- 论文标题:YOLO-Master: MOE-Accelerated with Specialized Transformers for Enhanced Real-time Detection
- 论文链接:http://arxiv.org/abs/2512.23273
- 代码链接:https://github.com/Tencent/YOLO-Master
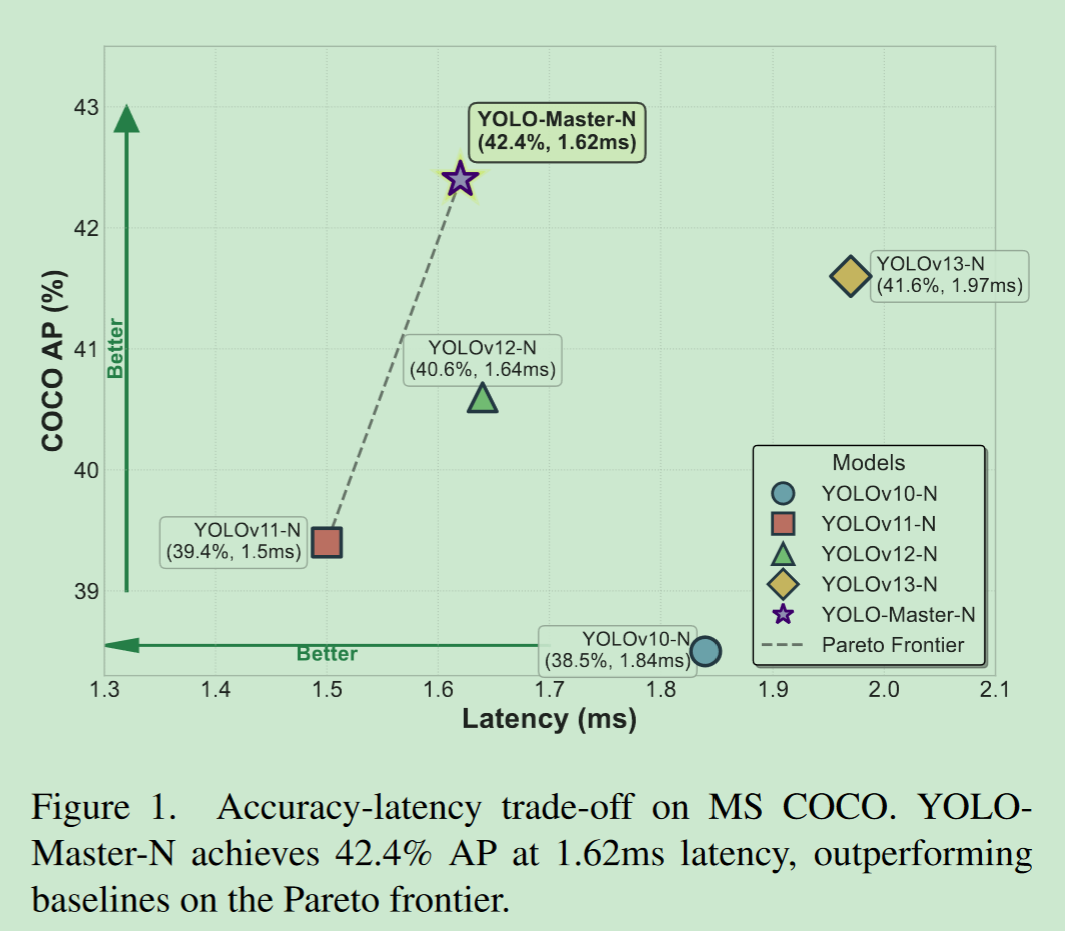
一、问题
这些模型依赖于对所在这里插入图片描述
有输入进行统一处理的静态稠密计算,错误地分配了表征能力和计算资源,例如将整体资源分配在琐碎的场景上,而忽略了复杂的场景。这种不匹配导致了计算冗余和次优的检测性能。
- 静态稠密计算
每个输入,不管其复杂程度如何,都通过相同的网络路径处理,计算资源是统一的。这种根本性的限制阻止了基于输入特征的自适应容量分配。
二、方法
YOLO-Master引入第一个为基于CNN的轻量级实时检测器量身定制的MoE框架。
ES-MoE模块遵循图2 (左下角)所示的信息流。具体来说,ES-MoE包含3个关键组件:i )产生实例依赖路由信号的动态路由网络;ii )选择最相关专家的Softmax门机制;iii )一个加权聚合单元,将激活的专家输出融合成一个精化的表示。核心动态路由网络采用分阶段路由策略,在训练过程中使用软路由以鼓励专家专长,在推理过程中使用硬Top-K激活以选择最相关的专家,如图2 (右)所示。
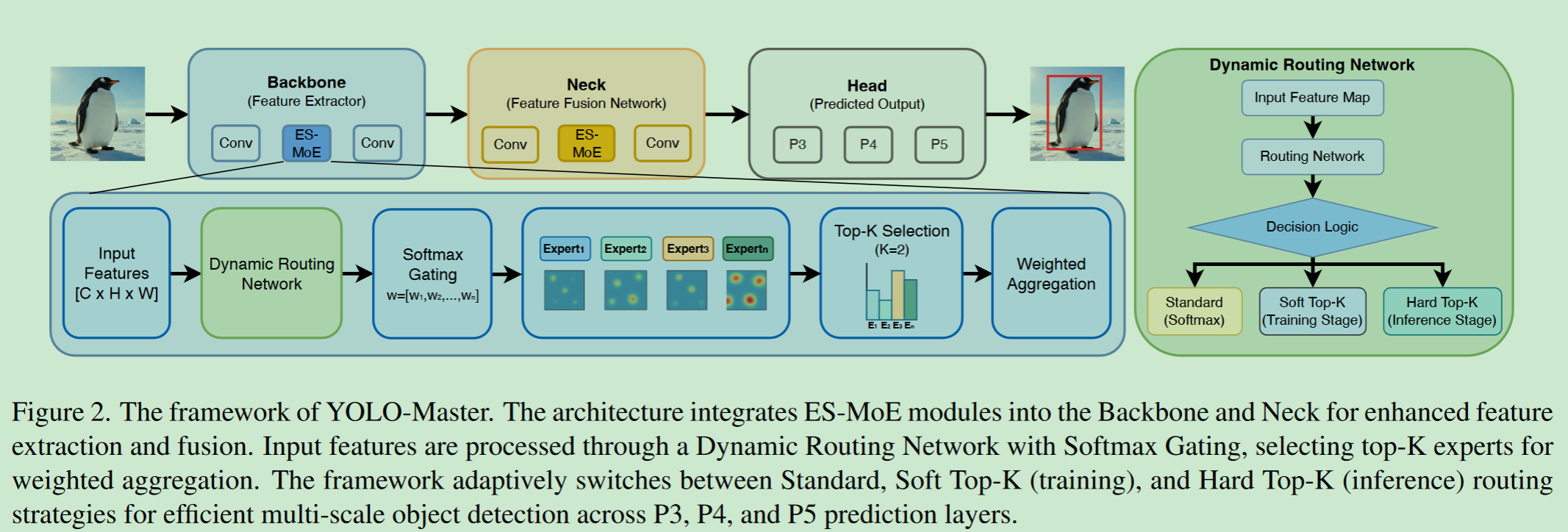
ES-MoE的关键创新点在于其分阶段路由策略,如图2 (右面板)所示。在训练过程 中,Soft Top-K路由机制通过为所有专家分配平滑、可微的权重来确保梯度连续性 ,同时强调最高权重的专家。在推理过程 中,该模块切换到Hard Top-K策略,仅激活K个专家,以实现实际的计算稀疏性和加速 7 。这种自适应机制有效地解决了传统密集模型中固有的计算冗余问题,实现了跨不同部署阶段的高效专家选择。
-
1、
