建议先看第四章的使用风险。
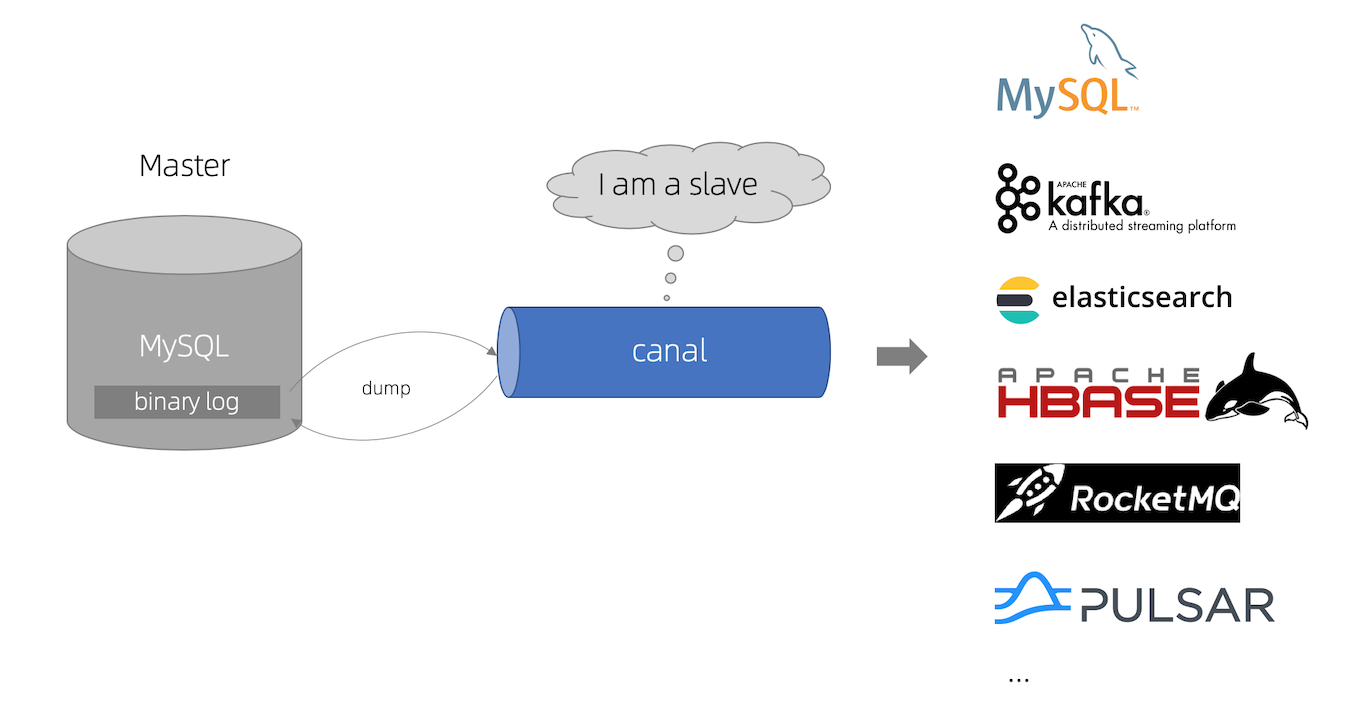
canal kə'næl,译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
工作原理
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
核心工作流程
MySQL Binlog → Canal Server(解析) → Canal Adapter(转换) → 目标存储一.Mysql准备
打开 MySQL 的 BinLog:
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
sql
SHOW VARIABLES LIKE 'binlog_format'; -- 结果应该是ROW
SHOW VARIABLES LIKE 'log_bin'; -- 结果应该是 ON
SHOW VARIABLES LIKE '%log%'; -- 所有binlog信息创建用于连接canal账号
sql
-- 1. 创建用户
CREATE USER 'canal'@'localhost' IDENTIFIED BY 'canal';
-- 2. 授予权限
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'localhost';
-- 3. 刷新权限
FLUSH PRIVILEGES;二、canal准备工作
最开始使用的是docker,搞死我了,各种问题。所以最后使用canal自己封装的startup.sh
https://github.com/alibaba/canal/releases

| 组件 | 功能 | 作用 |
|---|---|---|
| Canal Deployer | Canal 服务端 | 连接 MySQL,解析 binlog |
| Canal Adapter | Canal 适配器 | 数据同步到目标数据源(ES、RDBMS等) |
| Canal Admin | Canal 管理平台 | 集群管理、Web监控界面 |
1.canal deployer服务端
将服务端文件包解压,然后如下修改配置:
(1) canal.properties
XML
#################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
# canal.user = canal
# canal.passwd =
# canal admin config
#canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd =
# admin auto register
#canal.admin.register.auto = true
#canal.admin.register.cluster =
#canal.admin.register.name =
canal.zkServers =
# flush data to zk
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, rocketMQ, rabbitMQ, pulsarMQ
canal.serverMode = tcp
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
## memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384
## memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
## meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true
## detecing config
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
canal.instance.detecting.interval.time = 3
canal.instance.detecting.retry.threshold = 3
canal.instance.detecting.heartbeatHaEnable = false
# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60
# network config
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30
# binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false
canal.instance.filter.dml.insert = false
canal.instance.filter.dml.update = false
canal.instance.filter.dml.delete = false
# binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
# binlog ddl isolation
canal.instance.get.ddl.isolation = false
# parallel parser config
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256
# table meta tsdb info
canal.instance.tsdb.enable = true
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360
#################################################
######### destinations #############
#################################################
canal.destinations = example
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5
