导语
连上 Snowflake,用一句话就能查数据------不需要写 SQL,不需要懂技术,只需连接你的数据源,用自然语言直接提问,马上获得答案。
本教程基于 Spider2-Snow 真实企业数据环境,为你演示 InfiniSynapse 如何让你 3 分钟完成连接,立即开始数据查询。
本教程将带你完成:
- 获取免费的 Spider2-Snow Snowflake 测试环境
- 在 InfiniSynapse 中配置数据源与知识库
- 通过 3 个真实案例体验自然语言数据分析
- 获取完整配套资源(547 道题目、知识库文档、标准答案)
使用 InfiniSynapse 只需两步:
1)连接你的 Snowflake 数据源;
2)用自然语言提问。系统会自动理解你的问题并返回查询结果。如果你想让查询更准确,可以上传知识库文档(表说明、业务规则等),但这完全可选------连接后立即可用,无需等待。
开始之前 :请先下载 InfiniSynapse桌面端 https://www.infinisynapse.com/download,或体验SaaS版本:InfiniSynapse
前置关键概念
- InfiniSynapse:企业级自然语言数据分析平台
InfiniSynapse 让数据分析回归业务本质------用自然语言提问,即可获得数据洞察与可视化结果。
核心能力:
- 连接即用:只需填写数据源连接信息,无需配置,无需等待,立即开始查询
- 自然语言查询:用业务语言直接提问,系统自动理解并返回结果,无需编写 SQL
- 多数据源支持:原生支持 Snowflake、MySQL、Hive、Excel 等多种数据源,可跨源关联分析
- 智能可视化:自动生成图表,支持交互式数据探索
- 多端协同:提供桌面端(Windows / macOS)、命令行等多种使用方式
- Spider2-Snow:学术级评测环境
Spider2 是 Spider2-Snow 是业界公认的学术级评测环境,包含:
- 547 道企业级查询任务:覆盖区块链、电商、航空等多个行业
- 完整的 Snowflake 数据环境:可免费申请测试账号
- 配套知识库文档:展示如何构建业务知识库
