笔记来自Acwing算法课图论与搜索课上,比较详细,附有模版代码
搜索
dfs 深搜
bfs宽搜
| 搜索类型 | 方式 | 数据结构 | 空间 |
|---|---|---|---|
| dfs | 深度优先 | stack | O(h) |
| bfs | 宽度优先 | queue | O(2^h) |
bfs搜到的具有最短性(对于路径长度为1的图,它会最先找到最短路),dfs没有这个性质
DFS
排列型枚举
cpp
void dfs(int u)
{
if(u == n)
{
for(int i = 0; i < n; i ++)
printf("%d ", path[i]);
puts(" ");
return;
}
for(int i = 1; i <= n; i ++)
{
if(!st[i])
{
st[i] = true;
path[u] = i;
dfs(u + 1);
//恢复现场
st[i] = false;
}
}
}指数型枚举/组合
枚举n个数的任意多个进行组合,输出方案
从1~n依次考虑每个数选或者不选,全部选就是空集
cpp
int st[N];//记录每个数字的使用情况
int n;
void dfs(int u)//u代表该填哪个位置(从1开始)
{
if(u > n)
{
for(int i = 1; i <= n; i ++)
if(st[i] == 1) printf("%d ", i);
puts("");
return;
}
st[u] = 1;//选
dfs(u + 1);
//st[u] = 0;//恢复现场
st[u] = 2;//不选
dfs(u + 1);
}记录所以方案,可以考虑引入vector数组存,因为每个方案长度不一样,也可以开普通数组通过判断这个位置是不是0来输出
cpp
vector<vector<int>> ways;
void dfs(int u)
{
if(u > n)
{
vector<int> way;
for(int i = 1; i <= n; i ++)
if(st[i] == 1)
way.push_back(i);
ways.push_back(way);
return;
}
st[u] = 1;//选
dfs(u + 1);
//st[u] = 0;//恢复现场
st[u] = 2;//不选
dfs(u + 1);
}
int main()
{
cin>>n;
dfs(1);
for(int i = 0; i < ways.size(); i ++)
{
for(int j = 0; j < ways[i].size(); j ++)
printf("%d ", ways[i][j]);
puts("");
}
return 0; n皇后的处理思路
1、按照全排列思想遍历:每位表示行数,第一位就是第一行,填的数表示列数,如:2就表示皇后在第一行第二列,实际上就是一个二维的排列问题,同时需要维护一些对角线数组和记录已经填入的行的数组以判断是否合法。时间复杂度是O(n^2)
可以加入剪枝操作,如果有一个位置的皇后不合法就不再往下递归,直接排除
对于对角线坐标的计算,使用y坐标b进行区分,主对角线(黑色)是左上到右下,将棋盘逆时针旋转90度后,对应y = x + b,b = y - x,对于坐标点(1, 7)这样计算就会出现负索引,由于行纵坐标最多相差n-1,所以补上n就可以防止出现负索引,所以b = y - x + n
对于负对角线(蓝色),对应y = -x + b,b = y + x,不会有索引为负的情况
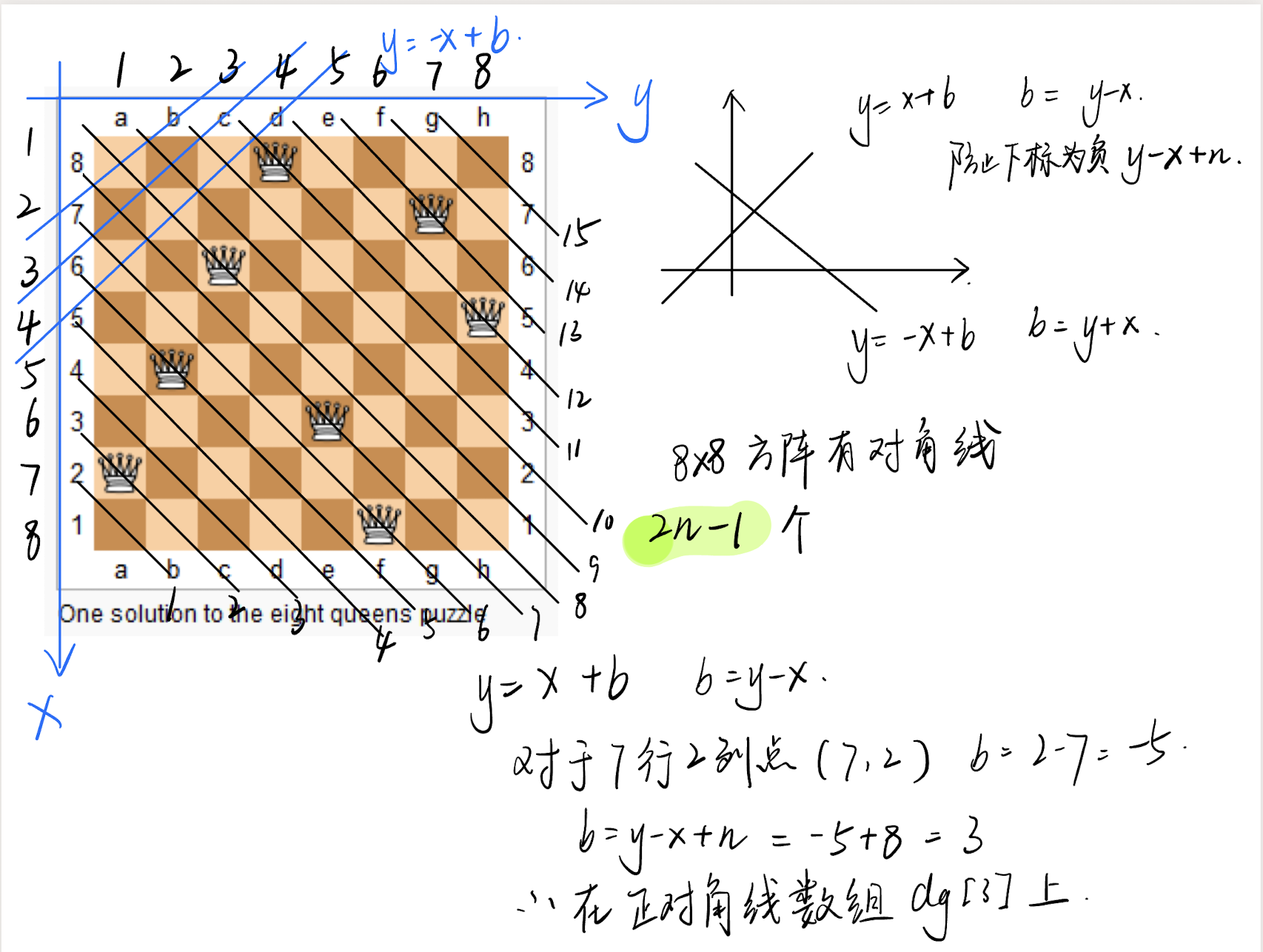
2、比较原始但是直观的方法;按照格子进行枚举,分别讨论放或者不放。时间复杂度是O(2^{n^2})
cpp
//使用x表示行号,y表示列号,s记录已经放了多少皇后
void dfs(int x, int y, int s)
{
if(s > n) return;
if(y == n) x ++, y = 0;
if(x == n)
{
if(s == n)
{
for(int i = 0; i < n; i ++)
printf("%s\n", g[i]);
puts("");
}
return;
}
//不放
g[x][y] = '.';
dfs(x, y + 1, s);
//放
//找到合法位置
if(!row[x] && !col[y] && !udg[y - x + n] && !dg[y + x])
{
g[x][y] = 'Q';
row[x] = col[y] = udg[y - x + n] = dg[y + x] = true;
dfs(x, y + 1, s + 1);
//恢复现场
row[x] = col[y] = udg[y - x + n] = dg[y + x] = false;
g[x][y] = '.';
}
}这段代码中的几个条件判断在DFS过程中起到了控制遍历流程和剪枝的作用,具体作用如下:
-
if(s > n) return;剪枝条件 :当已放置的皇后数量超过n时,直接返回。因为最多只能放置n个皇后,超过的情况不合法,无需继续搜索。 -
if(y == n) x++, y = 0;换行处理 :当遍历到当前行的最后一列(y从0到n-1)后,列号y会增加到n。此时需要将行号x加1,列号y重置为0,以处理下一行的第一个格子,确保按行优先顺序遍历棋盘。 -
if(x == n)棋盘遍历完成后的处理 :当行号x达到n时,说明所有行已遍历完毕。此时检查是否已放置n个皇后(s == n),若满足条件则输出合法棋盘配置,否则直接返回。这一条件确保仅当所有皇后正确放置时才输出解。
BFS
