
🎬 博主名称 :键盘敲碎了雾霭
🔥 个人专栏 : 《C语言》《数据结构》
⛺️指尖敲代码,雾霭皆可破

文章目录
前言
排序是计算机科学中最基础的问题之一,在实际开发中无处不在。然而,面对不同的数据规模和场景,我们需要选择或设计合适的排序算法。本文将围绕两个经典主题展开:
- 快速排序的优化:介绍三路划分快速排序(处理大量重复元素)和自省排序(防止递归过深)两种改进版本。
- 外部文件归并排序:当数据量超过内存容量时,如何利用磁盘文件进行排序。
文章将结合具体C语言代码,分析算法思想、实现细节,并指出潜在的问题和改进方向。
一、快速排序及其优化
快速排序(Quick Sort)因其平均时间复杂度 O(n log n) 和原地排序特性,成为最常用的排序算法之一。但传统快速排序在处理重复元素或极端数据时可能退化,因此需要优化。
1.1 三路划分快速排序
背景
当数组中存在大量重复元素时,传统快速排序会将所有等于基准值的元素分散到左右两侧,导致递归深度增加,效率下降。三路划分将数组划分为 小于基准、等于基准、大于基准 三个区域,从而避免对重复元素的重复处理。
算法思想

- 选定基准值
key(通常取区间第一个元素)。 - 使用三个指针:
left:指向小于区域的右边界(初始为区间左端)。cur:当前遍历指针(初始为left + 1)。right:指向大于区域的左边界(初始为区间右端)。
- 遍历过程中:
- 若
arr[cur] < key:将其与left处元素交换,left和cur右移。 - 若
arr[cur] > key:将其与right处元素交换,right左移(cur不动,因为交换过来的元素未处理)。 - 若
arr[cur] == key:cur右移。
- 若
- 最终区间被分为
[again, left-1](小于)、[left, right](等于)、[right+1, end](大于),然后递归处理左右两段。
代码实现
c
void QuickSort3(int* arr, int left, int right)
{
if (left >= right)
return;
int again = left; // 保存原始左边界
int end = right; // 保存原始右边界
int cur = left + 1;
int key = arr[left]; // 基准值
while (cur <= right)
{
if (arr[cur] < key)
{
Swap(&arr[left], &arr[cur]);
left++;
cur++;
}
else if (arr[cur] > key)
{
Swap(&arr[cur], &arr[right]);
right--;
}
else // arr[cur] == key
{
cur++;
}
}
// 递归处理小于和大于区域
QuickSort3(arr, again, left - 1);
QuickSort3(arr, right + 1, end);
}注意事项
- 代码中
else if(arr[cur] > arr[key])存在错误:arr[key]中的key是下标,但key已经作为变量保存了基准值,此处应改为arr[cur] > key。否则当left移动后,arr[key]可能不再是原基准值。 - 三路划分在处理大量重复数据时效率极高,可将相等元素直接跳过。
1.2 自省排序
背景
快速排序在最坏情况(如已有序数组)下递归深度达到 O(n),可能导致栈溢出。自省排序(Introspective Sort)通过监控递归深度,当深度超过阈值(如 2*log2(n))时,转而使用堆排序,保证最坏时间复杂度为 O(n log n)。
算法思想
- 在递归函数中增加深度参数
depth和最大深度阈值defaultDepth。 - 若
depth > defaultDepth,则对当前区间调用堆排序,并返回。 - 否则继续执行快速排序分区,并递归处理左右子区间,递归时深度加 1。
代码实现
c
void QuickSort(int* arr, int left, int right, int depth, int defaultDepth)
{
if (left >= right)
return;
if (depth > defaultDepth)
{