# set this value to 'true' means that when binlog pos not found, skip to latest.
# WARN: pls keep 'false' in production env, or if you know what you want.
canal.auto.reset.latest.pos.mode = false
canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
canal.instance.global.mode = spring
canal.instance.global.lazy = false
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml
##################################################
######### MQ Properties #############
##################################################
# aliyun ak/sk , support rds/mq
canal.aliyun.accessKey =
canal.aliyun.secretKey =
canal.aliyun.uid=
canal.mq.flatMessage = true
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = local
canal.mq.database.hash = true
canal.mq.send.thread.size = 30
canal.mq.build.thread.size = 8
##################################################
######### Kafka #############
##################################################
kafka.bootstrap.servers = 127.0.0.1:9092
kafka.acks = all
kafka.compression.type = none
kafka.batch.size = 16384
kafka.linger.ms = 1
kafka.max.request.size = 1048576
kafka.buffer.memory = 33554432
kafka.max.in.flight.requests.per.connection = 1
kafka.retries = 0
kafka.kerberos.enable = false
kafka.kerberos.krb5.file = ../conf/kerberos/krb5.conf
kafka.kerberos.jaas.file = ../conf/kerberos/jaas.conf
# sasl demo
# kafka.sasl.jaas.config = org.apache.kafka.common.security.scram.ScramLoginModule required \\n username=\"alice\" \\npassword="alice-secret\";
# kafka.sasl.mechanism = SCRAM-SHA-512
# kafka.security.protocol = SASL_PLAINTEXT
##################################################
######### RocketMQ #############
##################################################
rocketmq.producer.group = test
rocketmq.enable.message.trace = false
rocketmq.customized.trace.topic =
rocketmq.namespace =
rocketmq.namesrv.addr = 127.0.0.1:9876
rocketmq.retry.times.when.send.failed = 0
rocketmq.vip.channel.enabled = false
rocketmq.tag =
##################################################
######### RabbitMQ #############
##################################################
rabbitmq.host =
rabbitmq.virtual.host =
rabbitmq.exchange =
rabbitmq.username =
rabbitmq.password =
rabbitmq.queue =
rabbitmq.routingKey =
rabbitmq.deliveryMode =
##################################################
######### Pulsar #############
##################################################
pulsarmq.serverUrl =
pulsarmq.roleToken =
pulsarmq.topicTenantPrefix =(2) canal_local.properties
XML
# register ip
canal.register.ip = 192.168.146.xx
# canal admin config
canal.admin.manager = 192.168.146.xx:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = xxxxx
# admin auto register
canal.admin.register.auto = true
canal.admin.register.cluster = wj-canal-cluster
canal.admin.register.name = wj-canal(3) 启动canal服务
在bin路径下,启动
XML
./startup.sh启动后,可以去日志logs下查看日志,如果没有的话,在conf下,增加logback.xml
XML
