离故障"的步骤,让每一步都可以被单独约束、单独替换、单独审计。
这样做的结果是:即使模型偶尔犯错,系统也不会直接把错误扩大成线上事故。
3.2 ChatBI 的正确抽象:把问数过程拆成 6 个节点
如果把 ChatBI 当成一个能上线的系统,它的核心不是"生成 SQL",而是"把一次问数变成一条稳定的执行链"。
我们可以按下面这个顺序搭一个最小闭环:
用户问题 → 意图解析 → SQL 生成 → SQL 治理 → SQL 执行 → 结果解释 → 全链路归档
3.3 第一个节点:意图解析 Agent
在实际工程中,"用户输入"经常被当成"SQL 生成器的 prompt"。
但当系统规模发生变化时,这种做法会暴露出一个很致命的问题:你无法做治理。
因为治理需要的不是自然语言,而是结构化意图。
openJiuwen 在这里的设计选择,是先用一个轻量的 Agent,把用户问题解析成一个 QuerySpec。这个 QuerySpec 不追求"理解很深",但必须做到"可控"。
这样做的结果是:你后面任何治理策略,都可以围绕 QuerySpec 做,而不是围绕一段不可预测的用户文本做。
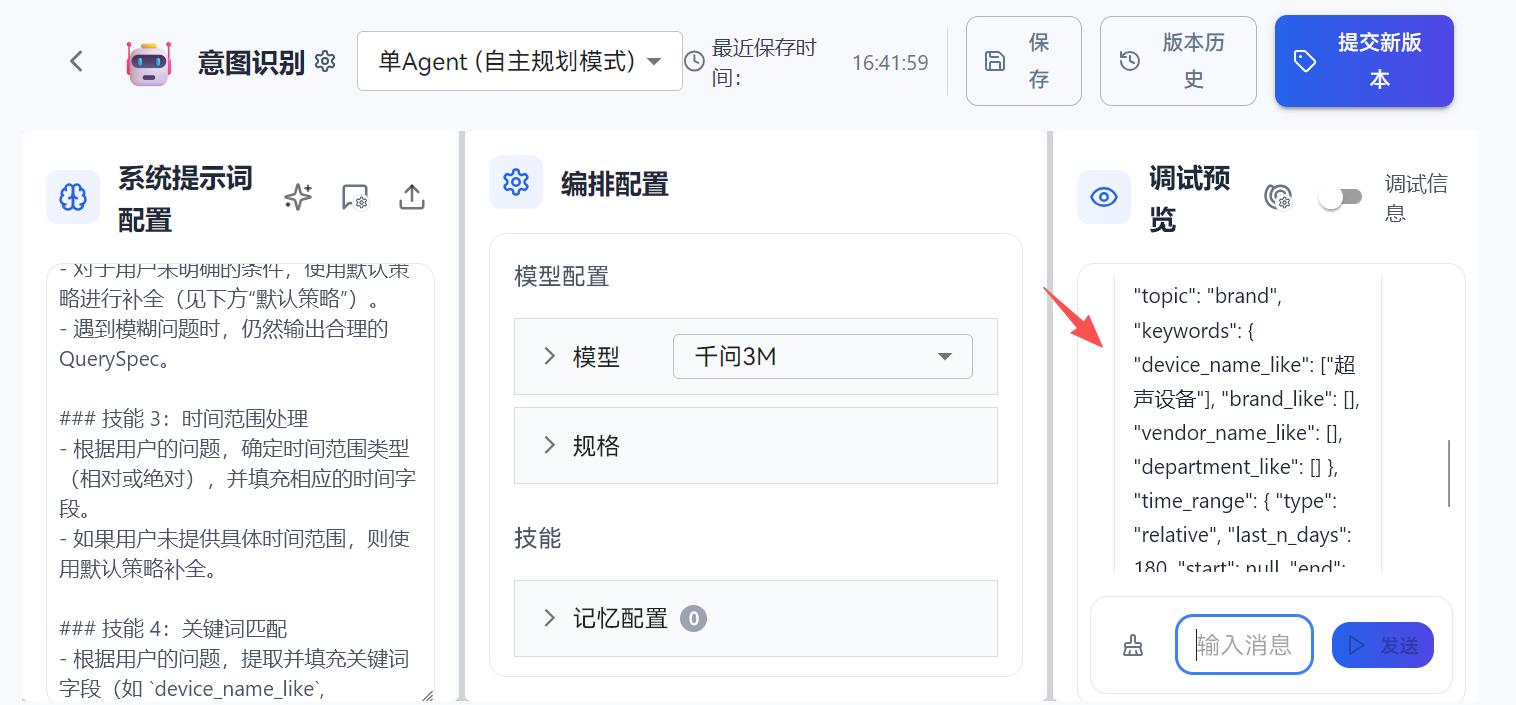
3.4 第二个节点:SQL 生成 Agent
在实际工程中,很多团队会把 SQL 生成写成"模型输出 + 解释文本"。
但当系统规模发生变化时,这种做法会暴露出一个非常烦人的问题:执行层很难处理。
因为你一旦混入自然语言,就意味着你要做解析、做清洗、做容错;而这些东西一旦写起来,就会变成你最不想维护的那类代码。
在这个工作流里,第一节点输出的是 QuerySpec(意图规范)。
第二节点的唯一职责,是把 QuerySpec 翻译成一段 MySQL 8.0 可直接执行的 SQL。
这里的关键点是:
SQL 生成 Agent 不应该再看用户原话。
它只看 QuerySpec------因为你要的是工程确定性,而不是语言发挥空间。
你可以把它理解成两层约束:
- QuerySpec 是"中间语言"(DSL)
- SQL Agent 是"后端编译器"(Compiler Backend)
