在 GTC 2026 上,NVIDIA 对 Blackwell 架构产品线做了一次更清晰的补齐。相比 B200 这类面向超大规模训练的数据中心 GPU,本次推出的 RTX PRO 4500 Blackwell Server Edition,更像是一款直接面向企业侧部署环境设计的产品。从规格上看,它并不追求绝对性能上限,而是在算力、功耗、形态与部署适配之间做了一个更工程化的平衡,这种取向在当前企业 AI 基础设施落地阶段反而更具现实意义。

从核心配置来看,RTX PRO 4500 Blackwell Server Edition 采用与标准 RTX PRO 4500 工作站卡相同的 GPU 核心规格,两者均配备 10496 个 CUDA Core 和 32GB GDDR7 显存,这意味着在计算能力层面,两者的基础是一致的,均基于 Blackwell 架构的新一代 Tensor Core,能够在 FP4 / FP8 等低精度路径下提供更高的推理吞吐能力。但真正拉开差异的,不是核心数量,而是围绕"部署场景"所做的一系列工程调整。
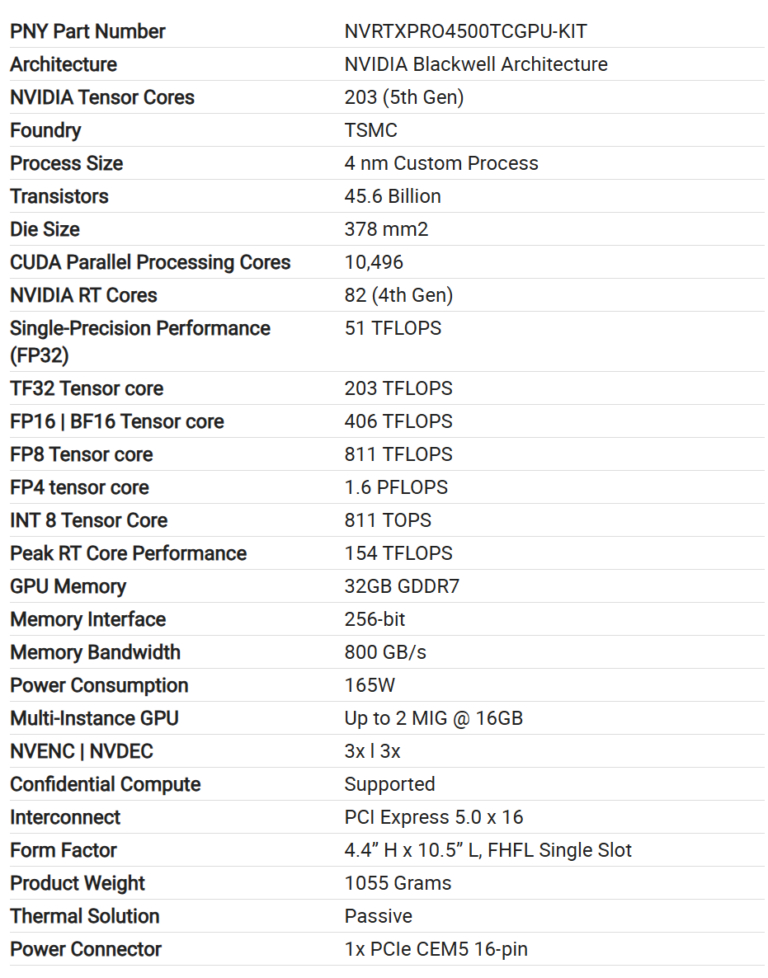
首先是功耗与形态。服务器版被设计为单槽、被动散热卡,额定功率约为 165W,而标准 RTX PRO 4500 工作站卡则采用双槽鼓风机结构,功耗约为 200W。这一变化的直接意义在于服务器环境的适配能力:被动散热配合机箱风道可以支持更高密度的 GPU 部署,同时降低单节点功耗压力,使其更适合 2U / 4U 服务器中的多卡配置。从系统设计角度看,这种差异会直接影响整机的电源设计、散热结构以及可部署密度。
其次是显存子系统的调整。服务器版的显存频率为 3125 MHz(等效 25 Gbps),而工作站版本为 3500 MHz(等效 28 Gbps),因此前者的总带宽约为 800 GB/s,略低于后者的 896 GB/s。这种带宽上的"下调"并不是性能退化,而是典型的工程取舍:在多数推理与企业应用场景中,带宽并不会成为首要瓶颈,而通过降低频率换取更好的功耗控制与稳定性,反而更符合长时间运行的服务器环境需求。
第三个关键差异在于 I/O 设计。服务器版取消了显示输出接口,而标准 RTX PRO 4500 则保留显示能力。这一变化本质上是角色定义的差异:前者面向机架式服务器与远程算力调用场景,强调作为计算节点运行;后者则仍然兼顾本地工作站的图形输出与交互需求。从这个角度看,服务器版已经完全脱离"显卡"的传统形态,更接近纯粹的计算加速器。
综合这些变化可以看到,RTX PRO 4500 Blackwell Server Edition 并不是简单的"降频版本",而是围绕数据中心与企业机房环境重新定义的一种形态。它保留了与工作站版本相同的核心计算能力与显存容量,但通过削减显示输出、调整显存带宽以及优化功耗与散热结构,换取更高的部署密度与更稳定的运行特性,这也是其"高密度节点型 GPU"的核心价值。
