
🔥承渊政道: 个人主页
❄️个人专栏: 《C语言基础语法知识》 《数据结构与算法》 《C++知识内容》 《Linux系统知识》 《算法刷题指南》 《测评文章活动推广》 《大模型语言路线学习》
✨逆境不吐心中苦,顺境不忘来时路!✨ 🎬 博主简介:

在算法的世界里,效率往往是区分优劣的分水岭.当面对海量数据的区间查询问题时,暴力遍历的O(n)时间复杂度常常成为程序的性能瓶颈,而前缀和 (Prefix Sum))作为一种简洁却极具威力的优化技术,正以其"时空转换器"的特质,成为解决这类问题的优选方案.它不仅是算法竞赛与面试中的高频考点,更是每位程序员进阶路上必须掌握的核心技能之一.前缀和的核心思想源于"空间换时间"的经典算法策略:预先计算并存储数组的累积状态,将重复计算的中间结果保存下来,后续查询时只需通过简单的减法运算即可快速获取答案.这种思想看似简单,却蕴含着算法设计的深刻智慧,它不仅能解决一维数组的区间求和问题,还能扩展到二维矩阵的区域查询、结合哈希表统计满足条件的子数组数量、处理环形数组等复杂场景.本文将带您深入探索前缀和的真谛,从基础原理到实战应用,从一维到二维,从传统场景到创新结合,全方位领略这一算法的魅力.我们将通过经典例题的实战演练,揭示前缀和如何将复杂问题简单化、将低效算法高效化,让您不仅掌握其实现技巧,更能理解其背后的算法思想,为解决更复杂的算法问题奠定坚实基础.无论您是算法初学者,还是寻求性能突破的资深开发者,前缀和都值得您深入学习与实践.让我们一同开启这段优化之旅,见证从O(n)到O(1)的效率飞跃,感受算法之美在实战中的绽放!废话不多说,下面跟着小编的节奏🎵一起去疯狂的学习吧!
目录
- 1.前缀和算法背景介绍
- 2.【模板】一维前缀和(OJ题)
- 3.【模板】二维前缀和(OJ题)
- 4.寻找数组的中心下标(OJ题)
- 5.除了自身以外数组的乘积(OJ题)
- 6.和为k的子数组(OJ题)
- 7.和可被k整除的子数组(OJ题)
- 8.连续数组(OJ题)
- 9.矩阵区域和(OJ题)
1.前缀和算法背景介绍
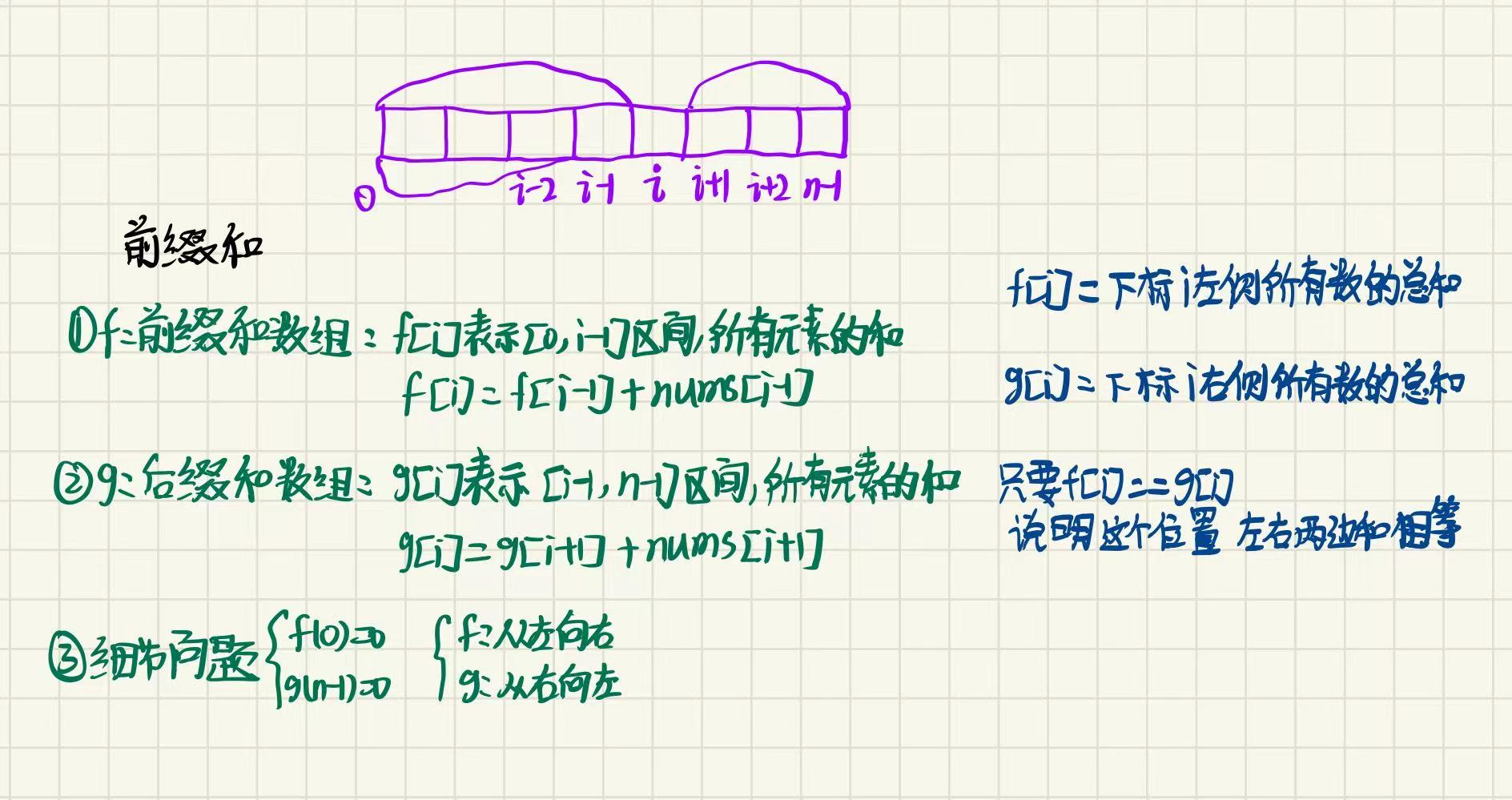
📚1️⃣核心概念
前缀和算法(Prefix Sum),也叫前缀和技巧,是一种针对静态数组的预处理优化方法,核心思想是:预先计算数组的前 i 项和并存储,后续任意区间l, r的和可以通过两个前缀和相减快速得到,将单次查询的时间复杂度从O(n)降至O(1).
📚算法本质与思想
前缀和本质是空间换时间:
- 用额外 O(n) 的空间存储前缀和数组,换取查询阶段的常数级时间效率.
- 数学原理:设原数组为
arr[1..n],前缀和数组dp[i] = arr[1] + arr[2] + ... + arr[i],则区间 l, r 的和 =dp[r] - dp[l-1].