这样做的结果是:当 SQL 出错时,你能定位是:
- QuerySpec 建错了(上游问题)
- 编译规则有 bug(本节点问题)
而不是像很多 Demo 一样,出了问题只能"再试一次"。
SQL 生成 Agent 的 System Prompt可以为:
bash
你是一个"只输出纯 MySQL SQL 的生成器",用于数据表 `announce_device_items_detail`。
你的输入永远是一个 JSON:QuerySpec。
你的输出必须是"可直接执行的 MySQL 8.0 SQL",且只输出 SQL,不允许任何解释、注释、标题、Markdown、代码围栏。
【表:announce_device_items_detail】
字段:
id, notice_id, title, publish_time, is_medical,
vendor_name, device_name, brand, manufacturer, model, department,
quantity, unit, unit_price, total_price, currency
【输入 QuerySpec 结构】
{
"intent": "detail|aggregate|trend|compare|topn|unknown",
"topic": "device|vendor|brand|department|price|amount|unknown",
"keywords": {
"device_name_like": [],
"brand_like": [],
"vendor_name_like": [],
"department_like": []
},
"time_range": {
"type": "relative|absolute",
"last_n_days": 365,
"start": null,
"end": null
},
"metrics": {
"need_unit_price": true,
"need_total_price": false,
"need_quantity": false,
"need_count": true,