Dynamic Routing Network(1)Efficient Expert Architecture;
使用DW卷积解耦空间和通道信息
(2)Diverse Receptive Fields
使用不同卷积尺度更有效地处理多尺度的特征
(3)Expert Output and Aggregation
每个专家输出特征维度为: R C o u t × H × W R^{C_{out}}\times H \times W RCout×H×W,通过与路由权重routing weights Ω = ω 1 , . . . , ω E Ω = ω_{1}, . . . , ω_{E} Ω=ω1,...,ωE点乘,得到最终ES-MoE模块的输出。
-
2、
Gating Network Design门控网络G在ES - MoE模块中起着至关重要的作用,负责产生激活E个专家的原始 l o g i t s Λ ∈ R E × 1 × 1 logits \ Λ\in R^{E \times 1 \times 1} logits Λ∈RE×1×1。其设计坚持轻量级原则,保证路由决策过程本身不会成为计算瓶颈。
(1)Information aggregation
对于一个输入特征图 X ∈ R C × H × W X \in R^{C \times H \times W} X∈RC×H×W使用全局平均池化GAP压缩输入特征到一个全局特征 P ∈ R C × 1 × 1 P \in R^{C \times 1 \times 1} P∈RC×1×1。
(2)Logits computation
一个参数高效的门控网络G,这个网络由两个 1 × 1 1 \times 1 1×1的卷积非线性层( C i n → C r e d → E C_{in} \rightarrow C_{red} \rightarrow E Cin→Cred→E)组成。引入通道缩减比 γ = 8 γ = 8 γ=8,定义中间通道尺寸 C r e d = m a x ( C / γ , 8 ) C_{red} = max( C / γ , 8) Cred=max(C/γ,8),公式化如下:
Λ = C o n v 1 × 1 o u t = E ( S i L U ( C o n v 1 × 1 o u t = C r e d ( P ) ) ) Λ = Conv^{out=E}{1×1} (SiLU (Conv^{out=C{red}}_{1×1} (P))) Λ=Conv1×1out=E(SiLU(Conv1×1out=Cred(P)))
(3)Expert logits
生成专家 l o g i t s Λ = Λ 1 , Λ 2 , . . , Λ E logits \ Λ = Λ_{1},Λ_{2},..,Λ_{E} logits Λ=Λ1,Λ2,..,ΛE的计算复杂度仅取决于通道维度 C C C和专家数量 E E E,与输入特征图的空间维度 H × W H × W H×W无关。
Phased Routing Strategy
(1)Computation of Expert Weights Ω Ω Ω。门控网络G输出原始的逻辑值 Λ ∈ R E × 1 × 1 Λ \in R^{E \times 1 \times 1} Λ∈RE×1×1,首先, Λ Λ Λ通过softmax归一化得到初始权重:
Ω′ = exp ( Λ i ) ∑ j = 1 E e x p ( Λ j ) Ω′ = \frac{ \exp(Λi) }{ \sum_{j=1}^{E} exp(Λ_{j})} Ω′=∑j=1Eexp(Λj)exp(Λi)
其中, Ω′ Ω′ Ω′代表每个所选专家的概率。
(2)Soft Top-K Strategy (Training Mode)。
采用Soft Top - K策略来加强稀疏性,同时保留非零权重的梯度。首先,定义 L K L_{K} LK为最大的前 K K K个权重,然后,基于 L K L_{K} LK构建二值掩码 M K M_{K} MK:
M K , i = 1 ( i f i ∈ L K ) , e l s e 0. M_{K,i} = 1 \ (if \ i \in L_{K}), else \ 0. MK,i=1 (if i∈LK),else 0.