边权都是1的时候最短路可以用BFS求,按照层搜索,从距离起点为1的层开始搜,借助队列实现

基本流程如下
queue <- 初始状态
While queue 不空
{
t <- 队头
拓展t
}向量表示,pair数组,队列实现手写或者stl
注意对于这种有空格的输入
-
测试样例中的每行数据包含空格(如"0 0 0 0 0 0 1 0 0 1")
-
scanf("%s", g[i])会因遇到空格截断读取,导致只保存每行第一个字符到g[i][0],后续位置被错误填充
cpp
int bfs(int x, int y)
{
PII q[N * N];
int hh = 0, tt = 0;
memset(dist, -1, sizeof dist);
dist[x][y] = 0;
q[0] = {x, y};
int dx[4] = {0, -1, 0, 1}, dy[4] = {1, 0, -1, 0};
while(hh <= tt)
{
auto t = q[hh ++];
//遍历此点的4个方向
for(int i = 0; i < 4; i ++)
{
int nx = t.x + dx[i], ny = t.y + dy[i];
if(nx < 0 || nx >= n || ny < 0 || ny >= m || g[nx][ny] == '1' || dist[nx][ny] != -1) continue;
q[++ tt] = {nx, ny};
dist[nx][ny] = dist[t.x][t.y] + 1;
}
}
return dist[n - 1][m - 1];
}保留前面的点相当于维护一个链表
cpp
PII q[N * N], Prev[N][N];
int bfs()
{
int hh = 0, tt = 0;
//将d数组初始化为-1,表示还没有更新距离
memset(d, -1, sizeof(d));
d[0][0] = 0;
q[0] = {0, 0};
tt ++;
//使用向量遍历四个方向
int dx[4] = {-1, 0, 1, 0}, dy[4] = {0, 1, 0, -1};
while(hh <= tt)
{
auto t = q[hh ++];
for(int i = 0; i < 4; i++)
{
int x = t.first + dx[i], y = t.second + dy[i];
if(x >= 0 && x < n && y >= 0 && y < m && g[x][y] == 0 && d[x][y] == -1)
{
d[x][y] = d[t.first][t.second] + 1;
Prev[x][y] = t;
q[tt ++] = {x, y};
}
}
}
int x = n - 1, y = m - 1;
while(x || y)
{
cout<<x<<' '<<y<<endl;
//是一个二维数组但存的是一个pair向量
auto t = Prev[x][y];
x = t.first, y = t. second;
}
return d[n - 1][m - 1];
}树和图
数是一种特殊的图,树是无环连通 图
图分有向图和无向图
无向图建立两条边就行,a->b,b->a
综上所述只需考虑有向图的存储
存储
1.邻接矩阵 g a b 使用true或者false表示是否有边,对于有权值的则用数字表示,有重复边只能保留一条
空间复杂度高为O(n),适合存储稠密图
2.邻接表
使用数组和拉链法的哈希表类似
一共n个点,每个点都有一个链表,存这个点可以到达哪个点
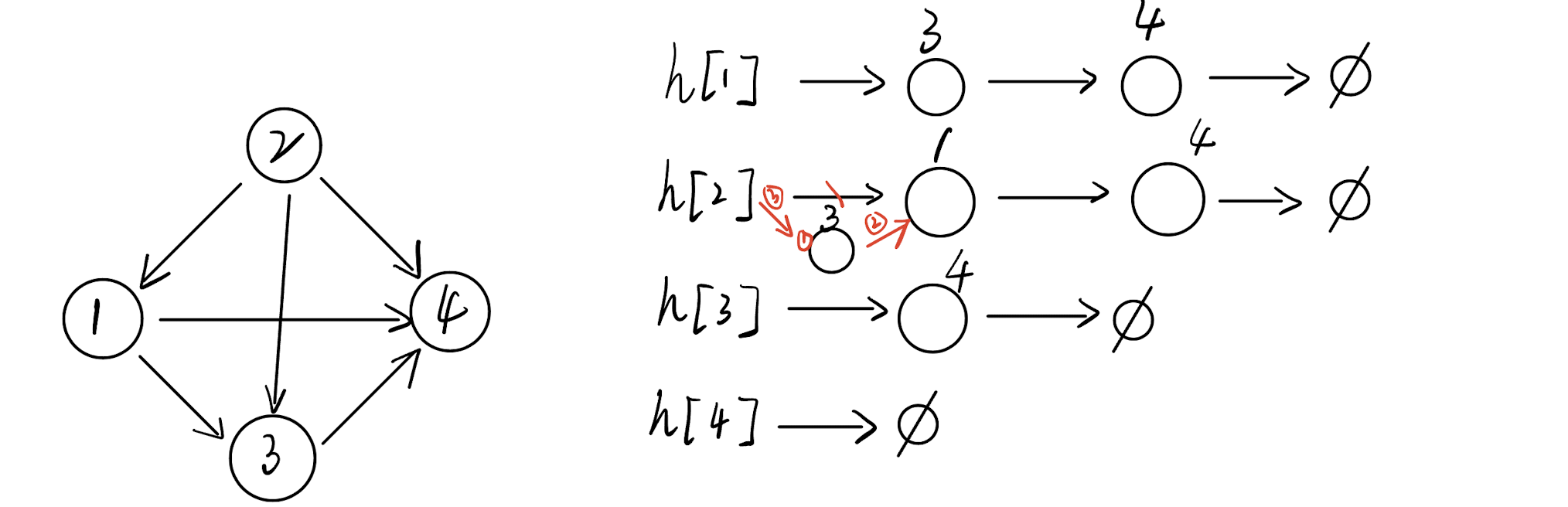
cpp
const int N = 100010, M = N * 2;
//h[N]表示各个以自身为头结点的链表,e[i]存头节点连出边的终点结点编号,即对于上图点3,点2这种编号,相当于边的数量
//h[i]这条链表示节点i课到达的点,并且这个链由idx串联,ne来保存下一个点的idx位置
//ne[i]指向结点编号为i的下一个节点的指针(编号)
int h[N], e[M], ne[M], idx;
//头插法,在a的链上插入点b
void add(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx ++;
}
int main()
{
//初始化把每条链表的头指针置为-1
memset(h, -1, sizeof(h));
}使用vector存储
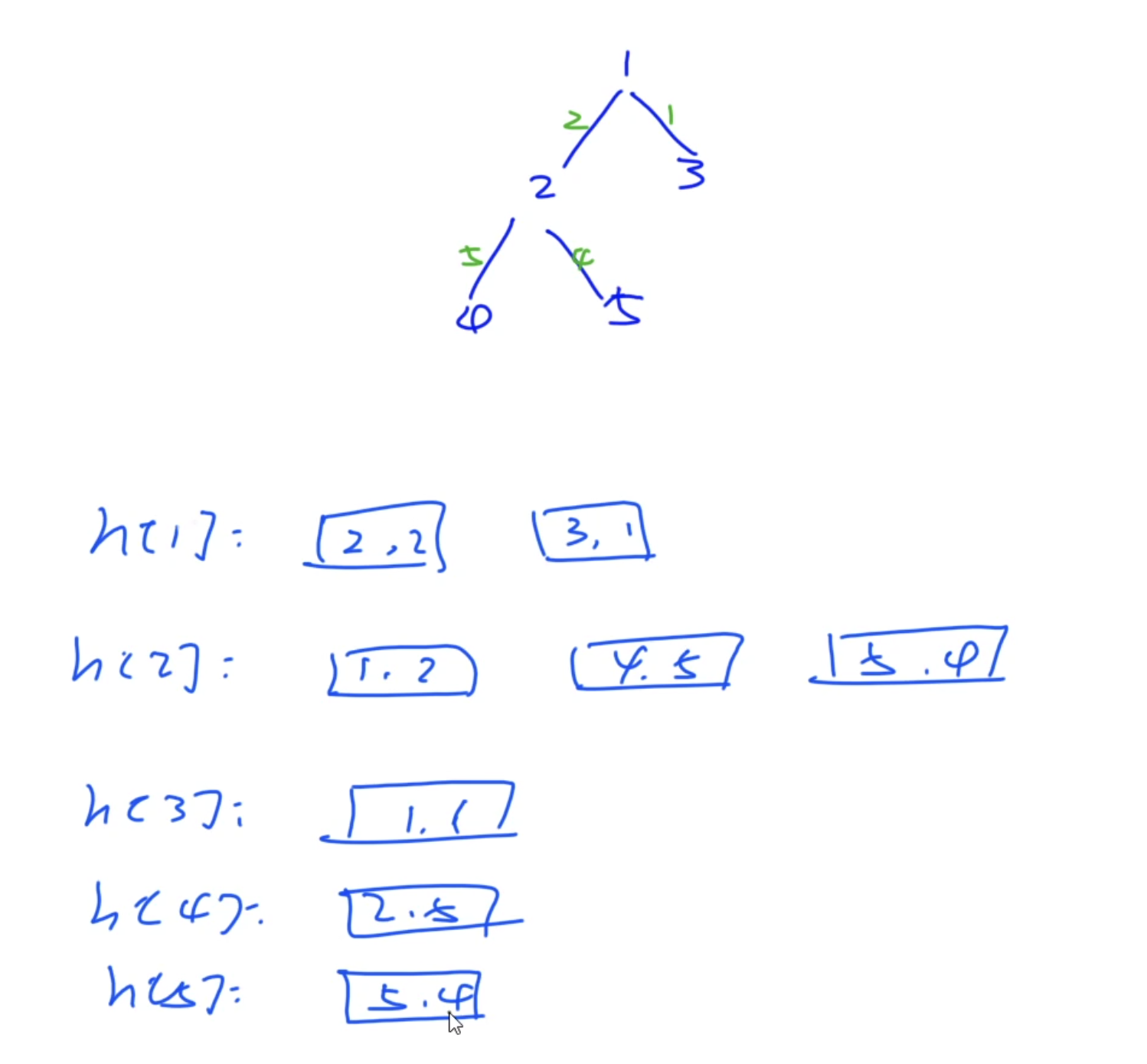
每行都是一个vector数组,其中每个二元组第一个是连接点的编号,第二个是边的长度
cpp
//使用n个vector数组存储图
//存储所以的边,由于是图,每个边会存储两遍
struct Egde
{
int id, w;
};
vector<Egde> h[N];
int dist[N];//表示从某一个起点开始距离其他点的距离
//由于要求数的直径这个数组要使用两遍
for(int i = 0; i < n; i ++)
{
int a, b, c;
scanf("%d%d%d", &a, &b, &c);
h[a].push_back({b, c});//因为是图所以要存两遍
h[b].push_back({a, c});
}遍历
只需考虑有向图是如何遍历的
深度优先搜索
cpp
//存储结点是否被遍历过
bool st[N];
void dfs(int u)
{
标记编号为u的结点已被遍历
st[u] = true;
//遍历以h[u]为首的链表