"stat": ["avg", "max", "min"]
},
"filters": {
"is_medical": 1,
"unit_price_not_null": true,
"total_price_not_null": false
},
"group_by": [],
"order_by": [
{ "field": "publish_time", "direction": "desc" }
],
"limit": 50,
"notes": ""
}
【必须遵守的工程规则】
1) 输出只能是一条 SQL(允许 WITH,但最终仍是一条 SQL)
2) 必须包含 WHERE 约束,至少包含 `is_medical` 条件(若 QuerySpec.filters.is_medical 存在)
3) 必须包含 LIMIT(取 QuerySpec.limit;若缺失默认 50;最大不得超过 200)
4) 所有字段名必须用反引号包裹:`publish_time`
5) 字符串与日期用单引号:'2026-01-01 00:00:00'
6) 禁止生成 INSERT/UPDATE/DELETE/DROP/TRUNCATE/ALTER,只允许 SELECT
7) LIKE 条件:对 keywords 中的每个关键词生成 `field LIKE '%关键词%'`,同类关键词用 OR,不同字段之间用 AND
8) time_range:
- type=relative:用 `publish_time >= NOW() - INTERVAL <last_n_days> DAY`
- type=absolute:用 `publish_time >= '<start>' AND publish_time <= '<end>'`(start/end 若为空则只生成存在的那一边)
9) metrics:
- need_unit_price=true 且 stat 包含 avg/max/min:生成 AVG/MAX/MIN(`unit_price`) 等
- need_total_price=true:生成 SUM(`total_price`)
