本章将涵盖:
- ML 平台的工具链
- 使用 MLflow 实验追踪器跟踪 ML 实验
- 在 MLflow Registry 中存储并使用训练好的模型
- 在 Feast 特征库中注册模型特征
随着我们更深入 ML 工程,现在要解决一个关键挑战:如何可靠地跟踪、复现并部署 ML 实验。本章将介绍一些关键工具,它们能把临时、随意的实验变成生产就绪的 ML 工作流。我们将搭建一个实用的 ML 平台,在保持足够灵活以适配真实场景的同时,显著提升可靠性。
具体来说,我们会探索第 1 章 1.3 节讨论的 ML 平台各个组件。我们将讨论不同的工具/应用:它们如何帮助我们跟踪数据科学实验、存储模型特征,并为流水线编排与模型部署提供支持。我们的目标是用这些工具展示一个完全可用的迷你 ML 平台,并突出它们之间的交互方式。
我们会像大多数数据科学家那样开启 ML 旅程------从理解数据开始。我们将进行探索性数据分析(EDA),把数据集拆分为训练集与测试集,并训练多个模型,选出表现最好的那个。数据科学项目的初期阶段通常以探索为主,因此我们会尝试不同特征、模型超参数与框架。
为了以有组织的方式跟踪实验,我们将使用 MLflow 实验追踪器。等我们得到一个性能满足预期标准的模型后,MLflow 会帮助我们选出最佳模型。随后,我们会把这个模型及其全部依赖放入 MLflow 模型注册表(model registry),这样我们就能复现实验、与其他数据科学家或 ML 工程师协作,或在需要部署时加载该模型。
在实验过程中,我们可能会通过特征工程生成新特征,从而提升模型表现。这些特征也需要被注册,因为模型部署时会用到它们,同时它们也能帮助与团队其他成员协作。为此,我们使用一个叫 Feast 的特征库(feature store)。它既作为特征的存储接口,也提供访问接口,用于模型训练或生成预测。
当特征与模型分别放到各自"该去的地方"之后,我们将聚焦模型部署。我们会把模型部署到批处理与实时两类用例中。对批处理用例,我们使用 Kubeflow Pipelines 编排器生成预测;对实时用例,我们使用 BentoML 作为部署管理器,把模型部署为 API 端点。我们还会处理模型上线后遇到的问题:由于数据分布发生变化,模型性能会随时间退化。我们将使用 Evidently 数据漂移监控工具来跟踪特征数据分布的变化。
所有这些工具都是 ML 平台的重要组件。现在我们可以回到第 1 章中展示过的 ML 平台示意图。把这些工具放到正确位置后,就得到图 4.1。
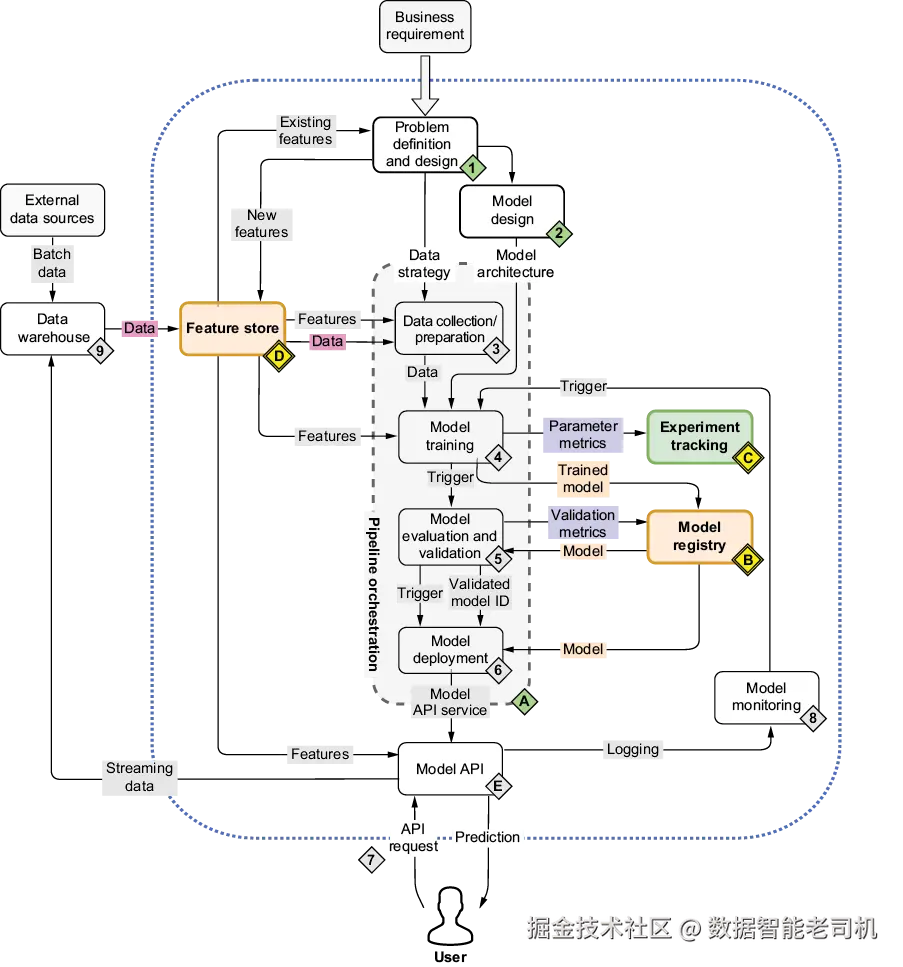
图 4.1 心智地图:我们现在聚焦特征库(D)、实验追踪(C)与模型注册表(B)
我们将用这个 ML 平台来构建一个简单的二分类器:把收入分为 <=50k 与 >50k。我们会使用前面介绍的 MLOps 工具链来构建并部署该模型。虽然示例本身很直接,但其中学到的经验仍可以迁移到更复杂的项目。本章我们将重点放在实验追踪与特征库上。本章全部代码都在 GitHub:https://github.com/practical-mlops/chapter-4。
4.1 使用 MLflow 进行实验追踪(MLflow for experiment tracking)
在构建模型时,跟踪在建模旅程中可能变化的不同参数非常重要。这些参数包括训练/测试数据、模型权重以及模型的准确率指标等。跟踪这些参数有多个原因:
- 可复现性(Reproducibility) ------作为数据科学家,我们可能需要与同事分享工作。跟踪参数能帮助我们复现实验并复刻结果。
- 模型选择(Model selection) ------绝大多数情况下,我们会为同一个用例构建多个模型,它们架构不同、性能指标也不同。跟踪参数能帮助我们确保能选出最佳模型。
- 性能跟踪(Performance tracking) ------我们选中的模型可能需要用更新的训练数据重新训练。如果我们保留了参数,就能把再训练后的模型性能与早期迭代进行对比。
那我们该如何跟踪这些参数?我们可以用版本控制系统,把参数也一并提交。若要重现某个场景,可以打开对应 commit 并重新运行代码。但这要求我们周期性提交,并且如果未来还想找回这些参数,还需要对 commit 做恰当的标记。我们也可以把所有参数写入文件,用它来重建与跟踪实验;但如果我们把这个文件与 Jupyter Notebook 一起分享,还得向其他数据科学家解释如何使用该文件,以便他们在自己的机器上复现实验。为了解决这些问题,我们将使用 MLflow:它提供一个 tracking server,帮助我们跟踪实验参数。
tracking server 提供了一个集中且可扩展的平台,用于管理与追踪 ML 实验。MLflow tracking server 会在模型开发过程中跟踪实验参数,包括模型超参数、数据、指标以及产物(artifacts,例如模型与绘图)。多个用户与团队可以协同使用 tracking server 来跟踪、对比并复现实验。
现在,让我们从大多数数据科学家使用的开发环境开始:Jupyter Notebook。数据分析与 ML 任务的迭代性和探索性,非常适合 Jupyter Notebook 提供的灵活、交互式环境。我们会对收入数据做一些简单 EDA,并构建几个用于收入分类的模型;同时加入一些 MLflow 的追踪逻辑,让我们更容易复现与管理实验。
作为 ML 工程师,我们经常会被问到这样的问题:
- 生产环境里运行的是哪个模型版本?
