为什么需要分层记忆系统
大语言模型的记忆困境
当前的主流大语言模型(如GPT系列、LLaMA等)虽然在单轮对话中表现出色,但在处理多轮、长程对话任务时,面临严重的记忆衰减 和上下文长度限制问题。传统的做法是将整个对话历史作为上下文输入,但这会带来几个关键问题:
-
计算成本指数增长:Transformer架构的自注意力机制计算复杂度为O(n²),随着上下文长度增加,计算资源和时间成本急剧上升。
-
信息稀释效应:重要信息可能被淹没在海量对话历史中,模型难以准确提取关键记忆。
-
缺乏记忆持久性:对话结束后,所有记忆随之消失,无法形成长期用户画像和偏好理解。
生活化案例:智能私人助手的记忆需求
想象一个智能私人助手,例如帮助管理日程、健康、学习的AI伙伴:
-
短期:记住你今天提到的会议时间变更
-
中期:了解你每周三晚上有健身习惯
-
长期:知道你对海鲜过敏,偏好早睡早起
传统模型每次对话都需要重新"学习"这些信息,而人类自然对话中,这些记忆是分层存储、按需提取的。这正是Mem0系统要解决的核心问题。(扩展阅读:Mem0:AI智能体的记忆革命------从临时对话到持久化认知伙伴)
传统记忆机制的局限与演进
早期方法:完整历史上下文
python
# 传统方法:将整个对话历史作为输入
def traditional_chat(context, new_query):
# context包含所有历史对话
full_input = context + "\n用户: " + new_query
response = model.generate(full_input)
return response问题:
-
受限于模型的上下文窗口(如4K、8K、32K tokens)
-
重要信息可能被稀释
-
计算效率低下
演进:向量存储与检索
python
# 向量检索方法
from sentence_transformers import SentenceTransformer
import numpy as np
class VectorMemory:
def __init__(self):
self.encoder = SentenceTransformer('all-MiniLM-L6-v2')
self.memories = []
self.embeddings = []
def store(self, text):
embedding = self.encoder.encode(text)
self.memories.append(text)
self.embeddings.append(embedding)
def retrieve(self, query, top_k=5):
query_embedding = self.encoder.encode(query)
similarities = np.dot(self.embeddings, query_embedding.T)
indices = np.argsort(similarities)[-top_k:]
return [self.memories[i] for i in indices]改进:
-
突破了上下文长度限制
-
实现了相似性检索
局限:
-
缺乏时间维度理解
-
没有信息重要性分级
-
记忆之间缺乏关联性
现有技术的核心痛点
-
记忆扁平化:所有记忆同等对待,没有重要性分层
-
时间感知缺失:无法理解记忆的时间相关性和衰减规律
-
缺乏结构化:记忆之间孤立存在,没有形成知识图谱
-
更新机制粗糙:简单的添加/删除,缺乏动态权重调整
Mem0分层记忆系统的核心架构
架构概览
Mem0采用四层记忆架构,模仿人类记忆的存储和检索机制:
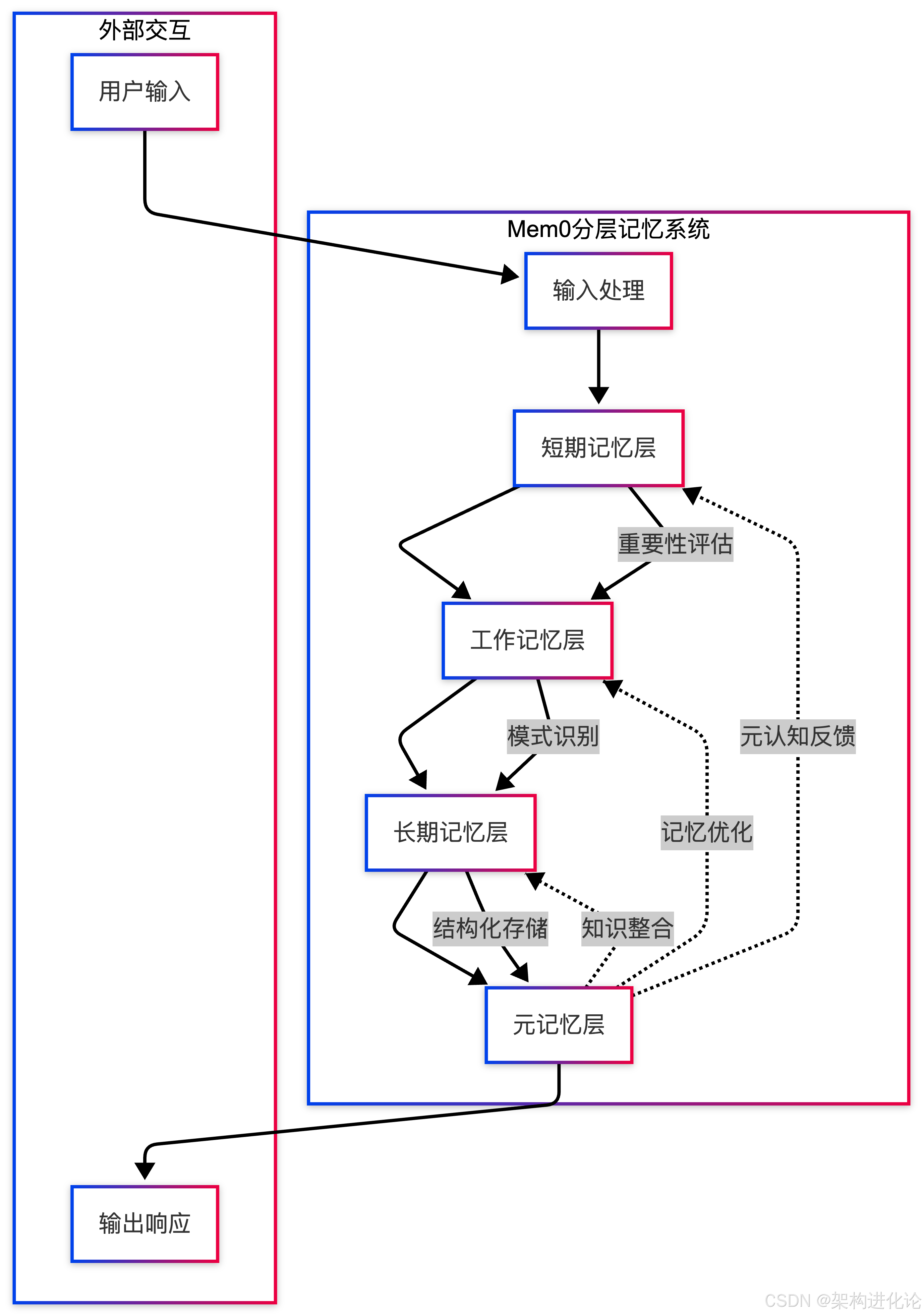
各层功能详解
短期记忆层(Short-term Memory)
-
功能:临时存储最近交互信息
-
容量:有限,遵循最近性原则
-
保留时间:分钟到小时级别
-
示例:刚提到的餐厅名称、临时的任务指令
工作记忆层(Working Memory)
-
功能:主动处理当前任务相关信息
-
特点:选择性注意、信息整合
-
示例:正在讨论的旅行计划细节、当前对话主题
长期记忆层(Long-term Memory)
-
功能:持久化存储重要信息
-
结构:分层索引、关联网络
-
示例:用户偏好、重要事实、长期目标
元记忆层(Meta-memory)
-
功能:管理记忆系统自身
-
职责:记忆评估、优化策略、遗忘机制
-
示例:识别哪些信息应该强化、哪些应该遗忘
记忆流动机制
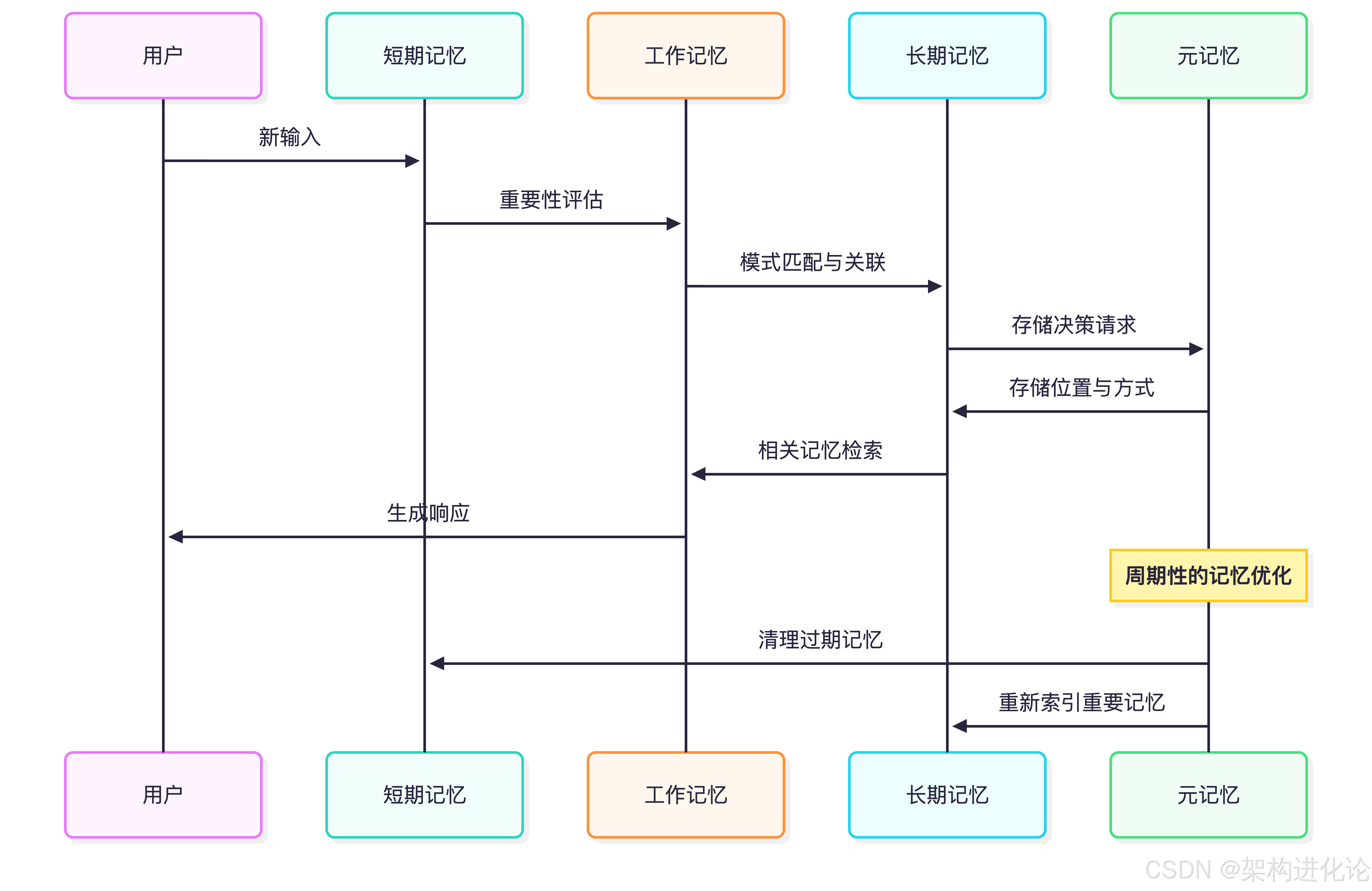
技术实现原理深度解析
记忆表示与编码
Mem0采用混合表示策略,结合文本、向量、图结构等多种表示方式:
python
from dataclasses import dataclass
from typing import List, Dict, Any, Optional
from datetime import datetime
import hashlib
import json
@dataclass
class MemoryChunk:
"""记忆块基础数据结构"""
id: str # 唯一标识符
content: str # 原始内容
embedding: List[float] # 向量表示
metadata: Dict[str, Any] # 元数据
importance_score: float # 重要性评分 0-1
access_count: int # 访问次数
last_accessed: datetime # 最后访问时间
created_at: datetime # 创建时间
decay_factor: float # 衰减因子
# 关联记忆
related_memories: List[str] # 相关记忆ID列表
memory_type: str # 记忆类型
def __post_init__(self):
"""初始化唯一ID"""
if not self.id:
content_hash = hashlib.md5(self.content.encode()).hexdigest()
timestamp = datetime.now().strftime("%Y%m%d%H%M%S")
self.id = f"{content_hash}_{timestamp}"
def update_access(self):
"""更新访问记录"""
self.access_count += 1
self.last_accessed = datetime.now()
def calculate_decay(self, current_time: datetime) -> float:
"""计算记忆衰减程度"""
