1. 数据窗口
上篇文章准备好了数据,本章介绍使用深度神经网络进行时间序列分析中的重要概念数据窗口。
1.1 数据窗口/滑动窗口的定义
在使用神经网络进行回归分析,如图像识别,输入是一系列像素点的RGB,对应输出结果为是否是某个图像。在数据序列分析中,输入和输出是同一个变量:输入是某段时间的数据值,比如某段时间内的PM2.5数值,对应输出的结果则是未来一段时间内的PM2.5数值。如何使用时间连续的数据进行训练呢?答案就是数据窗口:数据窗口(或称滑动窗口)是一种将连续时间序列数据转换为多个连续子样本的关键技术,目的是为了适应模型的输入要求并捕捉时间依赖性。简单说,就是用一个固定的"窗口"在时间轴上滑动,每次截取一段连续的历史数据作为输入特征,并用紧接着的下一个(或几个)时间点的数据作为预测目标。比如,输入1,2,3,预测输出为4。输入2,3,4,预测输出为5。这个过程就像是为模型准备了一本带有上下文的"习题集",每一道"题"(特征)都对应一个"标准答案"(标签),让模型学习从历史模式推断未来情况。
数据窗口有几个重要概念:
- 输入宽度input_width:每次用于预测的输入历史数据点数量,即训练数据。太小的窗口可能无法捕捉到长期趋势;太大的窗口则可能包含过多冗余噪声,并增加计算负担。
- 标签宽度label_width:相当于预测的时间步长数,即预测目标的宽度。如果仅预测一个时间步长,则标签宽度为1,如果预测一整天的数据(24小时),则标签宽度为24。
- 位移shift:是分离输入和预测的时间步长数,是从输入宽度结束时刻再向未来"前瞻"的时间距离。
- 窗口大小:total_width =input_width+shift。
- 标签起始位置:预测窗口的起始索引:label_start= total_width - label_width。
1.2 数据窗口举例
几个概念太过抽象,不容易理解。具几个例子。
- input_width=12, label_width=12, shift=12。 这意味着用过去12小时的数据来预测来预测未来12小时的数据。假设时间点index=0开始。
total_width= 12+12=24,即0-23小时的时长。
label_start= 12+12-12=12,即预测时间段为12-23小时。

- input_width=12,label_width=6,shift=12. 这意味着用过去12小时的数据,来预测未来第18小时到24小时的数据,而丢弃了中间6小时的数据没有使用。这种参数设置通常有特定目的,它要求模型不依赖最近的历史(被跳过的部分),而是直接根据较远的历史数据(前24小时)来预测一个相对遥远的未来(24小时后的12小时)。这对于测试或训练模型捕捉长期依赖关系和周期性规律(如每天的固定模式)非常有价值

- input_width=12, label_width=6,shift=1。这意味着使用过去1-12小时的数据来预测第7-13小时的数据。其中7-12小时的数据即作为模型输入,又作为模型输出。这可能导致严重的过拟合,泛化能力差。
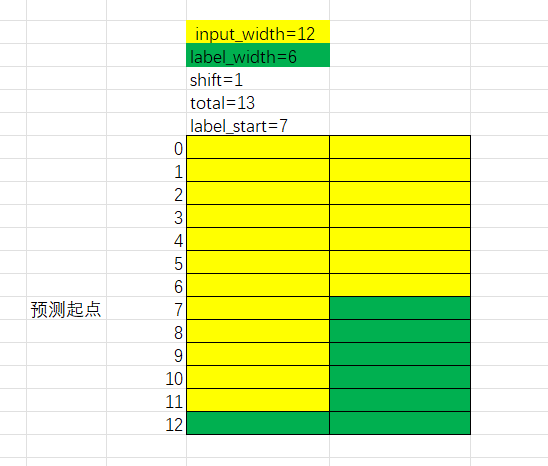
基于以上分析,我们常用的模式为单步预测和多步预测。
单步预测:即使用过去一段时间的数据来预测未来1点的数据,如input_width=12,label_width=1,shift=1.
多步预测:即使用过去一段时间的数据来预测紧接着的未来一段时间的数据,如input_width=12,label_width=12,shift=12.