- 哪些参数带来了最佳结果?
- 六个月前的结果还能复现吗?
MLflow 通过为实验过程提供结构来帮助回答这些问题。我们用这个收入分类示例来看看它如何在实践中工作。
4.1.1 数据探索(Data exploration)
我们先加载收入数据,用 Pandas 的 describe 与 info 获取一些基本描述性统计,如清单 4.1 所示。我们的数据只包含类别变量(取值数量固定的变量),包括 Workclass、Education、Marital-Status、Occupation、Relationship、Race、Sex 与 Native_country。此外还有目标变量 Target,它是二值:<=50K 或 >50K。
Pandas 的 info 显示我们有大约 30,000 行数据。describe 则展示每个类别中有多少唯一值,并给出出现频率最高的类别(top)及其频数(freq)。
清单 4.1 生成收入数据的描述性统计
kotlin
df=pd.read_csv('../data/income_data.csv', index_col=False)
print(df.head() ,'\n') #1
print(df.info(), '\n') #2
print(df.describe(), '\n') #3
Workclass Education Marital-Status Occupation \
0 State-gov Bachelors Never-married Adm-clerical
1 Self-emp-not-inc Bachelors Married-civ-spouse Exec-managerial
2 Private HS-grad Divorced Handlers-cleaners
3 Private 11th Married-civ-spouse Handlers-cleaners
4 Private Bachelors Married-civ-spouse Prof-specialty
Relationship Race Sex Native_country Target
0 Not-in-family White Male United-States <=50K
1 Husband White Male United-States <=50K
2 Not-in-family White Male United-States <=50K
3 Husband Black Male United-States <=50K
4 Wife Black Female Cuba <=50K
Workclass Education Marital-Status Occupation Relationship
count 30162 30162 30162 30162 30162
unique 7 16 7 14 6
top Private HS-grad Married- Prof- Husband
civ-spouse specialty
freq 22286 9840 14065 4038 12463
Race Sex Native_country Target
count 30162 30162 30162 30162
unique 5 2 41 2
top White Male United-States <=50K
freq 25933 20380 27504 22654
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 30162 entries, 0 to 30161
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Workclass 30162 non-null object
1 Education 30162 non-null object
2 Marital-Status 30162 non-null object
3 Occupation 30162 non-null object
4 Relationship 30162 non-null object
5 Race 30162 non-null object
6 Sex 30162 non-null object
7 Native_country 30162 non-null object
...
dtypes: object(9)
memory usage: 2.1+ MB
#1 打印数据框前几行
#2 打印数据框摘要信息
#3 生成数据框的描述性统计接下来,我们生成一些图,用来比较类别变量相对于目标变量的分布,如清单 4.2 所示。我们还会把这些图保存到一个名为 categorical_variable_plots 的目录中。
清单 4.2 类别变量与目标变量分布对比
scss
if not os.path.exists("categorical_variable_plots"):
os.makedirs("categorical_variable_plots")
for i in df.iloc[:,:-1].select_dtypes(include='object').columns:
print(f'Variable {i} \n ')
print(df[i].value_counts())
plot = ggplot(df)+ geom_bar(aes(x=df[i], fill=df.Target),
position='fill') +
theme_bw() +
labs(title=f'Variable {i} ~ Target') +
coord_flip()
print(plot) #1
plot.save(
f"categorical_variable_plots/Variable {i}"
) #2
#1 生成图表,用于对比类别变量与目标变量的分布
#2 将所有图保存到 categorical_variable_plots 目录一个示例图如图 4.2 所示。比如,在这里,自雇人群更有可能收入超过 50K。
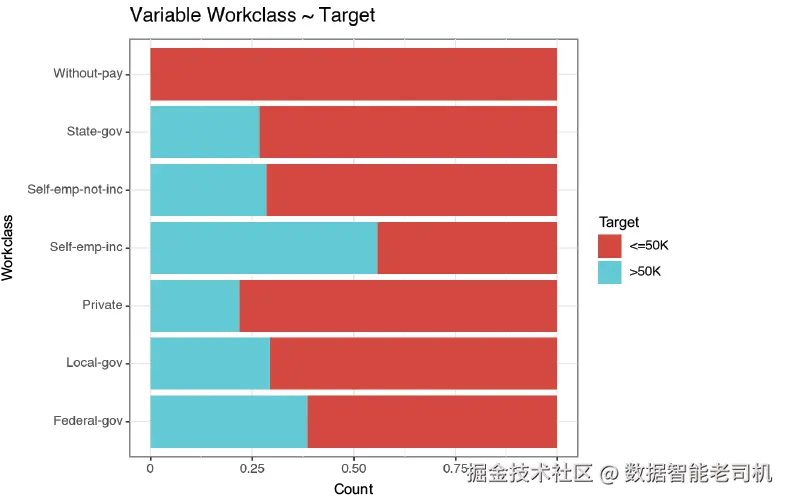
图 4.2 对比 workclass 各类别相对于目标变量分布的图
4.1.2 MLflow 跟踪(MLflow tracking)
MLflow tracking 可以帮助我们把这些图保存到 tracking server。要开始使用它,我们首先需要安装 MLflow:
ini
pip install mlflow==2.6.0然后运行 mlflow ui 启动本地 tracking server,它会在 5000 端口启动一个本地服务。这个命令需要在 notebook 外运行:
mlflow ui
less
[2023-09-22 13:50:58 +0800] [16047] [INFO] Starting gunicorn 21.2.0
[2023-09-22 13:50:58 +0800] [16047] [INFO] Listening at: http://127.0.0.1:5000启动 tracking server 后,我们初始化 MLflow。这一步在 Jupyter Notebook 中只需要做一次:设置 tracking server,并指定一个 experiment 名称,用来存放我们要记录的参数。你可以把 experiment 名称理解为一个"项目",我们在其中跟踪参数。我们把 experiment 命名为 income-classifier:
arduino
mlflow.set_tracking_uri("http://localhost:5000")
