近日,Meta AI 发布了 Segment Anything Model(SAM)系列的新成员------SAM 3D,这是一套能帮我们更好地"看懂"和重建真实世界三维结构的智能工具。如果你在做 AR/VR、游戏开发,或者需要快速生成3D内容,这套模型可能会让你眼前一亮。
SAM 3D 其实包含两个"搭档":一个叫 SAM 3D Objects ,专门用来从普通图像或视频中还原物体和场景的3D形状;另一个是 SAM 3D Body,专注于识别人的身体姿态和轮廓,生成逼真的人体3D模型。这项技术的突破,意味着我们离用日常数据轻松构建数字世界的愿景又近了一步。
在日常生活中,我们能轻易地从一张照片中感知到物体的三维形状,但对计算机而言,这是一个巨大的挑战。主要难题在于,我们缺少海量的、带有精确三维模型的真实世界图片来训练人工智能。现有的模型大多在干净的、单个物体的合成图像上表现不错,一旦进入充满遮挡和混乱的真实场景,效果就大打折扣,这极大地限制了3D技术在机器人、增强现实等领域的应用。
为了攻克这一难题,本论文提出了一个结合合成数据与真实世界数据进行多阶段训练的生成模型框架。这个名为SAM 3D的模型,通过一个创新的"人与模型在环"的数据标注流程,以前所未有的规模收集了真实世界图像的3D数据。最终,SAM 3D在处理真实、复杂的图像时,其3D重建效果远超现有方法,在人类偏好测试中获得了压倒性的胜利,为实现"万物皆可3D化"迈出了关键一步。
另外我整理了计算机视觉入门指南,包含:机器学习数学神书、Python+机器学习+深度学习系列课程、图像处理、目标检测、SCI论文写作技巧、绘图模板等干货资料,感兴趣的自取。
一、论文基本信息
论文标题: SAM 3D: 3Dfy Anything in Images
作者姓名: SAM 3D Team Xingyu Chen,Fu-Jen Chu,Pierre Gleize,Kevin J Liang,Alexander Sax,Hao Tang,Weiyao Wang,Michelle Guo,Thibaut Hardin,Xiang Li,Aohan Lin,Jiawei Liu,Ziqi Ma,Anushka Sagar,Bowen Song,Xiaodong Wang,
Jianing Yang,Bowen Zhang,Piotr Dollar,Georgia Gkioxari,Matt Feiszli,Jitendra Malik
作者单位/机构: Meta Superintelligence Labs
论文链接: SAM 3D Objects: https://ai.meta.com/research/publications/sam-3d-3dfy-anything-in-images/
项目主页: https://ai.meta.com/sam3d/
二、主要贡献与创新

- 发布了SAM 3D,一个能从单张图片精确预测物体完整3D形状、纹理和空间姿态的新基础模型。
- 构建了创新的模型在环(MITL)数据标注流水线,以前所未有的规模解决了真实世界3D标注数据稀缺的难题。
