目录
[(1)Seq2Seq(Sequence to Sequence)模型](#(1)Seq2Seq(Sequence to Sequence)模型)
[(2)image to sequence模型](#(2)image to sequence模型)
[2.条件语言模型 -> 选择最可能的句子](#2.条件语言模型 -> 选择最可能的句子)
1.编码-解码模型
(1)Seq2Seq(Sequence to Sequence)模型
- Seq2Seq模型是一种深度学习架构,主要用于将一个序列映射到另一个序列 ,在自然语言处理领域应用广泛。其核心思想是通过编码器-解码器结构,将输入序列(如一句话)编码为一个固定长度的向量,再由解码器根据该向量生成目标序列(如翻译结果)
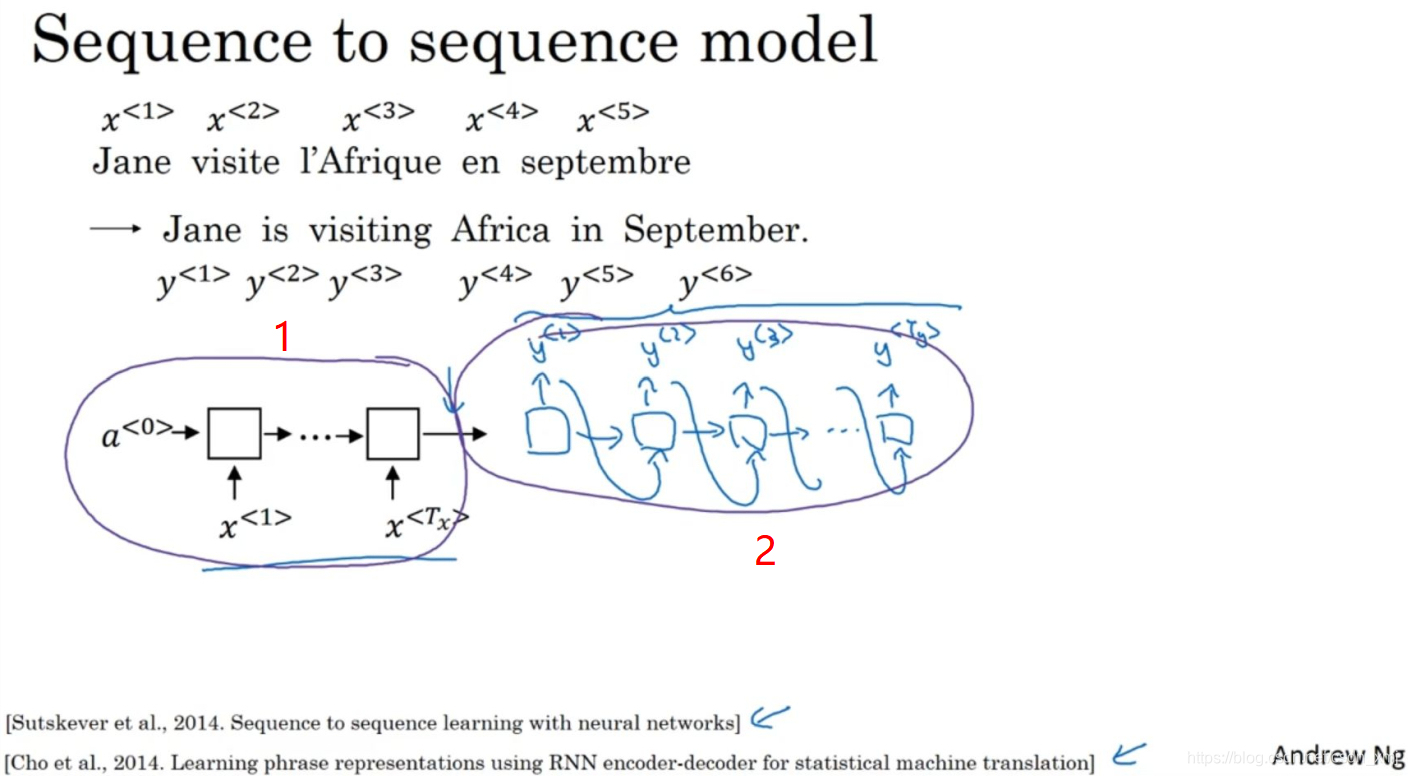
- 如上图,左边黑色的是编码器(编码网络),右边蓝色的是解码器(解码网络)。两者基本都基于RNN/LSTM/GRU实现。
- 每次向编码器中输入一个法语单词,将输入序列接收完毕后,这个RNN网络会输出一个向量来代表这个输入序列。然后将编码网络的输出输入给解码网络,之后它可以被训练为每次输出一个翻译后的单词,一直到它输出序列的结尾或者句子结尾标记。
(2)image to sequence模型
- mage to Sequence是一类将图像输入转化为有序序列输出的深度学习模型。
- 其核心逻辑也是:用视觉编码器 提取图像的结构化特征,再用序列解码器将视觉特征映射为有序的文本序列。
