1 题目
给你一个链表的头节点 head 和一个特定值x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。
你应当 保留 两个分区中每个节点的初始相对位置。
示例 1:
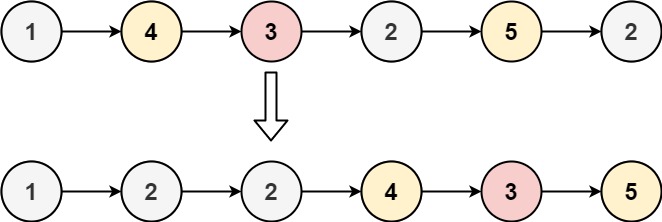
输入:head = [1,4,3,2,5,2], x = 3
输出:[1,2,2,4,3,5]示例 2:
输入:head = [2,1], x = 2
输出:[1,2]提示:
- 链表中节点的数目在范围
[0, 200]内 -100 <= Node.val <= 100-200 <= x <= 200
2 代码实现
c++
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* partition(ListNode* head, int x) {
if (head == nullptr || head -> next == nullptr){
return head ;
}
ListNode* dummy_a = new ListNode (0);
ListNode* dummy_b = new ListNode (0);
ListNode* cur_a = dummy_a;
ListNode* cur_b = dummy_b;
while (head != nullptr ){
if (head -> val < x ){
cur_a -> next = head ;
cur_a = cur_a -> next ;
}else {
cur_b -> next = head ;
cur_b = cur_b -> next ;
}
head = head -> next ;
}
cur_a -> next = dummy_b -> next ;
cur_b -> next = nullptr ;
ListNode* new_head = dummy_a -> next ;
delete dummy_a;
delete dummy_b;
return new_head;
}
};js
javascript
/**
* Definition for singly-linked list.
* function ListNode(val, next) {
* this.val = (val===undefined ? 0 : val)
* this.next = (next===undefined ? null : next)
* }
*/
/**
* @param {ListNode} head
* @param {number} x
* @return {ListNode}
*/
var partition = function(head, x) {
if (head == null){
return head ;
}
const dummy_a = new ListNode(0);
const dummy_b = new ListNode(0);
let cur_a = dummy_a;
let cur_b = dummy_b;
while (head != null ){
if (head.val < x ){
cur_a.next = head ;
cur_a = cur_a.next ;
}else{
cur_b.next = head ;
cur_b = cur_b.next ;
}
head = head.next ;
}
cur_a.next = dummy_b.next;
cur_b.next =null;
return dummy_a.next;
};思考
不知道怎么把这个val散落的节点合一起,不知道怎么搞,怎么弄啊。采用什么数据结构好啊,怎么连在一起呢?新建一个链表吗,那节点很散啊怎么防止丢失呢?判断的条件其实还好,本来就是有序的,小于特定节点的值筛出来,不知道怎么实现。怎么搞,不会算法。
题解
解题思路
这个问题的核心是拆分再合并,不需要复杂的数据结构,只用链表的基本操作就能解决:
- 准备两个「虚拟头节点」(哨兵节点):
dummy_small:用来串联所有小于 x 的节点;dummy_large:用来串联所有大于等于 x 的节点。
- 遍历原链表,把每个节点根据值的大小,分别挂到
dummy_small或dummy_large的链表尾部; - 遍历完成后,把
dummy_large的链表接在dummy_small链表的尾部; - 注意把
dummy_large链表的最后一个节点的next置为nullptr,避免形成循环链表; - 最终返回
dummy_small->next就是结果链表的头节点。
看了这个思路提示以后我自己写写看呢,先拆分,再合并。确实,当时想到要一步到位是有点难啊。
自己写的代码依旧出错
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* partition(ListNode* head, int x) {
if (head == nullptr || head -> next == nullptr){
return head ;
}
ListNode* dummy_a = new ListNode (0);
ListNode* dummy_b = new ListNode (0);
while (head!= nullptr){
if (head -> val < x ){
dummy_a -> next = head ;
}else {
dummy_b -> next = head ;
}
head = head -> next ;
}
ListNode* a_end = dummy_a ;
while (a_end != nullptr){
a_end = a_end -> next ;
}
a_end -> next = dummy_b -> next ;
return dummy_a;
}
};错误 1:「覆盖问题」------ 没有保留链表的节点链
