一、算法概述
本文基于Q-learning离线强化学习 ,实现三维栅格环境下无人机无碰撞、最短路径、最少步数 路径规划。无人机具备1格/2格三维全向移动、对角线飞行、悬停 能力,通过与环境交互迭代学习最优策略,以到达终点、路径距离、移动步数、避障为核心目标,输出满足约束的最优飞行路径。
二、环境与核心建模
1. 三维状态空间
将无人机飞行空间离散化为三维栅格地图,状态定义为无人机坐标:
S={(x,y,z)∣1≤x≤Xmax, 1≤y≤Ymax, 1≤z≤Zmax} S = \left\{ (x,y,z) \mid 1 \le x \le X_{max},\ 1 \le y \le Y_{max},\ 1 \le z \le Z_{max} \right\} S={(x,y,z)∣1≤x≤Xmax, 1≤y≤Ymax, 1≤z≤Zmax}
- (x,y,z)(x,y,z)(x,y,z):无人机空间位置
- Xmax,Ymax,ZmaxX_{max},Y_{max},Z_{max}Xmax,Ymax,Zmax:地图边界(代码中为10×10×1010 \times 10 \times 1010×10×10)
2. 动作空间(代码实现)
共54种动作,包含:
- 6个轴向1格移动、12个平面斜向1格移动、8个空间斜向1格移动
- 6个轴向2格移动、12个平面斜向2格移动、8个空间斜向2格移动
- 1个悬停动作 (0,0,0)(0,0,0)(0,0,0)
动作集合:
A={(Δx,Δy,Δz)∣Δx,Δy,Δz∈{−2,−1,0,1,2}, 非全零}∪{(0,0,0)} A = \{ (\Delta x,\Delta y,\Delta z) \mid \Delta x,\Delta y,\Delta z \in \{-2,-1,0,1,2\},\ 非全零 \} \cup \{ (0,0,0) \} A={(Δx,Δy,Δz)∣Δx,Δy,Δz∈{−2,−1,0,1,2}, 非全零}∪{(0,0,0)}
3. 约束条件
- 边界约束:坐标必须在地图范围内
- 避障约束:禁止进入障碍物坐标
- 目标约束 :从起点(2,2,2)(2,2,2)(2,2,2)到达终点(9,9,8)(9,9,8)(9,9,8)
三、Q-learning核心数学原理
1. Q值函数
Q(s,a)Q(s,a)Q(s,a) 表示状态sss下执行动作aaa的长期累积奖励期望,是算法核心决策依据:
Q(s,a)←Q(s,a)+α⋅R(s,a)+γ⋅maxa′Q(s′,a′)−Q(s,a) Q(s,a) \leftarrow Q(s,a) + \alpha \cdot \left R(s,a) + \\gamma \\cdot \\max_{a'} Q(s',a') - Q(s,a) \\right Q(s,a)←Q(s,a)+α⋅R(s,a)+γ⋅a′maxQ(s′,a′)−Q(s,a)
参数定义:
- α\alphaα:学习率,控制更新步长(代码中动态衰减:0.25→0.050.25 \to 0.050.25→0.05)
- γ\gammaγ:折扣因子,权衡远期奖励(代码中γ=0.99\gamma=0.99γ=0.99)
- R(s,a)R(s,a)R(s,a):即时奖励
- s′s's′:执行动作后的新状态
- maxQ(s′,a′)\max Q(s',a')maxQ(s′,a′):下一状态最优动作价值
2. 动作选择策略
采用**ε\varepsilonε-贪心策略+动态衰减**,平衡探索与利用:
π(a∣s)={argmaxaQ(s,a)概率 1−ε(利用最优策略)随机合法动作概率 ε(探索未知环境) \pi(a|s)= \begin{cases} \arg\max\limits_a Q(s,a) & 概率\ 1-\varepsilon(利用最优策略)\\ 随机合法动作 & 概率\ \varepsilon(探索未知环境) \end{cases} π(a∣s)={argamaxQ(s,a)随机合法动作概率 1−ε(利用最优策略)概率 ε(探索未知环境)