2. 构建数据窗口类
构建数据窗口类,为未来使用多种深度学习模型进行单步和多步预测打下基础。
2.1 tensorflow中的重要函数
首先介绍一个专门用于从时间序列数据自动生成滑动窗口数据集的实用函数tf.keras.preprocessing.timeseries_dataset_from_array()。
python
tf.keras.preprocessing.timeseries_dataset_from_array(
data, # 包含连续时间序列数据点的numpy array 或 eager 张量。 axis 0 作为时间维度。多为时间序列数据形状为(1000,5)的数组,表示1000个时间步和5个特征。
targets, # 对应于data中每个时间步的目标值(label).可以是未来预测值或与data相关的其他标签。None表示只生成输入数据。
sequence_length, #每个输出序列(滑动窗口)的长度。
sequence_stride=1,#连续输出序列之间的间隔(步长)。 设置为1表示窗口每次滑动1步,最大化样本数。如总数据集为[1,2,3,4,5]。 划分为窗口大小为3的窗口为:窗口1:[1,2,3],窗口2:[2,3,4],窗口3:[3,4,5]。设置为sequence_length,则表示窗口互不重叠。
sampling_rate=1,# 设置为1表示使用每个时间步;设置为2,则每隔1个点取样一次,进行下采样。
batch_size=128, # 每个批次中包含的序列样本数。=128即128个窗口作为一个批次。
shuffle=False,#是否打乱窗口之间的顺序。比如按时间顺序为窗口1,窗口2,窗口3.打乱后可能是窗口1,窗口3,窗口2.打乱顺序可以使模型泛化能力更好。
seed=None, # 当shuffle=true时,用于控制随机打乱的随机数种子。设置固定值,如42,可以保证每次运行代码时,数据打乱顺序完全相同,可用于复现实验结果。
start_index=None, # 定义从数据的那个索引开始才创建序列
end_index=None # 定义从数据的那个索引开始停止序列
)2.2 定义数据窗口类
python
class DataWindow():
def __init__(self, input_width, label_width, shift,
train_df=train_df, val_df=val_df, test_df=test_df,
label_columns=None):
self.train_df = train_df
self.val_df = val_df
self.test_df = test_df
self.label_columns = label_columns
if label_columns is not None:
self.label_columns_indices = {name: i for i, name in enumerate(label_columns)} # 为预测目标列label建立字典(0,'PM2.5'),(1,'PM10')
self.column_indices = {name: i for i, name in enumerate(train_df.columns)} # 为数据集中所有列创建idex:name字典
self.input_width = input_width
self.label_width = label_width
self.shift = shift
self.total_window_size = input_width + shift
self.input_slice = slice(0, input_width) # 定义如何从数据窗口中切出输入部分
self.input_indices = np.arange(self.total_window_size)[self.input_slice] # 输入部分在窗口总的具体索引
self.label_start = self.total_window_size - self.label_width
self.labels_slice = slice(self.label_start, None) # 定义如何从窗口中切出标签部分
self.label_indices = np.arange(self.total_window_size)[self.labels_slice] # 标签部分的具体索引
def split_to_inputs_labels(self, features):
inputs = features[:, self.input_slice, :] # 数据形状为[batch_size, input_width,featrue_nums]. 从features取出input_width个时间步作为模型输入
labels = features[:, self.labels_slice, :] # 从features中取出label_width个时间步作为预测目标
if self.label_columns is not None: # 从所有label列中取出需要预测的特征列,stack函数沿着新的维度(axis=-1)将这些列堆叠起来,形成一个新的labels张量。
labels = tf.stack(
[labels[:,:,self.column_indices[name]] for name in self.label_columns],
axis=-1
)
inputs.set_shape([None, self.input_width, None])
labels.set_shape([None, self.label_width, None])
return inputs, labels
def plot(self, model=None, plot_col='traffic_volume', max_subplots=3):
inputs, labels = self.sample_batch # 从数据窗口中获取一个批次的输入和标签数据
plt.figure(figsize=(12, 8))
plot_col_index = self.column_indices[plot_col] # 可视化数据的索引
max_n = min(max_subplots, len(inputs)) # 从3,32中取最小值,绘制3个子图
for n in range(max_n):
plt.subplot(3, 1, n+1)
plt.ylabel(f'{plot_col} [scaled]')
plt.plot(self.input_indices, inputs[n, :, plot_col_index],
label='Inputs', marker='.', zorder=-10)
if self.label_columns:
label_col_index = self.label_columns_indices.get(plot_col, None)
else:
label_col_index = plot_col_index
if label_col_index is None:
continue
plt.scatter(self.label_indices, labels[n, :, label_col_index],
edgecolors='k', marker='s', label='Labels', c='green', s=64)
if model is not None:
predictions = model(inputs)
plt.scatter(self.label_indices, predictions[n, :, label_col_index],
marker='X', edgecolors='k', label='Predictions',
c='red', s=64)
if n == 0:
plt.legend()
plt.xlabel('Time (h)')
def make_dataset(self, data):
data = np.array(data, dtype=np.float32)
ds = tf.keras.preprocessing.timeseries_dataset_from_array(
data=data,
targets=None,
sequence_length=self.total_window_size,
sequence_stride=1,
shuffle=True,
batch_size=32
)
ds = ds.map(self.split_to_inputs_labels) # 将data数据集自动切分成[32,sequence_length,n_features]的数据元素 作为ds中每个元素。即将每个元素(32个窗口)逐次传入split_to_inputs_labels,切分成对应的(input,label)元组进行训练。map保证了每个窗口的input和label的对应关系。每个窗口作为训练的一个样本
return ds # ds数据集可以理解为[(inputs_batch1,labels_batch1),(inputs_batch2,labels_batch2),...]