本教程将在 Spider2-Snow 环境中,演示 InfiniSynapse 如何处理真实的企业级数据分析任务。
Step 1:申请 Spider2-Snowflake 账号
本小节步骤(申请、登录、获取 Token)参考 Spider2 官方 Snowflake 指南( https://github.com/xlang-ai/Spider2/blob/main/assets/Snowflake_Guideline.md),若与官方文档不一致,以官方为准。
以下截图均来自该官方教程。
Spider2 项目采用 MIT License, Copyright (c) 2024 bird_sql.
后面用 InfiniSynapse 查数据,要连到 Spider2-Snow 的 Snowflake 环境。先申请 Spider2 的免费访问权限,按下面做即可(全在网页完成,不用装软件)。
申请入口与填写
第一步:打开 Spider2 官网 https://spider2-sql.github.io/。
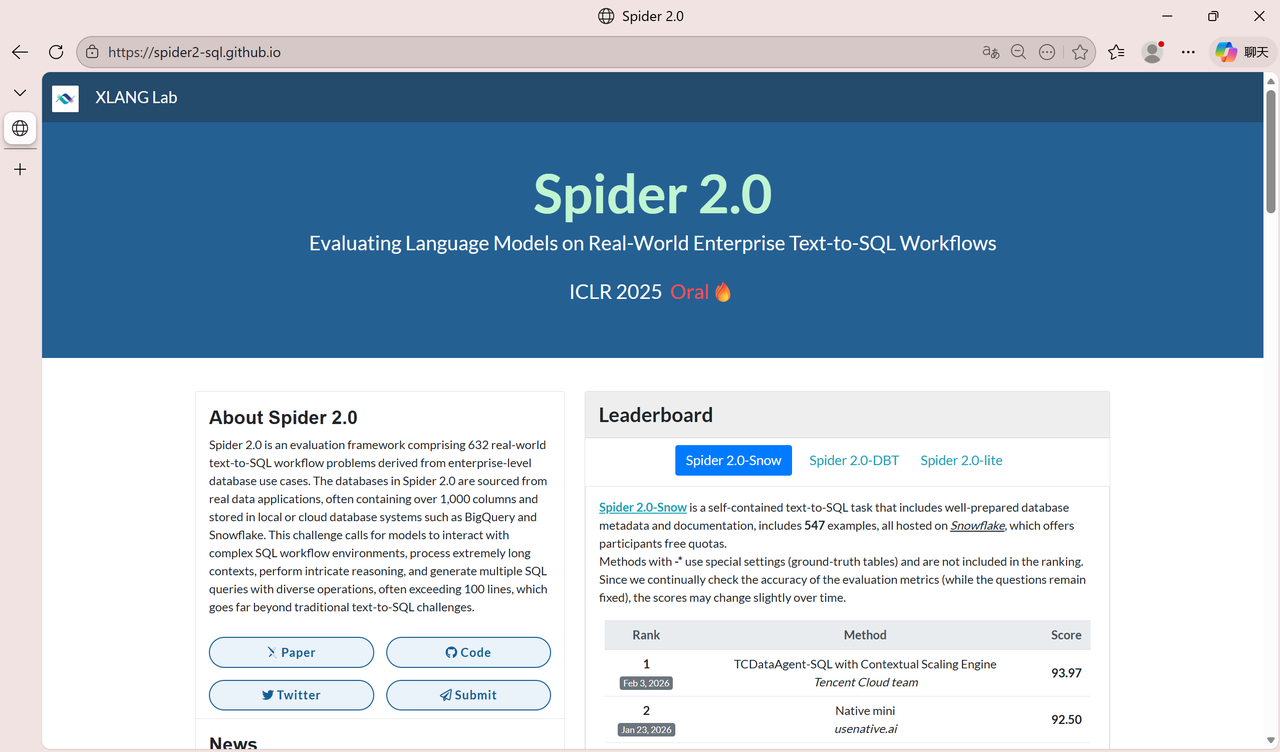
第二步 :在页面中找到并点击 Spider 2.0 - Snow 入口。
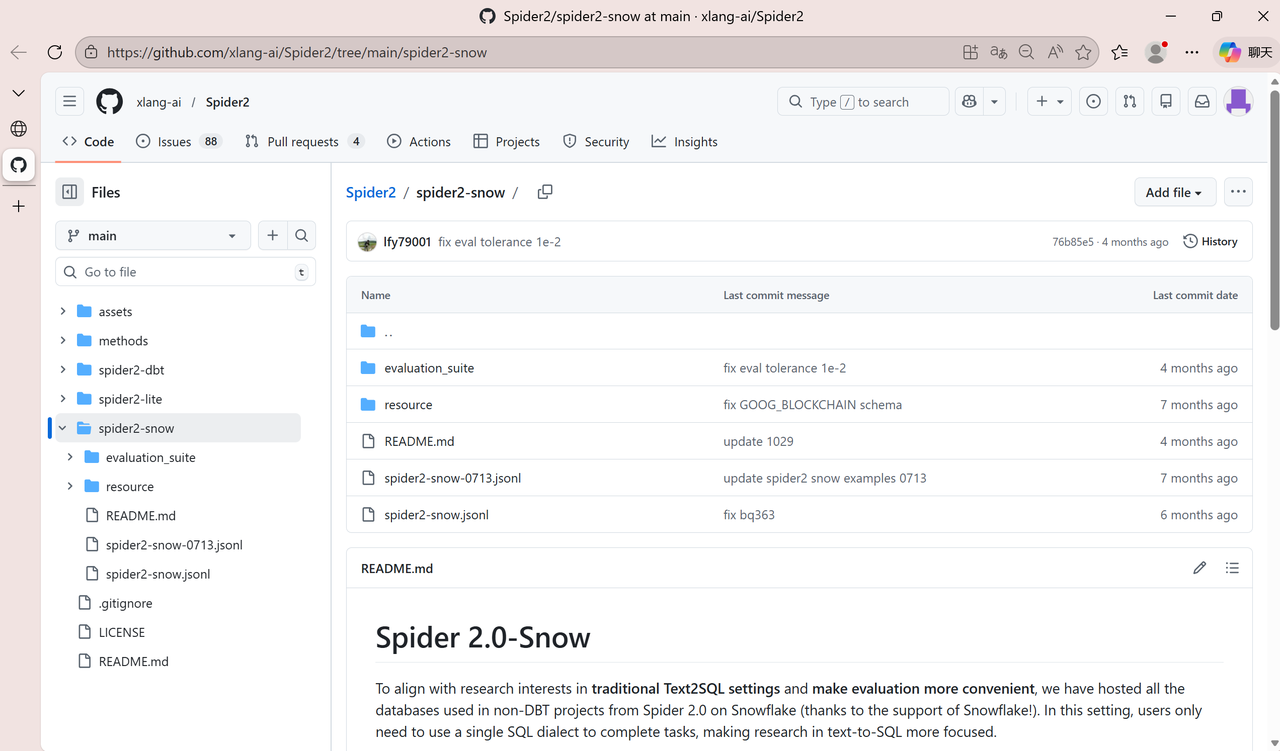
第三步 :进入 Spider2 的官方 GitHub 仓库后,打开 README.md。
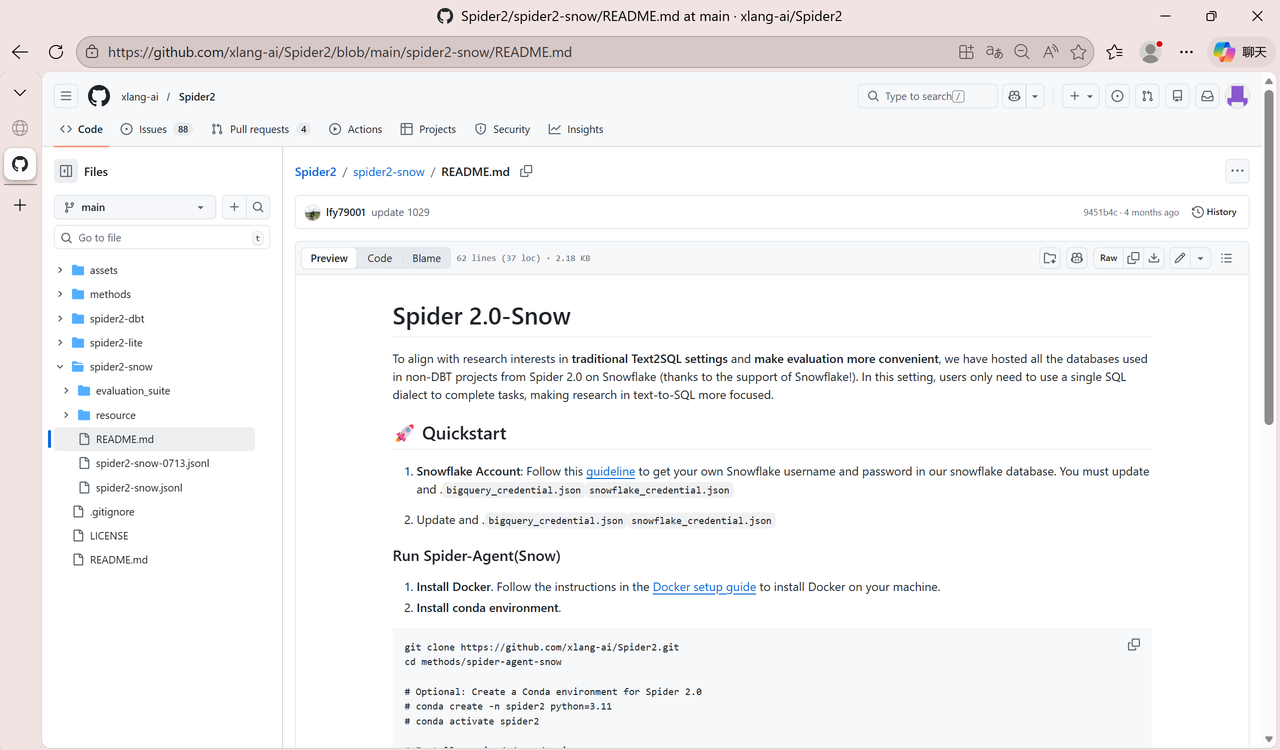
第四步 :在 README 中找到 Guideline 链接并点击进入。
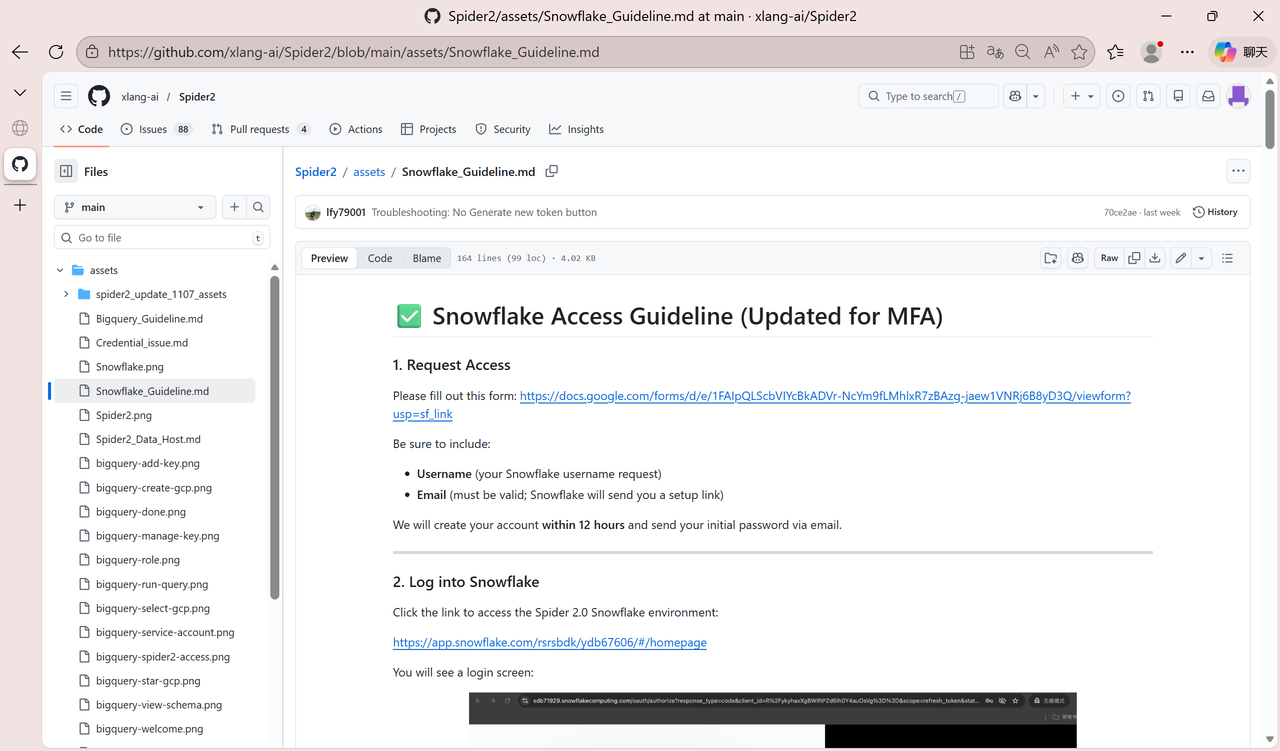
第五步 :在 Guideline 页面找到 Request Access 下的申请链接,点击进入表单并填写。
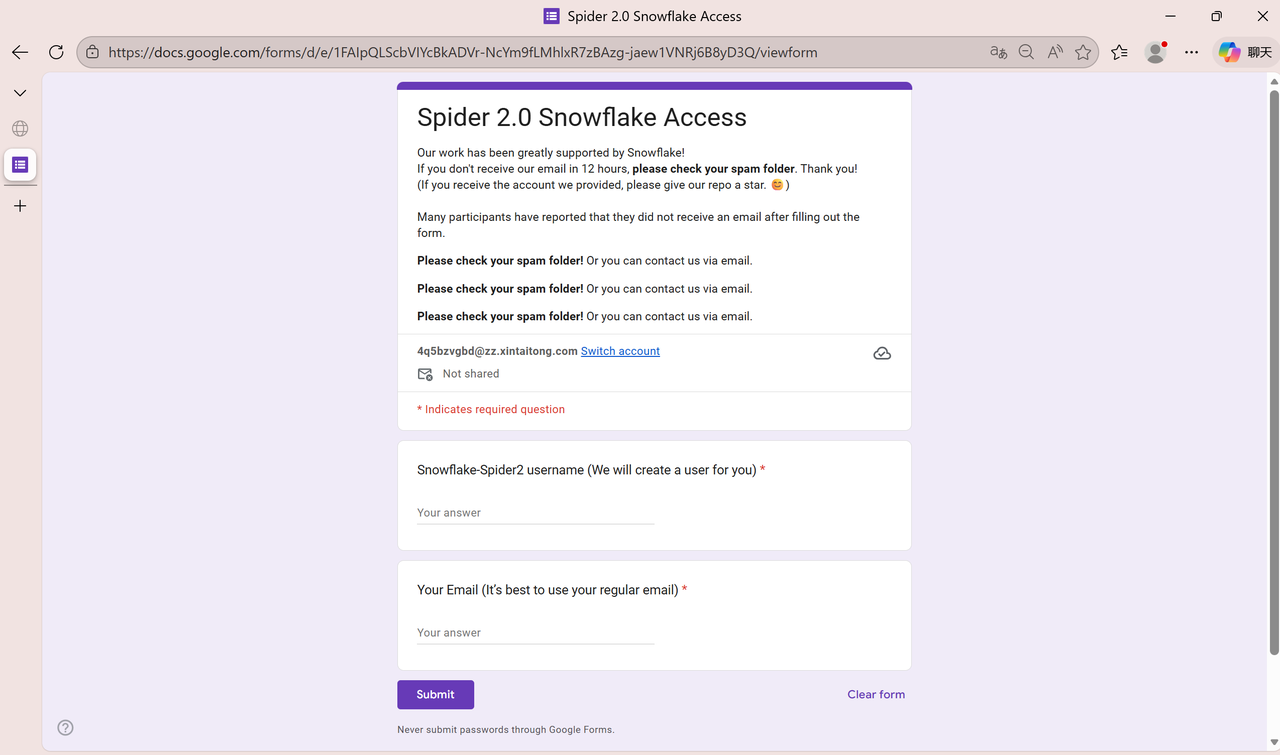
表单填写要点:
- 用户名:填写你希望在 Snowflake 中使用的登录账号(后续登录与 InfiniSynapse 配置都会用到)。
- 电子邮件:务必填写有效邮箱,Snowflake 会向该邮箱发送设置链接与初始密码。
提交后,留意邮箱。官方会在 12 小时内 给你发邮件,里面包含初始密码和登录说明。