2.【模板】一维前缀和(OJ题)

算法思路:解法(前缀和)
①先预处理出来一个前缀和数组:
用 d p i \boldsymbol{dpi} dpi 表示: 1 , i 1, i 1,i 区间内所有元素的和,那么 d p i − 1 \boldsymbol{dpi - 1} dpi−1 里面存的就是 1 , i − 1 1, i - 1 1,i−1 区间内所有元素的和,那么:可得递推公式: d p i = d p i − 1 + a r r i \boldsymbol{dpi = dpi - 1 + arri} dpi=dpi−1+arri;
②使用前缀和数组,快速求出某一个区间内所有元素的和:
当询问的区间是 l , r \boldsymbol{l, r} l,r时:区间内所有元素的和为: d p r − d p l − 1 \boldsymbol{dpr - dpl - 1} dpr−dpl−1.

完整代码
cpp
#include <iostream>
#include <vector>
using namespace std;
int main() {
//1.读入数据
int n, q;
cin >> n >> q;
vector<int> arr(n + 1);
for (int i = 1; i <= n; i++) cin >> arr[i];
//2.预处理出来一个前缀和数组
vector<long long> dp(n + 1);//防止溢出
for (int i = 1; i <= n; i++) dp[i] = dp[i - 1] + arr[i];
//3.使用前缀和数组
int l = 0, r = 0;
while (q--) {
cin >> l >> r;
cout << dp[r] - dp[l - 1] << endl;
}
return 0;
}3.【模板】二维前缀和(OJ题)

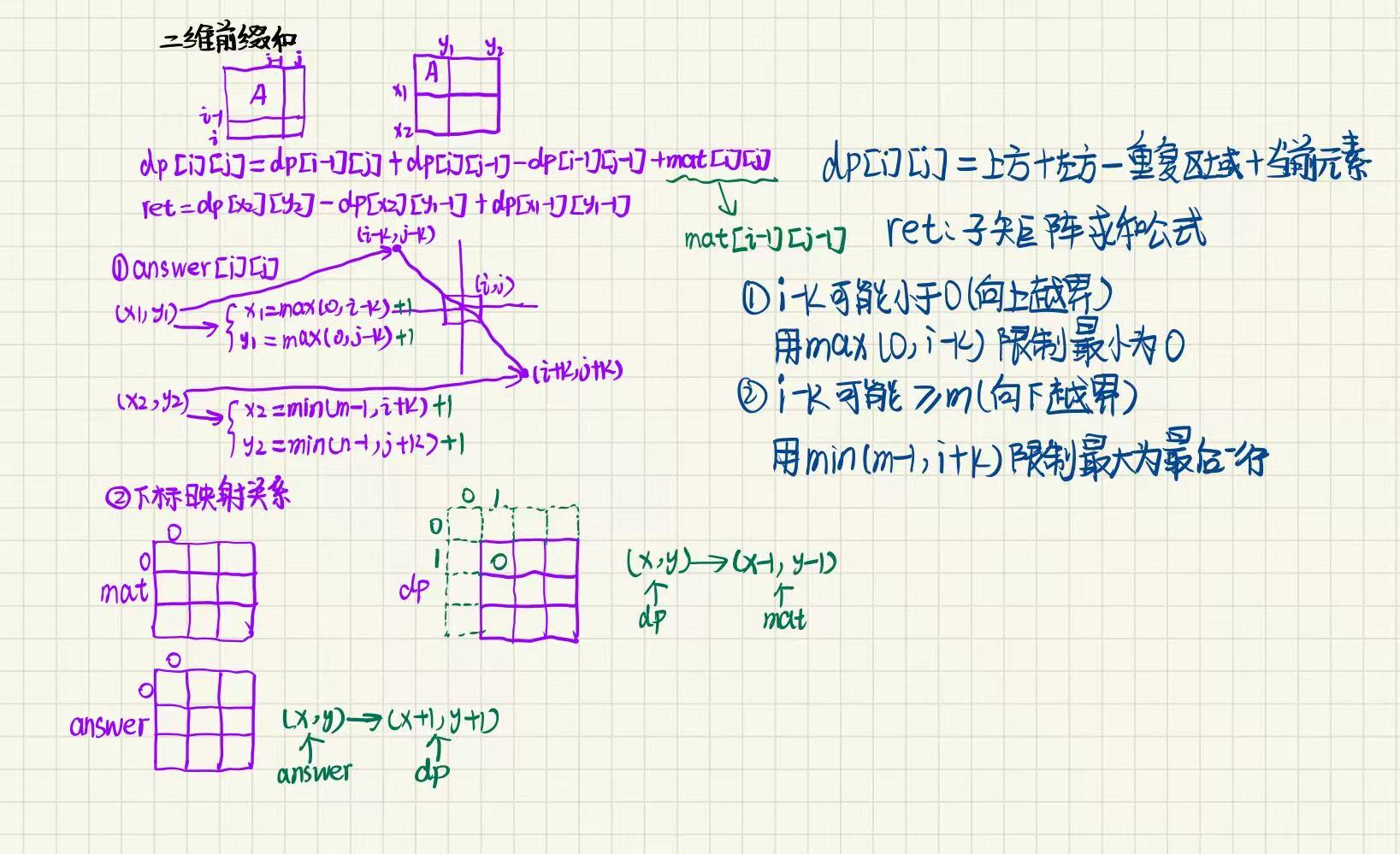
算法思路
类比于一维数组的形式,如果我们能处理出来从 0 , 0 0, 0 0,0位置到 i , j i, j i,j位置这片区域内所有元素的累加和,就可以在 O ( 1 ) O(1) O(1)的时间内,搞定矩阵内任意区域内所有元素的累加和.因此我们接下来仅需完成两步即可:
- 第一步:搞出来前缀和矩阵
这里就要用到一维数组里面的拓展知识,我们要在矩阵的最上面和最左边添加上一行和一列0,这样我们就可以省去非常多的边界条件的处理,处理后的矩阵就像这样:
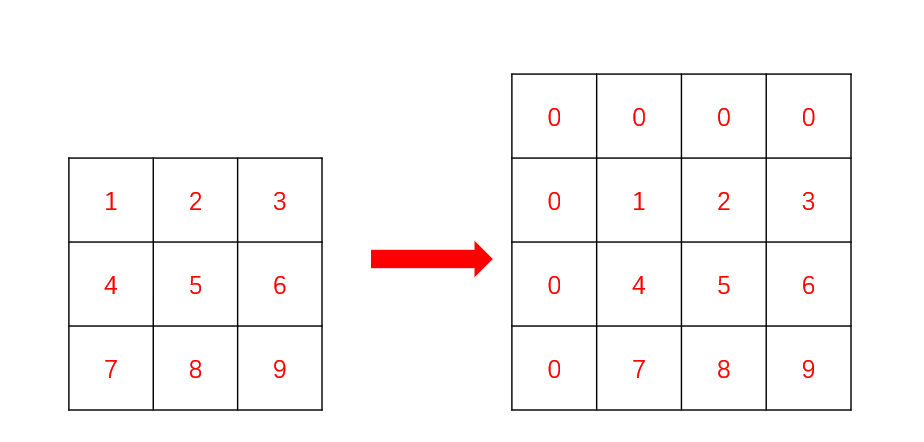
这样,我们填写前缀和矩阵数组的时候,下标直接从1开始,能大胆使用 i - 1, j - 1 位置的值.
注意 dp 表与原数组 matrix 内的元素的映射关系:
(1)从dp表到matrix矩阵,横纵坐标减一;
(2)从matrix矩阵到dp表,横纵坐标加一.
