一、好友关注
1. 关注和取消关注
(1) FollowController
java
//关注
@PutMapping("/{id}/{isFollow}")
public Result follow(@PathVariable("id") Long followUserId, @PathVariable("isFollow") Boolean isFollow) {
return followService.follow(followUserId, isFollow);
}
//取消关注
@GetMapping("/or/not/{id}")
public Result isFollow(@PathVariable("id") Long followUserId) {
return followService.isFollow(followUserId);
}(2) FollowService
java
取消关注service
@Override
public Result isFollow(Long followUserId) {
// 1.获取登录用户
Long userId = UserHolder.getUser().getId();
// 2.查询是否关注 select count(*) from tb_follow where user_id = ? and follow_user_id = ?
Integer count = query().eq("user_id", userId).eq("follow_user_id", followUserId).count();
// 3.判断
return Result.ok(count > 0);
}
关注service
@Override
public Result follow(Long followUserId, Boolean isFollow) {
// 1.获取登录用户
Long userId = UserHolder.getUser().getId();
String key = "follows:" + userId;
// 1.判断到底是关注还是取关
if (isFollow) {
// 2.关注,新增数据
Follow follow = new Follow();
follow.setUserId(userId);
follow.setFollowUserId(followUserId);
boolean isSuccess = save(follow);
} else {
// 3.取关,删除 delete from tb_follow where user_id = ? and follow_user_id = ?