- need_count=true:生成 COUNT(1)
10) intent 对应输出形态:
- detail:输出明细字段(notice_id,title,publish_time,vendor_name,device_name,brand,manufacturer,model,department,quantity,unit,unit_price,total_price,currency)
- aggregate:输出聚合指标(按 group_by 分组则带 GROUP BY)
- topn:聚合后 ORDER BY 指标 DESC 并 LIMIT
- trend:按时间桶分组(按月:DATE_FORMAT(publish_time,'%Y-%m') as time_bucket)
- compare:至少拆成两个条件的对比(若 QuerySpec.keywords 同类出现 2 个以上,优先 compare)
- unknown:退化为 detail
【输出模板约束】
- detail:SELECT <fields> FROM `announce_device_items_detail` WHERE <conditions> ORDER BY `publish_time` DESC LIMIT <limit>;
- aggregate/topn/trend:优先使用别名,如 avg_unit_price, total_amount, cnt 现在开始:读取输入 QuerySpec,生成一条 SELECT SQL。
这份 prompt 的核心,是把"自由生成"变成"规则驱动生成"。
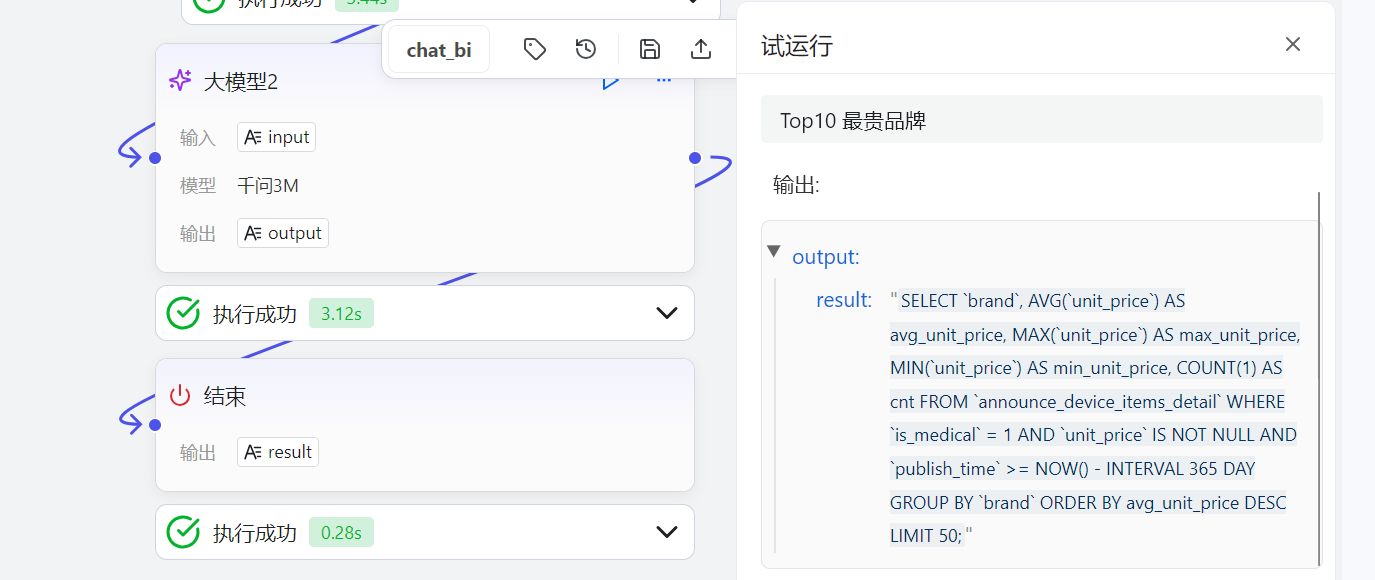
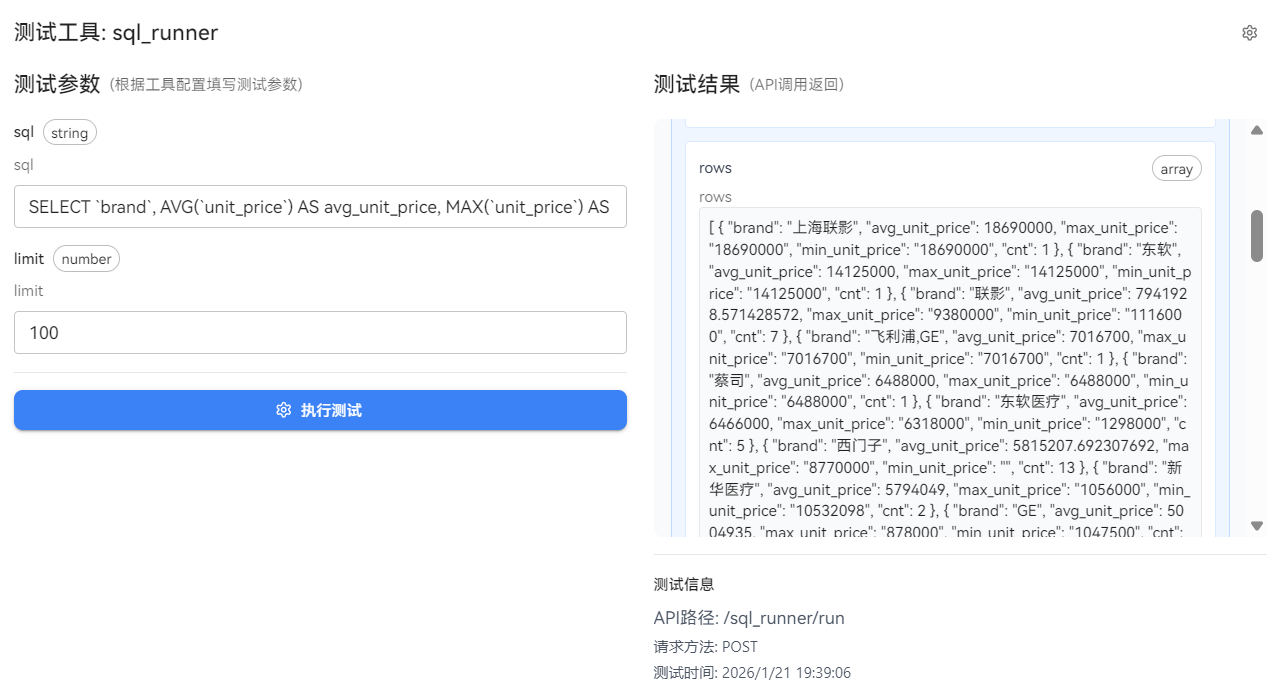
从截图可以看到,我们在 openJiuwen 的工作流画布中,已经把 SQL 生成 Agent 独立成一个可运行节点,并通过 Top10 最贵品牌 这个典型问数需求完成了一次完整推理。
最终节点输出的结果是一条可直接执行的 MySQL SQL:
json