hours_since_access = (current_time - self.last_accessed).total_seconds() / 3600
# 衰减公式:重要性越高,衰减越慢
decay_rate = 0.1 * (1 - self.importance_score)
decay = 1.0 - decay_rate * hours_since_access
return max(decay, 0) # 确保不小于0重要性评分算法
记忆的重要性不是静态的,而是动态评估的:
python
class ImportanceScorer:
"""重要性评分器"""
def __init__(self, model):
self.model = model # 用于分析语义重要性的模型
def calculate_importance(self, text: str, context: Dict[str, Any]) -> float:
"""
计算文本在给定上下文中的重要性
参数:
- text: 待评分的文本
- context: 包含对话历史、用户信息等上下文
返回:
- 重要性评分 (0-1)
"""
# 1. 基础特征提取
features = self._extract_features(text, context)
# 2. 多维度评分
scores = {
'relevance': self._calculate_relevance(text, context),
'specificity': self._calculate_specificity(text),
'emotional_weight': self._calculate_emotional_weight(text),
'actionable_content': self._calculate_actionable_content(text),
'novelty': self._calculate_novelty(text, context)
}
# 3. 加权综合评分
weights = {
'relevance': 0.25,
'specificity': 0.20,
'emotional_weight': 0.15,
'actionable_content': 0.25,
'novelty': 0.15
}
total_score = sum(scores[key] * weights[key] for key in scores)
# 4. 时间衰减调整
if 'timestamp' in context:
time_elapsed = (datetime.now() - context['timestamp']).total_seconds() / 3600
time_factor = max(0, 1 - time_elapsed * 0.01) # 每小时衰减1%
total_score *= time_factor
return min(max(total_score, 0), 1) # 确保在0-1范围内
def _extract_features(self, text: str, context: Dict) -> Dict:
"""提取文本特征"""
features = {
'length': len(text.split()),
'contains_numbers': any(char.isdigit() for char in text),
'contains_dates': self._extract_dates(text),
'contains_names': self._extract_entities(text, 'PERSON'),
'contains_locations': self._extract_entities(text, 'GPE'),
'question_type': self._classify_question(text) if '?' in text else None
}
return features
def _calculate_relevance(self, text: str, context: Dict) -> float:
"""计算与当前话题的相关性"""
current_topic = context.get('current_topic', '')
if not current_topic:
return 0.5
# 使用语义相似度计算相关性
topic_embedding = self._get_embedding(current_topic)
text_embedding = self._get_embedding(text)
similarity = self._cosine_similarity(topic_embedding, text_embedding)
return similarity
def _calculate_specificity(self, text: str) -> float:
"""计算信息特异性(与通用信息相比)"""
# 简单的启发式方法:包含具体细节的文本更特异
specificity_indicators = [
r'\d+', # 数字
r'[A-Z][a-z]+ [A-Z][a-z]+', # 全名
r'\b(?:January|February|March|April|May|June|July|August|September|October|November|December)\b',
r'\b(?:Monday|Tuesday|Wednesday|Thursday|Friday|Saturday|Sunday)\b',
r'\b(?:AM|PM)\b'
]
import re
matches = 0
for pattern in specificity_indicators:
if re.search(pattern, text):
matches += 1
return min(matches / len(specificity_indicators), 1.0)
# ... 其他评分方法的实现记忆检索与关联机制
python
class MemoryRetrievalSystem:
"""记忆检索系统"""
def __init__(self, memory_store, embedding_model):
self.memory_store = memory_store
self.embedding_model = embedding_model
self.index = self._build_index()
def _build_index(self):
"""构建记忆索引"""
# 多级索引结构
index = {
'temporal': {}, # 时间索引