HeapSort(arr + left, (right - left + 1));
return;
}
depth++;
int again = left;
int end = right;
int keyi = left; // 基准下标
while (again < end)
{
while (again < end && arr[end] >= arr[keyi])
end--;
while (again < end && arr[again] <= arr[keyi])
again++;
Swap(&arr[again], &arr[end]);
}
Swap(&arr[again], &arr[keyi]);
QuickSort(arr, left, again - 1, depth, defaultDepth);
QuickSort(arr, again + 1, right, depth, defaultDepth);
}说明
- 分区部分使用了经典的 Hoare 法,以
arr[keyi]为基准。 - 递归时传递
depth的当前值(已加 1),确保深度计数正确。 - 注意:
HeapSort函数需自行实现,此处仅为示意。实际使用时可以引入标准库的堆排序或自行编写。
二、文件归并排序(外部排序)

当数据量超过内存容量时,无法一次性加载所有数据到内存进行排序。此时需要借助磁盘文件,采用"分而治之"的思想:将大文件分割成若干可装入内存的小块,分别排序后,再通过多路归并得到最终有序文件。
2.1 基本思路
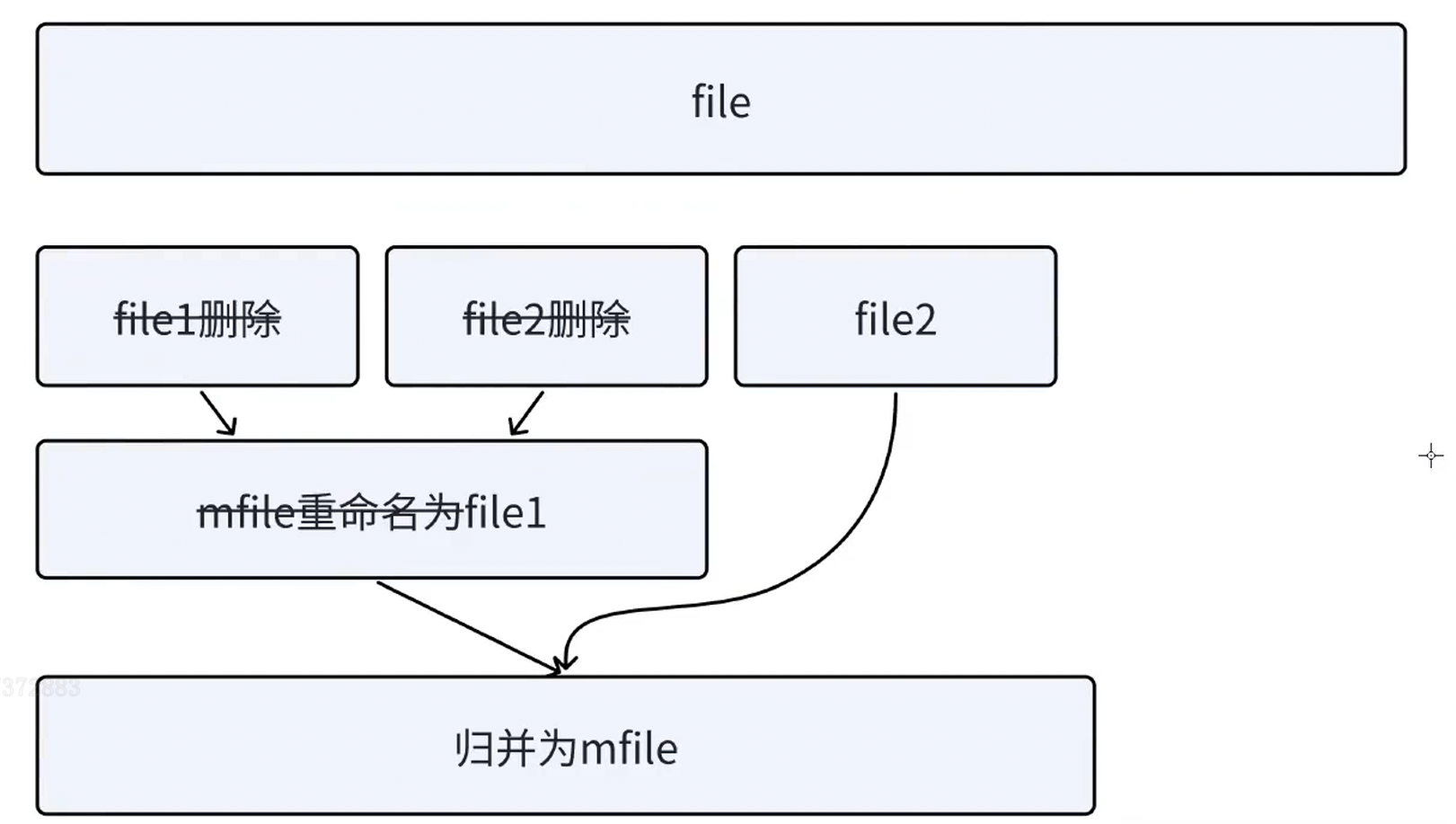
- 生成原始数据文件:创建一个包含大量整数的文件。
- 分割与排序 :每次从大文件中读取一定数量的数据(如 100 万个整数),在内存中用快速排序(或
qsort)排序,然后写入一个临时文件。 - 归并:将多个有序临时文件两两合并(或使用多路归并),直至最终得到一个完整的有序文件。
2.2 代码实现分析
生成数据文件
c
void GreatNum()
{
FILE* pf = fopen("data.txt", "w");
if (pf == NULL)
{
perror("fopen");
return;
}
for (int i = 0; i < 100000000; i++)
{
fprintf(pf, "%d\n", rand() + i);
}
fclose(pf);
}- 生成 1 亿个整数,每个数由
rand() + i产生,避免重复(但仍有随机性)。 - 注意:文件大小约为 1 亿 ×(数字长度 + 换行符)≈ 1 GB 左右,生成耗时较长,建议测试时可减小数量。
读取并排序一块数据
c
int ReadTofile(FILE* data, int n, const char* file)
{
int* arr = (int*)malloc(sizeof(int) * n);
if (arr == NULL) return 0;
int j = 0, tmp;
for (int i = 0; i < n; i++)
{
if (fscanf(data, "%d", &tmp) == EOF)
break;
arr[j++] = tmp;
}
if (j == 0) return 0;
qsort(arr, j, sizeof(int), compare); // 使用标准库快速排序
FILE* pfile = fopen(file, "w");
if (pfile == NULL)
{
perror("fopen");
free(arr);
return 0;
}
for (int i = 0; i < j; i++)
fprintf(pfile, "%d\n", arr[i]);
fclose(pfile);
free(arr);
return j; // 返回实际读取的元素个数
}- 从大文件
data中读取最多n个整数到内存数组,排序后写入临时文件。 - 返回实际读取个数,用于判断文件是否结束。
合并两个有序文件
c
void MergeFile(const char* file1, const char* file2, const char* mfile)
{
FILE* pfile1 = fopen(file1, "r");