前K个权重 Ω t r a i n = Ω′ ⊙ M K Ω_{train} = Ω′ \odot M_{K} Ωtrain=Ω′⊙MK,并重新规整为:
Ω t r a i n = Ω′ ⊙ M K ∑ j = 1 E ( ( Ω′ ) j ⊙ ( M K ) j + σ ) Ω_{train} = \frac{Ω′ \odot M_{K}}{\sum^{E}{j=1}((Ω′ ){j} \odot (M_{K})_{j} + \sigma)} Ωtrain=∑j=1E((Ω′)j⊙(MK)j+σ)Ω′⊙MK
仅有K个专家被激活,由于Ω′参与计算,因此保留了logits Λ的连续权重梯度。
(3)Hard Top-K Strategy (Inference Mode).
在推理时直接使用前K个最大逻辑值,并且应用Softmax进行归一化,其他K个逻辑值设置为0:
Ω i n f e r , i = e x p ( Λ i ) ∑ j ∈ L K e x p ( Λ i ) ( i f i ∈ L K ) ; e l s e 0. Ω_{infer,i}=\frac{exp(Λ_{i})}{\sum_{j \in L_{K}} exp(Λ_{i})} \ (if \ i \in \ L_{K}); else \ 0. Ωinfer,i=∑j∈LKexp(Λi)exp(Λi) (if i∈ LK);else 0.
Hard Top-K策略保证了在稀疏前向传播过程中,只调用K个专家模块进行计算,从而在实际硬件上实现了显著的加速。
(4)Dynamic Switching.
模型的前向传播逻辑是基于当前的操作模式( self . training ):Ω在训练时使用Ω_{train} ,在推理时使用 ,在推理时使用 ,在推理时使用Ω_{infer}。通过这种动态切换,在训练效果和推理速度之间实现了一个最优的平衡。
- 3、
损失函数
优化目标是最小化总损失函数 L T o t a l L_{Total} LTotal,它包含两个关键组件:标准的YOLOv8检测损失 L Y O L O L_{YOLO} LYOLO和专门为MoE架构设计的负载平衡损失 L L B L_{LB} LLB。该组合损失公式在保证模型达到较高检测精度的同时,有效地解决了专家利用率不均衡的问题: L T o t a l = L Y O L O + λ L B ⋅ L L B L_{Total} = L_{YOLO} + λ_{LB} · L_{LB} LTotal=LYOLO+λLB⋅LLB 其中 λ L B > 0 λ_{LB} > 0 λLB>0是控制负载均衡项对总损失贡献权重的超参数。
(1)检测损失Detection Loss L Y O L O L_{YOLO} LYOLO.
YOLO的检测损失遵循标准的YOLOv8公式,评估模型在目标分类和定位方面的性能。它由三个核心部分组成:分类损失 L c l s L_{cls} Lcls衡量预测类别和真实类别之间的差异 ,定位损失 L l o c L_{loc} Lloc通常使用CIoU或DIoU损失 来评估预测类别和真实类别之间的重叠和位置偏差,以及一种优化bounding box分布表示的分布聚焦损失 L D F L L_{DFL} LDFL
L Y O L O = L c l s + L l o c + L D F L . L_{YOLO} = L_{cls} + L_{loc} + L_{DFL}. LYOLO=Lcls+Lloc+LDFL.
(2)Load Balancing Loss L L B L_{LB} LLB
引入负载均衡损失 来缓解MoE训练中普遍存在的专家崩溃问题,其中路由网络G倾向于将大多数输入token分配给"更强"或初始化更好的专家的小子集。 L L B L_{LB} LLB通过惩罚每个专家的平均使用频率 μ i μ_{i} μi与理想一致之间的偏差来鼓励所有专家的均衡使用。定义专家 i i i在当前批次和所有空间位置上的平均使用频率 μ i μ_{i} μi为:
μ i = E ∑ h = 1 H ∑ w = 1 W ( Ω t r a i n ) i , h , w ∑ j = 1 E ∑ h = 1 H ∑ w = 1 W ( Ω t r a i n ) j , h , w . \mu_{i} = E\\frac{\\sum\^{H}_{h=1} \\sum\^{W}_{w=1}(Ω_{train})_{i, h, w}}{\\sum\^{E}_{j=1} \\sum\^{H}_{h=1} \\sum\^{W}_{w=1}(Ω_{train})_{j, h, w}}. μi=E∑j=1E∑h=1H∑w=1W(Ωtrain)j,h,w∑h=1H∑w=1W(Ωtrain)i,h,w.