ε\varepsilonε 随训练指数衰减:ε=max(εmin, ε0⋅e−0.007⋅episode)\varepsilon = \max(\varepsilon_{min},\ \varepsilon_0 \cdot e^{-0.007 \cdot episode})ε=max(εmin, ε0⋅e−0.007⋅episode)
四、奖励函数Reward设计
本算法以路径最短、无碰撞、必达终点、步数最少为目标,奖励函数分4类场景设计:
1. 奖励函数数学表达式
R(s,a)={3500−15⋅dstep−5⋅Nstep到达终点−1500碰撞障碍物/越界30⋅(dcur−dnext)−10⋅dstep−2⋅Nstep−10悬停30⋅(dcur−dnext)−10⋅dstep−2⋅Nstep正常飞行 R(s,a)= \begin{cases} 3500 - 15 \cdot d_{step} - 5 \cdot N_{step} & \text{到达终点}\\ -1500 & \text{碰撞障碍物/越界}\\ 30 \cdot (d_{cur}-d_{next}) -10 \cdot d_{step} -2 \cdot N_{step} -10 & \text{悬停}\\ 30 \cdot (d_{cur}-d_{next}) -10 \cdot d_{step} -2 \cdot N_{step} & \text{正常飞行} \end{cases} R(s,a)=⎩ ⎨ ⎧3500−15⋅dstep−5⋅Nstep−150030⋅(dcur−dnext)−10⋅dstep−2⋅Nstep−1030⋅(dcur−dnext)−10⋅dstep−2⋅Nstep到达终点碰撞障碍物/越界悬停正常飞行
2. 奖励项详细介绍
-
到达终点(最高奖励)
- 基础奖励:+3500+3500+3500,保证无人机优先到达目标
- 惩罚项:单步距离越长、总步数越多,奖励越低,强制最短路径+最少步数
-
碰撞障碍物/越界(最高惩罚)
- 惩罚:−1500-1500−1500,让无人机彻底学会避障,杜绝碰撞
-
悬停动作(额外惩罚)
- 惩罚:−10-10−10,避免无人机无效停留,提升飞行效率
-
正常飞行(启发式引导)
- 靠近终点:+30⋅(dcur−dnext)+30 \cdot (d_{cur}-d_{next})+30⋅(dcur−dnext),距离缩短越多奖励越高
- 远离终点:自动产生负奖励,引导无人机向目标飞行
- 距离惩罚:−10⋅dstep-10 \cdot d_{step}−10⋅dstep,飞行距离越长惩罚越高
- 步数惩罚:−2⋅Nstep-2 \cdot N_{step}−2⋅Nstep,步数越多惩罚越高
3. 奖励设计核心目标
✅ 无人机必须到达终点
✅ 无人机绝对不碰撞障碍物
✅ 飞行路径欧氏距离最小
✅ 飞行移动步数最少
✅ 禁止无效悬停,提升飞行效率
五、算法步骤
阶段1:参数初始化
- 初始化三维地图、起点、终点、障碍物坐标
- 定义54种移动动作+1种悬停动作
- 初始化四维Q表:Q(Xmax,Ymax,Zmax,A)=0Q(X_{max},Y_{max},Z_{max},A) = 0Q(Xmax,Ymax,Zmax,A)=0
- 设置超参数:α,γ,ε\alpha,\gamma,\varepsilonα,γ,ε、训练轮数、最大步长
阶段2:Q-learning训练迭代
for 每一轮训练 episode = 1:max_episode
动态衰减学习率α和探索率ε
无人机重置到起点,清空路径、奖励、步数
for 每一步飞行 step = 1:max_step