{"output:":"SELECT `brand`, AVG(`unit_price`) AS avg_unit_price, MAX(`unit_price`) AS max_unit_price, MIN(`unit_price`) AS min_unit_price, COUNT(1) AS cnt FROM `announce_device_items_detail` WHERE `is_medical` = 1 AND `unit_price` IS NOT NULL AND `publish_time` >= NOW() - INTERVAL 365 DAY GROUP BY `brand` ORDER BY avg_unit_price DESC LIMIT 50;"},并且具备 ChatBI 生产环境里最关键的三类特征:聚合口径明确、过滤条件可控、结果规模可控。
3.5 第三个节点:SQL执行插件
插件开发就是精髓大家要尤其注意,这里我将详细为大家讲述智能体平台核心,也就是为什么我们要搭建本地化部署的智能体平台的核心功能,就是和我们本地服务器的特殊(私有化项目)端口功能进行联合使用。首先我们打开主界面,按照步骤点击:
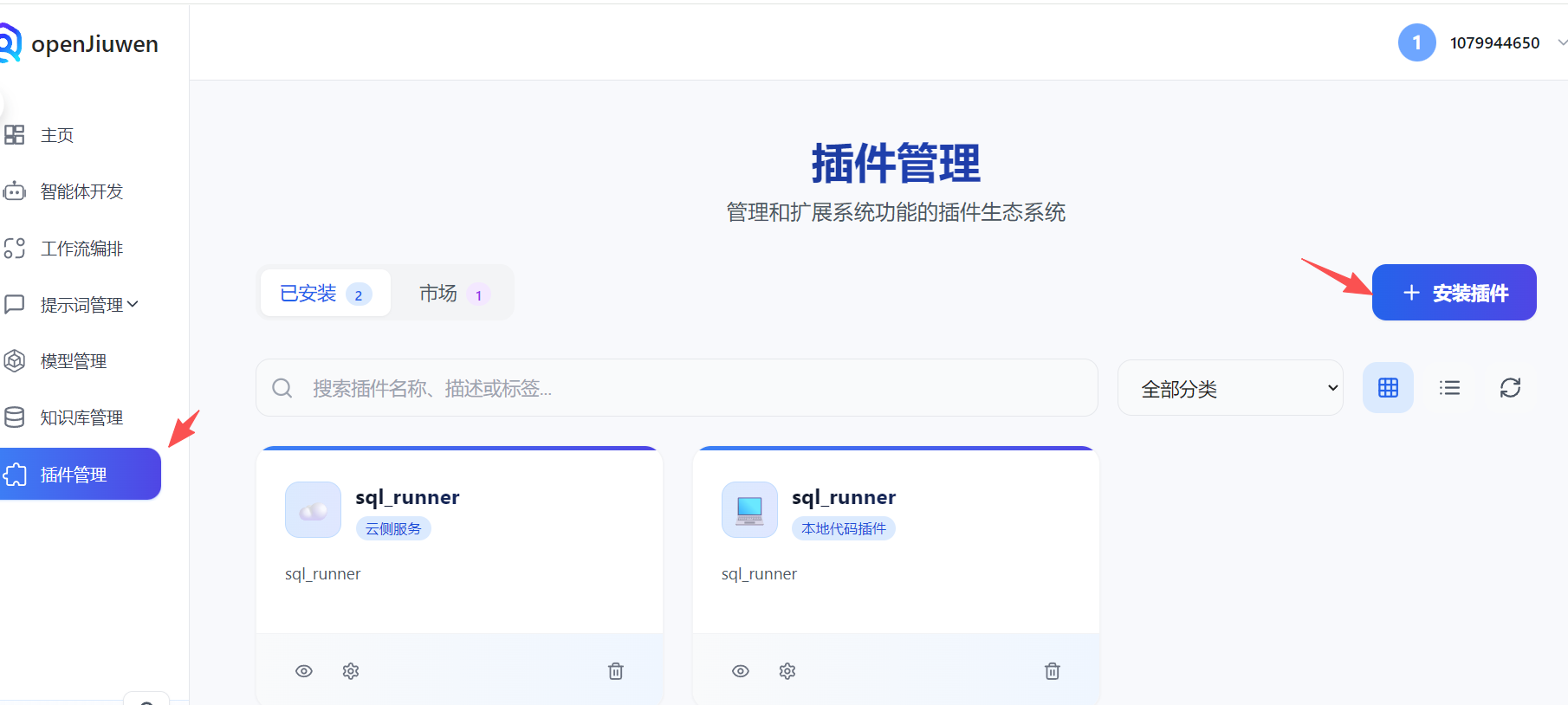
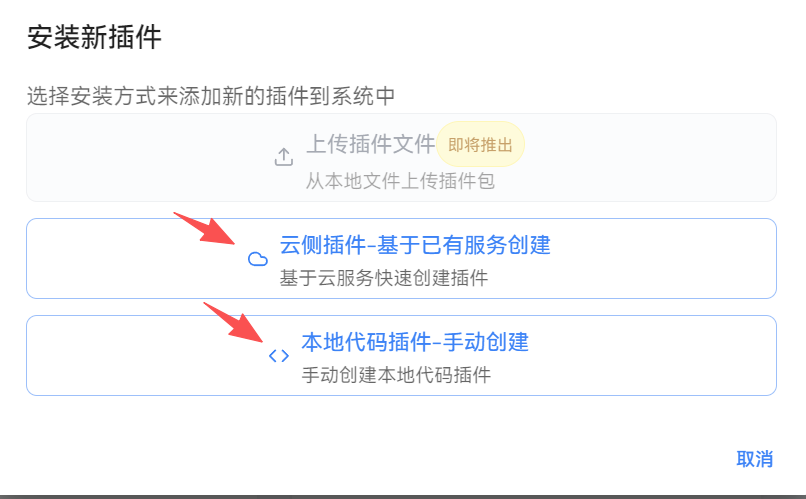
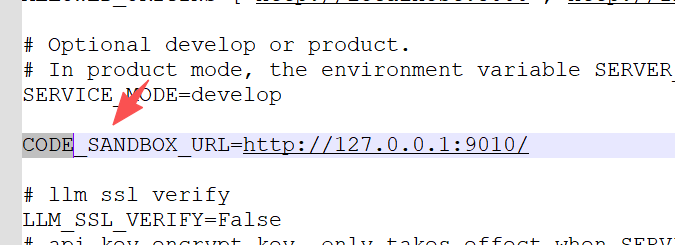
这边二者插件都可以创建,本地代码插件的运行逻辑是通过配置.env环境的变量:
然后将固定格式sandbox_server 收到的 body:
json
{
"language": "python",
"code": "......你的插件代码......",
"inputs": {"参数": "{"output:":{"result":"SELECT 1;"}}"},
"timeout": 30
}在 openJiuwen 的"本地插件(Python3)"里:
- openJiuwen 会 POST 到 CODE_SANDBOX_URL
- payload 固定是:language + code + inputs + timeout