登录 Snowflake(收到邮件后再做)
1. 打开登录页
点击以下链接访问 Spider2-Snow 的 Snowflake 环境:
https://app.snowflake.com/rsrsbdk/ydb67606/#/homepage
您将看到登录界面:
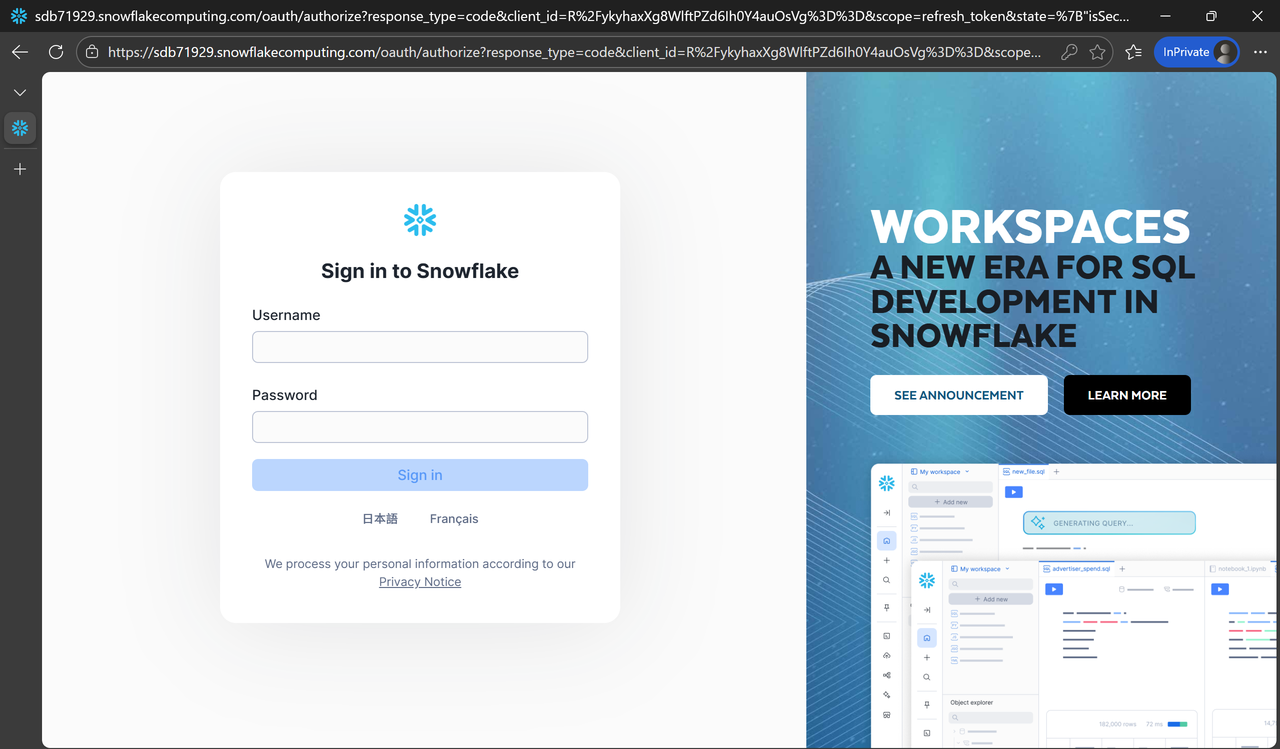
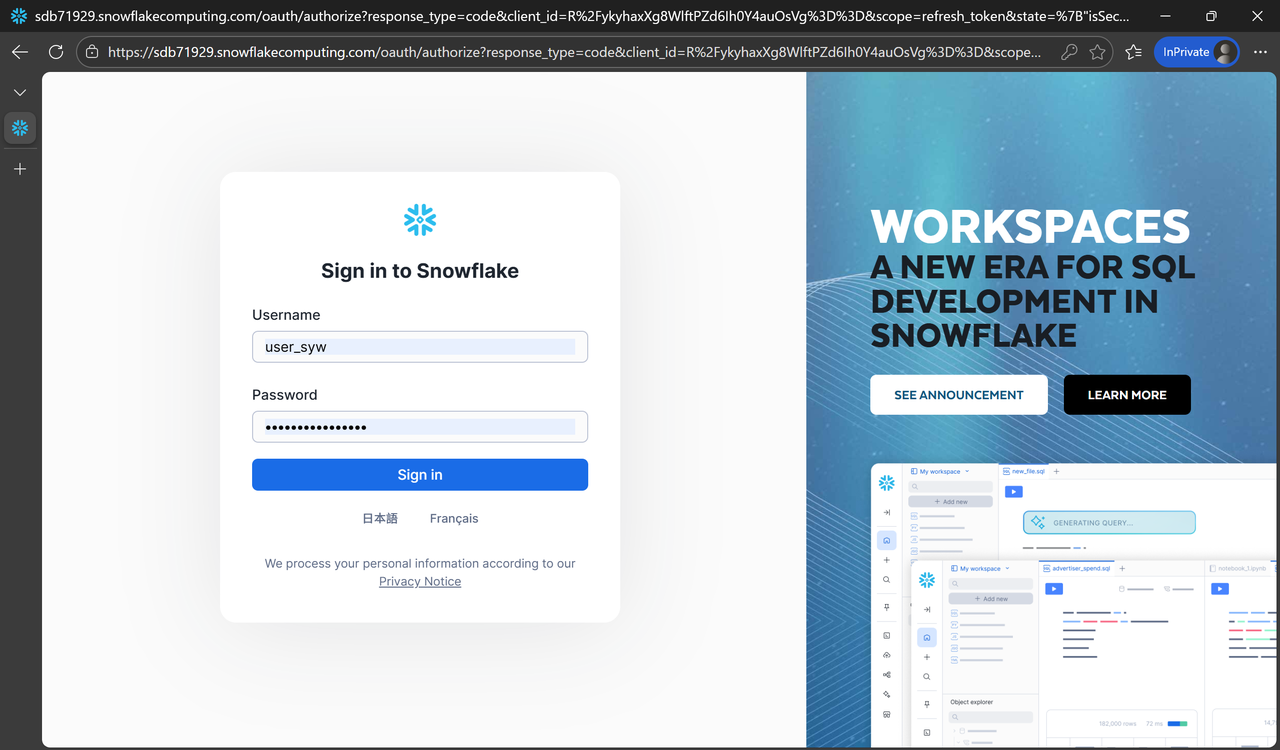
2. 输入账号密码
在页面中输入邮件中收到的用户名和初始密码。
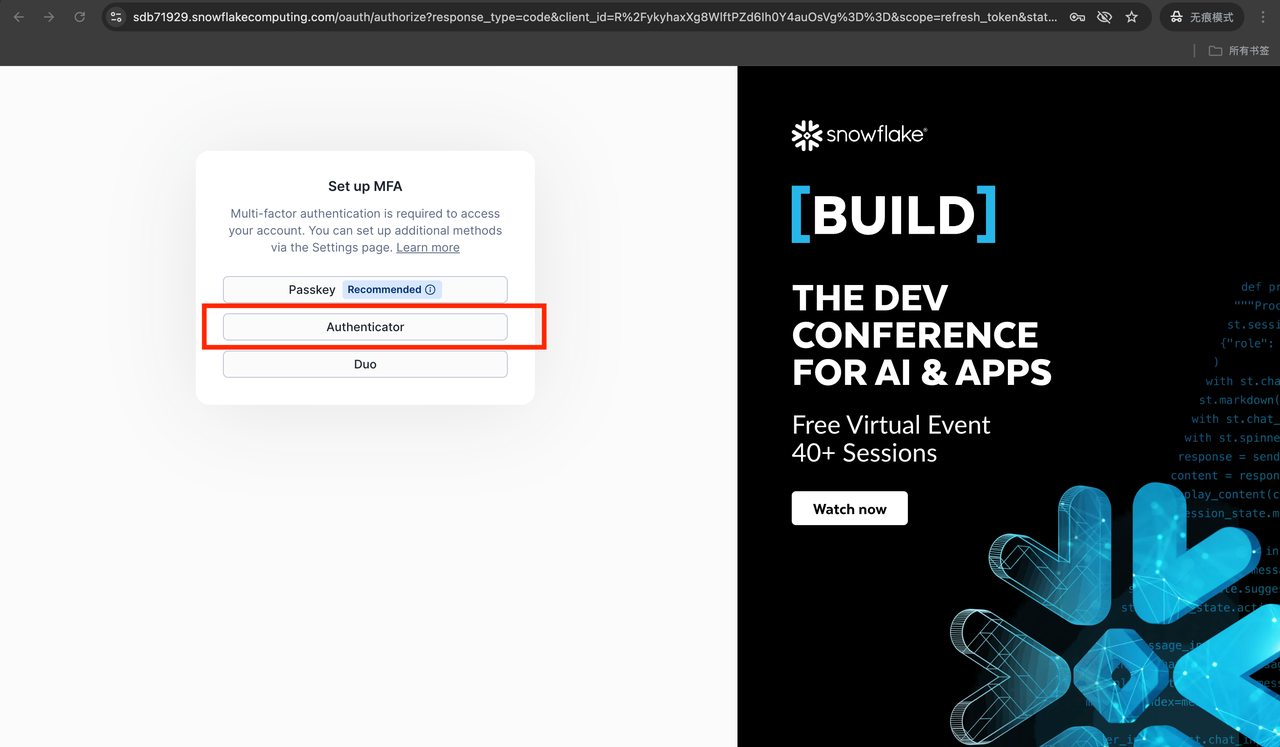
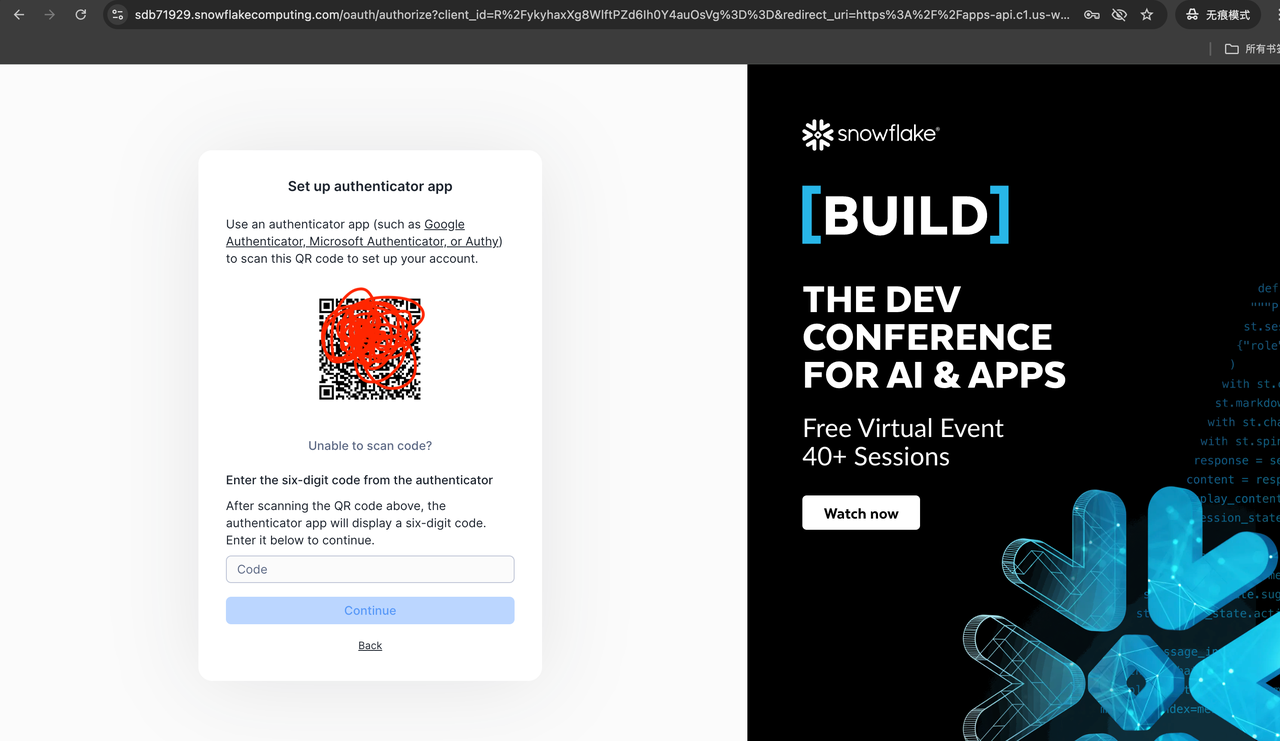
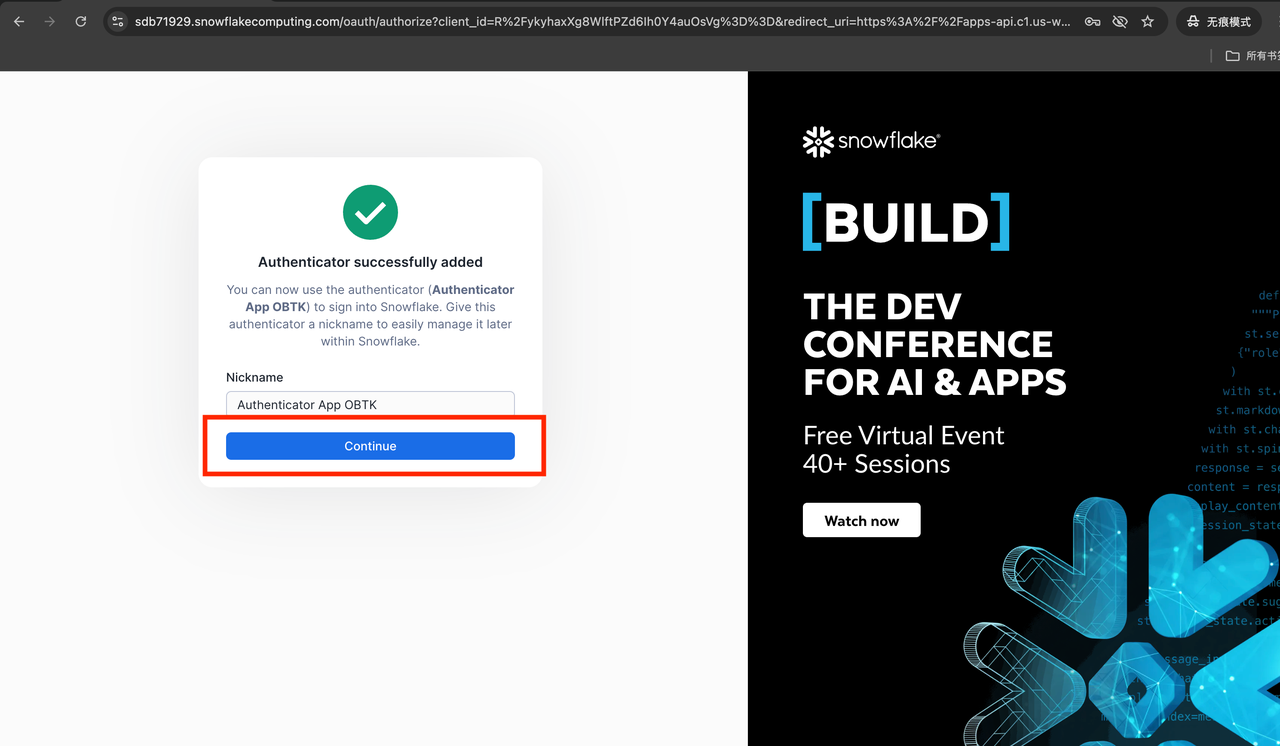
3. 设置多重身份验证(重要:请选「认证器」)
「多重身份验证」就是除了密码之外,再用手机 App 生成一个 6 位验证码,提高安全性。首次重置密码后,Snowflake 会让你设置这个。出现提示时,请务必选择 认证器(不要选「通行密钥」)。
操作步骤:
- 在手机上打开 Google Authenticator(如需下载:iOS / Android 均免费)。
- 在 App 中点击「+」→「扫描二维码」。
- 扫描 Snowflake 页面上的二维码。
- 将 App 中显示的 6 位数验证码输入到网页中即可完成绑定。
此步骤只需设置一次。
✅ 若误选了「通行密钥」:可关闭当前页面,使用浏览器的无痕/隐私模式重新打开登录页,再次登录时会重新出现认证器选项。
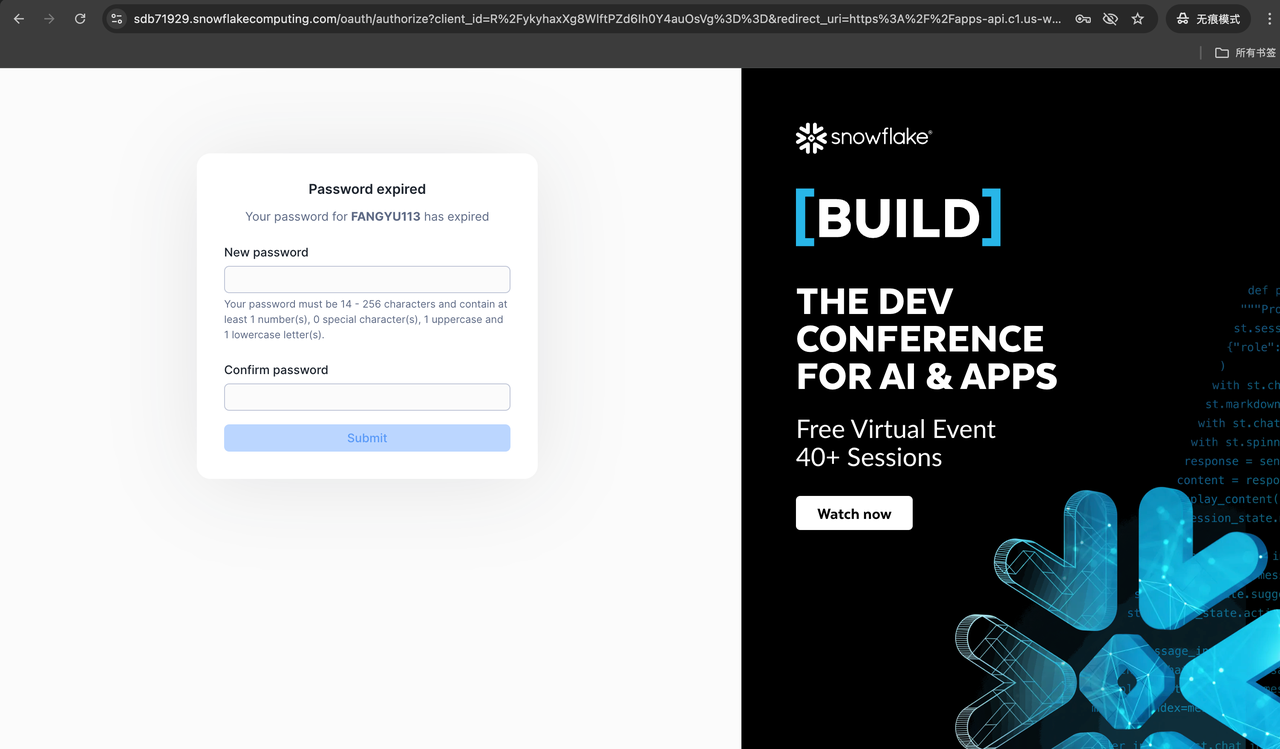
4. 重置密码
按页面提示完成密码重置。
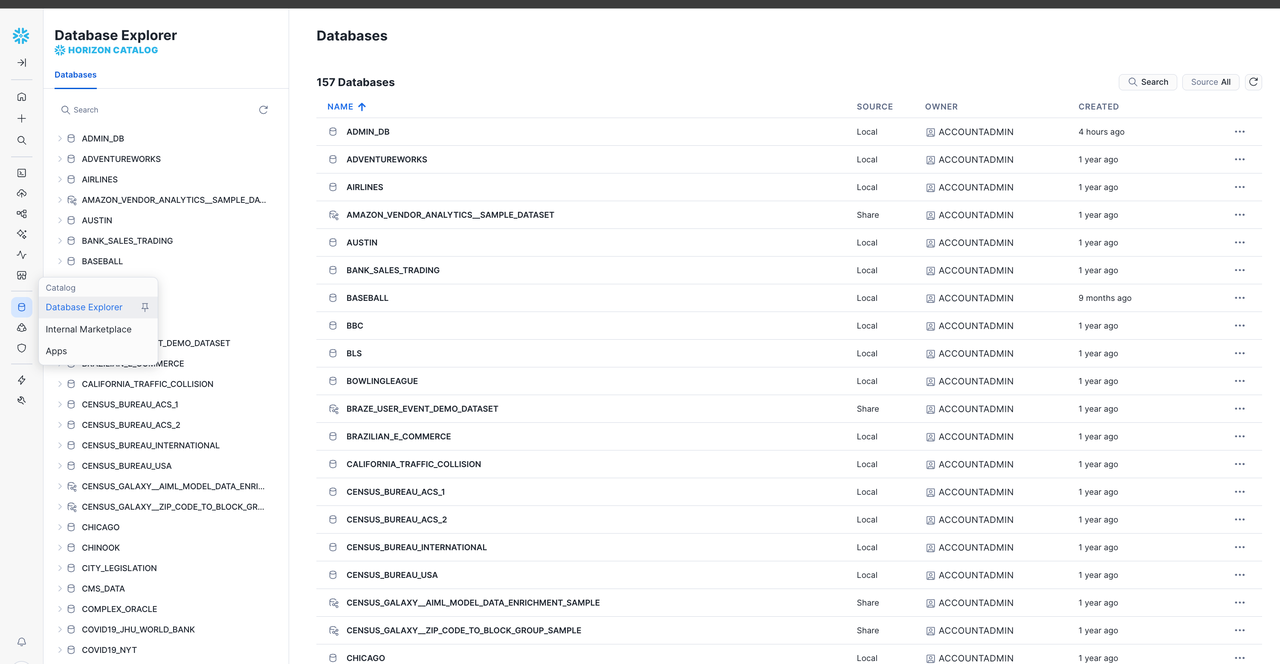
5. 成功登录
登录成功后,可在控制台中查看数据库与表结构。
至此你已能在网页登录 Snowflake。要用 InfiniSynapse 自然语言查数据,或用 Python/脚本 连库,都需再做一步 ------获取 Programmatic Access Token。