for(int i = h[u]; i != -1; i = ne[i])//也可以写出~i
{
//取出结点的编号,这里的i就相当于idx索引
int j = e[i];
if(!st[j]) dfs(j);
}
}宽度优先遍历
无权图最短路径
如果边长为1,可以用它求最短路,最短路考虑宽搜
/*
queue <- 1
while queue 不空
{
t <- 队头
拓展t的所以临点
if(x未遍历)
queue <- x
d[x] = d[t] + 1
}可以处理重边和自环的情况,遍历到重边后会因为di != -1也就是之前访问过,会跳过
diff
图:
1 → 2
1 → 2 (重边)
2 → 3
3 → 3 (自环)
初始:
队列 q = [1]
d = [-1, 0, -1, -1]
+Step 1:出队 1
- 邻接 1→2:d[2] = 1,入队
- 邻接 1→2 (重边):d[2] 已访问,忽略
队列 q = [2]
d = [-1, 0, 1, -1]
+Step 2:出队 2
- 邻接 2→3:d[3] = 2,入队
队列 q = [3]
d = [-1, 0, 1, 2]
+Step 3:出队 3
- 邻接 3→3 (自环):d[3] 已访问,忽略
队列 q = []
d = [-1, 0, 1, 2]
结束:
d[1]=0, d[2]=1, d[3]=2拓扑排序
有向图才有拓扑序列
宽搜的一个基本用法是求图的拓扑序列
将一个图的点从小到大排列,每一个边都是由小到大的,都是向后指出的,从前指向后的
有向无环图一定存在一个拓扑序列,有向无环图被称为拓扑图
入度为0的点都排在前面,应为他前面没有点指向它
一个有向无环图一定至少存在一个入度为0的点
证明:反证法,随便找到一个点,由于它的入度不为0,就找到此点的上一个点,
从图中任意选择一个节点 v_1,由于入度不为 0,存在一个节点 v_2 指向它; 同理,v_2 的入度也不为 0,存在一个节点 v_3 指向它; 依此类推,我们不断向前找到一个序列:
如此循环当找到第n+1个点时(图一共只有n个点),由抽屉原理可知,此时一定有两个点是相同的,所以存在一个环
拓扑序不唯一
cpp
/*
queue <- 入队所以入度为0的点
while queue 不空
{
t <- 队头出队
枚举所以t的出边t->j
删掉t->j,d[j] --入度减去1
if d[j] == 0
queue<-j
}*/
bool topsort()
{
//定义队列注意这里起始没有元素所以tt为-1
int hh = 0, tt = -1;
for(int i = 1; i <= n; i ++)
{
//点都是从1开始
if(!d[i]) q[++ tt] = i;
}
while(hh <= tt)
{
//出队的顺序是拓扑序
int t = q[hh ++];
for(int i = h[t]; i != -1; i = ne[i])
{
//每取出一个点就将它临接的边删除,此点入度减一,如果入度为0就入队
int j = e[i];
d[j] --;
if(!d[j]) q[++ tt] = j;
}
}
//如果正好入队0~n-1一共n个点则说明找到拓扑序
//说明有n个点入队,那么就相当于全部遍历完成
return tt == n - 1;
}
无环有向图(Directed Acyclic Graph, DAG)的拓扑排序 (Topological Sorting)是一种将图中所有顶点排成一个线性序列的方法,使得对于每一条有向边 u →v ,顶点 u 在序列中总是位于顶点 v 的前面。这种排序的本质是对 DAG 的顶点进行一种先后顺序的约束 。
示例
对于下图:
A → B → C
↓ ↓
D → E
可能的拓扑排序为: A → B → D → E → C 或 A → D → B → E → C。
复杂度
-
时间复杂度 :O (V +E ),其中 V 是顶点数,E 是边数。
-
空间复杂度 :O (V)(存储入度表、队列或递归栈)。
题目:
是通过拓扑排序的顺序,将更优的解从富人传递给穷人,确保每个节点的ansv始终记录的是当前已知的最优解。
如果要求按照点的编号从大到小输出则需要使用小根堆,使得在队列中的点,编号小的先出队
比如这种情况的队列初始的时候是1 4,将1点拿出进行断边,加入3点,但此时队列头还是4点,导致4晚于3先出。
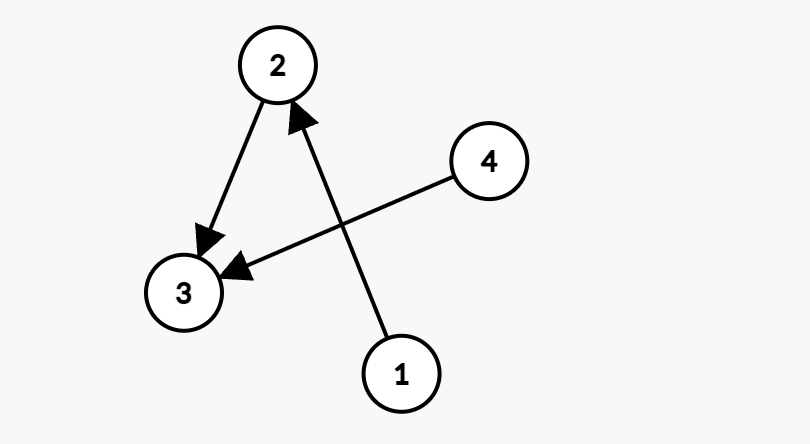
所以引入小根堆使得3加入小根堆以后先出
cpp
void topsort()
{
priority_queue<int, vector<int>, greater<int>> heap; // 小根堆
for (int i = 1; i <= n; i++)
if (indegree[i] == 0)
heap.push(i);
int idx = 0;
while (!heap.empty())
{
int u = heap.top();
heap.pop();
q[idx++] = u;
for (int i = h[u]; i != -1; i = ne[i])
{
int v = e[i];
indegree[v]--;
if (indegree[v] == 0)
heap.push(v);
}
}
for (int i = 0; i < idx; i++)
printf("%d ", q[i]);
puts("");
}
//此时队列就单纯保存答案,以移除小根堆堆顺序最短路
难点在于建图,如何将抽象的问题转化为最短路问题解决
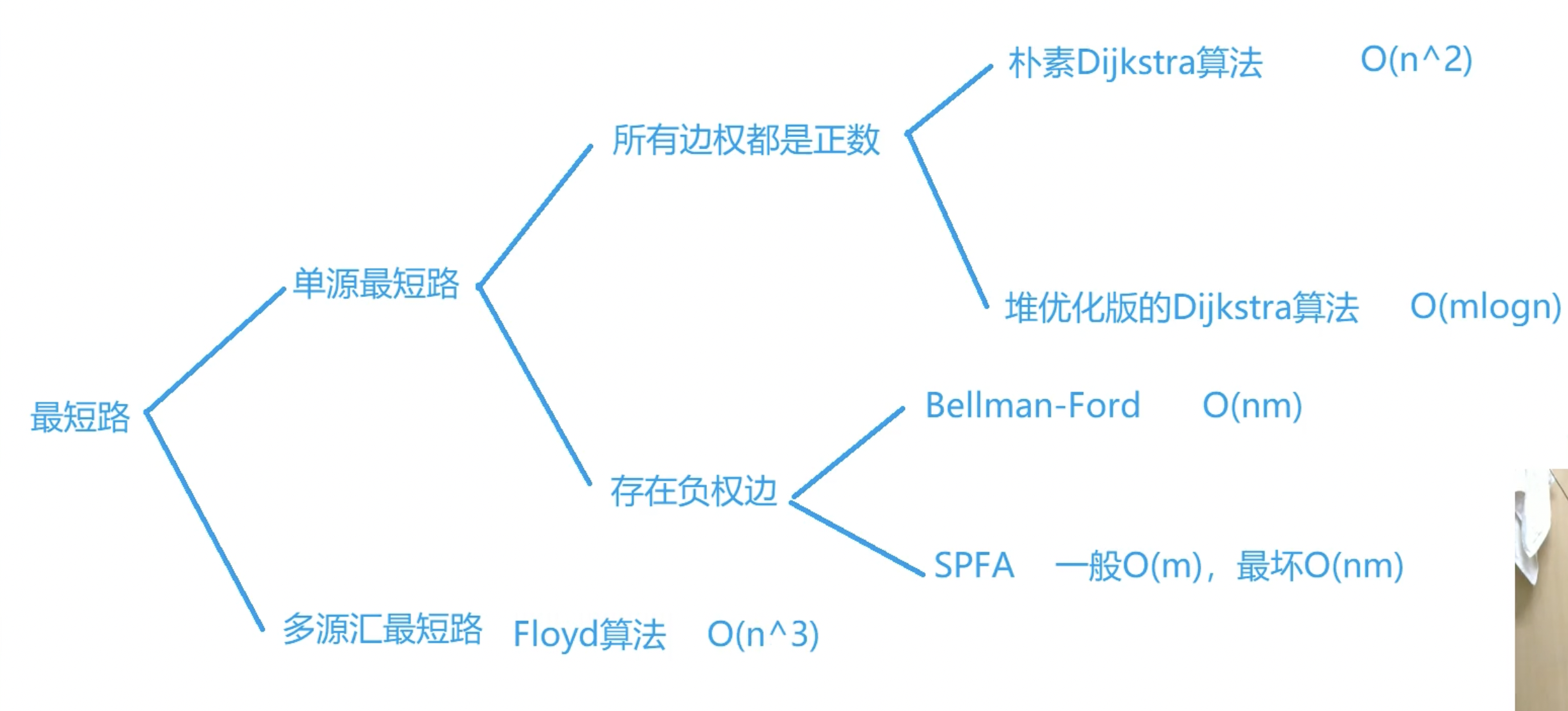
单源最短路是指从一个点出发到所以点的距离