'semantic': {}, # 语义索引
'associative': {}, # 关联索引
'importance': {} # 重要性索引
}
for memory in self.memory_store.get_all_memories():
# 时间索引(按天分组)
day_key = memory.created_at.strftime("%Y-%m-%d")
if day_key not in index['temporal']:
index['temporal'][day_key] = []
index['temporal'][day_key].append(memory.id)
# 重要性索引(分级存储)
importance_level = self._get_importance_level(memory.importance_score)
if importance_level not in index['importance']:
index['importance'][importance_level] = []
index['importance'][importance_level].append(memory.id)
return index
def retrieve_memories(self, query: str, context: Dict, top_k: int = 10) -> List[MemoryChunk]:
"""
检索相关记忆
参数:
- query: 检索查询
- context: 检索上下文
- top_k: 返回的记忆数量
返回:
- 相关记忆列表
"""
# 1. 多策略并行检索
strategies = [
self._semantic_retrieval,
self._temporal_retrieval,
self._associative_retrieval,
self._importance_based_retrieval
]
all_candidates = []
for strategy in strategies:
candidates = strategy(query, context)
all_candidates.extend(candidates)
# 2. 去重与排序
unique_candidates = self._deduplicate(all_candidates)
# 3. 综合评分排序
scored_candidates = []
for memory in unique_candidates:
score = self._calculate_retrieval_score(memory, query, context)
scored_candidates.append((score, memory))
# 4. 返回top_k结果
scored_candidates.sort(key=lambda x: x[0], reverse=True)
return [memory for _, memory in scored_candidates[:top_k]]
def _semantic_retrieval(self, query: str, context: Dict) -> List[MemoryChunk]:
"""基于语义相似度的检索"""
query_embedding = self.embedding_model.encode(query)
candidates = []
for memory in self.memory_store.get_all_memories():
# 计算余弦相似度
similarity = self._cosine_similarity(query_embedding, memory.embedding)
# 考虑记忆衰减
decay = memory.calculate_decay(datetime.now())
# 综合评分
score = similarity * decay * memory.importance_score
if score > 0.3: # 阈值
candidates.append((score, memory))
# 按分数排序
candidates.sort(key=lambda x: x[0], reverse=True)
return [memory for _, memory in candidates[:20]]
def _temporal_retrieval(self, query: str, context: Dict) -> List[MemoryChunk]:
"""基于时间相关性的检索"""
# 识别查询中的时间信息
time_references = self._extract_time_references(query)
candidates = []
for time_ref in time_references:
# 查找相近时间点的记忆
nearby_memories = self._find_nearby_memories(time_ref)
candidates.extend(nearby_memories)
return candidates
def _associative_retrieval(self, query: str, context: Dict) -> List[MemoryChunk]:
"""基于关联网络的检索"""
# 查找当前上下文中活跃的记忆
active_memories = context.get('active_memories', [])
candidates = []
for memory_id in active_memories:
memory = self.memory_store.get_memory(memory_id)
if memory:
# 获取关联记忆
related = memory.related_memories
for related_id in related:
related_memory = self.memory_store.get_memory(related_id)
if related_memory:
candidates.append(related_memory)
return candidates
def _calculate_retrieval_score(self, memory: MemoryChunk, query: str, context: Dict) -> float:
"""计算记忆检索的综合评分"""
scores = []
# 1. 语义相关性
query_embedding = self.embedding_model.encode(query)