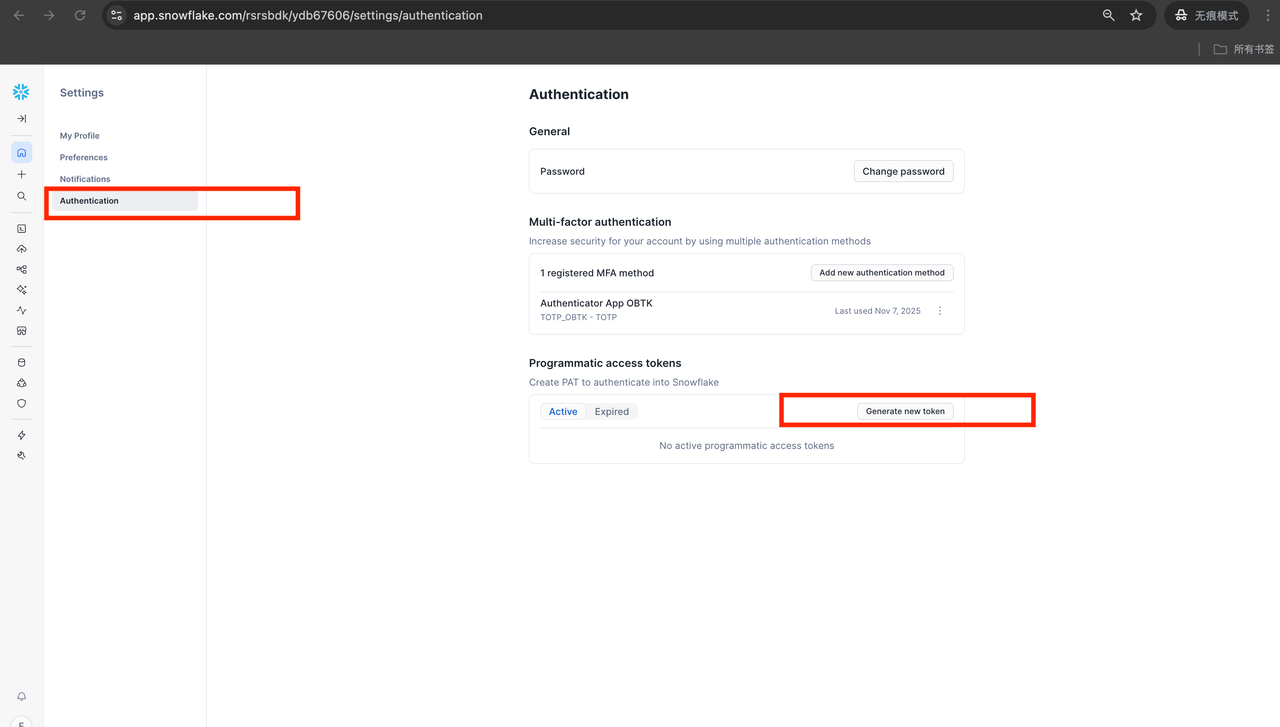
获取 Programmatic Access Token
(InfiniSynapse 与脚本均需)
在 Snowflake 里按界面提示获取 Programmatic Access Token(或从 Spider2 文档查看获取方式)。若用脚本,把 snowflake_credential.json 里的 username、password 改成你的用户名和该 token,例如:
{
"username": "<your_username>",
"password": "<your_generated_token>",
"account": "RSRSBDK-YDB67606",
"role": "PARTICIPANT",
"warehouse": "COMPUTE_WH_PARTICIPANT"
}
</your_generated_token></your_username>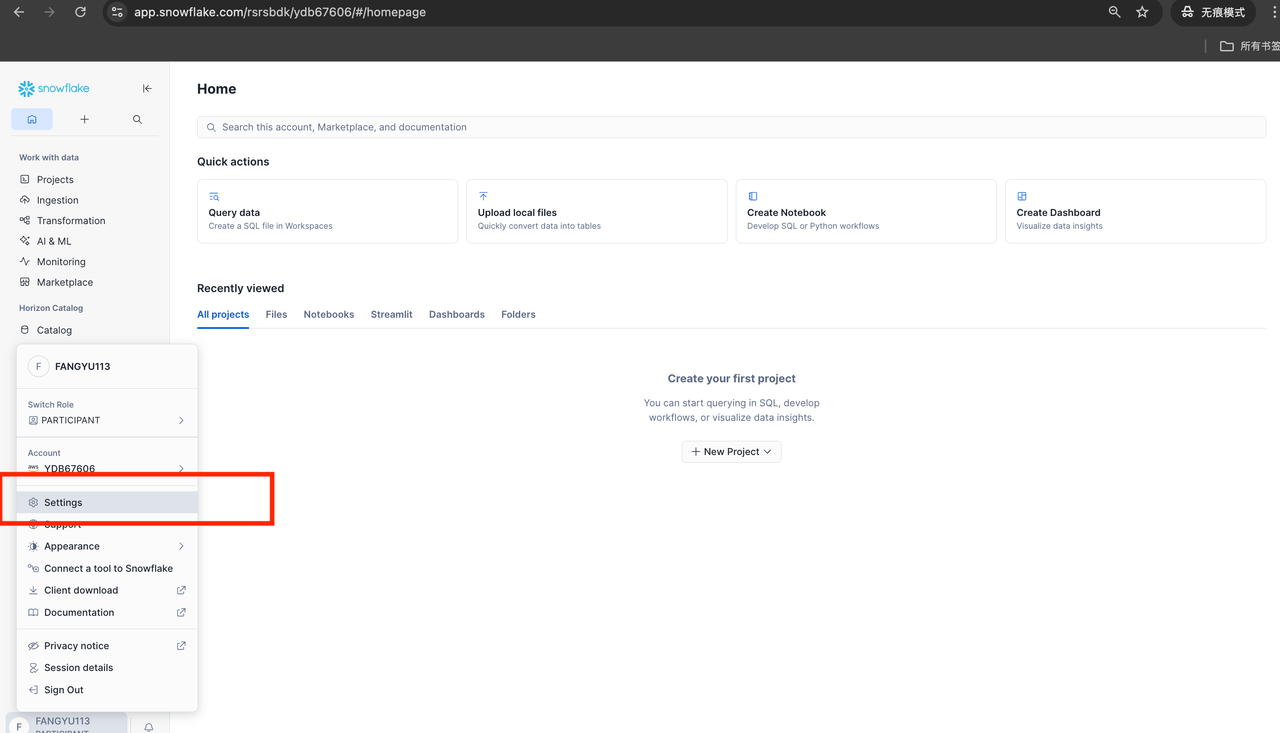
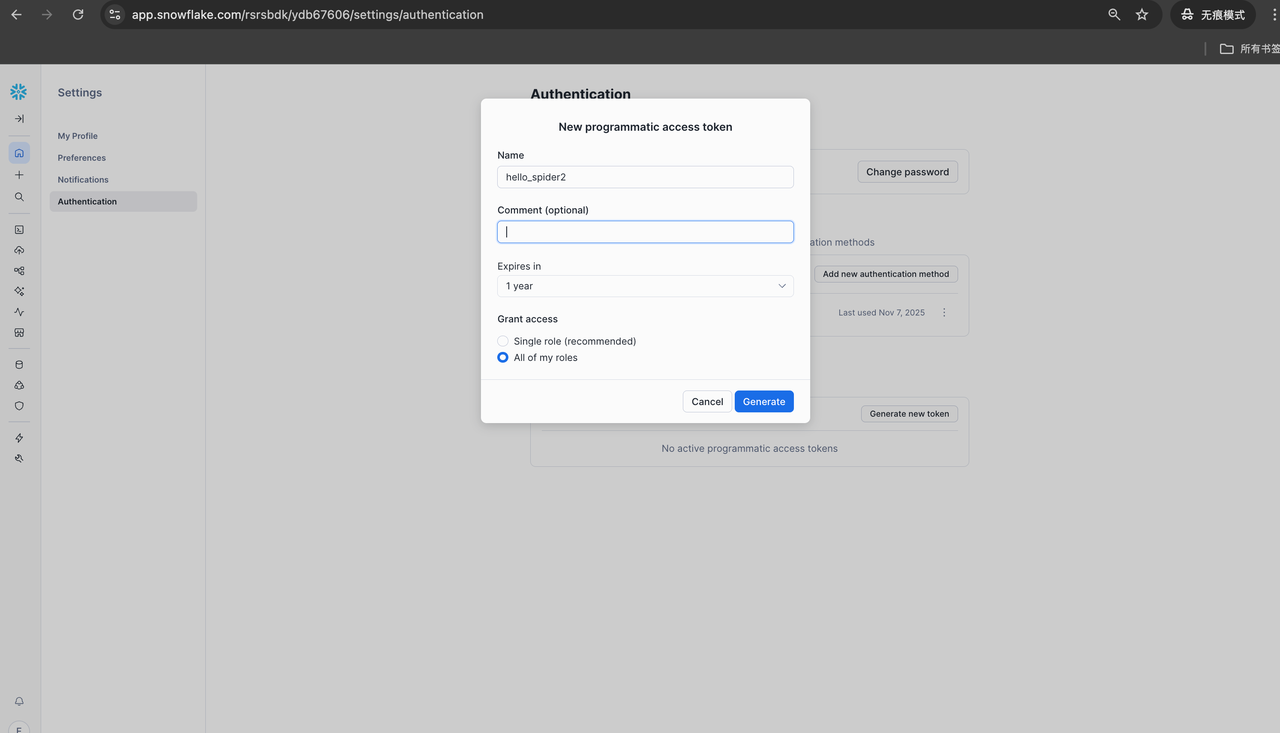
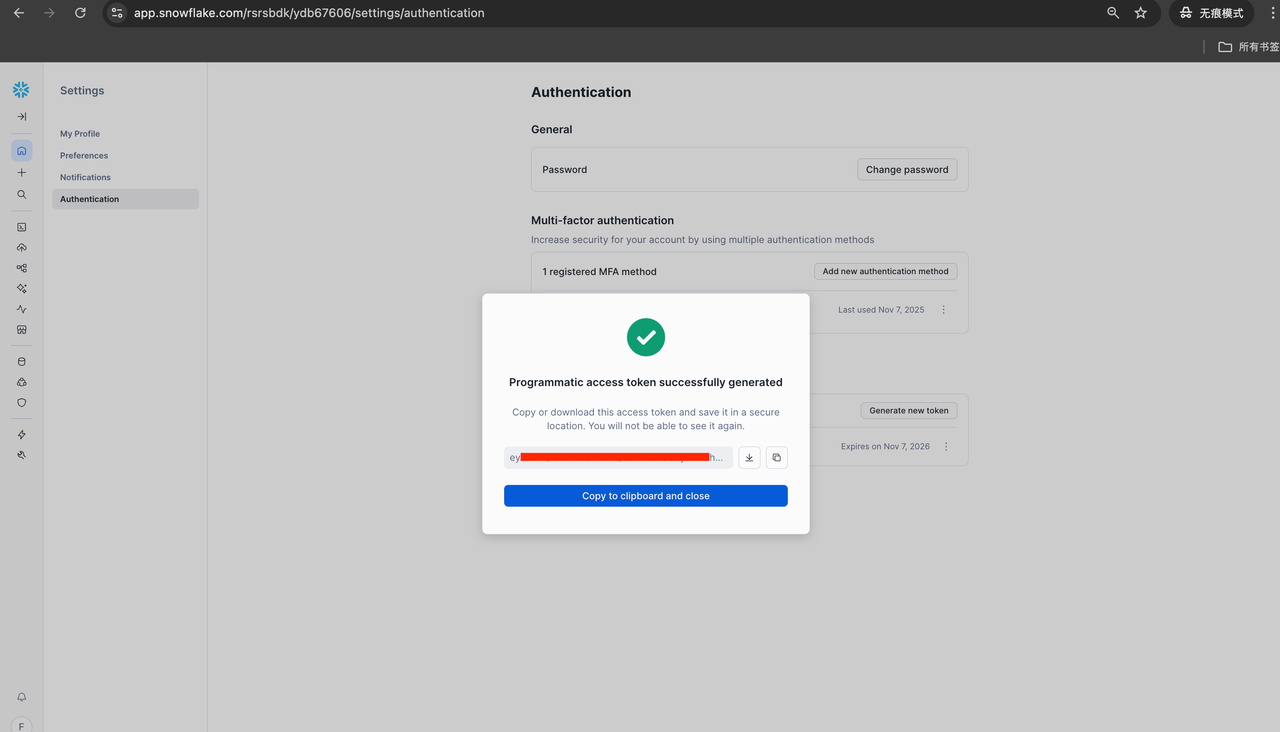
注意:这个 token 就是 Step 2 在 InfiniSynapse 里建 Snowflake 连接时「密码 」栏要填的------不是网页登录 Snowflake 的密码。请复制保存。
Step 2:连接 Snowflake 数据源
现在将 InfiniSynapse 连接到你的 Snowflake 数据环境。整个过程不到 2 分钟,无需任何代码或复杂配置。
连接信息:
- 用户名:你的 Snowflake 账号
- 密码:使用 Step 1 中获取的 Programmatic Access Token(不是网页登录密码)
- 其他信息:按照邮件或 Snowflake 控制台中的配置填写即可
创建 Snowflake 连接
第一步:打开 InfiniSynapse 产品界面。
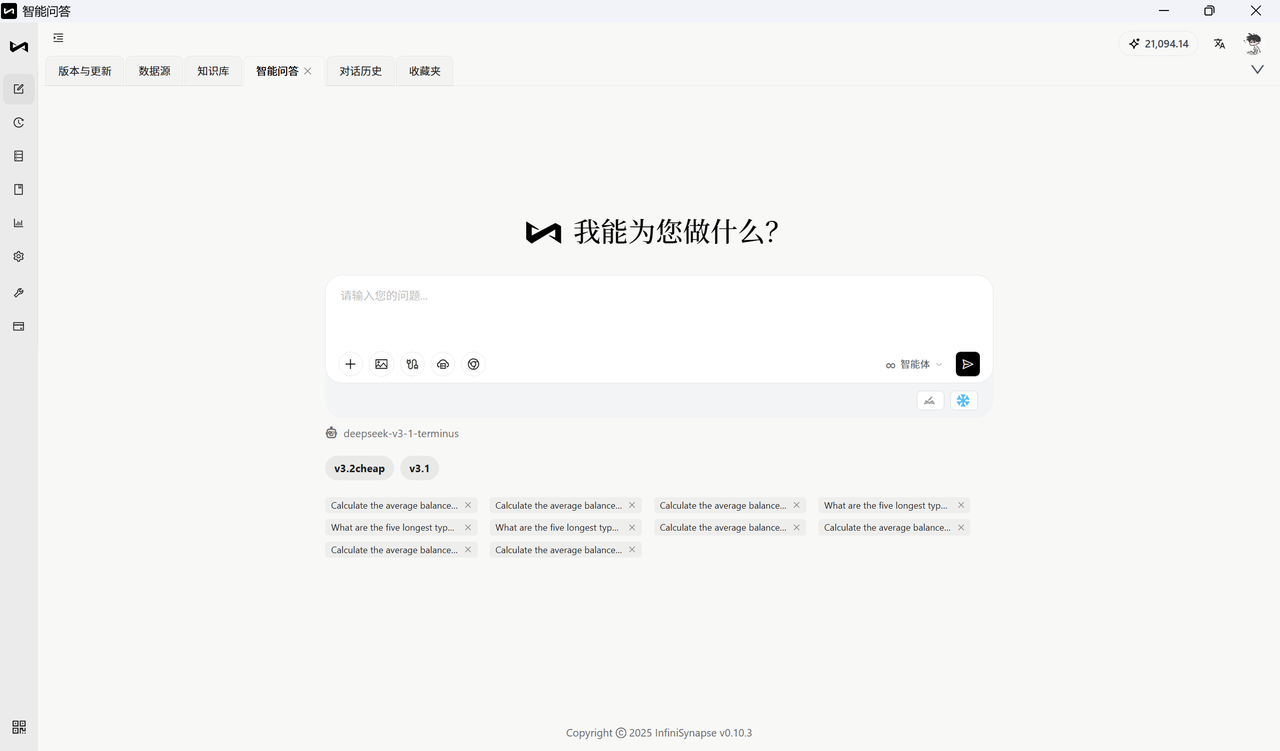