@property
def train(self): # 设置训练集
return self.make_dataset(self.train_df)
@property
def val(self): # 设置验证集
return self.make_dataset(self.val_df)
@property
def test(self): # 设置测试集
return self.make_dataset(self.test_df)
@property
def sample_batch(self): # 获取一个批次的数据
result = getattr(self, '_sample_batch', None)
if result is None:
result = next(iter(self.train))
self._sample_batch = result
return result3. 创建基线模型
3.1 单步基线模型
- 单步模型类。首先实现一个单步模型作为基线。在单步模型中,输入一个时间步长,输出下一个时间步长的预测。在这种情况下,下一个时间步长的预测值即是上一个时间步长的值。
python
from tensorflow.keras import Model, Sequential
# 继承自tf.keras.Model类,并重写call函数。 在后面evaluate评估时,看到会传入datawindow的train,val,test数据集。
class Baseline(Model):
def __init__(self, label_index=None):
super().__init__()
self.label_index = label_index
def call(self, inputs): # inputs在model.evaluate调用时,会自动i将train,val中的数据集(在Datawindow类的 def val()中定义 .所以,没一个批次,框架将自动将inputs_batch作为输入,数据形状为[batch_size, input_width,num_features] .
if self.label_index is None: # 如果没有制定目标,则返回所有列
print('inputs:')
print(inputs)
return inputs
elif isinstance(self.label_index, list): # 如果指定了多个目标列表,则只返回多个目标,用于多输出模型
tensors = []
for index in self.label_index:
result = inputs[:, :, index] #如果是单步预测,input,label,shift都=1. 则inputs为[32,1,1]. 即 返回上一步的结果 。 result为[batch_size,1]的二维数组 。
result = result[:, :, tf.newaxis] #增加维度,由二维变三维张量
tensors.append(result)
return tf.concat(tensors, axis=-1) # 沿着特征维度拼接形成一个新张量
result = inputs[:, :, self.label_index]
return result[:,:,tf.newaxis]这里面比较复杂,尤其是call函数返回的数据形状,举例说明:
假设你的模型参数和输入数据如下:
batch_size = 32(一个批次有32个样本)
time_steps = 24(每个样本有24个时间步)