懂了这个原理你就很好做本地化插件,比如我想做个运行SQL查询的插件,那你在本地插件,也就是code_sandbox_url发送的请求里面解析class:
json
class SandboxReq(BaseModel):
language: str = "python"
code: str
inputs: Dict[str, Any] = {}
timeout: int = 30把这个code拿出来然后运行,最后返回outputs即可。大家可能觉得本地化插件是比较冗余的,但是大家要思考这是作为中台使用,是面向客户的而不是我们智能体中台开发者的,如果公司其他人想要开发插件那么他上传这个代码就能直接部署到服务器本机,他也不用考虑开放一个api来调用了。
这里我们以云测插件来展示:
这里大家要注意clone仓库下来官网是附带过插件样例代码的:
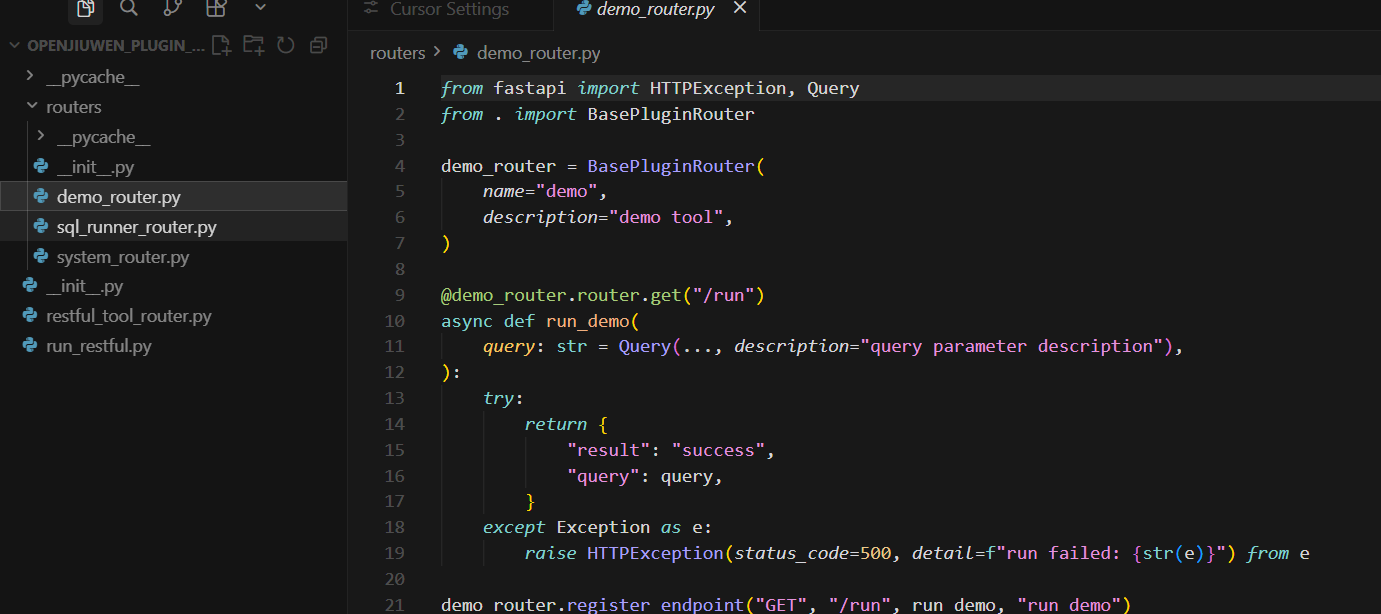
在这个路径openJiuwenagent-studioplugin_serveropenjiuwen_plugin_server,大家可以先跑通
demo_router.py这个插件:
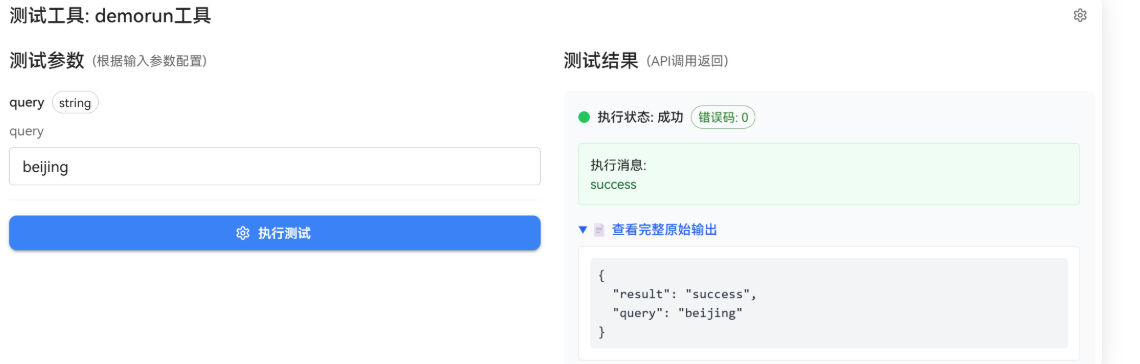
我这边演示sql接收运行插件:
主要配置我们基础的服务地址,也就是输入插件提供的服务地址,例如:https://api.example.com。
之后点开工具设置打开API工具列表:
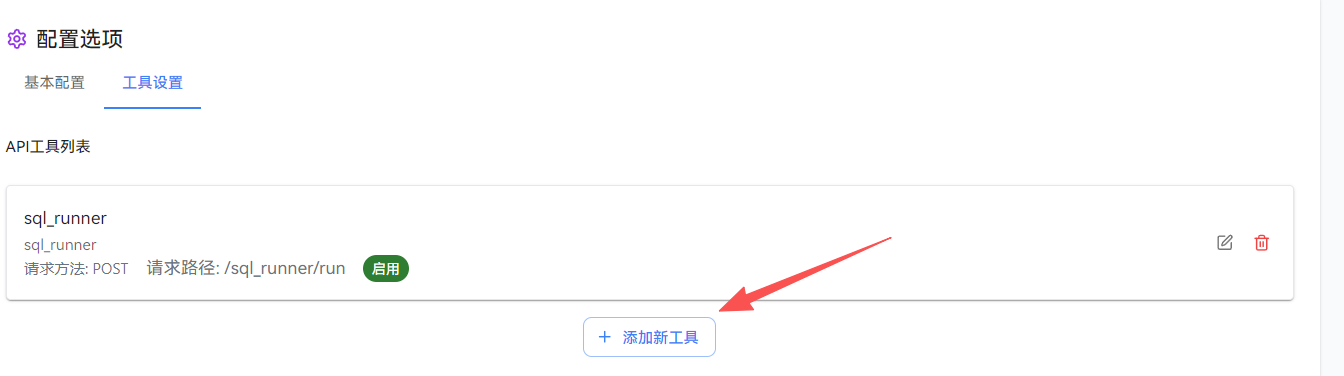
添加新的工具,之后我们根据我们的插件的模板开发相关接口的代码:
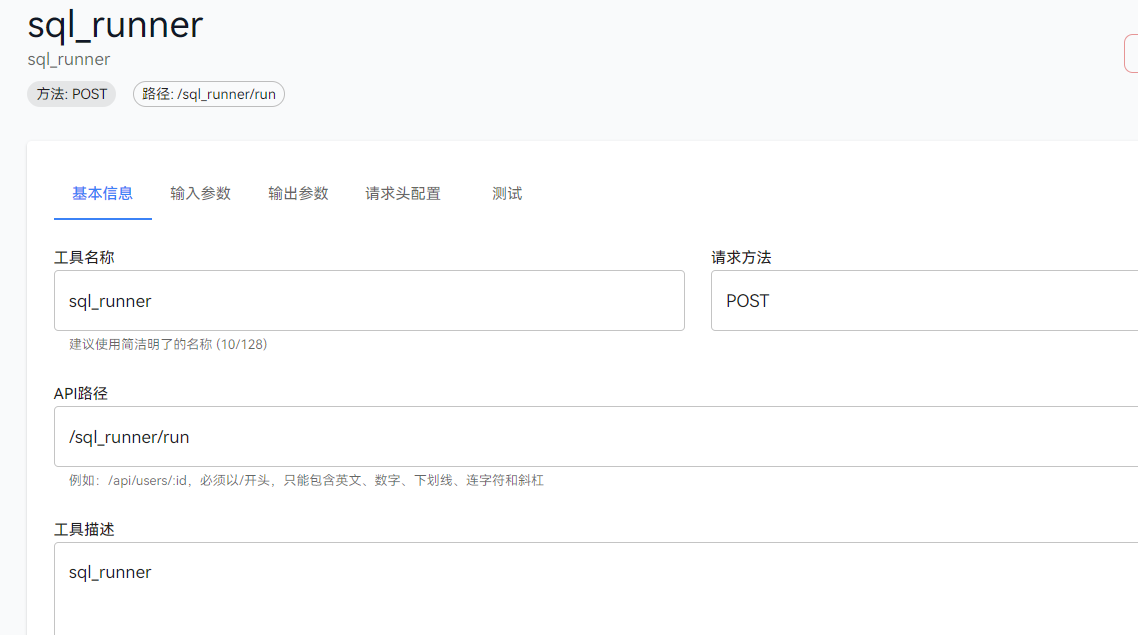
我推荐直接在项目自带的路径下面进行开发新的功能和routers
openJiuwenagent-studioplugin_serveropenjiuwen_plugin_serverrouters
在加入到对应的router里面,比如我这里开发了一个sql_runner_router,只需要写入在init里面加入
python