<configuration scan="true" scanPeriod=" 5 seconds">
<jmxConfigurator />
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{56} - %msg%n
</pattern>
</encoder>
</appender>
<appender name="CANAL-ROOT" class="ch.qos.logback.classic.sift.SiftingAppender">
<discriminator>
<Key>destination</Key>
<DefaultValue>canal</DefaultValue>
</discriminator>
<sift>
<appender name="FILE-${destination}" class="ch.qos.logback.core.rolling.RollingFileAppender">
<File>../logs/${destination}/${destination}.log</File>
<rollingPolicy
class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- rollover daily -->
<fileNamePattern>../logs/${destination}/%d{yyyy-MM-dd}/${destination}-%d{yyyy-MM-dd}-%i.log.gz</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<!-- or whenever the file size reaches 100MB -->
<maxFileSize>512MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<maxHistory>14</maxHistory>
</rollingPolicy>
<encoder>
<pattern>
%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{56} - %msg%n
</pattern>
</encoder>
</appender>
</sift>
</appender>
<appender name="CANAL-META" class="ch.qos.logback.classic.sift.SiftingAppender">
<discriminator>
<Key>destination</Key>
<DefaultValue>canal</DefaultValue>
</discriminator>
<sift>
<appender name="META-FILE-${destination}" class="ch.qos.logback.core.rolling.RollingFileAppender">
<File>../logs/${destination}/meta.log</File>
<rollingPolicy
class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- rollover daily -->
<fileNamePattern>../logs/${destination}/%d{yyyy-MM-dd}/meta-%d{yyyy-MM-dd}-%i.log.gz</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<!-- or whenever the file size reaches 100MB -->
<maxFileSize>32MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<maxHistory>14</maxHistory>
</rollingPolicy>
<encoder>
<pattern>
%d{yyyy-MM-dd HH:mm:ss.SSS} - %msg%n
</pattern>
</encoder>
</appender>
</sift>
</appender>
<appender name="RocketmqClientAppender" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>../logs/canal/rocketmq_client.log</file>
<rollingPolicy
class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- rollover daily -->
<fileNamePattern>../logs/canal/%d{yyyy-MM-dd}/rocketmq_client-%d{yyyy-MM-dd}-%i.log.gz</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<!-- or whenever the file size reaches 100MB -->
<maxFileSize>512MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<maxHistory>14</maxHistory>
</rollingPolicy>
<encoder charset="UTF-8">
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{56} - %msg%n</pattern>
</encoder>
</appender>
<logger name="com.alibaba.otter.canal.instance" additivity="false">
<level value="INFO" />
<appender-ref ref="CANAL-ROOT" />
</logger>
<logger name="com.alibaba.otter.canal.deployer" additivity="false">
<level value="INFO" />
<appender-ref ref="CANAL-ROOT" />
</logger>
<logger name="com.alibaba.otter.canal.meta.FileMixedMetaManager" additivity="false">