你写的这段代码:
cpp
while (head!= nullptr){
if (head -> val < x ){
dummy_a -> next = head ; // 问题点
}else {
dummy_b -> next = head ; // 问题点
}
head = head -> next ;
}👉 思考:每次循环都直接把 dummy_a->next 赋值为当前 head,这意味着前一次挂的节点会被覆盖。比如原链表是 1,2,x=3:
- 第一次循环:
dummy_a->next = 1; - 第二次循环:
dummy_a->next = 2(1 被覆盖了,链表只剩 2,而不是 1->2)。✅ 引导:你需要一个「尾指针」,比如cur_a = dummy_a,每次把节点挂到cur_a->next,然后cur_a往后移,才能保留节点的顺序。
错误 2:「空指针访问」------ 找 dummy_a 末尾的逻辑错误
你写的这段代码:
cpp
ListNode* a_end = dummy_a ;
while (a_end != nullptr){
a_end = a_end -> next ;
}
a_end -> next = dummy_b -> next ; // 问题点👉 思考:while (a_end != nullptr) 会一直循环到 a_end 变成 nullptr,然后你去访问 a_end->next ------ 这就是开头遇到的「空指针访问错误」!✅ 引导:找链表末尾的正确逻辑是「循环到 a_end->next == nullptr 为止」,此时 a_end 就是最后一个节点。
错误 3:「返回值错误」------ 返回了虚拟头节点本身
你写的 return dummy_a;:👉 思考:dummy_a 是你创建的「虚拟头节点」(值为 0),而题目要求返回的是有效节点的头 (比如示例 1 要返回 1,而不是 0)。✅ 引导:应该返回 dummy_a->next,这才是真正的结果链表头。
错误 4:「循环链表」------ 没有处理 dummy_b 末尾的 next
👉 思考:原链表最后一个节点的 next 可能指向其他节点,比如原链表是 1,4,3,x=3:
dummy_b挂了 4、3,最后一个节点是 3,它的next原本指向nullptr(没问题);- 但如果原链表是 3,2,1,x=2:
dummy_b挂了 3,3 的next原本指向 2,你直接把dummy_b接在dummy_a后,会导致链表循环(3->2->1->3...)。✅ 引导:需要把dummy_b链表的最后一个节点的next置为nullptr。
第三步:给你「修正方向」(不是直接答案,你自己改)
按照以下步骤修改你的代码,每改一步都思考为什么:
-
给
dummy_a和dummy_b各加一个「尾指针」:cppListNode* cur_a = dummy_a; // 跟踪dummy_a的末尾 ListNode* cur_b = dummy_b; // 跟踪dummy_b的末尾 -
遍历原链表时,用尾指针挂节点,挂完后尾指针后移:
cppwhile (head!= nullptr){ if (head -> val < x ){ cur_a->next = head; cur_a = cur_a->next; // 尾指针后移 }else { cur_b->next = head; cur_b = cur_b->next; // 尾指针后移 } head = head -> next ; } -
修正「找 dummy_a 末尾」的逻辑:
cpp// 不需要再循环找末尾了!cur_a 已经是dummy_a的最后一个节点 // 直接用 cur_a 即可,删掉你原来找a_end的循环 cur_a->next = dummy_b->next; -
处理循环链表问题:
cppcur_b->next = nullptr; // 把dummy_b末尾的next置空 -
修正返回值:
cppListNode* result = dummy_a->next; // 有效节点的头 delete dummy_a; // 释放虚拟节点内存 delete dummy_b; return result;
第二次提交
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* partition(ListNode* head, int x) {
if (head == nullptr || head -> next == nullptr){
return head ;
}
ListNode* dummy_a = new ListNode (0);
ListNode* dummy_b = new ListNode (0);
ListNode* cur_a = dummy_a;
ListNode* cur_b = dummy_b;
while (head != nullptr ){
if (head -> val < x ){
cur_a -> next = head ;
cur_a = cur_a -> next ;
}else {
cur_b -> next = head ;
cur_b = cur_b -> next ;
}
head = head -> next ;
}
cur_a -> next = dummy_b -> next ;
return dummy_a -> next;
}
};报错。
bash
Line 77: Char 9:
=================================================================
==23==ERROR: AddressSanitizer: heap-use-after-free on address 0x5020000000f8 at pc 0x5575ac8e7756 bp 0x7ffdb1a849c0 sp 0x7ffdb1a849b8
