详细笔记在:
lesson1:神经网络和深度学习(Neural Networks and Deep Learning)
Week1:Introduction
1. 什么是神经网络
2. 神经网络的监督学习与非监督学习

图像处理上我们一般会用到CNN
对于序列数据来说,RNN是比较常用的。英语和汉字字母表或单词都是逐个出现的,所以语言也是最子让的序列数据(NLP领域,Transformer解读 transformer是比RNN更佳的网络)
3. 结构化数据和非结构化数据
4. 深度学习为什么会兴起?
数据量变大了,而深度学习符合数据量越大或者网络越大性能越好
5. ReLU与Sigmoid之间的区别
Week2:Basics of Neural Network programming
1. 二分类
此节主要介绍一些符号与记号
2. 逻辑回归
3. 逻辑回归的代价函数与损失函数
损失函数(Loss Function) 针对单个样本,衡量模型对一个训练样本的预测误差:
代价函数(Cost Function) 针对整个训练集,是所有样本损失的某种汇总(通常是均值):
常见损失函数 :
回归任务
|-------------|----------------------------------------------------------------|------------------------|
| 名称 | 公式 | 特点 |
| MSE(均方误差) | | 对大误差惩罚重,对异常值敏感 |
| MAE(平均绝对误差) |  | 对异常值鲁棒,但不可微 |
| Huber Loss | MSE+MAE 的混合 | 小误差用 MSE,大误差用 MAE,兼顾两者 |
分类任务
|------------|------------------------------------------------------------|----------------|
| 名称 | 公式 | 特点 |
| 交叉熵(CE) | | 最常用的分类损失 |
| 二元交叉熵(BCE) | | 用于二分类 |
| Focal Loss | | 解决类别不均衡,抑制易分样本 |
| Hinge Loss | | SVM 常用,适合间隔最大化 |
4. 梯度下降算法
梯度就是曲线的曲线斜率
学习率就是每一步要下降多少
批量梯度下降(BGD)
随机梯度下降(SGD)
小批量梯度下降(MBGD)
梯度下降无法保证找到全局最优 有可能会陷入局部最优
5. 梯度消失与梯度爆炸
梯度消失 :反向传播时梯度在链式相乘过程中越来越小
梯度爆炸: 反向传播时梯度在 链式相乘过程中越来越大
反向传播的链式法则:
每一层都乘以一个雅可比矩阵,层数一深,就成了连乘。
📉 梯度消失详解
Sigmoid/Tanh 的致命弱点:两者的导数最大值分别为 0.25 和 1,在饱和区(输入较大/较小时)导数趋近于 0。
Sigmoid 导数:σ'(x) = σ(x)(1-σ(x)) ≤ 0.25100 层网络连乘:0.25100≈10−600.25{100} \approx 10{-60} 0.25100≈10−60,梯度完全消失。
症状:
- Loss 下降极慢甚至不动
- 浅层参数几乎不变,模型"学不动"
- 深层正常,浅层失效
📈 梯度爆炸详解
权重矩阵较大时,每层雅可比的范数 > 1,连乘后梯度指数级膨胀。
症状:
- Loss 出现 NaN 或 Inf
- 参数更新剧烈,模型震荡发散
- 在 RNN 中尤为常见(长序列 = 深层连乘)
🛠️ 解决方案对比
|-----------------------------|------|------|------------------|
| 方法 | 解决消失 | 解决爆炸 | 说明 |
| ReLU 激活函数 | ✅ | ❌ | 正区间导数恒为 1,不饱和 |
| BatchNorm | ✅ | ✅ | 每层归一化,稳定分布 |
| 梯度裁剪(Gradient Clipping) | ❌ | ✅ | 限制梯度范数上限,RNN 常用 |
| 残差连接(ResNet) | ✅ | ✅ | 梯度可直接流过跳跃连接 |
| 合理权重初始化(Xavier/He) | ✅ | ✅ | 让初始梯度在合理范围内 |
| LSTM/GRU | ✅ | 部分 | 门控机制控制梯度流动 |
| 层归一化(LayerNorm) | ✅ | ✅ | Transformer 中的标配 |
6. 反向传播算法/计算图
- 反向传播算法是为了加速计算参数梯度值的方法
- 可以借助计算图
7. 逻辑回归梯度下降
详细证明在逻辑回归梯度下降这文档中
多样本梯度下降
8. 向量化
向量化能够使计算效率更高
向量化是非常基础的去除代码中for循环的艺术,在深度学习安全领域、深度学习实践中,你会经常发现自己训练大数据集,因为深度学习算法处理大数据集效果很棒,所以你的代码运行速度非常重要,否则如果在大数据集上,你的代码可能花费很长时间去运行,你将要等待非常长的时间去得到结果。所以在深度学习领域,运行向量化是一个关键的技巧,让我们举个栗子说明什么是向量化。
在逻辑回归中你需要去计算
,
、
都是列向量。如果你有很多的特征那么就会有一个非常大的向量,所以
,
,所以如果你想使用非向量化方法去计算

,你需要用如下方式(python)
z=0
for i in range(n_x):
z += w[i]*x[i]
z += b这是一个非向量化的实现,你会发现这真的很慢,作为一个对比,向量化实现将会非常直接计算
,代码如下:
z=np.dot(w,x)+b
这是向量化计算
的方法,你将会发现这个非常快
让我们用一个小例子说明一下,在我的我将会写一些代码(以下为教授在他的Jupyter notebook 上写的Python代码,)
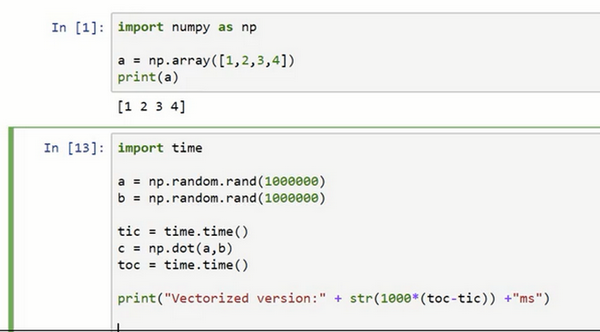
import numpy as np #导入numpy库
a = np.array([1,2,3,4]) #创建一个数据a
print(a)
# [1 2 3 4]
import time #导入时间库
a = np.random.rand(1000000)
b = np.random.rand(1000000) #通过round随机得到两个一百万维度的数组
tic = time.time() #现在测量一下当前时间
#向量化的版本
c = np.dot(a,b)
toc = time.time()
print("Vectorized version:" + str(1000*(toc-tic)) +"ms") #打印一下向量化的版本的时间
#继续增加非向量化的版本
c = 0
tic = time.time()
for i in range(1000000):
c += a[i]*b[i]
toc = time.time()
print(c)
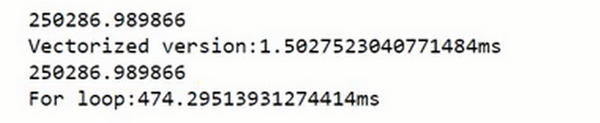
print("For loop:" + str(1000*(toc-tic)) + "ms")#打印for循环的版本的时间返回值见图。
在两个方法中,向量化和非向量化计算了相同的值,如你所见,向量化版本花费了1.5毫秒,非向量化版本的for 循环花费了大约几乎500毫秒,非向量化版本多花费了300倍时间。所以在这个例子中,仅仅是向量化你的代码,就会运行300倍快。这意味着如果向量化方法需要花费一分钟去运行的数据,for循环将会花费5个小时去运行。
一句话总结,以上都是再说和for循环相比,向量化可以快速得到结果。
你可能听过很多类似如下的话,"大规模的深度学习使用了GPU 或者图像处理单元实现",但是我做的所有的案例都是在jupyter notebook 上面实现,这里只有CPU ,CPU 和GPU 都有并行化的指令,他们有时候会叫做SIMD 指令,这个代表了一个单独指令多维数据,这个的基础意义是,如果你使用了built-in 函数,像np.function或者并不要求你实现循环的函数,它可以让python 的充分利用并行化计算,这是事实在GPU 和CPU 上面计算,GPU 更加擅长SIMD 计算,但是CPU 事实上也不是太差,可能没有GPU 那么擅长吧。接下来的视频中,你将看到向量化怎么能够加速你的代码,经验法则是,无论什么时候,避免使用明确的for循环。
以下代码及运行结果截图:

9. 向量化逻辑回归

为了计算

,numpy命令是

。这里在Python中有一个巧妙的地方,这里

是一个实数,或者你可以说是一个

矩阵,只是一个普通的实数。但是当你将这个向量加上这个实数时,Python自动把这个实数
扩展成一个

的行向量。所以这种情况下的操作似乎有点不可思议,它在Python 中被称作广播(brosdcasting)。
10.向量化逻辑回归的梯度输出
注:本节中大写字母代表向量,小写字母代表元素
如何向量化计算的同时,对整个训练集预测结果

,这是我们之前已经讨论过的内容。在本次视频中我们将学习如何向量化地计算

个训练数据的梯度,本次视频的重点是如何同时计算
个数据的梯度,并且实现一个非常高效的逻辑回归算法**(Logistic Regression**)。
之前我们在讲梯度计算的时候,列举过几个例子,

,

......等等一系列类似公式。现在,对
个训练数据做同样的运算,我们可以定义一个新的变量

,所有的

变量横向排列,因此,

是一个
的矩阵,或者说,一个
维行向量。在之前的幻灯片中,我们已经知道如何计算

,即

,我们需要找到这样的一个行向量

,由此,我们可以这样计算

,不难发现第一个元素就是

,第二个元素就是

......所以我们现在仅需一行代码,就可以同时完成这所有的计算。
在之前的实现中,我们已经去掉了一个for 循环,但我们仍有一个遍历训练集的循环,如下所示:



.............





.............


上述(伪)代码就是我们在之前实现中做的,我们已经去掉了一个for循环,但用上述方法计算

仍然需要一个循环遍历训练集,我们现在要做的就是将其向量化!
首先我们来看

,不难发现 $


dz{i)}

dZ



dw

dw=\\frac{1}{m}*X*dz{T}

X




$这样,我们就避免了在训练集上使用for循环。
Week3:One hidden layer Neural Networks
1.神经网络概览

2.神经网络表示方法
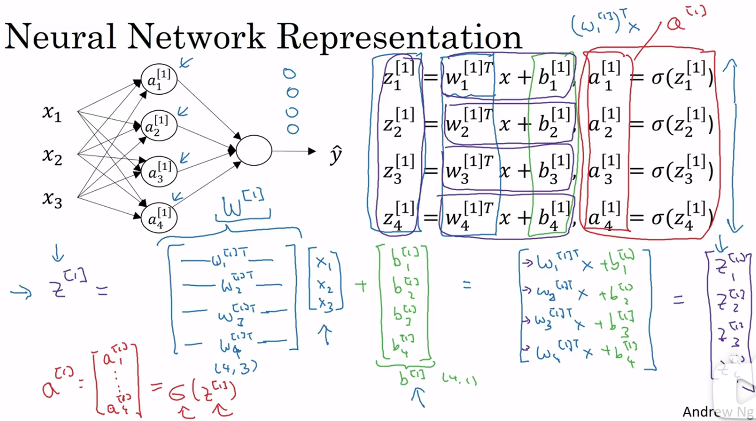
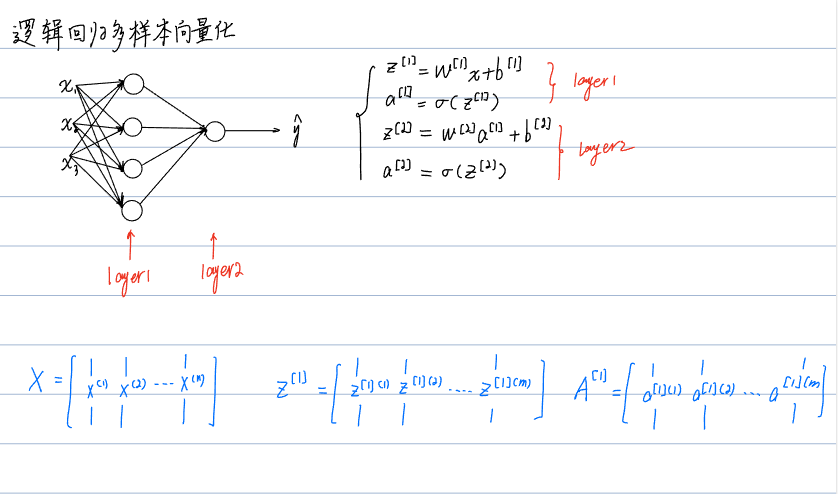
3.多样本向量化
为什么激活后还要再乘权重 + 偏置
激活函数只做「非线性变形」,不做特征融合;W 和 b 才是用来组合特征、提取新特征的
一、完整单层流程
- 上层输出 → 乘 W + 加 b(线性组合)
- 送入激活函数(加非线性)
- 得到本层结果 → 再拿去下一层继续乘 W+b
二、通俗解释
-
激活函数能干啥
只弯曲线条、打破线性,不能重新组合特征
比如:把负数压成 0、把值缩到 0~1,只改数值形态
-
W 权重 + b 偏置能干啥 把上一层所有神经元的信息加权融合 决定哪些特征重要、哪些不重要,生成全新特征
- 没有
Wx+b会怎样 每层输出原样传递,网络学不到任何新规律,等于白搭
三、极简原理
- W+b = 特征融合
- 激活函数 = 非线性变换
先融合特征,再扭曲非线性,层层重复才能深度学习
4.激活函数
sigmoid函数就是一种激活函数
激活函数的作用是引入非线性,如果没有激活函数,多层神经网络本质上等价于一个线性变换
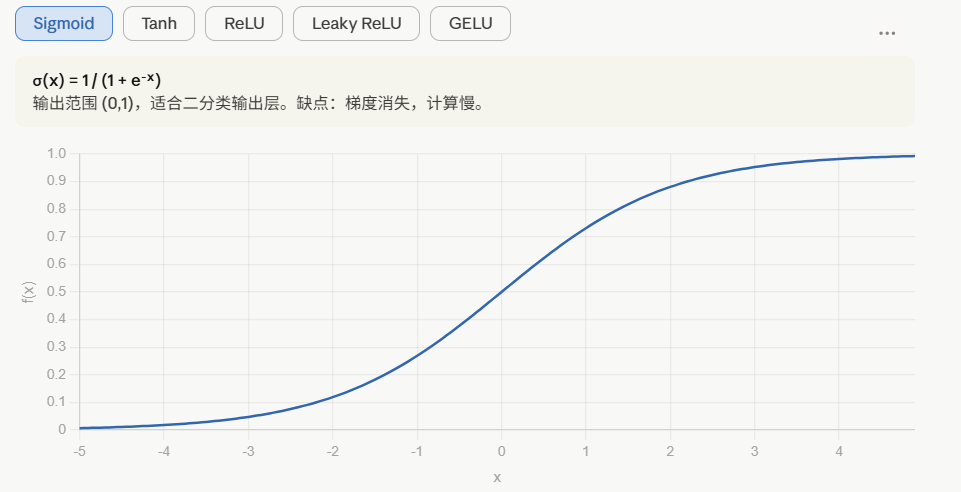
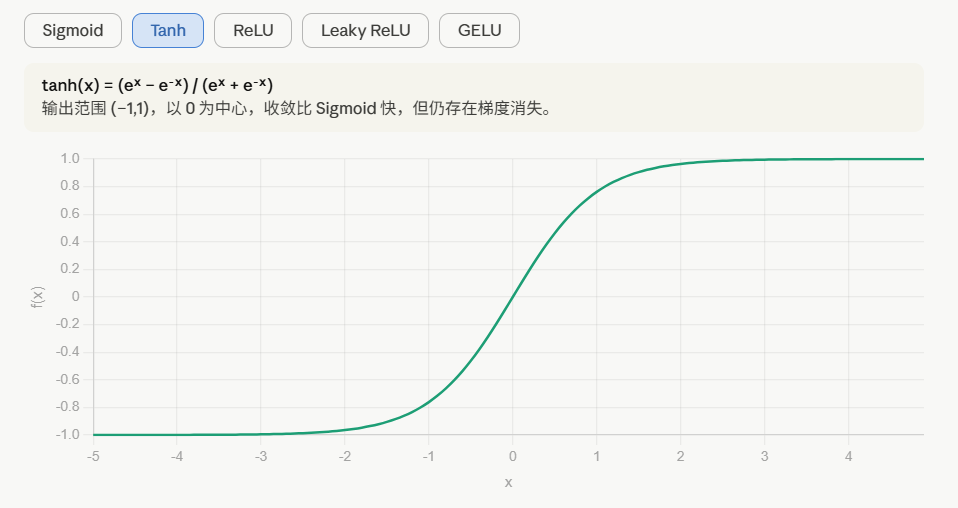
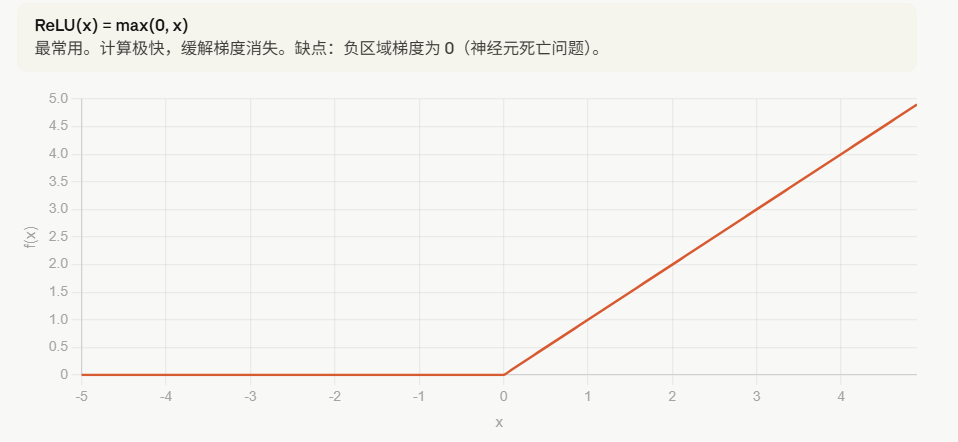
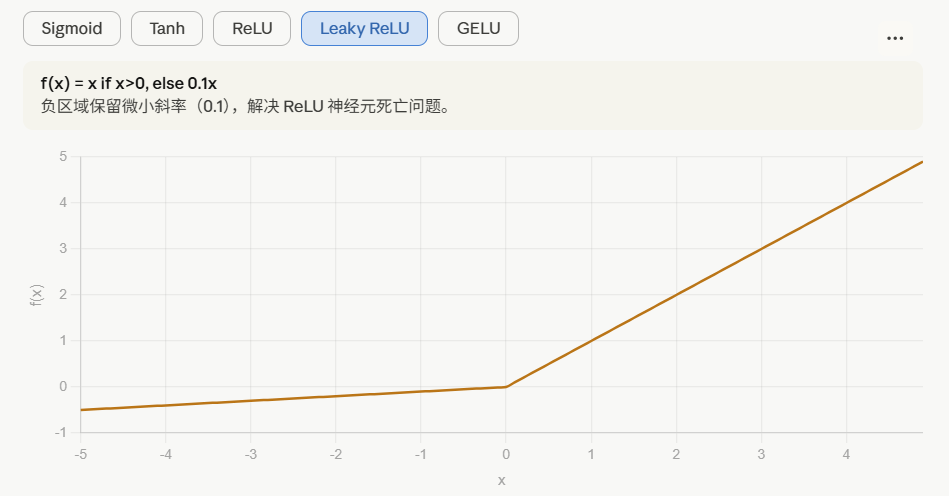
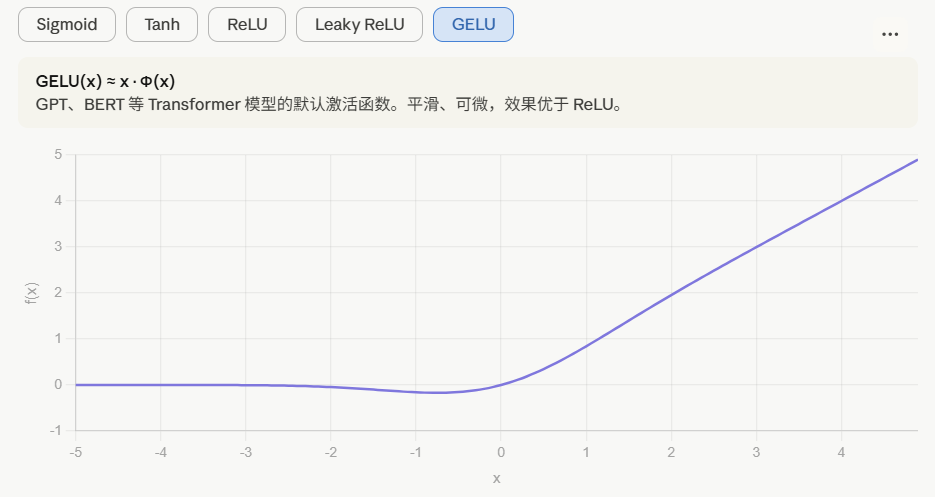