前缀和矩阵中 sum[i][j] 的含义,以及如何递推二维前缀和方程
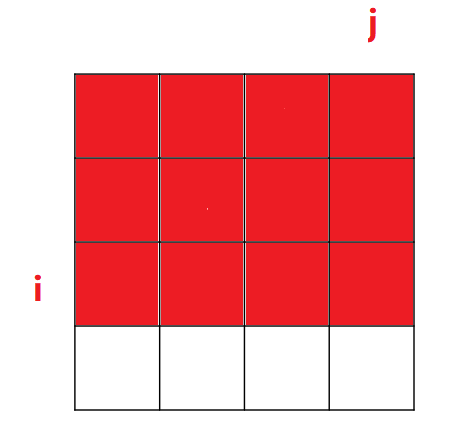
①sum[i][j] 的含义:
sum[i][j] 表示,从[0, 0]位置到[i, j]位置这段区域内,所有元素的累加和.对应下图的红色区域:
递推⽅程:
其实这个递推⽅程⾮常像我们⼩学做过求图形⾯积的题,我们可以将 0, 0 位置到 i, j位置这段区域分解成下⾯的部分:
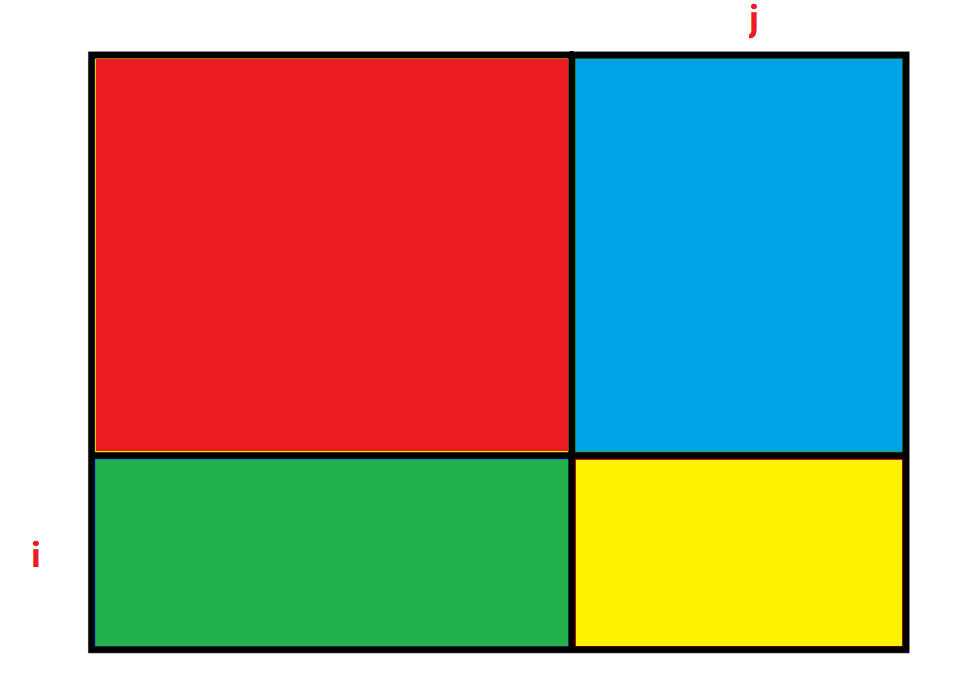
sum[i][j] = 红 + 蓝 + 绿 + 黄,分析一下这四块区域:
(1)黄色部分最简单,它就是数组中的 matrix[i - 1][j - 1](注意坐标的映射关系)
(2)单独的蓝不好求,因为它不是我们定义的状态表示中的区域,同理,单独的绿也是;
(3)但是如果是红 + 蓝,正好是我们 dp 数组中 sum[i - 1][j] 的值,美滋滋;
(4)同理,如果是红 + 绿,正好是我们 dp 数组中 sum[i][j - 1] 的值;
(5)如果把上面求的三个值加起来,那就是黄 + 红 + 蓝 + 红 + 绿,发现多算了一部分红的面积,因此再单独减去红的面积即可;
(6)红的面积正好也是符合 dp 数组的定义的,即 sum[i - 1][j - 1]
综上所述,我们的递推方程就是:
sum[i][j] = sum[i - 1][j] + sum[i][j - 1] - sum[i - 1][j - 1] + matrix[i - 1][j - 1]
第二步:使用前缀和矩阵
题目的接口中提供的参数是原始矩阵的下标,为了避免下标映射错误,这里直接先把下标映射成 dp 表里面对应的下标:row1++, col1++, row2++, col2++
接下来分析如何使⽤这个前缀和矩阵,如下图(注意这⾥的row和col都处理过了,对应的正是 sum 矩阵中的下标):
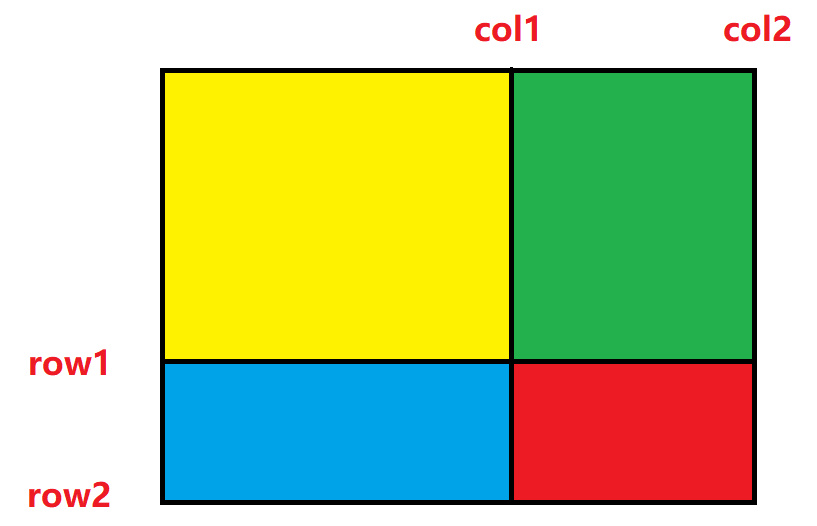
对于左上角 (row1, col1)、右下角 (row2, col2) 围成的区域,好是红色的部分.因此我们要求的就是红色部分的面积,继续分析几个区域:
(1)黄色,能直接求出来,就是 sum[row1 - 1, col1 - 1](为什么减一?因为要剔除掉 row 这一行和 col 这一列)
(2)绿色,直接求不好求,但是和黄色拼起来,正好是 sum 表内 sum[row1 - 1][col2] 的数据;
(3)同理,蓝色不好求,但是蓝 + 黄 = sum[row2][col1 - 1];
(4)再看看整个面积,好求嘛?非常好求,正好是 sum[row2][col2];
(5)那么,红色就 = 整个面积 - 黄 - 绿 - 蓝,但是绿蓝不好求,我们可以这样减:整个面积 - (绿 + 黄) - (蓝 + 黄),这样相当于多减去了一个黄,再加上即可.