semantic_score = self._cosine_similarity(query_embedding, memory.embedding)
scores.append(('semantic', semantic_score, 0.4))
# 2. 时间相关性
time_score = self._calculate_time_relevance(memory, context)
scores.append(('temporal', time_score, 0.2))
# 3. 重要性
importance_score = memory.importance_score
scores.append(('importance', importance_score, 0.2))
# 4. 访问频率
recency_score = min(memory.access_count / 100, 1.0) # 归一化
scores.append(('recency', recency_score, 0.1))
# 5. 衰减程度
decay = memory.calculate_decay(datetime.now())
scores.append(('freshness', decay, 0.1))
# 加权求和
total_score = sum(weight * score for _, score, weight in scores)
return total_score记忆整合与压缩算法
长期记忆中的信息需要定期整合和压缩,防止记忆爆炸:
python
class MemoryConsolidation:
"""记忆整合与压缩系统"""
def __init__(self, memory_store, llm_model):
self.memory_store = memory_store
self.llm_model = llm_model
def consolidate_memories(self, consolidation_threshold: float = 0.8):
"""
整合相似记忆
参数:
- consolidation_threshold: 整合阈值(相似度高于此值的记忆将被合并)
"""
# 1. 聚类相似记忆
clusters = self._cluster_memories(consolidation_threshold)
for cluster in clusters:
if len(cluster) > 1:
# 2. 合并相似记忆
consolidated_memory = self._merge_cluster(cluster)
# 3. 更新存储
self._update_memory_store(cluster, consolidated_memory)
def _cluster_memories(self, threshold: float) -> List[List[MemoryChunk]]:
"""聚类相似记忆"""
all_memories = self.memory_store.get_all_memories()
# 基于相似度的聚类
clusters = []
visited = set()
for i, memory in enumerate(all_memories):
if memory.id in visited:
continue
cluster = [memory]
visited.add(memory.id)
# 查找相似记忆
for j, other_memory in enumerate(all_memories[i+1:], start=i+1):
if other_memory.id in visited:
continue
similarity = self._calculate_memory_similarity(memory, other_memory)
if similarity > threshold:
cluster.append(other_memory)
visited.add(other_memory.id)
clusters.append(cluster)
return clusters
def _merge_cluster(self, cluster: List[MemoryChunk]) -> MemoryChunk:
"""合并聚类中的记忆"""
# 使用LLM提取关键信息并生成摘要
cluster_contents = [memory.content for memory in cluster]
prompt = f"""
请将以下多条相关信息整合成一条简洁、全面的记忆:
原始信息:
{chr(10).join(f'- {content}' for content in cluster_contents)}
整合后的记忆应该:
1. 保留所有重要细节
2. 消除冗余信息
3. 保持信息的准确性和完整性
4. 不超过100个词
整合后的记忆:
"""
# 调用LLM生成整合记忆
response = self.llm_model.generate(prompt)
# 计算合并后的重要性评分(取最大值)
max_importance = max(memory.importance_score for memory in cluster)
# 创建新的记忆块
consolidated_memory = MemoryChunk(
content=response,
importance_score=max_importance,
memory_type='consolidated'
)
# 继承所有相关记忆的关联
all_related = set()
for memory in cluster:
all_related.update(memory.related_memories)
consolidated_memory.related_memories = list(all_related)
return consolidated_memory实现案例:构建智能对话助手
系统架构设计
核心实现代码
python
class Mem0ChatAssistant:
"""基于Mem0的智能对话助手"""
def __init__(self, config: Dict[str, Any]):
# 初始化组件
self.config = config
self.llm_model = self._load_llm_model(config['model_path'])
self.embedding_model = self._load_embedding_model(config['embedding_model'])
# 初始化记忆系统
self.memory_store = MemoryStore()