READ of size 8 at 0x5020000000f8 thread T0
#0 0x5575ac8e7755 in __ListNodeUtils__::freeList(ListNode*&) (solution+0x1aa755)
#1 0x5575ac8c640d in main solution.cpp:77:9
#2 0x7f2905ef51c9 (/lib/x86_64-linux-gnu/libc.so.6+0x2a1c9) (BuildId: 274eec488d230825a136fa9c4d85370fed7a0a5e)
#3 0x7f2905ef528a in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x2a28a) (BuildId: 274eec488d230825a136fa9c4d85370fed7a0a5e)
#4 0x5575ac7efe74 in _start (solution+0xb2e74)
0x5020000000f8 is located 8 bytes inside of 16-byte region [0x5020000000f0,0x502000000100)
freed by thread T0 here:
#0 0x5575ac8c4702 in operator delete(void*, unsigned long) /root/llvm-project/compiler-rt/lib/asan/asan_new_delete.cpp:155:3
#1 0x5575ac8e7717 in __ListNodeUtils__::freeList(ListNode*&) (solution+0x1aa717)
#2 0x5575ac8c640d in main solution.cpp:77:9
#3 0x7f2905ef51c9 (/lib/x86_64-linux-gnu/libc.so.6+0x2a1c9) (BuildId: 274eec488d230825a136fa9c4d85370fed7a0a5e)
#4 0x7f2905ef528a in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x2a28a) (BuildId: 274eec488d230825a136fa9c4d85370fed7a0a5e)
#5 0x5575ac7efe74 in _start (solution+0xb2e74)
previously allocated by thread T0 here:
#0 0x5575ac8c3a9d in operator new(unsigned long) /root/llvm-project/compiler-rt/lib/asan/asan_new_delete.cpp:86:3
#1 0x5575ac8de475 in ListNode* _Deserializer_::deserialize<ListNode*>(rapidjson::GenericValue<rapidjson::UTF8<char>, rapidjson::MemoryPoolAllocator<rapidjson::CrtAllocator>>&, ListNode**) (solution+0x1a1475)
#2 0x5575ac8e07a2 in ListNode* _Deserializer_::deserialize<ListNode*>(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char>> const&) (solution+0x1a37a2)
#3 0x5575ac8c628d in main solution.cpp:77:35
#4 0x7f2905ef51c9 (/lib/x86_64-linux-gnu/libc.so.6+0x2a1c9) (BuildId: 274eec488d230825a136fa9c4d85370fed7a0a5e)
... 1699 more chars你现在的代码已经修复了之前的「覆盖节点」「返回虚拟头节点」等问题,但还存在两个关键漏洞,这也是导致你之前遇到内存错误 / 运行错误的核心原因。我会继续引导你找到问题,并教你怎么修正,先看你的代码现状:
第一步:先肯定你的进步(你已经做对的地方)
- 新增了
cur_a/cur_b尾指针,解决了节点覆盖的问题 ✅; - 尾指针每次挂完节点后后移,保证了节点顺序 ✅;
- 正确返回
dummy_a->next,而不是虚拟节点本身 ✅。
第二步:引导你找到剩余的两个关键错误
错误 1:没有处理「循环链表」问题(最核心)
你的代码中没有写 cur_b->next = nullptr,导致:
- 原链表最后一个节点的
next还指向原链表的某个节点(不是nullptr); - 比如示例 1 中,原链表最后一个节点是 2,它的
next原本是nullptr(没问题); - 但如果原链表是
[2,1],x=2:cur_b指向 2(原链表第一个节点),2 的next原本指向 1;- 你把
cur_a->next = dummy_b->next(即 1->2),但 2 的next还是指向 1 → 形成循环链表1->2->1->2...;
- 循环链表会导致后续遍历 / 释放时,程序无限循环,最终触发内存错误(比如
heap-use-after-free)。
👉 思考:拆分链表后,cur_b 是 dummy_b 链表的最后一个节点,必须把它的 next 置空,切断和原链表的联系。
错误 2:没有释放虚拟节点的内存(次要但规范)
你创建了 dummy_a/dummy_b(new ListNode(0)),但没有用 delete 释放,会导致内存泄漏(虽然 OJ 平台可能不检测,但这是 C++ 的良好习惯,也可能间接导致内存相关错误)。
ok,那我现在终于成功了....!