mlflow.set_experiment("income-classifier")接下来我们要把图保存到 tracking server:只需要加两行代码------把 for 循环放在 mlflow.start_run 代码块下面。一次 ML 实验或训练过程的一次执行称为一个 run 。每个 run 都有一个唯一标识符,称为 run ID ,并会捕获关键参数,例如指标、模型超参数与产物(artifacts)。在清单 4.3 中,我们用 uuid.uuid4() 显式指定 run name,它会为每次 run 生成一个唯一名称;如果不指定,MLflow 默认会自动生成一个 ID。我们这样做是为了把 EDA 的 MLflow runs 与建模 runs 区分开来。所有 runs 又都归属于一个 MLflow experiment。Artifacts 可以是模型文件、数据集,甚至是图表。在下面清单里,我们用 mlflow.log_artifacts 并指定存放图的目录名称,把图保存下来。
清单 4.3 在 MLflow 中保存图表
scss
with mlflow.start_run(run_name=f"eda-{uuid.uuid4()}"): #1
for i in df.iloc[:,:-1].select_dtypes(include='object').columns:
print(f'Variable {i} \n ')
print(df[i].value_counts())
plot = (
ggplot(df)
+ geom_bar(
aes(x=df[i], fill=df.Target),
position='fill'
)
+ theme_bw()
+ labs(title=f'Variable {i} ~ Target')
+ coord_flip()
)
print(plot)
if not os.path.exists("categorical_variable_plots"):
os.makedirs("categorical_variable_plots")
plot.save(f"categorical_variable_plots/Variable {i}")
mlflow.log_artifacts( #2
"categorical_variable_plots"
)
#1 在上下文中管理一个 MLflow run,并指定唯一 run name
#2 使用 mlflow log_artifacts 保存图表目录现在如果我们在浏览器打开 http://localhost:5000,就能看到 MLflow UI(图 4.3)。侧边栏里会列出两个 experiments:一个是默认 experiment,另一个是我们创建的、用于存放图表的 income-classifier experiment。
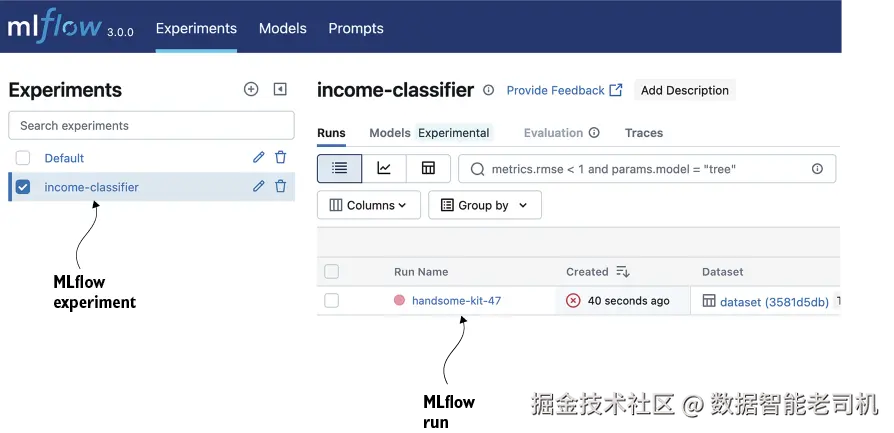
图 4.3 MLflow UI。左侧 experiments 列表显示我们新建的 income-classifier experiment。启动 MLflow run 并保存图表后,Run Name 下会出现一条新记录。
点击该 experiment 以及新创建的 run,就能进入单次 run 的页面。这里会包含 run 描述、该 run 生成的数据集、模型参数、指标与 artifacts。生成的图会出现在 run 的 Artifacts 标签页下(图 4.4)。
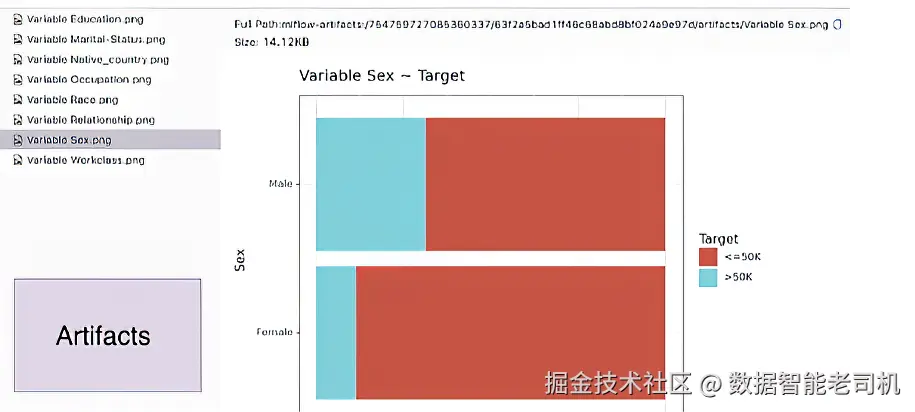
图 4.4 所有图都在 Artifacts 下。Run 的 artifacts 可以包含图表、文件,以及任何能保存到磁盘的对象。
接下来进入建模步骤------把数据集拆分为测试集与训练集。为此,我们首先要把类别变量转换为 dummy 变量(哑变量)或布尔指示变量。我们使用 pd.get_dummies 来做。我们也用 one-hot 编码把 <=50K 与 >50K 编成 0 与 1(见清单 4.4)。此外,我们会保存列名列表,后续做推理时会用到。最后,我们用 sklearn 提供的 train_test_split 函数来拆分数据集。
清单 4.4 使用 one-hot 编码把类别变量转换为 dummy
ini
target=df.Target
feature_df=df.drop('Target', axis=1)
encoder = OneHotEncoder(
sparse_output=False,
drop="if_binary"
) #1
target=encoder.fit_transform(np.array(target).reshape(-1,1))
dummyfied_df = pd.get_dummies(
feature_df,
drop_first=True,
sparse=False,
dtype=float
) #2
col_list = dummyfied_df.columns.to_list()
with open('column_list.pkl', 'wb') as f:
pickle.dump(col_list, f) #3
X_train, X_test, y_train, y_test = train_test_split(
dummyfied_df,
target,
train_size=0.80,
shuffle=True
) #4
#1 对特征与目标做编码
#2 把类别变量转换为 dummy 变量
#3 保存列名列表与顺序,供后续推理使用
#4 将数据拆分为训练集与测试集我们需要把这些数据集保存到外部位置。这个位置会被 MLflow 跟踪,使我们在需要复现或调试时能加载数据集。我们把数据集存到一个 MinIO bucket 里(当然也可以选择任何对象存储:Google Cloud Storage GCS、Amazon Simple Storage Solution S3)。
我们使用的 MinIO 实例与 Kubeflow 使用的是同一个。我们通过 kubectl port-forward 在本地工作站与 MinIO 实例之间建立连接:
bash
kubectl port-forward svc/minio-service -n kubeflow 9000:9000然后在浏览器中连接 MinIO,用默认用户名/密码 minio/minio123 登录。接着点击界面左下角(加号按钮)创建一个名为 mlflow-datasets 的新 bucket。我们会把数据集存放在这个 bucket 里。
现在对象存储已设置好,训练集与测试集也生成了,我们开始构建一些开启了 MLflow tracking 的模型------也就是说,我们会跟踪模型参数、数据集与指标。我们将训练三个模型:一个简单的决策树、一个随机森林,以及一个 XGBoost 模型。我们从决策树开始,如清单 4.5 所示。
清单 4.5 训练模型并用 MLflow 记录
ini
BUCKET_NAME = "mlflow-datasets"
with mlflow.start_run() as run:
results = pd.DataFrame(
index=[
'Roc Auc Score test',
'Accuracy score train',
'Accuracy Score test',
'time to fit'
]
)
tree = DecisionTreeClassifier()
run_id = run.info.run_id
feature_df_path = f"income-classifier-datasets/feature_df-{run_id}.csv"
save_df_to_minio(feature_df, BUCKET_NAME, feature_df_path)
train_df = pd.concat([X_train, pd.Series(y_train.ravel())], axis=1)
train_df_path = f"income-classifier-datasets/train-{run_id}.csv"
save_df_to_minio(
train_df,
BUCKET_NAME,
train_df_path
) #1
test_df = pd.concat([X_test, pd.Series(y_test.ravel())], axis=1)