FILE* pfile2 = fopen(file2, "r");
FILE* pmfile = fopen(mfile, "w");
if (!pfile1 || !pfile2 || !pmfile)
{
perror("fopen");
return;
}
int x, y;
int ret1 = fscanf(pfile1, "%d", &x);
int ret2 = fscanf(pfile2, "%d", &y);
while (ret1 != EOF && ret2 != EOF)
{
if (x < y)
{
fprintf(pmfile, "%d\n", x);
ret1 = fscanf(pfile1, "%d", &x);
}
else
{
fprintf(pmfile, "%d\n", y);
ret2 = fscanf(pfile2, "%d", &y);
}
}
while (ret1 != EOF)
{
fprintf(pmfile, "%d\n", x);
ret1 = fscanf(pfile1, "%d", &x);
}
while (ret2 != EOF)
{
fprintf(pmfile, "%d\n", y);
ret2 = fscanf(pfile2, "%d", &y);
}
fclose(pfile1);
fclose(pfile2);
fclose(pmfile);
}- 标准的两路归并算法,每次从两个文件取较小者写入结果文件。
主控逻辑
c
int main()
{
srand((unsigned int)time(NULL));
const char* file1 = "file1.txt";
const char* file2 = "file2.txt";
const char* mfile = "mfile.txt";
// 生成原始数据
GreatNum();
FILE* data = fopen("data.txt", "r");
if (data == NULL)
{
perror("fopen");
return 1;
}
int n = 1000000; // 每块大小
ReadTofile(data, n, file1);
ReadTofile(data, n, file2);
while (1)
{
MergeFile(file1, file2, mfile);
remove(file1);
remove(file2);
rename(mfile, file1);
int tmp = ReadTofile(data, n, file2);
if (tmp == 0)
break;
}
fclose(data);
return 0;
}- 先读取两块数据分别排序为
file1和file2。 - 然后循环:合并
file1和file2得到mfile,删除原文件,将mfile重命名为file1(作为当前已归并的有序文件)。 - 接着从
data读取下一块数据排序为file2,若读取不到(文件结束)则退出循环。 - 最终
file1即为所有数据的有序文件。
2.3 算法评价与改进
- 优点:实现简单,能处理超大数据集。
- 缺点 :
- 归并方式为"累积式"归并:每次只合并两个文件,且新块不断与已归并的大文件合并,导致总归并次数约为 O(k²)(k 为块数)。当数据量极大时,效率较低。
- 每轮归并都需要读写大量磁盘 I/O,开销大。
- 改进方向 :
- 采用多路归并:一次性合并多个有序文件,减少归并轮次。
- 使用败者树优化多路归并中的比较过程。
- 增加缓冲区,减少磁盘读写次数。
总结
本文介绍了两种排序算法的优化和一种外部排序的实现:
- 三路划分快速排序 通过将相等元素集中,避免了重复比较,适合大量重复数据的场景。
- 自省排序 结合快速排序和堆排序,防止递归过深,保证了最坏情况下的性能。
- 文件归并排序 展示了外部排序的基本思想,虽然示例中的归并策略效率不高,但足以说明分块排序再归并的核心流程。
在实际开发中,应根据数据规模、内存限制和重复元素比例等因素选择合适的排序策略。例如,C++ STL 中的 std::sort 通常就是自省排序的实现,而数据库或大数据处理则离不开外部排序的优化版本。
希望本文能帮助你加深对排序算法的理解,并在实际项目中灵活运用。欢迎留言讨论!