<level value="INFO" />
<appender-ref ref="CANAL-META" />
</logger>
<logger name="com.alibaba.otter.canal.connector.kafka" additivity="false">
<level value="INFO" />
<appender-ref ref="CANAL-ROOT" />
</logger>
<logger name="com.alibaba.otter.canal.connector.rocketmq" additivity="false">
<level value="INFO" />
<appender-ref ref="CANAL-ROOT" />
</logger>
<logger name="com.alibaba.otter.canal.connector.rabbitmq" additivity="false">
<level value="INFO" />
<appender-ref ref="CANAL-ROOT" />
</logger>
<logger name="RocketmqClient" additivity="false">
<level value="INFO" />
<appender-ref ref="RocketmqClientAppender" />
</logger>
<logger name="com.alibaba.otter.canal.connector.pulsarmq" additivity="false">
<level value="INFO" />
<appender-ref ref="CANAL-ROOT" />
</logger>
<root level="WARN">
<!-- <appender-ref ref="STDOUT"/> -->
<appender-ref ref="CANAL-ROOT" />
</root>
</configuration>2.canal admin 管理端
将管理端文件包解压,然后如下修改配置:
(1) application.yml
XML
server:
port: 8089
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
spring.datasource:
address: 192.168.146.xxx:3306
database: canal_manager
username: root
password: xxxxxx
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
#管理端账号
canal:
adminUser: admin
adminPasswd: xxxxx(2)canal_manager.sql
用该sql建立数据库
(3)启动admin服务
在bin路径下,启动
XML
./startup.shxxxxxxxxhttp://192.168.146.x:8089/
3.canal adapter 适配器
将文件包解压,然后如下修改配置:
(1)application.yml
向es同步。
XML
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: tcp #tcp kafka rocketMQ rabbitMQ
flatMessage: true
zookeeperHosts:
syncBatchSize: 1000
retries: -1
timeout:
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer
canal.tcp.server.host: 127.0.0.1:11111
canal.tcp.zookeeper.hosts:
canal.tcp.batch.size: 500
canal.tcp.username:
canal.tcp.password:
# kafka consumer
# kafka.bootstrap.servers: 127.0.0.1:9092
# kafka.enable.auto.commit: false
# kafka.auto.commit.interval.ms: 1000
# kafka.auto.offset.reset: latest
# kafka.request.timeout.ms: 40000
# kafka.session.timeout.ms: 30000
# kafka.isolation.level: read_committed
# kafka.max.poll.records: 1000
# rocketMQ consumer
# rocketmq.namespace:
# rocketmq.namesrv.addr: 127.0.0.1:9876
# rocketmq.batch.size: 1000
# rocketmq.enable.message.trace: false
# rocketmq.customized.trace.topic:
# rocketmq.access.channel:
# rocketmq.subscribe.filter:
# rabbitMQ consumer
# rabbitmq.host:
# rabbitmq.virtual.host:
# rabbitmq.username:
# rabbitmq.password:
# rabbitmq.resource.ownerId:
srcDataSources:
defaultDS:
url: jdbc:mysql://192.168.146.130:3306/ry-cloud?useUnicode=true
username: root
password: 123456
canalAdapters:
- instance: example # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: logger
key: logger1
- name: es7
key: mysql-wj
hosts: http://192.168.146.130:9200 # 127.0.0.1:9200 for rest mode
properties:
mode: rest # or rest