test_df_path = f"income-classifier-datasets/test-{run_id}.csv"
save_df_to_minio(test_df, BUCKET_NAME, test_df_path)
training_dataset = mlflow.data.from_pandas( #2
train_df, source=f"{BUCKET_NAME}/{train_df_path}"
)
test_dataset = mlflow.data.from_pandas(
test_df, source=f"{BUCKET_NAME}/{test_df_path}"
)
feature_dataset = mlflow.data.from_pandas(
feature_df, source=f"{BUCKET_NAME}/{feature_df_path}"
)
mlflow.log_input(
training_dataset,
context="training"
) #3
mlflow.log_input(test_dataset, context="testing")
mlflow.log_input(feature_dataset, context="reference")
tree.fit(X_train, y_train.ravel()) #4
roc_auc_score_train = roc_auc_score( #5
y_train == 1, tree.predict_proba(X_train)[:, 1]
)
roc_auc_score_test = roc_auc_score(
y_test == 1, tree.predict_proba(X_test)[:, 1]
)
training_accuracy = tree.score(X_train, y_train)
test_accuracy = tree.score(X_test, y_test)
mlflow.log_metric( #6
"roc_auc_score_train",
roc_auc_score_train
)
print(f"Roc Auc Score train: {roc_auc_score_train}\n")
mlflow.log_metric("roc_auc_score_test", roc_auc_score_test)
print(f"Roc Auc Score test: {roc_auc_score_test}\n")
mlflow.log_metric("training_accuracy", training_accuracy)
print(f"Accuracy train: {training_accuracy}")
mlflow.log_metric("test_accuracy", test_accuracy)
print(f"Accuracy test: {test_accuracy}")
mlflow.sklearn.log_model(tree, "income-classifier") #7
mlflow.log_params(tree.get_params()) #8
#1 把训练与测试数据框保存到 MinIO
#2 将 pandas data frame 转为 MLflow data frame
#3 把 MLflow data frame 记录到 MLflow
#4 训练模型
#5 生成模型性能指标
#6 在 MLflow 中记录性能指标
#7 在 MLflow 中记录模型
#8 在 MLflow 中记录模型参数我们会先把训练、测试与参考(reference)数据集保存到 MinIO,并在 MLflow 里记录这些路径。参考数据集是特征数据集,包含所有用户的全部特征------既包括训练也包括测试。我们需要用 mlflow.data.from_pandas 把 pandas data frame 转成 MLflow data frame。该方法需要两个参数:pandas data frame 以及该数据框的外部路径。它会生成一个 MLflow data frame,然后可以通过 mlflow.log_input 记录。MLflow 会记录该数据框的元数据,包括列信息(名称与类型)以及行数。随后我们拟合模型,并获取准确率与 AUC 等指标。我们用 mlflow.log_metric 记录指标,指定指标名与数值。我们还用 sklearn.log_model 与 log_params 分别记录模型与参数。MLflow 支持多种建模库,例如 scikit-learn、XGBoost、TensorFlow 与 PyTorch,并提供便捷的模型保存与加载能力。
这会生成一个 MLflow run,并把数据集存到 MinIO。点击最新生成的 run,我们就能在各个标签页下看到刚才记录的信息(图 4.5)。
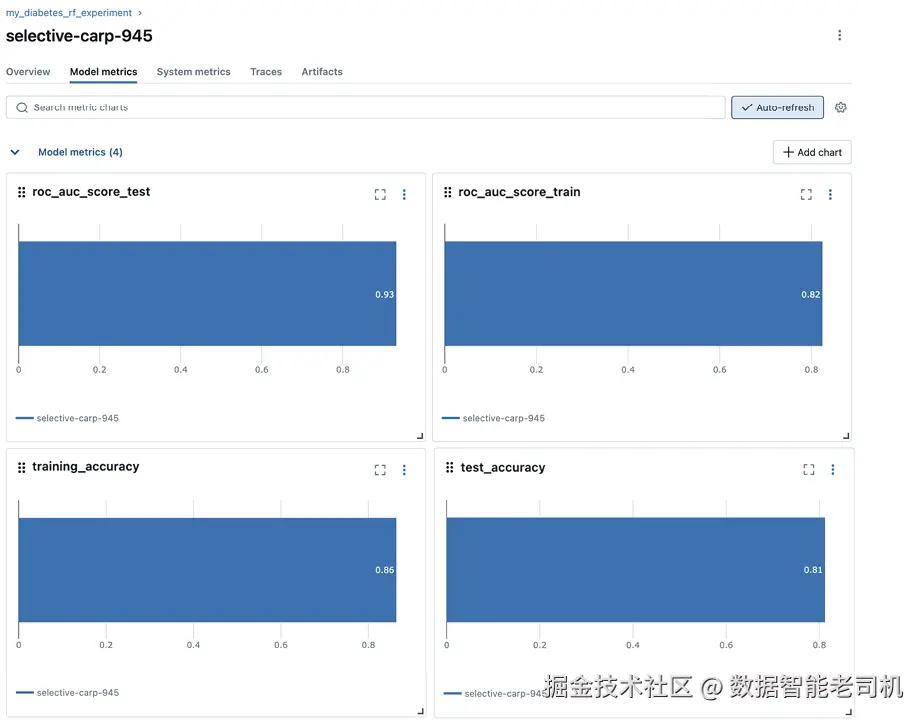
图 4.5 模型指标与 artifacts 分别显示在对应标签页下
我们以同样方式构建随机森林模型,并记录数据集、指标、模型与参数。MLflow 还有一个很有用的功能:autolog 。autolog 会在训练与评估过程中自动记录多种 ML 指标与 artifacts,从而简化实验追踪与模型性能跟踪------不需要手写大量显式记录代码。对 XGBoost 模型,我们将用 autolog 追踪参数,如清单 4.6 所示。只要加一行 mlflow.xgboost.autolog() 就能启用 autolog。不过 autolog 不会记录我们自定义的指标,这些仍需显式记录。此外,autolog 会把训练数据集以数组形式记录,而不是 data frame;但我们仍可以在 autolog 的基础上使用其他 log 方法,以我们希望的格式记录关注的参数。
清单 4.6 使用 MLflow 自动日志(autologging)
scss
with mlflow.start_run():
mlflow.xgboost.autolog() #1
n_round = 30
dtrain = xgb.DMatrix(data=X_train, label=y_train.ravel())
dtest = xgb.DMatrix(data=X_test, label=y_test.ravel())
params = {
"objective": "binary:logistic",
"colsample_bytree": 1,
"learning_rate": 1,
"max_depth": 10,
"subsample": 1,
}
model = xgb.train(params, dtrain, n_round)
ax = xgb.plot_importance(
model,
max_num_features=10,
importance_type="cover"
)
fig = ax.figure
fig.set_size_inches(10, 8)
pred_train = model.predict(dtrain)
pred_test = model.predict(dtest)
hinge_params = {
"objective": "binary:hinge",
"colsample_bytree": 1,
"learning_rate": 1,
"max_depth": 10,
"subsample": 1,
}
model = xgb.train(hinge_params, dtrain)
pred_train = model.predict(dtrain)
pred_test = model.predict(dtest)
roc_auc_score_train = roc_auc_score(y_train == 1, pred_train)
roc_auc_score_test = roc_auc_score(y_test == 1, pred_test)
