
在今天的文章中,我将使用 tavily web search 来创建一个 workflow。当我们搜索一个知识库,如果搜索的结果不是很相关的情况下,那么,我们调佣这个 workflow,并在网页上搜索。最终展示的结果是从互联网上的知识,而不是简单的 "不知道" 这样的结果。我们使用 Elastic Stack 9.3+。
更多阅读:Agentic RAG 详解 - 从头开始构建你自己的智能体系统
写入数据到 Elasticsearch
我们可以参考之前的文章 "Agentic RAG 详解 - 从头开始构建你自己的智能体系统",把网页 https://em360tech.com/tech-articles/what-llama-3-everything-you-need-know-about-metas-new-ai 的数据写入到 Elasticsearch 中去。这个网页的知识只有关于 llama 3 的知识,而没有其它的知识。我们将在下面对这个建立起来的知识库进行搜索。
我们使用的代码是:https://github.com/liu-xiao-guo/twosetai/blob/main/13_agentic_rag_es_workflow.ipynb
创建 🔎 Web Search via Tavily workflow
在 Kibana 中创建如下的 workflow:
# =============================================================================
# Workflow: 🔎 Web Search via Tavily
# Category: search
#
# This workflow is manually triggered and allows users to input a search query,
# defaulting to "what is the population of Malta?". It performs a web search using
# the Tavily API by sending a POST request with JSON payload and authorization.
# =============================================================================
name: 🔎 Web Search via Tavily
enabled: true