通过
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* partition(ListNode* head, int x) {
if (head == nullptr || head -> next == nullptr){
return head ;
}
ListNode* dummy_a = new ListNode (0);
ListNode* dummy_b = new ListNode (0);
ListNode* cur_a = dummy_a;
ListNode* cur_b = dummy_b;
while (head != nullptr ){
if (head -> val < x ){
cur_a -> next = head ;
cur_a = cur_a -> next ;
}else {
cur_b -> next = head ;
cur_b = cur_b -> next ;
}
head = head -> next ;
}
cur_a -> next = dummy_b -> next ;
cur_b -> next = nullptr ;
ListNode* new_head = dummy_a -> next ;
delete dummy_a;
delete dummy_b;
return new_head;
}
};3 小结
1. 链表拆分/重组的核心技巧:
用虚拟头节点(dummy)避免处理空指针边界;
用尾指针(cur_a/cur_b)跟踪链表末尾,避免节点覆盖,保证顺序。
2. 循环链表的避坑点:
拆分链表后,必须把新链表尾节点的 next 置空(cur_b->next = nullptr),切断和原链表的联系。
3. C++ 内存管理规范:
用 new 创建的节点,必须用 delete 释放,避免内存泄漏; - 释放虚拟节点前,先保存结果指针(dummy_a->next),再释放,避免访问已释放内存。
4. 边界条件处理:
提前判断空链表/单节点链表,直接返回原头节点,简化逻辑。
4 题目
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝 。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示Node.val的整数。random_index:随机指针指向的节点索引(范围从0到n-1);如果不指向任何节点,则为null。
你的代码 只 接受原链表的头节点 head 作为传入参数。
示例 1:
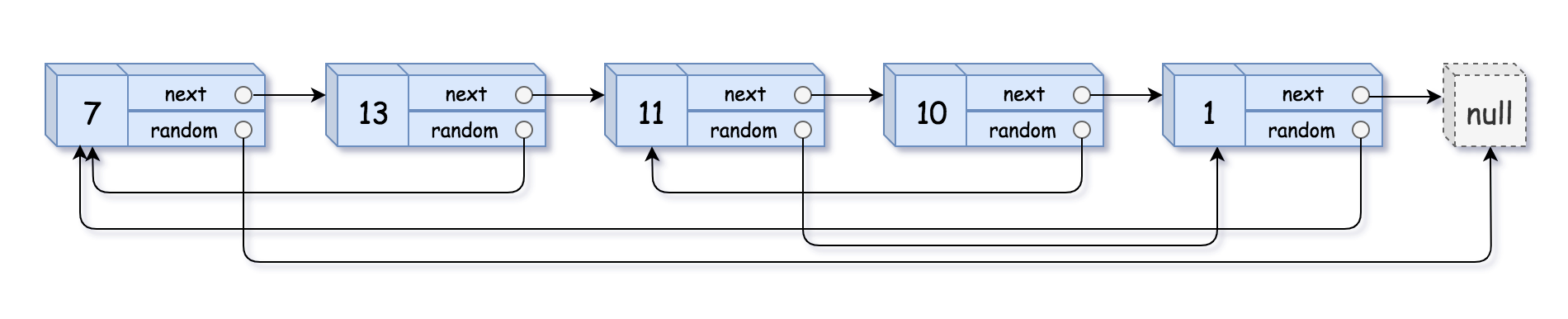
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]示例 2:

输入:head = [[1,1],[2,1]]
输出:[[1,1],[2,1]]示例 3:

输入:head = [[3,null],[3,0],[3,null]]
输出:[[3,null],[3,0],[3,null]]提示:
0 <= n <= 1000-104 <= Node.val <= 104Node.random为null或指向链表中的节点。
5 代码实现
c++
cpp
/*
// Definition for a Node.