remove(new QueryWrapper<Follow>()
.eq("user_id", userId).eq("follow_user_id", followUserId));
}
return Result.ok();
}说明:
| 字段 | 含义 |
|---|---|
userId |
当前登录用户(你自己) |
followUserId |
要关注 / 取关的用户(博主) |
tb_follow 表 |
专门存关注关系的表 |
isFollow |
true= 关注,false= 取关 |
① if (isFollow) → 关注(新增数据)
java
// 新建一个【关注关系】对象
Follow follow = new Follow();
// 设置:关注人是「我」(当前登录用户)
follow.setUserId(userId);
// 设置:被关注的人是「对方」(博主)
follow.setFollowUserId(followUserId);
// 把这条关注记录 保存到数据库
boolean isSuccess = save(follow);Follow follow = new Follow();数据库里有一张表叫tb_follow(关注表),我们要往表里加一条数据,就得先创建一个对应的对象。setUserId(userId)填数据:关注的人是我(我是主动关注的一方)。setFollowUserId(followUserId)填数据:我关注的人是他(对方是被关注的博主)。save(follow)MyBatis-Plus 提供的方法,直接把这条关注数据插入数据库。
② else → 取关(删除数据)
java
remove(new QueryWrapper<Follow>()
.eq("user_id", userId) // 条件1:关注人是我
.eq("follow_user_id", followUserId) // 条件2:被关注人是他
);new QueryWrapper<Follow>()
→ 删除条件
翻译:我不能乱删,必须告诉我删哪一行
2. 共同关注
(1) 代码实现
java
// UserController 根据id查询用户
@GetMapping("/{id}")
public Result queryUserById(@PathVariable("id") Long userId){
// 查询详情
User user = userService.getById(userId);
if (user == null) {
return Result.ok();
}
UserDTO userDTO = BeanUtil.copyProperties(user, UserDTO.class);
