使用Softmax与交叉熵损失实现简单的MNIST手写数字数据集分类问题。
Softmax
Softmax 是一种常用于多分类任务的激活函数,它将一个包含任意实数的向量(通常称为 logits)转换为一个概率分布:输出的每个元素都在 0 到 1 之间,且所有元素之和为 1。
在深度学习中,Softmax 通常接在神经网络最后一层,配合交叉熵损失(CrossEntropyLoss)使用。
值得注意的是,PyTorch 的 nn.CrossEntropyLoss 内部已自动应用了 Softmax 的数值稳定版本(LogSoftmax + NLLLoss),因此模型输出应直接返回原始 logits,无需显式添加 Softmax 层。


交叉熵损失
交叉熵损失(Cross-Entropy Loss)是多分类任务中最常用的损失函数,用于衡量模型预测的概率分布与真实标签(通常为 one-hot 编码或类别索引)之间的差异。
在 PyTorch 中,nn.CrossEntropyLoss 接收原始 logits(未经过 Softmax 的网络输出)和整数形式的真实标签,内部自动通过数值稳定的 LogSoftmax 计算负对数似然,从而避免直接计算 Softmax 可能带来的数值溢出问题。交叉熵越小 ,表示预测分布越接近真实分布,模型性能越好。

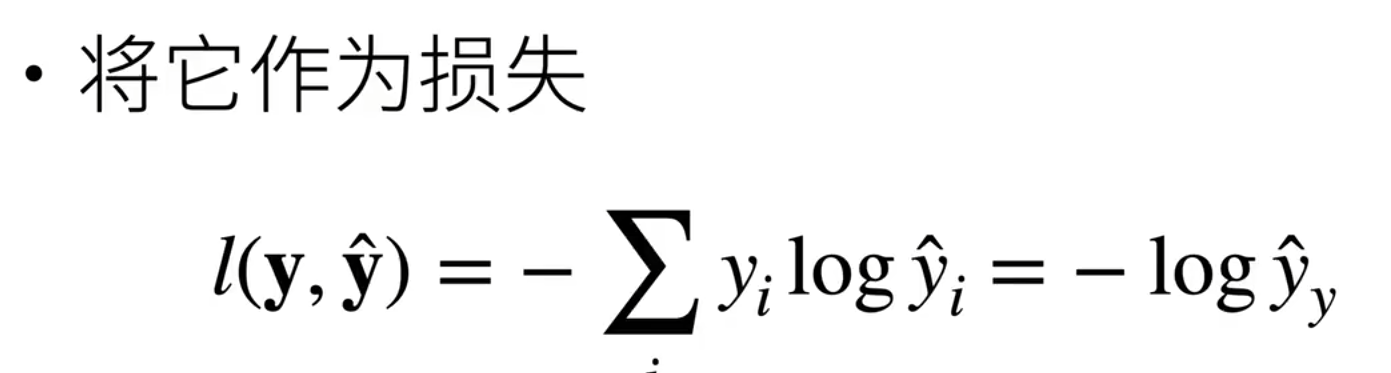
代码
完整代码如下:
python
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import os
data_root = r'D:\pycode\write\Minist1\w1'
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(root=data_root, train=True, download=False, transform=transform)
test_dataset = datasets.MNIST(root=data_root, train=False, download=False, transform=transform)
batch_size = 256
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
class SoftmaxRegression(nn.Module):
def __init__(self, input_dim=28*28, num_classes=10):
super(SoftmaxRegression, self).__init__()
self.linear = nn.Linear(input_dim, num_classes)
def forward(self, x):
x = x.view(x.size(0), -1)
return self.linear(x) # logits
def train(model, loader, criterion, optimizer, device):
model.train()
total_loss = 0
correct = 0
total = 0
for data, target in loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
total_loss += loss.item()
pred = output.argmax(dim=1)
correct += pred.eq(target).sum().item()
total += target.size(0)
return total_loss / len(loader), correct / total
def test(model, loader, criterion, device):
model.eval()
total_loss = 0
correct = 0
total = 0
with torch.no_grad():
for data, target in loader:
data, target = data.to(device), target.to(device)
output = model(data)
loss = criterion(output, target)
total_loss += loss.item()
pred = output.argmax(dim=1)
correct += pred.eq(target).sum().item()