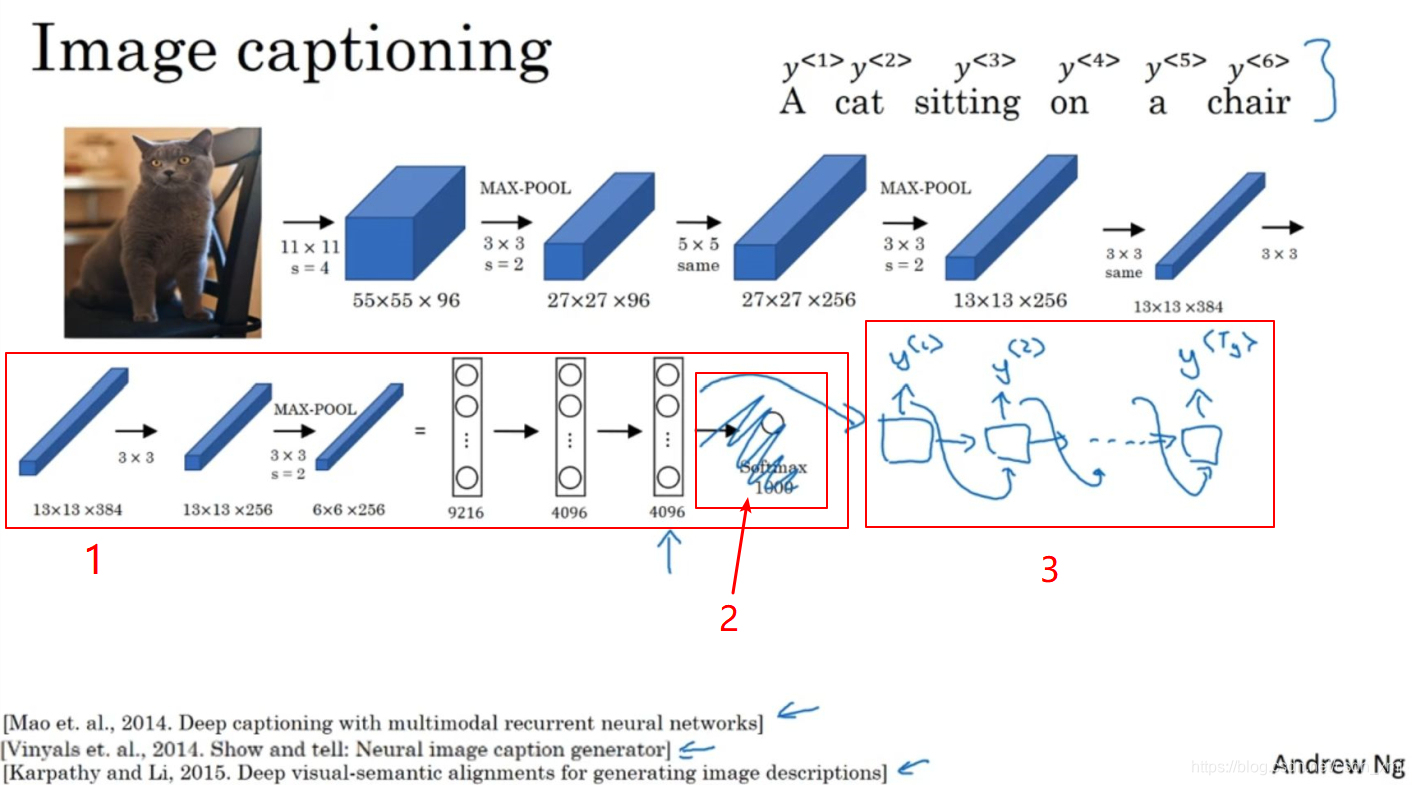
- 如上图,将图片输入到卷积神经网络中,让其学习图片的编码或者图片的特征。,卷积网络会得到一个4096维的特征向量,现在我们去掉最后的softmax单元(记号2),把这个向量输入到RNN中(记号3),让RNN要做的就是生成图像的描述。
2.条件语言模型 -> 选择最可能的句子
(1)语言模型与机器翻译模型
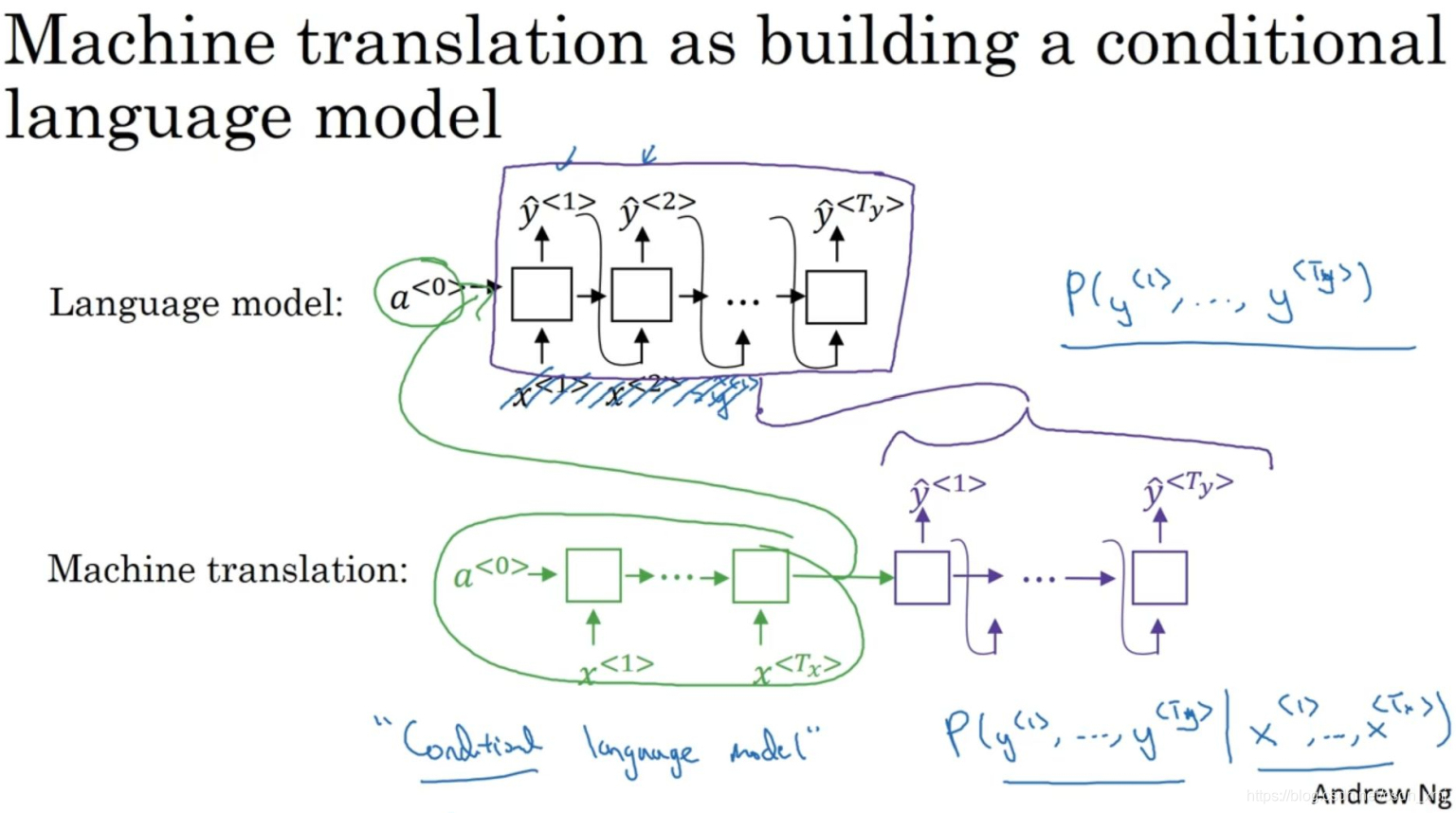
- 第一行是语言模型,可以估计句子的可能性或生成一个新的句子。其中x<1>为0向量 ,x<2> = y^<1>,x<3> = y^<2>............