self.short_term_memory = ShortTermMemory(
capacity=config.get('short_term_capacity', 20),
decay_rate=config.get('short_term_decay', 0.1)
)
self.working_memory = WorkingMemory(
attention_mechanism=config.get('attention_mechanism', 'transformer')
)
self.long_term_memory = LongTermMemory(
memory_store=self.memory_store,
consolidation_interval=config.get('consolidation_interval', 3600)
)
self.meta_memory = MetaMemory(
optimization_strategy=config.get('optimization_strategy', 'adaptive')
)
# 初始化检索系统
self.retrieval_system = MemoryRetrievalSystem(
memory_store=self.memory_store,
embedding_model=self.embedding_model
)
# 初始化对话状态
self.conversation_state = {
'current_topic': None,
'active_memories': [],
'user_profile': {},
'conversation_history': []
}
def process_message(self, user_message: str, user_id: str) -> str:
"""
处理用户消息的核心流程
参数:
- user_message: 用户消息
- user_id: 用户标识
返回:
- 助手回复
"""
# 步骤1:上下文准备
context = self._prepare_context(user_message, user_id)
# 步骤2:记忆检索与激活
retrieved_memories = self._retrieve_and_activate_memories(user_message, context)
# 步骤3:工作记忆处理
processed_info = self.working_memory.process(
user_message=user_message,
retrieved_memories=retrieved_memories,
context=context
)
# 步骤4:生成响应
response = self._generate_response(
user_message=user_message,
working_memory_content=processed_info,
context=context
)
# 步骤5:记忆存储与更新
self._store_new_memories(
user_message=user_message,
assistant_response=response,
context=context,
importance_scores=processed_info.get('importance_scores', {})
)
# 步骤6:记忆优化(异步)
self._optimize_memories_async(user_id)
# 步骤7:更新对话状态
self._update_conversation_state(
user_message=user_message,
assistant_response=response,
context=context
)
return response
def _prepare_context(self, user_message: str, user_id: str) -> Dict[str, Any]:
"""准备对话上下文"""
context = {
'user_id': user_id,
'current_time': datetime.now(),
'conversation_history': self.conversation_state['conversation_history'][-10:], # 最近10轮
'user_profile': self.conversation_state['user_profile'].copy(),
'current_topic': self.conversation_state['current_topic'],
'active_memories': self.conversation_state['active_memories'].copy()
}
# 分析用户消息的意图和实体
intent = self._classify_intent(user_message)
entities = self._extract_entities(user_message)
context.update({
'intent': intent,
'entities': entities,
'message_length': len(user_message.split()),
'contains_question': '?' in user_message
})
return context
def _retrieve_and_activate_memories(self, query: str, context: Dict) -> List[MemoryChunk]:
"""检索并激活相关记忆"""
# 1. 从各层记忆检索
short_term_memories = self.short_term_memory.retrieve(query, context)
long_term_memories = self.retrieval_system.retrieve_memories(query, context)
# 2. 合并并去重
all_memories = short_term_memories + long_term_memories
unique_memories = self._deduplicate_memories(all_memories)
# 3. 激活相关记忆(更新访问记录)
for memory in unique_memories:
memory.update_access()
# 如果记忆重要性足够高,存入工作记忆
if memory.importance_score > 0.7:
self.working_memory.activate_memory(memory)