from .demo_router import demo_router # noqa: E402
from .sql_runner_router import sql_runner_router # noqa: E402
from .system_router import system_router # noqa: E402
ALL_ROUTERS = [
demo_router,
system_router,
sql_runner_router,
]即可。之后我们只需要定义响应的输入输出参数:

开始进行测试端口连通性,效果如下:
那么这个插件就已经开发完了,接下来进行工作流整个拼接:
3.6工作流搭建
接下来的工作就十分简单了只需要将我们每个节点进行拼接链入不同的输出输出参数即可完成这个工作流的搭建
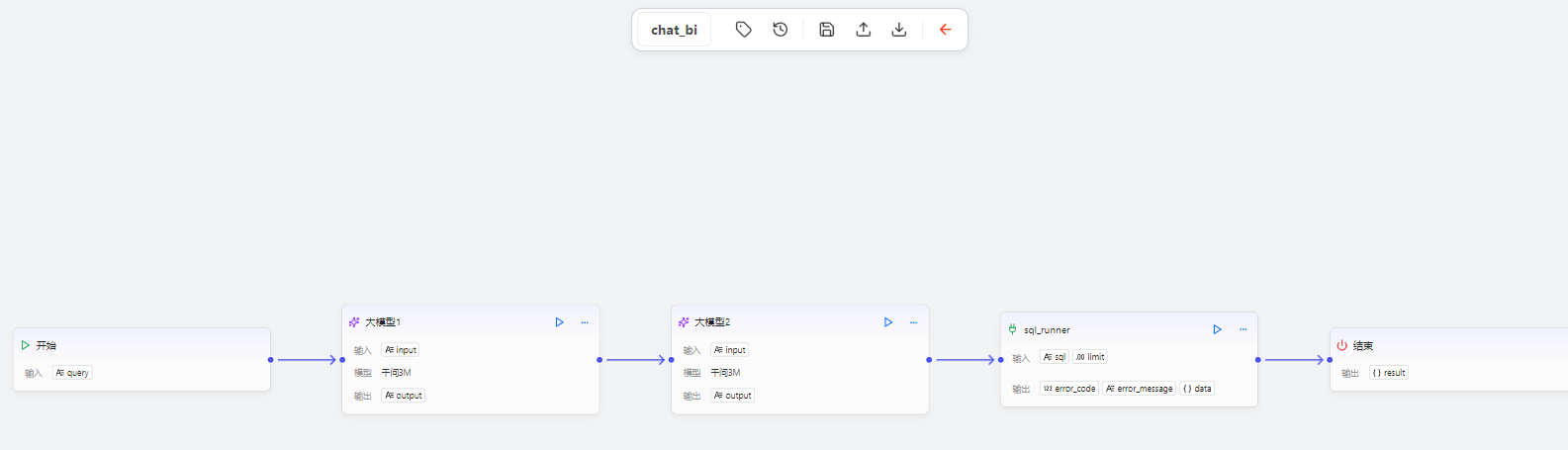
之后我们先测试节点的连通性:
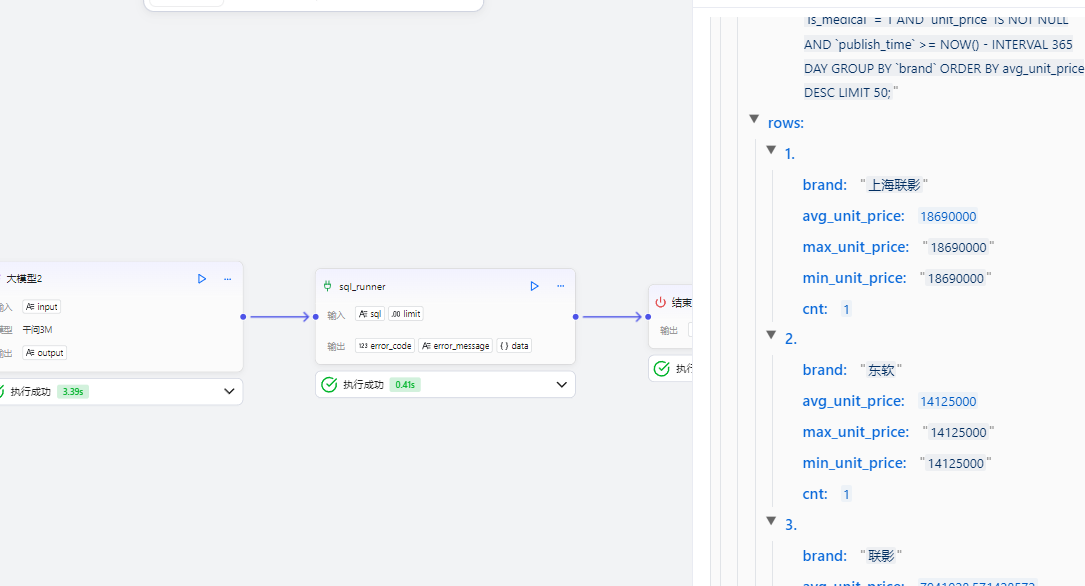
这样以来我们基础的一个数据智能分析工作流就基本搭建完成。
第 4 章|总结:把 ChatBI 从 Demo 变成系统,关键不是 NL2SQL,而是平台化
写到这里,其实我想先把一个容易被误解的点说清楚:这篇文章表面看是在讲 ChatBI,讲自然语言到 SQL,讲 openJiuwen 的工作流怎么连,但我真正想做的事情,从一开始就不是"让模型写出一条 SQL"这么简单。
因为只要你认真做过 NL2SQL,你就会知道:SQL 生成从来不是难点,难的是你敢不敢跑、跑完敢不敢给业务看、出了问题能不能兜住。模型能输出一条像模像样的 SELECT 并不稀奇,稀奇的是在企业环境里你还能保证它不乱扫表、不越权、不跑出一堆口径不一致的结果,更不会因为一次不稳定输出把线上数据库拖挂。
我先用意图解析把用户的模糊问题收敛成 QuerySpec,再让 SQL 生成 Agent 只看 QuerySpec,不再看用户原话。这个动作看起来像"多此一举",但做完你就会发现系统气质完全变了:你不再是在"求模型灵光一现",而是在用一个中间语言把需求固定下来,让后面的每一步都能被约束、被审计、被替换。很多 Demo 会把输入直接塞进 Prompt,然后祈祷模型输出干净 SQL;我反过来做,是因为我更在意工程确定性,而不是一次性的准确率。
