PPO(Proximal Policy Optimization,近端策略优化)是深度强化学习中最常用、最稳定的策略梯度算法之一,由OpenAI于2017年提出。此贴作为自己学习理解PPO算法的思路整理,同时与广大学习爱好者交流共勉,以下是其典型思路和核心机制整理:

1. 核心动机
解决策略梯度算法的不稳定性问题:
-
传统策略梯度(如REINFORCE、A2C)更新步长敏感:步长太小则收敛慢,步长太大则策略崩溃
-
TRPO(Trust Region Policy Optimization)通过复杂约束保证稳定性,但计算代价高
-
PPO目标:在保持TRPO稳定性的同时,实现更简单、计算更高效
2. 核心思路:限制策略变化幅度
PPO的核心是防止策略在一次更新中变化过大,避免破坏性的大幅度策略跳跃。
关键数学工具:重要性采样比率(Importance Sampling Ratio)
-
衡量新策略与旧策略在状态
选择动作
-
3. 两种主要变体
变体一:PPO-Clip(裁剪目标函数)⭐最常用
核心机制:对重要性比率进行裁剪,限制其偏离1的程度
目标函数:
-
-
-
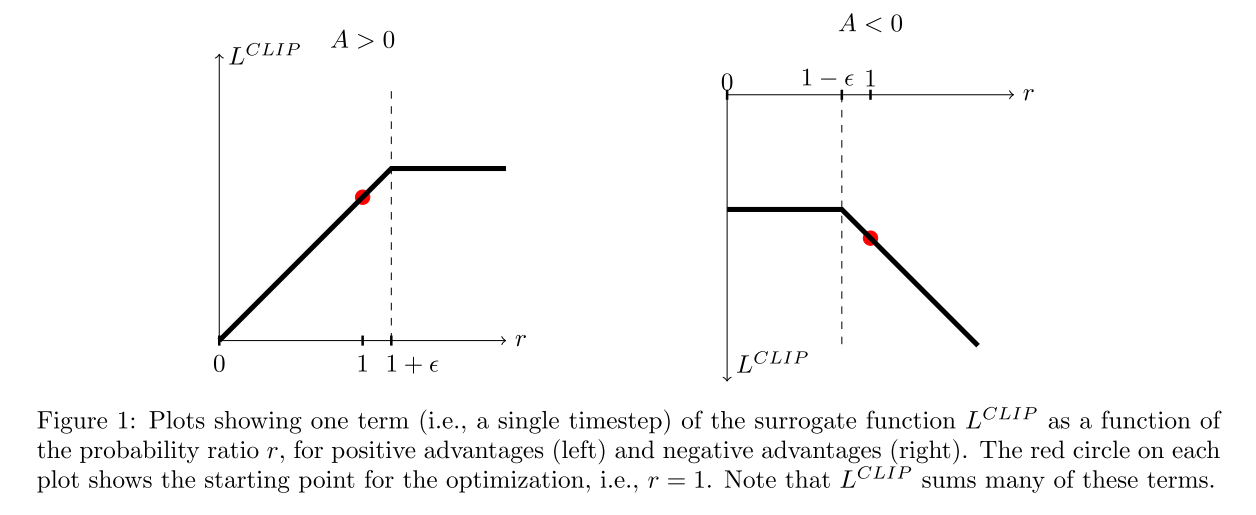
Clip操作 :将
直观理解:
-
当优势为正(
-
当优势为负(
-
取min确保取的是更悲观/保守的估计,防止过度乐观
变体二:PPO-Penalty(惩罚目标函数)
在目标函数中加入KL散度惩罚项:
-
自适应调整
-
实践中不如Clip版本稳定,使用较少
算法流程
1. 初始化策略网络 π_θ 和价值网络 V_φ
2. 使用当前策略收集N条轨迹数据(经验)
3. 计算每个时间步的回报和优势函数(通常用GAE)
4. 进行K轮优化(通常3-10轮):
- 在收集的数据上进行小批量随机梯度上升
- 最大化 L^CLIP(θ)
- 同时更新价值网络最小化价值误差
5. 用新策略替换旧策略,清空缓冲区
6. 重复步骤2-5直到收敛4. 关键技术细节
| 技术 | 作用 |
|---|---|
| GAE(Generalized Advantage Estimation) | 平衡偏差与方差的优势估计 |
| 多轮优化(Multiple Epochs) | 充分利用采集的数据,提高样本效率 |
| 小批量更新(Mini-batch) | 稳定梯度估计 |
| 价值函数裁剪 | 可选,对价值更新也做类似限制 |
| 熵正则化 | 鼓励探索,防止策略过早收敛到确定性 |
5. 与相关算法的对比
| 算法 | 核心机制 | 计算复杂度 | 稳定性 |
|---|---|---|---|
| TRPO | KL散度约束 + 共轭梯度 | 高 | 高 |
| PPO | Clip裁剪 | 低(普通梯度下降) | 高 |
| A2C/A3C | 无约束 | 低 | 中 |
| ACKTR | Kronecker因子化信任域 | 中 | 中高 |
总结
近端策略优化(proximal policy optimization)是一系列策略优化方法,使用随机梯度上升来执行每次策略更新。这种方法具有信任域方法的稳定性和可靠性,但实现起来要简单得多,只需要将几行代码更改为策略梯度实现,适用于更一般的设置(例如,当使用策略和值函数的联合架构时),并且具有更好的整体性能。
内容引用自
Schulman, John, et al. "Proximal policy optimization algorithms." arXiv preprint arXiv:1707.06347 (2017).