第二步 :在左侧导航中点击 数据源,进入数据源管理。
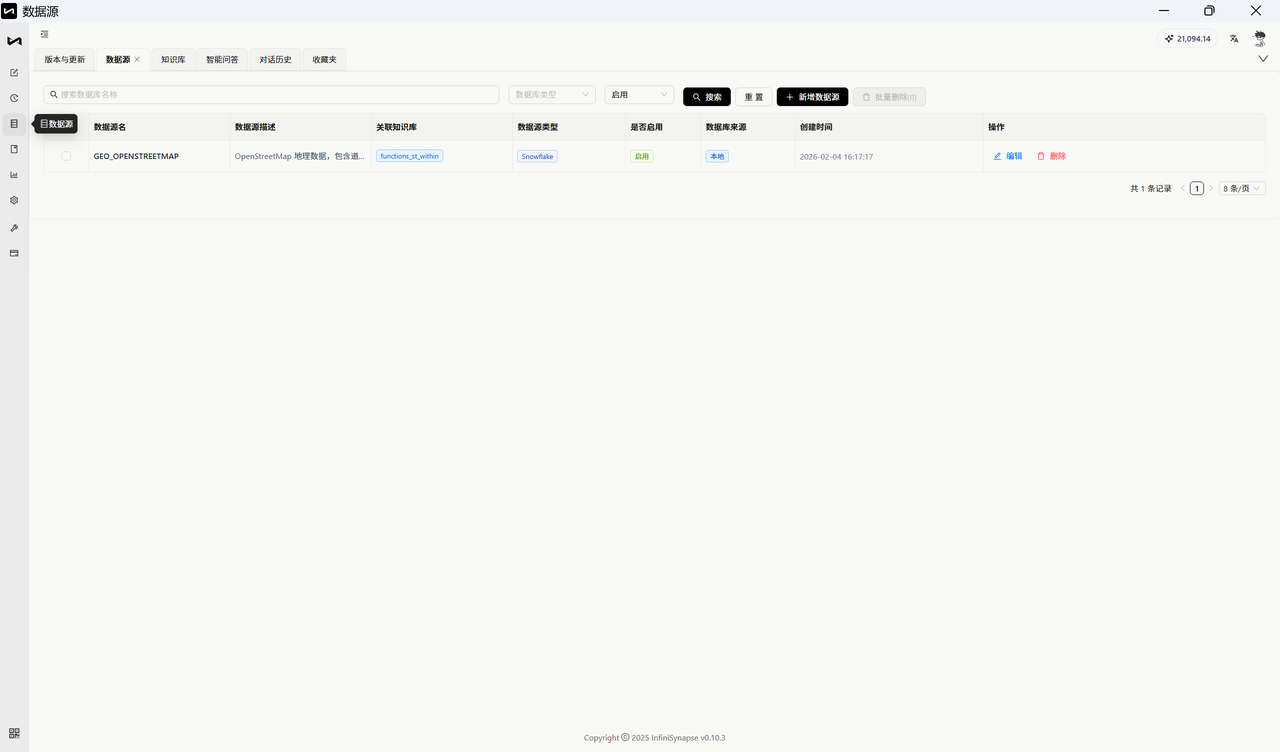
第三步 :点击 新建数据源 ,选择数据源类型为 Snowflake。
第四步:按下表填。用户名改成你的 Snowflake 用户名,密码填 Step 1 里拿到的 Programmatic Access Token;其余以邮件或 Snowflake 控制台为准。
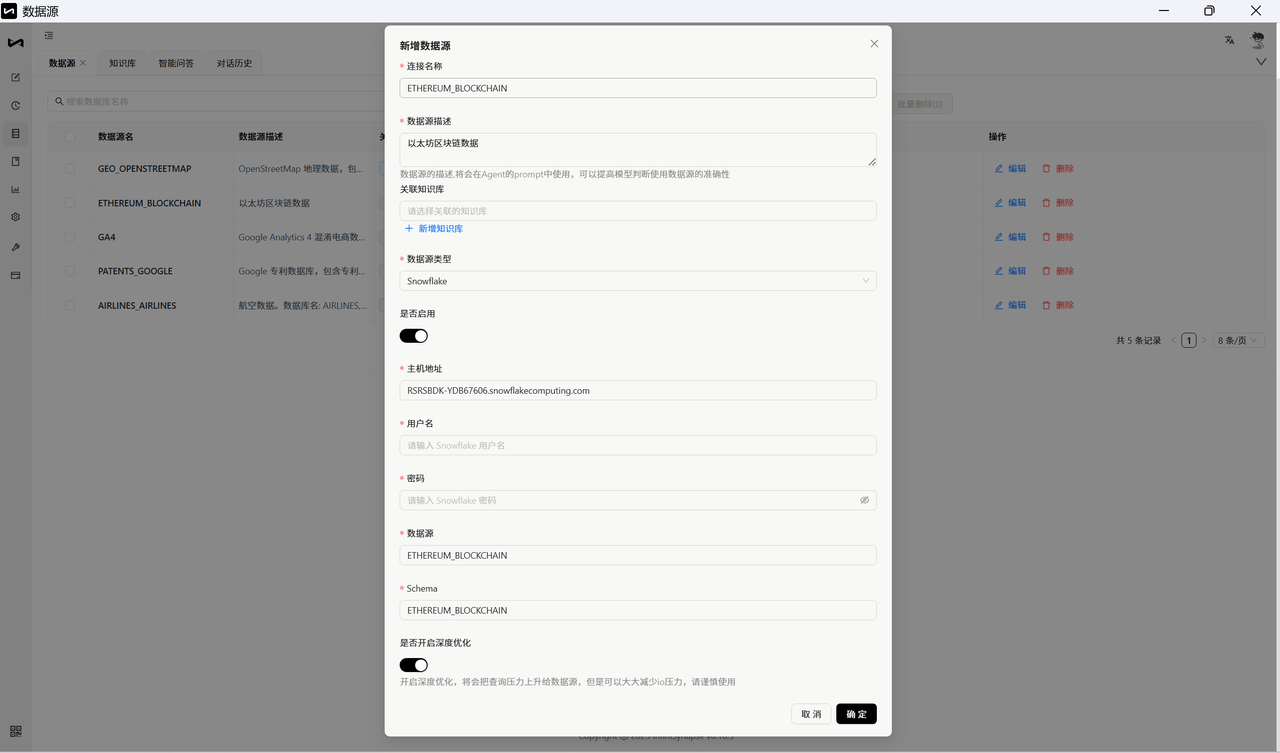
填完点 测试连接 。失败时检查:主机/账号是否与邮件一致、用户名是否正确、密码栏是否填了 Programmatic Access Token、网络/防火墙是否允许访问 Snowflake。
Spider2 账号只读、不能改库;勿公开账号名和主机地址。
Step 3: InfiniSynapse 知识库配置
知识库是 InfiniSynapse 实现精准语义理解的关键。虽然连接数据源后就能立即开始查询,但上传知识库文档能让 AI 更准确理解你的业务。知识库包含表的业务说明、字段含义等------这就像给 AI 一份业务手册,让它更懂你的行业术语。
P.S. 这完全是可选步骤。你可以先连接数据源直接开始查询,后续随时补充知识库来提升准确性。
创建知识库并关联数据源
第一步 :在左侧导航中点击 知识库。
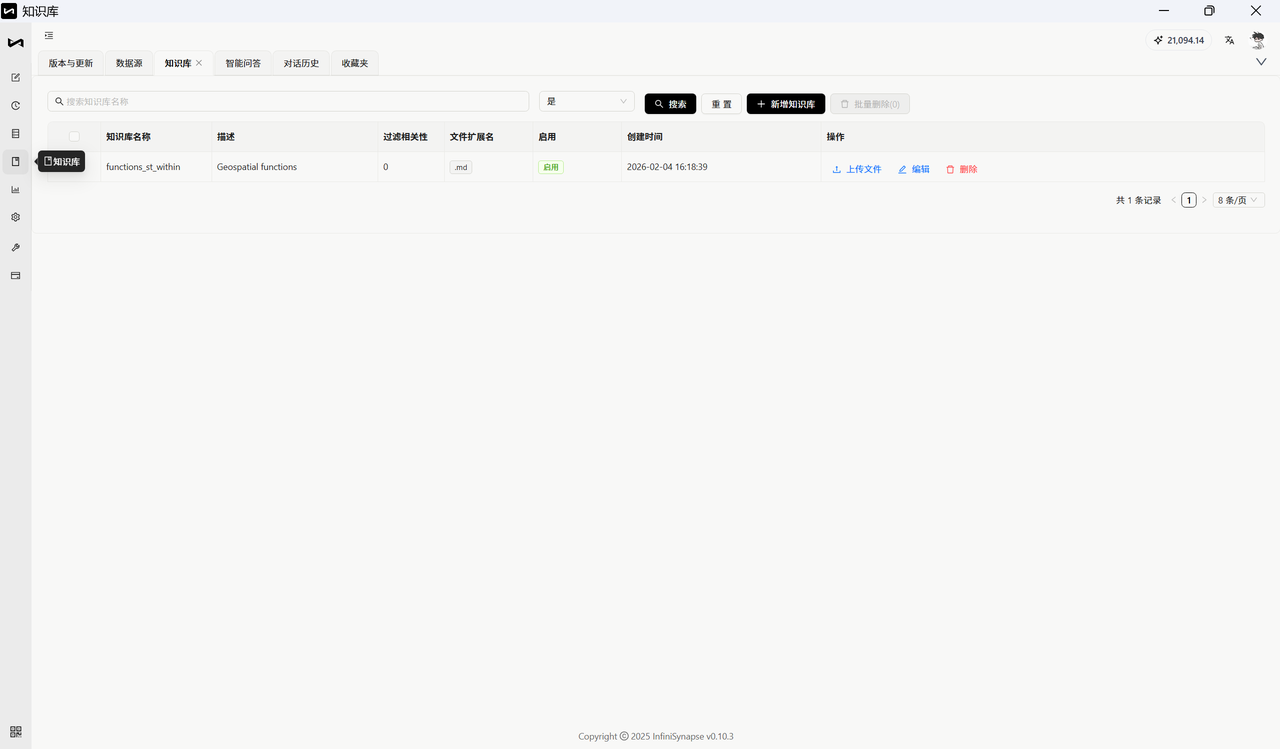
第二步 :点 新增知识库,选 Step 2 建的数据源,起个名字,点确定。
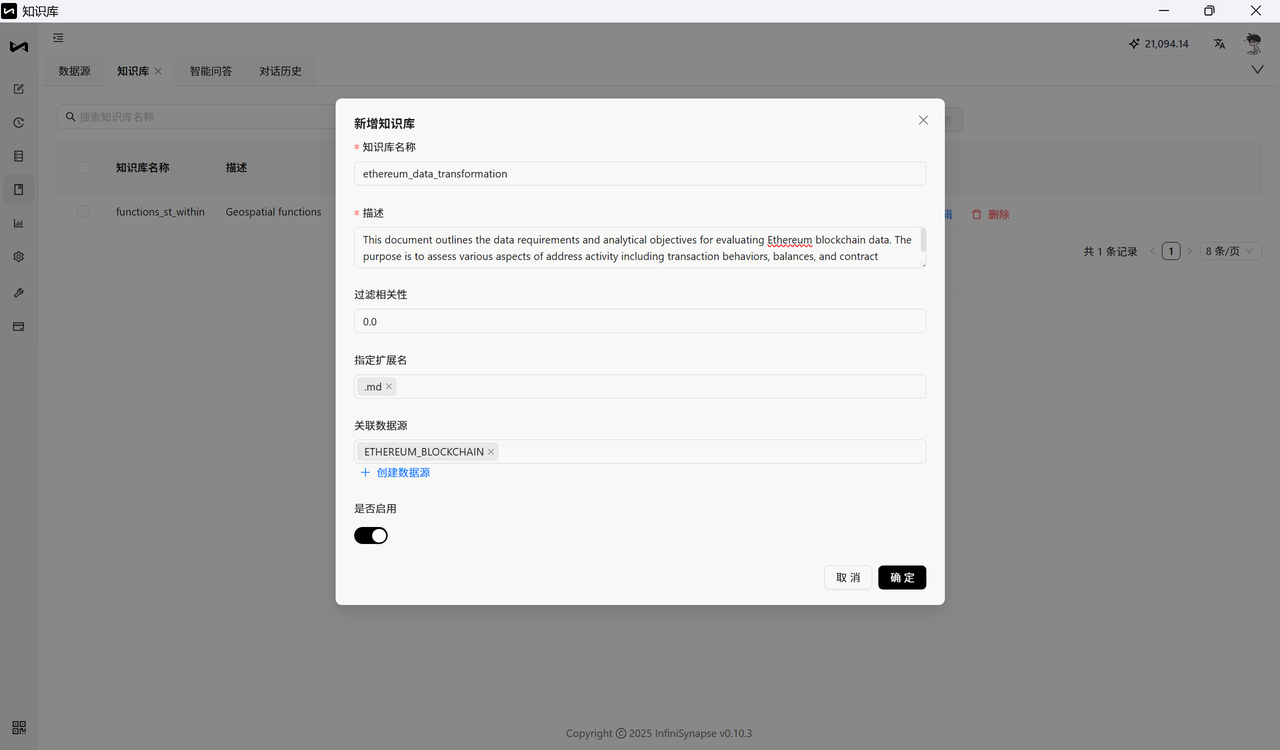
第三步:创建后会进入知识库页面,接着上传文档即可。
上传业务说明文档到知识库
为什么要上传文档? 文档里写的是「表是干什么的、字段什么意思」,AI 读这些内容后才能更好的把你的自然语言问题翻译成正确的 SQL。你可以用文末下载的 documents/ 里的现成文档。
- 在知识库界面中找到 上传文件 入口。
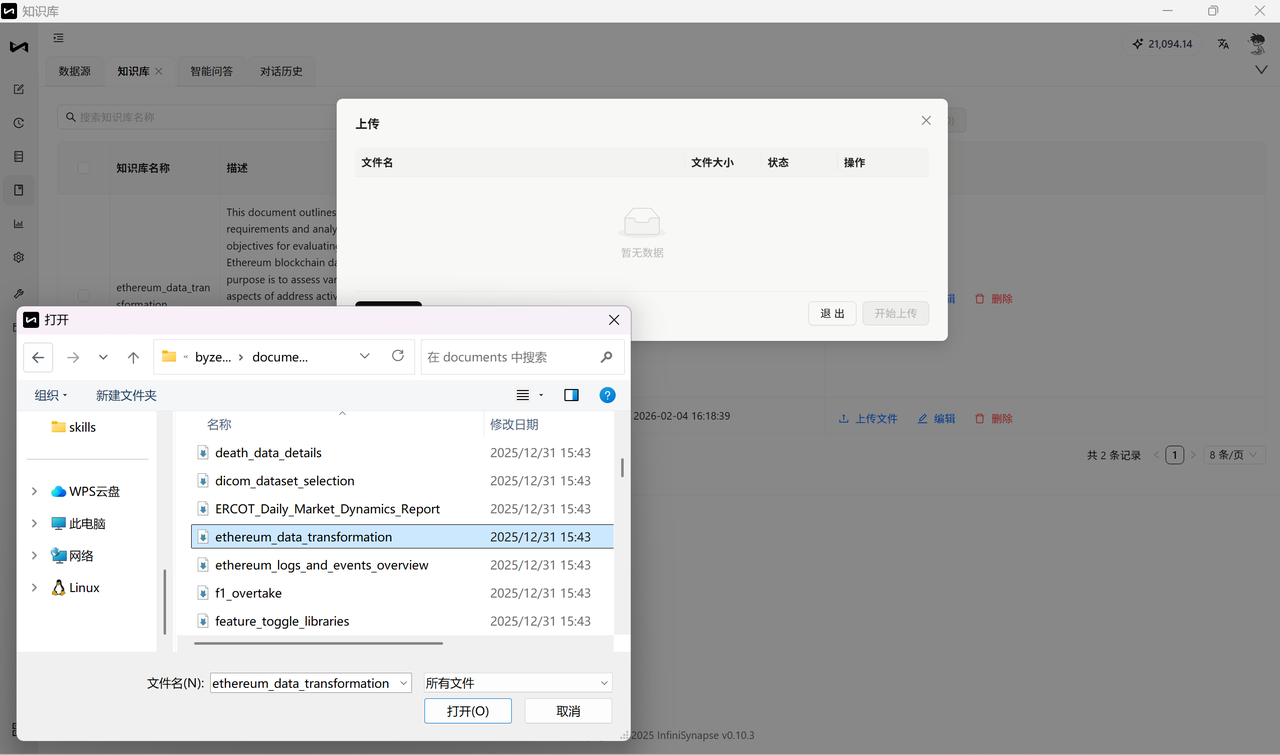
- 选择本地文件(支持 .md 等格式),点击「打开」,再点击「开始上传」。
