1. 研究背景
该代码旨在构建一个基于集成学习的回归模型,并利用SHAP(SHapley Additive exPlanations) 方法对模型预测结果进行解释。SHAP源于合作博弈论中的Shapley值,通过量化每个特征对预测的边际贡献,满足对称性、有效性、线性性和零贡献性,是目前机器学习可解释性领域的主流工具。代码将回归建模与SHAP解释相结合,适用于需要同时获得高精度预测和特征重要性分析的场景。
2. 主要功能
- 数据预处理:从Excel读取数据,进行归一化,划分训练集与测试集(可随机打乱)。
- 集成学习回归 :使用
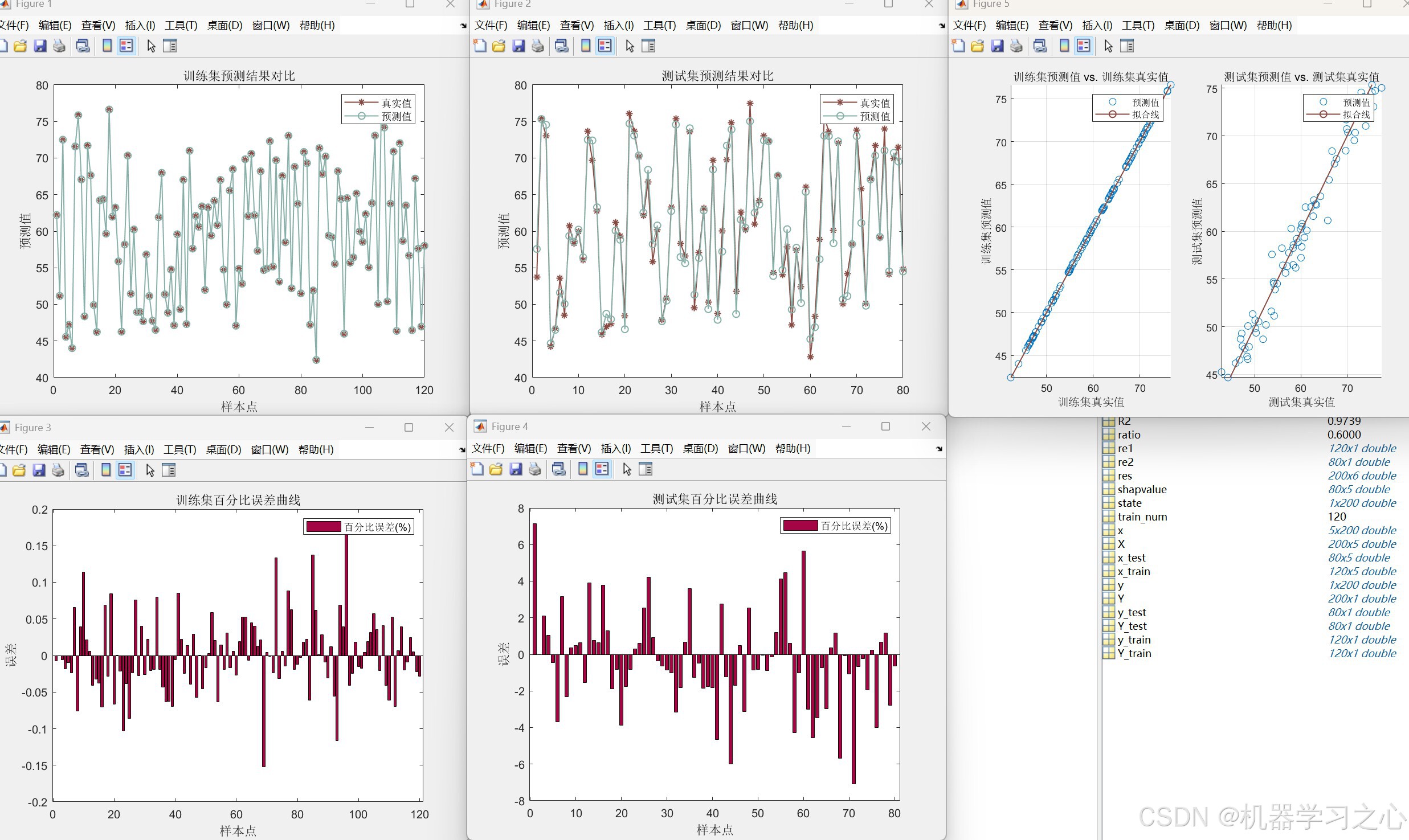
fitrensemble函数构建基于LSBoost的决策树集成模型,预测目标变量。 - 模型评估:计算训练集与测试集的R²、MAE、RMSE,并绘制预测对比图、百分比误差图和散点图。
- 新数据预测:对新的输入数据进行归一化、预测和反归一化,并保存结果。
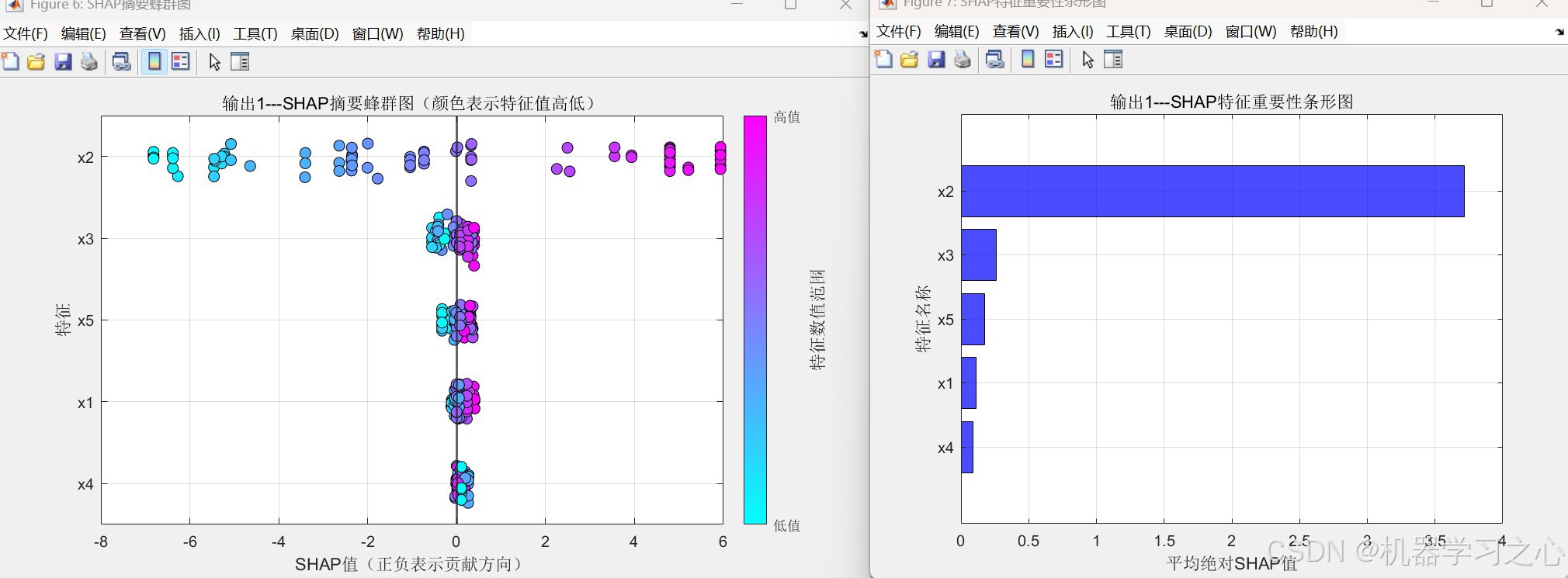
- SHAP值计算与可视化:针对每个输出(支持多输出),计算各样本每个特征的SHAP值,绘制蜂群图(展示SHAP值分布及特征值影响)和条形图(展示全局特征重要性)。
3. 算法步骤
3.1 数据预处理与建模
- 导入数据 :
xlsread读取Excel文件,最后一列为目标Y,其余为特征X;特征名从第一行获取。 - 归一化 :
mapminmax将X和Y归一化到0,1区间,保存归一化参数psin和psout。 - 划分数据集:按用户选择决定是否打乱样本,60%作为训练集,40%作为测试集。
- 模型训练 :调用
fitrensemble(x_train, y_train, 'Method', 'LSBoost', 'Learners', 'tree', 'LearnRate', 0.2, 'NumLearningCycles', 100),训练一个包含100棵决策树的LSBoost集成模型。 - 预测与反归一化 :用训练好的模型预测训练集和测试集,通过