综上所述:红 = 整个面积 - (绿 + 黄) - (蓝 + 黄) + 黄,从而可得红色区域内的元素总和为:
sum[row2][col2] - sum[row2][col1 - 1] - sum[row1 - 1][col2] + sum[row1 - 1][col1 - 1]
完整代码
cpp
#include <iostream>
#include <vector>
using namespace std;
int main() {
//1.读入数据
int n = 0, m = 0, q = 0;
cin >> n >> m >> q;
vector<vector<int>> arr(n + 1, vector<int>(m + 1));
for (int i = 1; i <= n; i++)
for (int j = 1; j <= m; j++)
cin >> arr[i][j];
//2.预处理前缀和矩阵
vector<vector<long long>> dp(n + 1, vector<long long>(m + 1)); //防止溢出
for (int i = 1; i <= n; i++)
for (int j = 1; j <= m; j++)
dp[i][j] = dp[i - 1][j] + dp[i][j - 1] + arr[i][j] - dp[i - 1][j - 1];
//3.使用前缀和矩阵
int x1 = 0, y1 = 0, x2 = 0, y2 = 0;
while (q--) {
cin >> x1 >> y1 >> x2 >> y2;
cout << dp[x2][y2] - dp[x1 - 1][y2] - dp[x2][y1 - 1] + dp[x1 - 1][y1 - 1] <<
endl;
}
return 0;
}4.寻找数组的中心下标(OJ题)

算法思路:解法(前缀和)
从中心下标的定义可知,除中心下标的元素外,该元素左边的前缀和等于该元素右边的后缀和.
- 因此,我们可以先预处理出来两个数组,一个表示前缀和,另一个表示后缀和.
- 然后,我们可以用一个 for 循环枚举可能的中心下标,判断每一个位置的前缀和以及后缀和,如果二者相等,就返回当前下标.
核心代码
cpp
class Solution
{
public:
int pivotIndex(vector<int>& nums)
{
int n = nums.size();
vector<int> f(n), g(n);
//1.预处理前缀和数组以及后缀和数组
for (int i = 1; i < n; i++)
f[i] = f[i - 1] + nums[i - 1];
for (int i = n - 2; i >= 0; i--)
g[i] = g[i + 1] + nums[i + 1];
//2.使用
for (int i = 0; i < n; i++)
if (f[i] == g[i])
return i;
return -1;
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
using namespace std;
class Solution
{
public:
int pivotIndex(vector<int>& nums)
{
int n = nums.size();
vector<int> f(n), g(n);
//1.预处理前缀和数组以及后缀和数组
for (int i = 1; i < n; i++)
f[i] = f[i - 1] + nums[i - 1];
for (int i = n - 2; i >= 0; i--)
g[i] = g[i + 1] + nums[i + 1];
//2.使用
for (int i = 0; i < n; i++)
if (f[i] == g[i])
return i;
return -1;
}
};
int main() {
Solution sol;
vector<int> nums1 = {1,7,3,6,5,6};
cout << "测试用例1 [1,7,3,6,5,6] 的中心下标:" << sol.pivotIndex(nums1) << endl;
vector<int> nums2 = {1,2,3};
cout << "测试用例2 [1,2,3] 的中心下标:" << sol.pivotIndex(nums2) << endl;
vector<int> nums3 = {2,1,-1};
cout << "测试用例3 [2,1,-1] 的中心下标:" << sol.pivotIndex(nums3) << endl;
vector<int> nums4 = {1};
cout << "测试用例4 [1] 的中心下标:" << sol.pivotIndex(nums4) << endl;
return 0;
}
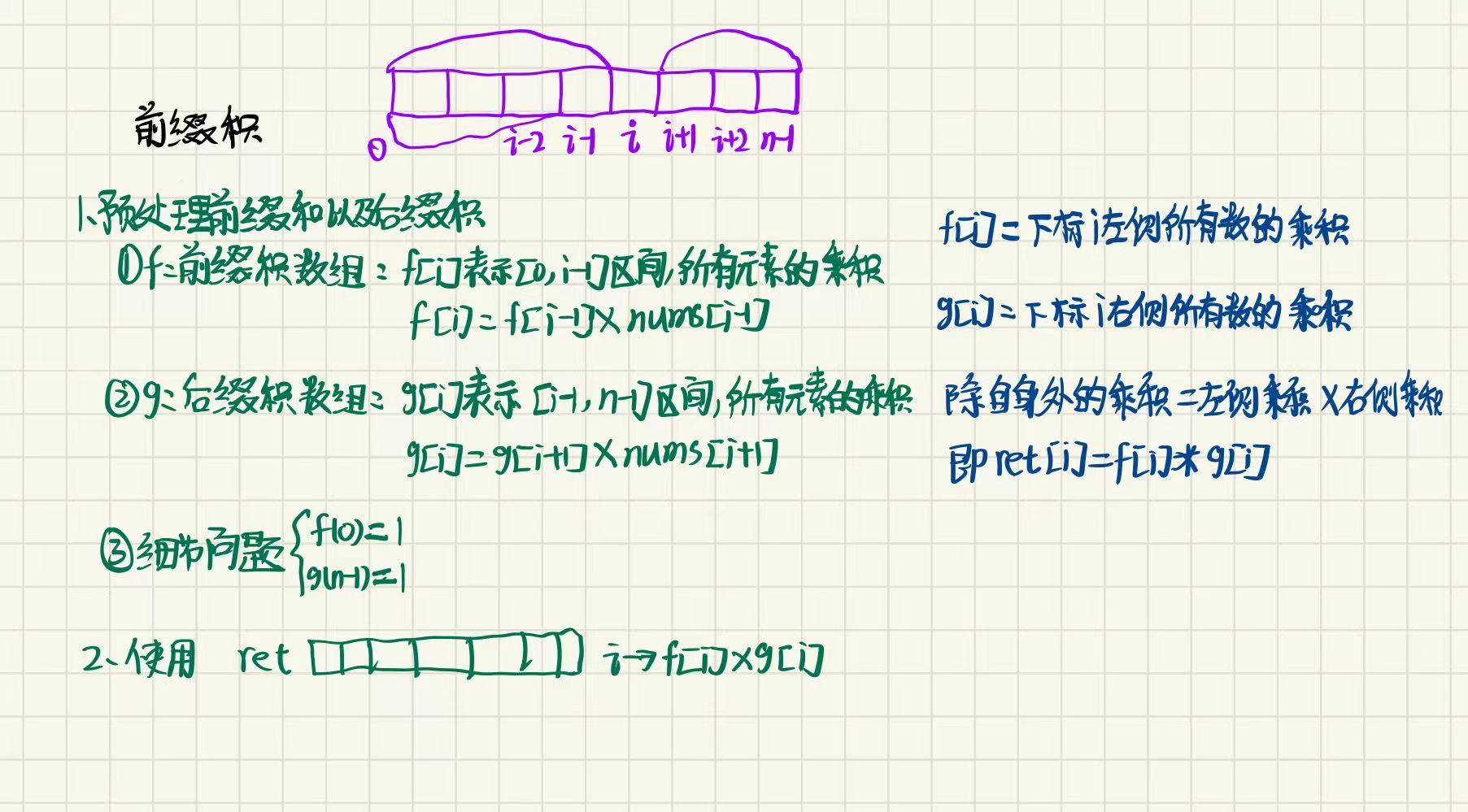
5.除了自身以外数组的乘积(OJ题)

算法思路:解法(前缀和数组)
注意题目的要求,不能使用除法,并且要在 O ( N ) O(N) O(N)的时间复杂度内完成该题.那么我们就不能使用暴力的解法,以及求出整个数组的乘积,然后除以单个元素的方法.
继续分析,根据题意,对于每一个位置的最终结果 ret[i],它是由两部分组成的:
(1)nums[0] * nums[1] * nums[2] * ... * nums[i - 1]
(2)nums[i + 1] * nums[i + 2] * ... * nums[n - 1]
于是,我们可以利用前缀和的思想,使用两个数组 f 和 g,分别处理出来两个信息:
(1)f 表示"i 位置之前的所有元素,即 [0, i - 1] 区间内所有元素的前缀乘积,
(2)g 表示:i 位置之后的所有元素,即 [i + 1, n - 1] 区间内所有元素的后缀乘积.然后再处理最终结果.
核心代码
cpp
class Solution
{
public:
vector<int> productExceptSelf(vector<int>& nums)
{
int n = nums.size();
vector<int> f(n), g(n);
// 1. 预处理一下前缀积数组以及后缀积数组
f[0] = g[n - 1] = 1; // 细节问题
for(int i = 1; i < n; i++)
f[i] = f[i - 1] * nums[i - 1];
for(int i = n - 2; i >= 0; i--)
g[i] = g[i + 1] * nums[i + 1];
// 2. 使用
vector<int> ret(n);
for(int i = 0; i < n; i++)
ret[i] = f[i] * g[i];
return ret;
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
using namespace std;
class Solution
{
public:
vector<int> productExceptSelf(vector<int>& nums)
{
int n = nums.size();
vector<int> f(n), g(n);
// 预处理前缀积数组、后缀积数组
f[0] = g[n - 1] = 1;
for(int i = 1; i < n; i++)
f[i] = f[i - 1] * nums[i - 1];
for(int i = n - 2; i >= 0; i--)
g[i] = g[i + 1] * nums[i + 1];
// 计算结果:前缀积 * 后缀积
vector<int> ret(n);
for(int i = 0; i < n; i++)
ret[i] = f[i] * g[i];
return ret;
}
};
void printVector(const vector<int>& vec) {
for (int num : vec) {
cout << num << " ";
}
cout << endl;
}
int main() {
Solution sol;
vector<int> nums1 = {1,2,3,4};
cout << "测试用例1输入:";
printVector(nums1);
vector<int> res1 = sol.productExceptSelf(nums1);
cout << "测试用例1输出:";
printVector(res1); // 预期:24 12 8 6
cout << "-------------------------" << endl;
vector<int> nums2 = {-1,1,0,-3,3};
cout << "测试用例2输入:";
printVector(nums2);
vector<int> res2 = sol.productExceptSelf(nums2);
cout << "测试用例2输出:";
printVector(res2); // 预期:0 0 9 0 0
cout << "-------------------------" << endl;
vector<int> nums3 = {2,3};
cout << "测试用例3输入:";
printVector(nums3);
vector<int> res3 = sol.productExceptSelf(nums3);
cout << "测试用例3输出:";
printVector(res3); // 预期:3 2
return 0;
}
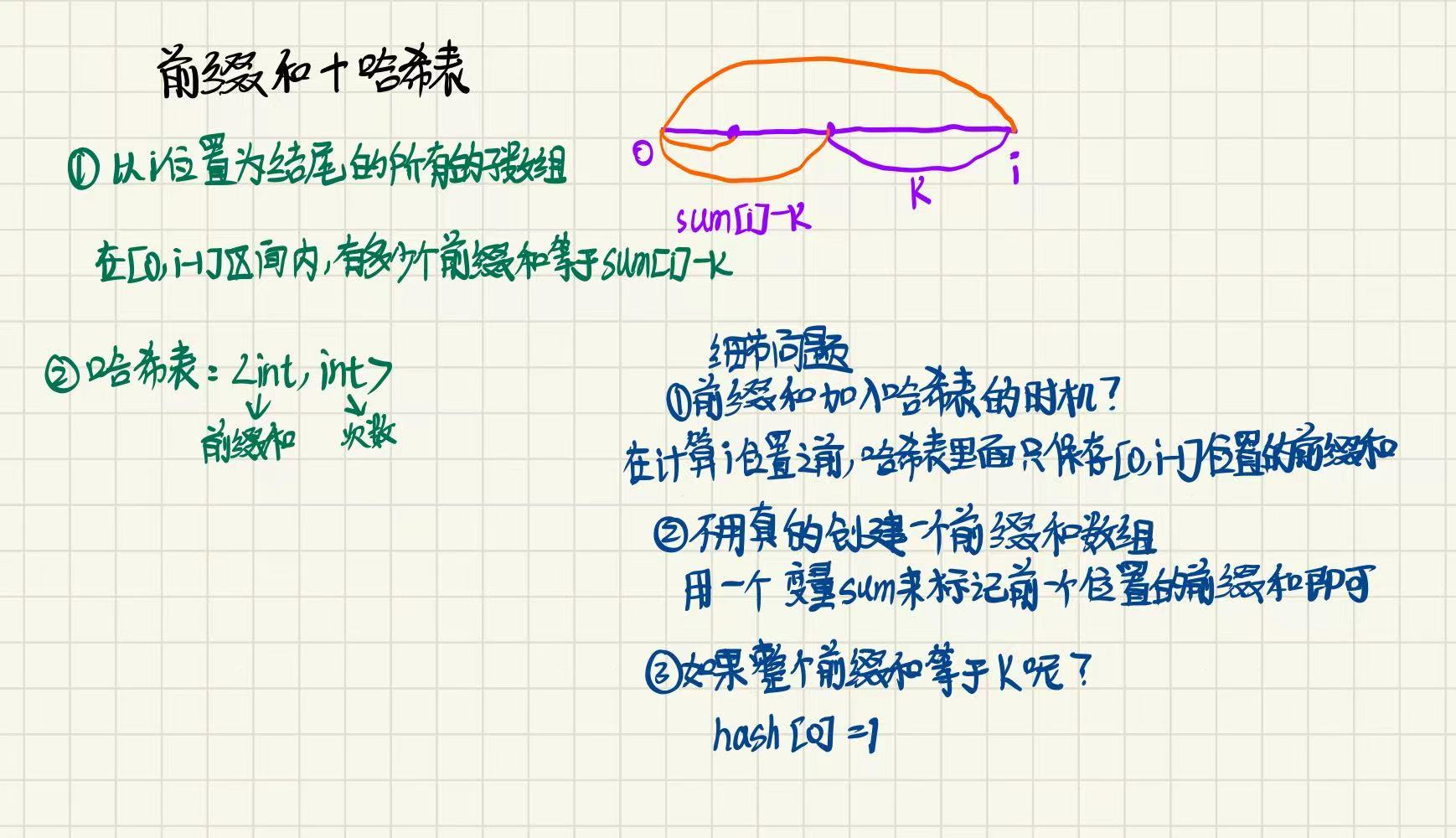
6.和为k的子数组(OJ题)

算法思路:解法(将前缀和存在哈希表中)
设 i 为数组中的任意位置,用 sum[i] 表示[0, i]区间内所有元素的和.
想知道有多少个以 i 为结尾的和为 k 的子数组,就要找到有多少个起始位置为 x1, x2, x3... 使得 [x, i] 区间内的所有元素的和为 k.那么 [0, x] 区间内的和是不是就是 sum[i] - k 了.于是问题就变成:
- 找到在
[0, i - 1]区间内,有多少前缀和等于sum[i] - k的即可.
我们不用真的初始化一个前缀和数组,因为我们只关心在 i 位置之前,有多少个前缀和等于 sum[i] - k.因此,我们仅需用一个哈希表,一边求当前位置的前缀和,一边存下之前每一种前缀和出现的次数.
核心代码
cpp
class Solution {
public:
int subarraySum(vector<int>& nums, int k)
{
unordered_map<int, int> hash; //统计前缀和出现的次数
hash[0] = 1;
int sum = 0, ret = 0;
for (auto x : nums)
{
sum += x; //计算当前位置的前缀和
if (hash.count(sum - k))
ret += hash[sum - k]; //统计个数
hash[sum]++;
}
return ret;
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <unordered_map>
using namespace std;
class Solution {
public:
int subarraySum(vector<int>& nums, int k)
{
unordered_map<int, int> hash; //统计前缀和出现的次数
hash[0] = 1; //初始化:前缀和为0的情况出现1次(关键边界)
int sum = 0, ret = 0;
for (auto x : nums)
{
sum += x; //计算当前位置的前缀和
if (hash.count(sum - k))
ret += hash[sum - k]; //统计符合条件的子数组个数
hash[sum]++; // 更新哈希表
}
return ret;
}
};
void printVector(const vector<int>& vec) {
cout << "[";
for (int i = 0; i < vec.size(); ++i) {
cout << vec[i];
if (i != vec.size() - 1) cout << ", ";
}
cout << "]";
}
int main() {
Solution sol;
vector<int> nums1 = {1, 1, 1};
int k1 = 2;
cout << "测试用例1:数组 = ";
printVector(nums1);
cout << ",k = " << k1 << endl;
cout << "结果:" << sol.subarraySum(nums1, k1) << " (预期:2)" << endl;
cout << "-------------------------" << endl;
vector<int> nums2 = {1, 2, 3};
int k2 = 3;
cout << "测试用例2:数组 = ";
printVector(nums2);
cout << ",k = " << k2 << endl;
cout << "结果:" << sol.subarraySum(nums2, k2) << " (预期:2)" << endl;
cout << "-------------------------" << endl;
vector<int> nums3 = {1};
int k3 = 1;
cout << "测试用例3:数组 = ";
printVector(nums3);
cout << ",k = " << k3 << endl;
cout << "结果:" << sol.subarraySum(nums3, k3) << " (预期:1)" << endl;
cout << "-------------------------" << endl;
vector<int> nums4 = {1};
int k4 = 0;
cout << "测试用例4:数组 = ";
printVector(nums4);
cout << ",k = " << k4 << endl;
cout << "结果:" << sol.subarraySum(nums4, k4) << " (预期:0)" << endl;
return 0;
}
7.和可被k整除的子数组(OJ题)

本题需要的前置知识:
- 同余定理
如果 ( a − b ) % n = = 0 (a - b) \% n == 0 (a−b)%n==0,那么我们可以得到一个结论: a % n = = b % n a \% n == b \% n a%n==b%n.用文字叙述就是,如果两个数相减的差能被 n n n 整除,那么这两个数对 n n n 取模的结果相同.
例如: ( 26 − 2 ) % 12 = = 0 (26 - 2) \% 12 == 0 (26−2)%12==0,那么 26 % 12 = = 2 % 12 = = 2 26 \% 12 == 2 \% 12 == 2 26%12==2%12==2.
- C++中负数取模的结果,以及如何修正负数取模的结果
- a. C++ 中关于负数的取模运算,结果是把负数当成正数,取模之后的结果加上一个负号.
例如: − 1 % 3 = − ( 1 % 3 ) = − 1 -1 \% 3 = -(1 \% 3) = -1 −1%3=−(1%3)=−1 - b. 因为有负数,为了防止发生出现负数的结果,以 ( a % n + n ) % n (a \% n + n) \% n (a%n+n)%n的形式输出保证为正.
例如: − 1 % 3 = ( − 1 % 3 + 3 ) % 3 = 2 -1 \% 3 = (-1 \% 3 + 3) \% 3 = 2 −1%3=(−1%3+3)%3=2
- a. C++ 中关于负数的取模运算,结果是把负数当成正数,取模之后的结果加上一个负号.
算法思路
思路与和为 K 的子数组这道题的思路相似.
设 i i i 为数组中的任意位置,用 s u m i sumi sumi 表示 0 , i 0, i 0,i 区间内所有元素的和.
- 想知道有多少个以 i i i为结尾的可被 k k k 整除的子数组,就要找到有多少个起始位置为 x 1 , x 2 , x 3... x1,x2,x3... x1,x2,x3... 使得 x , i x, i x,i区间内的所有元素的和可被 k k k整除.
- 设 0 , x − 1 0, x - 1 0,x−1 区间内所有元素之和等于 a a a, 0 , i 0, i 0,i 区间内所有元素的和等于 b b b,可得 ( b − a ) % k = = 0 (b - a) \% k == 0 (b−a)%k==0.
- 由同余定理可得, 0 , x − 1 0, x - 1 0,x−1 区间与 0 , i 0, i 0,i 区间内的前缀和同余.于是问题就变成:
找到在 0 , i − 1 0, i - 1 0,i−1区间内,有多少个前缀和的余数等于 s u m i % k sumi \% k sumi%k 的即可.
我们不用真的初始化一个前缀和数组,因为我们只关心在 i i i 位置之前,有多少个前缀和等于 s u m i − k sumi - k sumi−k.因此,我们仅需用一个哈希表,一边求当前位置的前缀和,一边存下之前每一种前缀和出现的次数.

核心代码
cpp
class Solution {
public:
int subarraysDivByK(vector<int>& nums, int k)
{
unordered_map<int, int> hash;
hash[0 % k] = 1; //0这个数的余数
int sum = 0, ret = 0;
for (auto x : nums)
{
sum += x; //算出当前位置的前缀和
int r = (sum % k + k) % k; //修正后的余数
if (hash.count(r))
ret += hash[r]; //统计结果
hash[r]++;
}
return ret;
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <unordered_map>
using namespace std;
class Solution {
public:
int subarraysDivByK(vector<int>& nums, int k)
{
unordered_map<int, int> hash;
hash[0 % k] = 1; //初始化:前缀和为0的余数情况出现1次
int sum = 0, ret = 0;
for (auto x : nums)
{
sum += x; //计算当前前缀和
int r = (sum % k + k) % k; //修正负数取模,保证余数为正
if (hash.count(r))
ret += hash[r]; //统计符合条件的子数组数量
hash[r]++; //更新哈希表
}
return ret;
}
};
void printVector(const vector<int>& vec) {
cout << "[";
for (int i = 0; i < vec.size(); ++i) {
cout << vec[i];
if (i != vec.size() - 1) cout << ", ";
}
cout << "]";
}
int main() {
Solution sol;
vector<int> nums1 = {4,5,0,-2,-3,1};
int k1 = 5;
cout << "测试用例1:数组 = ";
printVector(nums1);
cout << ",k = " << k1 << endl;
cout << "结果:" << sol.subarraysDivByK(nums1, k1) << " (预期:7)" << endl;
cout << "-------------------------" << endl;
vector<int> nums2 = {5};
int k2 = 9;
cout << "测试用例2:数组 = ";
printVector(nums2);
cout << ",k = " << k2 << endl;
cout << "结果:" << sol.subarraysDivByK(nums2, k2) << " (预期:0)" << endl;
cout << "-------------------------" << endl;
vector<int> nums3 = {7,4,-10};
int k3 = 5;
cout << "测试用例3:数组 = ";
printVector(nums3);
cout << ",k = " << k3 << endl;
cout << "结果:" << sol.subarraysDivByK(nums3, k3) << " (预期:1)" << endl;
cout << "-------------------------" << endl;
vector<int> nums4 = {-5};
int k4 = 5;
cout << "测试用例4:数组 = ";
printVector(nums4);
cout << ",k = " << k4 << endl;
cout << "结果:" << sol.subarraysDivByK(nums4, k4) << " (预期:1)" << endl;
return 0;
}
8.连续数组(OJ题)

算法思路
稍微转化一下题目,就会变成我们熟悉的题:
- 本题让我们找出一段连续的区间,
0和1出现的次数相同. - 如果将
0记为-1,1记为1,问题就变成了找出一段区间,这段区间的和等于0. - 于是,就和和为K的子数组这道题的思路一样.
设 i 为数组中的任意位置,用 sum[i] 表示 [0, i] 区间内所有元素的和.
想知道最大的以 i 为结尾的和为 0 的子数组,就要找到从左往右第一个 x1 使得 [x1, i] 区间内的所有元素的和为 0.那么 [0, x1 - 1] 区间内的和是不是就是 sum[i] 了.于是问题就变成:
- 找到在
[0, i - 1]区间内,第一次出现sum[i]的位置即可.
我们不用真的初始化一个前缀和数组,因为我们只关心在 i 位置之前,第一个前缀和等于 sum[i] 的位置.因此,我们仅需用一个哈希表,一边求当前位置的前缀和,一边记录第一次出现该前缀和的位置.
前缀和原理 :
如果两个下标 i 和 j 的前缀和相等 ,那么 i+1 ~ j 区间的子数组和为 0.
哈希表作用 :存储 前缀和第一次出现的下标 (只存第一次,才能保证子数组最长).
为什么 hash[0] = -1?
这是最容易困惑的点:
- 假设数组
[0,1],前缀和依次为:-1 → 0 - 当前缀和为
0时,下标是1 - 长度 =
1 - (-1) = 2,刚好是正确结果. - 如果不初始化,会丢失从数组开头就满足条件的子数组.
为什么只存前缀和第一次 出现的下标?
因为我们要最长长度 ,第一次出现的下标最小,差值最大.
如果后续重复出现相同前缀和,直接跳过,不更新哈希表.
举例演示
输入数组:nums = [0, 1, 0, 1]
转化后:[-1, 1, -1, 1]
| 下标i | 元素 | 前缀和sum | 哈希表(前缀和:下标) | 操作 | 结果ret |
|---|---|---|---|---|---|
| 初始化 | - | 0 | {0:-1} | - | 0 |
| 0 | 0 | -1 | 新增{-1:0} | 无匹配 | 0 |
| 1 | 1 | 0 | 已存在0:-1 | 1 - (-1)=2 | 2 |
| 2 | 0 | -1 | 已存在-1:0 | 2-0=2 | 2 |
| 3 | 1 | 0 | 已存在0:-1 | 3-(-1)=4 | 4 |
最终返回 4,即最长子数组长度为4 ✅
核心代码
cpp
class Solution
{
public:
//函数功能:寻找0和1数量相等的最长子数组长度
int findMaxLength(vector<int>& nums)
{
//哈希表:key = 前缀和,value = 该前缀和第一次出现的下标
unordered_map<int, int> hash;
//关键初始化:前缀和为0时,默认下标是-1
//作用:处理从数组开头到当前位置,和为0的情况
hash[0] = -1;
int sum = 0; //记录遍历过程中的前缀和
int ret = 0; //记录最终结果:最长子数组长度
//遍历数组,i是当前下标
for (int i = 0; i < nums.size(); i++)
{
//计算前缀和:0 → -1,1 → 1
sum += nums[i] == 0 ? -1 : 1;
//如果哈希表中已经存在当前前缀和
if (hash.count(sum))
{
//计算子数组长度:当前下标 - 前缀和第一次出现的下标
//并更新最大值
ret = max(ret, i - hash[sum]);
}
//如果哈希表中不存在当前前缀和
else
{
//只存储第一次出现的下标(保证长度最长)
hash[sum] = i;
}
}
return ret; //返回最长长度
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <unordered_map>
#include <algorithm>
using namespace std;
class Solution
{
public:
int findMaxLength(vector<int>& nums)
{
unordered_map<int, int> hash;
hash[0] = -1; //默认有一个前缀和为 0 的情况
int sum = 0, ret = 0;
for (int i = 0; i < nums.size(); i++)
{
sum += nums[i] == 0 ? -1 : 1; //计算当前位置的前缀和
if (hash.count(sum))
ret = max(ret, i - hash[sum]);
else
hash[sum] = i;
}
return ret;
}
};
void printVector(const vector<int>& vec) {
cout << "[";
for (int i = 0; i < vec.size(); ++i) {
cout << vec[i];
if (i != vec.size() - 1) cout << ", ";
}
cout << "]";
}
int main() {
Solution sol;
vector<int> nums1 = {0, 1};
cout << "测试用例1:数组 = ";
printVector(nums1);
cout << "\n最长子数组长度:" << sol.findMaxLength(nums1) << " (预期:2)" << endl;
cout << "-------------------------" << endl;
vector<int> nums2 = {0, 1, 0};
cout << "测试用例2:数组 = ";
printVector(nums2);
cout << "\n最长子数组长度:" << sol.findMaxLength(nums2) << " (预期:2)" << endl;
cout << "-------------------------" << endl;
vector<int> nums3 = {0,1,0,1};
cout << "测试用例3:数组 = ";
printVector(nums3);
cout << "\n最长子数组长度:" << sol.findMaxLength(nums3) << " (预期:4)" << endl;
cout << "-------------------------" << endl;
vector<int> nums4 = {0,0,0,1,1,1,0};
cout << "测试用例4:数组 = ";
printVector(nums4);
cout << "\n最长子数组长度:" << sol.findMaxLength(nums4) << " (预期:6)" << endl;
cout << "-------------------------" << endl;
vector<int> nums5 = {0};
cout << "测试用例5:数组 = ";
printVector(nums5);
cout << "\n最长子数组长度:" << sol.findMaxLength(nums5) << " (预期:0)" << endl;
return 0;
}
9.矩阵区域和(OJ题)

算法思路:
二维前缀和的简单应用题,关键就是我们在填写结果矩阵的时候,要找到原矩阵对应区域的左上角以及右下角的坐标(推荐大家画图)
左上角坐标: x 1 = i − k , y 1 = j − k x1 = i - k, y1 = j - k x1=i−k,y1=j−k,但是由于会超过矩阵的范围,因此需要对0 取一个max .因此修正后的坐标为: x 1 = max ( 0 , i − k ) x1 = \max(0, i - k) x1=max(0,i−k), y 1 = max ( 0 , j − k ) y1 = \max(0, j - k) y1=max(0,j−k);
右下角坐标: x 1 = i + k , y 1 = j + k x1 = i + k, y1 = j + k x1=i+k,y1=j+k,但是由于会超过矩阵的范围,因此需要对m - 1 ,以及n - 1 取一个min .因此修正后的坐标为: x 2 = min ( m − 1 , i + k ) x2 = \min(m - 1, i + k) x2=min(m−1,i+k), y 2 = min ( n − 1 , j + k ) y2 = \min(n - 1, j + k) y2=min(n−1,j+k).