class Node {
public:
int val;
Node* next;
Node* random;
Node(int _val) {
val = _val;
next = NULL;
random = NULL;
}
};
*/
class Solution {
public:
Node* copyRandomList(Node* head) {
if (head == nullptr ){
return head;
}
unordered_map <Node* ,Node*> nodeMap ;
Node* current = head ;
while (current != nullptr){
Node* newNode = new Node(current -> val);
nodeMap[current] = newNode;
current = current-> next ;
}
current = head ;
while(current != nullptr){
Node* newNode = nodeMap[current];
newNode -> next = nodeMap[current -> next];
newNode -> random = nodeMap[current -> random];
current = current -> next ;
}
return nodeMap[head];
}
};js
javascript
/**
* // Definition for a _Node.
* function _Node(val, next, random) {
* this.val = val;
* this.next = next;
* this.random = random;
* };
*/
/**
* @param {_Node} head
* @return {_Node}
*/
var copyRandomList = function(head) {
if (head == null ){
return null ;
}
const nodeMap = new Map() ;
let cur = head ;
while (cur){
nodeMap.set(cur , new Node(cur.val));
cur = cur.next ;
}
cur = head ;
while(cur){
const newNode = nodeMap.get(cur);
newNode.next = nodeMap.get(cur.next) || null ;
newNode.random = nodeMap.get(cur.random) || null ;
cur = cur.next;
}
return nodeMap.get(head);
};思考
说实话一遍下来还看不懂题目,只是模糊记得浅拷贝,深拷贝。啊哈哈哈,这个找点视频学一下,然后要总结一下链表题了,再看下算法笔记,第一轮链表就过了。
random指针的状态也要复制对吗,因为是深拷贝。
我看了一个讲解说第一遍遍历节点存入hashmap,然后第二次连random指针,这个怎么做的,怎么拿到random的连接状态的?
题解
先明确核心问题:为什么这个题难?
普通链表复制只需要复制val和next指针,顺着链表走就行;但这个题多了random指针 ------ 它可能指向链表中任意节点(甚至自己),也可能指向null。
关键难点:复制后的新节点的random指针,必须指向「复制链表」里的对应节点,而不是原链表的节点 。比如原链表中节点 A 的random指向节点 B,那复制的新节点 A' 的random必须指向复制的新节点 B',而不是原节点 B。
核心思路:哈希表「搭桥」
我们可以把原节点和复制节点的关系想象成「一对一的双胞胎」:
- 先给每个原节点造一个「双胞胎」新节点(只赋值
val); - 用哈希表(
unordered_map)记录「原节点 → 双胞胎新节点」的对应关系; - 再根据原链表的
next和random指向,给新节点的指针「找对应的双胞胎」。
分步拆解
第一步:定义节点结构(题目给定)
先明确链表节点的样子,这是基础:
cpp
// 定义随机链表的节点类
class Node {
public:
int val; // 节点值
Node* next; // 指向下一个节点的指针
Node* random; // 随机指针,指向任意节点或null
// 构造函数:初始化节点值,next和random默认是null
Node(int _val) {