# security.ca.path: /etc/es8/ca.crt
# security.auth: test:123456 # only used for rest mode
cluster.name: elasticsearch
# - name: kudu
# key: kudu
# properties:
# kudu.master.address: 127.0.0.1 # ',' split multi address
# - name: phoenix
# key: phoenix
# properties:
# jdbc.driverClassName: org.apache.phoenix.jdbc.PhoenixDriver
# jdbc.url: jdbc:phoenix:127.0.0.1:2181:/hbase/db
# jdbc.username:
# jdbc.password:
# - name: clickhouse
# key: clickhouse1
# properties:
# jdbc.driverClassName: ru.yandex.clickhouse.ClickHouseDriver
# jdbc.url: jdbc:clickhouse://127.0.0.1:8123/default
# jdbc.username: default
# jdbc.password: 123456
# batchSize: 3000
# scheduleTime: 600 # second unit
# threads: 3 # parallel threads下面配置 -name=es7,这个位置真是坑惨我了。官方下载的,写的是 -name=es,我以为这是表示是es这个类型,但是实际指的是读配置文件的路径。所以必须改成一致。
(2)bootstrap.yml
XML
canal:
manager:
jdbc:
url: jdbc:mysql://192.168.146.xx:3306/canal_manager?useUnicode=true&characterEncoding=UTF-8
username: root
password: xxxxx(3)es相关文件夹下的配置
需要根据自己表要进行配置,示例如下:
XML
dataSourceKey: defaultDS
destination: example
groupId: g1
outerAdapterKey: mysql-wj
esMapping:
_index: user
_id: user_id
# 注意:ES7中需要_type,一般设置为_doc,ES8中不需要
_type: _doc
sql: "select
user_id,
IFNULL(dept_id, 0) as dept_id,
user_name,
nick_name,
user_type,
IFNULL(email, '') as email,
IFNULL(phonenumber, '') as phonenumber,
IFNULL(sex, '0') as sex,
IFNULL(status, '0') as status,
IFNULL(del_flag, '0') as del_flag,
IFNULL(create_time, '') as create_time,
IFNULL(update_time, '') as update_time
from sys_user"
etlCondition: "where update_time>={}"
upsert: true # 关键设置:当文档不存在时插入,存在时更新
commitBatch: 3000
esFields:
user_id:
type: bigint
create_time:
type: date
format: "yyyy-MM-dd HH:mm:ss"
update_time:
type: date
format: "yyyy-MM-dd HH:mm:ss"(4)启动adapter服务
在bin路径下,启动
XML
.startup.sh(5)测试是否生效
我新增了用户,查看ES:

注意注意:索引必须存在,否则适配器日志里你能看到没有索引的报错。
我查了些资料,说无法自动生成索引,所以还是很烦,就有了第三章的改进。
三、ES自动创建索引,若依项目升级
不喜欢同步双写模式,尤其是代码嵌入式,对于若依已经的编码业务,改动起来是个大工程,所以创建了common-es模块(工具属性的,没有启动类),只要启动pom引入common-es的微服务,会自动根据相关注解,进行自动创建索引。
1.设计Es注解
java
/**
* Es创建索引初始化注解
*
* @author wj
* @version 1.0
* @date 2026/2/6 17:10
*/
@Documented
@Inherited
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Component
public @interface ElasticComponent {
@AliasFor(
annotation = Component.class
)
//实体类名
String value();
}2.配置类
java
import cn.hutool.core.util.ObjectUtil;
import com.ruoyi.common.core.annotation.ElasticComponent;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.ApplicationContext;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.core.IndexOperations;
import org.springframework.data.elasticsearch.core.mapping.IndexCoordinates;
import javax.annotation.Resource;
import java.util.Map;
/**
* @author wj
* @version 1.0
* @date 2026/2/6 17:08
*/
@Configuration
@Slf4j
public class EslasticsInitor {
@Resource
private ApplicationContext applicationContext;
@Autowired