- 第二行是机器翻译模型,左边部分表示编码网络,右边表示解码网络。我们可以发现decoder网络和语言模型非常相似。
- 两个模型不同的是:语言模型总是以零向量(a<0>)开始,而解码网络会用encoder网络计算出的一系列向量作为输入,所以机器翻译模型可以叫做条件语言模型 ,翻译模型会输出句子的英文翻译,取决于输入的法语句子。它会估计一个英文翻译的概率。
(2)选择最可能的句子
-

-
上面我们说了翻译模型(条件语言模型)会估计一个英文翻译的概率,以上图为例,通过输入的法语句子,模型将会告诉你各种英文翻译所对应的可能性,但是我们要找到最好的翻译,怎么找呢?我们肯定不能在这些句子中随机取样,而是要找到条件概率最大化(翻译最好)的句子。
-
所以我们在开发翻译系统时,需要一个算法,用来找出合适的y值,使得该项最大化。这要用到集束搜索。
-
为什么不用贪心搜索呢?贪心搜索是一种来自计算机科学的算法,生成第一个词的分布以后,它将会根据你的条件语言模型挑选出最有可能的第一个词进入你的机器翻译模型中,在挑选出第一个词之后它将会继续挑选出最有可能的第二个词,然后继续挑选第三个最有可能的词,但是你真正需要的是一次性挑选出整个单词序列,从y^<1>、y^<2>到y^<T_y>来使得整体的概率最大化。所以这种方法其实并不管用。
3.集束搜索
(1)介绍
- 在开发翻译系统时,用集束搜索来找出合适的y值,使得该项概率最大化。我们用法语句子翻译成英语的例子。
(2)过程
-
-
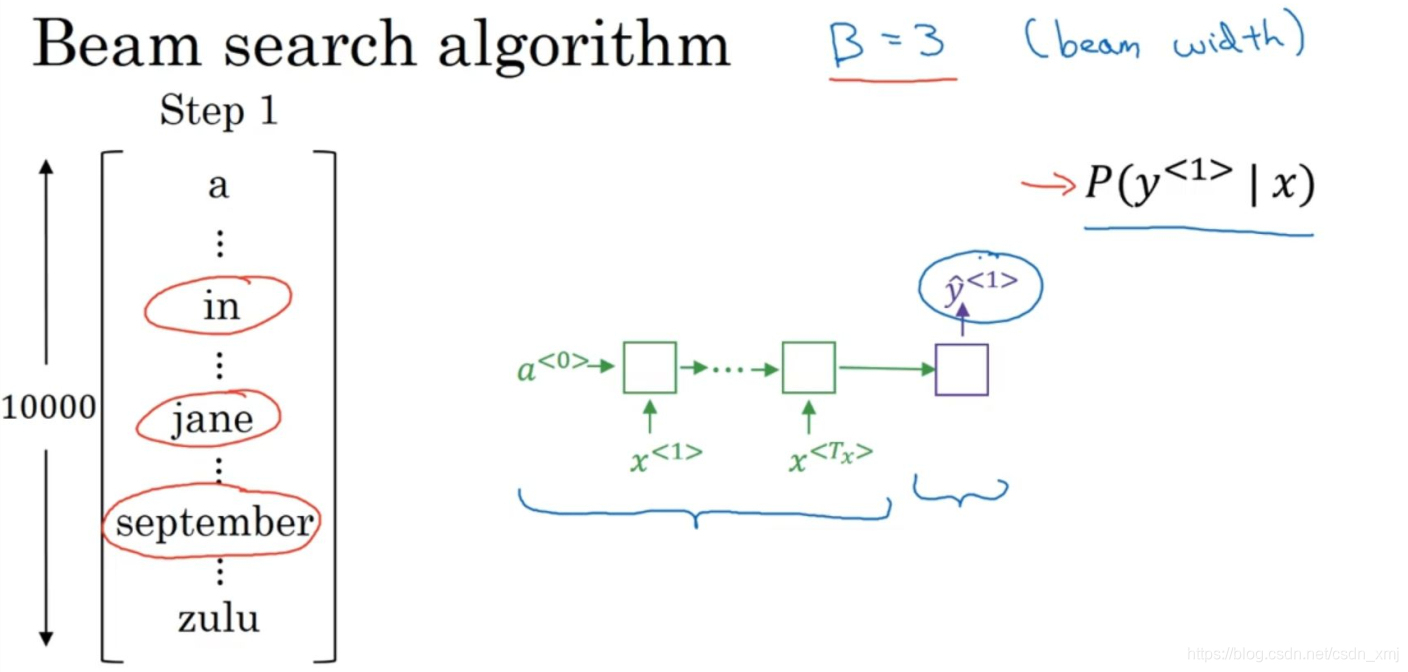
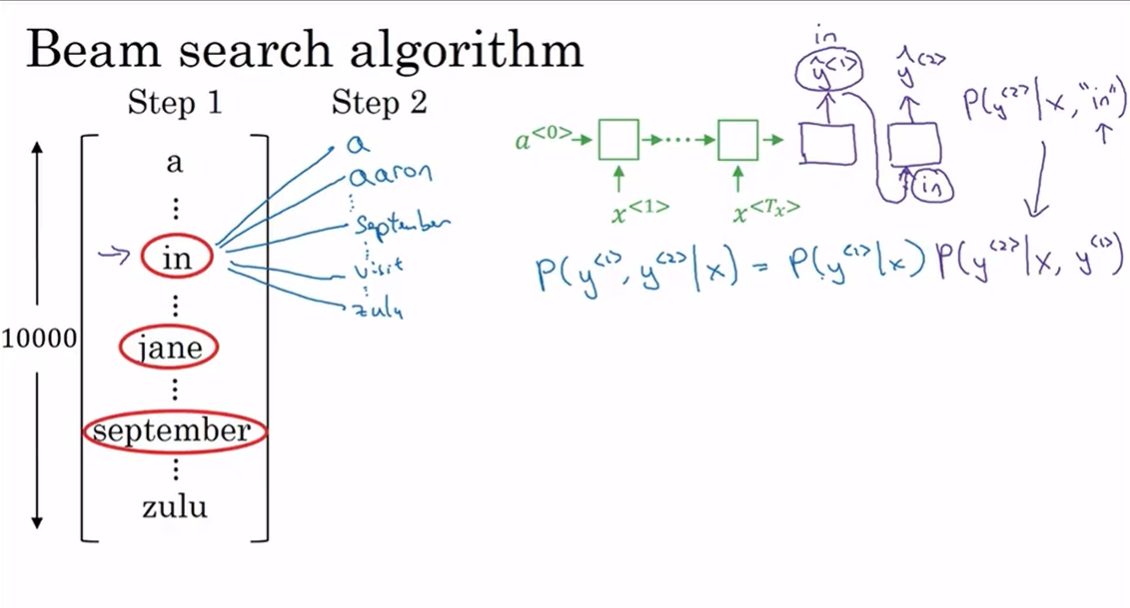
第一步:确定要输出的英语翻译中的第一个单词。词汇表有10000个词。在集束搜索的第一步中用的这个网络部分,绿色是编码部分,紫色是解码部分,来评估第一个单词的概率值,给定输入序列x,即法语作为输入,第一个输出y的概率值是多少。
-
集束搜索会考虑多个选择,集束搜索算法有一个参数B,叫做集束宽(beam width) 。在这个例子中B=3,这样就意味着集束搜索在每一步中会考虑3个结果,比如对第一个单词有三种不同选择的可能性,最后找到in、jane、september,是英语输出的第一个单词的最可能的三个选项,然后集束搜索算法会把结果存到计算机内存里以便后面尝试用这三个词。