多源汇最短路,源点就是起点,汇点就是终点,所以会有多个询问,起点终点不确定
约定:n表示点数,m表示边数,如果m和n^2一个级别就是稠密图
dijskra不能有负权边
要求一定不能存在负权边
求1号点到其他所有点的距离
只考虑有向图就行,遇到无向图就多加一个边,出现重边只保留最短的那条,如果权重都是正的子环不用考虑
对于初始点可以是1,也可以是k,如果是k的话dist数组求出的就是k距离各点的最短距离
稠密图用朴素版的dijskra
有自环或者重边(平行边)均不影响
1.初始化距离,dist1 = 0, disti = +\infty
2.for i 1~n循环,(s集合表示当前已经确定最短距离的点)
(1)找到不在s中的距离最近的点t
(2)将头加入到集合s
用t更新其他点的距离,如更新到x点的距离,主要判断distx > distt + w,循环n次就可得到每个点的距离
cpp
#include<cstdio>
#include<iostream>
#include<cstring>
using namespace std;
const int N = 510;
//分别存入稠密图,是否确定最终距离,起点到各点的距离
int g[N][N], st[N], dist[N];
int n, m;
int dijskra()
{
//先将各点初始化为1e9级别
memset(dist, 0x3f, sizeof dist);
//这里题目求1到n点的最短距离,所以先将1号点初始化
dist[1] = 0;
//寻找未确定最短距离,且dist数组值最小的点进行更新
for(int i = 1; i <= n; i ++)
{
int t = -1;
for(int j = 1; j <= n; j ++)
if(!st[j] && (t == -1 || dist[t] > dist[j]))
t = j;
//使用点t对1到所以点的最短距离dist数组进行更新
for(int j = 1; j <= n; j ++)
{
//判断到j的距离是否可以通过t的距离和t到j的距离进行更新
//如果遍历到t == j的时候,如果存在自环的话,因为所有边权均为正,
//所以 dist[t] + g[t][t] 必然大于 dist[t],因此自环不会更新(也不会使得距离更短)
//因此如果出现负权环则会失效
dist[j] = min(dist[j], dist[t] + g[t][j]);
}
//点t确定最终状态
st[t] = true;
}
if(dist[n] == 0x3f3f3f3f) return -1;
else return dist[n];
}
int main()
{
//读入n个点,m条边
scanf("%d%d", &n, &m);
//初始化g, 先将各点设置为不可达的状态
memset(g, 0x3f, sizeof g);
for(int i = 0; i < m; i ++)
{
int x, y, z;
scanf("%d%d%d", &x, &y, &z);
//处理重边,只选择最短的边
g[x][y] = min(g[x][y], z);
}
cout<<dijskra()<<endl;
return 0;
}这里t=-1的作用是什么?
保证寻找到当前未访问的且距离源点最近的
每一轮寻找当前距离源点的dist距离最小的点,使用未访问过的第一个点进行初始化,再与其他未访问的点进行比较。
cpp
int t = -1;
for(int j = 1; j <= n; j ++)
if(!st[j] && (t == -1 || dist[t] > dist[j]))
t = j;近一步的,如果源点是3,会有dist3 = 0,这里循环第一次j=1,满足条件更新t = j,但是实际dist1 = 0x3f3f3f3f只是t的作用,到j=3就会把t复制为正确的3
堆优化版本的dijskra算法
如果是稀疏图点的个数是1e5的话容易爆掉(因为朴素版dijskra的复杂度为n^2)
下面介绍堆优化版本的dijskra复杂度为O(mlogn)
dijskra几个步骤的复杂度分析
1.dist1 = 0, disti = +\infty
2.for i : 1~n
(1) t <- t不再s中的距离最近的点,时间复杂度n^2
优化后每次找距离最近的点的复杂度为O(1),循环n次变为n
(2) s <- t n次
(3) 用t更新其他距离 m次 它通过外层的循环和内层每个点确定最短距离后更新此点连接的边距离,这些操作相当于遍历了二维数据g的所以边,所以复杂度总体算下来是m即图的边数。
优化后对于堆堆每次push插入操作复杂度是logn,一共修改m次所以是mlogn
综上可以使用堆优化第一个操作,和第三个操作
优化后,
使用优先队列模拟堆,使用于稀疏矩阵,m < n^2 每次修改都往队列里面插入一个数,可能会有冗余,最多m个元素,复杂度mlogm
由于是稀疏图m<n^2,然后最外层的while复杂度为m,每次修改为logn n是节点个数,这里最多m条边进入堆,所以节点个数为m
和mlogn相同级别,
Bellman-ford 算法
存边方式可以通过结构体存储,主要是为了完成遍历所有边
大体流程如下

每次更新主要看到达b的距离和先到达a再通过a到达b的距离进行对比
时间复杂度O(nm)
一些名词
更新的操作dist[b] = min(dist[b], dist[a] + w)叫松弛操作
循环之后对于每个边一定满足dist[b] <= dist[a] + w称为三角不等式
cpp
struct edge
{
int a, b, c;
}edges[M];
void bellman_ford()