- 成功将大语言模型的训练范式迁移至3D领域,通过多阶段训练框架有效结合了合成数据与真实世界数据。
- 发布了SA-3DAO基准,一个由专业3D艺术家创建的高质量评测集,用于推动真实世界3D重建研究。
三、研究方法与原理
该论文提出的模型核心思路是:通过一个两阶段的生成模型,先预测物体的粗略几何形状和空间布局,再对细节和纹理进行精化和上色,从而实现高质量的3D重建。
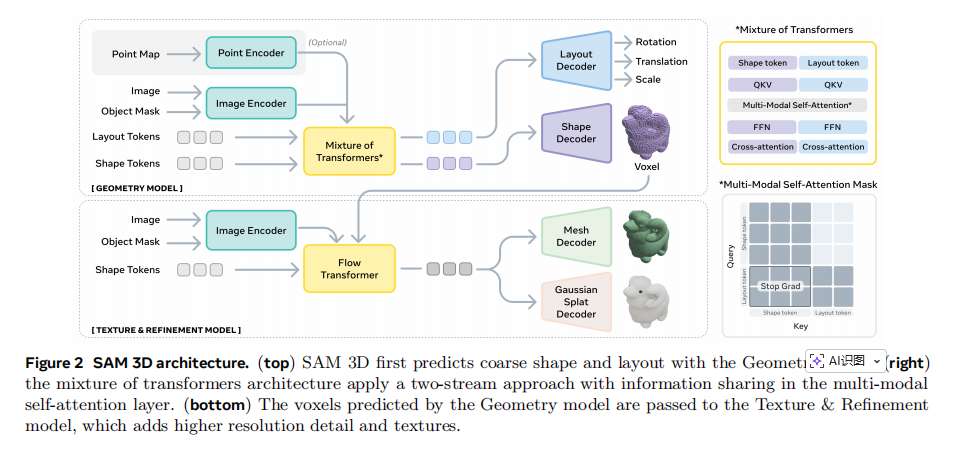
如图2所示,SAM 3D的整体架构分为两个核心模型:几何模型和纹理与精化模型,它们共同协作完成从2D图像到3D资产的转换。
模型整体架构
首先,模型接收一张图片和一个指示目标物体的掩码(mask)作为输入。为了同时捕捉物体的局部细节和全局场景信息,模型使用了一个强大的视觉特征提取器 (DINOv2) 作为编码器 (encoder) ,分别对裁剪后的物体图像 和完整的场景图像进行编码,生成四组不同的特征信息。这种设计让模型既能聚焦于目标,又不会忽视其在环境中的上下文关系。
-
几何模型 (Geometry Model)
这个模型是一个拥有12亿参数的transformer ,它的任务是基于输入的图像特征,联合预测物体的粗略形状、旋转、平移和缩放 。其目标是学习一个条件概率分布 p ( S , T , R , t , s ∣ I , M ) p(S,T,R,t,s|I,M) p(S,T,R,t,s∣I,M),其中 S S S 是形状, T T T 是纹理, R , t , s R,t,s R,t,s 分别代表旋转、平移和缩放。
该模型采用了创新的混合transformer (Mixture-of-Transformers, MoT) 架构。该架构内部包含两个独立的transformer流,一个专门处理形状信息(表示为 6 4 3 64^3 643 的体素),另一个处理位姿信息( R , t , s R,t,s R,t,s)。通过精巧的注意力掩码设计,这两个流可以独立训练,但在前向传播时又能通过共享的自注意力层进行信息交互。这种设计既保证了模块的灵活性,又实现了形状与位姿预测的内在一致性。
-
纹理与精化模型 (Texture & Refinement Model)
在几何模型输出了一个 64 × 64 × 64 64 \times 64 \times 64 64×64×64 分辨率的粗略形状 O O O 后,纹理与精化模型便开始工作。这是一个拥有6亿参数的稀疏潜在流transformer。它首先从粗略形状中提取出有效的体素部分,然后在其基础上增加更高分辨率的几何细节,并合成逼真的物体表面纹理 。这一步的目标是学习条件分布 p ( S , T ∣ I , M , O ) p(S,T|I,M,O) p(S,T∣I,M,O),使得最终生成的3D模型不仅形状完整,而且外观生动。
创新的多阶段训练范式