如果放在同一代 RTX PRO 产品体系中来看,RTX PRO 4500 与更高端的 RTX PRO 6000 之间的差异更能体现产品分层逻辑。两者同属 Blackwell 架构,但在资源配置上明显拉开层级:RTX PRO 6000 通常配备更大容量显存(接近或达到 96GB 级别),并具备更高的内存带宽和更强的 Tensor 计算能力,更适合中大型模型推理、复杂多任务并发甚至部分训练场景。而 RTX PRO 4500 则保持在 32GB 显存与中等带宽区间,更强调成本控制与部署密度。从实际应用来看,6000 更偏"能力上限",4500 更偏"规模复制",两者并不是替代关系,而是分别对应不同阶段和预算条件下的企业需求。
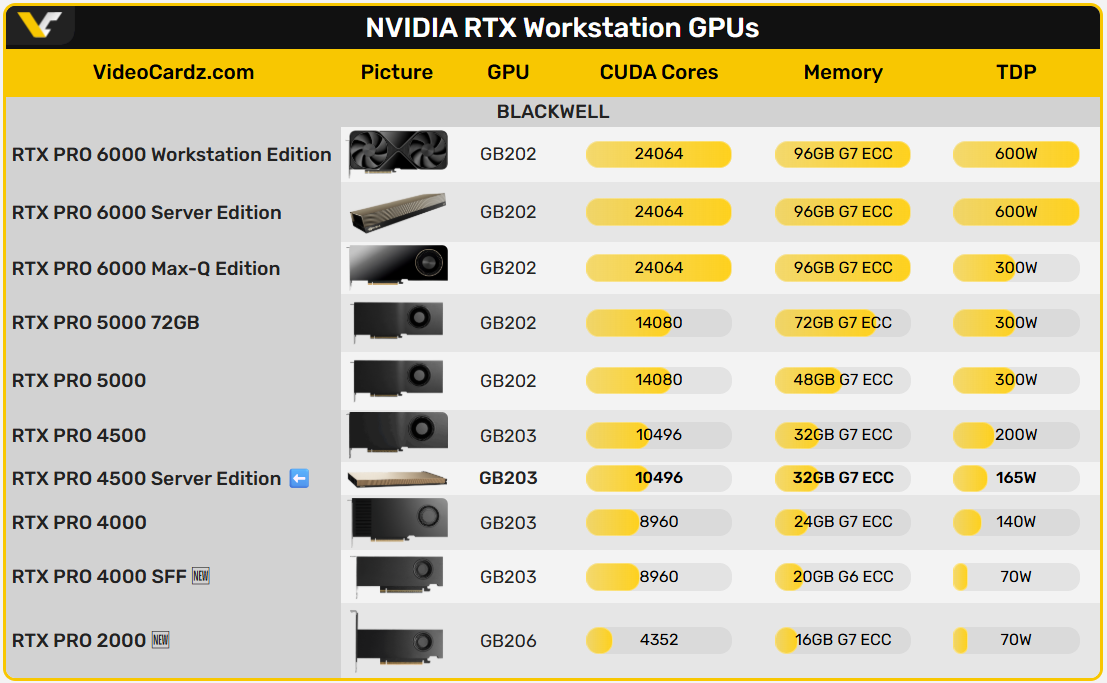
与数据中心 GPU(如 NVIDIA A100、NVIDIA H100、NVIDIA H200、NVIDIA B200)之间的关系,可以用一句话概括:分工大于竞争。这类数据中心 GPU 的核心价值在于大规模训练能力、高速互联(NVLink / NVSwitch)以及跨节点扩展,适用于基础模型训练或超大规模算力集群;而 RTX PRO 4500 所代表的这一类产品,更适合单节点或小规模集群中的推理与业务部署场景。在企业实际环境中,后者往往承担"把模型用起来"的角色,而不是"把模型训练出来"。
在软件与虚拟化层面,随着 vGPU 20.0 的推出,这一产品还将支持虚拟工作站能力,并通过多实例 GPU 技术实现基于硬件的资源切分。这意味着单张 GPU 可以被划分为多个独立实例,分别服务不同用户或任务,从而显著提升资源利用率。在企业 IT 架构中,这类能力通常比单卡性能提升更具实际价值。
从具体应用表现来看,这一代产品在多个典型场景中相较上一代入门数据中心 GPU(如 L4)也有明显提升。例如:
在小模型推理场景中,基于 NVIDIA Nemotron Nano 9B 的 SLM 推理性能最高可达到 L4 的约 10 倍;
在数据处理场景中,借助 NVIDIA cuDF 加速的 Apache Spark 查询,在处理 10TB 数据时性能可提升约 5 倍,同时整体拥有成本可压缩至传统 CPU 方案的十分之一左右;
在视觉 AI 方向,基于 NVIDIA Metropolis 平台并结合 Cosmos Reason 2 模型进行视频摘要生成时,其性能也可达到 L4 的约 4 倍。这些提升更多来自架构层面对 AI 负载的针对性优化,而非单纯的算力堆叠。

整体来看,RTX PRO 4500 Blackwell Server Edition 更接近一种面向企业部署场景优化的"算力单元"。它在保持核心计算能力不变的前提下,通过对功耗、带宽与形态的重新分配,使其更适合大规模、标准化的服务器部署环境;而在与 RTX PRO 6000 以及数据中心 GPU 的分层配合下,也逐渐形成了从"训练到推理"的完整算力结构。