{
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
for(int i = 0; i < k; i ++)
{
//获取上一轮迭代的dist数组
memcpy(backup, dist, sizeof dist);
//注意这里是遍历所有边
for(int j = 0; j < m; j ++)
{
int a = edges[j].a, b = edges[j].b, c = edges[j].c;
dist[b] = min(dist[b], backup[a] + c);
}
}
if(dist[n] > 0x3f3f3f3f / 2) printf("impossible");
else printf("%d\n", dist[n]);
}可以处理有负权边的图
有负权回路从1号点到n号点的最短距离会不存在,从1到5的最短距离不会存在

所以一般情况下能求出最短距离说明图中没有负权回路的
并非只要有负环就无法求出最短路径,只要负环不再最短路径上就行,注意这是有向图
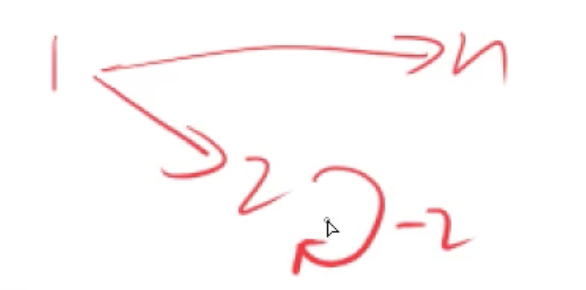
所以说有负权回路最短路径不一定存在
可以判断是否存在负权回路
迭代k次表示的含义,经过不超过k条边的最短距离
如果在第n次循环还有更新的话就说明,存在一条最短路径有n条边到第n点,但是1到n只有n-1个边,所以说明存在环
但是时间复杂度比较高,一般不使用它来做,一般用spfa做
这题只能用bellman-ford算法做(有限制经过的边的个数不能超过k)
为什么需要备份数组backup?防止串联如下图所示
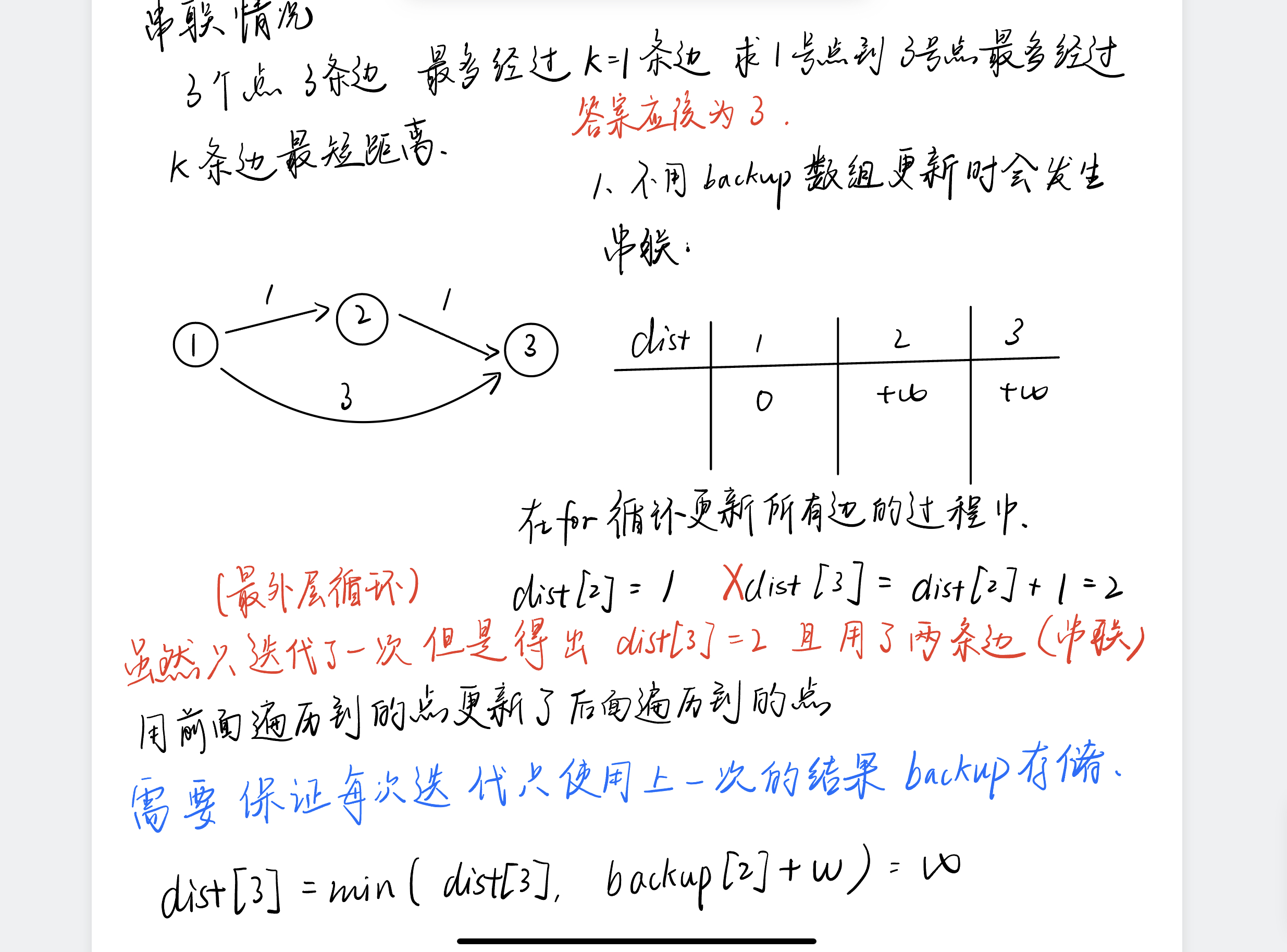

SPFA
只要没有负环就可以使用spfa算法,99.9%的最短路问题是没有负环的
其实是对bellman-ford算法的优化,对于bellman-ford的关键操作:每次循环对于每一个由a->b权重为w的边都进行如下更新
但是实际上并不是每次遍历所有边distb都会被更新,关键在于backupa是否变小
使用宽搜做优化,队列里存的就是所有变小的dista节点
主要思路是,我这个点变小了,通过变小的点更新其他的点,其他的点才会变小
cpp
queue <- 1
While queue 不空//如果t变小了那么所有以t为起点的边的终点距离都有可能变小
[1] t <- q.front
q.pop()
[2] 更新t的所有出边 t -> b
queue <- b 入队//如果队列没有此点则入队,使用st数组防止队列中出现重复的点
cpp
int spfa()
{
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
queue<int> q;
q.push(1);//放入的同时记录st数组
st[1] = true;
while(q.size())
{
auto t = q.front();
q.pop();
st[t] = false;
//遍历以t结点为头结点的边链表,用t更新t可以到达的节点
for(int i = h[t]; i != -1; i = ne[i])
{
int j = e[i];
//w[i]表示从点t经历一条边到达点j的距离
if(dist[j] > dist[t] + w[i])
{
dist[j] = dist[t] + w[i];
if(!st[j])
{
//当一个节点已经在队列中时,如果再次发现可以通过其他边松弛该节点,此时无需重复入队。因为队列中的该节点会在后续被处理,届时会重新检查所有邻边。
q.push(j);
st[j] = true;
}
}
}
}
return dist[n];
}为什么需要st数组
在SPFA算法中,st数组的作用是标记节点当前是否在队列中,避免重复入队,从而提升算法效率。
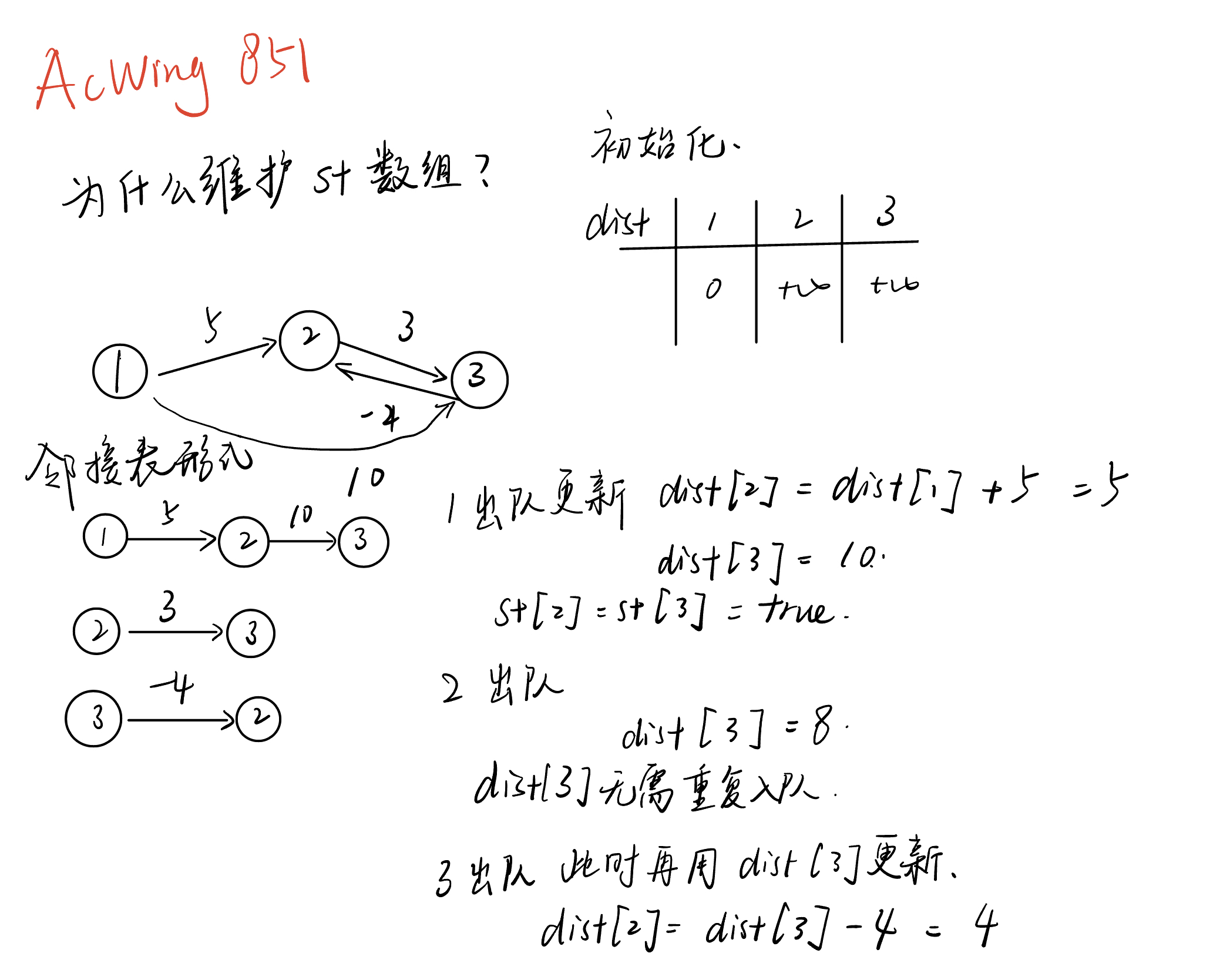
spfa循环队列写法
循环队列逻辑
初始化
cpp
int hh = 0, tt = 0; // 队列为空入队
cpp
q[++ tt] = x;
if(tt == CAP) tt = 0;//CAP 就是 q[] 的长度(比如你定义的 q[N],那 CAP = N)出队
cpp
int t = q[hh ++];
if(hh == CAP) tt = 0;每次出队入队涉及指针后移操作后就立即判断
判断循环队列是否为空
cpp
hh == tt // 队列为空判断队列是否为满
cpp
(hh == (tt + 1) % CAP) // 队列已满spfa循环队列写法
cpp
void spfa()
{
memset(dist, 0x3f, sizeof dist);
dist[S] = 0;
int hh = 0, tt = 1;
q[0] = S;
st[S] = true;
while(hh != tt)
{
auto t = q[hh ++];
if(hh == n) hh = 0;
st[t] = false;
for(int i = h[t]; ~i; i = ne[i])
{
int j = e[i];
if(dist[j] > dist[t] + w[i])
{
dist[j] = dist[t] + w[i];
if(!st[j])
{
q[tt ++] = j;
if(tt == n) tt = 0;
st[j] = true;
}
}
}
}
}使用spfa求负环
可以判断图中是否存在负权回路
负权回路(Negative Weight Cycle)是图中存在至少一个环,使得经过该环的路径权重之和为负值。