val = _val;
next = NULL; // C++11及以上建议用nullptr,效果一样
random = NULL;
}
};第二步:完整实现复制函数(分 2 个阶段)
我把函数拆成「造双胞胎」和「连指针」两个阶段,每一步都加详细注释:
cpp
#include <unordered_map> // 必须包含这个头文件才能用哈希表
using namespace std; // 简化代码,否则要写std::unordered_map
class Solution {
public:
Node* copyRandomList(Node* head) {
// 阶段0:处理空链表(特殊情况,直接返回null)
if (head == NULL) {
return NULL;
}
// ==================== 阶段1:造双胞胎,存哈希表 ====================
// 哈希表:键=原节点指针,值=对应的新节点指针(双胞胎)
unordered_map<Node*, Node*> nodeMap;
Node* current = head; // 遍历指针,从链表头开始
while (current != NULL) { // 遍历原链表的每一个节点
// 1. 给当前原节点造一个双胞胎新节点(只赋值val,指针先不管)
Node* newNode = new Node(current->val);
// 2. 把「原节点-新节点」的对应关系存到哈希表
nodeMap[current] = newNode;
// 3. 遍历指针往后走,处理下一个原节点
current = current->next;
}
// ==================== 阶段2:连指针(next + random) ====================
current = head; // 重置遍历指针,回到原链表头
while (current != NULL) {
// 1. 从哈希表中取出当前原节点对应的双胞胎新节点
Node* newNode = nodeMap[current];
// 2. 给新节点连next指针:原节点的next → 找它的双胞胎 → 作为新节点的next
// 比如原节点A的next是B,那新节点A'的next就是B的双胞胎B'
newNode->next = nodeMap[current->next];
// 3. 给新节点连random指针:逻辑和next完全一样
// 比如原节点A的random是C,那新节点A'的random就是C的双胞胎C'
newNode->random = nodeMap[current->random];
// 4. 遍历指针往后走,处理下一个节点
current = current->next;
}
// ==================== 最终返回 ====================
// 原链表头节点的双胞胎,就是复制链表的头节点
return nodeMap[head];
}
};用例子直观理解(拿最简单的示例 2)
示例 2 输入:[[1,1],[2,1]],原链表结构:
原节点1(val=1,next=原节点2,random=原节点2)→ 原节点2(val=2,next=null,random=原节点2)→ null阶段 1(造双胞胎):
遍历原链表,哈希表会存:
nodeMap[原节点1] = 新节点1(val=1,next=null,random=null)
nodeMap[原节点2] = 新节点2(val=2,next=null,random=null)阶段 2(连指针):
- 处理原节点 1:
- 取出新节点 1;
- 新节点 1.next = nodeMap 原节点 1.next = nodeMap 原节点 2 = 新节点 2;
- 新节点 1.random = nodeMap 原节点 1.random = nodeMap 原节点 2 = 新节点 2;
- 处理原节点 2:
- 取出新节点 2;
- 新节点 2.next = nodeMap 原节点 2.next = nodeMap null = null;
- 新节点 2.random = nodeMap 原节点 2.random = nodeMap 原节点 2 = 新节点 2;
最终复制链表结构:
新节点1(val=1,next=新节点2,random=新节点2)→ 新节点2(val=2,next=null,random=新节点2)→ null和原链表完全一致,且所有节点都是新的,没有指向原链表!