private ElasticsearchRestTemplate esRestTemplate;
@Bean
public void initEsIndex() {
// 获取待创建索引的实体
Map<String, Object> beansWithEsComponentMap = this.applicationContext.getBeansWithAnnotation(ElasticComponent.class);
Class<? extends Object> clazz = null;
for (Map.Entry<String, Object> entry : beansWithRqbbitComponentMap.entrySet()) {
log.info("初始化ES索引............");
//获取到实例对象的class信息
clazz = entry.getValue().getClass();
Document document = clazz.getAnnotation(Document.class);
if (ObjectUtil.isNotEmpty(document)) {
String indexName = document.indexName();
IndexOperations indexOps = esRestTemplate.indexOps(IndexCoordinates.of(indexName));
if (!indexOps.exists()) {
esRestTemplate.indexOps(clazz).createWithMapping();
log.info("完成初始化ES索引............" + indexName);
}
}
}
}
}3.注解使用
主要用于ES实体类
java
package cc.wj.test.es.domain;
import com.ruoyi.common.core.annotation.ElasticComponent;
import com.ruoyi.common.core.annotation.Excel;
import com.ruoyi.common.core.annotation.Excels;
import com.ruoyi.system.api.domain.SysDept;
import com.ruoyi.system.api.domain.SysRole;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.*;
import javax.annotation.processing.Completion;
import java.util.Date;
import java.util.List;
/**
* @author wj
* @version 1.0
* @date 2026/2/9 9:27
*/
@Document(indexName = "user", shards = 3, replicas = 1)
@ElasticComponent(value = "sysUser")
public class SysUserEs {
private static final long serialVersionUID = 1L;
/** 用户ID - ES主键 */
@Id
@Field(type = FieldType.Long)
@Excel(name = "用户序号", type = Excel.Type.EXPORT, cellType = Excel.ColumnType.NUMERIC, prompt = "用户编号")
private Long userId;
/** 部门ID */
@Field(type = FieldType.Long)
@Excel(name = "部门编号", type = Excel.Type.IMPORT)
private Long deptId;
/** 用户账号 */
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
@Excel(name = "登录名称")
private String userName;
/** 用户昵称 */
@MultiField(
mainField = @Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart"),
otherFields = {
@InnerField(suffix = "keyword", type = FieldType.Keyword),
@InnerField(suffix = "pinyin", type = FieldType.Text, analyzer = "standard")
}
)
@Excel(name = "用户名称")
private String nickName;
/** 用户邮箱 */
@Field(type = FieldType.Keyword)
@Excel(name = "用户邮箱")
private String email;
/** 手机号码 */
@Field(type = FieldType.Keyword)
@Excel(name = "手机号码", cellType = Excel.ColumnType.TEXT)
private String phonenumber;
/** 用户性别 */
@Field(type = FieldType.Keyword)
@Excel(name = "用户性别", readConverterExp = "0=男,1=女,2=未知")
private String sex;
/** 用户头像 */
@Field(type = FieldType.Text, index = false) // 不索引,只存储
private String avatar;
/** 密码 */
@Field(type = FieldType.Text, index = false) // 不索引,只存储
private String password;
/** 账号状态(0正常 1停用) */
@Field(type = FieldType.Keyword)
@Excel(name = "账号状态", readConverterExp = "0=正常,1=停用")
private String status;
/** 删除标志(0代表存在 2代表删除) */
@Field(type = FieldType.Keyword)