使用抽屉原理
dist表示虚拟原点到x点的最短距离
cnt表示当前最短路边的数量

图中可能存在负环,但是由一号点出发可能到不了,需要将所有点都放入初始队列里面
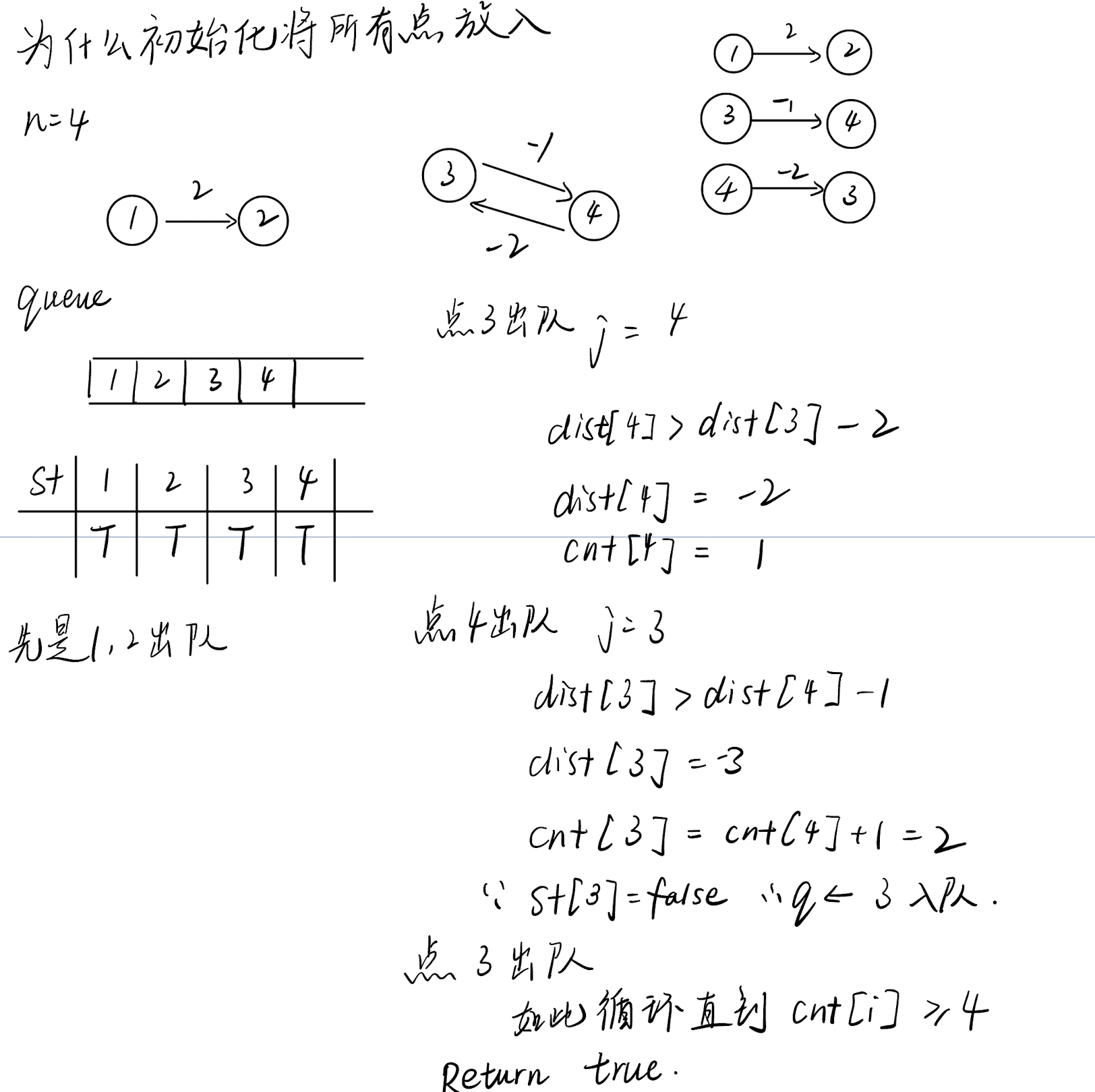
cpp
//dist存储虚拟源点到各点距离,原点和各点距离为0,所以不影响距离数组
//cnt存储虚拟原点到各点的变数,初始也是0,原点到各点边数为0
int dist[N], cnt[N], st[N];
void add(int x, int y, int z)
{
e[idx] = y, ne[idx] = h[x], w[idx] = z, h[x] = idx ++;
}
bool spfa()
{
queue<int> q;
//需要初始将所以点入队,和spfa只入队第一个点不同,
//防止1到n的路径不经过存在的负权回路
for(int i = 1; i <= n; i ++)
{
q.push(i);
st[i] = true;
}
while(q.size())
{
auto t = q.front();
q.pop();
st[t] = false;
for(int i = h[t]; i != -1; i = ne[i])
{
int j = e[i];
if(dist[j] > dist[t] + w[i])
{
dist[j] = dist[t] + w[i];
cnt[j] = cnt[t] + 1;
if(cnt[t] >= n) return true;
if (!st[j])
{
q.push(j);
st[j] = true;
}
}
}
}
return false;
}Floyd
可以求出任意两点间距离
基于动态规划的思想,distk, i, j表示有i开始只经过1~k这些中间点然后到达k的最短距离 distk, i, j = distk-1, i, k + distk-1, k, j; 经过k-1条边i到k再加上k到j只经过k-1条边
时间复杂度为O(n^3),所以一般用Floyd算法的n都不会太大,而且m边数一遍比较大,使用邻接矩阵的方法存储
简单证明
问题:任意两点之间的最短路径
输入图的边权(disti j 一开始就是从 i 到 j 的直接边权,如果没有边就是无穷大)
输出任意两点之间的最短路径
定义:dp[k][i][j] = 从 i 到 j 的最短路径长度,且中间点只允许从 1 ~ k 中选择。
这样我们把大问题分解为子问题:
-
最终答案就是
dp[n][i][j]。 -
边界条件:
dp[0][i][j] = 初始边权(只允许不经过任何中间点时,最短路就是直接边)。
状态转移方程
如果我们要计算 dp[k][i][j],有两种情况:
-
不经过 k 作为中间点 :那最短路就是
dp[k-1][i][j]。 -
经过 k 作为中间点 :那路径就拆成两段:
i → k和k → j,所以是dp[k-1][i][k] + dp[k-1][k][j]。
注意这里的dp[k-1][k][j]表示经过的中间点是1~k-1,起点是k,终点是j,dp[k-1][i][k]表示经过的中间点是1~k-1,起点是i,终点是k,这样他们的组合就相当于经过了k个点,起点为i,终点为j的最短路径长度
因此有递归公式
注意到 dp[k][*][*] 只依赖 dp[k-1][*][*],所以可以把三维数组压缩成二维:
cpp
void floyd()
{
for(int k = 1; k <= n; k ++)
for(int i = 1; i <= n; i ++)
for(int j = 1; j <= n; j ++)
dist[i][j] = min(dist[i][j], dist[i][k] + dist[k][j]);
}不受重边影响,输入的时候对于重边取最小值即可1
不受自环影响
-
-
权值为 0:对最短路没有影响,因为我们一般初始化
dist[i][i] = 0,自环权值再小也不会更优。 -
权值为正:完全无用,因为走一圈再回来只会变长。
-
权值为负:这时就相当于一个负环(negative cycle),会导致最短路不收敛。
- Floyd 在这种情况下不会报错,但
dist[i][i]最终会变成负数,可以用它来检测负环。
- Floyd 在这种情况下不会报错,但
-
注意:即使负环不包含自环,最终还是会在环上的点的 dist[i][i] 里显现出来
只要有负权环(无论是否自环)最后一定会有dist[i][i]<0
-
自环负权环
- 边
i → i权值 < 0:
dist[i][i] = min(dist[i][i], dist[i][i] + w) = w < 0- 直接导致
dist[i][i]变负。
- 边
-
非自环负权环
-
环
v1 → v2 → ... → vk → v1权值和 < 0。 -
当 Floyd 放开中间点
{v1,...,vk}时:
dist[v1][v1] <= dist[v1][v2] + … + dist[vk][v1] < 0- 环上所有顶点的
dist[vi][vi]都会变负。
-
-
为什么不用
dist[i][j]-
对
i ≠ j,Floyd 有限次松弛,可能得到负数但不能确定负环。 -
对
i = j,走环权值为负时,dist[i][i] < 0是负环的充要条件。
-
for (int i = 1; i <= n; i++) {
if (dist[i][i] < 0) {
cout << "Graph has a negative cycle\n";
}
}最小生成树
最小生成树的问题一般是针对无向图比较多,难点在于建图
稠密图用朴素版的Prim,稀疏图用堆优化版的