核心代码
cpp
class Solution
{
public:
vector<vector<int>> matrixBlockSum(vector<vector<int>>& mat, int k)
{
//1.获取矩阵的 行数m、列数n
int m = mat.size(), n = mat[0].size();
//2.创建 (m+1)行*(n+1)列 的二维前缀和数组 dp
//前缀和数组统一从 下标1 开始,避免处理 0 下标复杂的边界问题
vector<vector<int>> dp(m + 1, vector<int>(n + 1));
//3.预处理:构建二维前缀和矩阵
for (int i = 1; i <= m; i++)
for (int j = 1; j <= n; j++)
//二维前缀和核心公式
dp[i][j] = dp[i - 1][j] //上方前缀和
+ dp[i][j - 1] //左方前缀和
- dp[i - 1][j - 1]//减去重复计算的左上角区域
+ mat[i - 1][j - 1]; //加上当前原矩阵的元素
//4.创建结果矩阵,大小和原矩阵一致 m*n
vector<vector<int>> ret(m, vector<int>(n));
//5.遍历原矩阵每一个位置 (i,j),计算对应区域和
for (int i = 0; i < m; i++)
for (int j = 0; j < n; j++)
{
//计算正方形区域的 左上角坐标(x1,y1)、右下角坐标(x2,y2)
//max(0, i-k):防止向上越界,最小只能到第0行
//+1:把原矩阵的0-based下标 转为 前缀和矩阵的1-based下标
int x1 = max(0, i - k) + 1;
int y1 = max(0, j - k) + 1;
//min(m-1, i+k):防止向下越界,最大只能到最后一行
//+1:转为1-based下标
int x2 = min(m - 1, i + k) + 1;
int y2 = min(n - 1, j + k) + 1;
//二维前缀和 计算子矩阵和的核心公式
ret[i][j] = dp[x2][y2] //右下角总和
- dp[x1 - 1][y2] //减去上方区域
- dp[x2][y1 - 1] //减去左方区域
+ dp[x1 - 1][y1 - 1]; //加回重复减去的左上角区域
}
//返回最终结果矩阵
return ret;
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
class Solution
{
public:
vector<vector<int>> matrixBlockSum(vector<vector<int>>& mat, int k)
{
//1.获取矩阵的 行数m、列数n
int m = mat.size(), n = mat[0].size();
//2.创建 (m+1)行*(n+1)列 的二维前缀和数组 dp
// 前缀和数组统一从 下标1 开始,避免处理 0 下标复杂的边界问题
vector<vector<int>> dp(m + 1, vector<int>(n + 1));
//3.预处理:构建二维前缀和矩阵
for (int i = 1; i <= m; i++)
for (int j = 1; j <= n; j++)
//二维前缀和核心公式
dp[i][j] = dp[i - 1][j] //上方前缀和
+ dp[i][j - 1] //左方前缀和
- dp[i - 1][j - 1]//减去重复计算的左上角区域
+ mat[i - 1][j - 1];// 加上当前原矩阵的元素
//4.创建结果矩阵,大小和原矩阵一致 m*n
vector<vector<int>> ret(m, vector<int>(n));
//5.遍历原矩阵每一个位置 (i,j),计算对应区域和
for (int i = 0; i < m; i++)
for (int j = 0; j < n; j++)
{
//计算正方形区域的 左上角坐标(x1,y1)、右下角坐标(x2,y2)
//max(0, i-k):防止向上越界,最小只能到第0行
//+1:把原矩阵的0-based下标 转为 前缀和矩阵的1-based下标
int x1 = max(0, i - k) + 1;
int y1 = max(0, j - k) + 1;
//min(m-1, i+k):防止向下越界,最大只能到最后一行
// +1:转为1-based下标
int x2 = min(m - 1, i + k) + 1;
int y2 = min(n - 1, j + k) + 1;
//二维前缀和 计算子矩阵和的核心公式
ret[i][j] = dp[x2][y2] //右下角总和
- dp[x1 - 1][y2] //减去上方区域
- dp[x2][y1 - 1] //减去左方区域
+ dp[x1 - 1][y1 - 1]; //加回重复减去的左上角区域
}
//返回最终结果矩阵
return ret;
}
};
void printMatrix(const vector<vector<int>>& mat) {
for (const auto& row : mat) {
for (int num : row) {
cout << num << "\t";
}
cout << endl;
}
}
int main() {
Solution sol;
vector<vector<int>> mat1 = {{1,2,3},{4,5,6},{7,8,9}};
int k1 = 1;
cout << "测试用例1:原矩阵(k=1)" << endl;
printMatrix(mat1);
cout << "结果矩阵:" << endl;
vector<vector<int>> res1 = sol.matrixBlockSum(mat1, k1);
printMatrix(res1);
cout << "-------------------------" << endl;
vector<vector<int>> mat2 = {{1,2,3},{4,5,6},{7,8,9}};
int k2 = 2;
cout << "测试用例2:原矩阵(k=2)" << endl;
printMatrix(mat2);
cout << "结果矩阵:" << endl;
vector<vector<int>> res2 = sol.matrixBlockSum(mat2, k2);
printMatrix(res2);
cout << "-------------------------" << endl;
vector<vector<int>> mat3 = {{5}};
int k3 = 10;
cout << "测试用例3:原矩阵(k=10)" << endl;
printMatrix(mat3);
cout << "结果矩阵:" << endl;
vector<vector<int>> res3 = sol.matrixBlockSum(mat3, k3);
printMatrix(res3);
return 0;
}

🚀真正的勇者不是流泪的人,而是含泪奔跑的人!
敬请期待下一篇文章内容:【优选算法】(实战体会位运算的逻辑思维)
每日心灵鸡汤:珍惜生命,专注当下,让自己开心的过好每一天!
一个三甲医院医生说:"人只有在即将死亡的时候才能够明白这一切.人生其实就是一场骗局,最主要的任务根本不是买房买车,也不是即时行乐,这其实是欲望,不是真相."人生就是一个梦,虚无缥缈并不真实.我们不要给自己那么多的使命感和过剩的责任感,在这个世界上,活着的我们和一只蚂蚁,一只昆虫,一只蚊子,一只甲壳虫,没有任何区别.当你走到了生命的尾声,蓦然回首,就会明白,我们追求的一切都恍若云烟,功名利禄终将变为尘土,恩怨情仇也终将随风飘散,我们在这个世间最真实的需要,不过就是内心的感受而已,我们最根本的任务不是买房买车,不是让别人羡慕,也不是过的一定要比别人好,而是可以按照自己喜欢的方式度过一生,请记住你透支健康换来的优秀,不过是人事档案里随时可替换的几行宋体字.而单位的运转齿轮从未因此停滞半分.人生不是用红头文件丈量的,而是用看见花开、听见雨声的瞬间拼凑的.毕竟,你熬的夜、拼的命、流的泪,最后都成了档案袋里轻飘飘白A4纸,而你错过的晚霞、失约的晚餐、没牵到的手,才是永远无法补录的人生正文.