// 返回
return Result.ok(userDTO);
}
// BlogController 根据id查询博主的探店笔记
@GetMapping("/of/user")
public Result queryBlogByUserId(
@RequestParam(value = "current", defaultValue = "1") Integer current,
@RequestParam("id") Long id) {
// 根据用户查询
Page<Blog> page = blogService.query()
.eq("user_id", id).page(new Page<>(current, SystemConstants.MAX_PAGE_SIZE));
// 获取当前页数据
List<Blog> records = page.getRecords();
return Result.ok(records);
}说明:
① @PathVariable 和 @RequestParam 的区别
@PathVariable(路径参数,写在 URL / 里的), @RequestParam 是 查询参数 ,写在 URL ? 后面的。
| 注解 | 位置 | 例子 |
|---|---|---|
@PathVariable |
URL 路径 / 里 |
/100/true |
@RequestParam |
URL 问号 ? 后面 |
?current=1&id=100 |
② blogService.query()
→ 翻译:我要查 blog 表(博客表)的数据
→ 等价 SQL:SELECT * FROM blog
③ .page(分页参数)
.page(new Page<>(current, SystemConstants.MAX_PAGE_SIZE));
这是MyBatis-Plus 分页方法,两个参数:
current:当前页码(比如 1 = 第一页,2 = 第二页)SystemConstants.MAX_PAGE_SIZE:固定值,比如 10 → 一页显示 10 条博客
④ page.getRecords()
→ 翻译:从分页结果里,把「当前页的博客列表」拿出来
→ 结果:[博客1, 博客2, ..., 博客10]
(2) 修改FollowServiceImpl
改造原因:我们需要在用户关注了某位用户后,需要将数据放入到set集合中,方便后续进行共同关注,同时当取消关注时,也需要从set集合中进行删除。set集合可以实现交集、并集、补集的功能。
java
@Override
public Result followCommons(Long id) {