关键细节答疑(新手常问)
- 为什么哈希表能存指针? C++ 中指针本质是一个内存地址(数值),
unordered_map支持把指针作为键,只要两个指针指向不同节点,就是不同的键。 nodeMap[current->next]如果current->next是 null 会怎样? C++11 及以上,unordered_map查找nullptr(或 NULL)会返回nullptr,正好符合我们的需求(新节点的 next/random 设为 null)。- **为什么要分两次遍历?**第一次遍历必须先把所有新节点造出来,否则第二次连指针时,可能遇到「原节点的 random 指向还没创建的新节点」的情况。
总结
- 核心逻辑:用哈希表建立「原节点→新节点」的映射,把「找新节点」的问题转化为「哈希表查询」,解决 random 指针的定位难题。
- **第一次遍历:**创建所有新节点,用哈希表记录「原节点→新节点」的映射(只填 val,指针空);
- **第二次遍历:**根据原节点的 next/random 指针,通过哈希表找到对应的新节点,完善新链表的指针;
- 输入里的 random: 代码中是节点的
random指针(已存在),题目里的random_index只是给你看的描述,不是代码输入。
js实现
如何用 JavaScript 实现随机链表的复制,核心是搞懂 JS 里怎么用「哈希表」(其实就是普通对象 / Map)替代 C++ 的 unordered_map,我会用最易懂的方式讲清楚,代码可以直接运行。
先明确 JS 里的「哈希表」实现方式
JS 中没有专门的 unordered_map,但有两种等价方案:
- 普通对象(Object):用「原节点对象」作为键(JS 会自动把对象转为唯一的引用标识),值为复制的新节点;
- Map 数据结构 (推荐):ES6 新增的
Map可以直接用对象作为键,比普通对象更安全、语义更清晰。
用 Map 来实现,因为它是处理「对象→对象」映射的最佳实践。
JS 完整实现(核心逻辑和 C++ 完全一致)
第一步:定义节点结构(模拟题目中的链表节点)
javascript
// 定义随机链表节点类(和题目逻辑一致)
function Node(val, next = null, random = null) {
this.val = val;
this.next = next;
this.random = random;
}第二步:实现复制函数(分两步遍历 + Map 映射)
javascript
/**
* @param {Node} head
* @return {Node}
*/
var copyRandomList = function(head) {
// 处理空链表
if (head === null) return null;
// 1. 第一步遍历:创建所有新节点,用Map存「原节点→新节点」的映射
const nodeMap = new Map();
let current = head;
while (current !== null) {
// 为每个原节点创建新节点(只赋值val,指针默认null)
nodeMap.set(current, new Node(current.val));
current = current.next;
}
// 2. 第二步遍历:完善新节点的next和random指针
current = head;
while (current !== null) {
// 取出当前原节点对应的新节点
const newNode = nodeMap.get(current);
// 新节点的next = 原节点next对应的新节点(null的话Map.get返回undefined,手动转null)
newNode.next = nodeMap.get(current.next) || null;
// 新节点的random = 原节点random对应的新节点
newNode.random = nodeMap.get(current.random) || null;
// 遍历指针后移
current = current.next;
}
// 返回复制链表的头节点(原头节点对应的新节点)
return nodeMap.get(head);
};关键细节解释(JS 特有)
-
Map 的使用:
nodeMap.set(原节点, 新节点):把原节点和新节点的映射存起来,和 C++ 的nodeMap[current] = new Node(...)完全等价;nodeMap.get(原节点):根据原节点找到对应的新节点,和 C++ 的nodeMap[current]等价;- 注意:如果原节点的
next/random是null,Map.get(null)会返回undefined,所以需要用|| null转成null(和 C++ 的nullptr对应)。
-
节点引用的特性:JS 中对象(包括 Node 实例)是「引用类型」,两个不同的 Node 实例即使 val 相同,也是不同的对象 ------ 这正好满足「深拷贝」的要求(新节点和原节点是完全独立的对象)。
-
和 C++ 的对比:
C++ 写法 JS 写法 说明 unordered_map<Node*, Node*>new Map()存储对象映射 nodeMap[current] = new Node(...)nodeMap.set(current, new Node(...))存入映射 nodeMap[current]nodeMap.get(current)取出映射 NULL/nullptrnull空指针对应
测试示例(直观理解执行过程)
我们用示例 2 的输入来测试,手动构建原链表并复制:
javascript
// 构建原链表:[[1,1],[2,1]]
const node1 = new Node(1);
const node2 = new Node(2);
node1.next = node2;
node1.random = node2; // node1的random指向node2
node2.next = null;
node2.random = node2; // node2的random指向自己
// 复制链表
const copyHead = copyRandomList(node1);
// 验证结果
console.log(copyHead.val); // 1(新节点1的val)
console.log(copyHead.next.val); // 2(新节点1的next指向新节点2)
console.log(copyHead.random.val); // 2(新节点1的random指向新节点2)
console.log(copyHead.next.random.val); // 2(新节点2的random指向自己)
console.log(copyHead === node1); // false(新节点和原节点不是同一个对象,深拷贝成功)总结
- 核心逻辑 :JS 版本和 C++ 完全一致,都是「两步遍历 + 哈希表映射」,只是语法换成了 JS 的
Map; - JS 关键 :用
Map存储「原节点→新节点」的映射,set存、get取,注意处理null转undefined的问题; - 深拷贝本质 :新节点是全新的
Node实例,和原节点无引用关联,指针只指向新链表的节点。
6 小结
这道「随机链表的复制」题看似是链表操作题,但核心是解决「映射」和「关联」问题,能给你带来的启发远超链表本身,不管是编程思维还是实际开发,都有很实用的参考价值。我把最核心的启发拆解成 3 个维度,帮你把这道题的价值最大化:
一、解题思维层面:遇到「找不到对应关系」的问题,优先想「哈希表搭桥」
这是这道题最核心的启发,也是算法里的高频思路:
- 问题本质:随机链表复制的难点不是复制节点,而是「新节点的 random 指针不知道该指向谁」------ 原节点的 random 指向原链表的某个节点,但我们需要让新节点指向新链表的对应节点,这是一种「跨集合的对应关系」。
- 解决方案:用哈希表(Map / 字典)建立「原节点→新节点」的一一映射,把「找不到对应节点」的问题,转化为「哈希表的 O (1) 查询」。
- 举一反三 :这种思路能解决所有「需要在两个独立集合间建立关联」的问题,比如:
- 复制带父指针的树(父指针需要指向复制树的对应节点);
- 把数组 A 的元素映射到数组 B 的对应元素(比如 A 是原数据,B 是处理后的数据,需要保留 A 的关联关系);
- 缓存场景(用 Map 存「计算过的结果」,避免重复计算)。
二、编码习惯层面:复杂问题「分阶段拆解」,不要一步到位
这道题的两步遍历法,是「分阶段解决问题」的典型示范:
- 反面思路:如果想「遍历一次就同时创建节点 + 连 next + 连 random」,会遇到「random 指向的节点还没创建」的问题,逻辑会极其混乱;
- 正面思路 :把问题拆成两个独立阶段:
- 第一阶段:只做「创建节点 + 记录映射」(不处理任何指针),确保所有新节点都已存在;
- 第二阶段:只做「完善指针」(不创建新节点),此时所有节点都在哈希表里,直接查就行。
- 落地习惯:以后写代码遇到复杂逻辑(比如既要处理数据创建、又要处理关联关系),先问自己:「能不能把问题拆成『无依赖的前置阶段』和『依赖处理阶段』?」------ 拆分后代码更清晰、更易调试,也不容易出错。
三、语言特性层面:理解「引用类型」的本质,是做好深拷贝的关键
这道题的「深拷贝」要求,本质是考察对「引用类型」的理解:
- 浅拷贝 vs 深拷贝 :
- 浅拷贝:只是复制了节点的指针(比如直接让新节点的 random 指向原节点的 random),最终新链表的指针还是指向原链表的节点,不符合要求;
- 深拷贝:创建全新的节点对象,指针只指向新对象,和原对象完全解耦。
- 语言共性:不管是 C++ 的指针、Java 的对象引用、JS 的引用类型,核心逻辑一致 ------「深拷贝的核心是创建新实例,而非复制引用」;
- 实际开发价值 :前端的对象深拷贝、后端的对象克隆,本质都是这个逻辑:比如 JS 中不能直接用
Object.assign复制带引用的对象,需要递归 / 用 Map 建立映射,和这道题的思路完全一致。
总结(核心启发)
- 核心技巧:遇到「跨集合关联」问题,用哈希表建立映射,把「找不到」变成「查得到」;
- 解题思路:复杂问题拆成无依赖的阶段,先解决「基础创建」,再解决「关联处理」;
- 底层认知:深拷贝的关键是「创建新实例」,而非复制引用,这是所有引用类型语言的共性。