-
集束搜索确定第一个词的过程就是,输入法语句子到编码网络,然后解码这个网络,这个softmax层(紫色蓝框)会输出10,000个概率值(10000个词),得到这10,000个输出的概率值,取前三个存起来。
-
-
第二步:确定第二个词的步骤和第一个词相似,接下来会对第一步确定的三个单词分别考虑第二个单词是什么。同样,每个单词后面都有10000中选择(词汇表有10000个词),这样总共就有30000种组合,因为B=3,所以要从30000中组合中选择3个作为最可能的组合。这里的组合是指第一个词和第二个词的组合 ,也就是说第二步选择的是前两个单词最可能的三种组合 ,也就是 P(y^<1>,y^<2>|x) 最大的三种组合,P(y^<1>,y^<2>|x) = P(y^<1>|x) × P(y^<2>|x,y^<1>)。同理第三步选择的是前三个单词最可能的三种组合。
-
假如30,000个选择里最可能的是"in September"、"jane is"和"jane visits",可以发现第一步选择的September没有被选中,那之后的过程中就不再考虑September作为第一个词的情况了。
-
第三步,第四步......:和前面一样,第三步是在"in September"、"jane is"和"jane visits"3个组合提供的30000中选择中选3个。后面也是一样的。直到在句尾符号(EOS)结束。
-
注意如果集束宽等于1,意味着只考虑1种可能结果,这实际上就变成了贪婪搜索算法
4.改进集束搜索
(1)取对数
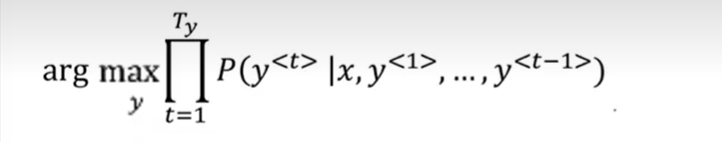
- 如上图,我们知道集束搜索就是要最大化这个概率。这个概率可以表示成下面两种形式。
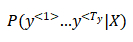
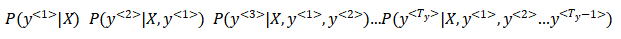
- 这样就是个乘积概率,我们知道很多小于1的数乘起来,会得到很小很小的数字,可能造成数值下溢(numerical underflow),数值下溢就是数值太小了,导致电脑的浮点表示不能精确地储存。
- 所以我们取对数(下图),这样就把概率值相乘的积变为了概率值对数相加的和,而取对数只对计算结果有影响,并不会对最后的选择造成影响。
