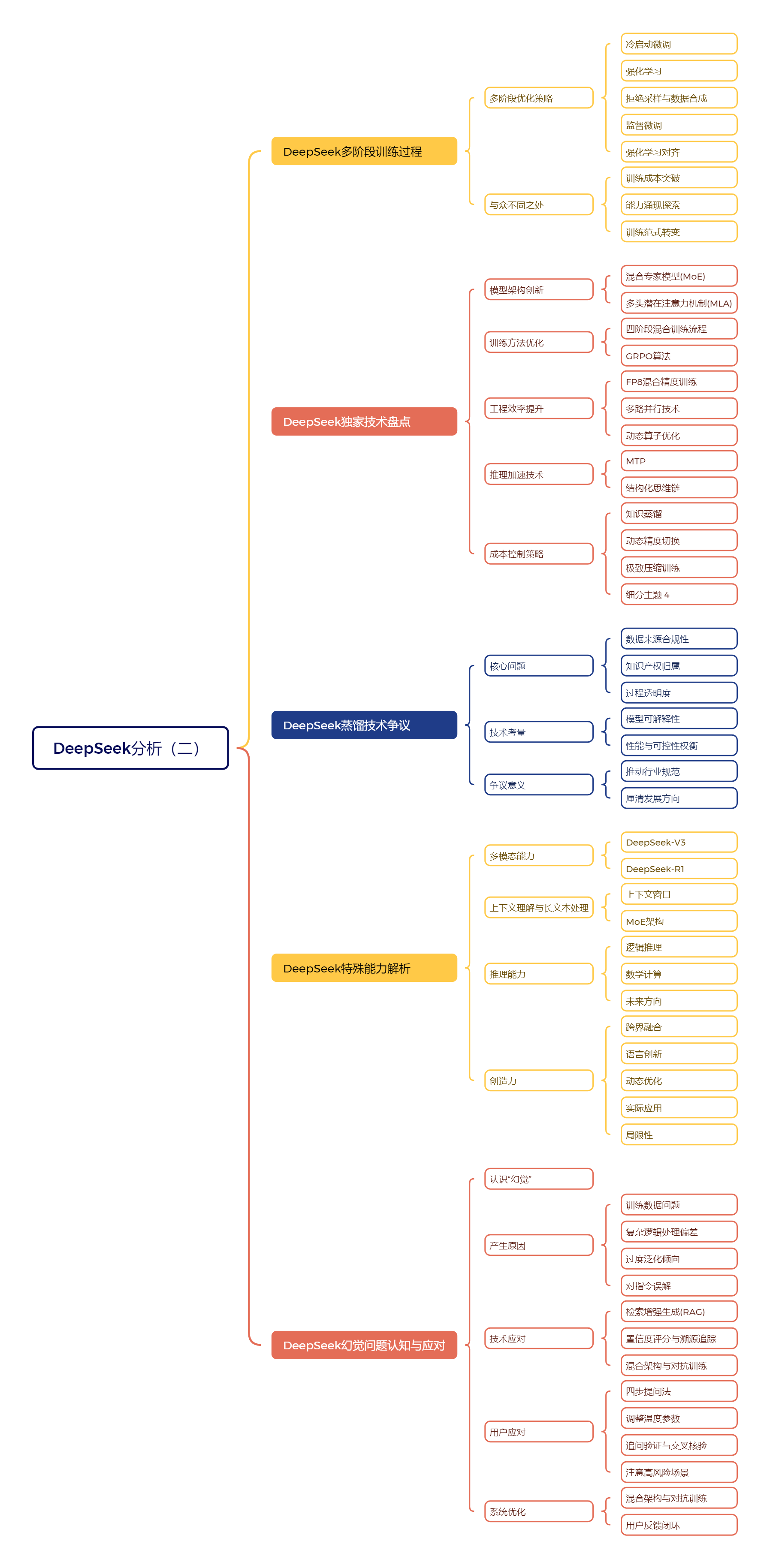
一、DeepSeek多阶段训练过程
1、多阶段优化策略
**【冷启动微调】**冷启动微调是DeepSeek训l练的第一步,使用少量高质量数据,引导模型掌握基本推理逻辑。
**【强化学习】**强化学习阶段,DeepSeek:采用GRPO算法,引入多维度奖励机制。
**【拒绝采样与数据合成】**模型对未标注问题生成候选答案,筛选高质量答案作为样本,同时生成合成数据,提高训练数据质量和多样性。
**【监督微调】**监督微调阶段,DeepSeek采用参数解冻策略和渐进式训练策略,选择性调整参数,初期重点训练数学和代码类任务,后期加入通用问答数据,提升模型在通用任务中的表现。
**【强化学习对齐】**强化学习对齐阶段,DeepSeek使用混合奖励模型,设定不同任务的奖励目标,引入对抗样本训练,采用动态温度调度策略,使模型输出更贴近人类价值观和表达习惯。
2、与众不同之处
**【训练成本突破】**DeepSeek通过算法改进和工程优化,大幅降低训练成本。GRPO算法减少约30%的计算量,合成数据替代90%的人工标注数据,8bit量化技术压缩40%的显存占用。
**【能力涌现探索】**DeepSeek训练目标不仅是提高性能指标,更在于理解大模型如何发展出复杂能力。通过精心设计的奖励函数,模型展现出类似自我纠错、多步推理、跨领域类比等涌现能力。
**【训练范式转变】**DeepSeek训练范式从单纯依赖数据和算力堆砌,转向更注重算法创新和工程细节的精密调控,代表了大模型发展的重要方向。
二、DeepSeek独家技术盘点
1、模型架构创新
**【混合专家模型(MoE)】**MoE模型由多个"专业专家"组成团队,每个专家专注于特定领域,引入动态路由机制,根据输入内容选择合适专家参与计算,避免资源浪费,提升计算效率,实现6710亿参数规模,推理效率提升5倍以上。
**【多头潜在注意力机制(MLA)】**MLA机制通过潜在空间映射技术压缩KV缓存,减少显存占用,使模型能处理长达10万个token的文本,增强对长文本的理解能力,有效降低显存消耗,提高推理效率。
2、训练方法优化
**【四阶段混合训练流程】**DeepSeek采用四阶段混合训练流程,包括冷启动微调、强化学习、监督微调和强化学习对齐,每个阶段都有明确目标和方法,逐步提升模型性能。
**【GRPO算法】**GRPO算法跳过传统PPO算法中额外训练价值网络的环节,通过比较群体中其他模型的表现相对评估当前模型优劣,训练速度快18倍,收敛样本量减少63%。
3、工程效率提升
**【FP8混合精度训练】**FP8混合精度训练将GEMM运算从常规的16位或32位浮点数压缩到8位,提升训川练速度2.1倍,减少GPU显存占用43%,提高性价比。
**【多路并行技术】**DeepSeek采用DualPipe多路并行技术,实现l6路流水线并行和64路专家并行,提升计算效率,千卡并行效率达89.76,通信开销降低37%。
**【动态算子优化】**动态算子优化根据任务类型自动匹配最优底层计算方式,提升模型在H100GPU上的推理吞吐量至每秒3270 token,相比A100提升2.8倍
4、推理加速技术
**【MTP】**MTP技术允许模型在生成当前token的同时预判接下来2~3个tokent的内容,减少重复计算,解码速度提升4.2倍,token接受率高达91%。
**【结构化思维链】**结构化思维链强制模型按固定逻辑结构输出结果,如"分析→验证→结论",结合规则引擎实时校验中间步骤,使模型在GSM8K数学题测试中的错误自查修正率达到78%。
5、成本控制策略