其中, Ω t r a i n Ω_{train} Ωtrain表示在训练阶段计算的Soft Top-K权重。负载均衡损耗 L L B L_{LB} LLB采用均方误差(MSE)形式来衡量 μ i μ_{i} μi与目标均匀利用率 1 / E 1 / E 1/E之间的差异:
L L B = 1 E ∑ i = 1 E ( μ i − 1 E ) 2 . L_{LB} = \frac{1}{E} \sum^{E}{i = 1} (μ{i} - \frac{1}{E})^{2}. LLB=E1i=1∑E(μi−E1)2.
通过最小化 L L B L_{LB} LLB,确保模型在训练过程中充分利用所有 E E E类专家,从而增强其整体泛化能力和鲁棒性。
三、测试
- 1、安装及模型下载
shell
# 1. Create and activate a new environment
conda create -n yolo_master python=3.11 -y
conda activate yolo_master
# 2. Clone the repository
git clone https://github.com/isLinXu/YOLO-Master
cd YOLO-Master
# 3. Install dependencies
pip install -r requirements.txt
pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
# 4. Optional: Install FlashAttention for faster training (CUDA required)
pip install flash_attn目标检测模型:
ES-MOE模型及图像分割模型(截至2026年2月19日官方发布的YOLO-Master-v26.02)
YOLO-Master-EsMoE-N.pt
YOLO-Master-EsMoE-S.pt
YOLO-Master-v0.1-L.pt
YOLO-Master-v0.1-M.pt
YOLO-Master-v0.1-N.pt
YOLO-Master-v0.1-S.pt(https://githu
b.com/Tencent/YOLO-Master/releases/download/YOLO-Master-v26.02/YOLO-Master-v0.1-S.pt)
来自v0.0.0
yolo-master-seg-n.pt
yolo-master-cls-n.pt
bus.jpg图像

- 1、目标检测性能及测试
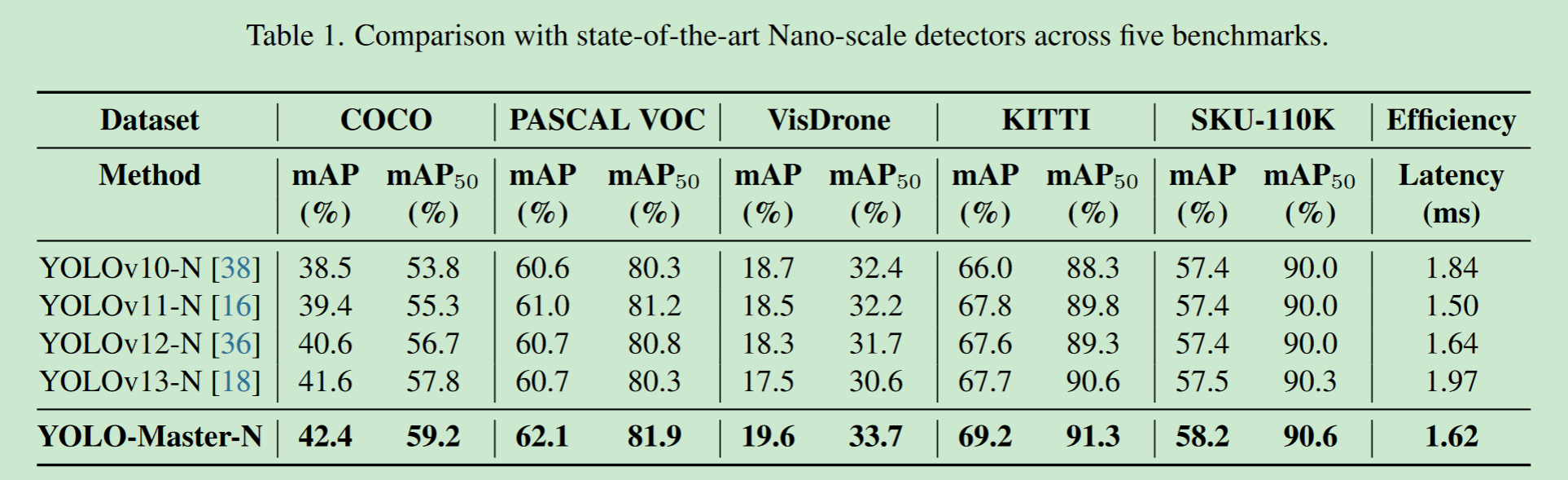
官方提供的性能表现如下:
python
from ultralytics import YOLO
import os
model = YOLO("weights/YOLO-Master-v0.1-N.pt")
# model = YOLO("weights/YOLO-Master-EsMoE-N.pt") # 推理时间快100ms(估计)
results = model("images/bus.jpg")