稀疏图使用kruskal比较多
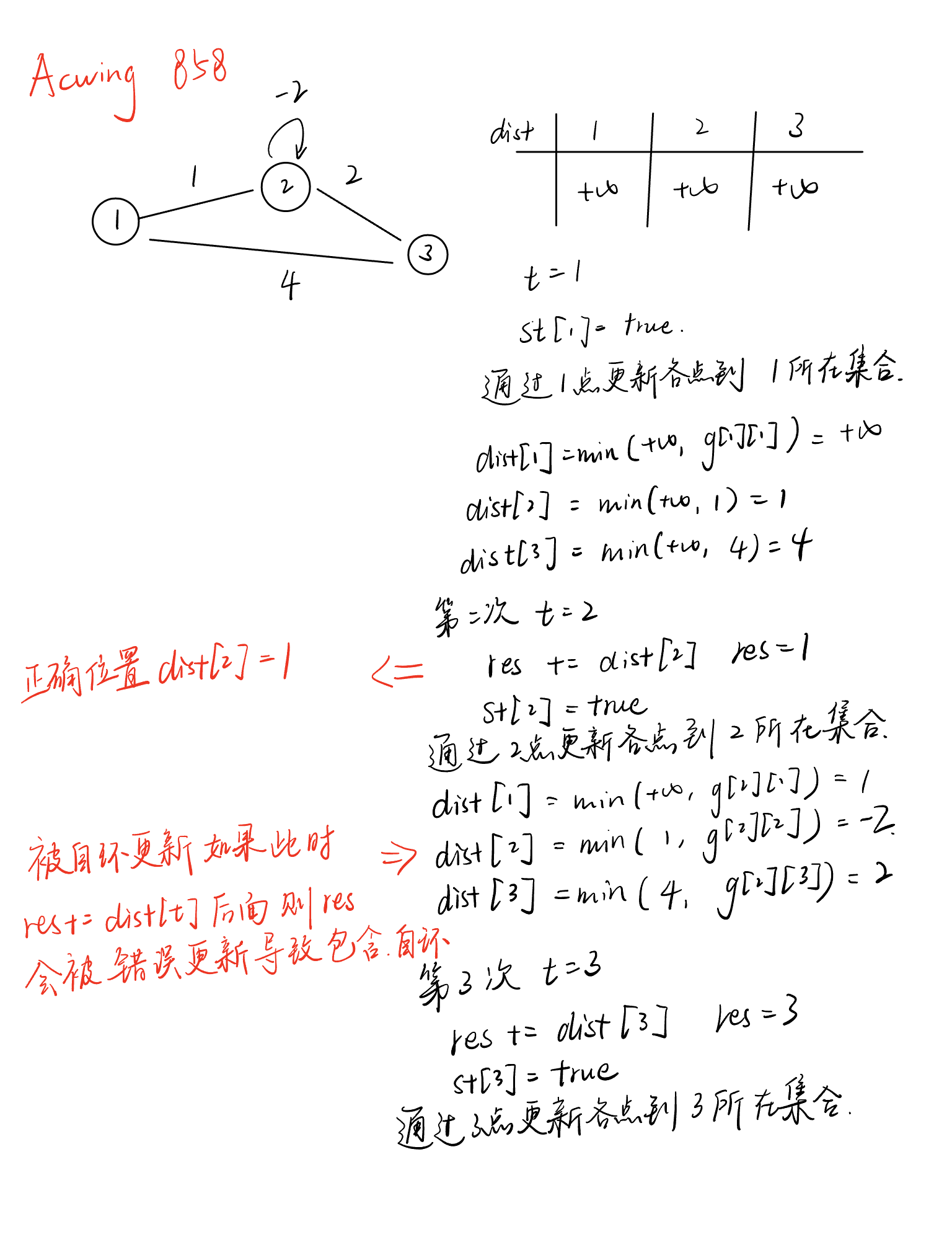
朴素版Prim
与dijskra很像
伪代码如下
distn <- +\infin全部赋值无穷
For(int i = 0; i < n; i ++)
1.t <- 找到集合外距离最近的点
2.用t更新其他点到集合的距离
stt = true
为什么这里是迭代n次而不是像dijskra迭代n-1次?
因为这里需要加入n个点,而dijskra是上来先选中一个点,那么只剩下n-1个点需要添加,那么只需迭代n-1次即可,而prim上来没有选中一个点,所以需要迭代n次
cpp
int prim()
{
int res = 0;
memset(dist, 0x3f, sizeof dist);
//因为有n个点所以维持n次循环
for(int i = 0; i < n; i ++)//O(n)
{
int t = -1;
for(int j = 1; j <= n; j ++)//O(n)
if(!st[j] &&(t == -1 || dist[t] > dist[j]))
t = j;
//如果t不是第一个点而且距离还是INF的话,说明不可达
//由最小生成树的定义,有不可达点说明没有最小生成树
if(i && dist[t] == INF) return INF;
//如果找到的点不是第一个点的话就加上边的权重
if(i) res += dist[t];
//使用点t对t能到达的点进行更新
for(int j = 1; j <= n; j ++)//o(n)
//这里的g[t][j]仅表示点j到目前的最小生成树中的点t的距离
dist[j] = min(dist[j], g[t][j]);
st[t] = true;//表示加入最小生成树
}
return res;
}为什么要将res += distt写在更新距离代码的前面?
Kruskal
Kruskal算法求最小生成树基本流程
1.将所以边按照权重从大到小排序O(mlogm)
2.枚举每条边a-b权重为c
if a,b不连通将这条边加入集合之中
使用并查集完成,由于并查集每次合并的复杂度是O(1),并且循环m次最多执行m次合并操作(给的图本身就是一个数)所以这部的复杂度为O(m),综上复杂度为O(mlogm)
总体思路:从小到大试图将每条边加入图里面去
cpp
//使用结构体存储
struct Edge
{
int a, b, w;
//重载运算符<
bool operator< (const Edge& W)const
{
return w < W.w;
}
}edge[M];
int find(int x)
{
if(p[x] != x) p[x] = find(p[x]);
return p[x];
}
void kruskal()
{
sort(edge, edge + m);
//并查集数组初始化
for(int i = 1; i <= n; i ++) p[i] = i;//每个结点代表自己一个集合
//记录最小生成树的长度,cnt记录加上的边数
int res = 0, cnt = 0;
for(int i = 0; i < m; i ++)
{
int a = edge[i].a, b = edge[i].b, w = edge[i].w;
int ra = find(a), rb = find(b);
if(ra != rb)
{
p[ra] = rb;
res += w;
cnt ++;
}
}
//n个点的最小生成树有n-1条边
if(cnt < n - 1) printf("impossible\n");
else printf("%d\n", res);
}二分图
判别二分图;染色法
求二分图的最大匹配;匈牙利算法

染色法
什么是二分图
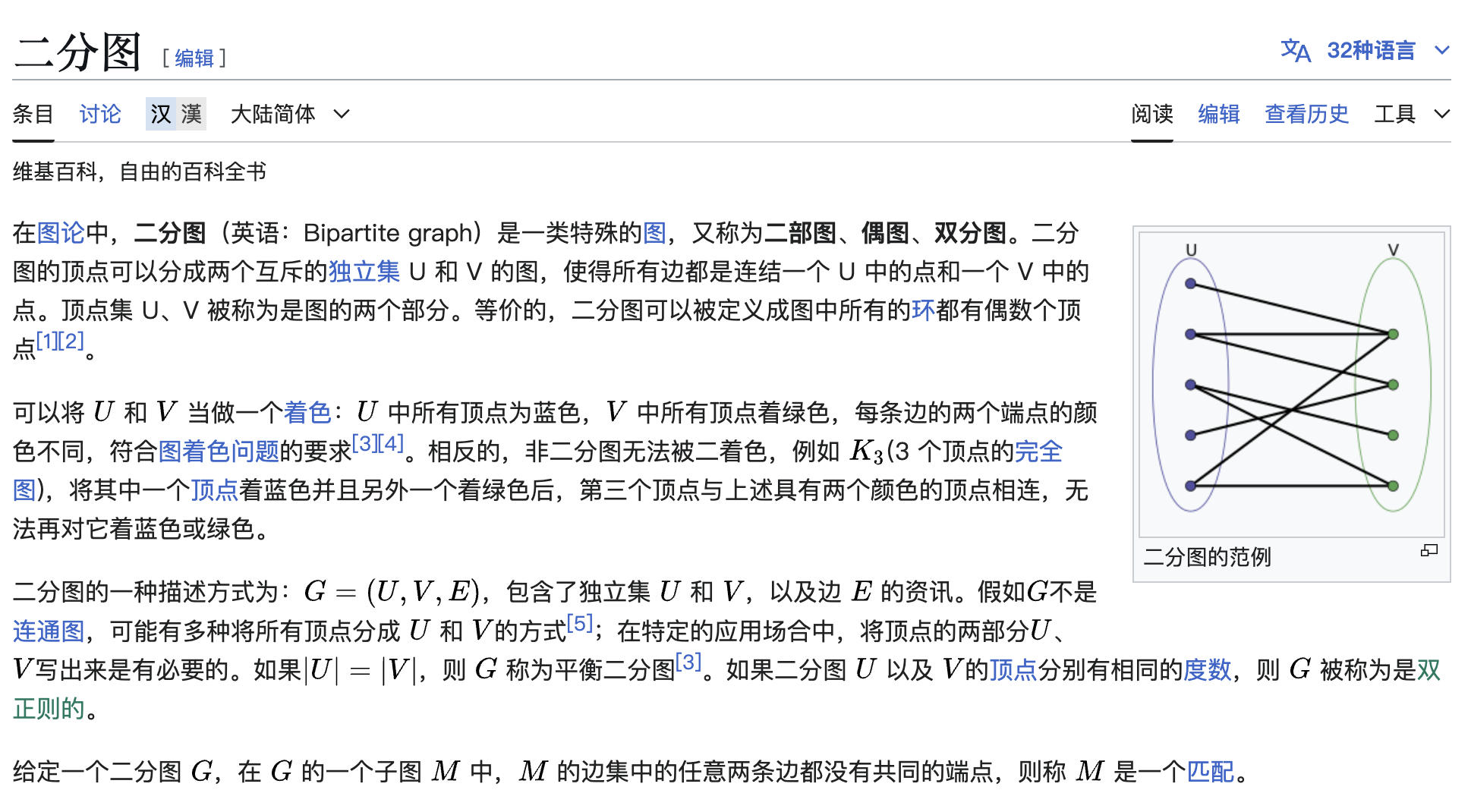
一个图是二分图当且仅当图中不含奇数环
证明如下:
假设存在一个奇数环点的个数为奇数个,设1号点在集合1中,那么2号点则在集合2中,3号点在集合1中,4号点在集合2中,5号点在集合2中,由于点的个数是奇数个,当再次回到1号点的时候发现1号点在集合2中,矛盾
二分图中不含有奇数环是二分图的必要性
充分性: 从前往后遍历所以点如果没有分组就将它放到左边去,遍历所以和这个点连通的点这些点属于右边,和右边这些点相连的点属于左边。由于图中没有奇数环所以这个染色过程中一定没有矛盾,可以构造反证,假设环上的结点分布是集合是1,2,1,2...如果出现矛盾一定是在某个点和之前的集合成环了,并且在连接处一条边的两个端点所在集合相同,而这种情况一定是出现了奇数环
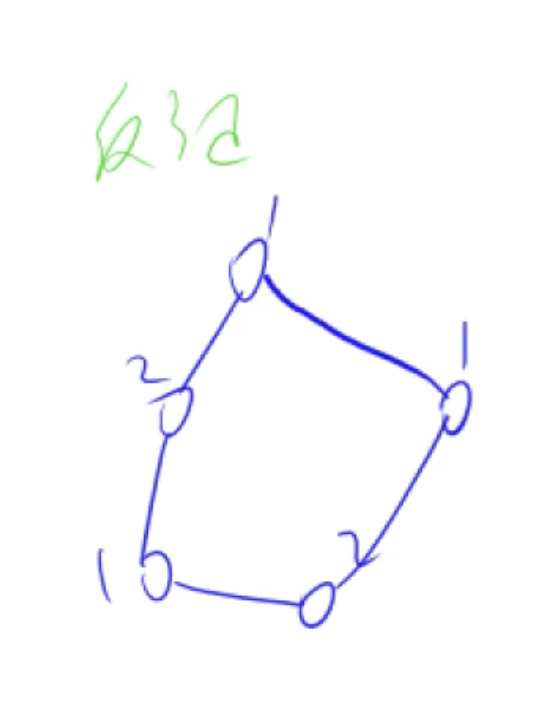
所以在染色法的过程中没有矛盾则是一个二分图
cpp
int color[N];//记录节点的颜色0表示未染色,1和2表示两种不同的颜色
bool flag;//记录当前的染色进度是否出现矛盾
//false表示染色失败,true表示成功
bool dfs(int u, int c)
{
//先为点u染色
color[u] = c;
//遍历u能到达的所以点
for(int i = h[u]; i != -1; i = ne[i])
{
int j = e[i];
if(!color[j])
{
if(!dfs(j, 3 - c)) return false;
}
else if(color[j] == c)
return false;
}
return true;
}
bool flag = true;
for(int i = 1; i <= n; i ++)
{