// 1.获取当前用户
Long userId = UserHolder.getUser().getId();
String key = "follows:" + userId;
// 2.求交集
String key2 = "follows:" + id;
Set<String> intersect = stringRedisTemplate.opsForSet().intersect(key, key2);
if (intersect == null || intersect.isEmpty()) {
// 无交集
return Result.ok(Collections.emptyList());
}
// 3.解析id集合
List<Long> ids = intersect.stream().map(Long::valueOf).collect(Collectors.toList());
// 4.查询用户
List<UserDTO> users = userService.listByIds(ids)
.stream()
.map(user -> BeanUtil.copyProperties(user, UserDTO.class))
.collect(Collectors.toList());
return Result.ok(users);
}说明:
.collect(Collectors.toList())
把转换好的数字 ID,打包成一个列表
3. Feed流实现方案
针对好友的操作,采用的是Timeline的方式,只需要拿到我们关注用户的信息,然后按照时间排序即可,因此采用Timeline的模式。该模式的实现方案有三种:
-
拉模式
-
推模式
-
推拉结合
(1) 拉模式
① 核心逻辑:
当张三、李四和王五发了消息后,都会保存在自己的邮箱中。假设赵六要读取信息,那么它会从读取它自己的收件箱,此时系统会从它关注的人群中,把它关注人的信息全部都进行拉取,然后在进行排序。
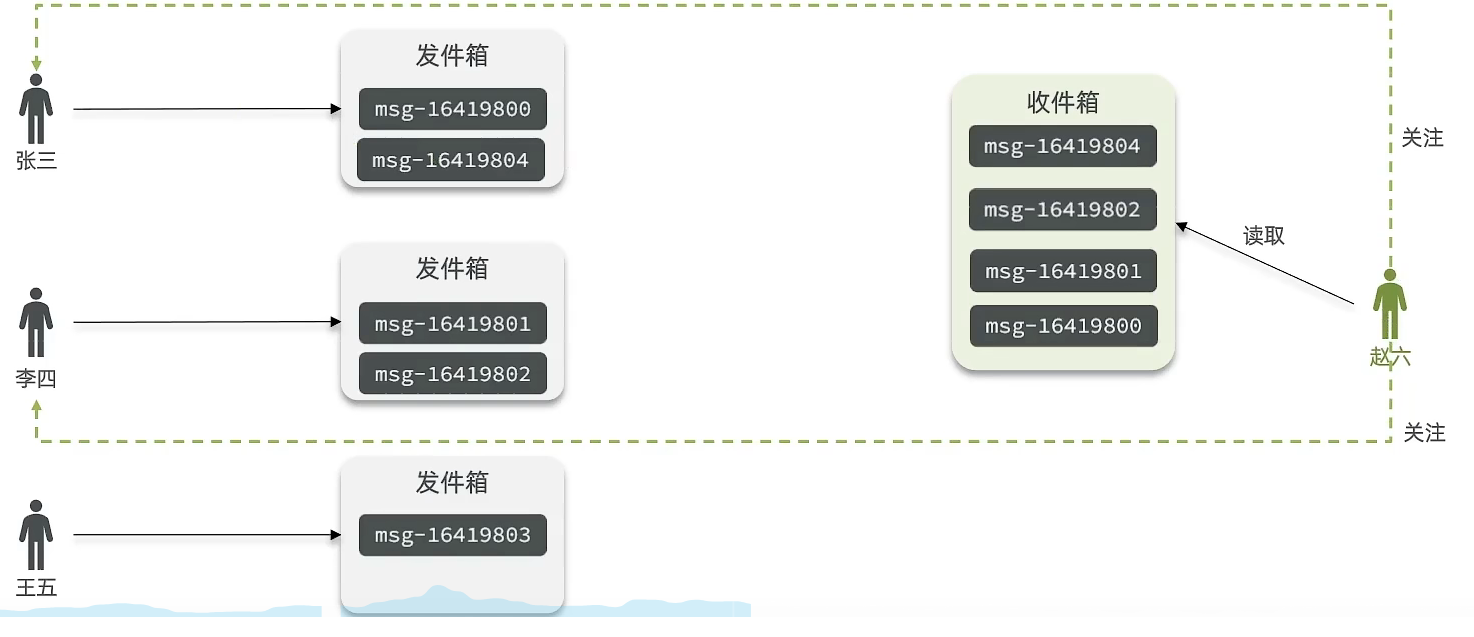
② 优点:比较节约空间,因为赵六在读信息时,并没有重复读取,而且读取完之后可以把它的收件箱进行清楚。
③ 缺点:比较延迟,当用户读取数据时才去关注的人里边去读取数据,假设用户关注了大量的用户,那么此时就会拉取海量的内容,对服务器压力巨大。
(2) 推模式
① 核心逻辑:
推模式是没有写邮箱的,当张三写了一个内容,此时会主动的把张三写的内容发送到它的粉丝收件箱中去,假设此时李四再来读取,就不用再去临时拉取了。
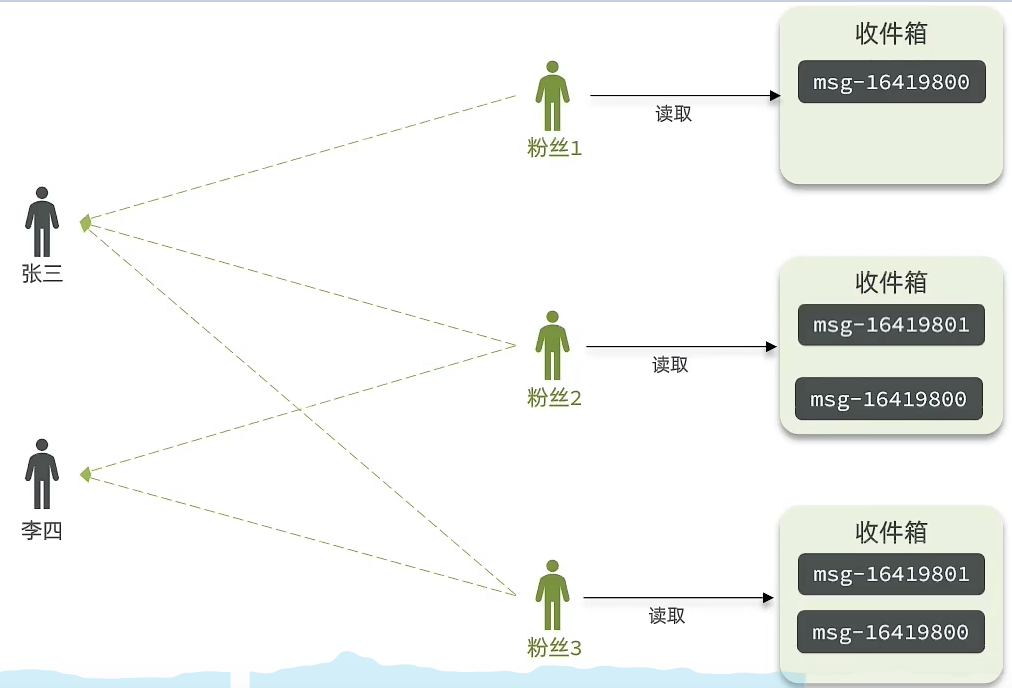
② 优点:时效快,不用临时拉取。
③ 缺点:内存压力大,假设一个大V写信息,很多人关注它, 就会写很多分数据到粉丝那边去
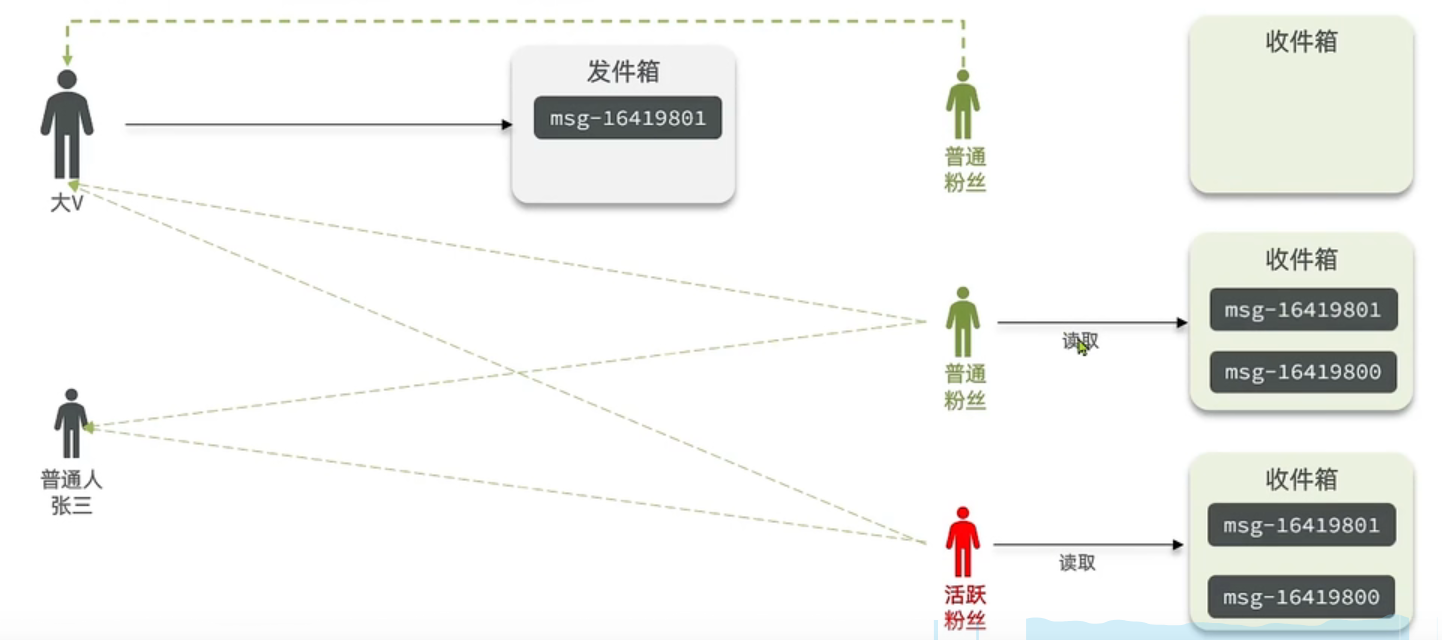
(3) 推拉模式
推拉模式是一个折中的方案。
① 站在发件人这一端,如果是个普通的人,那么我们采用写扩散的方式,直接把数据写入到它的粉丝中去,因为普通的人它的粉丝关注量比较小,所以这样做没有压力。如果是大V,那么它是直接将数据先写入到一份到发件箱里边去,然后再直接写一份到活跃粉丝收件箱里边去。
② 现在站在收件人这端来看,如果是活跃粉丝,那么大V和普通的人发的都会直接写入到自己收件箱里边来,而如果是普通的粉丝,由于它们上线不是很频繁,所以等它们上线时,再从发件箱里边去拉信息。
4. 推送到粉丝收件箱
(1) 需求
-
修改新增探店笔记的业务,在保存blog到数据库的同时,推送到粉丝的收件箱
-
收件箱满足可以根据时间戳排序,必须用Redis的数据结构实现
-
查询收件箱数据时,可以实现分页查询
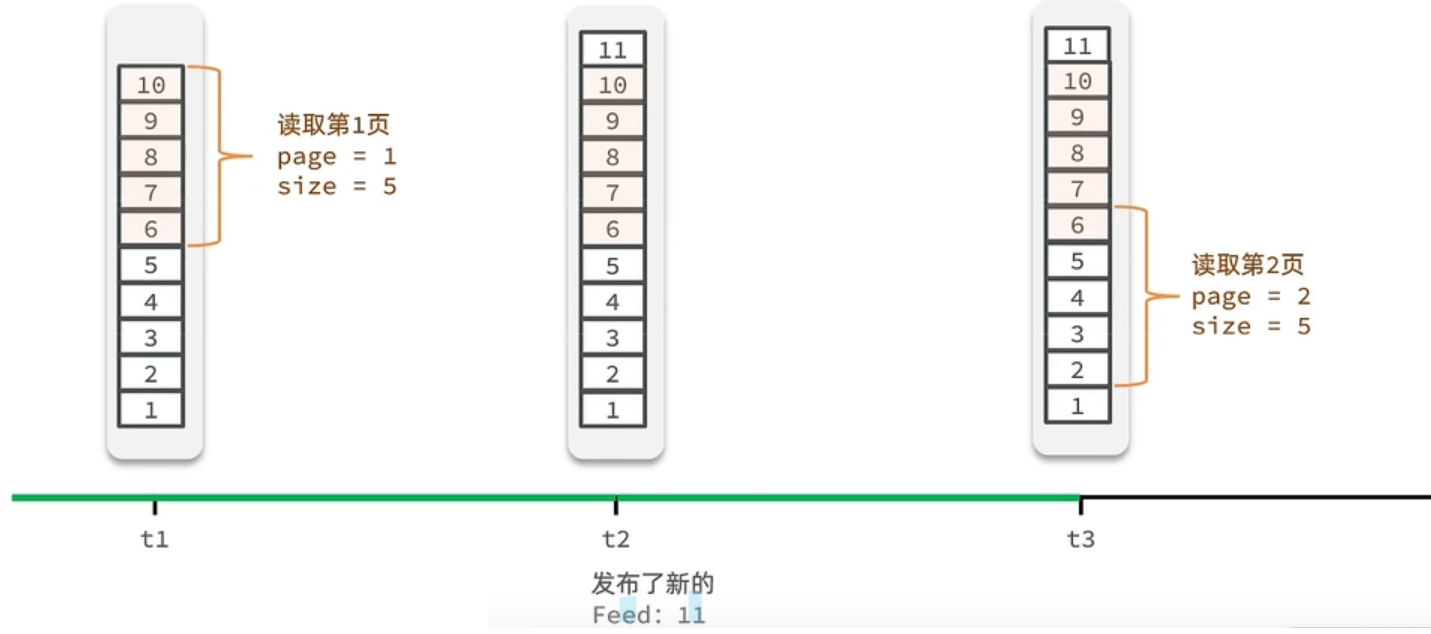
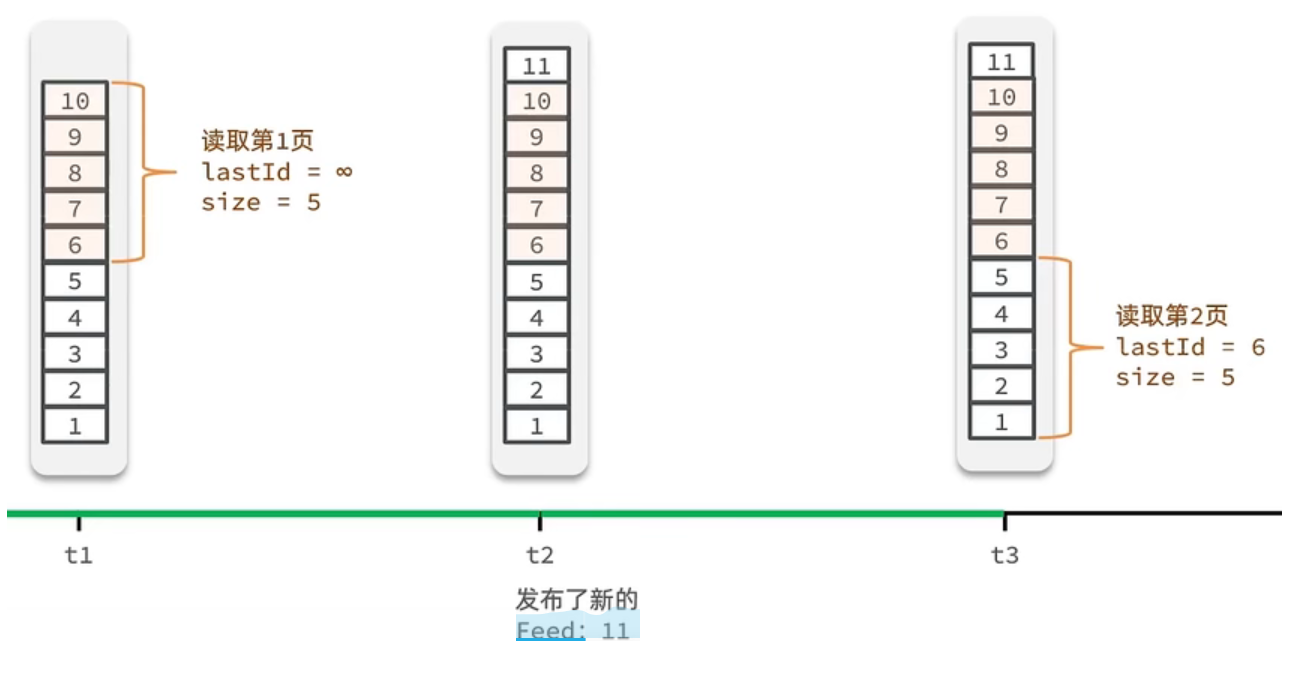
(2) Feed流的分页问题
① 传统分页
- t1 时刻 :取第 1 页(
page=1, size=5),拿到10,9,8,7,6。 - t2 时刻 :新增一条内容
11,数据整体后移。 - t3 时刻 :取第 2 页(
page=2, size=5),按传统逻辑从第 6 条开始取,拿到6,5,4,3,2。 - 结果 :
6在第 1 页和第 2 页都出现了,数据重复。
② 滚动分页
- t1 时刻 :首次加载,
lastId = ∞(无前置数据),取前 5 条10,9,8,7,6,记录lastId = 6。 - t2 时刻 :新增内容
11,插入到最顶部,不影响已记录的6。 - t3 时刻 :加载下一页,传入
lastId = 6,从6之后的5开始取,拿到5,4,3,2,1,无重复。
(3) 代码实现
java
@Override
public Result saveBlog(Blog blog) {
// 1.获取登录用户
UserDTO user = UserHolder.getUser();
blog.setUserId(user.getId());
// 2.保存探店笔记
boolean isSuccess = save(blog);
if(!isSuccess){
return Result.fail("新增笔记失败!");
}
// 3.查询笔记作者的所有粉丝 select * from tb_follow where follow_user_id = ?
List<Follow> follows = followService.query().eq("follow_user_id", user.getId()).list();
// 4.推送笔记id给所有粉丝
for (Follow follow : follows) {
// 4.1.获取粉丝id
Long userId = follow.getUserId();
// 4.2.推送
String key = FEED_KEY + userId;
stringRedisTemplate.opsForZSet().add(key, blog.getId().toString(), System.currentTimeMillis());
}
// 5.返回id
return Result.ok(blog.getId());
}5. 实现分页查询收邮箱
(1) 需求
① 每次查询完成后,我们要分析出查询出数据的最小时间戳,这个值会作为下一次查询的条件
② 我们需要找到与上一次查询相同的查询个数作为偏移量,下次查询时,跳过这些查询过的数据,拿到我们需要的数据
| 参数 | 含义 | 核心目的 |
|---|---|---|
lastId |
上一次查询结果里的最小时间戳 | 限定本次查询只加载「比这个时间更早」的 Blog,保证数据按时间倒序加载,避免重复获取 |
offset |
上一次查询返回的Blog 数量 | 用来跳过已经加载过的数据,实现 "下一页" 的翻页效果 |
(2) 代码实现
① 定义出来具体的返回值实体类
java
@Data
public class ScrollResult {
private List<?> list;
private Long minTime;
private Integer offset;
}② BlogController
java
@GetMapping("/of/follow")
public Result queryBlogOfFollow(
@RequestParam("lastId") Long max, @RequestParam(value = "offset", defaultValue = "0") Integer offset){
return blogService.queryBlogOfFollow(max, offset);
}③ BlogServiceImpl
java
@Override
public Result queryBlogOfFollow(Long max, Integer offset) {
// 1.获取当前用户
Long userId = UserHolder.getUser().getId();
// 2.查询收件箱 ZREVRANGEBYSCORE key Max Min LIMIT offset count
String key = FEED_KEY + userId;
Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet()
.reverseRangeByScoreWithScores(key, 0, max, offset, 2);
// 3.非空判断
if (typedTuples == null || typedTuples.isEmpty()) {
return Result.ok();
}
// 4.解析数据:blogId、minTime(时间戳)、offset
List<Long> ids = new ArrayList<>(typedTuples.size());
long minTime = 0; // 2
int os = 1; // 2
for (ZSetOperations.TypedTuple<String> tuple : typedTuples) { // 5 4 4 2 2
// 4.1.获取id
ids.add(Long.valueOf(tuple.getValue()));
// 4.2.获取分数(时间戳)
long time = tuple.getScore().longValue();
if(time == minTime){
os++;
}else{
minTime = time;
os = 1;
}
}
os = minTime == max ? os : os + offset;
// 5.根据id查询blog
String idStr = StrUtil.join(",", ids);
List<Blog> blogs = query().in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list();
for (Blog blog : blogs) {
// 5.1.查询blog有关的用户
queryBlogUser(blog);
// 5.2.查询blog是否被点赞
isBlogLiked(blog);
}
// 6.封装并返回
ScrollResult r = new ScrollResult();
r.setList(blogs);
r.setOffset(os);
r.setMinTime(minTime);
return Result.ok(r);
}说明:
① List<Long> ids = new ArrayList<>(typedTuples.size());
List<Long>:创建一个列表 ,里面专门存 数字类型的博客 ID(数据库里的 ID 是数字,不是字符串)ids:列表的名字,意思就是 id 集合new ArrayList<>():创建列表对象typedTuples.size():提前指定列表的大小- 比如 Redis 查到了 2 条数据,列表就直接开 2 个位置
- 作用:优化性能,不用让列表自动扩容
② String idStr = tuple.getValue(); ids.add(Long.valueOf(idStr));
tuple:循环中每一个 Redis 包裹(包含博客 ID + 时间戳)tuple.getValue():拿出包裹里的博客 ID(注意:是字符串格式,比如 "1001")Long.valueOf(idStr):把字符串 ID 转成 数字 ID- 因为数据库里的 ID 是
Long数字类型,字符串查不到数据,必须转类型
- 因为数据库里的 ID 是
ids.add(...):把转换后的数字 ID,放进刚才创建的列表里
③List<Blog> blogs = query().in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list();
1). 问题
Redis 查出的 blogId 是按时间倒序 的,但 MySQL 的 IN 查询不会保证返回顺序!直接查会导致博客顺序乱掉。
2). 解决方案
ORDER BY FIELD(id, 1,2,3):强制让数据库返回的顺序 和 Redis 中的 id 顺序完全一致,保证前端展示顺序正确。
二、附近商户
1. GEO数据结构的基本用法
GEO就是Geolocation的简写形式,代表地理坐标。Redis在3.2版本中加入了对GEO的支持,允许存储地理坐标信息,帮助我们根据经纬度来检索数据。常见的命令有:
-
GEOADD:添加一个地理空间信息,包含:经度(longitude)、纬度(latitude)、值(member)
-
GEODIST:计算指定的两个点之间的距离并返回
-
GEOHASH:将指定member的坐标转为hash字符串形式并返回
-
GEOPOS:返回指定member的坐标
-
GEORADIUS:指定圆心、半径,找到该圆内包含的所有member,并按照与圆心之间的距离排序后返回。6.以后已废弃
-
GEOSEARCH:在指定范围内搜索member,并按照与指定点之间的距离排序后返回。范围可以是圆形或矩形。6.2.新功能
-
GEOSEARCHSTORE:与GEOSEARCH功能一致,不过可以把结果存储到一个指定的key。6.2.新功能
2. 导入店铺数据到GEO
(1) Redis GEO 数据结构设计
① 按「商家类型」分组存储
Redis GEO 本身不支持额外的类型筛选条件 (比如只查美食、排除 KTV),所以我们用分组来解决:
- 给每种商家类型建一个独立的 GEO 集合,Key 格式为:
shop:geo:{类型}- 美食类:
shop:geo:美食 - KTV 类:
shop:geo:KTV
- 美食类:
- 这样用户选「美食」时,直接查询
shop:geo:美食,天然就过滤了类型,只查美食商家。
② GEO 里只存「商家 ID」,不存完整信息
Redis 是内存数据库,存太多数据会占满内存,所以:
- Value(member) :只存商家的ID(比如海底捞的 ID 是 1,就存 "1")
- Score:Redis 自动把经纬度转换成 GeoHash 值,用来计算距离和排序
- 完整的商家信息(名称、地址、评分等)依然存在数据库(MySQL)里,之后用 ID 去查。
(2) 代码实现
java
@Test
void loadShopData() {
// 1.查询店铺信息
List<Shop> list = shopService.list();
// 2.把店铺分组,按照typeId分组,typeId一致的放到一个集合
Map<Long, List<Shop>> map = list.stream().collect(Collectors.groupingBy(Shop::getTypeId));
// 3.分批完成写入Redis
for (Map.Entry<Long, List<Shop>> entry : map.entrySet()) {
// 3.1.获取类型id
Long typeId = entry.getKey();
String key = SHOP_GEO_KEY + typeId;
// 3.2.获取同类型的店铺的集合
List<Shop> value = entry.getValue();
List<RedisGeoCommands.GeoLocation<String>> locations = new ArrayList<>(value.size());
// 3.3.写入redis GEOADD key 经度 纬度 member
for (Shop shop : value) {
// stringRedisTemplate.opsForGeo().add(key, new Point(shop.getX(), shop.getY()), shop.getId().toString());
locations.add(new RedisGeoCommands.GeoLocation<>(
shop.getId().toString(),
new Point(shop.getX(), shop.getY())
));
}
stringRedisTemplate.opsForGeo().add(key, locations);
}
}说明:
① Map<Long, List<Shop>> map = list.stream() .collect(Collectors.groupingBy(Shop::getTypeId));
- 用
groupingBy(Shop::getTypeId)把所有店铺,按类型 ID分成一组一组; - 最终得到一个
Map:key = 类型 ID,value = 该类型的所有店铺; - 后续给每个类型创建一个独立的 Redis GEO Key (比如
shop:geo:1是美食店,shop:geo:2是 KTV),查询时直接查对应 Key,天然过滤类型。
② 往箱子里「装每个店铺的包裹」
java
for (Shop shop : value) {
locations.add(
new GeoLocation<>(
shop.getId().toString(), // 包裹里的「快递单号」:店铺ID
new Point(shop.getX(), shop.getY()) // 包裹里的「收货地址」:经纬度
)
);
}shop.getId().toString():把店铺 ID 转成字符串,作为 Redis GEO 里的member(相当于快递单号,用来后续查询店铺信息)new Point(shop.getX(), shop.getY()):封装店铺的经纬度
3. 实现附近商户功能
(1) ShopController
java
@GetMapping("/of/type")
public Result queryShopByType(
@RequestParam("typeId") Integer typeId,
@RequestParam(value = "current", defaultValue = "1") Integer current,
