介绍一下什么是索引?
拿书举例,索引相当于目录
计算机科学方面,类比可以得出索引是帮助 mysql 高效获取数据的数据结构
mysql 的 InnoDB 存储引擎主要使用的是 B+树 数据结构作为索引
构建出属于表的索引书,走索引查询,可以减少磁盘 I/O 次数,加快查询次数
MySQL都有哪些索引?索引类型?(聚集索引和二级索引)
按数据结构分:
InnoDb 存储引擎主要使用的是 B+树索引,少数情况(比如说大量等值查询)下 InnoDb 会创建自适应 hash 索引
按物理存储类型分:
聚集索引,非聚集索引(二级索引),聚集索引叶子节点存储的是整行数据,一张表只能有一个
如果非聚集索引拿不到数据,也就是无法形成覆盖索引,那就需要拿着非聚集索引的叶子节点的主键信息取聚集索引里面回表查询
举一个项目中的例子,使用MySQL做的查询,依据什么去做的查询?
sql 语句前半部分:要查询出哪些信息
sql 语句后半部分:依据字段,索引信息,先 where 再 order by
实习的时候处理工单,根据用户问题去数据库里用 mysql 查询信息
主要是根据订单号去(order_no 全局唯一)查询,这个订单号肯定是有索引的
然后联表作进一步处理
还是基于这个订单号,满足最左前缀,避免失效
查多了的时候可以用 explain 看一下查询全表覆盖率,走索引情况等,多了解
比如说商品信息,价格
联合索引是(category_id,price),那查询的时候先定分类在按照价格排序
有遇到过一些慢查询的场景吗?知道什么是慢查询吗?
慢查询就是 sql 执行时间超过一个定义的 long_query_time 默认是 10 秒
没走索引,查询数据量过大,笛卡尔积过大导致扫行过多,select * 返回数据量太大
explain关键字你通常会关注哪些输出信息作为判断。
type:查询类型。从好到坏:system > const > eq_ref > ref > range > index > ALL。一般要求达到 ref 或 range 级别,绝对不能是 ALL(全表扫描)。
key:实际使用的索引。如果是 NULL 说明没用索引。
rows:预计扫描的行数,越少越好。
Extra:关注一些额外字段
Using index(好,覆盖索引,不需要回表)。
Using filesort(坏,需要外部排序)。
Using temporary(坏,用了临时表)。
有遇到过选错索引的情况吗?有别的索引失效的场景吗?
未满足最左前缀
想一下 B+树结构 ,非叶子节点呈折半查找,叶子节点呈已排序好的链表
模、型、数、空
模糊查询问题 like %%
类型转换问题 字符串不加引号
数学函数运算
有的条件没有索引,如 OR 连接条件中某个字段没索引
介绍一下MySQL的事务的隔离级别。
读未提交
读已经提交
可重复读
幻读
幻读是一个什么样的场景?
幻读场景:事务A先读取所有 age>10 的人(共5个),事务B插入了一个 age=15 的人并提交。事务A再次读取,发现变成了6个。像产生了幻觉一样。重点是"多出来或少了一行数据"。
可重复读的隔离级别可以解决幻读,那他底层是怎么解决幻读的呢?
快照读 (普通 Select):通过 MVCC (多版本并发控制) 解决。读取事务开始时的快照版本,而不会统计未来事务生成的数据。
当前读 (Select for update, Insert, Update):快照读的时候不能解决修改问题,因为不能去修改历史快照,通过 Next-Key Lock (临键锁) 解决。锁住记录本身+间隙,防止别的事务插入数据。
你项目中用到的是哪个隔离级别,为什么这么选择?
我使用的是默认的不可重复读
保证数据一致性,防止脏读、不可重复读,且MySQL对RR优化得很好。
如果现在让你选择一个隔离级别,你会参考哪些条件去选择隔离级别?
有些互联网大厂(如阿里)会改成 RC (Read Committed)。理由是:RC 的锁粒度更小(只有行锁,没有间隙锁),并发度更高,且死锁概率低。为了解决主从复制数据不一致问题,需要将 binlog 格式设置为 ROW。
介绍一下单例模式。
保证一个类只有一个实例,并且提供全局访问点
第一次判断:如果已经有实例了,直接返回,避免不必要的同步,提升性能。
第二次判断:防止并发创建。假设A和B同时通过了第一次判断,A抢到了锁创建了对象,A释放锁。B拿到锁进入同步块,如果不判断,B会再创建一个对象,单例就破了。
手写一下单例模式,说明主要步骤即可。
判断单例是否为空
抢锁,上锁
判断单例是否为空
创建单例
public class Singleton {
// volatile 禁止指令重排序,防止拿到半初始化对象
private static volatile Singleton instance;
private Singleton() {} // 私有构造
public static Singleton getInstance() {
if (instance == null) { // 第一次检查
synchronized (Singleton.class) {
if (instance == null) { // 第二次检查
instance = new Singleton();
}
}
}
return instance;
}
}说到Bean的两种状态,单例和非单例,那么这两种方式对比一下?