# 4. 更新活动记忆列表
active_ids = [m.id for m in unique_memories[:5]] # 最多激活5个
self.conversation_state['active_memories'] = active_ids
return unique_memories
def _generate_response(self, user_message: str, working_memory_content: Dict, context: Dict) -> str:
"""生成助手回复"""
# 构建提示词
prompt = self._build_prompt(
user_message=user_message,
working_memory=working_memory_content,
context=context
)
# 调用LLM生成回复
response = self.llm_model.generate(prompt)
# 后处理:确保回复符合对话逻辑和记忆一致性
processed_response = self._post_process_response(
response=response,
context=context,
working_memory=working_memory_content
)
return processed_response
def _store_new_memories(self, user_message: str, assistant_response: str,
context: Dict, importance_scores: Dict):
"""存储新的记忆"""
# 创建消息记忆
message_memory = MemoryChunk(
content=f"用户说:{user_message}",
metadata={
'type': 'user_message',
'intent': context.get('intent'),
'entities': context.get('entities'),
'timestamp': datetime.now()
},
importance_score=importance_scores.get('user_message', 0.5)
)
# 创建响应记忆
response_memory = MemoryChunk(
content=f"助手回复:{assistant_response}",
metadata={
'type': 'assistant_response',
'timestamp': datetime.now(),
'related_message': message_memory.id
},
importance_score=importance_scores.get('assistant_response', 0.4)
)
# 如果包含重要信息,创建事实记忆
important_facts = self._extract_important_facts(user_message, assistant_response)
for fact in important_facts:
fact_memory = MemoryChunk(
content=fact['content'],
metadata={
'type': 'fact',
'category': fact.get('category'),
'source': 'conversation',
'confidence': fact.get('confidence', 0.8)
},
importance_score=fact.get('importance', 0.7),
memory_type='fact'
)
self.memory_store.store(fact_memory)
# 存储到短期记忆
self.short_term_memory.store(message_memory)
self.short_term_memory.store(response_memory)
# 评估是否需要存入长期记忆
if message_memory.importance_score > 0.7:
self.long_term_memory.store(message_memory)
if response_memory.importance_score > 0.6:
self.long_term_memory.store(response_memory)
def _optimize_memories_async(self, user_id: str):
"""异步优化记忆"""
# 在实际实现中,这里会启动异步任务
# 包括:记忆整合、重要性重新评估、过期记忆清理等
if self.meta_memory.should_optimize():
optimization_tasks = [
self.long_term_memory.consolidate_similar_memories,
self.meta_memory.reassess_importance_scores,
self.short_term_memory.clean_expired_memories
]
for task in optimization_tasks:
try:
task(user_id)
except Exception as e:
print(f"优化任务失败:{e}")使用示例:健康管理助手
python
# 初始化健康管理助手
health_config = {
'model_path': 'models/llm/health_specialist',
'embedding_model': 'models/embeddings/health_domain',
'short_term_capacity': 30,
'long_term_categories': ['symptoms', 'medications', 'appointments', 'lifestyle'],
'importance_weights': {
'medical_fact': 0.9,
'symptom': 0.8,
'preference': 0.6,
'casual_info': 0.3
}
}
health_assistant = Mem0ChatAssistant(health_config)
# 模拟对话
conversation = [
"用户:我最近经常感到疲劳,下午尤其明显",
"用户:我每天喝两杯咖啡,晚上12点睡觉",
"用户:上周体检发现血压有点高,140/90",
"用户:医生给我开了降压药,每天一次",
"用户:我还需要注意什么吗?"