选择激活函数的经验法则:
如果输出是0、1值(二分类问题),则输出层选择sigmoid 函数,然后其它的所有单元都选择Relu函数。
这是很多激活函数的默认选择,如果在隐藏层上不确定使用哪个激活函数,那么通常会使用Relu 激活函数。有时,也会使用tanh 激活函数,但Relu的一个优点是:当

是负值的时候,导数等于0。
这里也有另一个版本的Relu 被称为Leaky Relu。
当

是负值时,这个函数的值不是等于0,而是轻微的倾斜,如图。
这个函数通常比Relu 激活函数效果要好,尽管在实际中Leaky ReLu使用的并不多。
5.为什么需要非线性激活函数
深度网络,有很多层的神经网络,很多隐藏层。事实证明,如果你使用线性激活函数或者没有使用一个激活函数,那么无论你的神经网络有多少层一直在做的只是计算线性函数,所以不如直接去掉全部隐藏层。在我们的简明案例中,事实证明如果你在隐藏层用线性激活函数,在输出层用sigmoid 函数,那么这个模型的复杂度和没有任何隐藏层的标准Logistic回归是一样。
总而言之,不能在隐藏层用线性激活函数,可以用ReLU 或者tanh 或者leaky ReLU或者其他的非线性激活函数,唯一可以用线性激活函数的通常就是输出层;除了这种情况,会在隐层用线性函数的,除了一些特殊情况,比如与压缩有关的,那方面在这里将不深入讨论。在这之外,在隐层使用线性激活函数非常少见。
6.激活函数的导数
7.神经网络梯度下降
Cost function :
公式:

loss function 和之前做logistic回归完全一样。
Forward propagation :
(1)

(2)

(3)

(4)

Back propagation :
公式3.32:

公式3.33:

公式3.34:

公式3.35:
dz^{1} = \underbrace{W^{2T}{\rm d}z^{2}}{(n^{1},m)}\quad*\underbrace{{g^{1}}^{'}}{activation \; function \; of \; hidden \; layer}*\quad\underbrace{(z^{1})}_{(n^{1},m)}
公式3.36:

公式3.37:

上述是反向传播的步骤,注:这些都是针对所有样本进行过向量化,

是

的矩阵;这里np.sum是python的numpy命令,axis=1表示水平相加求和,keepdims是防止python输出那些古怪的秩数

,加上这个确保阵矩阵

这个向量输出的维度为

这样标准的形式。
目前为止,我们计算的都和Logistic 回归十分相似,但当你开始计算反向传播时,你需要计算,是隐藏层函数的导数,输出在使用sigmoid函数进行二元分类。这里是进行逐个元素乘积,因为

和

这两个都为

矩阵;
还有一种防止python 输出奇怪的秩数,需要显式地调用reshape把np.sum输出结果写成矩阵形式。
8.随机初始化
当你训练神经网络时,权重随机初始化是很重要的。对于逻辑回归,把权重初始化为0当然也是可以的。但是对于一个神经网络,如果你把权重或者参数都初始化为0,那么梯度下降将不会起作用。
以神经网络为例,模型中有大量参数(权重 weight 和偏置 bias):
y=Wx+b
训练的目标就是不断调整这些参数,使模型预测更准确。
如果一开始所有参数都设为相同值(例如全 0):
- 每个神经元会学习到完全一样的东西
- 网络失去"多样性"
- 无法有效学习复杂特征
因此需要:
给参数一个随机的初始值,使不同神经元学习不同特征。
Week4:Deep Neural Networks
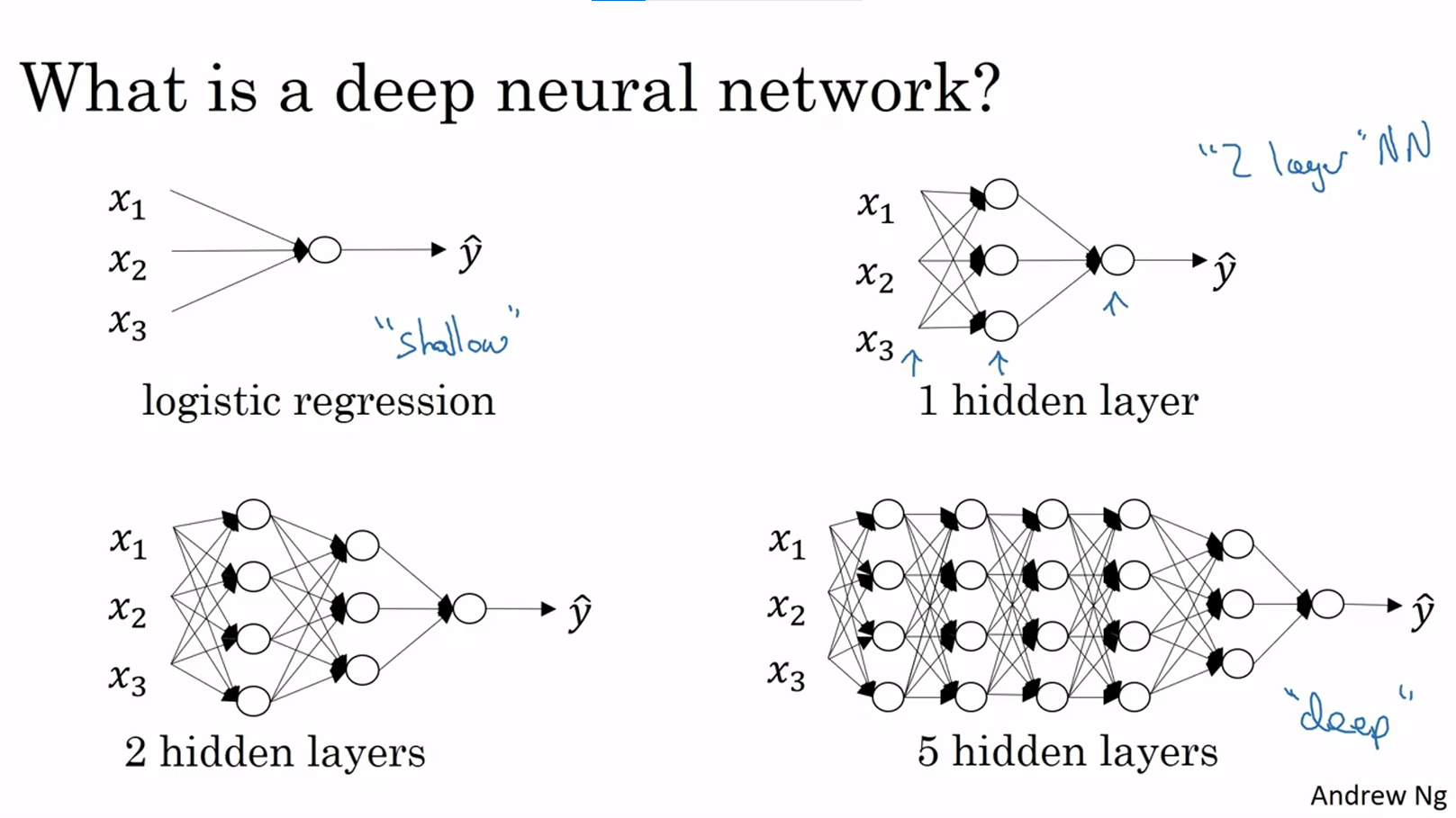
1.深度L层神经网络
2.深度网络前向传播与反向传播
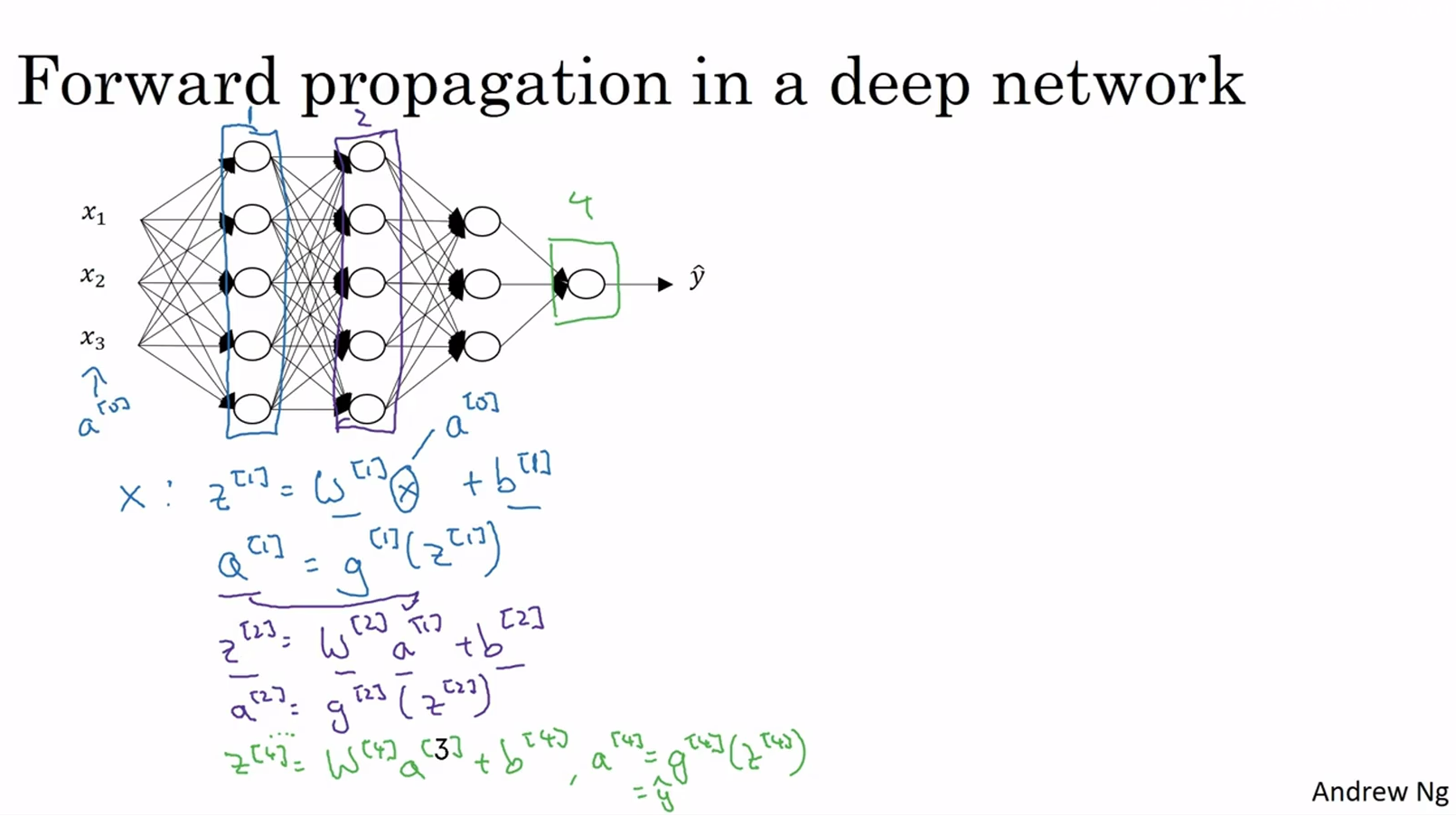
前向传播
先讲前向传播,输入

,输出是

,缓存为

;从实现的角度来说我们可以缓存下

和

,这样更容易在不同的环节中调用函数。

所以前向传播的步骤可以写成:


向量化实现过程可以写成:


前向传播需要喂入

也就是

,来初始化;初始化的是第一层的输入值。

对应于一个训练样本的输入特征,而

对应于一整个训练样本的输入特征,所以这就是这条链的第一个前向函数的输入,重复这个步骤就可以从左到右计算前向传播。
反向传播
输入为

,输出为

,

,


所以反向传播的步骤可以写成:
(1)d{{z}^{l}}=d{{a}^{l}}*{{g}^{l}}'( {{z}^{l}})
(2)

(3)

(4)

(5)d{{z}^{l}}={{w}^{l+1T}}d{{z}^{l+1}}\cdot \text{ }{{g}^{l}}'( {{z}^{l}})~
式子(5)由式子(4)带入式子(1)得到,前四个式子就可实现反向函数。
向量化实现过程可以写成:
(6)d{{Z}^{l}}=d{{A}^{l}}*{{g}^{\left l \\right}}'\left({{Z}^{l}} \right)~~
(7)

(8)

(9)

总结一下:
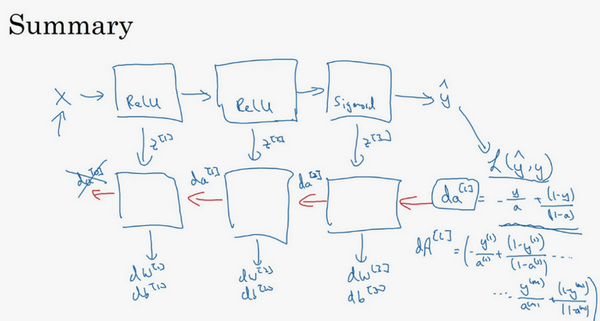
第一层你可能有一个ReLU 激活函数,第二层为另一个ReLU 激活函数,第三层可能是sigmoid函数(如果你做二分类的话),输出值为,用来计算损失;这样你就可以向后迭代进行反向传播求导来求

,

,

,

,

,

。在计算的时候,缓存会把



传递过来,然后回传

,

,可以用来计算

,但我们不会使用它,这里讲述了一个三层网络的前向和反向传播,还有一个细节没讲就是前向递归------用输入数据来初始化,那么反向递归(使用Logistic回归做二分类)------对

求导。
3.深度表示的优势
深度表示(深度特征表示)核心优势
- 自动特征学习,无需人工设计 传统方法依赖手工设计特征 (如 SIFT、HOG、SURF),需要领域专家调参、设计规则; 深度表示通过神经网络端到端自动挖掘特征,从原始数据(图像、文本、语音)逐层提取低层→中层→高层语义特征,省去人工特征工程成本。
- 层级化多尺度语义表达 深度表示具备分层抽象能力:
-
- 低层:边缘、纹理、轮廓;
-
- 中层:部件、局部结构;
-
- 高层:目标、场景、语义概念。 天然适配视觉、NLP 任务的多尺度理解,比传统浅层表示语义更丰富。
- 强泛化能力,适配复杂场景 深度特征具有鲁棒性:对光照、遮挡、形变、噪声、视角变化不敏感; 在真实复杂场景下,迁移能力远优于手工特征,适配开放世界任务。
- 高维稠密表征,信息建模能力强 深度表示是连续稠密向量,能精细刻画数据间细微差异; 可精准建模非线性关系、复杂分布,适合分类、检测、分割、跟踪、检索等精细任务。
- 可迁移性与预训练赋能 深度特征具备通用先验:在大数据集(ImageNet、预训练大模型)学到的表示,可迁移到小样本、小众任务; 大幅降低下游任务训练数据量和收敛难度,小样本、零样本任务依赖深度表示。
- 多模态统一表示 深度表示可将图像、文本、语音、视频映射到同一特征空间,实现跨模态检索、匹配、生成(如图文匹配、多模态大模型),传统手工特征无法做到跨模态统一建模。
- 适配端到端任务优化 深度表示和任务损失联合优化,特征学习直接服务于最终任务(分类 / 检测 / 跟踪); 不是先提特征再单独建模,整体最优,任务精度上限更高。
- 适合大数据与大规模建模 数据量越大,深度表示效果越强,符合大数据时代特性; 可支撑千万级甚至亿级样本、高维输入的建模,传统浅层表示易陷入维度灾难、拟合能力不足。
4.深度神经网络构建模块
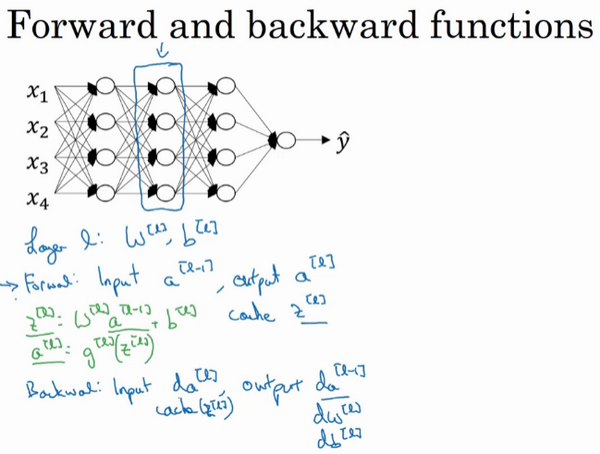
这是一个层数较少的神经网络,我们选择其中一层(方框部分),从这一层的计算着手。在第l层你有参数W^{l}和b^{l},正向传播里有输入的激活函数,输入是前一层a^{l-1},输出是a^{l},我们之前讲过z^{l} =W^{l}a^{l-1} +b^{l},a^{l} =g^{l}(z^{l}),那么这就是你如何从输入a^{l-1}走到输出的a^{l}。之后你就可以把z^{l}的值缓存起来,我在这里也会把这包括在缓存中,因为缓存的z^{i}对以后的正向反向传播的步骤非常有用。
然后是反向步骤或者说反向传播步骤,同样也是第l层的计算,你会需要实现一个函数输入为da^{l},输出da^{l-1}的函数。一个小细节需要注意,输入在这里其实是da^{l}以及所缓存的z^{l}值,之前计算好的z^{l}值,除了输出da^{l-1}的值以外,也需要输出你需要的梯度dW^{l}和db^{l},这是为了实现梯度下降学习。
这就是基本的正向步骤的结构,我把它成为称为正向函数,类似的在反向步骤中会称为反向函数。总结起来就是,在l层,你会有正向函数,输入a^{l-1}并且输出a^{l},为了计算结果你需要用W^{l}和b^{l},以及输出到缓存的z^{l}。然后用作反向传播的反向函数,是另一个函数,输入da^{l},输出da^{l-1},你就会得到对激活函数的导数,也就是希望的导数值da^{l}。a^{l-1}是会变的,前一层算出的激活函数导数。在这个方块(第二个)里你需要W^{l}和b^{l},最后你要算的是dz^{l}。然后这个方块(第三个)中,这个反向函数可以计算输出dW^{l}和db^{l}。我会用红色箭头标注标注反向步骤,如果你们喜欢,我可以把这些箭头涂成红色。
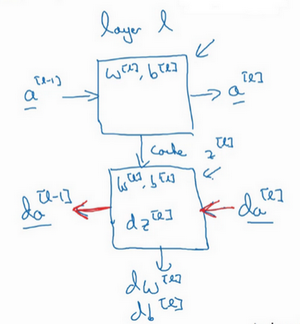
然后如果实现了这两个函数(正向和反向),然后神经网络的计算过程会是这样的:
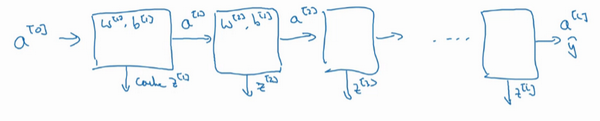
把输入特征a^{0},放入第一层并计算第一层的激活函数,用a^{1}表示,你需要W^{1}和b^{1}来计算,之后也缓存z^{l}值。之后喂到第二层,第二层里,需要用到W^{2}和b^{2},你会需要计算第二层的激活函数a^{2}。后面几层以此类推,直到最后你算出了a^{L},第L层的最终输出值\hat y。在这些过程里我们缓存了所有的z值,这就是正向传播的步骤。
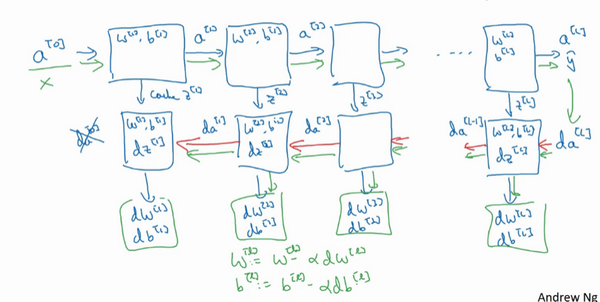
对反向传播的步骤而言,我们需要算一系列的反向迭代,就是这样反向计算梯度,你需要把da^{L}的值放在这里,然后这个方块会给我们{da}^{L-1}的值,以此类推,直到我们得到{da}^{2}和{da}^{1},你还可以计算多一个输出值,就是{da}^{0},但这其实是你的输入特征的导数,并不重要,起码对于训练监督学习的权重不算重要,你可以止步于此。反向传播步骤中也会输出dW^{l}和db^{l},这会输出dW^{3}和db^{3}等等。目前为止你算好了所有需要的导数,稍微填一下这个流程图。
神经网络的一步训练包含了,从a^{0}开始,也就是 x 然后经过一系列正向传播计算得到\hat y,之后再用输出值计算这个(第二行最后方块),再实现反向传播。现在你就有所有的导数项了,W也会在每一层被更新为W=W-αdW,b也一样,b=b-αdb,反向传播就都计算完毕,我们有所有的导数值,那么这是神经网络一个梯度下降循环。
继续下去之前再补充一个细节,概念上会非常有帮助,那就是把反向函数计算出来的z值缓存下来。当你做编程练习的时候去实现它时,你会发现缓存可能很方便,可以迅速得到W^{l}和b^{l}的值,非常方便的一个方法,在编程练习中你缓存了z,还有W和b对吧?从实现角度上看,我认为是一个很方便的方法,可以将参数复制到你在计算反向传播时所需要的地方。好,这就是实现过程的细节,做编程练习时会用到。
5.参数与超参数
什么是超参数?
比如算法中的learning rate a(学习率)、iterations (梯度下降法循环的数量)、L(隐藏层数目)、{{n}^{l}}(隐藏层单元数目)、choice of activation function(激活函数的选择)都需要你来设置,这些数字实际上控制了最后的参数W和b的值,所以它们被称作超参数。
实际上深度学习有很多不同的超参数,之后我们也会介绍一些其他的超参数,如momentum 、mini batch size 、regularization parameters等等。

如何寻找超参数的最优值?
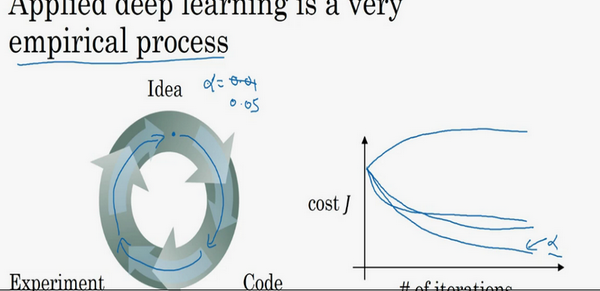
走Idea---Code---Experiment---Idea这个循环,尝试各种不同的参数,实现模型并观察是否成功,然后再迭代。
6.深度学习与大脑的关联性
深度学习和大脑有什么关联性吗?
先说结论:关联不大
那么人们为什么会说深度学习和大脑相关呢?
当你在实现一个神经网络的时候,那些公式是你在做的东西,你会做前向传播、反向传播、梯度下降法,其实很难表述这些公式具体做了什么,深度学习像大脑这样的类比其实是过度简化了我们的大脑具体在做什么,但因为这种形式很简洁,也能让普通人更愿意公开讨论,也方便新闻报道并且吸引大众眼球,但这个类比是非常不准确的。
一个神经网络的逻辑单元可以看成是对一个生物神经元的过度简化,但迄今为止连神经科学家都很难解释究竟一个神经元能做什么,它可能是极其复杂的;它的一些功能可能真的类似logistic回归的运算,但单个神经元到底在做什么目前还没有人能够真正可以解释。
深度学习的确是个很好的工具来学习各种很灵活很复杂的函数,学习到从x到y的映射,在监督学习中学到输入到输出的映射。

但这个类比还是很粗略的,这是一个logistic 回归单元的sigmoid激活函数,这里是一个大脑中的神经元,图中这个生物神经元,也是你大脑中的一个细胞,它能接受来自其他神经元的电信号,比如x_1,x_2,x_3,或可能来自于其他神经元a_1,a_2,a_3 。其中有一个简单的临界计算值,如果这个神经元突然激发了,它会让电脉冲沿着这条长长的轴突,或者说一条导线传到另一个神经元。
所以这是一个过度简化的对比,把一个神经网络的逻辑单元和右边的生物神经元对比。至今为止其实连神经科学家们都很难解释,究竟一个神经元能做什么。一个小小的神经元其实却是极其复杂的,以至于我们无法在神经科学的角度描述清楚,它的一些功能,可能真的是类似logistic回归的运算,但单个神经元到底在做什么,目前还没有人能够真正解释,大脑中的神经元是怎么学习的,至今这仍是一个谜之过程。到底大脑是用类似于后向传播或是梯度下降的算法,或者人类大脑的学习过程用的是完全不同的原理。
所以虽然深度学习的确是个很好的工具,能学习到各种很灵活很复杂的函数来学到从x到y的映射。在监督学习中,学到输入到输出的映射,但这种和人类大脑的类比,在这个领域的早期也许值得一提。但现在这种类比已经逐渐过时了,我自己也在尽量少用这样的说法。
这就是神经网络和大脑的关系,我相信在计算机视觉,或其他的学科都曾受人类大脑启发,还有其他深度学习的领域也曾受人类大脑启发。但是个人来讲我用这个人类大脑类比的次数逐渐减少了。
lesson2:改善深层神经网络:超参数调试、正则化以及优化(Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization)
Week1:Setting up your ML application
1.训练集/验证集/测试集
训练数据划分为几个部分,一部分做为训练集,一部分作为简单交叉验证集,另一部分作为测试集。
接下来,我们开始对训练集执行算法,通过验证集或简单交叉验证集选择最好的模型,经过充分验证,我们选定了最终模型,然后就可以在测试集上进行评估了,为了无偏评估算法的运行状况。
在机器学习发展的小数据量时代,常见做法是将所有数据三七分,就是人们常说的70%训练集,30%测试集。如果明确设置了验证集,也可以按照60%训练集,20%验证集和20%测试集来划分。这是前几年机器学习领域普遍认可的最好的实践方法。如果只有100条,1000条或者1万条数据,那么上述比例划分是非常合理的。
但是在大数据时代,我们现在的数据量可能是百万级别,那么验证集和测试集占数据总量的比例会趋向于变得更小。因为验证集的目的就是验证不同的算法,检验哪种算法更有效,因此,验证集只要足够大到能评估不同的算法,比如2个甚至10个不同算法,并迅速判断出哪种算法更有效。我们可能不需要拿出20%的数据作为验证集。
比如我们有100万条数据,那么取1万条数据便足以进行评估,找出其中表现最好的1-2种算法。同样地,根据最终选择的分类器,测试集的主要目的是正确评估分类器的性能,所以,如果拥有百万数据,我们只需要1000条数据,便足以评估单个分类器,并且准确评估该分类器的性能。假设我们有100万条数据,其中1万条作为验证集,1万条作为测试集,100万里取1万,比例是1%,即:训练集占98%,验证集和测试集各占1%。对于数据量过百万的应用,训练集可以占到99.5% ,验证和测试集各占0.25%,或者验证集占0.4%,测试集占0.1%。
总结一下,在机器学习中,我们通常将样本分成训练集,验证集和测试集三部分,数据集规模相对较小,适用传统的划分比例,数据集规模较大的,验证集和测试集要小于数据总量的20%或10%。后面我会给出如何划分验证集和测试集的具体指导。
现代深度学习的另一个趋势是越来越多的人在训练和测试集分布不匹配的情况下进行训练,假设你要构建一个用户可以上传大量图片的应用程序,目的是找出并呈现所有猫咪图片,可能你的用户都是爱猫人士,训练集可能是从网上下载的猫咪图片,而验证集和测试集是用户在这个应用上上传的猫的图片,就是说,训练集可能是从网络上抓下来的图片。而验证集和测试集是用户上传的图片。结果许多网页上的猫咪图片分辨率很高,很专业,后期制作精良,而用户上传的照片可能是用手机随意拍摄的,像素低,比较模糊,这两类数据有所不同,针对这种情况,根据经验,我建议大家要确保验证集和测试集的数据来自同一分布,关于这个问题我也会多讲一些。因为你们要用验证集来评估不同的模型,尽可能地优化性能。如果验证集和测试集来自同一个分布就会很好。
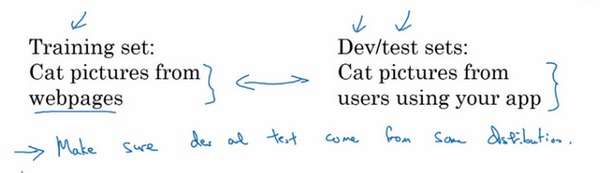
但由于深度学习算法需要大量的训练数据,为了获取更大规模的训练数据集,我们可以采用当前流行的各种创意策略,例如,网页抓取,代价就是训练集数据与验证集和测试集数据有可能不是来自同一分布。但只要遵循这个经验法则,你就会发现机器学习算法会变得更快。我会在后面的课程中更加详细地解释这条经验法则。
最后一点,就算没有测试集也不要紧,测试集的目的是对最终所选定的神经网络系统做出无偏估计,如果不需要无偏估计,也可以不设置测试集。所以如果只有验证集,没有测试集,我们要做的就是,在训练集上训练,尝试不同的模型框架,在验证集上评估这些模型,然后迭代并选出适用的模型。因为验证集中已经涵盖测试集数据,其不再提供无偏性能评估。当然,如果你不需要无偏估计,那就再好不过了。
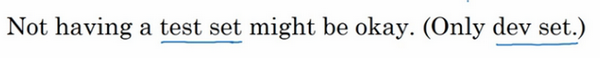
在机器学习中,如果只有一个训练集和一个验证集,而没有独立的测试集,遇到这种情况,训练集还被人们称为训练集,而验证集则被称为测试集,不过在实际应用中,人们只是把测试集当成简单交叉验证集使用,并没有完全实现该术语的功能,因为他们把验证集数据过度拟合到了测试集中。如果某团队跟你说他们只设置了一个训练集和一个测试集,我会很谨慎,心想他们是不是真的有训练验证集,因为他们把验证集数据过度拟合到了测试集中,让这些团队改变叫法,改称其为"训练验证集",而不是"训练测试集",可能不太容易。即便我认为"训练验证集"在专业用词上更准确。实际上,如果你不需要无偏评估算法性能,那么这样是可以的。
所以说,搭建训练验证集和测试集能够加速神经网络的集成,也可以更有效地衡量算法地偏差和方差,从而帮助我们更高效地选择合适方法来优化算法。
2.偏差与方差
- 偏差(Bias)
定义:模型期望预测值 与真实值 之间的差距。
反映:模型拟合能力不足、有没有学到本质规律。
-
- 高偏差:模型太简单,欠拟合
-
- 低偏差:模型复杂度够,能贴合数据真实规律
- 方差(Variance)
定义:在不同训练集上训练出的模型,预测结果的波动程度 。
反映:模型对训练集噪声、随机波动的敏感程度。
-
- 高方差:模型太复杂,过拟合
-
- 低方差:模型稳定,受数据集变化影响小
- 方差与偏差的比喻
打靶类比:
-
- 偏差:靶子中心点偏不偏(整体准不准)
-
- 方差:弹孔散不散(稳不稳定)
-
- 高偏差、低方差:弹孔集中,但全都偏离靶心 → 整体不准、但很稳定(欠拟合)
-
- 低偏差、高方差:弹孔围着靶心,但四处散落 → 平均准、但波动大(过拟合)
-
- 低偏差、低方差:弹孔集中在靶心 → 拟合完美
-
- 高偏差、高方差:既偏又散 → 最差情况
- 和模型复杂度的关系
2.模型过于复杂(深层网络、高次多项式)
- 偏差 ↓ 方差 ↑
- 表现:过拟合,训练集误差很小,测试集误差很大-
- 模型过于简单(线性模型、浅层网络)
-
-
- 偏差 ↑ 方差 ↓
-
-
-
- 表现:欠拟合,训练集、测试集误差都大
-
- 偏差 - 方差权衡(Bias-Variance Tradeoff)
核心:减小偏差往往会增大方差,反之亦然 ,无法同时无限降低。 我们的目标:找到模型最佳复杂度,使总误差最小。 总误差 ≈ 偏差 ² + 方差 + 不可约误差(数据本身噪声)
- 怎么解决高偏差 / 高方差
-
- 高偏差(欠拟合)解决
-
- 增加模型复杂度(加深网络、增加特征)
-
- 减少正则化
-
- 训练更多轮数
-
- 高方差(过拟合)解决
-
- 增加训练数据
-
- 加入正则化(L1、L2、Dropout)
-
- 降低模型复杂度
-
- 数据增强、早停
3.正则化
正则化是 在模型训练中加入额外约束或惩罚 ,目的是防止模型在训练数据上表现很好,但在新数据上表现很差,也就是防止 过拟合(Overfitting) 。
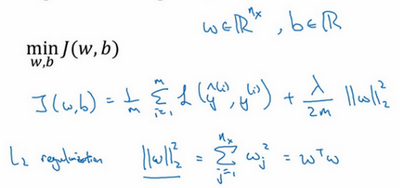
上图是L2正则化
为什么只正则化参数w?为什么不再加上参数 b 呢?你可以这么做,只是我习惯省略不写,因为w通常是一个高维参数矢量,已经可以表达高偏差问题,w可能包含有很多参数,我们不可能拟合所有参数,而b只是单个数字,所以w几乎涵盖所有参数,而不是b,如果加了参数b,其实也没太大影响,因为b只是众多参数中的一个,所以我通常省略不计,如果你想加上这个参数,完全没问题。
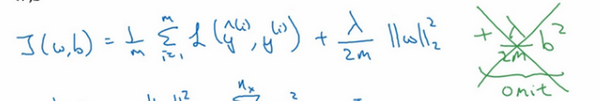
该如何使用该范数实现梯度下降呢?
用backprop 计算出dW的值,backprop会给出J对W的偏导数,实际上是W^{l},把W^{l}替换为W^{l}减去学习率乘以dW。
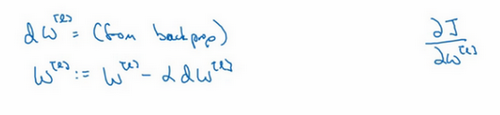
这就是之前我们额外增加的正则化项,既然已经增加了这个正则项,现在我们要做的就是给dW加上这一项\frac {\lambda}{m}W^{l},然后计算这个更新项,使用新定义的dW^{l},它的定义含有相关参数代价函数导数和,以及最后添加的额外正则项,这也是L2正则化有时被称为"权重衰减"的原因。
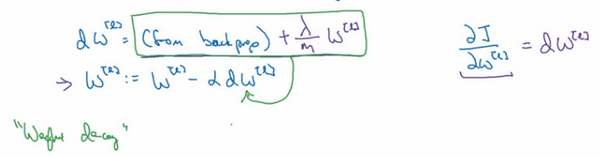
我们用dW^{l}的定义替换此处的dW^{l},可以看到,W^{l}的定义被更新为W^{l}减去学习率\alpha 乘以backprop 再加上\frac{\lambda}{m}W^{l}。

该正则项说明,不论W^{l}是什么,我们都试图让它变得更小,实际上,相当于我们给矩阵W乘以(1 - \alpha\frac{\lambda}{m})倍的权重,矩阵W减去\alpha\frac{\lambda}{m}倍的它,也就是用这个系数(1-\alpha\frac{\lambda}{m})乘以矩阵W,该系数小于1,因此L2范数正则化也被称为"权重衰减",因为它就像一般的梯度下降,W被更新为少了\alpha乘以backprop 输出的最初梯度值,同时W也乘以了这个系数,这个系数小于1,因此L2正则化也被称为 "权重衰减" 。
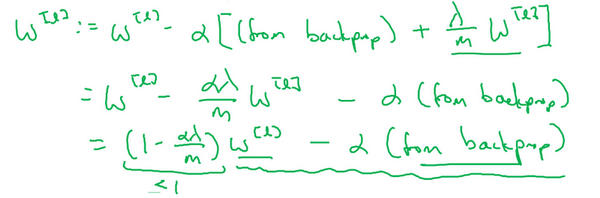
我不打算这么叫它,之所以叫它"权重衰减"是因为这两项相等,权重指标乘以了一个小于1的系数。
4.正则化缓解过拟合机理
为什么正则化有利于预防过拟合呢?为什么它可以减少方差问题?我们通过两个例子来直观体会一下。
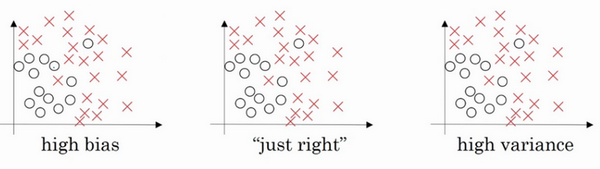
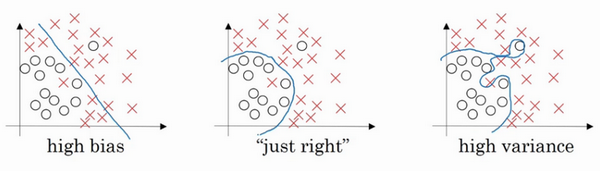
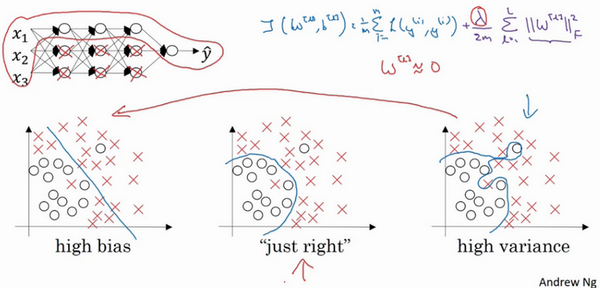
左图是高偏差,右图是高方差,中间是Just Right,这几张图我们在前面课程中看到过。
现在我们来看下这个庞大的深度拟合神经网络。我知道这张图不够大,深度也不够,但你可以想象这是一个过拟合的神经网络。这是我们的代价函数J,含有参数W,b。我们添加正则项,它可以避免数据权值矩阵过大,这就是弗罗贝尼乌斯范数,为什么压缩L2范数,或者弗罗贝尼乌斯范数或者参数可以减少过拟合?
直观上理解就是如果正则化\lambda设置得足够大,权重矩阵W被设置为接近于0的值,直观理解就是把多隐藏单元的权重设为0,于是基本上消除了这些隐藏单元的许多影响。如果是这种情况,这个被大大简化了的神经网络会变成一个很小的网络,小到如同一个逻辑回归单元,可是深度却很大,它会使这个网络从过度拟合的状态更接近左图的高偏差状态。
但是\lambda会存在一个中间值,于是会有一个接近"Just Right"的中间状态。
直观理解就是\lambda增加到足够大,W会接近于0,实际上是不会发生这种情况的,我们尝试消除或至少减少许多隐藏单元的影响,最终这个网络会变得更简单,这个神经网络越来越接近逻辑回归,我们直觉上认为大量隐藏单元被完全消除了,其实不然,实际上是该神经网络的所有隐藏单元依然存在,但是它们的影响变得更小了。神经网络变得更简单了,貌似这样更不容易发生过拟合,因此我不确定这个直觉经验是否有用,不过在编程中执行正则化时,你实际看到一些方差减少的结果。
我们再来直观感受一下,正则化为什么可以预防过拟合,假设我们用的是这样的双曲线激活函数。

用g(z)表示tanh(z),我们发现如果 z 非常小,比如 z 只涉及很小范围的参数(图中原点附近的红色区域),这里我们利用了双曲正切函数的线性状态,只要z可以扩展为这样的更大值或者更小值,激活函数开始变得非线性。
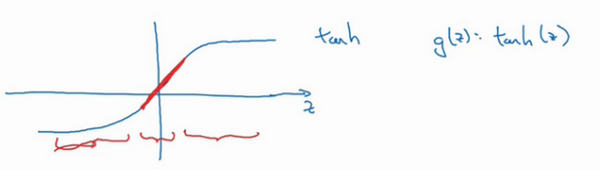
现在你应该摒弃这个直觉,如果正则化参数λ很大,激活函数的参数会相对较小,因为代价函数中的参数变大了,如果W很小,
如果W很小,相对来说,z也会很小。
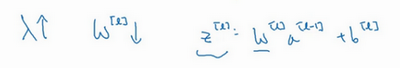
特别是,如果z的值最终在这个范围内,都是相对较小的值,g(z)大致呈线性,每层几乎都是线性的,和线性回归函数一样。

第一节课我们讲过,如果每层都是线性的,那么整个网络就是一个线性网络,即使是一个非常深的深层网络,因具有线性激活函数的特征,最终我们只能计算线性函数,因此,它不适用于非常复杂的决策,以及过度拟合数据集的非线性决策边界,如同我们在幻灯片中看到的过度拟合高方差的情况。
总结一下,如果正则化参数变得很大,参数W很小,z也会相对变小,此时忽略b的影响,z会相对变小,实际上,z的取值范围很小,这个激活函数,也就是曲线函数tanh会相对呈线性,整个神经网络会计算离线性函数近的值,这个线性函数非常简单,并不是一个极复杂的高度非线性函数,不会发生过拟合。
大家在编程作业里实现正则化的时候,会亲眼看到这些结果,总结正则化之前,我给大家一个执行方面的小建议,在增加正则化项时,应用之前定义的代价函数J,我们做过修改,增加了一项,目的是预防权重过大。
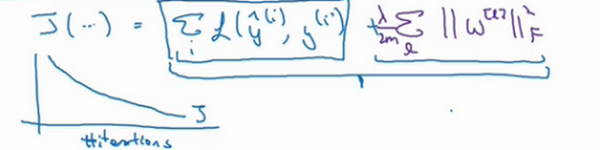
如果你使用的是梯度下降函数,在调试梯度下降时,其中一步就是把代价函数J设计成这样一个函数,在调试梯度下降时,它代表梯度下降的调幅数量。可以看到,代价函数对于梯度下降的每个调幅都单调递减。如果你实施的是正则化函数,请牢记,J已经有一个全新的定义。如果你用的是原函数J,也就是这第一个项正则化项,你可能看不到单调递减现象,为了调试梯度下降,请务必使用新定义的J函数,它包含第二个正则化项,否则函数J可能不会在所有调幅范围内都单调递减。
5. Dropout正则化
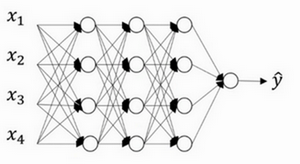
假设你在训练上图这样的神经网络,它存在过拟合,这就是dropout 所要处理的,我们复制这个神经网络,dropout 会遍历网络的每一层,并设置消除神经网络中节点的概率。假设网络中的每一层,每个节点都以抛硬币的方式设置概率,每个节点得以保留和消除的概率都是0.5,设置完节点概率,我们会消除一些节点,然后删除掉从该节点进出的连线,最后得到一个节点更少,规模更小的网络,然后用backprop 方法进行训练。
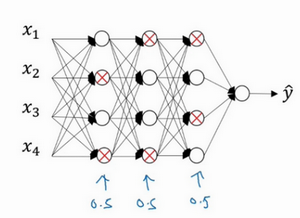
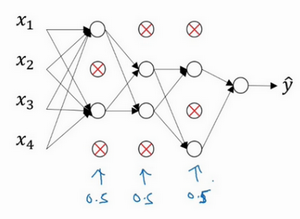
这是网络节点精简后的一个样本,对于其它样本,我们照旧以抛硬币的方式设置概率,保留一类节点集合,删除其它类型的节点集合。对于每个训练样本,我们都将采用一个精简后神经网络来训练它,这种方法似乎有点怪,单纯遍历节点,编码也是随机的,可它真的有效。不过可想而知,我们针对每个训练样本训练规模小得多的网络,最后你可能会认识到为什么要正则化网络,因为我们在训练规模小得多的网络。
随机反向失活
首先要定义向量d,d^{3}表示网络第三层的dropout向量
d3 = np.random.rand(a3.shape[0],a3.shape[1])
然后看它是否小于某数,我们称之为keep-prob ,keep-prob 是一个具体数字,上个示例中它是0.5,而本例中它是0.8,它表示保留某个隐藏单元的概率,此处keep-prob等于0.8,它意味着消除任意一个隐藏单元的概率是0.2,它的作用就是生成随机矩阵,如果对a^{3}进行因子分解,效果也是一样的。d^{3}是一个矩阵,每个样本和每个隐藏单元,其中d^{3}中的对应值为1的概率都是0.8,对应为0的概率是0.2,随机数字小于0.8。它等于1的概率是0.8,等于0的概率是0.2。
接下来要做的就是从第三层中获取激活函数,这里我们叫它a^{3},a^{3}含有要计算的激活函数,a^{3}等于上面的a^{3}乘以d^{3},a3 =np.multiply(a3,d3),这里是元素相乘,也可写为a3*=d3,它的作用就是让d^{3}中所有等于0的元素(输出),而各个元素等于0的概率只有20%,乘法运算最终把d^{\left\lbrack3 \right]}中相应元素输出,即让d^{3}中0元素与a^{3}中相对元素归零。
6.理解Dropout
Dropout可以随机删除网络中的神经单元,他为什么可以通过正则化发挥如此大的作用呢?
直观上理解:不要依赖于任何一个特征,因为该单元的输入可能随时被清除,因此该单元通过这种方式传播下去,并为单元的四个输入增加一点权重,通过传播所有权重,dropout 将产生收缩权重的平方范数的效果,和之前讲的L2正则化类似;实施dropout的结果实它会压缩权重,并完成一些预防过拟合的外层正则化;L2对不同权重的衰减是不同的,它取决于激活函数倍增的大小。
总结一下,dropout的功能类似于L2正则化,与L2正则化不同的是应用方式不同会带来一点点小变化,甚至更适用于不同的输入范围。
7.其他正则化方法
-
数据扩增
假设你正在拟合猫咪图片分类器,如果你想通过扩增训练数据来解决过拟合,但扩增数据代价高,而且有时候我们无法扩增数据,但我们可以通过添加这类图片来增加训练集。例如,水平翻转图片,并把它添加到训练集。所以现在训练集中有原图,还有翻转后的这张图片,所以通过水平翻转图片,训练集则可以增大一倍,因为训练集有冗余,这虽然不如我们额外收集一组新图片那么好,但这样做节省了获取更多猫咪图片的花费。除了水平翻转图片,你也可以随意裁剪图片,这张图是把原图旋转并随意放大后裁剪的,仍能辨别出图片中的猫咪。通过随意翻转和裁剪图片,我们可以增大数据集,额外生成假训练数据。和全新的,独立的猫咪图片数据相比,这些额外的假的数据无法包含像全新数据那么多的信息,但我们这么做基本没有花费,代价几乎为零,除了一些对抗性代价。以这种方式扩增算法数据,进而正则化数据集,减少过拟合比较廉价。
像这样人工合成数据的话,我们要通过算法验证,图片中的猫经过水平翻转之后依然是猫。大家注意,我并没有垂直翻转,因为我们不想上下颠倒图片,也可以随机选取放大后的部分图片,猫可能还在上面。对于光学字符识别,我们还可以通过添加数字,随意旋转或扭曲数字来扩增数据,把这些数字添加到训练集,它们仍然是数字。为了方便说明,我对字符做了强变形处理,所以数字4看起来是波形的,其实不用对数字4做这么夸张的扭曲,只要轻微的变形就好,我做成这样是为了让大家看的更清楚。实际操作的时候,我们通常对字符做更轻微的变形处理。因为这几个4看起来有点扭曲。所以,数据扩增可作为正则化方法使用,实际功能上也与正则化相似。
- (早停)early stopping 还有另外一种常用的方法叫作early stopping,运行梯度下降时,我们可以绘制训练误差,或只绘制代价函数J的优化过程,在训练集上用0-1记录分类误差次数。呈单调下降趋势,如图。
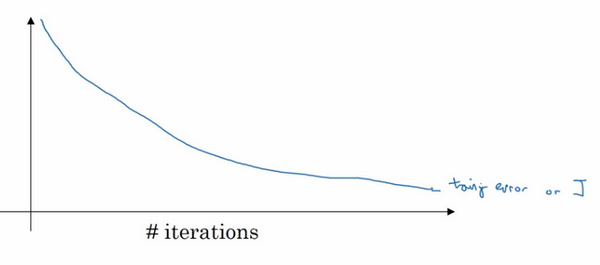
因为在训练过程中,我们希望训练误差,代价函数J都在下降,通过early stopping ,我们不但可以绘制上面这些内容,还可以绘制验证集误差,它可以是验证集上的分类误差,或验证集上的代价函数,逻辑损失和对数损失等,你会发现,验证集误差通常会先呈下降趋势,然后在某个节点处开始上升,early stopping的作用是,你会说,神经网络已经在这个迭代过程中表现得很好了,我们在此停止训练吧,得到验证集误差,它是怎么发挥作用的?
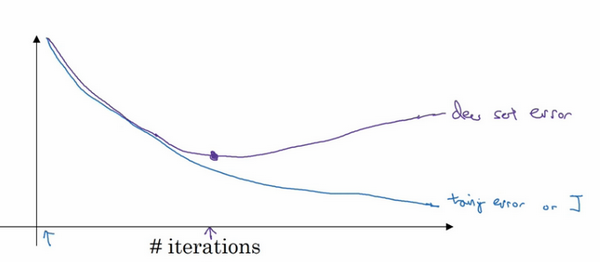
当你还未在神经网络上运行太多迭代过程的时候,参数w接近0,因为随机初始化w值时,它的值可能都是较小的随机值,所以在你长期训练神经网络之前w依然很小,在迭代过程和训练过程中w的值会变得越来越大,比如在这儿,神经网络中参数w的值已经非常大了,所以early stopping 要做就是在中间点停止迭代过程,我们得到一个w值中等大小的弗罗贝尼乌斯范数,与L2正则化相似,选择参数w范数较小的神经网络,但愿你的神经网络过度拟合不严重。
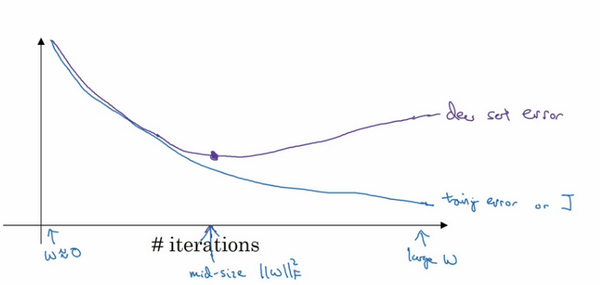
术语early stopping 代表提早停止训练神经网络,训练神经网络时,我有时会用到early stopping,但是它也有一个缺点,我们来了解一下。
我认为机器学习过程包括几个步骤,其中一步是选择一个算法来优化代价函数J,我们有很多种工具来解决这个问题,如梯度下降,后面我会介绍其它算法,例如Momentum ,RMSprop 和Adam 等等,但是优化代价函数J之后,我也不想发生过拟合,也有一些工具可以解决该问题,比如正则化,扩增数据等等。
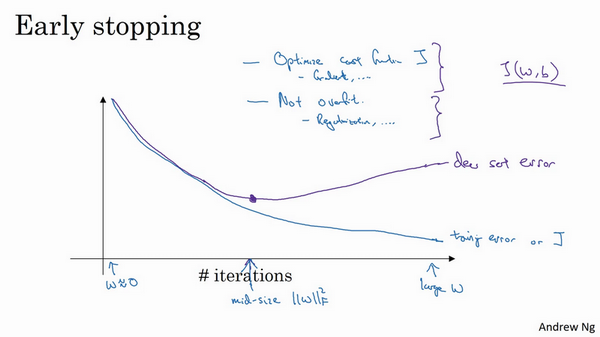
在机器学习中,超级参数激增,选出可行的算法也变得越来越复杂。我发现,如果我们用一组工具优化代价函数J,机器学习就会变得更简单,在重点优化代价函数J时,你只需要留意w和b,J(w,b)的值越小越好,你只需要想办法减小这个值,其它的不用关注。然后,预防过拟合还有其他任务,换句话说就是减少方差,这一步我们用另外一套工具来实现,这个原理有时被称为"正交化"。思路就是在一个时间做一个任务,后面课上我会具体介绍正交化,如果你还不了解这个概念,不用担心。
但对我来说early stopping的主要缺点就是你不能独立地处理这两个问题,因为提早停止梯度下降,也就是停止了优化代价函数J,因为现在你不再尝试降低代价函数J,所以代价函数J的值可能不够小,同时你又希望不出现过拟合,你没有采取不同的方式来解决这两个问题,而是用一种方法同时解决两个问题,这样做的结果是我要考虑的东西变得更复杂。
如果不用early stopping,另一种方法就是L2正则化,训练神经网络的时间就可能很长。我发现,这导致超级参数搜索空间更容易分解,也更容易搜索,但是缺点在于,你必须尝试很多正则化参数\lambda的值,这也导致搜索大量\lambda值的计算代价太高。
Early stopping的优点是,只运行一次梯度下降,你可以找出w的较小值,中间值和较大值,而无需尝试L2正则化超级参数\lambda的很多值。
如果你还不能完全理解这个概念,没关系,下节课我们会详细讲解正交化,这样会更好理解。
虽然L2正则化有缺点,可还是有很多人愿意用它。吴恩达老师个人更倾向于使用L2正则化,尝试许多不同的\lambda值,假设你可以负担大量计算的代价。而使用early stopping也能得到相似结果,还不用尝试这么多\lambda值。
早停止法的核心思想 是在模型训练过程中,持续监控验证集上的性能。当验证损失不再改善时,提前终止训练,而不是等待所有预设的 epoch 全部完成。
训练过程通常分为三个阶段:
训练损失 ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
验证损失 ↓↓↓↓↓↓↓↓↓↑↑↑↑↑↑↑↑↑↑↑
↑
最佳停止点(早停触发)|------|------|------|--------|
| 阶段 | 训练损失 | 验证损失 | 状态 |
| 欠拟合期 | 持续下降 | 持续下降 | 继续训练 |
| 最优点 | 下降 | 最低点 | ✅ 理想停止 |
| 过拟合期 | 继续下降 | 开始上升 | ❌ 应该停止 |
8.归一化输入
归一化的核心目标 是让不同特征的数据分布处于相近的尺度范围,从而提升模型训练效率与稳定性 ^51d377
训练神经网络,其中一个加速训练的方法就是归一化输入。假设一个训练集有两个特征,输入特征为2维,归一化需要两个步骤: ^6ef96c
- 零均值
- 归一化方差
我们希望无论是训练集和测试集都是通过相同的μ和σ^2定义的数据转换,这两个是由训练集得出来的。
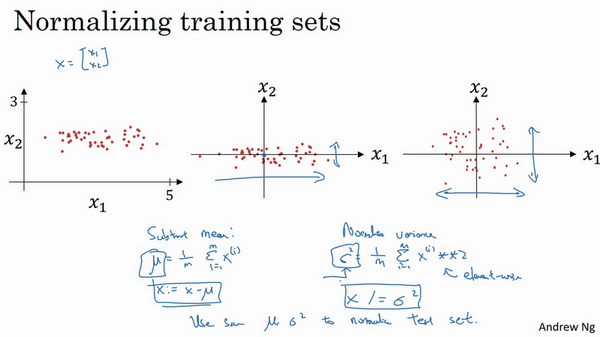
第一步 是零均值化,\mu = \frac{1}{m}\sum_{i =1}^{m}x^{(i)},它是一个向量,x等于每个训练数据 x减去\mu,意思是移动训练集,直到它完成零均值化。
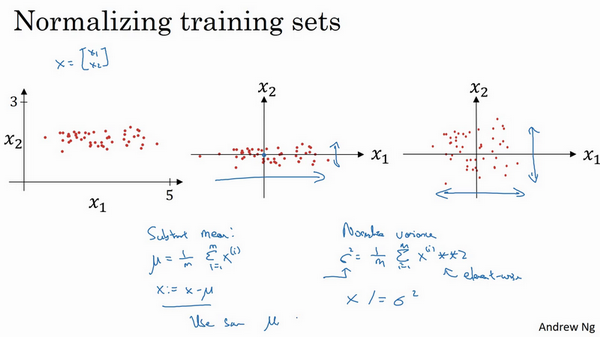
第二步是归一化方差,注意特征x_{1}的方差比特征x_{2}的方差要大得多,我们要做的是给\sigma赋值,\sigma^{2}= \frac{1}{m}\sum_{i =1}^{m}{({x^{(i)})}^{2}},这是节点y 的平方,\sigma^{2}是一个向量,它的每个特征都有方差,注意,我们已经完成零值均化,({x^{(i)})}^{2}元素y^{2}就是方差,我们把所有数据除以向量\sigma^{2},最后变成上图形式。
x_{1}和x_{2}的方差都等于1。提示一下,如果你用它来调整训练数据,那么用相同的 μ和 \sigma^{2}来归一化测试集。尤其是,你不希望训练集和测试集的归一化有所不同,不论μ的值是什么,也不论\sigma^{2}的值是什么,这两个公式中都会用到它们。所以你要用同样的方法调整测试集,而不是在训练集和测试集上分别预估μ 和 \sigma^{2}。因为我们希望不论是训练数据还是测试数据,都是通过相同μ和\sigma^{2}定义的相同数据转换,其中μ和\sigma^{2}是由训练集数据计算得来的。
我们为什么要这么做呢?为什么我们想要归一化输入特征,回想一下右上角所定义的代价函数。
J(w,b)=\frac{1}{m}\sum\limits_{i=1}^{m}{L({{{\hat{y}}}^{(i)}},{{y}^{(i)}})}
如果你使用非归一化的输入特征,代价函数会像这样:
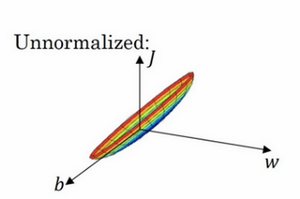
****
这是一个非常细长狭窄的代价函数,你要找的最小值应该在这里。但如果特征值在不同范围,假如x_{1}取值范围从1到1000,特征x_{2}的取值范围从0到1,结果是参数w_{1}和w_{2}值的范围或比率将会非常不同,这些数据轴应该是w_{1}和w_{2},但直观理解,我标记为w和b,代价函数就有点像狭长的碗一样,如果你能画出该函数的部分轮廓,它会是这样一个狭长的函数。
然而如果你归一化特征,代价函数平均起来看更对称,如果你在上图这样的代价函数上运行梯度下降法,你必须使用一个非常小的学习率。因为如果是在这个位置,梯度下降法可能需要多次迭代过程,直到最后找到最小值。但如果函数是一个更圆的球形轮廓,那么不论从哪个位置开始,梯度下降法都能够更直接地找到最小值,你可以在梯度下降法中使用较大步长,而不需要像在左图中那样反复执行。 ^e83d6e
当然,实际上w是一个高维向量,因此用二维绘制w并不能正确地传达并直观理解,但总地直观理解是代价函数会更圆一些,而且更容易优化,前提是特征都在相似范围内,而不是从1到1000,0到1的范围,而是在-1到1范围内或相似偏差,这使得代价函数J优化起来更简单快速。
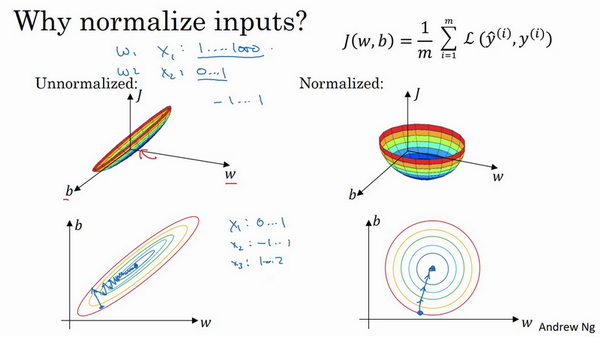
实际上如果假设特征x_{1}范围在0-1之间,x_{2}的范围在-1到1之间,x_{3}范围在1-2之间,它们是相似范围,所以会表现得很好。
当它们在非常不同的取值范围内,如其中一个从1到1000,另一个从0到1,这对优化算法非常不利。但是仅将它们设置为均化零值,假设方差为1,就像上一张幻灯片里设定的那样,确保所有特征都在相似范围内,通常可以帮助学习算法运行得更快。
所以如果输入特征处于不同范围内,可能有些特征值从0到1,有些从1到1000,那么归一化特征值就非常重要了。如果特征值处于相似范围内,那么归一化就不是很重要了。执行这类归一化并不会产生什么危害,我通常会做归一化处理,虽然我不确定它能否提高训练或算法速度。
9.梯度消失和梯度爆炸
训练神经网络,尤其是深度神经所面临的一个问题就是梯度消失或梯度爆炸,也就是你训练神经网络的时候,导数或坡度有时会变得非常大,或者非常小,甚至于以指数方式变小,这加大了训练的难度。
这节课,你将会了解梯度消失或梯度爆炸的真正含义,以及如何更明智地选择随机初始化权重,从而避免这个问题。
假设你正在训练这样一个极深的神经网络,为了节约幻灯片上的空间,我画的神经网络每层只有两个隐藏单元,但它可能含有更多,但这个神经网络会有参数W^{1},W^{2},W^{3}等等,直到W^{l},为了简单起见,假设我们使用激活函数g(z)=z,也就是线性激活函数,我们忽略b,假设b^{l}=0,如果那样的话,输出y=W^{l}W^{L -1}W^{L - 2}\ldots W^{3}W^{2}W^{1}x,如果你想考验我的数学水平,W^{1} x = z^{1},因为b=0,所以我想z^{1} =W^{1} x,a^{1} = g(z^{1}),因为我们使用了一个线性激活函数,它等于z^{1},所以第一项W^{1} x = a^{1},通过推理,你会得出W^{2}W^{1}x =a^{2},因为a^{2} = g(z^{2}),还等于g(W^{2}a^{1}),可以用W^{1}x替换a^{1},所以这一项就等于a^{2},这个就是a^{3}(W^{3}W^{2}W^{1}x)。
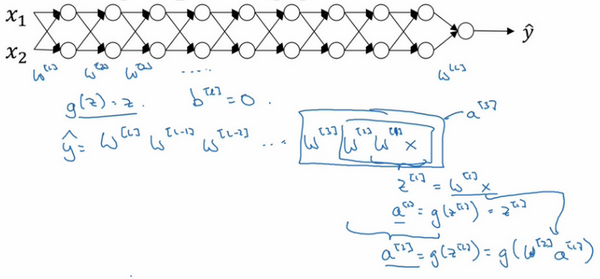
所有这些矩阵数据传递的协议将给出\hat y而不是y的值。
假设每个权重矩阵W^{l} = \begin{bmatrix} 1.5 & 0 \\0 & 1.5 \\\end{bmatrix},从技术上来讲,最后一项有不同维度,可能它就是余下的权重矩阵,y= W^{1}\begin{bmatrix} 1.5 & 0 \\ 0 & 1.5 \\\end{bmatrix}^{(L -1)}x,因为我们假设所有矩阵都等于它,它是1.5倍的单位矩阵,最后的计算结果就是\hat{y},\hat{y}也就是等于{1.5}^{(L-1)}x。如果对于一个深度神经网络来说L值较大,那么\hat{y}的值也会非常大,实际上它呈指数级增长的,它增长的比率是{1.5}^{L},因此对于一个深度神经网络,y的值将爆炸式增长。
相反的,如果权重是0.5,W^{l} = \begin{bmatrix} 0.5& 0 \\ 0 & 0.5 \\ \end{bmatrix},它比1小,这项也就变成了{0.5}^{L},矩阵y= W^{1}\begin{bmatrix} 0.5 & 0 \\ 0 & 0.5 \\\end{bmatrix}^{(L - 1)}x,再次忽略W^{L},因此每个矩阵都小于1,假设x_{1}和x_{2}都是1,激活函数将变成\frac{1}{2},\frac{1}{2},\frac{1}{4},\frac{1}{4},\frac{1}{8},\frac{1}{8}等,直到最后一项变成\frac{1}{2^{L}},所以作为自定义函数,激活函数的值将以指数级下降,它是与网络层数数量L相关的函数,在深度网络中,激活函数以指数级递减。
我希望你得到的直观理解是,权重W只比1略大一点,或者说只是比单位矩阵大一点,深度神经网络的激活函数将爆炸式增长,如果W比1略小一点,可能是\begin{bmatrix}0.9 & 0 \\ 0 & 0.9 \\ \end{bmatrix}。
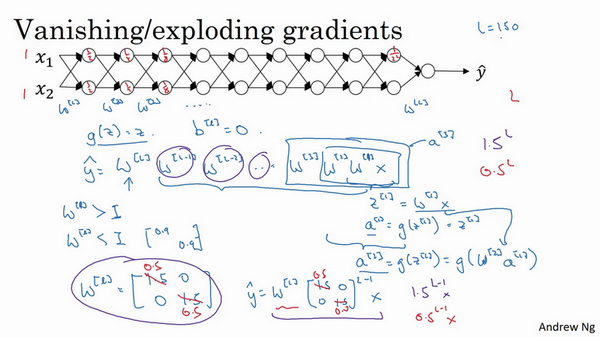
在深度神经网络中,激活函数将以指数级递减,虽然我只是讨论了激活函数以与L相关的指数级数增长或下降,它也适用于与层数L相关的导数或梯度函数,也是呈指数级增长或呈指数递减。
对于当前的神经网络,假设L=150,最近Microsoft对152层神经网络的研究取得了很大进展,在这样一个深度神经网络中,如果激活函数或梯度函数以与L相关的指数增长或递减,它们的值将会变得极大或极小,从而导致训练难度上升,尤其是梯度指数小于L时,梯度下降算法的步长会非常非常小,梯度下降算法将花费很长时间来学习。
总结一下,我们讲了深度神经网络是如何产生梯度消失或爆炸问题的,实际上,在很长一段时间内,它曾是训练深度神经网络的阻力,虽然有一个不能彻底解决此问题的解决方案,但是已在如何选择初始化权重问题上提供了很多帮助。
10.神经网络的权重初始化
神经网络中的**权重初始化(Weight Initialization)**是指:
在训练开始之前,为网络中的参数 W和 b 赋初值。
虽然只是"开始时随便给个值",但初始化方式会直接影响:
- 是否能正常训练
- 收敛速度
- 梯度是否爆炸/消失
- 最终模型效果
在深度学习中,这是非常关键的一步。
1️⃣ 为什么不能全部初始化为 0
假设某层:
z=Wx+b
如果所有权重:
W=0
那么:
- 每个神经元输出相同
- 反向传播得到的梯度也相同
- 参数更新永远一致
结果:
所有神经元学到完全一样的东西。
这叫:
对称性问题(Symmetry Problem)
神经网络就失去了"多个神经元学习不同特征"的能力。
2️⃣ 为什么使用随机初始化
随机初始化可以:
✅ 打破对称性
✅ 让不同神经元学习不同特征
✅ 促进网络有效训练
例如:
W = np.random.randn(m,n)*0.01表示:
- 从正态分布随机采样
- 数值较小
3️⃣ 为什么"太大"或"太小"都不行
(1)初始化太大
假设:
W \gg 1
则:
z = Wx + b
会变得很大。
对于 sigmoid:
\sigma(z) = \frac{1}{1+e^{-z}}
若:
z \to -\infty
则:
\sigma(z)\approx1
梯度:
\sigma'(z)\approx0
出现:
梯度消失
(2)初始化太小
若:
W \approx 0
则:
- 信号传播越来越弱
- 深层网络输出接近 0
- 梯度也会越来越小
同样导致训练困难。
4️⃣ 理想初始化的目标
我们希望:
前向传播时
每层输出的方差保持稳定:
\text{Var}(a^{l}) \approx \text{Var}(a^{l-1})
避免:
- 激活值越来越大
- 或越来越小
反向传播时
梯度方差也保持稳定:
\text{Var}(\delta^{l}) \approx \text{Var}(\delta^{l+1})
避免:
- 梯度爆炸
- 梯度消失
5️⃣ 常见初始化方法
1.Xavier 初始化(Glorot Initialization)
2.He 初始化(最常用)
3.LeCun 初始化
6️⃣ 不同初始化适配关系
|------------|--------|
| 激活函数 | 推荐初始化 |
| Sigmoid | Xavier |
| Tanh | Xavier |
| ReLU | He |
| Leaky ReLU | He |
| SELU | LeCun |
7️⃣ 偏置(bias)怎么初始化
通常:
b=0
即可。
因为:
- bias 不会导致对称性问题
- 权重才是关键
8️⃣ 深层网络为什么更依赖初始化
浅层网络:
- 即使初始化一般
- 也可能训练成功
但深层网络:
- 每层都会放大问题
- 梯度可能指数级衰减/爆炸
因此:
网络越深,初始化越重要。
11.梯度的数值逼近
1.12 梯度的数值逼近(Numerical approximation of gradients)
梯度的数值逼近是用微小的扰动来近似计算梯度的方法,常用于
检查反向传播是否正确(Gradient Checking),验证神经网络代码,在无法解析求导时近似梯度
前向差分:
f'(x)\approx\frac{f(x+\epsilon)-f(x)}{\epsilon}
中心差分:
f'(x)\approx\dfrac{f(x+\epsilon)-f(x-\epsilon)}{2\epsilon}
12.梯度检验
梯度检验帮我们节省了很多时间,也多次帮我发现backprop 实施过程中的bug,接下来,我们看看如何利用它来调试或检验backprop的实施是否正确。
假设你的网络中含有下列参数,W^{1}和b^{1}......W^{l}和b^{l},为了执行梯度检验,首先要做的就是,把所有参数转换成一个巨大的向量数据,你要做的就是把矩阵W转换成一个向量,把所有W矩阵转换成向量之后,做连接运算,得到一个巨型向量\theta,该向量表示为参数\theta,代价函数J是所有W和b的函数,现在你得到了一个\theta的代价函数J(即J(\theta))。接着,你得到与W和b顺序相同的数据,你同样可以把dW^{1}和{db}^{1}......{dW}^{l}和{db}^{l}转换成一个新的向量,用它们来初始化大向量d\theta,它与\theta具有相同维度。
同样的,把dW^{1}转换成矩阵,db^{1}已经是一个向量了,直到把{dW}^{l}转换成矩阵,这样所有的dW都已经是矩阵,注意dW^{1}与W^{1}具有相同维度,db^{1}与b^{1}具有相同维度。经过相同的转换和连接运算操作之后,你可以把所有导数转换成一个大向量d\theta,它与\theta具有相同维度,现在的问题是d\theta和代价函数J的梯度或坡度有什么关系?
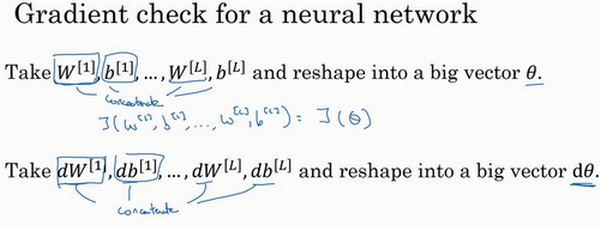
这就是实施梯度检验的过程,英语里通常简称为"grad check",首先,我们要清楚J是超参数\theta的一个函数,你也可以将J函数展开为J(\theta_{1},\theta_{2},\theta_{3},\ldots\ldots),不论超级参数向量\theta的维度是多少,为了实施梯度检验,你要做的就是循环执行,从而对每个i也就是对每个\theta组成元素计算d\theta_{\text{approx}}i的值,我使用双边误差,也就是
d\theta_{\text{approx}}\lefti \\right = \frac{J\left( \theta_{1},\theta_{2},\ldots\theta_{i} + \varepsilon,\ldots \right) - J\left( \theta_{1},\theta_{2},\ldots\theta_{i} - \varepsilon,\ldots \right)}{2\varepsilon}
只对\theta_{i}增加\varepsilon,其它项保持不变,因为我们使用的是双边误差,对另一边做同样的操作,只不过是减去\varepsilon,\theta其它项全都保持不变。

从上节课中我们了解到这个值(d\theta_{\text{approx}}\lefti \\right)应该逼近d\theta\lefti \\right=\frac{\partial J}{\partial\theta_{i}},d\theta\lefti \\right是代价函数的偏导数,然后你需要对i的每个值都执行这个运算,最后得到两个向量,得到d\theta的逼近值d\theta_{\text{approx}},它与d\theta具有相同维度,它们两个与\theta具有相同维度,你要做的就是验证这些向量是否彼此接近。
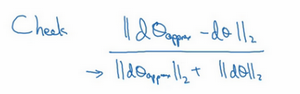
具体来说,如何定义两个向量是否真的接近彼此?我一般做下列运算,计算这两个向量的距离,d\theta_{\text{approx}}\lefti \\right - d\thetai的欧几里得范数 ,注意这里({||d\theta_{\text{approx}} -d\theta||}_{2})没有平方,它是误差平方之和,然后求平方根,得到欧式距离,然后用向量长度归一化,使用向量长度的欧几里得范数。分母只是用于预防这些向量太小或太大,分母使得这个方程式变成比率,我们实际执行这个方程式,\varepsilon可能为10^{-7},使用这个取值范围内的\varepsilon,如果你发现计算方程式得到的值为10^{-7}或更小,这就很好,这就意味着导数逼近很有可能是正确的,它的值非常小。
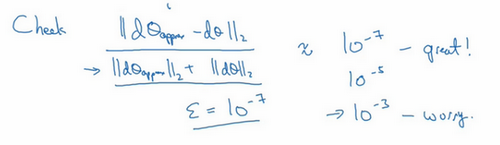
如果它的值在10^{-5}范围内,我就要小心了,也许这个值没问题,但我会再次检查这个向量的所有项,确保没有一项误差过大,可能这里有bug。
如果左边这个方程式结果是10^{-3},我就会担心是否存在bug ,计算结果应该比10^{- 3}小很多,如果比10^{-3}大很多,我就会很担心,担心是否存在bug 。这时应该仔细检查所有\theta项,看是否有一个具体的i值,使得d\theta_{\text{approx}}\lefti \\right与d\thetai大不相同,并用它来追踪一些求导计算是否正确,经过一些调试,最终结果会是这种非常小的值(10^{-7}),那么,你的实施可能是正确的。

在实施神经网络时,我经常需要执行foreprop 和backprop ,然后我可能发现这个梯度检验有一个相对较大的值,我会怀疑存在bug,然后开始调试,调试,调试,调试一段时间后,我得到一个很小的梯度检验值,现在我可以很自信的说,神经网络实施是正确的。
现在你已经了解了梯度检验的工作原理,它帮助我在神经网络实施中发现了很多bug,希望它对你也有所帮助。
13.梯度检验应用的注意事项

首先,不要在训练中使用梯度检验,它只用于调试。我的意思是,计算所有i值的d\theta_{\text{approx}}\lefti\\right是一个非常漫长的计算过程,为了实施梯度下降,你必须使用W和b backprop 来计算d\theta,并使用backprop来计算导数,只要调试的时候,你才会计算它,来确认数值是否接近d\theta。完成后,你会关闭梯度检验,梯度检验的每一个迭代过程都不执行它,因为它太慢了。
第二点,如果算法的梯度检验失败,要检查所有项,检查每一项,并试着找出bug ,也就是说,如果d\theta_{\text{approx}}\lefti\\right与dθi的值相差很大,我们要做的就是查找不同的i值,看看是哪个导致d\theta_{\text{approx}}\lefti\\right与d\theta\lefti\\right的值相差这么多。举个例子,如果你发现,相对某些层或某层的\theta或d\theta的值相差很大,但是\text{dw}^{l}的各项非常接近,注意\theta的各项与b和w的各项都是一一对应的,这时,你可能会发现,在计算参数b的导数db的过程中存在bug 。反过来也是一样,如果你发现它们的值相差很大,d\theta_{\text{approx}}\lefti\\right的值与d\theta\lefti\\right的值相差很大,你会发现所有这些项目都来自于dw或某层的dw,可能帮你定位bug的位置,虽然未必能够帮你准确定位bug的位置,但它可以帮助你估测需要在哪些地方追踪bug。
第三点,在实施梯度检验时,如果使用正则化,请注意正则项。如果代价函数J(\theta) = \frac{1}{m}\sum_{}^{}{L(\hat y^{(i)},y^{(i)})} + \frac{\lambda}{2m}\sum_{}^{}{||W^{l}||}^{2},这就是代价函数J的定义,d\theta等于与\theta相关的J函数的梯度,包括这个正则项,记住一定要包括这个正则项。
第四点,梯度检验不能与dropout 同时使用,因为每次迭代过程中,dropout 会随机消除隐藏层单元的不同子集,难以计算dropout 在梯度下降上的代价函数J。因此dropout 可作为优化代价函数J的一种方法,但是代价函数J被定义为对所有指数极大的节点子集求和。而在任何迭代过程中,这些节点都有可能被消除,所以很难计算代价函数J。你只是对成本函数做抽样,用dropout ,每次随机消除不同的子集,所以很难用梯度检验来双重检验dropout 的计算,所以我一般不同时使用梯度检验和dropout 。如果你想这样做,可以把dropout 中的keepprob 设置为1.0,然后打开dropout ,并寄希望于dropout 的实施是正确的,你还可以做点别的,比如修改节点丢失模式确定梯度检验是正确的。实际上,我一般不这么做,我建议关闭dropout ,用梯度检验进行双重检查,在没有dropout 的情况下,你的算法至少是正确的,然后打开dropout。
最后一点,也是比较微妙的一点,现实中几乎不会出现这种情况。当w和b接近0时,梯度下降的实施是正确的,在随机初始化过程中......,但是在运行梯度下降时,w和b变得更大。可能只有在w和b接近0时,backprop的实施才是正确的。但是当W和b变大时,它会变得越来越不准确。你需要做一件事,我不经常这么做,就是在随机初始化过程中,运行梯度检验,然后再训练网络,w和b会有一段时间远离0,如果随机初始化值比较小,反复训练网络之后,再重新运行梯度检验。
Week2:优化算法 (Optimization algorithms)
1.小批量梯度下降
那么究竟mini-batch 梯度下降法的原理是什么?在训练集上运行mini-batch 梯度下降法,你运行for t=1......5000,因为我们有5000个各有1000个样本的组,在for循环里你要做得基本就是对X^{\{t\}}和Y^{\{t\}}执行一步梯度下降法。假设你有一个拥有1000个样本的训练集,而且假设你已经很熟悉一次性处理完的方法,你要用向量化去几乎同时处理1000个样本。

首先对输入也就是X^{\{ t\}},执行前向传播,然后执行z^{\lbrack 1\rbrack} =W^{\lbrack 1\rbrack}X + b^{\lbrack 1\rbrack},之前我们这里只有,但是现在你正在处理整个训练集,你在处理第一个mini-batch ,在处理mini-batch 时它变成了X^{\{ t\}},即z^{\lbrack 1\rbrack} = W^{\lbrack 1\rbrack}X^{\{ t\}} + b^{\lbrack1\rbrack},然后执行A^{1k} =g^{1}(Z^{1}),之所以用大写的Z是因为这是一个向量内涵,以此类推,直到A^{\lbrack L\rbrack} = g^{\left\lbrack L \right\rbrack}(Z^{\lbrack L\rbrack}),这就是你的预测值。注意这里你需要用到一个向量化的执行命令,这个向量化的执行命令,一次性处理1000个而不是500万个样本。接下来你要计算损失成本函数J,因为子集规模是1000,J= \frac{1}{1000}\sum_{i = 1}^{l}{L(\hat y^{(i)},y^{(i)})},说明一下,这(L(\hat y^{(i)},y^{(i)}))指的是来自于mini-batchX^{\{ t\}}和Y^{\{t\}}中的样本。
如果你用到了正则化,你也可以使用正则化的术语,J =\frac{1}{1000}\sum_{i = 1}^{l}{L(\hat y^{(i)},y^{(i)})} +\frac{\lambda}{2 1000}\sum_{l}^{}{||w^{l}||}{F}^{2},因为这是一个mini-batch的损失,所以我将J损失记为上角标t,放在大括号里(J^{\{t\}} = \frac{1}{1000}\sum{i = 1}^{l}{L(\hat y^{(i)},y^{(i)})} +\frac{\lambda}{2 1000}\sum_{l}^{}{||w^{l}||}_{F}^{2})。
你也会注意到,我们做的一切似曾相识,其实跟之前我们执行梯度下降法如出一辙,除了你现在的对象不是X,Y,而是X^{\{t\}}和Y^{\{ t\}}。接下来,你执行反向传播来计算J^{\{t\}}的梯度,你只是使用X^{\{ t\}}和Y^{\{t\}},然后你更新加权值,W实际上是W^{\lbrack l\rbrack},更新为W^{l}:= W^{l} - adW^{l},对b做相同处理,b^{l}:= b^{l} - adb^{l}。这是使用mini-batch 梯度下降法训练样本的一步,我写下的代码也可被称为进行"一代"(1 epoch)的训练。一代这个词意味着只是一次遍历了训练集。

使用batch 梯度下降法,一次遍历训练集只能让你做一个梯度下降,使用mini-batch 梯度下降法,一次遍历训练集,能让你做5000个梯度下降。当然正常来说你想要多次遍历训练集,还需要为另一个while 循环设置另一个for循环。所以你可以一直处理遍历训练集,直到最后你能收敛到一个合适的精度。
如果你有一个丢失的训练集,mini-batch 梯度下降法比batch 梯度下降法运行地更快,所以几乎每个研习深度学习的人在训练巨大的数据集时都会用到,下一个视频中,我们将进一步深度讨论mini-batch梯度下降法,你也会因此更好地理解它的作用和原理。
2.理解小批量梯度下降
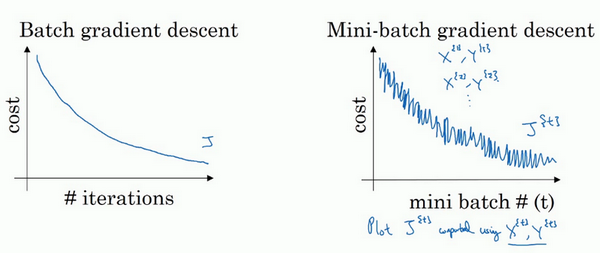
使用batch梯度下降法时,每次迭代你都需要历遍整个训练集,可以预期每次迭代成本都会下降,所以如果成本函数J是迭代次数的一个函数,它应该会随着每次迭代而减少,如果J在某次迭代中增加了,那肯定出了问题,也许你的学习率太大。
使用mini-batch 梯度下降法,如果你作出成本函数在整个过程中的图,则并不是每次迭代都是下降的,特别是在每次迭代中,你要处理的是X^{\{t\}}和Y^{\{ t\}},如果要作出成本函数J^{\{ t\}}的图,而J^{\{t\}}只和X^{\{ t\}},Y^{\{t\}}有关,也就是每次迭代下你都在训练不同的样本集或者说训练不同的mini-batch ,如果你要作出成本函数J的图,你很可能会看到这样的结果,走向朝下,但有更多的噪声,所以如果你作出J^{\{t\}}的图,因为在训练mini-batch 梯度下降法时,会经过多代,你可能会看到这样的曲线。没有每次迭代都下降是不要紧的,但走势应该向下,噪声产生的原因在于也许X^{\{1\}}和Y^{\{1\}}是比较容易计算的mini-batch ,因此成本会低一些。不过也许出于偶然,X^{\{2\}}和Y^{\{2\}}是比较难运算的mini-batch ,或许你需要一些残缺的样本,这样一来,成本会更高一些,所以才会出现这些摆动,因为你是在运行mini-batch梯度下降法作出成本函数图。
你需要决定的变量之一是mini-batch 的大小,m就是训练集的大小,极端情况下,如果mini-batch 的大小等于m,其实就是batch 梯度下降法,在这种极端情况下,你就有了mini-batch X^{\{1\}}和Y^{\{1\}},并且该mini-batch 等于整个训练集,所以把mini-batch 大小设为m可以得到batch 梯度下降法。
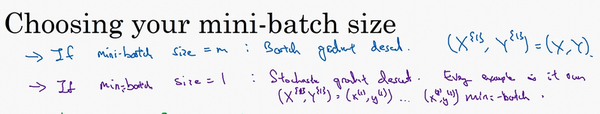
另一个极端情况,假设mini-batch 大小为1,就有了新的算法,叫做随机梯度下降法,每个样本都是独立的mini-batch ,当你看第一个mini-batch ,也就是X^{\{1\}}和Y^{\{1\}},如果mini-batch 大小为1,它就是你的第一个训练样本,这就是你的第一个训练样本。接着再看第二个mini-batch ,也就是第二个训练样本,采取梯度下降步骤,然后是第三个训练样本,以此类推,一次只处理一个。
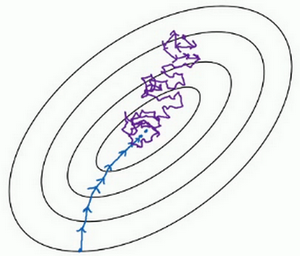
看在两种极端下成本函数的优化情况,如果这是你想要最小化的成本函数的轮廓,最小值在那里,batch梯度下降法从某处开始,相对噪声低些,幅度也大一些,你可以继续找最小值。
相反,在随机梯度下降法中,从某一点开始,我们重新选取一个起始点,每次迭代,你只对一个样本进行梯度下降,大部分时候你向着全局最小值靠近,有时候你会远离最小值,因为那个样本恰好给你指的方向不对,因此随机梯度下降法是有很多噪声的,平均来看,它最终会靠近最小值,不过有时候也会方向错误,因为随机梯度下降法永远不会收敛,而是会一直在最小值附近波动,但它并不会在达到最小值并停留在此。
实际上你选择的mini-batch 大小在二者之间,大小在1和m之间,而1太小了,m太大了,原因在于如果使用batch 梯度下降法,mini-batch 的大小为m,每个迭代需要处理大量训练样本,该算法的主要弊端在于特别是在训练样本数量巨大的时候,单次迭代耗时太长。如果训练样本不大,batch梯度下降法运行地很好

相反,如果使用随机梯度下降法,如果你只要处理一个样本,那这个方法很好,这样做没有问题,通过减小学习率,噪声会被改善或有所减小,但随机梯度下降法的一大缺点是,你会失去所有向量化带给你的加速,因为一次性只处理了一个训练样本,这样效率过于低下,所以实践中最好选择不大不小的mini-batch 尺寸,实际上学习率达到最快。你会发现两个好处,一方面,你得到了大量向量化,上个视频中我们用过的例子中,如果mini-batch 大小为1000个样本,你就可以对1000个样本向量化,比你一次性处理多个样本快得多。另一方面,你不需要等待整个训练集被处理完就可以开始进行后续工作,再用一下上个视频的数字,每次训练集允许我们采取5000个梯度下降步骤,所以实际上一些位于中间的mini-batch 大小效果最好。
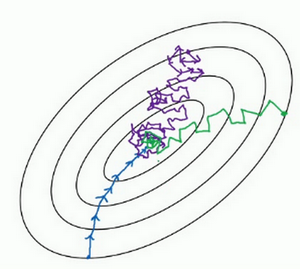
用mini-batch梯度下降法,我们从这里开始,一次迭代这样做,两次,三次,四次,它不会总朝向最小值靠近,但它比随机梯度下降要更持续地靠近最小值的方向,它也不一定在很小的范围内收敛或者波动,如果出现这个问题,可以慢慢减少学习率,我们在下个视频会讲到学习率衰减,也就是如何减小学习率。
如果mini-batch大小既不是1也不是m,应该取中间值,那应该怎么选择呢?其实是有指导原则的。
首先,如果训练集较小,直接使用batch 梯度下降法,样本集较小就没必要使用mini-batch 梯度下降法,你可以快速处理整个训练集,所以使用batch 梯度下降法也很好,这里的少是说小于2000个样本,这样比较适合使用batch 梯度下降法。不然,样本数目较大的话,一般的mini-batch 大小为64到512,考虑到电脑内存设置和使用的方式,如果mini-batch 大小是2的n次方,代码会运行地快一些,64就是2的6次方,以此类推,128是2的7次方,256是2的8次方,512是2的9次方。所以我经常把mini-batch 大小设成2的次方。在上一个视频里,我的mini-batch 大小设为了1000,建议你可以试一下1024,也就是2的10次方。也有mini-batch 的大小为1024,不过比较少见,64到512的mini-batch比较常见。
最后需要注意的是在你的mini-batch 中,要确保X^{\{ t\}}和Y^{\{t\}}要符合CPU /GPU 内存,取决于你的应用方向以及训练集的大小。如果你处理的mini-batch 和CPU /GPU 内存不相符,不管你用什么方法处理数据,你会注意到算法的表现急转直下变得惨不忍睹,所以我希望你对一般人们使用的mini-batch 大小有一个直观了解。事实上mini-batch 大小是另一个重要的变量,你需要做一个快速尝试,才能找到能够最有效地减少成本函数的那个,我一般会尝试几个不同的值,几个不同的2次方,然后看能否找到一个让梯度下降优化算法最高效的大小。希望这些能够指导你如何开始找到这一数值。
表格
|-------|---------|-----------|------------|
| 特点 | BGD 批量 | SGD 随机 | MBGD 小批量 |
| 每次样本数 | 全部样本 | 单个样本 | 固定小批次 |
| 收敛速度 | 慢 | 很快 | 适中最快 |
| 震荡程度 | 无震荡,平稳 | 震荡剧烈 | 小幅震荡 |
| 最优值 | 精准收敛最低点 | 难精准收敛 | 易收敛最优 |
| 算力内存 | 极大 | 极小 | 适中 |
| 泛化能力 | 一般 | 强(自带噪声正则) | 最优 |
| 适用场景 | 极小数据集 | 老式机器学习 | 深度学习标配 |
3.指数加权平均数
指数加权平均数算法比梯度下降法要快
你要做的是,首先使v_{0} =0,每天,需要使用0.9的加权数之前的数值加上当日温度的0.1倍,即v_{1} =0.9v_{0} + 0.1\theta_{1},所以这里是第一天的温度值。
第二天,又可以获得一个加权平均数,0.9乘以之前的值加上当日的温度0.1倍,即v_{2}= 0.9v_{1} + 0.1\theta_{2},以此类推。
第二天值加上第三日数据的0.1,如此往下。大体公式就是某天的v等于前一天v值的0.9加上当日温度的0.1。
如此计算,然后用红线作图的话,便得到这样的结果。
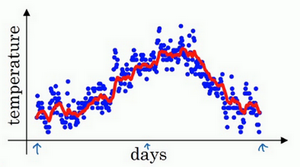
你得到了移动平均值,每日温度的指数加权平均值。
看一下上一张幻灯片里的公式,v_{t} = 0.9v_{t - 1} +0.1\theta_{t},我们把0.9这个常数变成\beta,将之前的0.1变成(1 - \beta),即v_{t} = \beta v_{t - 1} + (1 - \beta)\theta_{t}
由于以后我们要考虑的原因,在计算时可视v_{t}大概是\frac{1}{(1 -\beta)}的每日温度,如果\beta是0.9,你会想,这是十天的平均值,也就是红线部分。
我们来试试别的,将\beta设置为接近1的一个值,比如0.98,计算\frac{1}{(1 - 0.98)} =50,这就是粗略平均了一下,过去50天的温度,这时作图可以得到绿线。
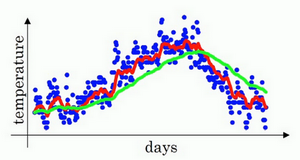
这个高值\beta要注意几点,你得到的曲线要平坦一些,原因在于你多平均了几天的温度,所以这个曲线,波动更小,更加平坦,缺点是曲线进一步右移,因为现在平均的温度值更多,要平均更多的值,指数加权平均公式在温度变化时,适应地更缓慢一些,所以会出现一定延迟,因为当\beta=0.98,相当于给前一天的值加了太多权重,只有0.02的权重给了当日的值,所以温度变化时,温度上下起伏,当\beta 较大时,指数加权平均值适应地更缓慢一些。
我们可以再换一个值试一试,如果\beta是另一个极端值,比如说0.5,根据右边的公式(\frac{1}{(1-\beta)}),这是平均了两天的温度。

作图运行后得到黄线。
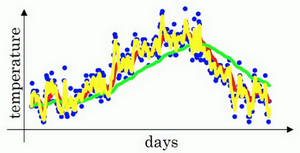
由于仅平均了两天的温度,平均的数据太少,所以得到的曲线有更多的噪声,有可能出现异常值,但是这个曲线能够更快适应温度变化。
所以指数加权平均数经常被使用,再说一次,它在统计学中被称为指数加权移动平均值,我们就简称为指数加权平均数。通过调整这个参数(\beta),或者说后面的算法学习,你会发现这是一个很重要的参数,可以取得稍微不同的效果,往往中间有某个值效果最好,\beta为中间值时得到的红色曲线,比起绿线和黄线更好地平均了温度。
4.理解指数加权平均数
- 越近的数据权重越大,越久远数据权重指数衰减
- 等效大概平均 (\dfrac{1}{1-\beta}) 个历史数据
- 例:(\beta=0.9) → 平均近10个数据
指数加权平均数公式的好处之一在于,它占用极少内存,电脑内存中只占用一行数字而已,然后把最新数据代入公式,不断覆盖就可以了,正因为这个原因,其效率,它基本上只占用一行代码,计算指数加权平均数也只占用单行数字的存储和内存,当然它并不是最好的,也不是最精准的计算平均数的方法。如果你要计算移动窗,你直接算出过去10天的总和,过去50天的总和,除以10和50就好,如此往往会得到更好的估测。但缺点是,如果保存所有最近的温度数据,和过去10天的总和,必须占用更多的内存,执行更加复杂,计算成本也更加高昂。
5.指数加权平均偏差修正
计算移动平均数的时候,初始化v_{0} = 0,v_{1} = 0.98v_{0} +0.02\theta_{1},但是v_{0} =0,所以这部分没有了(0.98v_{0}),所以v_{1} =0.02\theta_{1},所以如果一天温度是40华氏度,那么v_{1} = 0.02\theta_{1} =0.02 \times 40 = 8,因此得到的值会小很多,所以第一天温度的估测不准。
v_{2} = 0.98v_{1} + 0.02\theta_{2},如果代入v_{1},然后相乘,所以v_{2}= 0.98 \times 0.02\theta_{1} + 0.02\theta_{2} = 0.0196\theta_{1} +0.02\theta_{2},假设\theta_{1}和\theta_{2}都是正数,计算后v_{2}要远小于\theta_{1}和\theta_{2},所以v_{2}不能很好估测出这一年前两天的温度。
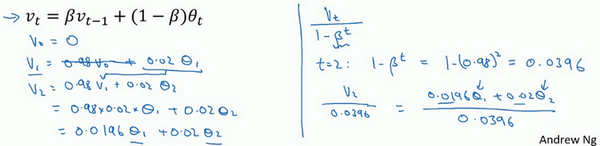
有个办法可以修改这一估测,让估测变得更好,更准确,特别是在估测初期,也就是不用v_{t},而是用\frac{v_{t}}{1- \beta^{t}},t就是现在的天数。举个具体例子,当t=2时,1 - \beta^{t} = 1 - {0.98}^{2} = 0.0396,因此对第二天温度的估测变成了\frac{v_{2}}{0.0396} =\frac{0.0196\theta_{1} + 0.02\theta_{2}}{0.0396},也就是\theta_{1}和\theta_{2}的加权平均数,并去除了偏差。你会发现随着t增加,\beta^{t}接近于0,所以当t很大的时候,偏差修正几乎没有作用,因此当t较大的时候,紫线基本和绿线重合了。不过在开始学习阶段,你才开始预测热身练习,偏差修正可以帮助你更好预测温度,偏差修正可以帮助你使结果从紫线变成绿线。
在机器学习中,在计算指数加权平均数的大部分时候,大家不在乎执行偏差修正,因为大部分人宁愿熬过初始时期,拿到具有偏差的估测,然后继续计算下去。如果你关心初始时期的偏差,在刚开始计算指数加权移动平均数的时候,偏差修正能帮助你在早期获取更好的估测。
6.动量梯度下降
核心思想:在SGD 随机梯度下降 基础上,引入历史梯度累积 ,用指数加权平均 EMA 平滑梯度,减少震荡、加快收敛、冲出局部最优。
公式:
- 累积动量(梯度移动平均) v_t = \beta v_{t-1} + (1-\beta)g_t g_t:当前批次梯度 \beta 常用 0.9
- 参数更新 \theta_t = \theta_{t-1} - \alpha \cdot v_t \alpha:学习率
- 普通 SGD:只看当下梯度,走一步看一步,容易左右晃
- 动量 Momentum:带着之前的惯性往前走 下坡顺势加速,遇到震荡自动平缓

第一步:
dW:当前小批量数据计算出的权重梯度
db:当前小批量数据计算出的偏置梯度
第二步:
v_dW/v_db:权重 / 偏置的动量变量(累积的梯度移动平均)
β:动量系数,这里固定为0.9,表示 "记住过去 10 轮左右的梯度"
- 公式含义:
-
β * v_dW:保留上一轮累积的梯度(惯性)
-
(1 - β) * dW:加入当前新的梯度信息
- 效果:平滑掉梯度的随机震荡,让下降方向更稳定,同时保持下降的 "惯性",加快收敛。
第三步:
W/b:模型的权重和偏置参数
α:学习率(控制每次更新的步长)
- 关键区别:
-
- 普通 SGD:用
dW/db直接更新
- 普通 SGD:用
-
- 动量 SGD:用 累积的动量
v_dW/v_db来更新
- 动量 SGD:用 累积的动量
- 效果:沿着平滑后的梯度方向前进,既减少震荡,又能更快冲出局部最优。
α:学习率,决定每次更新的步长大小
β:动量系数,常用值就是 0.9,代表 "90% 的历史惯性 + 10% 的当前梯度"
7.RMSprop优化算法
RMSprop全称root mean square prop,主要解决动量梯度下降左右摆动大,纵向更新慢的问题。
解决思路:自适应调整学习率
- 梯度大的方向:减小步长
- 梯度小的方向:放大步长
核心公式:
- 累积梯度平方(指数加权平均) S_{dW} = \beta \cdot S_{dW} + (1-\beta)\cdot (dW)^2 S_{db} = \beta \cdot S_{db} + (1-\beta)\cdot (db)^2
- 参数更新 W = W - \alpha \cdot \frac{dW}{\sqrt{S_{dW}}+\varepsilon} b = b - \alpha \cdot \frac{db}{\sqrt{S_{db}}+\varepsilon}
参数含义
- \beta:一般取 0.9,平滑梯度平方
- \alpha:全局学习率
- \varepsilon:极小值(10^{-8}),防止分母为 0
- S_{dW}:历史梯度平方的移动平均值
RMSprop + Momentum 动量 = Adam
我们来拆解一下:为什么 RMSprop 要用梯度的平方做指数加权平均,而不是直接用梯度本身。
一、核心目的:解决「梯度更新方向不平衡」的问题
RMSprop 想解决的痛点是:
- 在某些方向上,梯度波动很大(来回震荡);
- 在另一些方向上,梯度变化很平缓,前进缓慢。
如果我们直接对梯度做平均(不平方),会遇到两个致命问题:
- 梯度有正有负,直接平均会互相抵消
举个例子:
- 某方向上的梯度序列是:
+0.1, -0.1, +0.1, -0.1
- 直接做指数加权平均的话,结果会趋近于 0,相当于认为这个方向 "梯度很小,应该放大步长"。
- 但实际上,这个方向梯度的波动非常剧烈 ,正确的做法是缩小步长来稳定更新。
梯度的正负代表方向,而平方可以消除符号,只反映 "波动大小",让算法知道 "这个方向梯度震荡很厉害,得放慢脚步"。
- 用平方可以实现「按梯度大小缩放学习率」的效果
RMSprop 的更新公式是:
W = W - \alpha \cdot \frac{dW}{\sqrt{S_{dW}}+\varepsilon}
其中 S_{dW} 是梯度平方的指数加权平均,\sqrt{S_{dW}} 就是梯度的均方根(RMS),可以理解为 "梯度的平均波动幅度"。
- 如果 dW 波动大 → S_{dW} 大 → 分母大 → 实际步长 \alpha \cdot \frac{dW}{\sqrt{S_{dW}}} 被缩小,避免震荡;
- 如果 dW 波动小 → S_{dW}小 → 分母小 → 实际步长被放大,加快前进。
如果不用平方,分母是梯度的平均(有正有负),就无法实现这种 "按波动幅度缩放步长" 的效果,RMSprop 的核心优势就消失了。
RMSprop 用梯度的平方做指数加权平均,是为了:
- 消除梯度的正负号,避免梯度互相抵消;
- 捕捉梯度的波动幅度,实现 "梯度大的方向缩小步长、梯度小的方向放大步长" 的自适应学习率,从而解决梯度下降中的震荡问题。
8. Adam优化算法
Adam = 动量 Momentum + RMSprop 结合体
同时拥有惯性加速 + 自适应学习率,深度学习最通用优化器。
- 一阶矩(动量,梯度均值 EMA) v_t = \beta_1 v_{t-1} + (1-\beta_1)g_t
- 二阶矩(梯度平方 EMA,RMSprop 思想) s_t = \beta_2 s_{t-1} + (1-\beta_2)g_t^2
- 偏差修正(解决初期偏置) \hat{v}_t = \frac{v_t}{1-\beta_1^t},\quad \hat{s}_t = \frac{s_t}{1-\beta_2^t}
- 参数更新 \theta_t = \theta_{t-1} - \alpha \cdot \frac{\hat{v}_t}{\sqrt{\hat{s}_t}+\varepsilon}
默认超参
- \alpha 学习率:0.001
- \beta_1 一阶矩系数:0.9
- \beta_2 二阶矩系数:0.999
- \varepsilon 防除零极小值:10^{-8}
各部分作用:
- 一阶矩 ( v_t ) 继承动量,累积历史梯度,增加惯性、加速收敛、减小震荡
- 二阶矩 ( s_t ) 累积梯度平方,实现自适应学习率 梯度大 → 步长缩小;梯度小 → 步长放大
- 偏差修正 迭代初期(v、s)初始为 0,值偏小,修正后前期更新更准确
Adam 优化算法基本上就是将Momentum 和RMSprop 结合在一起,那么来看看如何使用Adam算法。

使用Adam 算法,首先你要初始化,v_{dW} = 0,S_{dW} =0,v_{db} = 0,S_{db} =0,在第t次迭代中,你要计算微分,用当前的mini-batch 计算dW,db,一般你会用mini-batch 梯度下降法。接下来计算Momentum 指数加权平均数,所以v_{dW}= \beta_{1}v_{dW} + ( 1 - \beta_{1})dW(使用\beta_{1},这样就不会跟超参数\beta_{2}混淆,因为后面RMSprop 要用到\beta_{2}),使用Momentum时我们肯定会用这个公式,但现在不叫它\beta,而叫它\beta_{1}。同样v_{db}= \beta_{1}v_{db} + ( 1 -\beta_{1} ){db}。
接着你用RMSprop进行更新,即用不同的超参数\beta_{2},S_{dW}=\beta_{2}S_{dW} + ( 1 - \beta_{2}){(dW)}^{2},再说一次,这里是对整个微分dW进行平方处理,S_{db} =\beta_{2}S_{db} + \left( 1 - \beta_{2} \right){(db)}^{2}。
相当于Momentum 更新了超参数\beta_{1},RMSprop 更新了超参数\beta_{2}。一般使用Adam算法的时候,要计算偏差修正,v_{dW}^{\text{corrected}},修正也就是在偏差修正之后,
v_{dW}^{\text{corrected}}= \frac{v_{dW}}{1 - \beta_{1}^{t}},
同样v_{db}^{\text{corrected}} =\frac{v_{db}}{1 -\beta_{1}^{t}},
S也使用偏差修正,也就是S_{dW}^{\text{corrected}} =\frac{S_{dW}}{1 - \beta_{2}^{t}},S_{db}^{\text{corrected}} =\frac{S_{db}}{1 - \beta_{2}^{t}}。
最后更新权重,所以W更新后是W:= W - \frac{a v_{dW}^{\text{corrected}}}{\sqrt{S_{dW}^{\text{corrected}}} +\varepsilon}(如果你只是用Momentum ,使用v_{dW}或者修正后的v_{dW},但现在我们加入了RMSprop的部分,所以我们要除以修正后S_{dW}的平方根加上\varepsilon)。
根据类似的公式更新b值,b:=b - \frac{\alpha v_{\text{db}}^{\text{corrected}}}{\sqrt{S_{\text{db}}^{\text{corrected}}} +\varepsilon}。
所以Adam 算法结合了Momentum 和RMSprop梯度下降法,并且是一种极其常用的学习算法,被证明能有效适用于不同神经网络,适用于广泛的结构。
9.学习率衰减
加快学习算法的一个办法就是随时间慢慢减少学习率,我们将之称为学习率衰减
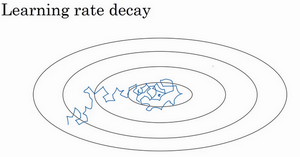
假设你要使用mini-batch 梯度下降法,mini-batch 数量不大,大概64或者128个样本,在迭代过程中会有噪音(蓝色线),下降朝向这里的最小值,但是不会精确地收敛,所以你的算法最后在附近摆动,并不会真正收敛,因为你用的a是固定值,不同的mini-batch 中有噪音。
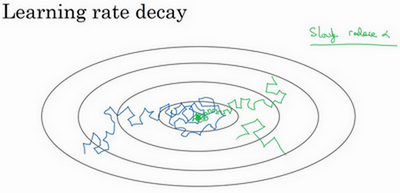
但要慢慢减少学习率a的话,在初期的时候,a学习率还较大,你的学习还是相对较快,但随着a变小,你的步伐也会变慢变小,所以最后你的曲线(绿色线)会在最小值附近的一小块区域里摆动,而不是在训练过程中,大幅度在最小值附近摆动。
所以慢慢减少a的本质在于,在学习初期,你能承受较大的步伐,但当开始收敛的时候,小一些的学习率能让你步伐小一些。
你可以这样做到学习率衰减,记得一代要遍历一次数据,如果你有以下这样的训练集,