为了跨越3D训练数据的"数据鸿沟",SAM 3D借鉴了大语言模型的成功经验,设计了一套从易到难、从合成到真实的多阶段训练 (multi-stage training) 范式,如图4 所示。整个训练过程使用条件流匹配 (Conditional Rectified Flow Matching) 作为核心目标函数,其损失函数定义为:
L CFM = ∑ m ∈ M λ m E τ , x 0 m ∥ v m − v θ m ( x τ m , c , τ ) ∥ 2 \mathcal{L}{\text{CFM}} = \sum{m \in \mathcal{M}} \lambda_m \mathbb{E}_{\tau, x_0^m} \left \\\|v\^m - v_\\theta\^m(x_\\tau\^m, c, \\tau)\\\|\^2 \\right LCFM=m∈M∑λmEτ,x0m∥vm−vθm(xτm,c,τ)∥2
这个公式的核心思想是训练一个神经网络 v θ m v_\theta^m vθm 来预测一个"速度场",这个速度场可以将一个随机噪声点 x 0 m x_0^m x0m "推动"到目标数据点 x 1 m x_1^m x1m(即真实的3D模型)。
整个训练流程分为三个关键步骤:
-
第一步:预训练 (Pre-training)
在这一阶段,模型仅在海量的合成数据 (Iso-3DO) 上进行训练。这些数据包含270万个独立的3D物体模型,通过在不同视角下渲染生成。这个阶段的目的是让模型学习到关于物体形状和纹理的丰富先验知识,建立一个强大的3D"词汇表"。
-
第二步:中间训练 (Mid-Training)
为了让模型学会处理真实世界中的遮挡和复杂布局,研究者们创造了一种名为**"渲染并粘贴 (render-paste)"** 的半合成数据 (RP-3DO)。他们将合成的3D模型以符合物理规律的方式"贴"到真实的背景图片中,并人为制造遮挡。通过在这个包含6100万样本的数据集上训练,模型学会了从遮挡中补全形状 ,并估计物体在场景中的准确位置。
-
第三步:后训练 (Post-Training)
这是SAM 3D最具创新性的部分,旨在让模型的能力与真实世界和人类的偏好对齐。此阶段包含两个核心环节:
- 数据收集 :研究者们建立了一个模型在环 (Model-in-the-Loop, MITL) 的数据引擎,如图5 所示。对于一张真实图片中的物体,系统会调用包括SAM 3D自身在内的多个模型生成若干个候选3D模型。普通标注员的任务不再是凭空创造3D模型,而是从这些选项中选出最佳的一个,并将其位姿与场景对齐。对于模型完全无法处理的"硬骨头"案例,则交由专业的3D艺术家手动创建。这个流程极大地降低了标注门槛,从而以前所未有的规模(近百万张图片)获得了宝贵的真实世界3D数据。
- 模型提升 :收集到的数据被用于进一步优化模型。首先,通过监督微调 (Supervised Finetuning, SFT) ,模型在这些高质量的真实数据上进行学习,以弥合合成数据与真实世界之间的领域差异。随后,利用标注过程中产生的"偏好对"(即被选中的模型 vs. 被拒绝的模型),模型通过**直接偏好优化 (Direct Preference Optimization, DPO)**进行对齐。DPO的目标函数如下:
L DPO = − E log σ ( − β T w ( τ ) ⋅ Δ ) \mathcal{L}_{\text{DPO}} = -\mathbb{E} \left \\log \\sigma \\left( -\\beta T w(\\tau) \\cdot \\Delta \\right) \\right LDPO=−Elogσ(−βTw(τ)⋅Δ)
其中 Δ \Delta Δ 项衡量了模型在"偏好"样本上的损失与在"不偏好"样本上的损失之差。通过优化此目标,模型被引导去生成更符合人类审美和准确性偏好的结果,例如消除悬浮碎片、保证对称性等。
四、实验设计与结果分析
论文的实验部分设计得非常全面,旨在验证SAM 3D在真实世界场景中的3D重建能力。实验使用了多个数据集,包括新提出的SA-3DAO (包含1000个由艺术家从真实图片创建的高精度3D模型)、ISO3D (无3D真值的真实图片集)和Aria Digital Twin (ADT) (带有精确传感器数据的室内场景)。评测指标涵盖几何精度(F-score, vIoU, Chamfer Distance)、感知相似度(ULIP, Uni3D)和位姿准确度(3D IoU, ADD-S)。
与SOTA方法的对比实验
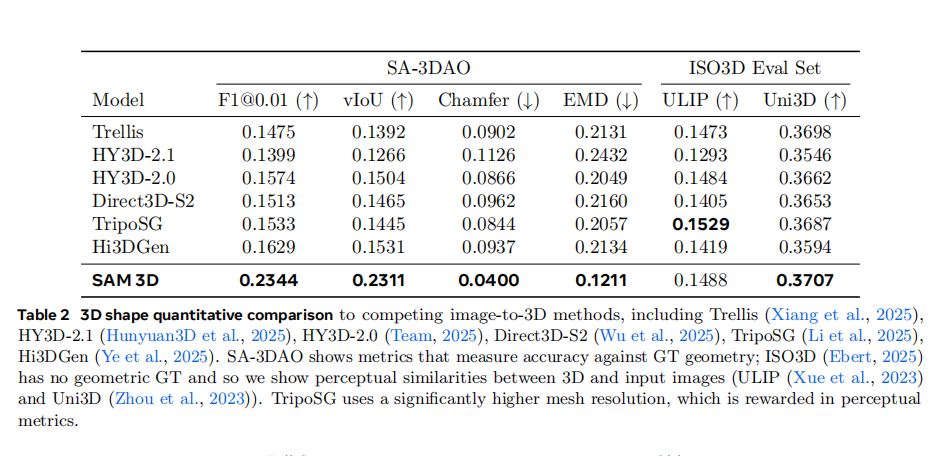
在3D形状和纹理质量的对比中,如表2 所示,SAM 3D在处理具有挑战性的真实世界数据SA-3DAO时,各项指标均显著优于 所有其他方法。例如,在F1@0.01指标上,SAM 3D达到了0.2344,而其他模型的最高分仅为0.1629。这表明SAM 3D在几何精度上取得了巨大突破。图6中的可视化对比也直观地展示了这一点,即使在物体被严重遮挡的情况下,SAM 3D依然能重建出完整且合理的形状,而其他模型则常常产生破碎或扭曲的结果。
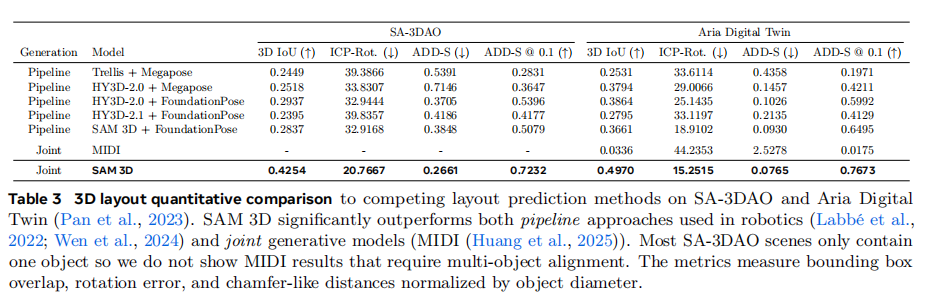
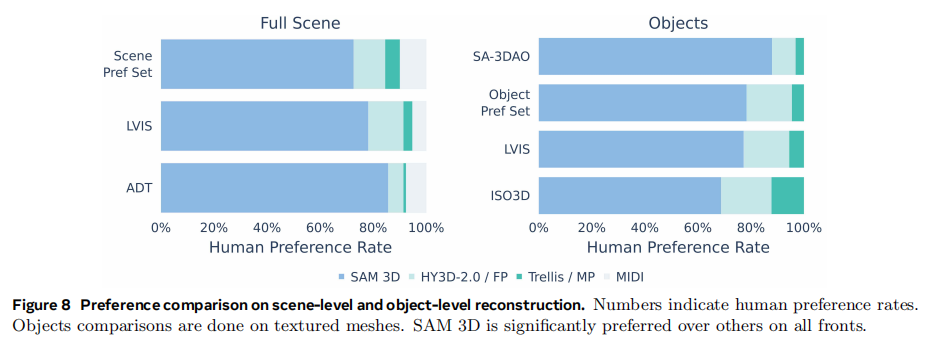
在完整的场景重建(包括物体位姿)方面,如表3 所示,SAM 3D同样表现出色。与将其他3D生成模型与位姿估计模型组合的"流水线"方法相比,SAM 3D的端到端联合预测方法在SA-3DAO和ADT数据集上的精度都更高。特别是在ADD-S@0.1(位姿误差小于物体直径10%的样本比例)这一关键指标上,SAM 3D在ADT数据集上达到了76.7% ,远高于其他方法。图8 的人类偏好测试结果更具说服力,无论是在单个物体还是整个场景的重建上,SAM 3D都以超过5:1甚至6:1的胜率碾压了竞争对手。
分析研究 (Ablation Studies)
为了验证其方法设计的有效性,论文进行了一系列消融实验。
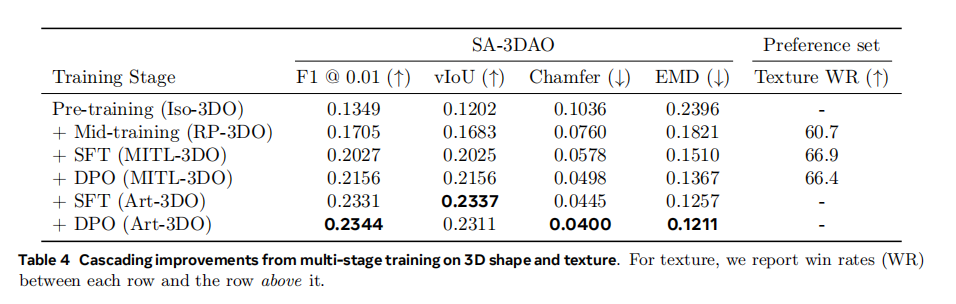
- 多阶段训练的有效性 :表4 展示了逐步增加训练阶段对模型性能的影响。从仅使用合成数据预训练开始,每增加一个训练阶段(中间训练、SFT、DPO),模型在SA-3DAO上的性能几乎都是单调提升的。例如,加入中间训练后,Chamfer Distance从0.1036降至0.0760;在加入了所有真实世界数据和DPO对齐后,最终降至0.0400。这有力地证明了论文提出的多阶段训练范式的每一个环节都至关重要。
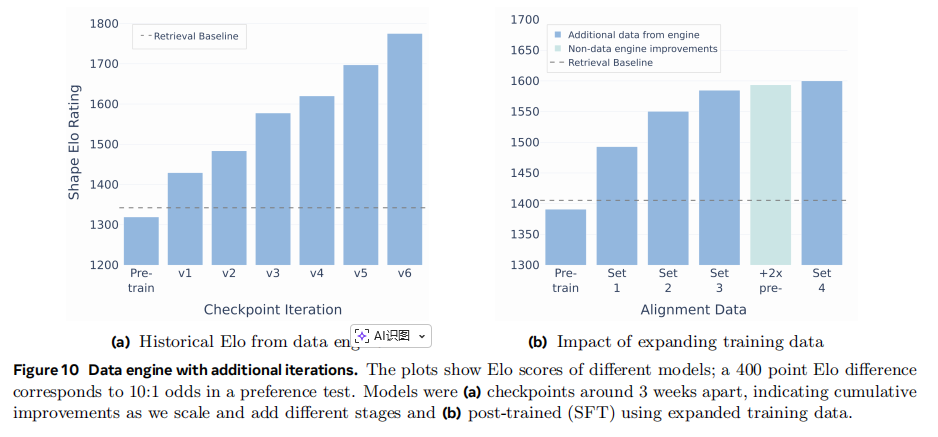
- 数据引擎迭代的效果 :图10 展示了数据引擎迭代对模型性能的持续提升作用。图10a 的Elo评分历史图显示,随着数据引擎的不断运行和模型的持续迭代,模型的相对性能稳步增长,验证了"模型-数据"飞轮效应。图10b则表明,仅仅增加真实世界训练数据的规模,模型性能也能持续改善,尽管边际效应会递减。
五、论文结论与评价
总结
理论上 ,SAM 3D成功地将大语言模型中成熟的多阶段训练和对齐范式迁移到了3D视觉领域,证明了结合大规模合成数据预训练和精细化真实世界数据对齐是克服3D数据瓶颈的有效路径。实验上,SAM 3D在多个基准上取得了当前最佳性能,尤其是在处理充满遮挡和背景干扰的真实世界图像时,其重建质量远超以往方法。这项研究为未来的3D感知和生成技术指明了一个清晰的方向,即通过构建高效的数据引擎和先进的训练策略,可以逐步实现对现实世界中任意物体的精确3D重建,这将对机器人、AR/VR、内容创作等领域产生深远影响。
优点
- 数据引擎的革命性 :本文最大的亮点是其模型在环(MITL)数据引擎。它巧妙地将高难度的3D建模任务转化为普通标注员也能完成的"选择"和"对齐"任务,极大地提升了真实世界3D数据的生产效率和规模,是解决该领域核心痛点的关键一步。
- 卓越的真实世界泛化能力:与许多在"温室"里(合成数据)训练和测试的模型不同,SAM 3D直面真实世界的复杂性。实验结果充分证明,它在处理遮挡、光照变化和多样的物体类别时具有极强的鲁棒性和泛化能力。
- 系统性的方法论:论文提出的**"预训练-中间训练-后训练"**三步走框架非常系统和完整。它不仅构建了一个强大的基础模型,还通过SFT和DPO等手段确保模型最终能生成符合人类偏好的高质量结果,为构建强大的感知模型提供了一套可参考的"操作手册"。
缺点
- 分辨率和精细度有限 :模型生成的粗略几何形状分辨率为 6 4 3 64^3 643,这对于重建一些具有复杂细节(如人脸、手部)或精细结构(如蕾丝)的物体来说,仍然显得不足,可能导致细节丢失或形状过于平滑。
- 缺乏物理交互和场景一致性:SAM 3D目前是逐个物体进行重建,没有显式地对物体间的物理关系(如接触、支撑、无穿模)进行建模。因此,在重建整个场景时,可能会出现物体悬空或相互穿插等不符合物理常识的情况。
- 纹理与姿态的耦合问题:由于纹理预测和姿态预测是相对独立的,对于那些具有旋转对称性的物体(如瓶子),模型有时会预测出与物体几何朝向不匹配的纹理,相当于将纹理"旋转"到了错误的位置。后续研究可以考虑将姿态信息作为纹理生成的条件,以解决这一问题。