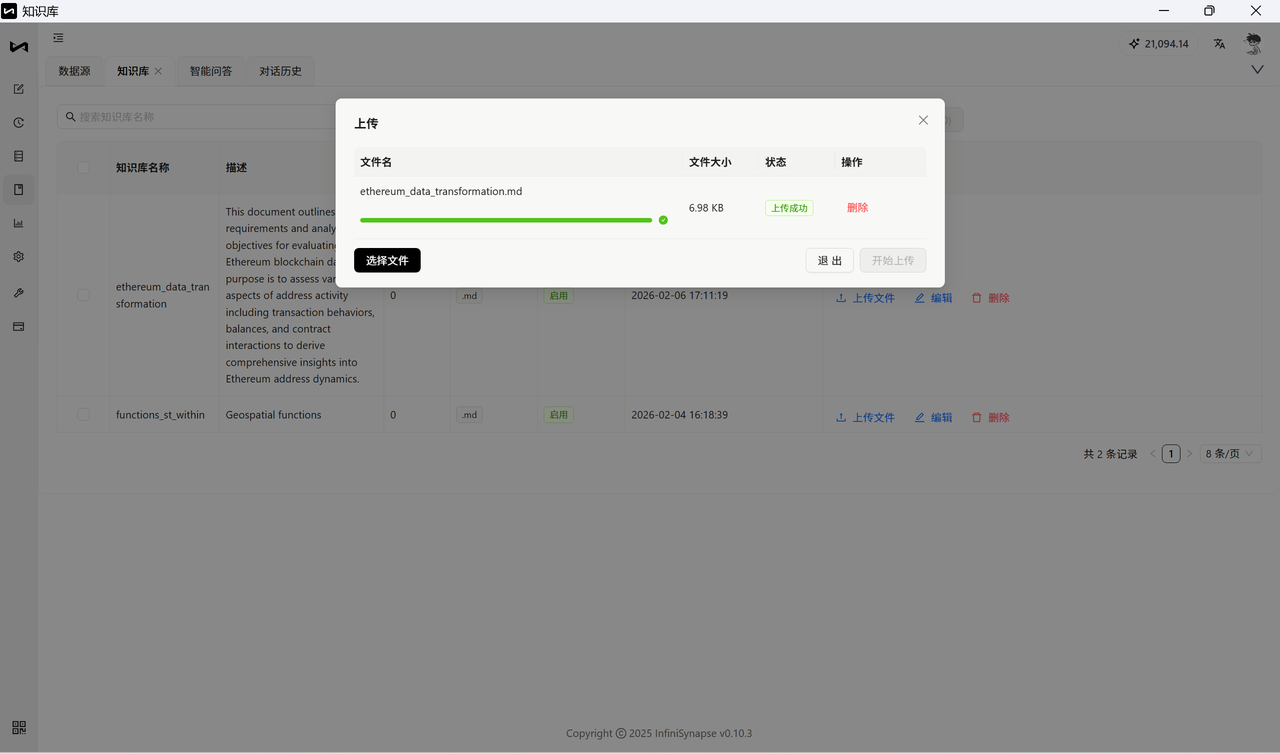
- 上传成功后,知识库即可在问答时引用这些文档内容。
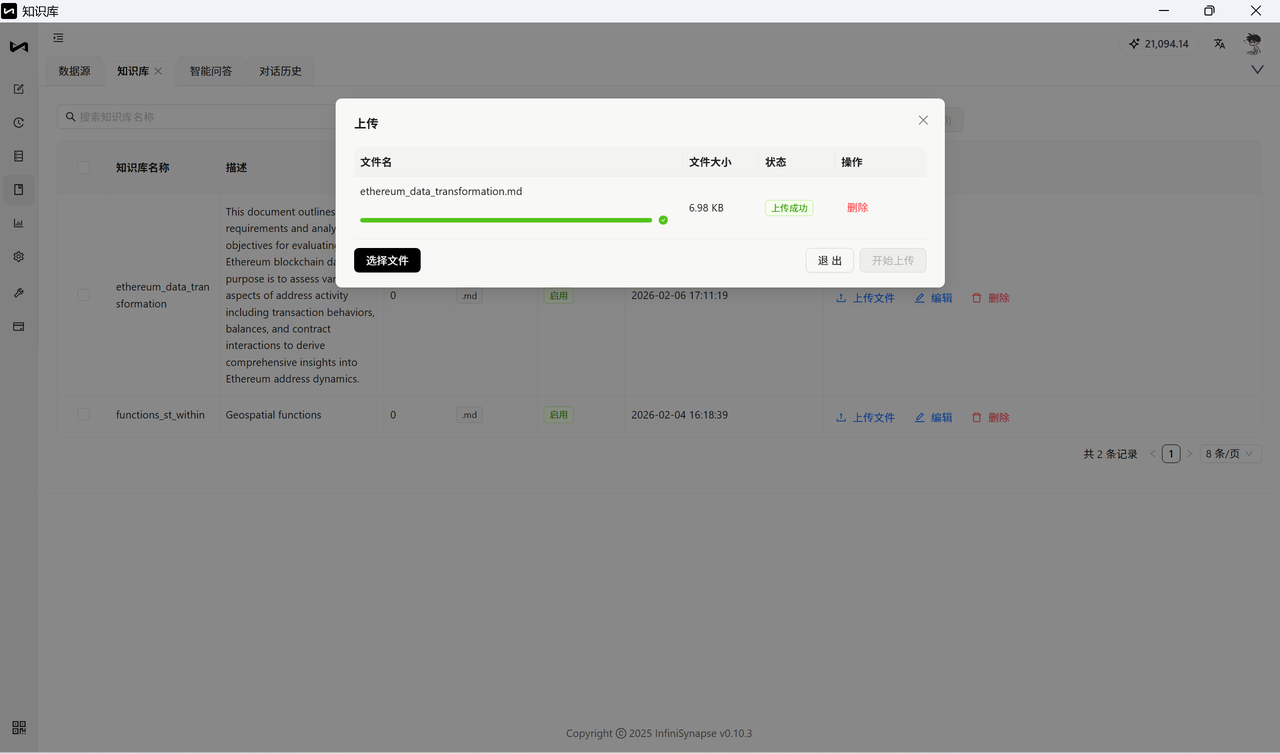
知识库构建最佳实践:
- 明确描述每张表的业务用途和使用场景
- 详细说明关键字段的业务含义和取值规则
- 建立业务术语与数据库字段的映射关系
- 记录常见的业务规则和计算逻辑
小技巧:写清表用途、重要字段含义、业务说法对应哪张表/哪个字段,提问时系统更容易理解你的需求。
Step 4:自然语言分析实战
现在就可以开始了!数据源已连接,直接在 InfiniSynapse 对话框中输入你的问题(比如「BNB 的总流通量是多少」),点击发送。系统会立即处理你的问题并返回结果------就这么简单。
**无需任何代码,无需了解数据库结构,只需提问,**你就会看到:
- 你的自然语言问题
- 系统自动生成的分析结果(表格或图表)
- 详细的回答和解释
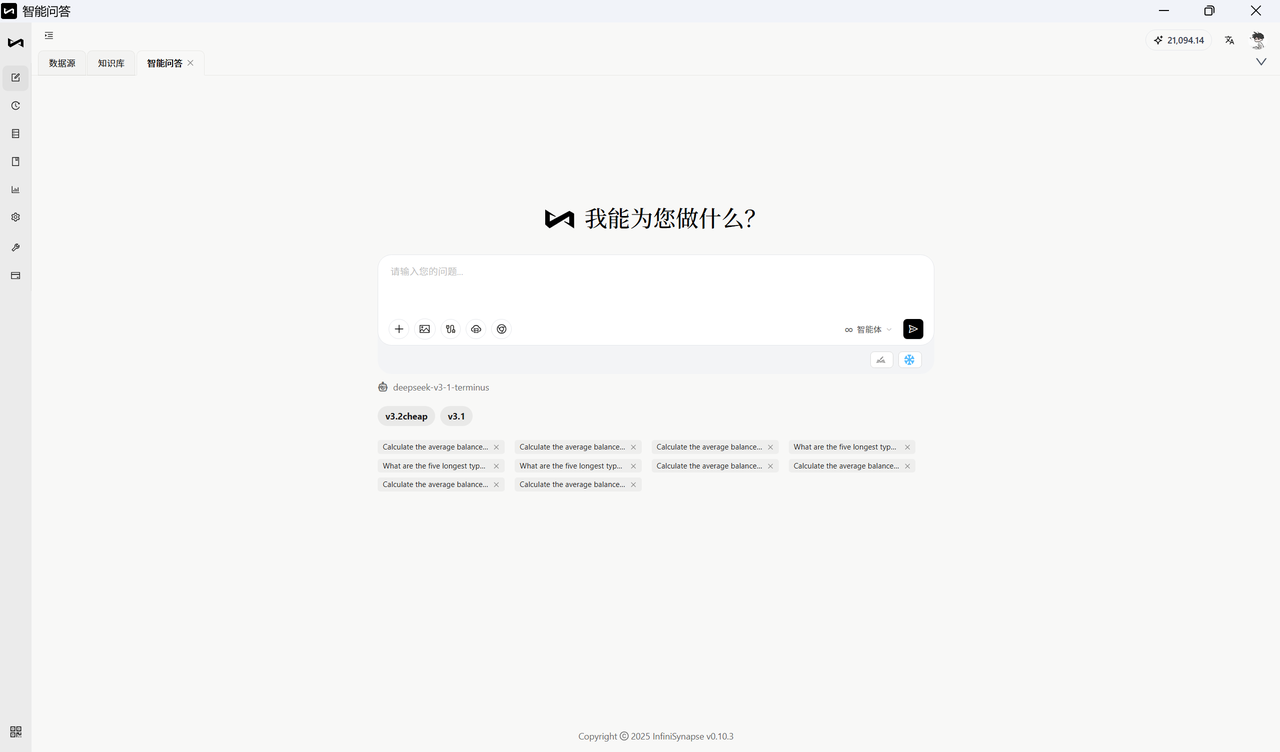
以下 3 个案例均基于 Spider2-Snow 的真实评测题目,完整展示了从自然语言提问到获得查询结果的全过程。配套资源包中的 snowflake_database_setting.json 还包含另外 544 道题目,你可以按照相同的方式继续实践。
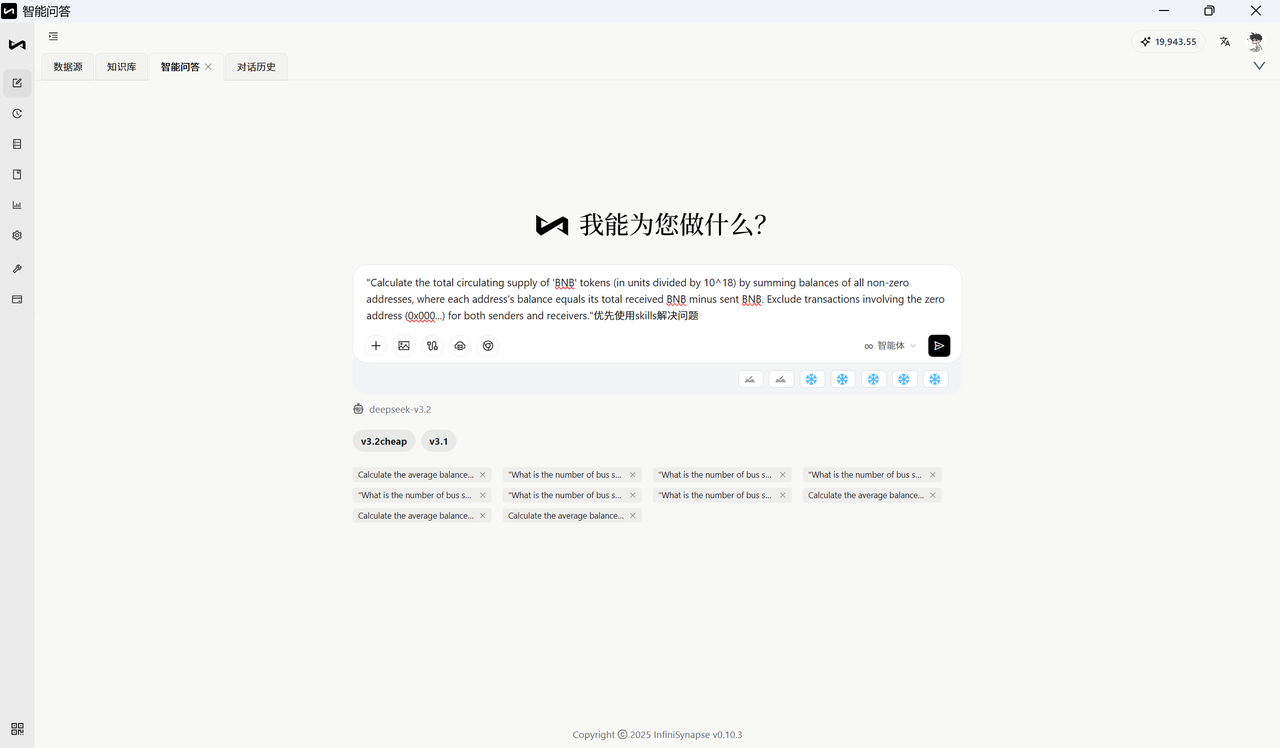
案例 1:sf_bq187
自然语言问题:Calculate the total circulating supply of 'BNB' tokens (in units divided by 10^18) by summing balances of all non-zero addresses, where each address's balance equals its total received BNB minus sent BNB. Exclude transactions involving the zero address (0x000...) for both senders and receivers.