results[0].show()
results[0].save('res.jpg') 或在终端输入yolo predict model=yolo_master_n.pt source='path/to/image.jpg' show=True。
执行以上代码后,测试结果如下:

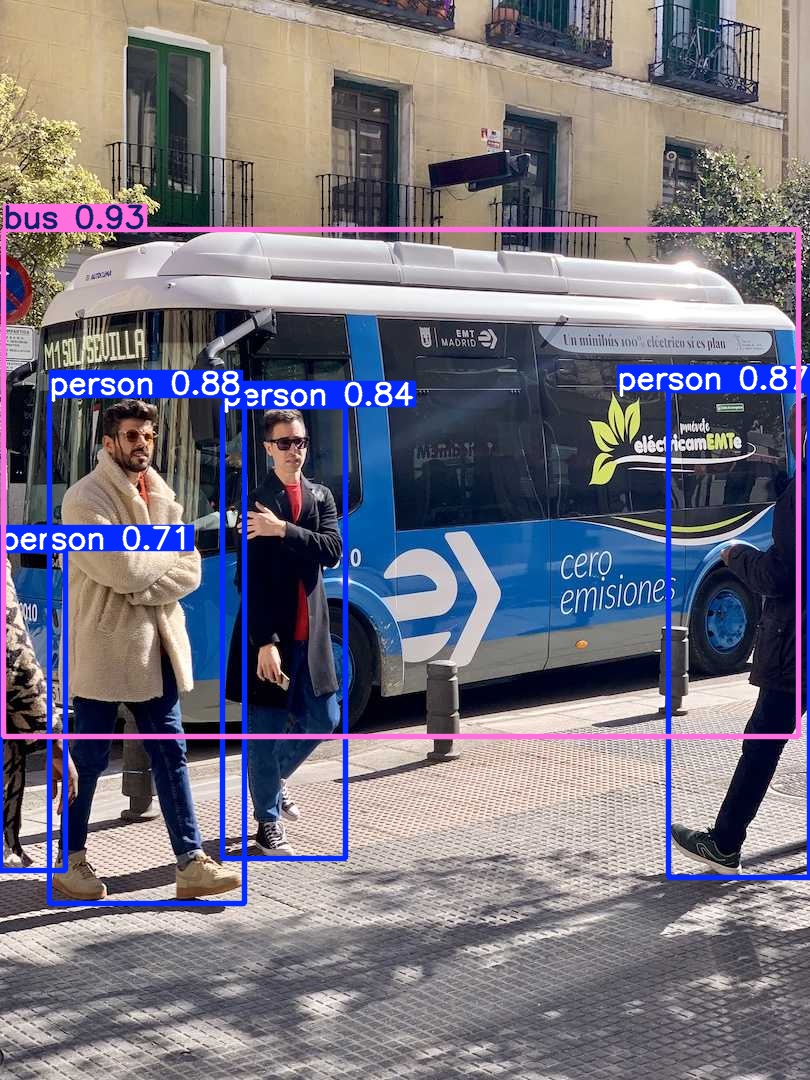
看样子,测试结果比YOLO26的检测效果更好。
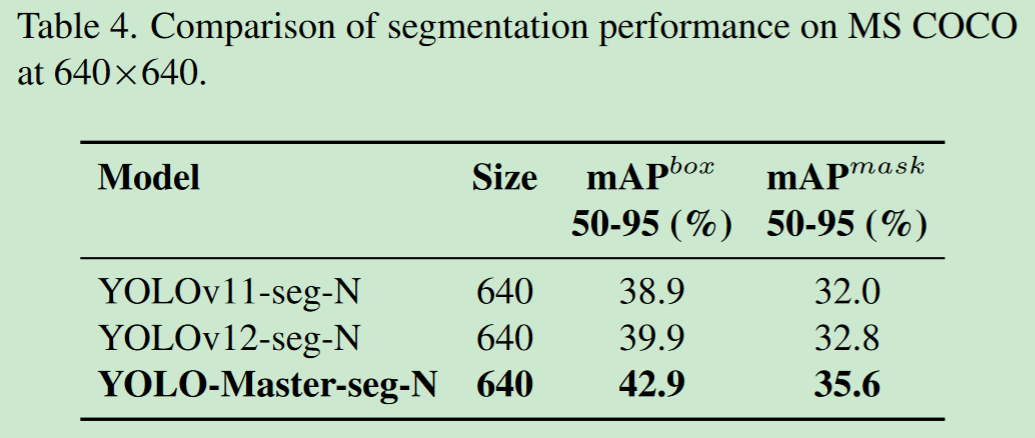
- 2、图像分割性能及测试
官方提供的性能表现如下:
python
from ultralytics import YOLO
import os
model = YOLO("weights/yolo-master-seg-n.pt") # 目前官方只提供该模型
results = model("images/bus.jpg")
results[0].show()
results[0].save('res.jpg') 执行以上代码后,测试结果如下:


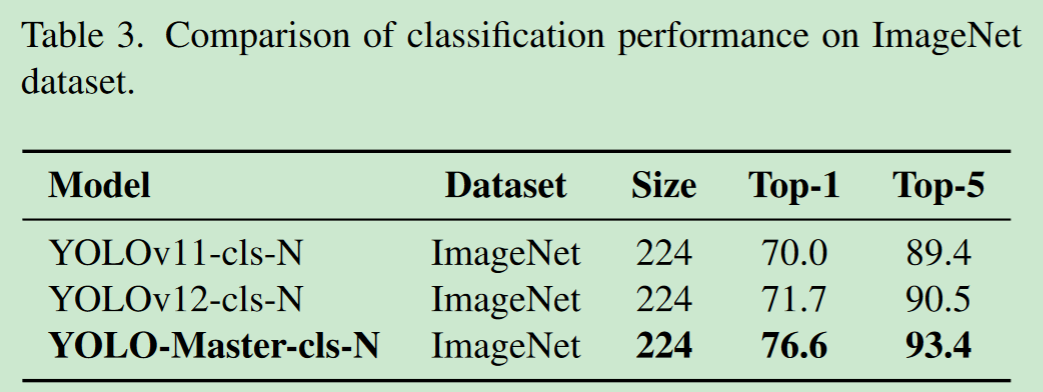
- 3、图像分类
官方提供的性能表现如下:
python
from ultralytics import YOLO
model = YOLO("weights/yolo-master-cls-n.pt").cpu()
results = model("images/bus.jpg")
print(results[0]) 执行以上代码后,测试结果如下:
