部署llama.cpp
按照如下操作完成
1、在huggingface中找到合适的模型,地址:https://huggingface.co/
-
根据主机配置选择合适的模型(根据模型参数量xxb来判断,xxb越大那么模型效果越好,但需要的资源也越多)
-
-xxb-chat的模型是指令微调后的模型,直接用来做人机对话的部署(这种模型的后缀也有是-xxb-Instruct)
-
-xxb 像这样什么都不带的模型则是基础模型,所以说这个不适合直接拿来做人机对话,更适合在垂直领域上的训练或者微调
-
-xxb-Chat-xx也算基础模型是在-xxb-Chat 模型上量化得到的,所谓的量化 就是,将模型的参数从高精度模式转变为低精度格式,这样能减小模型消耗资源的大小,让低资源配置的机器也能够正常运行大模型。简单来说,模型量化(Model Quantization) 就像是把一张"超高清蓝光原片"压缩成"720P清晰度"。虽然损失了一些细节,但文件变小了,播放也更流畅了。在深度学习中,量化是将模型参数(权重和激活值)从高精度 (通常是 32 位浮点数,FP32)转换为低精度(如 8 位整数,INT8)的过程。
-
-xxb-chat-gguf 格式的模型是针对llama.cpp框架的,这个框架是纯C++的实现,它的主要目标是在各种硬件资源上,实现高效的大模型推理(大模型推理框架有:Transfromer,vLLM,llama.cpp),它非常适合显存很小或者没有显卡的场景。llama.cpp的主要目标是让大语言模型在本地或云端的各种硬件上,以最少的设置和最先进的性能进行推理,它是基于C和C++实现的,这意味着它可以轻松的各种不通的操作系统上编译和运行。这个框架提供了各种的量化方案。在针对llama.cpp框架选择模型的时候,选择量化模型的-xxb-chat-qx_k_m.gguf模型版本,因为它保留了模型大部分的性能,而且模型的体积也得到了最够的压缩。
1.为什么要量化?(核心痛点)
现代大模型(如 Llama 3, GPT 系列)动辄拥有百亿、千亿级参数。如果不做处理,它们会面临以下三个严峻问题:
内存占用巨大: 一个 FP32 的参数占用 4 字节。一个 70B(700亿参数)的模型仅权重就需要 280GB 显存,普通的消费级显卡(如 RTX 4090 仅 24GB)根本跑不动。
计算速度慢: 浮点数运算(Floating Point)比整数运算(Integer)更复杂,消耗的时钟周期更多。
能耗高: 在手机、摄像头等嵌入式设备上,高精度的计算会迅速耗尽电量并导致设备发烫。
2.量化的具体作用
1. 极大地压缩模型体积 通过量化,模型大小通常能直接缩减为原来的 1/4 甚至更小。
FP32 → \rightarrow → INT8: 体积缩小 4 倍。
FP32 → \rightarrow → INT4: 体积缩小 8 倍(这是目前大模型端侧运行的主流格式)。
2. 显著提升推理速度
大多数现代芯片(如英伟达的 Tensor Core、手机的 NPU)在处理整数运算时,单位时间内的计算量(OPS)远高于浮点运算。量化后的模型在推理(Inference)时响应更积极。
3. 降低显存门槛量化让原本只能在昂贵服务器(如 A100/H100)上运行的模型,能够跑在个人电脑、甚至手机的主存里。
3.量化会有损失吗?
会有损失,但通常在可接受范围内。 量化本质上是引入了舍入误差。
-
精度下降: 模型的逻辑推理能力、分类准确率可能会轻微下降。
-
补偿方案: 现在的技术(如 QLoRA 或 AWQ)已经能做到在量化到 4-bit 的情况下,性能损失微乎其微。
-
下载llama.cpp ,下载地址: Release b8763 · ggml-org/llama.cpp · GitHub
-
下载gguf的量化模型,我选择千问3,离线方式进行部署,因为在线方式,网络不稳定。下载地址:Qwen/Qwen3-0.6B-GGUF at mainQwen/Qwen3-0.6B-GGUF at main
手动下载模型文件
由于 llama-cli -hf 这种自动下载方式受网络波动影响很大,最稳妥的方法是手动下载。
-
前往镜像站或 HF 官网手动下载
Qwen3-0.6B-GGUF的.gguf文件。 -
将文件放在你的
D:\app\llama-b8763-bin-win-cpu-x64文件夹下。 -
修改命令,直接指向本地文件,避开网络请求:
` Bash
llama-cli -m Qwen3-0.6B-Q8_0.gguf --jinja --color on -ngl 99 -fa on -sm row --temp 0.6 --top-k 20 --top-p 0.95 --min-p 0 --presence-penalty 1.5 -c 40960 -n 32768 --no-context-shift`(注意:请根据你下载的实际文件名修改 -m 后面的参数)一个温馨的小提醒 我注意到你的路径里写着 win-cpu-x64,并且日志显示加载的是 ggml-cpu-icelake.dll。由于 Qwen3 虽然只有 0.6B,但如果你想用 -fa on (Flash Attention) 和 -ngl 99 (GPU 卸载),纯 CPU 编译版的 llama.cpp 是跑不动这些硬件加速特性的 。如果手动下载后运行依然报错,建议去掉 -fa on 和 -ngl 99,或者换成 cublas (NVIDIA GPU) 版本的 llama-cli。