@RequestParam(value = "x", required = false) Double x,
@RequestParam(value = "y", required = false) Double y
) {
return shopService.queryShopByType(typeId, current, x, y);
}(2) ShopServiceImpl
java
@Override
public Result queryShopByType(Integer typeId, Integer current, Double x, Double y) {
// 1.判断是否需要根据坐标查询
if (x == null || y == null) {
// 不需要坐标查询,按数据库查询
Page<Shop> page = query()
.eq("type_id", typeId)
.page(new Page<>(current, SystemConstants.DEFAULT_PAGE_SIZE));
// 返回数据
return Result.ok(page.getRecords());
}
// 2.计算分页参数
int from = (current - 1) * SystemConstants.DEFAULT_PAGE_SIZE;
int end = current * SystemConstants.DEFAULT_PAGE_SIZE;
// 3.查询redis、按照距离排序、分页。结果:shopId、distance
String key = SHOP_GEO_KEY + typeId;
GeoResults<RedisGeoCommands.GeoLocation<String>> results = stringRedisTemplate.opsForGeo() // GEOSEARCH key BYLONLAT x y BYRADIUS 10 WITHDISTANCE
.search(
key,
GeoReference.fromCoordinate(x, y),
new Distance(5000),
RedisGeoCommands.GeoSearchCommandArgs.newGeoSearchArgs().includeDistance().limit(end)
);
// 4.解析出id
if (results == null) {
return Result.ok(Collections.emptyList());
}
List<GeoResult<RedisGeoCommands.GeoLocation<String>>> list = results.getContent();
if (list.size() <= from) {
// 没有下一页了,结束
return Result.ok(Collections.emptyList());
}
// 4.1.截取 from ~ end的部分
List<Long> ids = new ArrayList<>(list.size());
Map<String, Distance> distanceMap = new HashMap<>(list.size());
list.stream().skip(from).forEach(result -> {
// 4.2.获取店铺id
String shopIdStr = result.getContent().getName();
ids.add(Long.valueOf(shopIdStr));
// 4.3.获取距离
Distance distance = result.getDistance();
distanceMap.put(shopIdStr, distance);
});
// 5.根据id查询Shop
String idStr = StrUtil.join(",", ids);
List<Shop> shops = query().in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list();
for (Shop shop : shops) {
shop.setDistance(distanceMap.get(shop.getId().toString()).getValue());
}
// 6.返回
return Result.ok(shops);
}说明:
① .page(new Page<>(current, 每页条数))
current:前端传的当前页码(比如第 1 页、第 2 页)SystemConstants.DEFAULT_PAGE_SIZE:每页默认显示多少条店铺(比如 10 条)
② return Result.ok(page.getRecords());
Page 分页对象里包含了很多分页信息:
- 总页数、总条数、当前页、每页条数、数据列表
getRecords()= 获取分页查询到的「店铺数据列表」(就是我们要展示给用户的店铺集合)
③ 指定类型 + 5 公里范围内 + 按距离排序 的店铺
| 参数 | 代码写法 | 大白话翻译 |
|---|---|---|
| 第 1 个 | key |
查哪种类型的店铺(比如美食店) |
| 第 2 个 | GeoReference.fromCoordinate(x, y) |
以用户当前坐标 为圆心 |
| 第 3 个 | new Distance(5000) |
以圆心为中心,画 **5000 米(5 公里)** 的圈 |
| 第 4 个 | includeDistance() |
必须计算并返回每个店铺离用户的距离 |
| 第 4 个 | limit(end) |
最多查 end 条数据(分页用) |
④ Map<String, Distance> distanceMap = new HashMap<>(list.size());
distanceMap:一个空 Map- 作用:等会儿存 "店铺 ID → 离你多远"
- 比如:
105 → 1.2km
⑤ shop.setDistance(distanceMap.get(shop.getId().toString()).getValue());
.getValue() 的作用是从 Distance 对象里,提取出纯数字的距离值 (比如 1.2),Distance 对象是 Redis 封装的,包含单位、数值等信息,我们只需要数值给前端展示