当这条链路跑起来后,你会很明显地感受到一个变化:出了问题,你能定位问题在"意图层"还是"编译层",而不是像传统方式那样只剩一句"再试一次"。这对长期维护来说太关键了。一个能上线的 ChatBI,从来不是靠几条 Prompt 运气好撑起来的,它靠的是你能把不确定性拆散、隔离,然后把风险收束在固定边界里。
很多人做 Agent 系统,总觉得核心在模型,最后卡住却往往卡在工具接入:业务接口杂、网络环境复杂、权限口径一堆要求、还要和内网服务打通。openJiuwen 的插件机制给了我一个非常清晰的工程抓手------不管是本地代码插件通过 CODE_SANDBOX_URL 走固定的请求结构,还是 API 工具走统一注册方式,本质上都是把工具调用从"散落在脚本里的 if/else"提升为"平台级能力"。这件事一旦成立,openJiuwen 就不再只是一个能画工作流的东西,它开始像一个中台:你可以把公司内部的 SQL Runner、指标服务、权限校验、审计服务都接进来,让所有 Agent 复用同一套工具体系,而不是每个团队各写各的。
我在 Windows 本地部署这套东西的时候也踩了不少坑,尤其是前端依赖那一段:pnpm workspace、symlink、Vite 版本、Semi 的 ESM 导入、构建脚本跨平台......说实话,这些问题放在"纯演示"文章里可以略过,但我反而觉得写出来更真实。而且它也提醒了一个现实结论:Windows 本地更适合验证与学习,如果你要把它作为团队长期使用的平台,最终还是应该迁移到更标准的 Linux/Docker 形态,环境差异会小很多,后续治理也更稳。
最后照例打个卡------我写技术文章一直有个偏执:能讲清楚原理不算本事,能让读者复现出来、并且知道怎么扩展才算。
我是 Fanstuck,致力于将复杂的技术知识以易懂的方式传递给读者,热衷于分享最新的行业动向和技术趋势。
如果你对大模型的创新应用、AI 技术发展以及实际落地实践感兴趣,那么请关注 Fanstuck。