training_accuracy = accuracy_score(y_train, pred_train)
test_accuracy = accuracy_score(y_test, pred_test)
mlflow.log_metric( #2
"roc_auc_score_train",
roc_auc_score_train
)
mlflow.log_metric("roc_auc_score_test", roc_auc_score_test)
mlflow.log_metric("training_accuracy", training_accuracy)
mlflow.log_metric("test_accuracy", test_accuracy)
print(f"ROC AUC Score (train): {roc_auc_score_train}\n")
print(f"ROC AUC Score (test): {roc_auc_score_test}\n")
print(f"Accuracy (train): {training_accuracy}")
print(f"Accuracy (test): {test_accuracy}")
#1 启用 MLflow 自动日志
#2 记录自定义模型性能指标autologging 的结果可以在 run 中看到:它会在无需显式 logging 的情况下记录模型、图表与模型参数(图 4.6)。
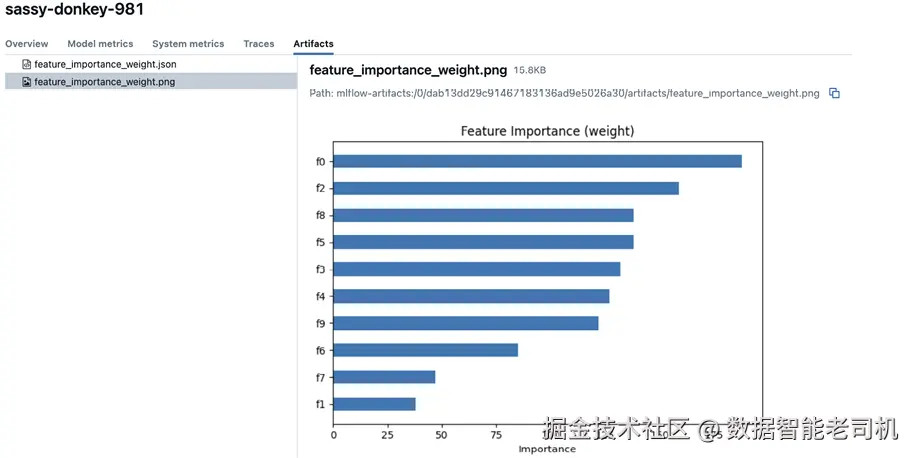
图 4.6 autologging 会在无需显式 logging 的情况下记录模型参数与数据集;我们还会自动获得特征重要性图。
4.1.3 MLflow 模型注册表(MLflow model registry)
我们已经构建了三个模型:决策树、随机森林,以及 XGBoost。那我们如何从这三个里选出最好的模型并把它保存下来?既然我们已经记录了所有关心的模型指标,就可以直接查询 MLflow 来得到最佳模型。确定最佳模型后,我们可以把它保存到 MLflow 的模型注册表中。MLflow 的 model registry 组件充当一个仓库,用于在模型生命周期内管理 ML 模型。它帮助我们高效协作、跟踪模型版本,并确保模型治理与可复现性。
我们可以用两种方式找到最佳模型并注册:通过 MLflow UI,或通过 MLflow client。
使用 MLflow UI
我们可以在 MLflow UI 的搜索栏里直接写查询条件。查询 metrics.roc_auc_score_test > 0.8 会返回所有测试集 AUC 大于 0.8 的模型。我们也可以点击图表视图图标,查看每个 run 的该指标图表(见图 4.7)。然后我们就能很容易选出 AUC 最高的模型------在我们的例子里是随机森林模型。
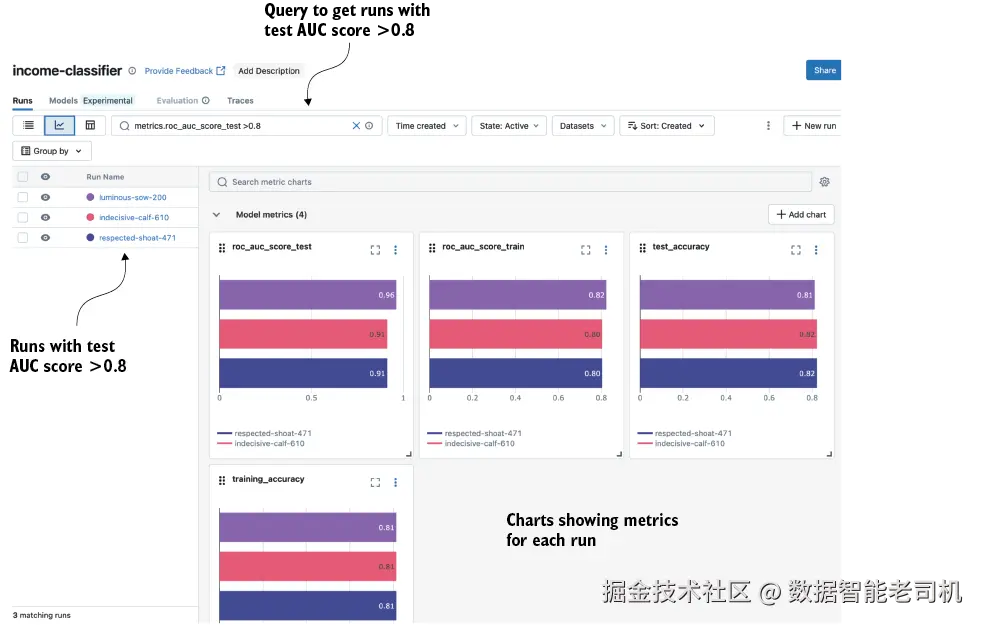
图 4.7 使用 MLflow UI 查询测试集 AUC 分数 > 0.8 的 runs,结果以图表视图展示。
MLflow Client
我们也可以用 MLflow client 以编程方式完成同样的事情。MLflow client 提供一个程序化接口,用于管理与查询 ML 实验、跟踪指标,以及访问 MLflow 的各种功能。我们会用 client 搜索最佳模型,并将其注册到 MLflow model registry,如清单 4.7 所示。我们用 MlflowClient 对象通过 get_experiment_by_name 获取 experiment ID。然后用 search_runs 按此前相同的 filter string 过滤 runs,并按 roc_auc_score_test 排序。接着我们用 run ID 与 experiment name 生成 model URI。基于该 model URI,我们用 register_model 把模型注册到 model registry,并指定模型的 URI 与名称。
清单 4.7 获取 MLflow runs 并注册模型
ini
from mlflow import MlflowClient
mlflow_client = MlflowClient()
experiment_name = "income-classifier"
experiment = mlflow_client.get_experiment_by_name(experiment_name)
run_object = mlflow_client.search_runs(
experiment_ids=experiment.experiment_id,
filter_string="metrics.roc_auc_score_test > 0.8",
max_results=1,
order_by=["metrics.roc_auc_score_test DESC"]
)[0] #1
model_uri = f"runs:/{run_object.info.run_id}/{experiment_name}" #2
mlflow.register_model(
model_uri,
"random-forest-classifier"
) #3
#1 获取测试集 AUC 最高的 run 的 run object
#2 为该 run 的 run ID 生成 model URI
#3 在 MLflow model registry 中注册模型现在模型已经以 random-forest-classifier 这个名称注册完成,我们就可以在推理时取回它,或在需要复现实验时使用它。我们可以在 UI 顶部导航栏点击 Models 标签页来查看该模型(见图 4.8)。类似于我们在测试后把代码从 staging 平台提升到 production 平台,模型也可以被提升到 staging 与 production 等不同阶段。
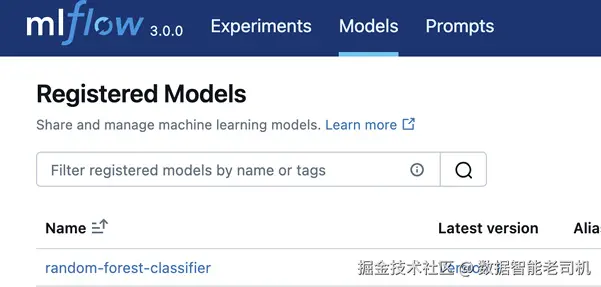
图 4.8 MLflow 注册的模型会在 UI 的 Models 标签页下列出。这里展示了我们的随机森林模型。
MLflow 现在还包含一个 Prompts 标签页,用于管理大语言模型(LLM)应用中使用的 prompts(见图 4.8)。不过在写作本书时,这个功能在能力上仍较为有限。因此在第 12、13 章,我们会探索一个替代工具 Langfuse,它在 prompt 跟踪、评估与版本管理方面提供更强的能力。
定义 Prompt 管理是指在开发过程中,对 prompt 如何被创建、测试、迭代与记录进行系统化处理。正如前面章节提到的,工具只是手段;关键是选择最契合你项目需求的工具。
在前面的示例中,我们部署的是本地 MLflow 实例,但本地实例无法支持协作。为此,我们需要把 MLflow 安装在一个团队成员都可访问的环境中,例如云环境或 Kubernetes 集群环境。我们在附录 A 中提供了如何在 Kubernetes 集群上安装 MLflow 的说明。MLflow tracking 与 model registry 是 MLflow 最常用的组件。更多信息请参考文档:https://mlflow.org/docs/latest/index.xhtml。
到这里,我们已经构建了第一版模型,并把它注册进 model registry。接下来,在把模型生产化之前,我们还需要注册模型的特征。在下一节中,我们会使用特征库来注册特征,以确保在推理或再训练时使用的是正确的特征。
当模型已在 MLflow 中被跟踪并注册之后,我们会遇到另一个关键挑战:如何确保训练与推理阶段的特征工程一致?这正是 Feast 这类 feature store 变得必不可少的原因。它们帮助我们保持可复现性,同时让特征可以在不同模型与团队之间复用。
4.2 Feast 作为特征库(Feast as a feature store)
我们的收入分类器特征很幸运地都在一个文件里。然而在真实场景中,特征会来自多张表或多个文件,我们需要写复杂的特征处理与 join 逻辑,最终才能得到一个数据集。我们用当前数据集来模拟这种情况:把单个文件拆成三个独立文件(见图 4.9);每个文件都包含时间戳、用户 ID 列,以及三类特征之一的数据:

图 4.9 我们把单个文件拆成三个文件,分别代表三类特征:人口统计、关系、职业。
- 人口统计特征(Demographic features) ------Sex、Race、Native_country
- 关系特征(Relationship features) ------Marital status、Relationship
- 职业特征(Occupation features) ------Workclass、Education、Occupation
定义好特征文件之后,我们需要一种方式,在推理或再训练时取到"正确的特征"。什么叫正确的特征?例如,我们想取某个用户(user_id)在 5 月 22 日的特征。我们为该用户在多个时间戳记录过特征:1 月 7 日、5 月 21 日、12 月 4 日。那么在 5 月 22 日这个场景下,正确的特征应该是距离 5 月 22 日最近的一份------也就是 5 月 21 日记录的特征。我们需要在特征取数时把这套逻辑纳入其中。我们可以写脚本或 SQL 查询(又多一个需要维护与调试的东西),也可以依赖 Feast 特征库提供的数据抽象层。Feast 的核心能力之一,就是生成时间点正确(point-in-time correct) 的特征集合,让数据科学家把精力放在特征工程上,而不是 join 逻辑上。
这些特征文件可以被移动到一个公共位置,例如 MinIO bucket。训练与推理时,我们都从这个公共位置取特征。一个公共流程把特征集合写入 MinIO;这样做让特征生成逻辑与建模逻辑解耦。公共位置的另一个优势是:特征可以在团队与组织内部复用与共享。Feast 通过提供一个 feature registry(特征注册表),让我们能注册特征,并在需要时查询它们,从而把特征开放给团队其他成员使用。
如果我们在构建一个实时服务,特征检索时延通常要求很低。Feast 允许我们把特征从 MinIO(离线存储,offline store)推送到低时延数据库(在线存储,online store),例如 Redis,从而在实时推理时实现快速取特征。Redis 是常见选择,但 Feast 也支持其他在线数据库(如 DynamoDB、Google Cloud Datastore),具体取决于系统需求。
基于这些考虑,我们来看特征库的设计(图 4.10)。我们会有一个特征计算流程或流水线,把特征集写入离线存储(数据仓库或对象存储)。为了做实时预测,Feast 会周期性地把离线特征推到在线存储中,使其可用于在线预测。Feast 把这一过程称为 materialization(物化) 。核心位置上,feature registry 保存特征定义,包括它们的位置与名称。我们还会使用 Feast Python SDK 接口,方便从离线或在线存储取特征。该 SDK 提供从两类存储读取数据的方法,也提供把离线数据推送/物化到在线存储的方法。离线特征用于模型训练,在线特征用于模型推理。
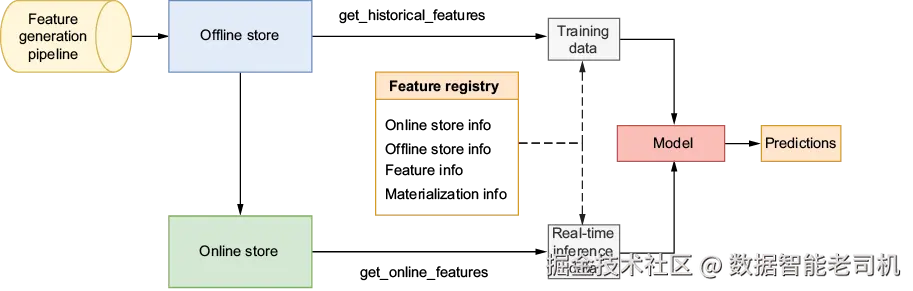
图 4.10 Feast 特征库设计:特征流水线填充离线存储;Feast 周期性把离线特征物化到在线存储。特征注册表保存特征定义以及在线/离线存储信息。Feast SDK 提供从在线与离线存储取特征的方法,用于训练与推理。
我们先为 Feast 搭建 Redis 在线存储,并把数据集放到 MinIO 中。相关说明在附录 A 的 A.2.1 节。
4.2.1 注册特征(Registering features)
现在我们要把特征注册到 Feast。首先需要注册 entity。entity 指的是收集特征所对应的标识符。在我们的例子里,我们为用户收集特征,而用户有唯一的 user ID,因此 user_id 就是 entity。如果我们记录的是商品的特征,那么 product_id 就会是 entity。在 entity.py 中,我们定义 user_id entity,包括名称、描述与 entity 数据类型(这里是字符串),如下面清单所示。
清单 4.8 创建一个 entity
python
from feast import Entity, ValueType
from feast.types import String
user = Entity(name="user_id", description="A user") #1
#1 通过提供名称、描述与数据类型来创建一个 Feast entity接下来,我们需要把 MinIO service port-forward 到本地,这样 Feast 才能在 registry 中注册特征源的位置。执行:
bash
kubectl port-forward svc/minio-service 9000:9000 -n kubeflow接着,我们在文件里定义每个特征类别以及它们在 MinIO 中的位置。例如,对人口统计特征,我们用 s3 路径指定文件在 MinIO 中的位置,如清单 4.9 所示。同时我们还需要提供 s3_endpoint_override,指向我们 port-forward 后的 MinIO 服务端点。
清单 4.9 定义人口统计特征文件的位置
ini
demo_features_parquet_file_source = FileSource(
file_format=ParquetFormat(), #1
path =
"s3://feature_data_sets/demographic_features.parquet" #2
s3_endpoint_override = "http://localhost:9000" #3
)
#1 指定文件格式。Feast 目前只支持 Parquet。
#2 指定文件路径
#3 提供 s3 endpoint override,指向我们的 MinIO 端点然后我们使用 Feast 的 FeatureView 定义特征,如清单 4.10 所示。FeatureView 用于表示一组逻辑上相关的特征。我们指定 FeatureView 名称与 entity(这里是 user),然后列出特征并设置 ttl(time to live)。TTL 限制 Feast 在生成历史数据集时回看(look back)的时间范围。TTL 使用 datetime.timedelta 来定义。例如,假设我们要为 5 月 22 日生成历史数据集,TTL 是 2 天,那么 Feast 只会回看至 5 月 20 日,因为更早的特征不会被纳入生成数据集。这个限制是为了确保训练与推理使用最新鲜的特征。我们把 ttl 设为 365 天(1 年),因为我们希望确保能拿到所有必要特征,而不被过小的 TTL 限制。接着我们指定数据来源(前面定义的 file source),并可选地添加一些 tags,以提升可读性并提供额外信息。
清单 4.10 定义 FeatureView
ini
demo_features = FeatureView(
name="demographic",
entities=[user], #1
schema=[
Field(name="Native_country", dtype=String),
Field(name="Sex", dtype=String),
Field(name="Race", dtype=String), #2
],
ttl=timedelta(days=365), #3
source=demo_features_parquet_file_source, #4
tags={
"authors": "Benjamin Tan <benjamin.tan@abc.random.com,"
"Varun Mallya <varun.mallya@abc.random.com"
"description": "User Demographics",
"used_by": "Income_Calculation_Team", #5
},
)
#1 指定特征关联的 entity