Singleton (默认):IOC容器启动时创建,整个应用生命周期只有一个。优点:节省内存,减少GC。缺点:有线程安全问题(如果有状态的话)。
Prototype:每次获取Bean都创建一个新对象。
单例适合哪些场景?一般什么类需要去做一个单例?
什么类做单例:无状态的类(Service, Dao, Util),配置类。
线程安全:单例本身不安全,但因为Service/Dao通常没有成员变量(状态),所以使用起来是安全的。
写一个线程安全的单例模式的伪代码;为什么要判断两次是否为空呢?
-
判断单例是否为空
-
抢锁,上锁
-
判断单例是否为空
-
创建单例
public class Singleton {
// volatile 禁止指令重排序,防止拿到半初始化对象
private static volatile Singleton instance;
private Singleton() {} // 私有构造public static Singleton getInstance() { if (instance == null) { // 第一次检查 synchronized (Singleton.class) { if (instance == null) { // 第二次检查 instance = new Singleton(); } } } return instance; }}
线程 B 可能在 线程 A 释放锁后线程 B 可能在步骤 1,2 之间,直接拿到锁创建~
商户缓存,介绍一下场景,要缓存哪些信息?
场景方面:商户详情页、店铺信息,这是读多写少的场景。
内容方面:商户的基础信息(名字、地址、评分)、热门商品列表。
介绍缓存穿透、缓存雪崩、缓存击穿。
击穿:热点Key过期,大量并发请求瞬间击穿Redis打到DB。解法:互斥锁(setnx)、逻辑过期(永不过期,后台异步更新)。
穿透:查不存在的数据(Redis没,DB也没),请求直打DB。解法:布隆过滤器、缓存空对象。
雪崩:大量Key同时过期 或 Redis宕机。解法:过期时间加随机值、Redis集群高可用。
电商项目优惠卷秒杀,优惠券存在哪里?
存在哪里:Redis的 String (存库存) 和 Set (存已购买用户ID,去重)。
流程:Lua脚本保证原子性(扣减库存+判断用户是否买过)。
秒杀优化的阻塞队列是通过什么实现的?
面试官可能问的是你代码里的 BlockingQueue。
实现:Java内存中的队列。
为什么用:实现异步下单。秒杀瞬间只要Redis扣库成功就返回"抢购中",后台线程慢慢从队列取任务去写数据库。削峰填谷。
不足/优化:内存队列断电会丢数据,且容量有限。生产环境应该用 RabbitMQ / Kafka。它们支持持久化、确认机制、高吞吐。
异步下单场景,那你怎么通知用户下单成功?(直接成功,并且指出不足,说出有思考下单失败应该怎么办)
直接方案:前端轮询(Polling)后端接口查询状态。
失败怎么办:
如果是DB写失败(概率小),需要补偿机制(重试)。
如果彻底失败,需要回滚Redis库存(增加库存,移除用户记录),并通知用户"下单失败"。
介绍一下点赞排行是个什么功能?为什么使用zset呢?(面试官好像不理解为什么要使用zset)
用 zset 是为了排序,zset 是排序的 key 可以排序的 hashmap
实现完全是为了简单,只要 redis 的 zset 就能实现。
了解过zset的底层实现吗?(跳表)如果往zset中添加一个元素,这个过程是怎么样的?
跳表 一种加了索引的链表,并没有红黑树复杂
结构:一种多层的链表。最底层包含所有元素,上面每一层都是下面一层的索引。
添加过程:
找到插入位置(类似二分查找的路径)。
插入底层链表。
随机抛硬币决定该节点是否提拔到上一层索引。层层往上,直到不提拔。
为什么不用红黑树:跳表实现简单,范围查询(Range)效率比红黑树高(红黑树需要中序遍历,跳表直接链表往后走)。
feed流实现关注推送,关注推送功能是怎么实现的?(推模式)
发布订阅模型
推模式 (Push / 写扩散):
实现:大V发微博,直接写到所有粉丝的收件箱(Redis List/ZSet)。
优点:粉丝读取快,拿出来就是做好的时间线。
缺点:大V粉丝千万级,发一条要写千万次,写入延迟极高。
有了解过拉模式吗?对比一下推拉模式有哪些优缺点?