原始 inputs张量形状为 (32, 24, 5)(即共有5个特征列)
self.label_index = 0, 2(你希望提取第1个和第3个特征列)。 则:
执行result = inputs:, :, index 后, 针对index=0和index=2,形状都变为(32,24);
执行 result = result:, :, tf.newaxis,形状都变为(32,24,1)
执行 tensors.append(result),将处理后的第1个特征张量加入列表,将处理后的第3个特征张量加入列表
执行tf.concat(tensors, axis=-1),变为(32,24,2)的形状
- 预测并评估
python
single_step_window = DataWindow(input_width=1, label_width=1, shift=1, label_columns=['traffic_volume']) # 单步预测窗口
wide_window = DataWindow(input_width=24, label_width=24, shift=1, label_columns=['traffic_volume']) # 多步观察绘图窗口
column_indices = {name: i for i, name in enumerate(train_df.columns)} # 创建列名到索引的映射
baseline_last = Baseline(label_index=column_indices['traffic_volume'])
baseline_last.compile(loss=MeanSquaredError(), metrics=[MeanAbsoluteError()]) # 配置模型的损失函数为均方差MSE,评估指标为平均绝对值误差MAE
val_performance = {}
performance = {}
val_performance['Baseline - Last'] = baseline_last.evaluate(single_step_window.val) # 自动遍历数据集,计算损失和指标。verbose=0用于关闭评估过程的日志输出
performance['Baseline - Last'] = baseline_last.evaluate(single_step_window.test, verbose=0)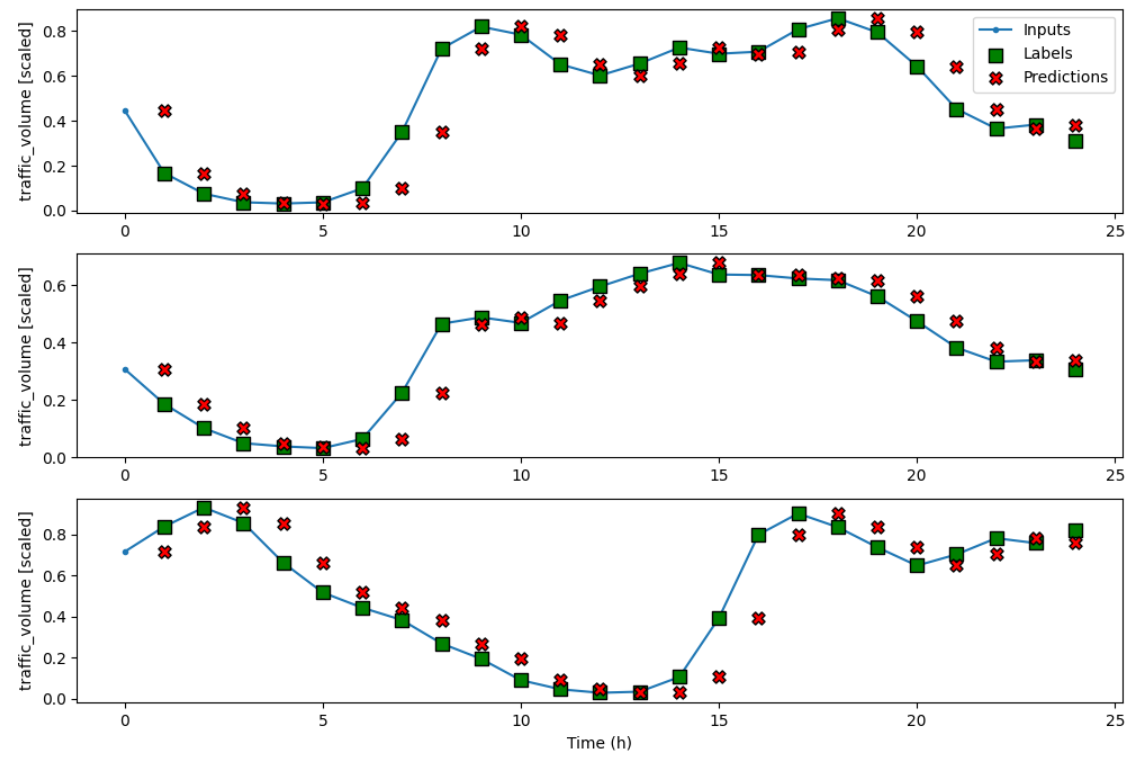
3.2 多步基线模型
使用多步基线模型预测未来24小时的交通流量。我们假设有两个多步模型作为基线。
3.2.1 使用最后一个已知值作为预测值
python
# 多步预测类
class MultiStepLastBaseline(Model):
def __init__(self, label_index=None):
super().__init__()
self.label_index = label_index
def call(self, inputs):
if self.label_index is None:
return tf.tile(inputs[:, -1:, :], [1, 24, 1]) #inputs[:,-1:,:],表示选择inputs中最后一个时间步的值。 tf.tile(...,[1,24,1])是平铺(复制)操作。该函数根据multiples参数制定的次数在各维度上复制输入张量。 multiples=[1,24,1],表示 在批次维度(0维)上复制1次。在时间维度(1维)上复制24次。 在特征维度(2维)复制1次。