**【知识蒸馏】**知识蒸馏利用已有高质量模型生成训练数据,DeepSeek使用规则引擎筛选合成数据,替代90%的人工标注数据,降低数据获取成本。
**【动态精度切换】**动态精度切换技术根据任务复杂程度自动在FP16和INT8之间切换,节省能耗,单位tokeni的能耗低至0.0028瓦时,推理电费成本降低82%.
**【极致压缩训练】**多项技术协同作用,将DeepSeek训练成本压缩到极低水平,展现成本优势,体现资源利用率领先水平。
三、DeepSeek蒸馏技术争议
1、核心问题
**【数据来源合规性】**DeepSeek蒸馏技术引发争议,数据来源合法性是核心问题之一。若"教师模型"使用未经授权数据,通过蒸馏训练的"学生模型"也可能面临"数据来源不清"的质疑。
**【知识产权归属】**知识产权归属复杂,若"教师模型"使用受版权保护内容,通过蒸馏生成的"学生模型"可能侵权。目前法律对AI模型中"知识"归属及输出内容版权问题未明确界定。
**【过程透明度】**蒸馏过程透明度受关注,若DeepSeek未公开"教师模型"训练数据和方式,外界难以判断其符合道德和法律标准,影响公众对技术信任。
2、技术考量
**【模型可解释性】**DeepSeek采用蒸馏与微调等技术提升Rl模型表现,但也使模型难以理解和解释,变成"黑箱"。相比之下,R1Zero完全通过强化学习训练,可解释性更强,但输出质量、语言流畅度不如R1。
**【性能与可控性权衡】**这是AI发展过程中的技术难题,DeepSeek在提升性能的同时,面临可解释性降低的挑战,需要在性能与可控性之间找到平衡。
3、争议意义
**【推动行业规范】**DeepSeek蒸馏技术争议反映出AI行业快速发展中面临的共性挑战,促使行业思考如何在技术创新的同时,建立完善的法律框架和伦理规范,确保技术健康发展。
**【厘清发展方向】**通过深入讨论这些问题,可更好地厘清AI技术发展方向,为未来技术发展打下坚实基础,推动AI技术朝着更健康、可持续的方向前进。
四、DeepSeek特殊能力解析
1、多模态能力
**【DeepSeek-V3】**DeepSeek-V3具备原生多模态能力,能处理文字、图像、声音、视频等多种信息,适用于智能客服、跨语言翻译、内容创作等场景。其架构类似混合专家模型,不同"专家"处理不同模态信息,通过动态注意力机制融合,实现高效协同工作。
**【DeepSeek-R1】**DeepSeek-Rl专注于文本深度理解和推理,擅长逻辑思维和语言处理。通过外部框架如Align-Anything框架扩展,R1也可获得视觉能力,处理图像信息,甚至在结合视觉信息后,推理能力有所提升,展现出"模态穿透效应"。
2、上下文理解与长文本处理
**【上下文窗口】**DeepSeek,特别是V3版本,支持高达128 K token的上下文长度,相当于20万个汉字,可处理长篇内容,如小说、报告等。其引入动态稀疏注意力机制,像人类"跳读"技巧,处理超长文本时保持高效信息追踪。
**【MoE架构】**DeepSeek采用MoE架构,将长文本不同段落分配给擅长的"专家子网络",并行工作后汇总信息,实现全局语义分析,避免逻辑断裂。在金融分析、法律检索、科研等领域有出色表现,但面对超长文本时,末端信息召回能力会下降。
3、推理能力