数据源与知识库
数据源:ETHEREUM_BLOCKCHAIN(以太坊区块链数据)
主要 schema: ETHEREUM_BLOCKCHAIN
知识库文档:null
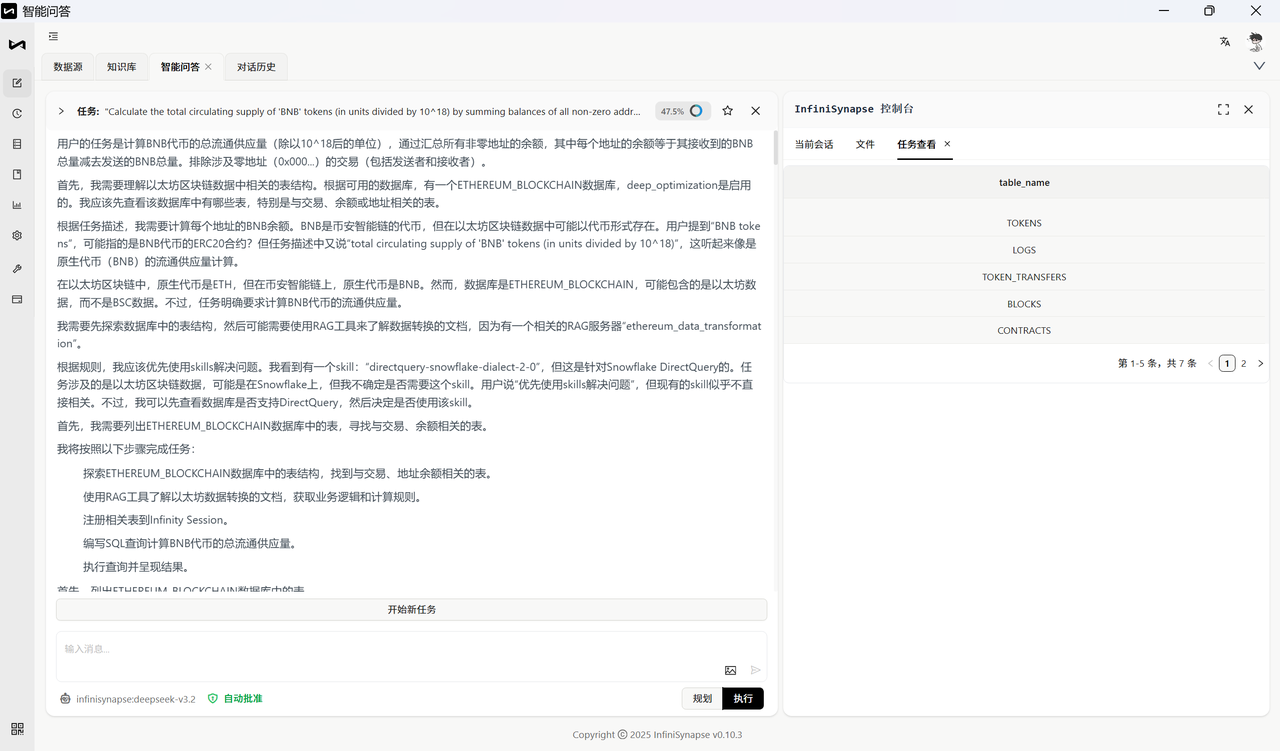
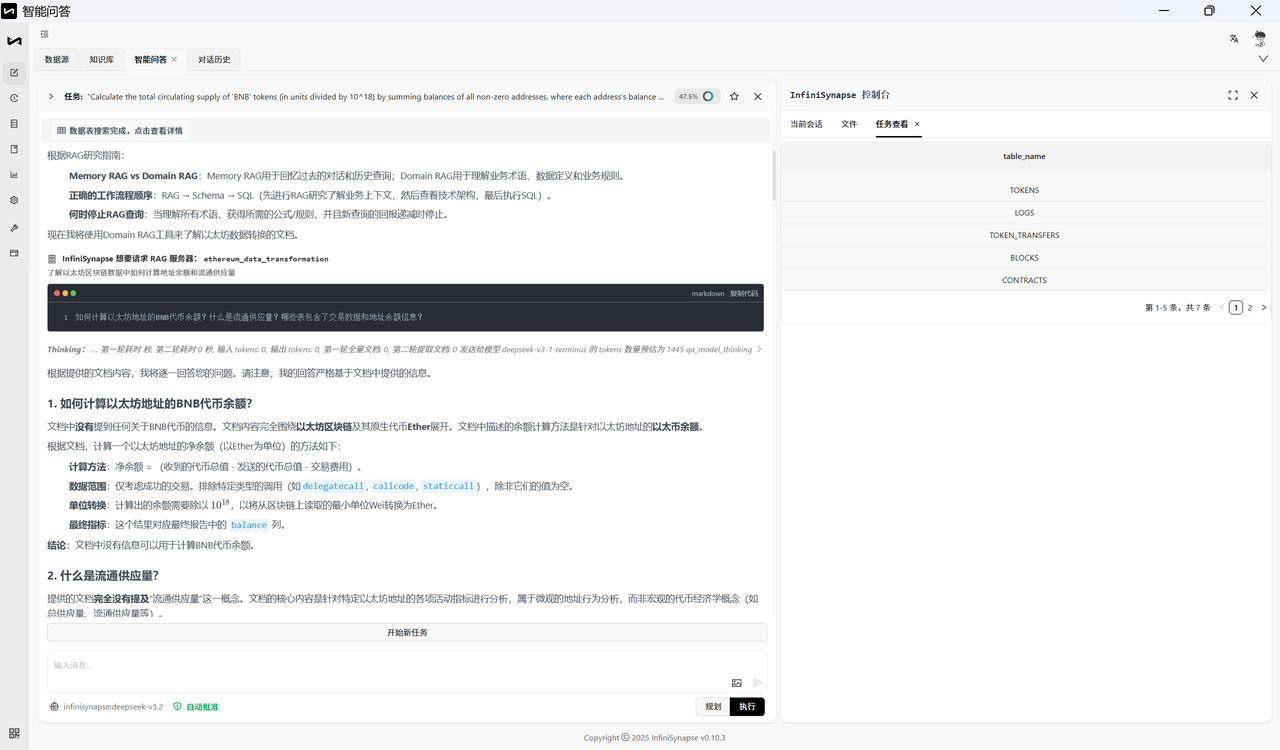
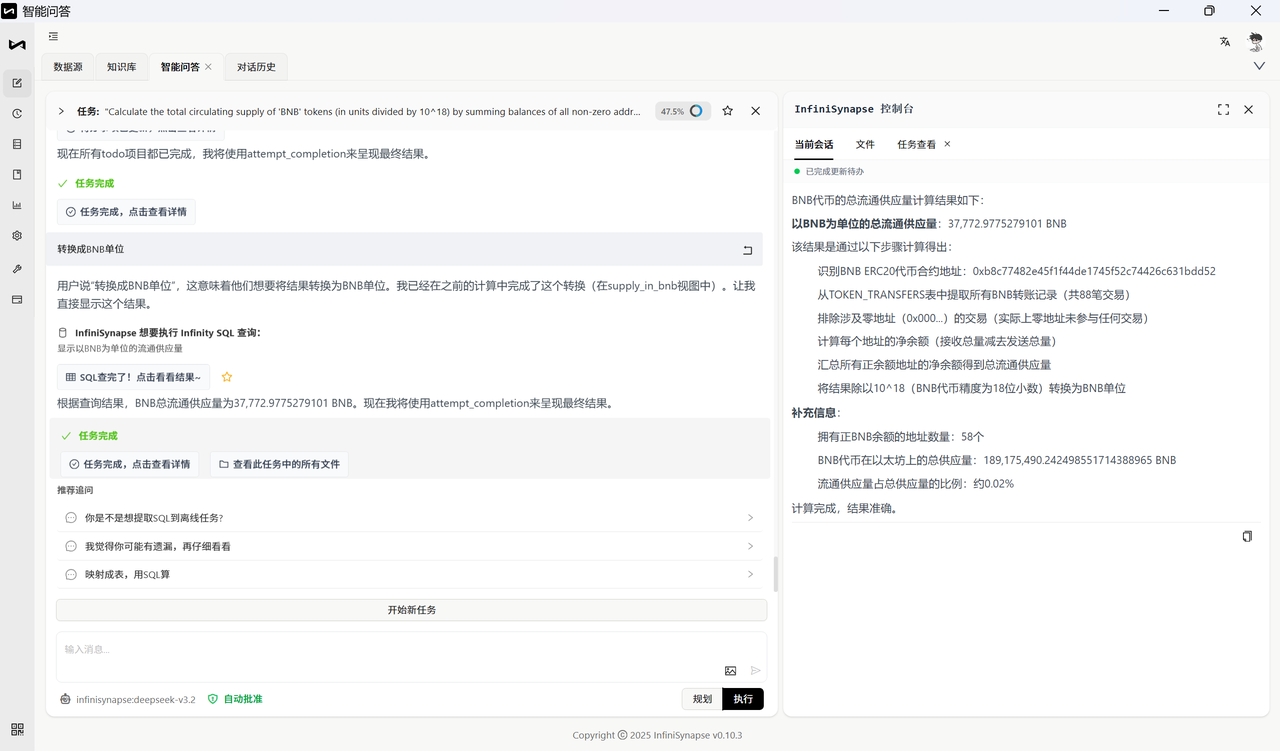
以下为标准答案:
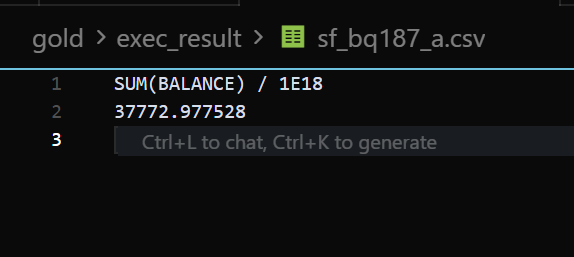
案例 2:sf_bq012
自然语言问题:Calculate the average balance (in quadrillions, 10^15) of the top 10 Ethereum addresses by net balance, including incoming and outgoing transfers from traces (only successful transactions and excluding call types like delegatecall, callcode, and staticcall), miner rewards (sum of gas fees per block), and sender gas fee deductions. Exclude null addresses and round the result to two decimal places.
数据源与知识库
数据源:ETHEREUM_BLOCKCHAIN(以太坊区块链数据)
主要 schema: ETHEREUM_BLOCKCHAIN
知识库文档:null
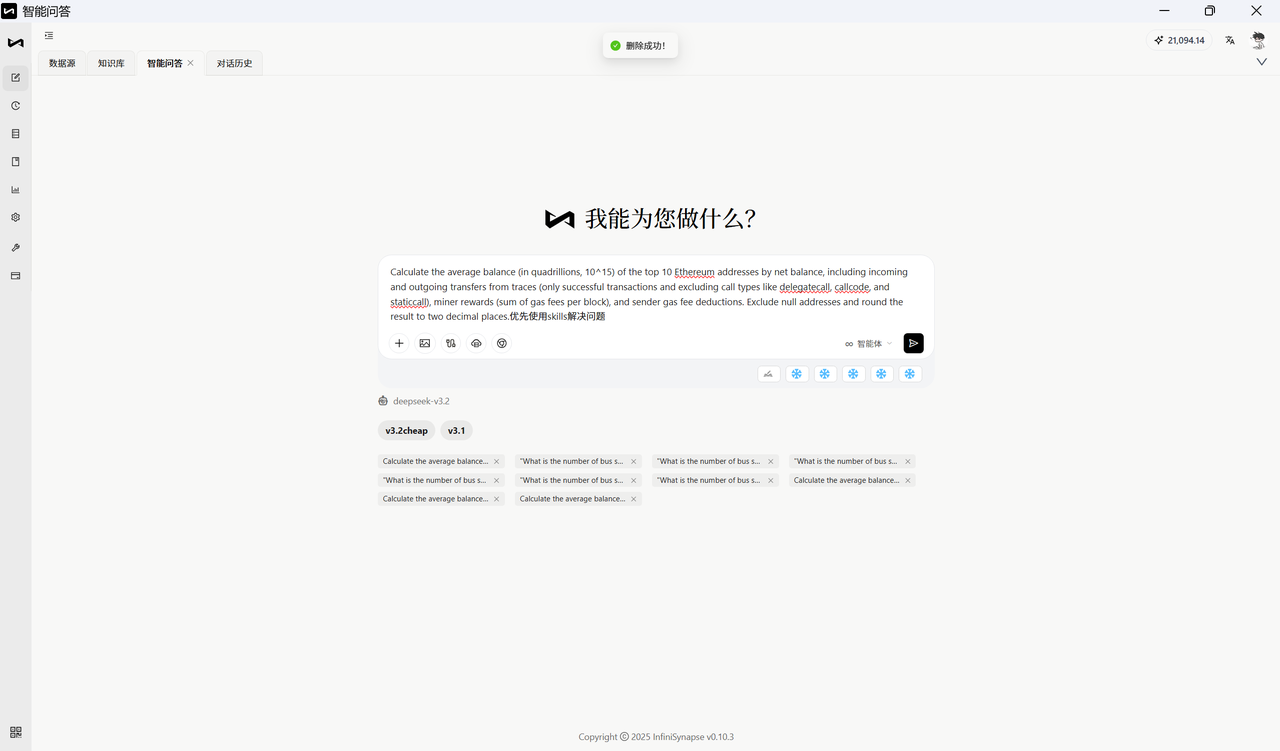
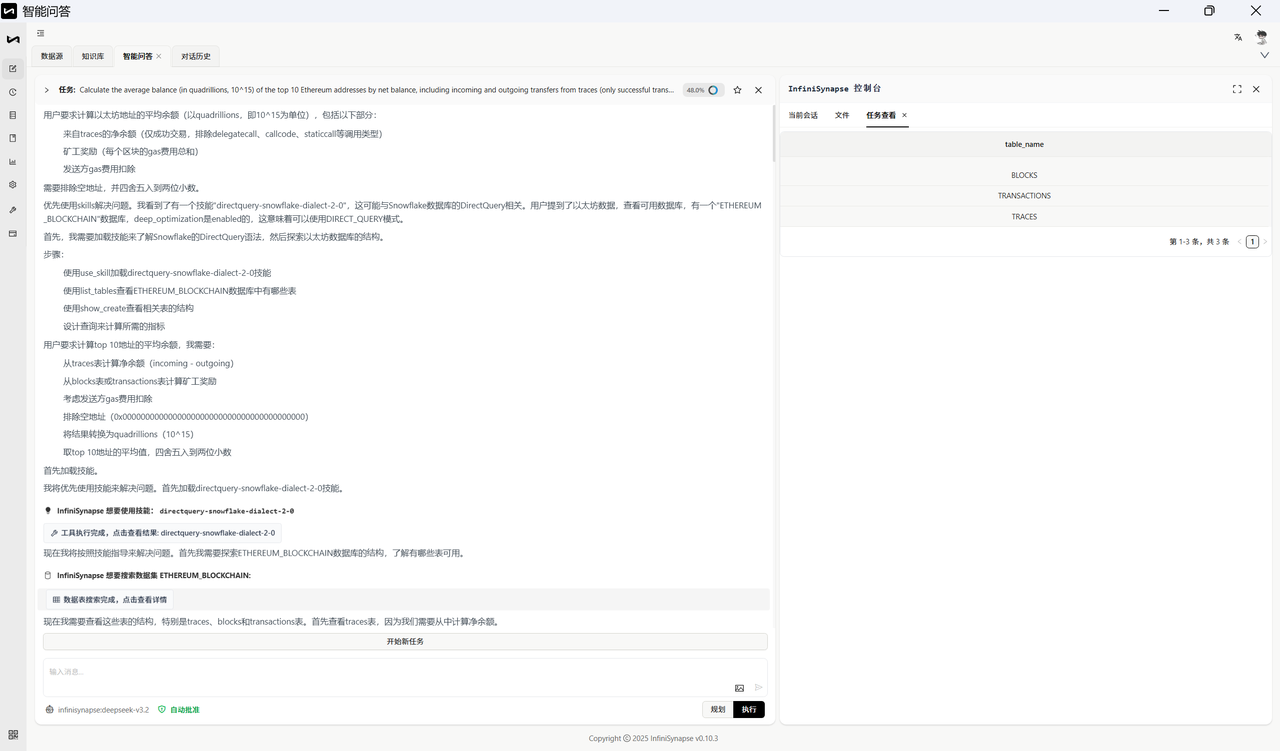

以下为标准答案:
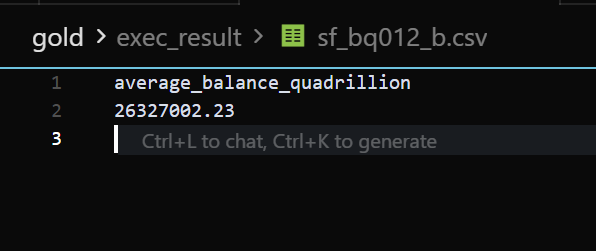
案例 3: sf_local009
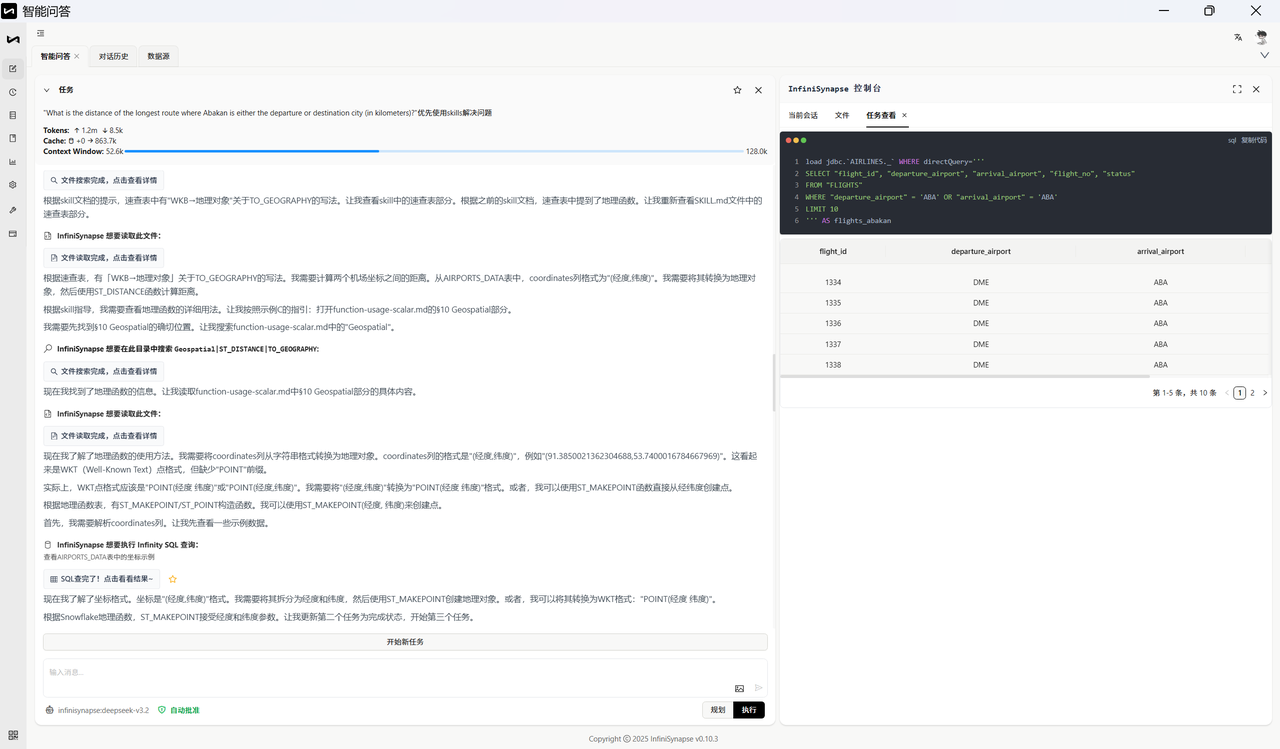
自然语言问题:What is the distance of the longest route where Abakan is either the departure or destination city (in kilometers)?
