Transformer实战------Transformer跨语言文本分类
-
- [0. 前言](#0. 前言)
- [1. 跨语言文本分类](#1. 跨语言文本分类)
- [2. 数据加载与处理](#2. 数据加载与处理)
- [3. 模型训练与测试](#3. 模型训练与测试)
- 相关链接
0. 前言
我们已经了解了跨语言模型能够理解不同语言,并且相似的句子(无论为何种语言)在语义向量空间中彼此接近。但问题在于,如何在样本较少的情况下,利用这种能力来解决实际问题。
1. 跨语言文本分类
例如,假设正在为一个聊天机器人开发意图分类系统,其中第二种语言的样本很少甚至没有;而第一语言有足够的样本。在这种情况下,可以冻结跨语言模型本身,只训练一个分类器来完成任务。训练好的分类器可以在第二种语言上进行测试,而不是在用于训练的语言上进行测试。
在本节中,将学习如何用英语训练一个跨语言模型进行文本分类,并在其他语言上进行测试。我们选择了一种低资源语言------高棉语 (Khmer),互联网上关于高棉语的资源很少,很难找到高质量的数据集来训练模型。我们将使用 IMDb 电影评论数据集,测试模型在未经训练的语言上的表现。
模型训练与测试流程如下图所示。模型在左侧的训练数据上进行训练,然后将该模型应用于右侧的测试集。需要注意的是,机器翻译 (Machine Translation, MT) 和句子编码映射在这一流程中起着重要作用。
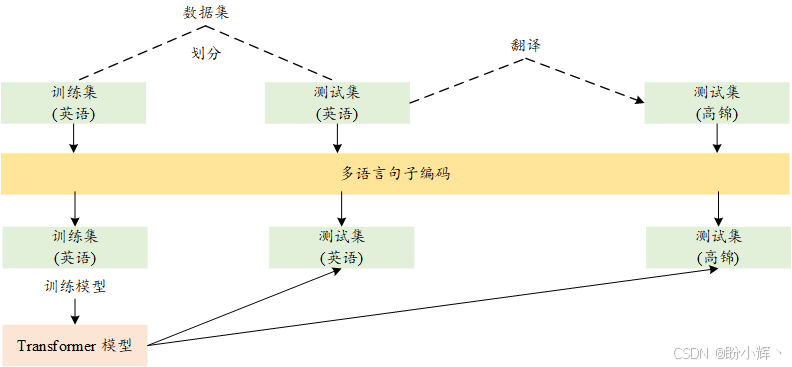
2. 数据加载与处理
(1) 首先,加载数据集:
python
from datasets import load_dataset
imdb = load_dataset("imdb")(2) 在使用数据集之前打乱样本的顺序:
python
imdb = imdb.shuffle()(3) 接下来,从数据集中划分出一个测试集,并将其翻译成高棉语。为此,可以使用 Google 翻译等翻译应用。首先,将数据集保存为 Excel 格式:
python
imdb_x = [x for x in imdb['train'][:1000]['text']]
labels = [x for x in imdb['train'][:1000]['label']]
import pandas as pd
pd.DataFrame(imdb_x,
columns=["text"]).to_excel(
"imdb.xlsx",
index=None) (4) 之后,可以将其上传到翻译应用(如 Google 翻译)中并获取该数据集的高棉语翻译版本:
(5) 选择并上传文档后,将获得高棉语的翻译版本,可以将其复制并粘贴到 Excel 文件中,同样需要将其保存为 Excel 格式。最终得到一个翻译自原始英语数据集的 Excel 文档,使用 pandas 读取该文件:
python
pd.read_excel("KHMER.xlsx") 结果如下所示:

(6) 获取文本部分:
python
imdb_khmer = list(pd.read_excel("KHMER.xlsx").text) (7) 得到两种语言的文本和标签后,划分训练和测试验证集:
python
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y, khmer_train, khmer_test = train_test_split(imdb_x, labels, imdb_khmer, test_size = 0.2, random_state = 1) (8) 接下来,使用 XLM-R 跨语言模型为这些句子提供表示。首先,加载模型:
python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("stsb-xlm-r-multilingual") (9) 获取句子的向量表示:
python
encoded_train = model.encode(train_x)
encoded_test = model.encode(test_x)
encoded_khmer_test = model.encode(khmer_test) (10) 将标签转换为 NumPy 格式,因为在使用 Keras 模型的 fit 函数时,TensorFlow 和 Keras 需要处理 NumPy 数组:
python
import numpy as np
train_y = np.array(train_y)
test_y = np.array(test_y) 3. 模型训练与测试
(1) 创建模型对表示进行分类:
python
import tensorflow as tf
input_ = tf.keras.layers.Input((768,))
classification = tf.keras.layers.Dense(
1,
activation="sigmoid")(input_)
classification_model = tf.keras.Model(input_, classification)
classification_model.compile(
loss=tf.keras.losses.BinaryCrossentropy(),