#2 列出 Parquet 文件中的特征名/列名
#3 指定 TTL(回看窗口)
#4 指定特征数据来源
#5 提升可读性的 tags我们对其他特征组(relationship 与 occupation)也做同样处理。随后定义 feature_store.yaml 配置,如清单 4.11 所示。该配置文件列出 feature registry 项目的名称、registry 的位置,以及 online/offline store 的配置。registry 可以理解为保存所有特征与 entity 定义的公共位置;在我们的例子里,它是一个叫 registry_local.db 的文件,存放在 MinIO 的 feature-registry bucket 中。我们的 offline store 类型是 Filestore,因为数据存放在 MinIO 的文件里。online store 是一个 Redis 实例,我们需要提供包含 Redis IP 的连接串。
清单 4.11 Feature store 配置
yaml
project: my_feature_repo
registry: s3://feature-registry/registry_local.db #1
provider: local #2
offline_store:
type: file #3
online_store:
type: redis #4
connection_string: "localhost:6379"
#1 feature registry 路径
#2 指定环境名:云厂商或本地
#3 offline store 配置
#4 online store 配置我们的 feature repository 目录结构现在如下:
├── entity.py
├── feature_store.yaml
├── features.py现在我们已经配置了 Feast 并定义了特征与 entities,但还没有把任何定义推到 feature registry。为此,我们需要先把 MinIO 与 Redis 的 service port-forward 到本地环境------因为我们要注册特征及其 sources(离线与在线)。执行:
bash
kubectl port-forward svc/minio-service 9000:9000 -n kubeflow
kubectl port-forward svc/redis-deployment-master 6379:6379 -n redis接着运行 feast apply。该命令会用特征与 entity 定义更新 feature registry。命令输出会显示创建的 entities 与 feature views 信息。"Deploying infrastructure" 表示 Redis 已被设置为在线特征库。命令输出如下:
feast apply
rust
Created entity user_id
Created feature view relationship
Created feature view occupation
Created feature view demographic
Deploying infrastructure for relationship
Deploying infrastructure for occupation
Deploying infrastructure for demographic4.2.2 获取特征(Retrieving features)
当特征定义完成后,我们可以通过 Feast SDK 的 get_historical_features 方法来获取特征,该方法需要两个参数。第一个参数是一个 pandas data frame,包含 entity 数据(用户 ID)与时间戳。注意列名必须与 entity 名一致(user_id),而时间戳列名必须是 event_timestamp。在我们的例子里,假设用户是 9f2ac416-06e1-44a0-87bd-d4787c85bf66,时间戳是 2023 年 5 月 22 日。第二个参数是我们要为该用户取回的特征列表。如果要从 demographic feature view 取 Sex 特征,特征列表如下:
ini
feature_list = ["demographic:Sex"]我们还需要指定 feature_store.yaml 路径并初始化 feature store 对象。完成后即可获取历史特征,如清单 4.12 所示。
清单 4.12 获取历史特征
python
from datetime import datetime
import pandas as pd
from feast import FeatureStore
entity_df = pd.DataFrame.from_dict(
{
"user_id": ["9f2ac416-06e1-44a0-87bd-d4787c85bf66"],
"event_timestamp": [
datetime(2023, 1, 30, 10, 59, 42),
],
}
) #1
store = FeatureStore(repo_path=".") #2
training_df = store.get_historical_features(
entity_df=entity_df,
features=[
"demographic:Sex",
],
).to_df() #3
print("----- Feature schema -----\n")
print(training_df.info()) #4
print("----- Example features -----\n")
print(training_df.head()) #5
#1 定义 entity 的 pandas data frame
#2 初始化 feature store
#3 通过 entity_df 与 feature 列表获取历史特征
#4 打印 training_df 的 schema
#5 打印 training_df 的前几行上述脚本输出会给出 training_df 的 schema 信息。training_df 包含一个用户(user_id 为 9f2ac416-06e1-44a0-87bd-d4787c85bf66)的 demographic:Sex 特征:
sql
----- Feature schema -----
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1 entries, 0 to 0
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 1 non-null object
1 event_timestamp 1 non-null datetime64[ns, UTC]
2 Sex 1 non-null object
dtypes: datetime64, object(2)
memory usage: 152.0+ bytes
None
----- Example features -----
user_id event_timestamp Sex
0 9f2ac416-06e1-44a0-87bd-d4787c85bf66 2023-01-30 10:59:42+00:00 Male接下来我们尝试从 online store 取特征。但在此之前,需要先把离线数据推到在线存储。Feast 提供一个简单命令 feast materialize 来完成:需要传入开始时间(START_TS)与结束时间(END_TS)。Feast 会读取 offline store 中 START_TS 与 END_TS 之间的所有数据,并写入 online store:
ini
START_TIME="2022-09-16T00:00:00"
END_TIME="2023-09-17T00:00:00"