**【逻辑推理】**DeepSeek在逻辑推理方面表现出色,能准确识别逻辑谬误,处理反直觉逻辑题和高阶逻辑任务,正确率高。其推理机制具备灵活性和可塑性,能自我纠错和适应,但面对精心设计的逻辑陷阱题时,可能出现判断失误。
**【数学计算】**DeepSeek在数学计算方面达到行业领先水平,基础数学运算和高阶数学领域表现优异,如在MATH-500和AIME2024数学竞赛中准确率高。其在物理方程推导等综合任务中也展现强大能力,但面对MO级别压轴题时,推理链条构建仍有不足。
**【未来方向】**尽管DeepSeek在推理能力上取得突破,但仍存在局限性,未来需进一步优化,提升在复杂推理任务中的表现,推动Al在推理领域持续发展。
4、创造力
**【跨界融合】**DeepSeek能将不同概念创造性结合,如将古典音乐与现代短视频风格融合,生成有趣视频脚本。
**【语言创新】**它在语言表达上创新能力强,能创造新颖词语和表达方式,如"早八续命水"增强语言生动性和表现力,适合多种创作场景。
**【动态优化】**DeepSeek借助强化学习不断优化生成内容,缩短从草稿到优质内容的周期,能在不同文学风格间自由切换,提升创作效率和质量。
**【实际应用】**在网络小说创作、商业文案撰写、公文写作、学术辅助等领域实用价值高,能高效生成大量内容,提升创作效率,但情感表达和原创性方面仍有挑战。
**【局限性】**DeepSeek在情感描写细腻度和版权问题上存在不足,其创造力多体现在元素重新组合和优化上,需人类提供创意框架,未来创作模式可能是人机协同。
五、DeepSeek幻觉问题认知与应对
1、认识"幻觉"
DeepSeek有时会出现"幻觉"现象,即输出看似合理但错误的内容,类似人在做梦时经历的真实情景,但醒来发现是虚构的。这并非故意编造,而是由于其工作机制与人类大脑不同。
2、产生原因
**【训练数据问题】**训川练数据中包含错误信息,如网络谣言等,模型在学习过程中被"污染",导致输出错误。
**【复杂逻辑处理偏差】**在处理复杂逻辑或多步骤任务时,模型可能出现偏差,导致结果出错。
**【过度泛化倾向】**模型可能将局部、特定知识错误推广到更广泛场景,产生"以偏概全"的错误认知。
**【对指令误解】**用户提出开放式问题或要求推测性回答时,模型可能误以为鼓励"自由创作",从而输出脱离现实的内容。
3、技术应对
**【检索增强生成(RAG)】**给AI增加"外脑",在回答问题前查阅权威知识库,确保信息准确可靠。
**【置信度评分与溯源追踪】**为模型输出添加置信度评分,让用户判断答案可信度;开发溯源追踪系统,提供参考资料链接,方便用户验证。
**【混合架构与对抗训练】**构建混合架构,关键环节引入符号系统,如调用数学引擎计算;通过对抗训练,使用陷阱问题数据集训练模型,提高错误识别能力。
4、用户应对
**【四步提问法】**提问时明确背景、任务、要求和补充说明,引导模型更准确输出信息。
**【调整温度参数】**适当调低模型的温度参数,如设置为0.5以下,使输出更稳定、少随机性。
**【追问验证与交叉核验】**多问细节问题,通过追问检验信息真实性;建立交叉核验矩阵,将输出内容与搜索引擎、专业数据库比对,甚至请教专家,确保信息准确。
**【注意高风险场景】**涉及人身安全、财产决策或引用非公开政策文件时,必须多重验证,不能盲目相信AI输出。
5、系统优化
**【混合架构与对抗训练】**构建混合架构,引入符号系统提高准确性;通过对抗训川练,提升模型错误识别能力。
**【用户反馈闭环】**建立用户反馈闭环,收集错误案例用于模型持续微调和改进,形成良性循环。