if(!color[i])
{
if(!dfs(i, 1))
{
flag = false;
break;
}
}
}
if(flag) puts("Yes");
else puts("No");匈牙利算法
匹配是指边的数量,没有两个边是公用一个点叫一个成功的匹配,匈牙利算法可以返回成功匹配中匹配数量最大的
时间复杂度考虑左边每个点(男生)O(n)最坏情况下把所以边遍历一遍所以最坏O(nm)
基本流程
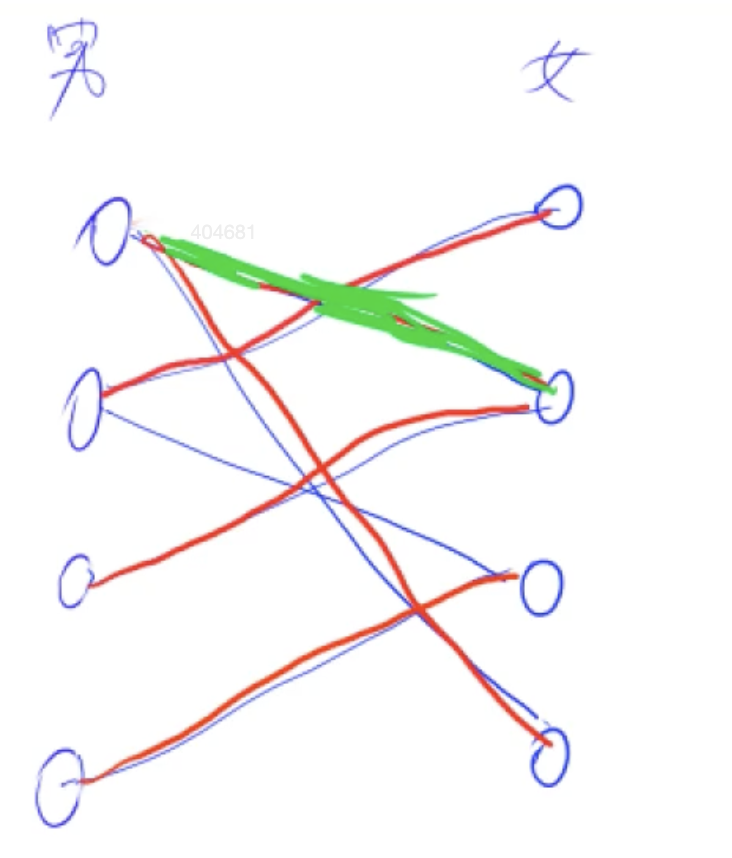
左一首先匹配右二,然后左二匹配右一,到左三发现也想匹配右二,所以找到右二匹配到左一,左一再去找其他喜欢的;先遍历到右二发现st2为true跳过,找到下一个节点右四且它的状态为st4 = false所以可以匹配
如果没有st数组,那么左一还会先找到右2进行匹配,发现右二已经匹配match2 = 1,所以右运行find(1),然后又从左一开始遍历到右2,会导致如此反复
cpp
#include<cstdio>
#include<iostream>
#include<cstring>
using namespace std;
//只会找左边连接右边的点,所以M不需要乘2
const int N = 510, M = 100010;
int e[M], ne[M], h[N], idx;
int n1, n2, m;
bool st[N];//判重防止重复搜索一个点
int match[N];//存储女生匹配上的男生节点编号
void add(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx ++;
}
bool find(int x)
{
//寻找男生所有看上的女生,并判断她们的状态
for(int i = h[x]; i != -1; i = ne[i])
{
int j = e[i];
//如果没有被考虑过
if(!st[j])
{
st[j] = true;
//如果这个女生还没有匹配,或者她匹配过的男生可以找到下家
//就和这个男生匹配
if(match[j] == 0 || find(match[j]))
{
match[j] = x;
return true;
}
}
}
return false;
}
int main()
{
cin>>n1>>n2>>m;
memset(h, -1, sizeof h);
for(int i = 0; i < m; i ++)
{
int a, b;
scanf("%d%d", &a, &b);
add(a, b);
}
int res = 0;
for(int i = 1; i <= n1; i ++)
{
memset(st, false, sizeof st);
if(find(i)) res ++;
}
printf("%d\n", res);
return 0;
}常见的两种使用dfs统计可以到达节点数
如何写一个清晰、正确的 DFS
我们应该回归到简单、标准的 DFS 写法。这里提供两种最常见的正确模式:
void类型
模式一:void类型的 DFS (通过引用计数)
这是对你现有想法的直接修正,逻辑最接近。
cpp
// DFS 函数只负责遍历和修改引用,不返回值
void dfs(int now, vector<vector<int>>& adj, vector<bool>& visited, int& count) {
visited[now] = true;
count++; // 将当前节点计入总数
// 遍历所有邻居
for (int neighbor : adj[now]) {
if (!visited[neighbor]) {
dfs(neighbor, adj, visited, count); // 递归访问未访问过的邻居
}
}
}主函数中这样调用:
cpp
int ans = 0;
if (n == 0) return 0;
for (int i = 0; i < n; i++) {
vector<bool> visited(n, false);
int count = 0; // 为每次DFS初始化计数器
dfs(i, adj, visited, count); // i是起点
ans = max(ans, count);
}
return ans;这个模式非常清晰:dfs 的任务就是填满 visited 数组和更新 count,主函数负责循环和找最大值。
返回 int 类型
模式二:返回 int 类型的 DFS (通过返回值计数)
这个模式更"函数式",它将子问题的结果返回给调用者。
cpp
// DFS 函数返回从 now 出发能引爆的节点数
int dfs(int now, vector<vector<int>>& adj, vector<bool>& visited) {
if (visited[now]) return 0; // 如果已访问,贡献为0
visited[now] = true;
int count = 1; // 先把自己算上
for (int neighbor : adj[now]) {
count += dfs(neighbor, adj, visited);
}
return count;
}主函数中这样调用:
cpp
int ans = 0;
if (n == 0) return 0;
for (int i = 0; i < n; i++) {
vector<bool> visited(n, false); // 每次都需要新的 visited
ans = max(ans, dfs(i, adj, visited));
}
return ans;