private String delFlag;
/** 最后登录IP */
@Field(type = FieldType.Keyword)
@Excel(name = "最后登录IP", type = Excel.Type.EXPORT)
private String loginIp;
/** 最后登录时间 */
@Field(type = FieldType.Date, format = DateFormat.custom, pattern = "yyyy-MM-dd HH:mm:ss")
@Excel(name = "最后登录时间", width = 30, dateFormat = "yyyy-MM-dd HH:mm:ss", type = Excel.Type.EXPORT)
private Date loginDate;
/** 密码最后更新时间 */
@Field(type = FieldType.Date, format = DateFormat.custom, pattern = "yyyy-MM-dd HH:mm:ss")
private Date pwdUpdateDate;
/** 部门对象 */
@Excels({
@Excel(name = "部门名称", targetAttr = "deptName", type = Excel.Type.EXPORT),
@Excel(name = "部门负责人", targetAttr = "leader", type = Excel.Type.EXPORT)
})
private SysDept dept;
/** 角色对象 */
@Field(type = FieldType.Nested) // 嵌套类型
private List<SysRole> roles;
/** 角色组 */
@Field(type = FieldType.Long)
private Long[] roleIds;
/** 岗位组 */
@Field(type = FieldType.Long)
private Long[] postIds;
/** 角色ID */
@Field(type = FieldType.Long)
private Long roleId;
/** ES 特定字段 - 全文搜索内容 */
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String fullTextContent;
/** ES 特定字段 - 建议器 */
@CompletionField(maxInputLength = 100)
private Completion suggest;
/** ES 特定字段 - 地理位置(如果需要) */
@GeoPointField
private String location;
/** ES 特定字段 - 文档分数 */
private Float score;
}在@Document中有个参数createIndex = true,我使用了但是不会生成索引的。
这个示例比较完整,相关的docment注解也是必须使用的,这会作为创建索引使用的。
项目启动后,会自动去创建索引的。
索引名称一定要和adapter配置的一致。
由于采用了binlog机制,Mysql中的新增、更新、删除操作,对应的Elasticsearch都能实时新增、更新、删除。
四、使用风险
1.一个配置文件出错,无法运行
在适配器中,若新增相关表配置,如果有错,其他的表配置一样会失效,无法正常运行。换句话说,一个有问题,全部无法运行。要用canal的话,建议要有备份服务。
2.只支持增量同步
第一次需要全量新增doc,之后增量新增doc。比较麻烦。

3.不支持视图
视图本身不会产生任何的数据更改操作,因此其对binlog没有直接的影响。但是,在某些情况下(更新视图,删除视图,插入到视图,删除基础表),对视图的操作会间接地引起基础表的数据更改,从而触发binlog的记录。但是对我们的ES同步数据需求来说,可以理解成视图无法支持同步。
4.联表痛苦
Canal-Adapter的配置方式较为固定,通常一个表对应一个配置。联表这个也不好做,我一个简单的联表:
sql
SELECT
CONCAT( u.user_id, '_', IFNULL( u.dept_id, 0 ), '_', 0 ) AS id,
u.`user_id` AS `user_id`,
u.`user_name` AS `user_name`,
u.`nick_name` AS `nick_name`,
u.`phonenumber` AS `phonenumber`,
p.`post_id` AS `post_id`,
u.`dept_id` AS `dept_id`,
d.`dept_name` AS `dept_name`,
d.`leader` AS `leader`,
p.`post_name` AS `post_name`,
p.`post_code` AS `post_code`,
u.`create_time` AS `create_time`
FROM
sys_user u
LEFT JOIN sys_user_post up ON u.`user_id` = up.`user_id`
LEFT JOIN sys_post p ON up.`post_id` = p.`post_id`
LEFT JOIN sys_dept d ON u.`dept_id` = d.`dept_id`配置如下:
sql
dataSourceKey: defaultDS
destination: example
groupId: g1
outerAdapterKey: mysql-wj
esMapping:
_index: user_dept_post
_id: id
_type: _doc
sql: |
SELECT
CONCAT(u.user_id, '_', IFNULL(u.dept_id, 0), '_', 0) AS id,
u.user_id AS user_id,
u.user_name AS user_name,
u.nick_name AS nick_name,
u.phonenumber AS phonenumber,
p.post_id AS post_id,
u.dept_id AS dept_id,
d.dept_name AS dept_name,
d.leader AS leader,
p.post_name AS post_name,
p.post_code AS post_code,