total += target.size(0)
return total_loss / len(loader), correct / total
if __name__ == "__main__":
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
model = SoftmaxRegression().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
epochs = 10
for epoch in range(1, epochs + 1):
train_loss, train_acc = train(model, train_loader, criterion, optimizer, device)
test_loss, test_acc = test(model, test_loader, criterion, device)
print(f"Epoch {epoch:2d} | "
f"Train Loss: {train_loss:.4f}, Acc: {train_acc:.4f} | "
f"Test Loss: {test_loss:.4f}, Acc: {test_acc:.4f}")
print("\n训练完成!")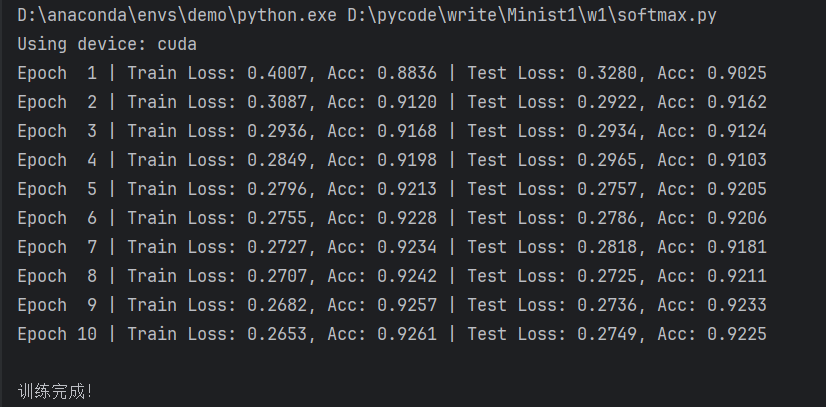
导入库
python
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import ostorch:PyTorch 核心库,提供张量计算和自动微分。
nn:神经网络模块,包含层(如 Linear)、损失函数等。
DataLoader:用于批量加载数据,支持打乱、多线程等。
datasets, transforms:torchvision 提供的标准数据集(如 MNIST)和数据预处理工具。
os:用于路径操作。
数据加载与预处理
python
data_root = r'D:\pycode\write\Minist1\w1'
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(root=data_root, train=True, download=False, transform=transform)
test_dataset = datasets.MNIST(root=data_root, train=False, download=False, transform=transform)
batch_size = 256
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)data_root:指定 MNIST 数据集的父目录。PyTorch 会在该目录下寻找 MNIST/raw/ 中的 .gz 文件。
transforms.Compose:
ToTensor():将 PIL 图像(0~255)转为 FloatTensor(0.0~1.0),并调整维度为 C, H, W。
Normalize(mean, std):对每个像素做标准化:(x - mean) / std。MNIST 的全局均值 ≈ 0.1307,标准差 ≈ 0.3081。
datasets.MNIST:
train=True/False:分别加载训练集(6万张)和测试集(1万张)。
download=False:不联网下载,使用本地数据。
DataLoader:
batch_size=256:每次输入 256 张图片。
shuffle=True(仅训练集):打乱顺序,提升泛化能力;测试集无需打乱。
模型定义 ------ Softmax 回归
python
class SoftmaxRegression(nn.Module):
def __init__(self, input_dim=28*28, num_classes=10):
super(SoftmaxRegression, self).__init__()
self.linear = nn.Linear(input_dim, num_classes)
def forward(self, x):
x = x.view(x.size(0), -1) # [B, 1, 28, 28] → [B, 784]
return self.linear(x) # 输出 logits,形状 [B, 10]这是一个没有隐藏层的线性分类器,即 Softmax 回归。