optimizer="Adam",
metrics=["accuracy", "Precision", "Recall"]) (2) 训练模型:
classification_model.fit(
x = encoded_train,
y = train_y,
validation_data=(encoded_test, test_y),
epochs = 20) 模型在 20 个训练 epoch 的性能变化如下所示:
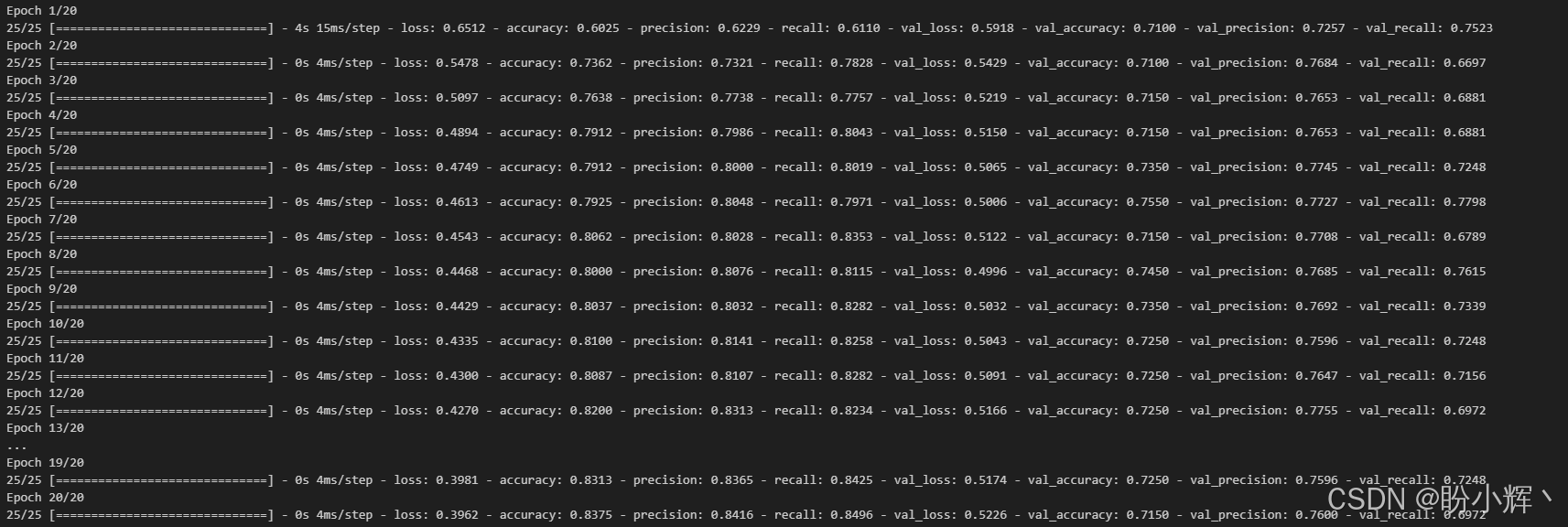
可以看到,我们使用英文测试集来评估模型在各个训练 epoch 的表现,最终结果如下:
shell
val_loss: 0.5226
val_accuracy: 0.7150
val_precision: 0.7600
val_recall: 0.6972(3) 我们已经训练了模型并在英文数据集上进行了测试,接下来,我们在高棉语测试集上进行测试:
python
classification_model.evaluate(x = encoded_khmer_test,
y = test_y) 测试结果如下所示:
shell
val_loss: 0.5944913625717163
val_accuracy: 0.7250000238418579
val_precision: 0.7014925479888916
val_recall: 0.8623853325843811我们已经了解了如何利用跨语言模型在低资源语言中发挥其能力。当在某些情况下,训练模型的数据非常稀缺甚至没有数据时,能够使用这种能力能够发挥重要作用。
相关链接
Transformer实战(1)------词嵌入技术详解
Transformer实战(2)------循环神经网络详解
Transformer实战(3)------从词袋模型到Transformer:NLP技术演进
Transformer实战(4)------从零开始构建Transformer
Transformer实战(5)------Hugging Face环境配置与应用详解
Transformer实战(6)------Transformer模型性能评估
Transformer实战(7)------datasets库核心功能解析
Transformer实战(8)------BERT模型详解与实现
Transformer实战(9)------Transformer分词算法详解
Transformer实战(10)------生成式语言模型 (Generative Language Model, GLM)
Transformer实战(11)------从零开始构建GPT模型
Transformer实战(12)------基于Transformer的文本到文本模型
Transformer实战(13)------从零开始训练GPT-2语言模型
Transformer实战(14)------微调Transformer语言模型用于文本分类
Transformer实战(15)------使用PyTorch微调Transformer语言模型
Transformer实战(16)------微调Transformer语言模型用于多类别文本分类
Transformer实战(17)------微调Transformer语言模型进行多标签文本分类
Transformer实战(18)------微调Transformer语言模型进行回归分析
Transformer实战(19)------微调Transformer语言模型进行词元分类
Transformer实战(20)------微调Transformer语言模型进行问答任务
Transformer实战(21)------文本表示(Text Representation)
Transformer实战(22)------使用FLAIR进行语义相似性评估
Transformer实战(23)------使用SBERT进行文本聚类与语义搜索
Transformer实战(24)------通过数据增强提升Transformer模型性能
Transformer实战(25)------自动超参数优化提升Transformer模型性能
Transformer实战(26)------通过领域适应提升Transformer模型性能
Transformer实战(27)------参数高效微调(Parameter Efficient Fine-Tuning,PEFT)
Transformer实战(28)------使用 LoRA 高效微调 FLAN-T5
Transformer实战(29)------大语言模型(Large Language Model,LLM)
Transformer实战(30)------Transformer注意力机制可视化
Transformer实战(31)------解释Transformer模型决策
Transformer实战(32)------Transformer模型压缩
Transformer实战(33)------高效自注意力机制
Transformer实战(34)------多语言和跨语言Transformer模型
Transformer实战(35)------跨语言相似性任务