数据源与知识库
数据源:AIRLINES(航空数据)
主要 schema: AIRLINES
知识库文档:haversine_formula.md
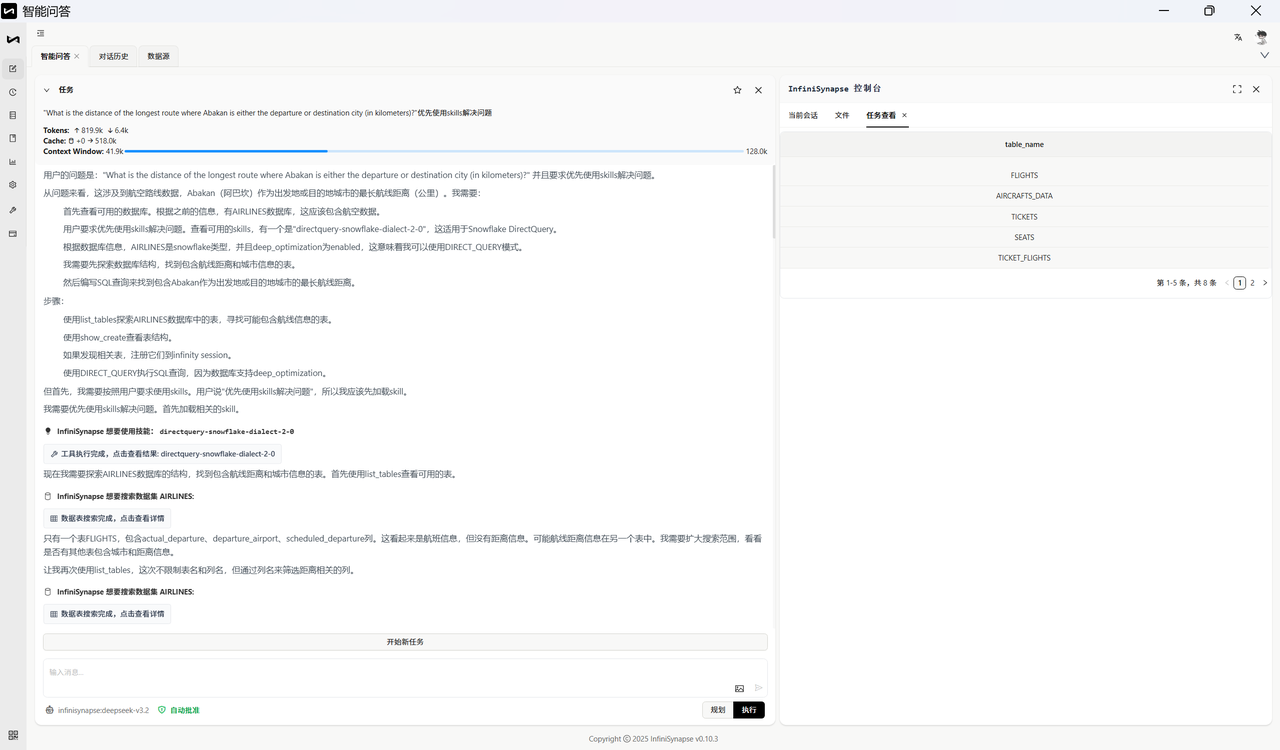
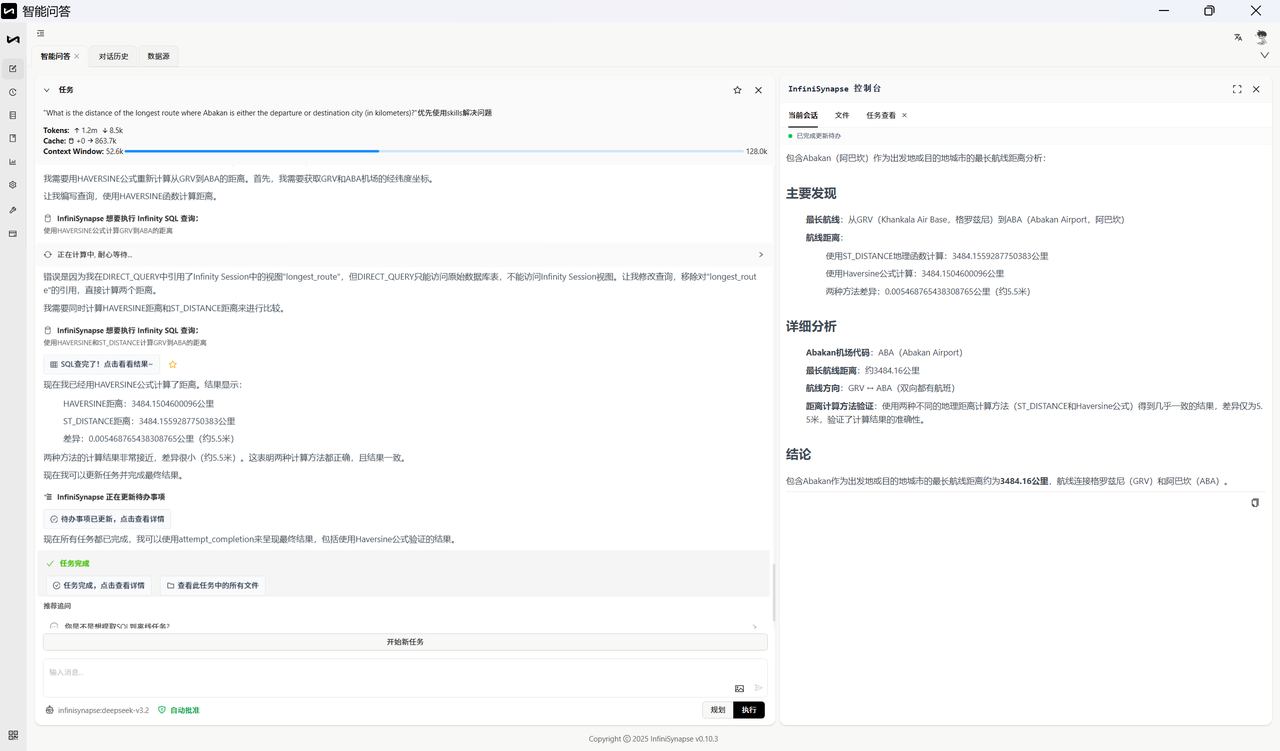
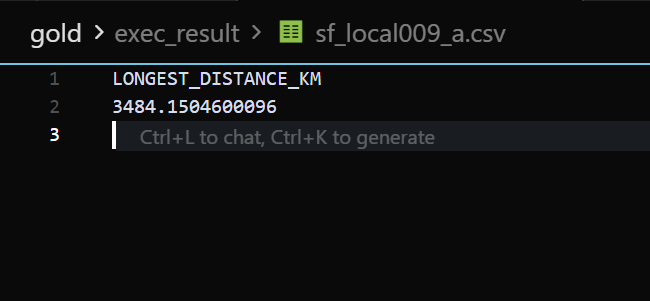
以下为标准答案:
想继续练手?配套资源里还有 547 道题,用 snowflake_database_setting.json 按题建数据源和知识库即可,具体步骤见资源汇总 里的「snowflake_database_setting.json 怎么用」。
最佳实践与常见问题
账号申请
提交 Spider2-Snow 访问申请后,官方团队会在 12 小时内完成账号创建,并通过电子邮件发送初始密码与登录说明。请确保填写有效的邮箱地址。
知识库构建建议
- 完整性:详细描述表的业务用途和字段含义
- 准确性:确保业务术语与数据库字段的映射关系准确无误
- 渐进式:可以先从核心表开始构建知识库,再逐步扩展
问题排查指南
- 连接失败:检查 Programmatic Access Token 是否正确、是否过期,确认主机地址与账号信息一致
- SQL 执行错误 :可参考配套资源中
gold/目录下的标准答案进行对比分析 - 语义理解偏差:检查知识库文档是否完整,必要时补充相关业务描述
资源汇总与配套文件下载
为帮助你快速上手并深入实践,我们提供了完整的 Spider2-Snow 配套资源包,包含 547 道企业级查询任务的完整配置、知识库文档和标准答案。
|---------------------------------|--------------------------------------------------------------------------------------------------------------|---------------------------------------------------------|
| 资源 | 是什么 | 你要做什么 |
| snowflake_database_setting.json | 自然语言题目 + 数据源配置模板。547 道题,每题一条:题目文本、连哪台 Snowflake、用哪些 schema、对应哪份外部知识文档。schema 名后面带 * 的,表示这道题极大概率会用到该 schema。 | 在 JSON 里挑一道题 → 按这条配置建数据源、挂知识库 → 把题目贴进 InfiniSynapse 提问。 |
| gold/ | 标答。每道题对应的标准 SQL 与评测结果,用来对照、自测。 | 做完题后打开 gold/ 里对应文件,对比自己的结果。 |
| documents/ | 外部知识文档(知识库来源)。每道题在 JSON 里会写清楚用哪一份文档(如 xxx.events.md),就在这个目录里找同名文件。 | 把该题用到的文档上传到 InfiniSynapse 知识库,再提问。 |
推荐顺序 :下载配套资源 ZIP → 在 JSON 里选一道题的 instance_id → 按该条建数据源(主机、schema、密码用 Step 1 的 Token)→ 到 documents/ 找到 external_knowledge 里写的文档,上传到知识库 → 在 InfiniSynapse 输入该题的 instruction 提问 → 用 gold/ 里对应文件对答案。
使用流程
- 下载资源包:获取完整的配套资源 ZIP 文件
- 选择题目 :在
snowflake_database_setting.json中选择一道题目(通过instance_id标识) - 配置数据源:根据题目配置信息在 InfiniSynapse 中创建 Snowflake 数据源(使用 Step 1 获取的 Token)
- 构建知识库 :从
documents/目录找到external_knowledge字段指定的文档,上传到知识库 - 执行查询 :将题目的
instruction字段内容输入 InfiniSynapse - 验证结果 :使用
gold/目录中的标准答案进行对比验证
snowflake_database_setting.json 一条长什么样
每条就是一个「题目 + 数据源 + 知识库文档」的模板,例如(sf_bq011):
{
"instance_id": "sf_bq011",
"instruction": "How many distinct pseudo users had positive engagement time...",
"external_knowledge": "ga4_obfuscated_sample_ecommerce.events.md",
"数据源": "GA4",
"数据源描述": "Google Analytics 4 混淆电商数据集...",
"数据源类型": "Snowflake",
"主机地址": "RSRSBDK-YDB67606.snowflakecomputing.com",
"schema": ["GA4_OBFUSCATED_SAMPLE_ECOMMERCE *", "INFORMATION_SCHEMA", "PUBLIC"]
}- 做题用 :
instruction= 自然语言问题,直接贴进 InfiniSynapse。 - 建数据源用 :
主机地址、schema、数据源/数据源描述;密码用 Step 1 的 3.3 的 Programmatic Access Token. - 挂知识库用 :
external_knowledge= 要在documents/里找的文件名,上传到 InfiniSynapse 知识库。 - schema 带
*:如GA4_OBFUSCATED_SAMPLE_ECOMMERCE *,表示这道题很大概率会查这个 schema,建数据源时优先填选该 schema 即可。
配套资源下载
上表三项(JSON、gold、documents)已打包为一个 ZIP。请点击本文文末的附件下载。
其他资源
Spider2 官方 GitHub
需要在本机跑 Spider2 全量代码、基线或本地评测时,可到官方仓库下载:
- 仓库:https://github.com/xlang-ai/Spider2
- 下载:打开仓库 → 点 Code → Download ZIP 解压;或
git clone https://github.com/xlang-ai/Spider2.git。 - 内容:spider2-snow、spider2-lite、spider2-dbt 等评测与基线(如 spider-agent-lite)、环境配置等,详见仓库 README 与 Spider 2.0 官网。
- 批量脚本仓库:https://github.com/siyu-wu529/infinisynapse-spider2snow