feast materialize $START_TIME $END_TIME输出类似:
csharp
relationship from 2022-09-16 00:00:00+08:00 to
2023-09-18 00:00:00+08:00:
100%|████████████████████████████████████████████| 28066/28066
[00:01<00:00, 20350.45it/s]
occupation from 2022-09-16 00:00:00+08:00 to
2023-09-18 00:00:00+08:00:
100%|████████████████████████████████████████████| 28066/28066
[00:01<00:00, 19162.95it/s]
demographic from 2022-09-16 00:00:00+08:00 to
2023-09-18 00:00:00+08:00:
100%|████████████████████████████████████████████| 28066/28066
[00:01<00:00, 20267.80it/s]数据推送完成后,我们可以使用 get_online_features,如清单 4.13 所示。它与 get_historical_features 类似,但只会取某个 user_id 的最新特征。
清单 4.13 获取在线特征
ini
from feast import FeatureStore
store = FeatureStore(repo_path=".")
online_features = store.get_online_features(
features=[
"demographic:Sex", #1
],
entity_rows = [
{"user_id": "9f2ac416-06e1-44a0-87bd-d4787c85bf66"}
] #2
)
print(online_features.to_df())
#1 指定特征名
#2 指定 user_id现在我们已经能够从 offline store 与 online store 两边取特征:训练或批量推理时用 get_historical_features;实时推理时用 get_online_features。
4.2.3 特征服务(Feature server)
Feast 还提供了一个 feature server,它提供了一组 API 端点,用于与 feature store 交互。当我们的应用使用的编程语言没有 Feast SDK 时,这尤其有用。要在本地环境启动 feature server,可以运行 feast serve:
feast serve这会启动一个本地服务,用于为给定用户检索特征:
less
[2023-10-11 19:08:16 +0800] [12270] [INFO] Starting gunicorn 21.2.0
[2023-10-11 19:08:16 +0800] [12270] [INFO] Listening at:
http://127.0.0.1:6566 (12270)
[2023-10-11 19:08:16 +0800] [12270] [INFO] Using worker:
uvicorn.workers.UvicornWorker
[2023-10-11 19:08:16 +0800] [12278] [INFO] Booting worker with pid: 12278
[2023-10-11 19:08:18 +0800] [12278] [INFO] Started server process [12278]
[2023-10-11 19:08:18 +0800] [12278] [INFO] Waiting for application startup.
[2023-10-11 19:08:18 +0800] [12278] [INFO] Application startup complete.
[2023-10-11 19:08:32 +0800] [12270] [INFO] Handling signal: winch随后我们可以用 curl 拉取在线特征:指定要取的特征列表,以及要为哪个 user_id 取值。这些特征将从在线特征库中读取:
vbnet
curl -X POST \
"http://localhost:6566/get-online-features" \
-d '{
"features": [
"demographic:Sex"
],
"entities": {
"user_id": ["9f2ac416-06e1-44a0-87bd-d4787c85bf66"]
}
}'会返回如下响应,其中包含特征与 entity 的名称及其对应值:
json
{
"metadata": {
"feature_names": [
"user_id",
"Sex"
]
},
"results": [
{
"values": [
"9f2ac416-06e1-44a0-87bd-d4787c85bf66"
],
"statuses": [
"PRESENT"
],
"event_timestamps": [
"1970-01-01T00:00:00Z"
]
},
{
"values": [
" Male"
],
"statuses": [
"PRESENT"
],
"event_timestamps": [
"2023-01-24T06:52:20Z"
]
}
]
}4.2.4 使用 Feast UI
最后,Feast 也提供了一个简单 UI,用来列出我们在 feature registry 中定义的全部 features 与 entities。运行下面命令即可启动 UI:
feast ui然后在浏览器访问 http://localhost:8888 就能打开 Feast UI(见图 4.11)。该 UI 会展示 registry 中注册的 features 与 entities 信息,也会显示特征的数据源。我们甚至可以通过 tags(例如 description 与 authors)来过滤 feature view。
图 4.11 Feast UI 提供一种直观方式,展示所有项目中 feature views 与 entities 的细节。
特征库通过提供结构化、中心化的特征管理方式,可以显著提升 ML 项目的效率、可靠性与可维护性。Feast 是目前领先的开源特征库之一。你可以在 Feast 文档(https://docs.feast.dev/)中看到示例,了解它与不同在线/离线存储的集成方式。
当我们用 MLflow 跟踪了模型实验,并用 Feast 注册了特征之后,我们就建立了可靠 ML 系统的两个关键组件:MLflow 的实验追踪器与模型注册表确保我们可以复现训练结果并对模型做版本控制;而 Feast 帮助我们在训练与推理之间一致地管理与服务特征。不过,这些组件在一些任务上仍需要人工介入,例如用新数据再训练模型、或更新特征。
在下一章中,我们会通过 Kubeflow 构建 ML pipelines,把这些过程自动化。我们将看到如何编排 MLflow 与 Feast 的交互、自动化模型再训练,并创建可规模化运行的可复现工作流。这种自动化对在生产环境维持可靠 ML 系统至关重要------当数据量增长、再训练更频繁时,人工流程会变得不现实。
总结
- 像 MLflow 这样的实验追踪器,可用于在模型训练与评估期间跟踪模型性能与超参数。
- MLflow 模型注册表是一个用于管理、组织与版本化 ML 模型的平台,便于协作与部署。
- Feast 的特征库简化了 ML 可用特征(经整理、可直接使用)的管理与共享,增强模型开发与部署效率。
- Feast 支持时间点正确(point-in-time)的 join,以确保推理时特征的新鲜度。
- Feast 同时支持基于 offline store 的历史特征检索,以及基于 online store 的低时延特征检索。