# ---------------------------------------------------------------------------
# TRIGGERS
# ---------------------------------------------------------------------------
triggers:
- type: manual
# ---------------------------------------------------------------------------
# INPUTS
# ---------------------------------------------------------------------------
inputs:
- name: query
default: what is the population of Malta?
description: query to pass into Tavily search
type: string
# ---------------------------------------------------------------------------
# STEPS
# ---------------------------------------------------------------------------
steps:
# -------------------------------------------------------------------------
# STEP 1: tavily_search
# -------------------------------------------------------------------------
# Performs a web search using the Tavily API.
- name: tavily_search
type: http
with:
url: https://api.tavily.com/search
method: POST
headers:
Content-Type: application/json
Authorization: Bearer <Your Tavily API key>
body: |
{
"query": "{{ inputs.query }}"
}
# -------------------------------------------------------------------------
# STEP 2: Process each Tavily result
# -------------------------------------------------------------------------
- name: process_each_result
type: foreach
foreach: "{{ steps.tavily_search.output.data.results }}"
steps:
- name: log_result
type: console
with:
message: |
Title: {{ foreach.item.title }}
URL: {{ foreach.item.url }}
Content: {{ foreach.item.content }}在上面,我们必须填入自己的 Tavily API key。这个 key 可以是免费的,针对开发者而言。
创建 search-for-llama 工具
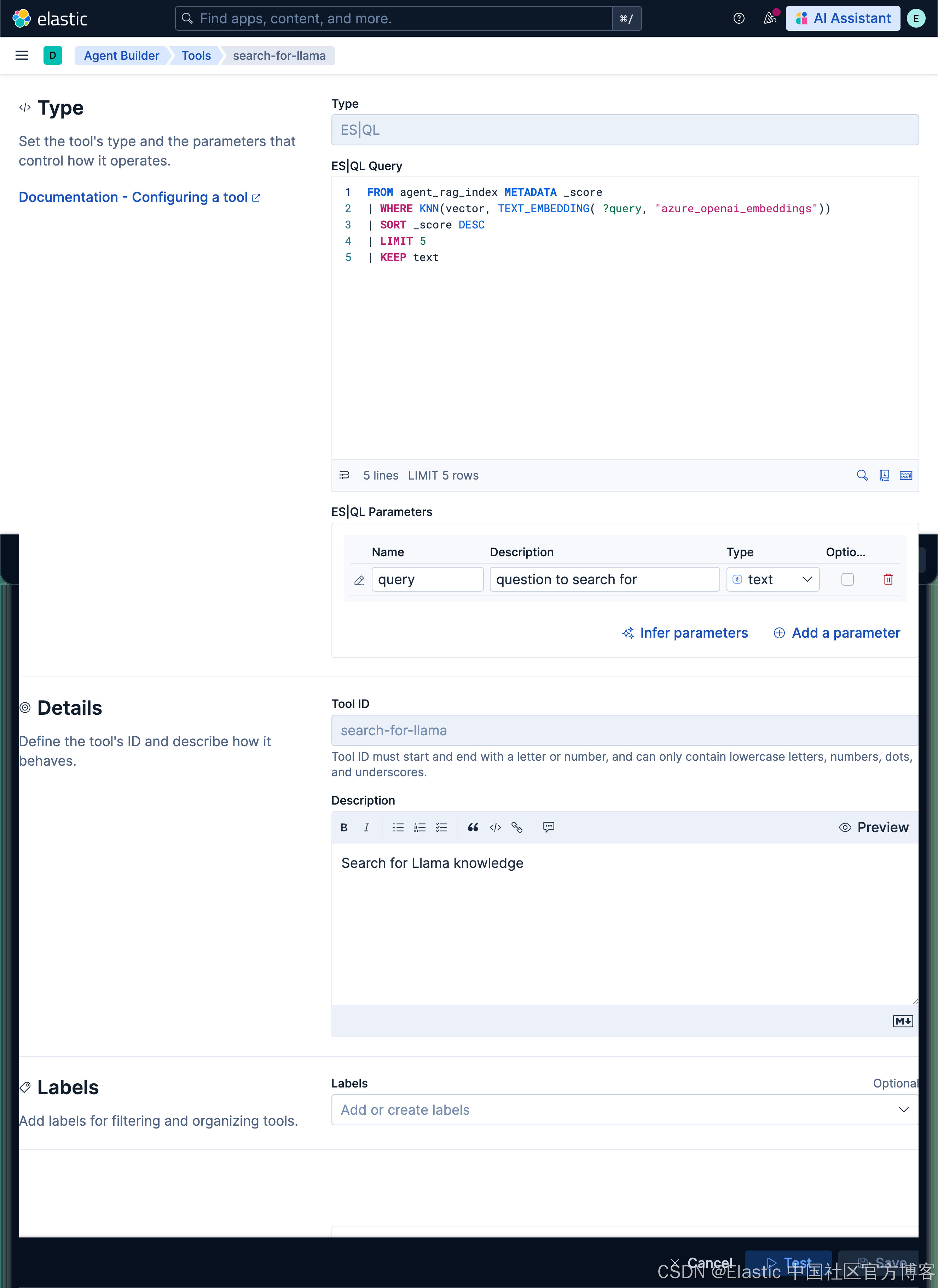
FROM agent_rag_index METADATA _score
| WHERE KNN(vector, TEXT_EMBEDDING( ?query, "azure_openai_embeddings"))
| SORT _score DESC
| LIMIT 5
| KEEP text我们创建上面的 search-for-llama 工具。它使用向量搜索来搜索我们的知识库。
创建 Search for Llama 智能体
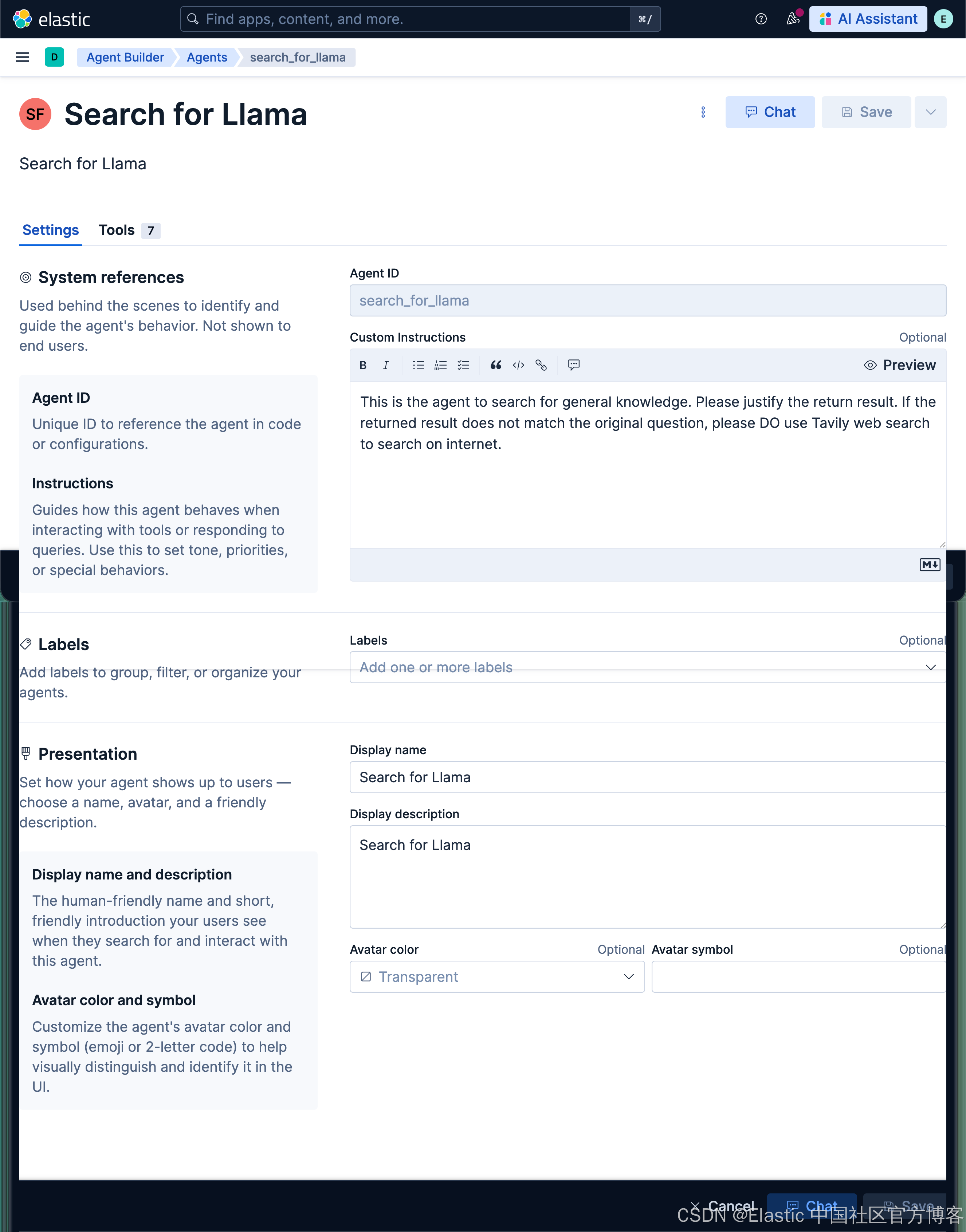
This is the agent to search for general knowledge. Please justify the return result. If the returned result does not match the original question, please DO use Tavily web search to search on internet.如上所示,当我们搜索到的结果不能和搜索的话题匹配的话,那么我们将自动使用 Tavily 搜索来搜索网页来得到结果。它包含如下的工具:
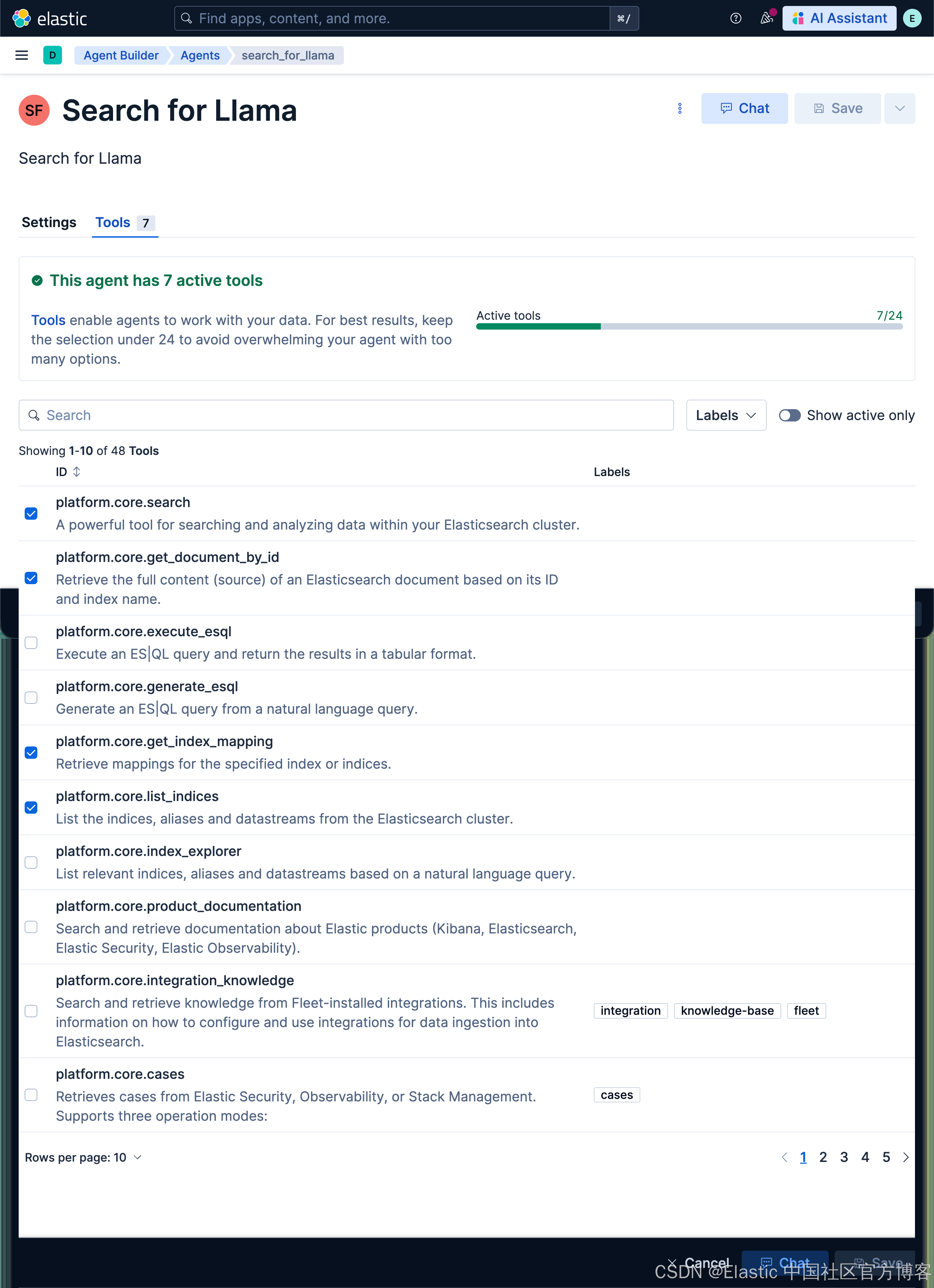
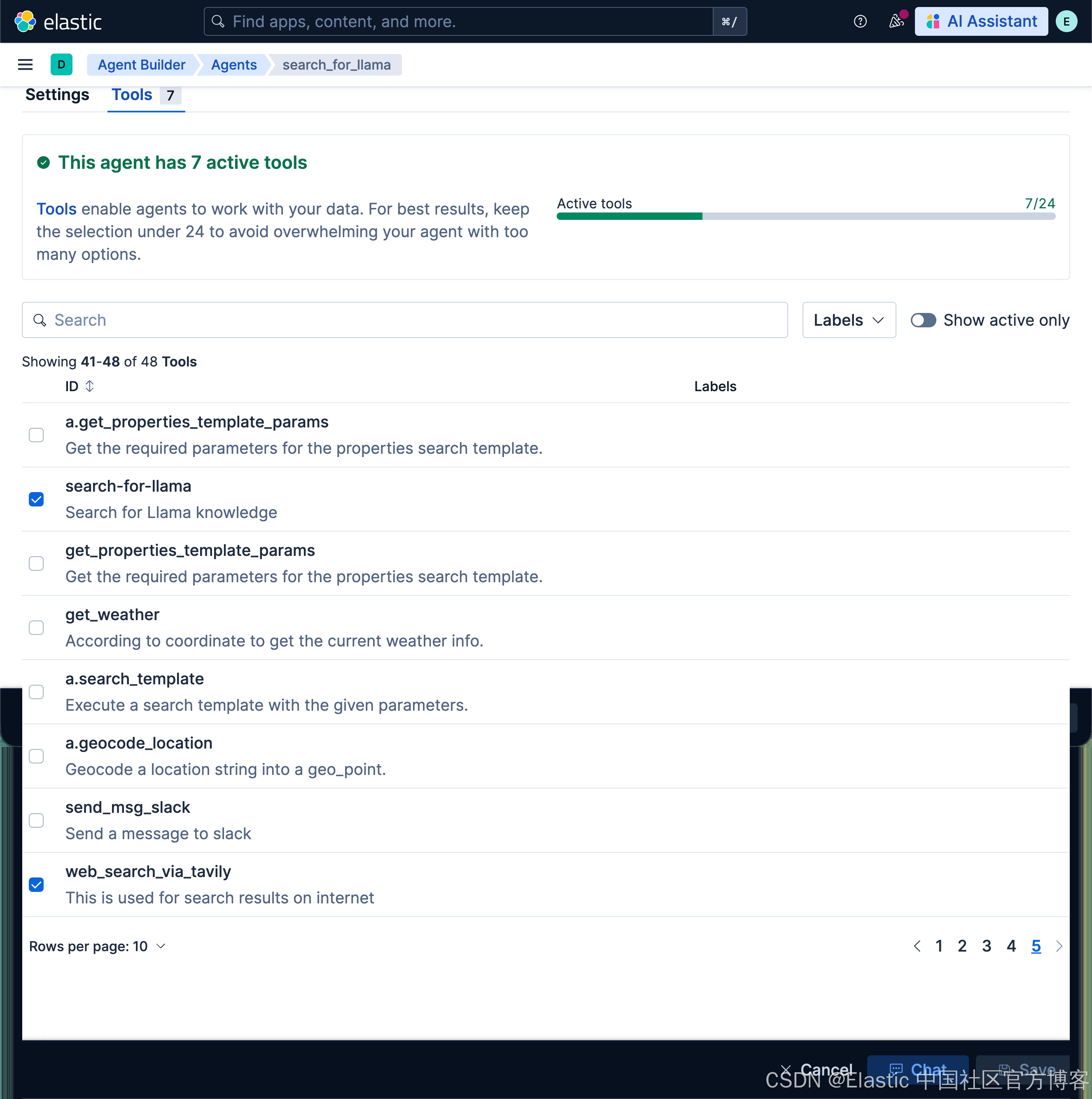
测试
我们使用如下的问题来进行提问:
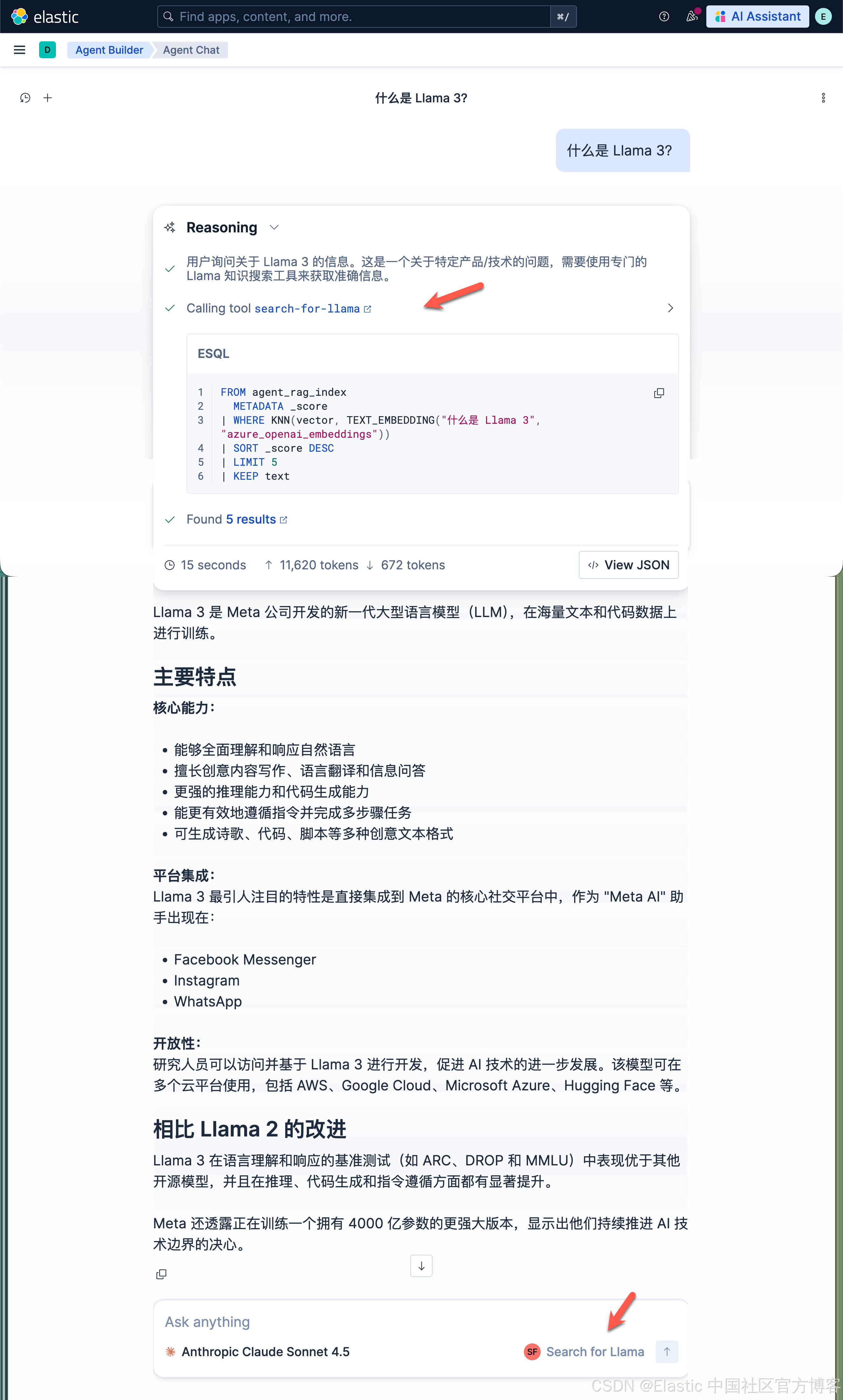
如上所示,它生成的结果和问题匹配,所以它没有调用 Tavily 来进行搜索网页。
我们再次使用如下的话题来进行提问:

很显然,我们的知识库没有相应的知识。它最终调用 Tavily 网页搜索来查询到相应的知识。
最后,祝大家创建智能体愉快,也祝大家新春快乐!