mapminmax('reverse')恢复原始量纲。 - 评估指标:计算RMSE、R²、MAE,并绘制多种图形(对比图、误差图、散点图)。
3.2 SHAP值计算与可视化(shapley_function.m)
- 初始化 :获取测试样本数
numSamples、特征数numFeatures,计算参考值(各特征的均值)作为基线。 - 逐样本逐特征计算Shapley值 :
- 对于每个样本
i和每个特征j,考虑所有不包含j的特征子集S。 - 对于每个子集
S,构造两个输入:- 包含特征
j的输入:特征j用真实值,S中的特征用真实值,其余特征用参考值; - 不包含特征
j的输入:特征j用参考值,S中的特征用真实值,其余特征用参考值。
- 包含特征
- 分别用模型预测得到
predWith和predWithout,计算边际贡献predWith - predWithout。 - 根据Shapley公式加权累加:贡献除以组合数
nchoosek(numFeatures-1, |S|)(等价于权重(|S|!(numFeatures-|S|-1)!)/numFeatures!)。 - 最终累加值即为特征
j在该样本上的SHAP值。
- 对于每个样本
- 可视化 :
- 蜂群图:每个特征对应一组散点,横坐标为SHAP值,纵坐标按平均绝对SHAP值排序,颜色表示特征原始值的高低(归一化后)。
- 条形图:按平均绝对SHAP值绘制水平条形图,展示全局特征重要性。
- 输出:打印各特征的平均绝对SHAP值。
4. 技术路线
- 建模:集成学习(LSBoost + 决策树)提供高精度回归预测。
- 解释性:SHAP方法对黑箱模型进行事后解释,量化特征贡献,增强模型可信度。
- 流程:数据预处理 → 模型训练 → 评估 → SHAP计算 → 可视化。
5. 公式原理
SHAP值的计算公式(Shapley值)为:
ϕj=∑S⊆F∖{j}∣S∣!(∣F∣−∣S∣−1)!∣F∣!fS∪{j}(xS∪{j})−fS(xS) \phi_j = \sum_{S \subseteq F \setminus \{j\}} \frac{|S|! (|F| - |S| - 1)!}{|F|!} \left f_{S \\cup \\{j\\}}(x_{S \\cup \\{j\\}}) - f_S(x_S) \\right ϕj=S⊆F∖{j}∑∣F∣!∣S∣!(∣F∣−∣S∣−1)!fS∪{j}(xS∪{j})−fS(xS)
其中:
-FFF 为所有特征的集合;
- SSS为不包含特征(j)的任意子集;
- fS(xS)f_S(x_S)fS(xS) 表示仅使用子集SSS中的特征(其他特征用基线值替代)时的模型预测;
- 权重因子确保公平分配所有特征组合的边际贡献。
代码实现中,基线值采用各特征的全局均值,通过枚举所有子集(幂集)计算加权和。
6. 参数设定
| 参数 | 值 | 说明 |
|---|---|---|
| 随机种子 | 2222 | 固定结果复现 |
| 归一化范围 | 0,1 | mapminmax的默认参数 |
| 训练集比例 | 0.6 | 总样本的60%用于训练 |
| 集成方法 | LSBoost | 最小二乘增强 |
| 基学习器 | 决策树 | 每个弱学习器为回归树 |
| 学习率 | 0.2 | 控制每棵树的贡献 |
| 学习周期 | 100 | 集成模型中树的数量 |
| SHAP计算方式 | 全枚举 | 遍历所有特征子集(复杂度随特征数指数增长) |
7. 运行环境
- 软件 :MATLAB(版本建议R2018b及以上,因使用了
fitrensemble等函数)。
8. 应用场景
该代码适用于以下场景:
- 回归预测任务:如房价预测、销量预测、工业参数预测等,需要建立精确模型。
- 模型解释需求:当需要向非技术人员解释模型决策依据,或进行特征筛选时,SHAP值可量化各特征的影响方向和强度。
- 多输出预测:代码已预留多输出支持,可应用于多目标回归问题。
- 科研与教学:用于展示集成学习与可解释性方法的结合,理解SHAP原理。