return tf.tile(inputs[:, -1:, self.label_index:], [1, 24, 1]) # inputs[:,-1:,self.label_index:] 使用了切片语法,表示选取从索引label_index开始到末尾的所有特征。通常用于预测多个特征列。 与[:,-1:,self.label_index]的区别是前者通过切片保持维度不变,而后者会降维。
# 创建多步窗口,用过去24小时数据,预测接下来的24小时数据
multi_window = DataWindow(input_width=24, label_width=24, shift=24, label_columns=['traffic_volume'])
ms_baseline_last = MultiStepLastBaseline(label_index=column_indices['traffic_volume'])
ms_baseline_last.compile(loss=MeanSquaredError(), metrics=[MeanAbsoluteError()])
ms_val_performance = {}
ms_performance = {}
ms_val_performance['Baseline - Last'] = ms_baseline_last.evaluate(multi_window.val)
ms_performance['Baseline - Last'] = ms_baseline_last.evaluate(multi_window.test, verbose=0)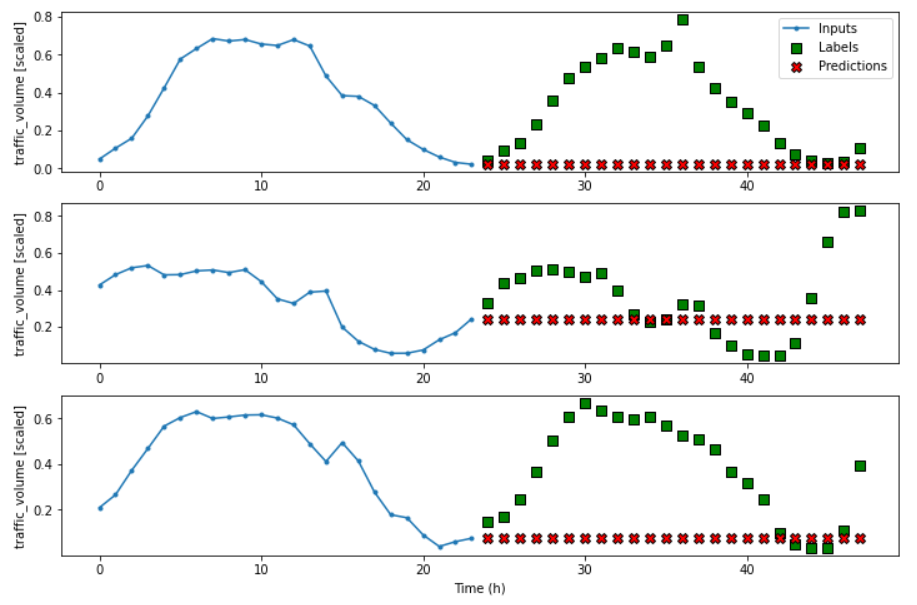
3.2.2使用最后已知的24小时值预测未来24小时值
python
class RepeatBaseline(Model):
def __init__(self, label_index=None):
super().__init__()
self.label_index = label_index
def call(self, inputs):
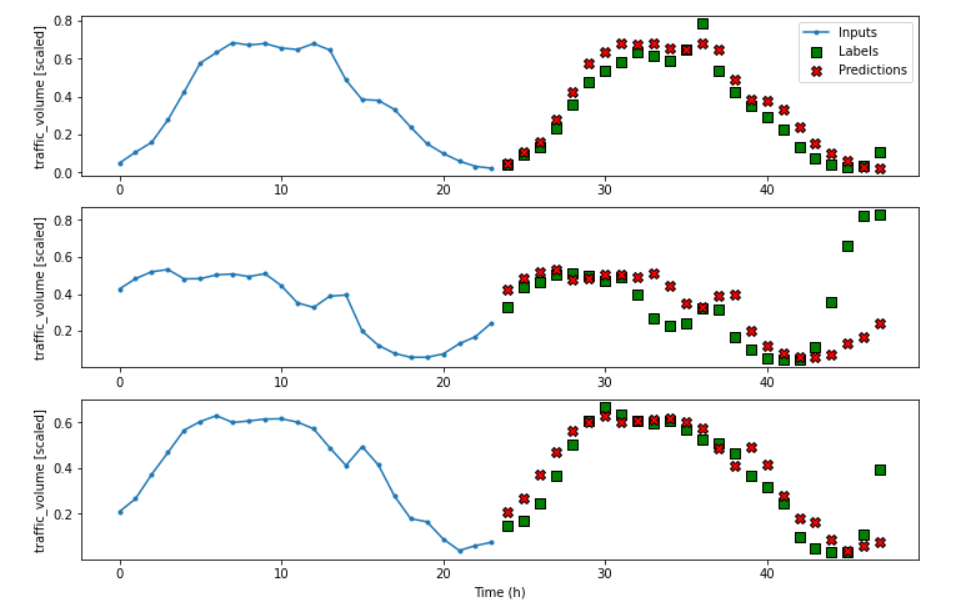
return inputs[:, :, self.label_index:] # 返回inputs所有批次样本的所有时间步
ms_baseline_repeat = RepeatBaseline(label_index=column_indices['traffic_volume'])
ms_baseline_repeat.compile(loss=MeanSquaredError(), metrics=[MeanAbsoluteError()])
ms_val_performance['Baseline - Repeat'] = ms_baseline_repeat.evaluate(multi_window.val)
ms_performance['Baseline - Repeat'] = ms_baseline_repeat.evaluate(multi_window.test, verbose=0)
multi_window.plot(ms_baseline_repeat)结果可以看到,24小时的值完全复制了之前24小时的值
4. 代码获取
本案例的全部代码,数据集和注释都在我的闲鱼小店,有需要的可以看看。
https://m.tb.cn/h.7tmEyDw?tk=8tP6UQ4jlsI tG-#22>lD