]
# 处理对话
user_profile = {}
for i, message in enumerate(conversation):
print(f"\n--- 第{i+1}轮对话 ---")
print(f"输入:{message}")
response = health_assistant.process_message(
user_message=message.split(":")[1],
user_id="patient_001"
)
print(f"助手:{response}")
# 展示记忆状态
if i == len(conversation) - 1:
print("\n--- 记忆系统状态 ---")
print("活跃记忆:", health_assistant.conversation_state['active_memories'])
print("当前话题:", health_assistant.conversation_state['current_topic'])
# 检索相关健康建议
related_advice = health_assistant.retrieval_system.retrieve_memories(
query="降压药注意事项",
context=health_assistant.conversation_state,
top_k=3
)
print("\n相关健康建议:")
for memory in related_advice:
print(f"- {memory.content[:100]}... (重要性:{memory.importance_score:.2f})")性能评估与优化策略
评估指标
Mem0系统的性能需要从多个维度进行评估:
python
class MemorySystemEvaluator:
"""记忆系统评估器"""
@staticmethod
def evaluate_performance(memory_system, test_dataset):
"""
综合评估记忆系统性能
参数:
- memory_system: 要评估的记忆系统
- test_dataset: 测试数据集
返回:
- 评估结果字典
"""
results = {
'retrieval_accuracy': [],
'response_relevance': [],
'memory_coherence': [],
'computational_efficiency': [],
'scalability': []
}
for test_case in test_dataset:
# 1. 检索准确率评估
retrieval_acc = evaluator.evaluate_retrieval_accuracy(
memory_system, test_case['query'], test_case['expected_memories']
)
results['retrieval_accuracy'].append(retrieval_acc)
# 2. 响应相关性评估
relevance_score = evaluator.evaluate_response_relevance(
memory_system, test_case['query'], test_case['expected_response']
)
results['response_relevance'].append(relevance_score)
# 3. 记忆一致性评估
coherence_score = evaluator.evaluate_memory_coherence(
memory_system, test_case['conversation_history']
)
results['memory_coherence'].append(coherence_score)
# 计算平均得分
avg_results = {k: sum(v)/len(v) for k, v in results.items() if v}
return {
'detailed_results': results,
'average_scores': avg_results,
'overall_score': sum(avg_results.values()) / len(avg_results)
}
@staticmethod
def evaluate_retrieval_accuracy(memory_system, query, expected_memories):
"""评估记忆检索准确率"""
retrieved = memory_system.retrieve_memories(query, {})
# 计算召回率
retrieved_ids = {m.id for m in retrieved}
expected_ids = {m.id for m in expected_memories}
if not expected_ids:
return 1.0 if not retrieved_ids else 0.0
recall = len(retrieved_ids & expected_ids) / len(expected_ids)
# 计算精确率
precision = len(retrieved_ids & expected_ids) / len(retrieved_ids) if retrieved_ids else 0
# F1分数
if precision + recall == 0:
return 0
f1 = 2 * (precision * recall) / (precision + recall)
return f1优化策略
动态重要性调整
python
class DynamicImportanceOptimizer:
"""动态重要性优化器"""
def __init__(self, learning_rate=0.01, decay_factor=0.995):
self.learning_rate = learning_rate
self.decay_factor = decay_factor
self.feedback_history = []
def adjust_importance(self, memory_id: str, feedback: Dict[str, Any]):
"""
根据反馈调整记忆重要性
反馈类型:
- 'used_in_response': 记忆被用于生成响应
- 'user_positive_feedback': 用户正面反馈