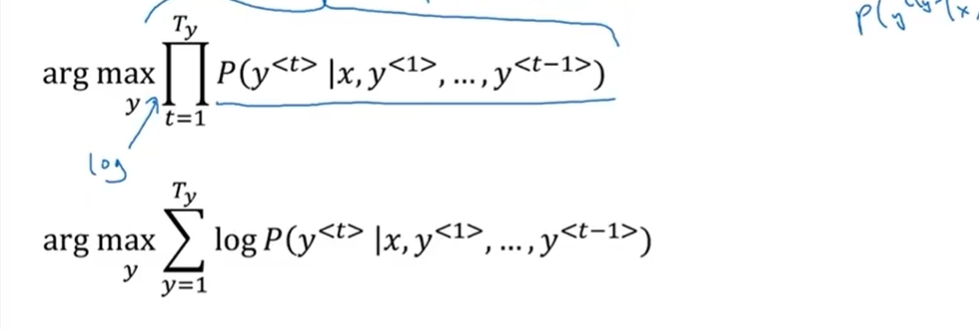
(2)长度归一化
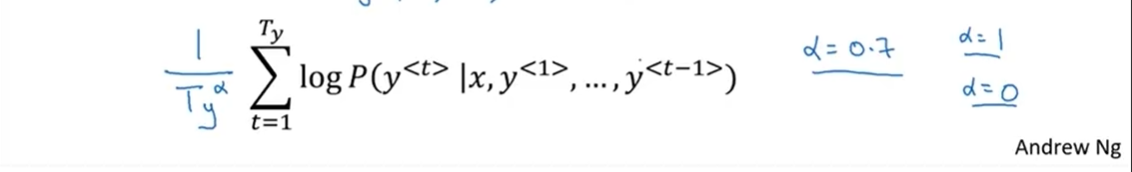
- 如果句子很长,很多概率值相乘就会得到更小的概率值,所以它可能倾向于简短的翻译。即使取对数,概率的log值通常小于等于1,在这个范围内,加起来的项越多,结果越负。我们可以把原目标函数归一化,通过除以翻译结果的单词数量,取每个单词的概率对数值的平均,这样做很明显地减少了对输出长的结果的惩罚。
- 在实践中,相比于直接除T_y(输出句子的单词总数),我们会用一个更柔和的方法,在T_y上加上指数α,α一般取0.7。如果α等于1,就相当于完全用长度来归一化,α等于0,T_y的0次幂就是1,就相当于完全没有归一化,这就是在完全归一化(full normalization)和没有归一化(no normalization)之间。α就是算法另一个超参数,需要调整大小来得到最好的结果。
(3)总结
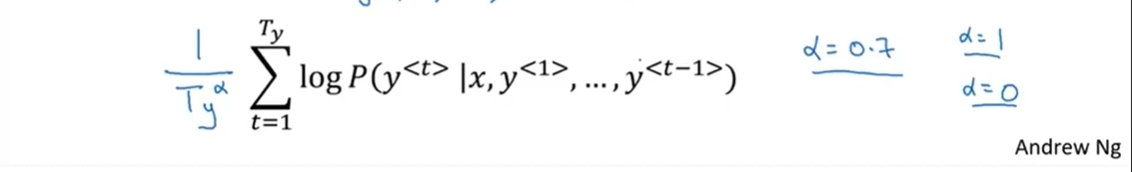
- 总结一下如何运行束搜索算法。当我们运行束搜索时,可能会有各种长度的句子,因为束宽为3,你会记录不同长度句子的三个最可能的选择。然后针对这些所有的可能的输出句子,用上面的这个式子给它们打分,取概率最大的几个句子,然后对这些束搜索得到的句子,计算这个目标函数。最后从经过评估的这些句子中,挑选出在归一化的log概率目标函数上得分最高的一个。这就是最终输出的翻译结果,这就是如何实现束搜索。
(4)其他
- 如何选择束宽B。B越大,我们需要考虑的选择越多,得到的句子可能越好,但是B越大,算法的计算代价越大,因为很多的可能选择要保存起来。
- 不同取值的B有各自的优缺点。(1)如果束宽很大,我们会考虑很多的可能,倾向于得到一个更好的结果,但是算法会运行的慢一些,内存占用也会增大,计算起来会慢一点。(2)如果用小的束宽,结果会没那么好,因为在算法运行中,保存的选择更少,但是算法运行的更快,内存占用也小。
- 在前面的例子中我们用了束宽为3,所以会保存3个可能选择,在实践中这个值有点偏小。在产品中,经常可以看到把束宽设到10,这也取决于不同应用。但是对科研而言,人们想压榨出全部性能,这样有个最好的结果用来发论文,也经常束宽为1000或3000,这也是取决于特定的应用和特定的领域。