1. 动作剪枝:剔除越界、碰撞障碍物的无效动作
2. ε-贪心策略选择最优/随机动作
3. 执行动作,得到新状态s'
4. 计算即时奖励R(核心:避障+距离+步数+终点)
5. 更新Q值:Q(s,a) ← Q(s,a)+α[R+γ·maxQ(s',a')−Q(s,a)]
6. 判断终止:到达终点/碰撞/越界
7. 更新状态、累计奖励、飞行路径
end
计算本轮总距离、总步数、总奖励并保存
end阶段3:最优路径规划
- 加载训练完成的Q表
- 从起点出发,每一步选择Q(s,a)Q(s,a)Q(s,a)最大的动作
- 严格校验边界与障碍物,保证无碰撞
- 到达终点后,输出最优路径、总步数、总距离
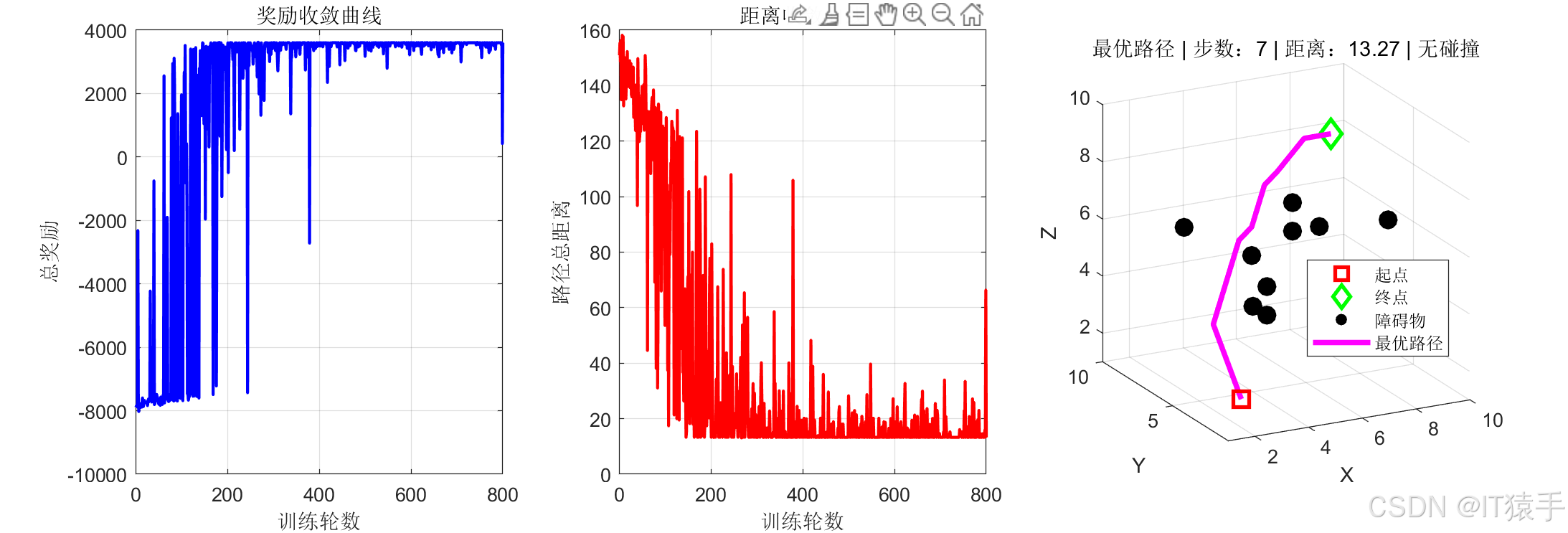
阶段4:结果可视化
- 绘制奖励收敛曲线
- 绘制路径距离收敛曲线
- 绘制三维最优路径、起点、终点、障碍物
六、部分MATLAB代码及结果
bash
% 最终结果
final_steps = size(path,1)-1;
final_dist = 0;
for i = 1:final_steps
final_dist = final_dist + norm(path(i+1,:)-path(i,:));
end
fprintf('\n=========================================\n');
fprintf(' 最优步数:%d 步\n', final_steps);
fprintf(' 最短距离:%.4f\n', final_dist);
fprintf(' 避障状态:无碰撞\n');
fprintf('=========================================\n');
%% 绘图
figure('Color','w','Position',[80,80,1200,380]);
subplot(1,3,1); plot(1:max_episode, reward_curve, 'b-','LineWidth',1.6);
xlabel('训练轮数'); ylabel('总奖励'); title('奖励收敛曲线'); grid on;
subplot(1,3,2); plot(1:max_episode, episode_path_distance, 'r-','LineWidth',1.6);
xlabel('训练轮数'); ylabel('路径总距离'); title('距离收敛曲线'); grid on;
subplot(1,3,3); hold on; grid on; axis equal; view(3);
xlabel('X'); ylabel('Y'); zlabel('Z');
title(sprintf('最优路径 | 步数:%d | 距离:%.2f | 无碰撞',final_steps,final_dist));
xlim([1 x_max]); ylim([1 y_max]); zlim([1 z_max]);
plot3(start_state(1),start_state(2),start_state(3),'rs','MarkerSize',11,'LineWidth',2);
plot3(end_state(1),end_state(2),end_state(3),'gd','MarkerSize',11,'LineWidth',2);
scatter3(obstacle(:,1),obstacle(:,2),obstacle(:,3),100,'k','filled');
plot3(path(:,1),path(:,2),path(:,3),'m-','LineWidth',2.8,'MarkerSize',5);
legend('起点','终点','障碍物','最优路径','Location','best');