-
使用模型/运行模型,执行命令
llama-cli -m Qwen3-0.6B-Q8_0.gguf --jinja --color on -ngl 99 -fa on -sm row --temp 0.6 --top-k 20 --top-p 0.95 --min-p 0 --presence-penalty 1.5 -c 40960 -n 32768 --no-context-shift这个是终端方式进行交互,如下图:
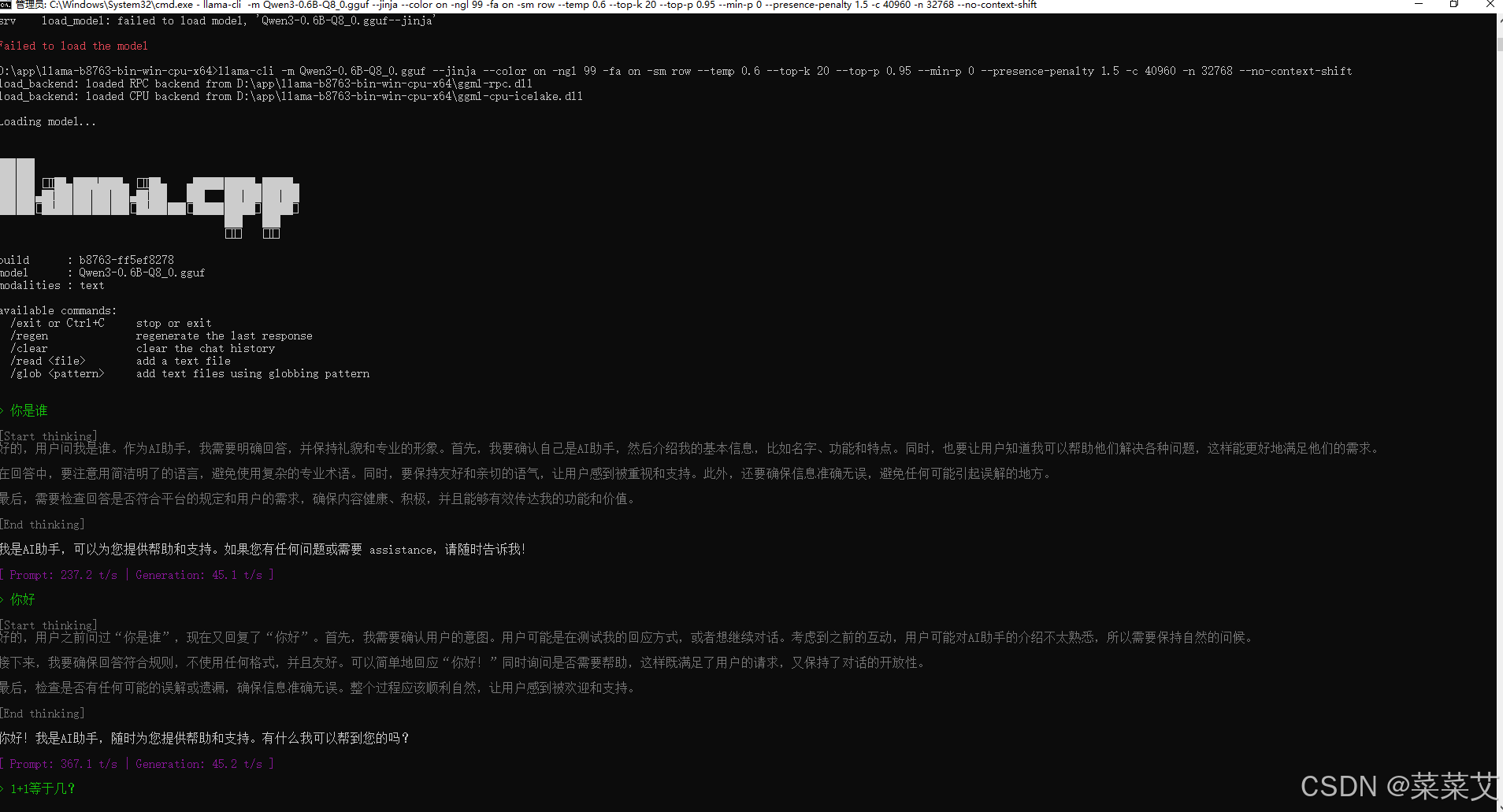
-
想要像gpt这样在浏览器里优雅地对话,而不是对着黑乎乎的 CMD 窗口,需要启动
llama.cpp自带的 Server 模式 。它会开启一个本地网页服务器,让你通过浏览器访问。使用llama-server(最快、最直接):在文件夹里,应该有一个叫llama-server.exe的程序。如果没有,通常llama-cli.exe所在的包里都会附带它。 -
启动服务器: 在 CMD 中运行以下命令(参数和你之前的基本一致,只需把
llama-cli换成llama-server): -
下面的是已经下载好gguf模型执行方式,如果需要在线下载运行,使用-hf参数替换-m参数
Bash llama-server -m Qwen3-0.6B-Q8_0.gguf --jinja -ngl 99 -fa on -sm row -c 8192 --host 0.0.0.0 --port 8080 -
访问网页: 打开浏览器(Chrome, Edge 等),在地址栏输入:
http://127.0.0.1:8080 -
开始对话: 你会看到一个非常简洁的 Web 界面,功能齐全,支持调整参数和聊天模式。如下图:
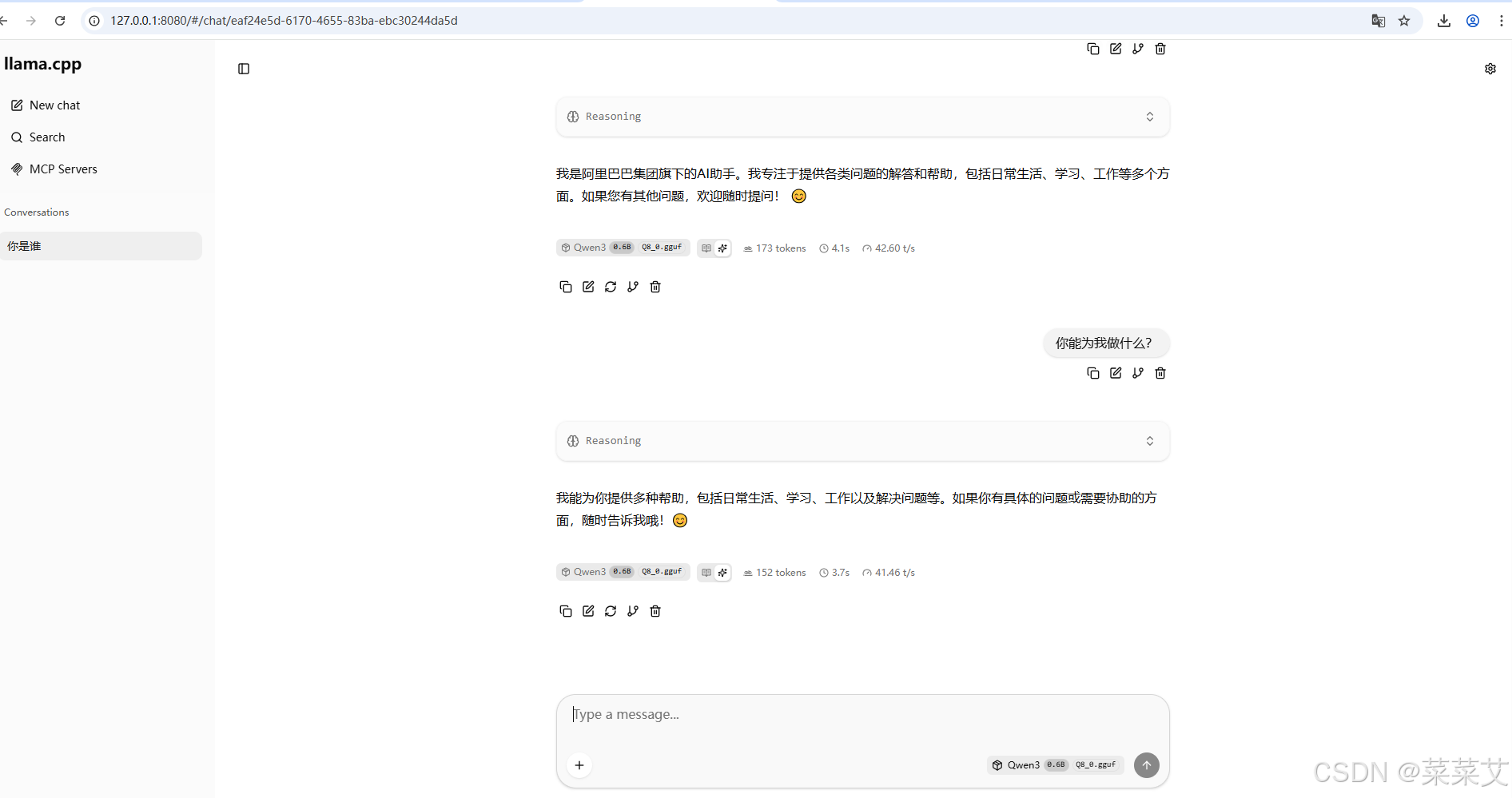
关键点提示
-
保持 CMD 运行: 浏览器只是个"脸",
llama-server.exe才是"大脑"。如果你关掉了 CMD 窗口,网页就会失去响应。 -
关于资源占用: 浏览器也会占用一部分内存,如果你发现电脑卡顿,可以适当调小
-c 40960(上下文窗口大小),比如改为-c 8192。