模式 (Pull / 读扩散):
实现:大V只发到自己的发件箱。粉丝看Feed时,临时去关注的人的发件箱里拉取并排序。
优点:写入极快。
缺点:粉丝关注的人多时,聚合查询慢。
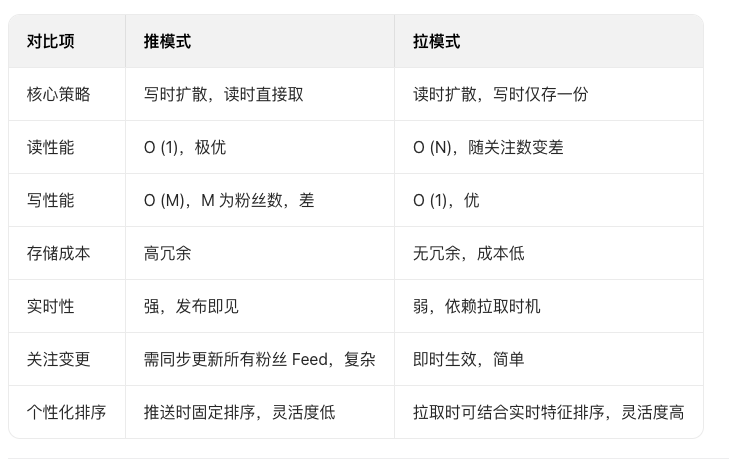
讲一下推拉模式该怎么选择
普通用户用推模式:粉丝少,写扩散成本可控,保证读性能与实时性。
头部大 V 用拉模式:避免写风暴,用户刷新时实时拉取大 V 最新内容。
新用户冷启动:先用拉模式获取历史内容,积累行为后切换到推模式。
热点内容特殊处理:热点内容先推至活跃用户,长尾用户拉取,兼顾实时性与成本。
读写分离:推模式用 Redis 存个人 Feed,拉模式用 MySQL+ES 存发布者内容池。
缓存策略:推模式缓存个人 Feed 队列;拉模式缓存关注列表与发布者最新内容切片。
限流熔断:对大 V 写扩散做 QPS 限制,读扩散时设置超时与降级(如返回部分内容)。
算法手撕:(定时20min)带TTL的LRU
LRU的核心是:HashMap + 双向链表。Map存Key-Node,链表维护顺序(最近用的在头,最久没用的在尾)。
带TTL(过期时间):需要在 Node 类中增加 expireTime 字段。
惰性删除:不开启线程定时删,而是每次 get(key) 时,判断当前时间是否超过 expireTime。如果过期,视为不存在,执行删除逻辑。
import java.util.HashMap;
import java.util.Map;
class LRUCacheWithTTL {
// 双向链表节点
class Node {
int key, value;
long expireTime; // 过期时间戳
Node prev, next;
public Node(int k, int v, long ttl) {
this.key = k;
this.value = v;
// 计算绝对过期时间
this.expireTime = System.currentTimeMillis() + ttl;
}
}
private int capacity;
private Map<Integer, Node> map;
private Node head, tail; // 虚拟头尾节点
public LRUCacheWithTTL(int capacity) {
this.capacity = capacity;
this.map = new HashMap<>();
head = new Node(-1, -1, 0);
tail = new Node(-1, -1, 0);
head.next = tail;
tail.prev = head;
}
// 获取数据
public int get(int key) {
if (!map.containsKey(key)) {
return -1;
}
Node node = map.get(key);
// 核心:判断过期
if (System.currentTimeMillis() > node.expireTime) {
removeNode(node);
map.remove(key);
return -1; // 已过期
}
// 没过期,移动到头部
moveToHead(node);
return node.value;
}
// 存入数据
public void put(int key, int value, long ttl) {
if (map.containsKey(key)) {
Node node = map.get(key);
node.value = value;
node.expireTime = System.currentTimeMillis() + ttl; // 更新过期时间
moveToHead(node);
} else {
Node newNode = new Node(key, value, ttl);
map.put(key, newNode);
addToHead(newNode);
if (map.size() > capacity) {
Node last = tail.prev;
removeNode(last);
map.remove(last.key);
}
}
}
// 辅助方法:移动到头部
private void moveToHead(Node node) {
removeNode(node);
addToHead(node);
}
// 辅助方法:添加到头部
private void addToHead(Node node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
// 辅助方法:移除节点
private void removeNode(Node node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
}