view(x.size(0), -1):将每张 28×28 的图像展平为 784 维向量。
nn.Linear(784, 10):学习一个权重矩阵W和偏置b,输出 logits。
注:不加 Softmax,因为 CrossEntropyLoss 内部会处理,直接返回 logits 即可。
训练函数
python
def train(model, loader, criterion, optimizer, device):
model.train() # 启用训练模式(如 Dropout、BatchNorm)
total_loss = 0
correct = 0
total = 0
for data, target in loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad() # 清空梯度
output = model(data) # 前向传播
loss = criterion(output, target) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
total_loss += loss.item()
pred = output.argmax(dim=1) # 预测类别
correct += pred.eq(target).sum().item() # 统计正确数
total += target.size(0)
return total_loss / len(loader), correct / total测试函数
python
def test(model, loader, criterion, device):
model.eval() # 启用评估模式
total_loss = 0
correct = 0
total = 0
with torch.no_grad(): # 禁用梯度计算,节省内存、加速
for data, target in loader:
data, target = data.to(device), target.to(device)
output = model(data)
loss = criterion(output, target)
total_loss += loss.item()
pred = output.argmax(dim=1)
correct += pred.eq(target).sum().item()
total += target.size(0)
return total_loss / len(loader), correct / total主程序 ------ 训练循环
python
if __name__ == "__main__":
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
model = SoftmaxRegression().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
epochs = 10
for epoch in range(1, epochs + 1):
train_loss, train_acc = train(model, train_loader, criterion, optimizer, device)
test_loss, test_acc = test(model, test_loader, criterion, device)
print(f"Epoch {epoch:2d} | "
f"Train Loss: {train_loss:.4f}, Acc: {train_acc:.4f} | "
f"Test Loss: {test_loss:.4f}, Acc: {test_acc:.4f}")
print("\n训练完成!")测试/训练损失
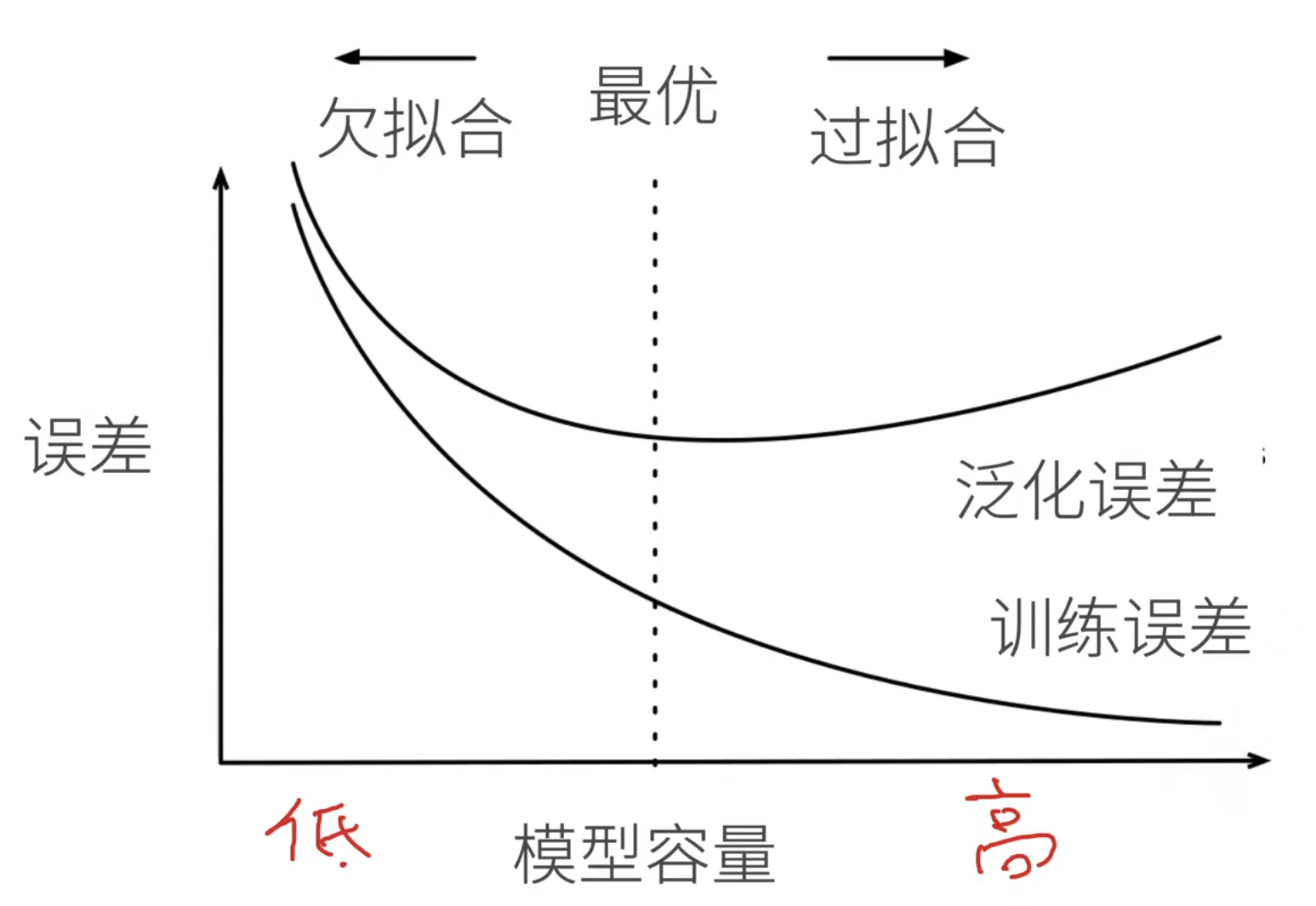
训练损失(Training Loss) 是模型在训练数据上预测结果与真实标签之间的平均误差,反映了模型对已见数据的拟合程度。训练过程中,优化器通过反向传播不断调整参数以最小化该损失,因此训练损失通常随着训练轮次增加而逐渐下降。
测试损失(Test Loss) (测试误差、泛化误差)则是模型在未参与训练的测试集上的平均误差,用于评估模型的泛化能力------即对新数据的适应能力。
理想的训练状态是训练损失和测试损失都较低且接近;若测试损失明显高于训练损失,往往说明模型过拟合,记住了训练数据的细节却未能学到通用规律。