- 在实现你的应用时,尝试不同的束宽的值,当B很大的时候,性能提高会越来越少。对于很多应用来说,从束宽等于1(贪心算法),到束宽为3到10,你会看到一个很大的改善。但是当束宽从1000增加到3000时,效果就没那么明显了。
5.集束搜索的误差分析
(1)简介
- 集束搜索算法是一种近似搜索算法,也被称作启发式搜索算法,它不总是输出可能性最大的句子,有可能出错。机器翻译有两个组件,一个是RNN(seq2seq),一个是集束搜索算法。当机器翻译出错时,我们可以通过误差分析来判断:是优化RNN好还是优化集束搜索算法好?
(2)误差分析过程
-

-
以上图句子为例,对于法语"Jane visite l'Afrique en septembre"来说,
-
在开发集中,人工翻译是:Jane visits Africa in September,这是一个很好的人工翻译结果,*标记为 y
-
在已完成学习的RNN翻译模型中运行束搜索算法时,它输出翻译结果为:Jane visited Africa last September,**标记为y^
-
我们知道模型会计算P(y|x)并选择概率最大的句子,所以我们可以用这个模型来计算P(y*|x)和P(y-帽|x),并比较大小,分析以下两种情况:
-
(1)第一种情况,P(y*|x) > P(y-帽|x):这意味着什么呢? 集束搜索算法做的就是尝试寻找使P(y|x)最大的y,但是y* 的值更P(y|x)大,所以集束搜索算法没有给你一个能使P(y|x)最大化的y值,因此是集束搜索算法出错了。
-
(2)第二种情况:P(y*|x) ≤ P(y-帽|x) :我们知道y是比y-帽更好的翻译结果,但是RNN模型计算的P(y|x) < P(y^|x),所以是RNN模型出了问题。
-

-
知道了对单个错误句子的分析过程,我们就遍历开发集,标记每个错误类型,集束搜索算法出错标记为B,RNN出错标记为R。
-
然后统计两种错误的比例:
-
(1)如果发现是束搜索算法造成了大部分错误,可以增大集束宽度。
-
(2)如果发现是RNN模型出了更多错,那么可以进行更深层次的分析,来决定是需要增加正则化还是获取更多的训练数据,抑或是尝试一个不同的网络结构,或是其他方案。