u.create_time AS create_time
FROM sys_user u
LEFT JOIN sys_user_post up ON u.user_id = up.user_id
LEFT JOIN sys_post p ON up.post_id = p.post_id
LEFT JOIN sys_dept d ON u.dept_id = d.dept_id
pk: user_id
upsert: true
commitBatch: 3000
etlCondition: "where u.create_time>={}"apdater日志
sql
2026-02-09 09:13:33.130 [pool-3-thread-1] DEBUG c.a.o.canal.client.adapter.es.core.service.ESSyncService - DML: {"data":[{"user_id":131,"dept_id":null,"user_name":"求我·","nick_name":"lll","user_type":"00","email":"","phonenumber":"18909890986","sex":"0","avatar":"","password":"$2a$10$vm3/GMx.oM37dR6v37wewOZ11oWv/QIsAhIvuXZz.bcrnxSpWr1ry","status":"0","del_flag":"0","login_ip":"","login_date":null,"pwd_update_date":null,"create_by":"admin","create_time":1770656701000,"update_by":"","update_time":null,"remark":null}],"database":"ry-cloud","destination":"example","es":1770628412000,"groupId":"g1","isDdl":false,"old":null,"pkNames":["user_id"],"sql":"","table":"sys_user","ts":1770628413117,"type":"INSERT"}
Affected indexes: user user_dept_post 但实际上,关联表索引,根本没有新增doc。
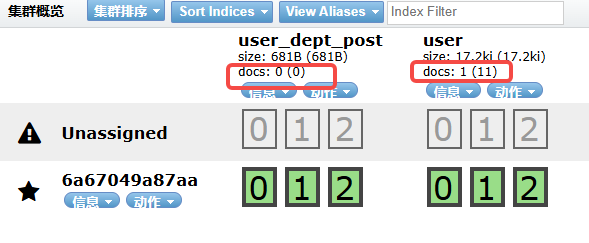
听说canal同步es,sql是有些限制的,但是这个简单的都不行。我表示怀疑。
5.必须先建好索引
我想进行数据同步的初衷,就是想避开代码侵入写法。虽然还是解决了(处理方式如第三章),但是我认为这么很不合理,应该封装在canal中的。
6.canal无法获取的信息
也是看binlog的支持什么和不支持什么
| 支持项 | 是否支持 | 说明 | 示例 |
|---|---|---|---|
| DDL语句 | ✅ 支持 | 表结构变更 | CREATE TABLE, ALTER TABLE, DROP TABLE |
| DML语句 | ✅ 支持 | 数据增删改 | INSERT, UPDATE, DELETE |
| 事务 | ✅ 支持 | 多语句事务 | BEGIN, COMMIT, ROLLBACK |
| 行级变更 | ✅ 支持 | 每行的具体变化 | ROW格式记录前后镜像 |
| 字段类型 | ✅ 支持 | 所有MySQL字段类型 | INT, VARCHAR, DATETIME, BLOB等 |
| NULL值 | ✅ 支持 | 空值处理 | 记录为NULL |
| 主键变更 | ✅ 支持 | 主键更新 | 旧主键删除 + 新主键插入 |
| 批量操作 | ✅ 支持 | 批量DML | INSERT INTO ... VALUES (...), (...) |
| 存储过程/函数 | ⚠️ 部分支持 | 执行结果支持,逻辑不记录 | 只记录最终数据变更 |
| 触发器 | ✅ 支持 | 触发器产生的变更 | 记录最终结果 |
| 视图 | ⚠️ 间接支持 | 通过视图操作基表 | 记录对基表的实际变更 |
| 外键约束 | ✅ 支持 | 级联更新删除 | 记录所有级联变更 |
| 字符集编码 | ✅ 支持 | 各种字符集 | UTF8, GBK, LATIN1等 |
| 时区转换 | ✅ 支持 | 时区自动转换 | 存储为UTC,按连接时区显示 |
| 大事务 | ✅ 支持 | 超大事务拆分 | 自动拆分为多个事件 |
| GTID | ✅ 支持 | 全局事务标识 | 确保主从一致性 |
| XA事务 | ✅ 支持 | 分布式事务 | 两阶段提交记录 |
| 临时表 | ⚠️ 有限支持 | 会话临时表不记录 | 只记录影响永久表的操作 |
这也是为什么视图、存储函数/过程无法同步的原因。
7.数据同步选型问题
反正问题还挺多的,用起来不得劲。数据同步工具,选型工作还需深度做下。AI告诉我的:
| 维度 | Logstash | DataX | Canal |
|---|---|---|---|
| 定位 | 日志/数据处理管道 | 批处理数据同步 | 实时增量数据同步 |
| 同步方式 | 轮询拉取/实时流 | 批量拉取 | 实时binlog监听 |
| 数据源支持 | 丰富(插件化) | 非常丰富(官方插件) | 主要MySQL(插件有限) |
| 实时性 | 准实时(秒级) | 批量(分钟/小时级) | 实时(毫秒级) |
| 数据量级 | 中小规模 | 海量数据 | 中大规模 |
| 架构复杂度 | 中等 | 简单 | 复杂 |
| 资源消耗 | 高(JRuby) | 中等 | 中等 |
| 使用场景 | 日志收集、ETL、实时监控 | 数据仓库ETL、数据迁移 | 业务数据实时同步、缓存更新 |
| 你的需求 | 推荐工具 | 原因 |
|---|---|---|
| MySQL → ES 实时同步 | Canal | 实时性要求高,数据一致性重要 |
| 日志收集 → ES | Logstash | 日志解析能力强,与ELK生态集成好 |
| 多数据源批量迁移 | DataX | 数据源支持广泛,批量性能强 |
| 数据仓库ETL | DataX | 批量处理,数据质量控制好 |
| 业务缓存更新 | Canal | 实时性强,保证缓存一致性 |
| 简单定时同步 | Logstash | 配置简单,无需复杂开发 |
那我觉得,其实,可以混合架构,比如(Canal实时 + DataX批量)