- 'user_negative_feedback': 用户负面反馈
- 'contradiction_found': 发现矛盾
- 'repetition_avoided': 避免了重复信息
"""
adjustment = 0
if feedback.get('used_in_response'):
adjustment += 0.05 * feedback.get('relevance_score', 1.0)
if feedback.get('user_positive_feedback'):
adjustment += 0.1
if feedback.get('user_negative_feedback'):
adjustment -= 0.15
if feedback.get('contradiction_found'):
adjustment -= 0.2
if feedback.get('repetition_avoided'):
adjustment += 0.03
# 应用调整(带衰减)
self._apply_adjustment(memory_id, adjustment)
self._record_feedback(memory_id, feedback, adjustment)
def _apply_adjustment(self, memory_id: str, adjustment: float):
"""应用重要性调整"""
memory = self.memory_store.get_memory(memory_id)
if memory:
# 重要性评分限制在[0, 1]范围内
new_importance = max(0, min(1, memory.importance_score + adjustment))
memory.importance_score = new_importance
# 更新记忆衰减因子
memory.decay_factor = self._calculate_new_decay(new_importance)
def _calculate_new_decay(self, importance: float) -> float:
"""根据重要性计算衰减因子"""
# 重要性越高,衰减越慢
base_decay = 0.95
importance_factor = 1 - importance * 0.3 # 重要性每增加1,衰减减慢30%
return base_decay * importance_factor记忆压缩与归档
python
class MemoryCompressor:
"""记忆压缩器"""
def compress_memories(self, threshold_days: int = 30):
"""
压缩旧记忆
参数:
- threshold_days: 压缩阈值(超过此天数的记忆将被压缩)
"""
old_memories = self._get_old_memories(threshold_days)
# 按主题分组
themes = self._cluster_by_theme(old_memories)
for theme, memories in themes.items():
if len(memories) > 3: # 只有记忆数量足够多时才压缩
# 生成主题摘要
summary = self._generate_theme_summary(theme, memories)
# 创建压缩记忆
compressed_memory = MemoryChunk(
content=f"关于{theme}的总结:{summary}",
metadata={
'type': 'compressed',
'original_count': len(memories),
'compression_date': datetime.now(),
'original_ids': [m.id for m in memories]
},
importance_score=self._calculate_compressed_importance(memories),
memory_type='compressed_summary'
)
# 存储压缩记忆,归档原始记忆
self.memory_store.store(compressed_memory)
self._archive_original_memories(memories)未来展望与发展方向
技术发展趋势
多模态记忆扩展
-
整合图像、音频、视频记忆
-
跨模态记忆关联与检索
分布式记忆网络
-
跨设备记忆同步
-
联邦学习保护隐私
神经符号记忆融合
-
结合神经网络与符号推理
-
可解释的记忆决策过程(扩展阅读:可解释AI(XAI):构建透明可信人工智能的架构设计与实践)
应用场景扩展
个性化教育
-
记忆学习进度和难点
-
自适应教学内容调整
企业知识管理
-
组织记忆的积累与传承
-
团队协作记忆共享
医疗健康助手
-
长期健康数据记忆
-
病症模式识别与预警
技术挑战与解决方案
| 挑战 | 解决方案 |
|---|---|
| 记忆一致性维护 | 版本控制与冲突解决机制 |
| 隐私保护 | 差分隐私、本地化处理 |
| 计算资源优化 | 分层存储、智能缓存 |
| 记忆偏差纠正 | 多源验证、主动学习 |
结论
Mem0分层记忆系统代表了大语言模型记忆机制的重要演进方向。通过模仿人类记忆的分层结构和动态特性,它有效解决了传统记忆机制的局限性,为构建真正智能、个性化的对话系统提供了坚实的技术基础。
核心贡献总结:
-
架构创新:提出的四层记忆架构为LLMs提供了全面的记忆支持
-
动态适应性:记忆的重要性、衰减、检索都是动态调整的
-
可扩展性:模块化设计支持不同应用场景的定制
-
效率优化:通过分层存储和智能检索平衡了性能与准确性
实践意义:
对于AI产品开发者而言,Mem0系统提供了一套完整的记忆解决方案,可以:
-
显著提升长对话的质量和一致性
-
实现真正的个性化交互体验
-
降低模型的计算成本和延迟
-
为复杂任务处理提供记忆支持
展望:
随着技术的不断成熟,Mem0分层记忆系统有望成为下一代对话AI的标准配置。未来的研究方向将集中在记忆的跨模态扩展、隐私保护机制、以及与其他认知模块(如推理、规划)的深度集成上。
记忆不仅是信息的存储,更是智能的基石。Mem0系统通过赋予AI持久、结构化、可演进的记忆能力,正在推动人工智能向更高层次的认知能力迈进。
代码仓库 :完整的Mem0实现代码可在GitHub仓库获取。