你应该拆分成不同的mini-batch ,第一次遍历训练集叫做第一代。第二次就是第二代,依此类推,你可以将a学习率设为a= \frac{1}{1 + decayrate * \text{epoch}\text{-num}}a_{0}(decay-rate 称为衰减率,epoch-num 为代数,\alpha_{0}为初始学习率),注意这个衰减率是另一个你需要调整的超参数。
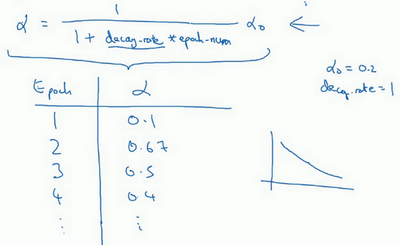
这里有一个具体例子,如果你计算了几代,也就是遍历了几次,如果a_{0}为0.2,衰减率decay-rate 为1,那么在第一代中,a = \frac{1}{1 + 1}a_{0} = 0.1,这是在代入这个公式计算(a= \frac{1}{1 + decayrate * \text{epoch}\text{-num}}a_{0}),此时衰减率是1而代数是1。在第二代学习率为0.67,第三代变成0.5,第四代为0.4等等,你可以自己多计算几个数据。要理解,作为代数函数,根据上述公式,你的学习率呈递减趋势。如果你想用学习率衰减,要做的是要去尝试不同的值,包括超参数a_{0},以及超参数衰退率,找到合适的值,除了这个学习率衰减的公式,人们还会用其它的公式。

比如,这个叫做指数衰减,其中a相当于一个小于1的值,如a ={0.95}^{\text{epoch-num}} a_{0},所以你的学习率呈指数下降。
人们用到的其它公式有a =\frac{k}{\sqrt{\text{epoch-num}}}a_{0}或者a =\frac{k}{\sqrt{t}}a_{0}(t为mini-batch的数字)。
有时人们也会用一个离散下降的学习率,也就是某个步骤有某个学习率,一会之后,学习率减少了一半,一会儿减少一半,一会儿又一半,这就是离散下降(discrete stair cease)的意思。
到现在,我们讲了一些公式,看学习率a究竟如何随时间变化。人们有时候还会做一件事,手动衰减。如果你一次只训练一个模型,如果你要花上数小时或数天来训练,有些人的确会这么做,看看自己的模型训练,耗上数日,然后他们觉得,学习速率变慢了,我把a调小一点。手动控制a当然有用,时复一时,日复一日地手动调整a,只有模型数量小的时候有用,但有时候人们也会这么做。
所以现在你有了多个选择来控制学习率a。你可能会想,好多超参数,究竟我应该做哪一个选择,我觉得,现在担心为时过早。下一周,我们会讲到,如何系统选择超参数。对我而言,学习率衰减并不是我尝试的要点,设定一个固定的a,然后好好调整,会有很大的影响,学习率衰减的确大有裨益,有时候可以加快训练,但它并不是我会率先尝试的内容,但下周我们将涉及超参数调整,你能学到更多系统的办法来管理所有的超参数,以及如何高效搜索超参数。
10.局部最优解问题
在深度学习研究早期,人们总是担心优化算法会困在极差的局部最优,不过随着深度学习理论不断发展,我们对局部最优的理解也发生了改变。我向你展示一下现在我们怎么看待局部最优以及深度学习中的优化问题。
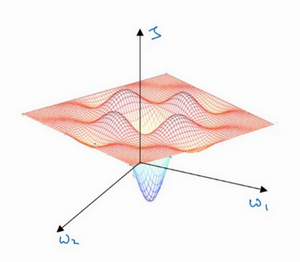
这是曾经人们在想到局部最优时脑海里会出现的图,也许你想优化一些参数,我们把它们称之为W_{1}和W_{2},平面的高度就是损失函数。在图中似乎各处都分布着局部最优。梯度下降法或者某个算法可能困在一个局部最优中,而不会抵达全局最优。如果你要作图计算一个数字,比如说这两个维度,就容易出现有多个不同局部最优的图,而这些低维的图曾经影响了我们的理解,但是这些理解并不正确。事实上,如果你要创建一个神经网络,通常梯度为零的点并不是这个图中的局部最优点,实际上成本函数的零梯度点,通常是鞍点 。
也就是在这个点,这里是W_{1}和W_{2},高度即成本函数J的值。
但是一个具有高维度空间的函数,如果梯度为0,那么在每个方向,它可能是凸函数,也可能是凹函数。如果你在2万维空间中,那么想要得到局部最优,所有的2万个方向都需要是这样,但发生的机率也许很小,也许是2^{-20000},你更有可能遇到有些方向的曲线会这样向上弯曲,另一些方向曲线向下弯,而不是所有的都向上弯曲,因此在高维度空间,你更可能碰到鞍点。
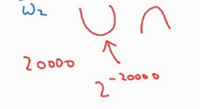
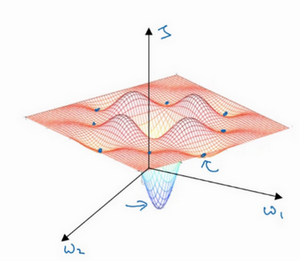
就像下面的这种:
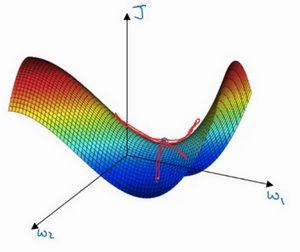
而不会碰到局部最优。至于为什么会把一个曲面叫做鞍点,你想象一下,就像是放在马背上的马鞍一样,如果这是马,这是马的头,这就是马的眼睛,画得不好请多包涵,然后你就是骑马的人,要坐在马鞍上,因此这里的这个点,导数为0的点,这个点叫做鞍点。我想那确实是你坐在马鞍上的那个点,而这里导数为0。
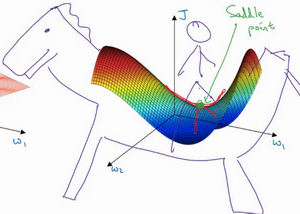
所以我们从深度学习历史中学到的一课就是,我们对低维度空间的大部分直觉,比如你可以画出上面的图,并不能应用到高维度空间中。适用于其它算法,因为如果你有2万个参数,那么J函数有2万个维度向量,你更可能遇到鞍点,而不是局部最优点。
如果局部最优不是问题,那么问题是什么?结果是平稳段会减缓学习,平稳段是一块区域,其中导数长时间接近于0,如果你在此处,梯度会从曲面从从上向下下降,因为梯度等于或接近0,曲面很平坦,你得花上很长时间慢慢抵达平稳段的这个点,因为左边或右边的随机扰动,我换个笔墨颜色,大家看得清楚一些,然后你的算法能够走出平稳段(红色笔)。
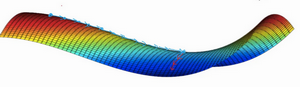
我们可以沿着这段长坡走,直到这里,然后走出平稳段。
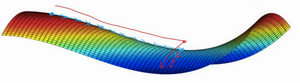
所以此次视频的要点是,首先,你不太可能困在极差的局部最优中,条件是你在训练较大的神经网络,存在大量参数,并且成本函数J被定义在较高的维度空间。
第二点,平稳段是一个问题,这样使得学习十分缓慢 ,这也是像Momentum 或是RMSprop ,Adam 这样的算法,能够加速学习算法的地方。在这些情况下,更成熟的优化算法,如Adam算法,能够加快速度,让你尽早往下走出平稳段。
因为你的网络要解决优化问题,说实话,要面临如此之高的维度空间,我觉得没有人有那么好的直觉,知道这些空间长什么样,而且我们对它们的理解还在不断发展,不过我希望这一点能够让你更好地理解优化算法所面临的问题。
Week3 超参数调试、Batch正则化和程序框架(Hyperparameter tuning)
1.调参流程
学习率是最重要的
2.为超参数选择合适的范围
3.超参数调优---panda or caviar?

一种是你照看一个模型,通常是有庞大的数据组,但没有许多计算资源或足够的CPU 和GPU 的前提下,基本而言,你只可以一次负担起试验一个模型或一小批模型,在这种情况下,即使当它在试验时,你也可以逐渐改良。比如,第0天,你将随机参数初始化,然后开始试验,然后你逐渐观察自己的学习曲线,也许是损失函数J,或者数据设置误差或其它的东西,在第1天内逐渐减少,那这一天末的时候,你可能会说,看,它学习得真不错。我试着增加一点学习速率,看看它会怎样,也许结果证明它做得更好,那是你第二天的表现。两天后,你会说,它依旧做得不错,也许我现在可以填充下Momentum或减少变量。然后进入第三天,每天,你都会观察它,不断调整你的参数。也许有一天,你会发现你的学习率太大了,所以你可能又回归之前的模型,像这样,但你可以说是在每天花时间照看此模型,即使是它在许多天或许多星期的试验过程中。所以这是一个人们照料一个模型的方法,观察它的表现,耐心地调试学习率,但那通常是因为你没有足够的计算能力,不能在同一时间试验大量模型时才采取的办法。
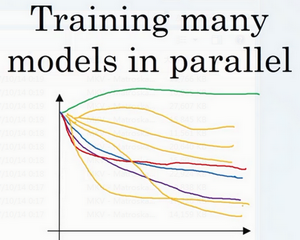
另一种方法则是同时试验多种模型,你设置了一些超参数,尽管让它自己运行,或者是一天甚至多天,然后你会获得像这样的学习曲线,这可以是损失函数J或实验误差或损失或数据误差的损失,但都是你曲线轨迹的度量。同时你可以开始一个有着不同超参数设定的不同模型,所以,你的第二个模型会生成一个不同的学习曲线,也许是像这样的一条(紫色曲线),我会说这条看起来更好些。与此同时,你可以试验第三种模型,其可能产生一条像这样的学习曲线(红色曲线),还有另一条(绿色曲线),也许这条有所偏离,像这样,等等。或者你可以同时平行试验许多不同的模型,橙色的线就是不同的模型。用这种方式你可以试验许多不同的参数设定,然后只是最后快速选择工作效果最好的那个。在这个例子中,也许这条看起来是最好的(下方绿色曲线)。
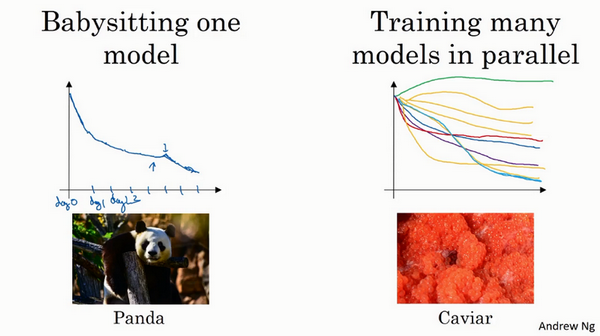
打个比方,我把左边的方法称为熊猫方式。当熊猫有了孩子,他们的孩子非常少,一次通常只有一个,然后他们花费很多精力抚养熊猫宝宝以确保其能成活,所以,这的确是一种照料,一种模型类似于一只熊猫宝宝。对比而言,右边的方式更像鱼类的行为,我称之为鱼子酱方式。在交配季节,有些鱼类会产下一亿颗卵,但鱼类繁殖的方式是,它们会产生很多卵,但不对其中任何一个多加照料,只是希望其中一个,或其中一群,能够表现出色。我猜,这就是哺乳动物繁衍和鱼类,很多爬虫类动物繁衍的区别。我将称之为熊猫方式与鱼子酱方式,因为这很有趣,更容易记住。
4.网络激活归一化
Batch Normalization 批量归一化 BN
1.计算流程(激活前归一化)
设一层线性输出:Z
- 求批次均值
\mu_B = \frac1m\sum_{i=1}^m Z_i
- 求批次方差
\sigma_B^2=\frac1m\sum_{i=1}^m (Z_i-\mu_B)^2
- 标准化
\hat Z_i = \frac{Z_i-\mu_B}{\sqrt{\sigma_B^2+\varepsilon}}
- 缩放平移(恢复表达能力)
\tilde Z_i = \gamma\hat Z_i + \beta
- 送入激活函数:A=\sigma(\tilde Z)
特点
- 维度:同一批次所有样本归一化
- 位置:线性层后,激活函数之前
- 优点:加速收敛、可用更大学习率、轻微正则
- 缺点:依赖 batch size,小批次效果差;RNN / 时序模型不适用
2.Layer Normalization 层归一化 LN
- 对单个样本 的所有神经元维度计算均值方差
- 不依赖批次大小
- 同样带可学习参数 \gamma,\beta
- 适用:Transformer、VLM、大模型、RNN
3.Instance Normalization 实例归一化 IN
单样本单通道归一化,多用于图像生成、风格迁移。
4.为什么要归一化激活值(核心作用)
- 稳定梯度流动 限制激活值范围,避免 Sigmoid/Tanh 进入饱和区,缓解梯度消失
- 消除内部协变量偏移 让每层输入分布稳定,大幅加快收敛速度
- 解放学习率 归一化后参数更新更平稳,可设置更大学习率
- 保留模型表达能力 \gamma、\beta 缩放平移,不会丢失原有特征信息
**5.标准搭建顺序
线性 / 卷积计算 → 归一化(BN/LN) → 激活函数
错误顺序:先激活再归一化效果极差
5.整合批量归一化到神经网络
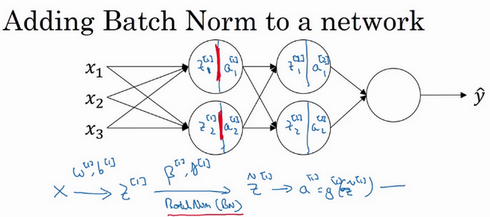
假设你有一个这样的神经网络,我之前说过,你可以认为每个单元负责计算两件事。第一,它先计算z,然后应用其到激活函数中再计算a,所以我可以认为,每个圆圈代表着两步的计算过程。同样的,对于下一层而言,那就是

和

等。所以如果你没有应用Batch归一化,你会把输入

拟合到第一隐藏层,然后首先计算

,这是由

和

两个参数控制的。接着,通常而言,你会把

拟合到激活函数以计算

。但Batch归一化的做法是将

值进行Batch 归一化,简称BN,此过程将由

和

两参数控制,这一操作会给你一个新的规范化的
值(

),然后将其输入激活函数中得到

,即

。
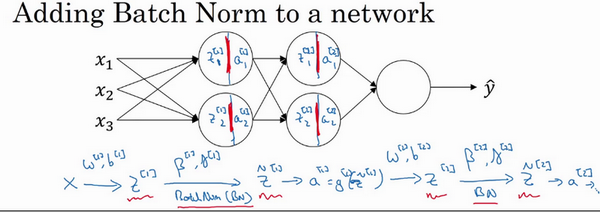
现在,你已在第一层进行了计算,此时Batch归一化发生在z的计算和

之间,接下来,你需要应用

值来计算

,此过程是由

和

控制的。与你在第一层所做的类似,你会将

进行Batch 归一化,现在我们简称BN ,这是由下一层的Batch归一化参数所管制的,即

和

,现在你得到

,再通过激活函数计算出

等等。
所以需要强调的是Batch归一化是发生在计算

和

之间的。直觉就是,与其应用没有归一化的

值,不如用归一过的

,这是第一层(

)。第二层同理,与其应用没有规范过的

值,不如用经过方差和均值归一后的{\tilde{z}}^{2}。所以,你网络的参数就会是w^{1},b^{1},w^{2}和b^{2}等等,我们将要去掉这些参数。但现在,想象参数w^{1},b^{1}到w^{l},b^{l},我们将另一些参数加入到此新网络中{\beta}^{1},{\beta}^{2},\gamma^{1},\gamma^{2}等等。对于应用Batch 归一化的每一层而言。需要澄清的是,请注意,这里的这些\beta({\beta}^{1},{\beta}^{2}等等)和超参数\beta没有任何关系,下一张幻灯片中会解释原因,后者是用于Momentum 或计算各个指数的加权平均值。Adam 论文的作者,在论文里用\beta代表超参数。Batch 归一化论文的作者,则使用\beta代表此参数({\beta}^{1},{\beta}^{2}等等),但这是两个完全不同的\beta。我在两种情况下都决定使用\beta,以便你阅读那些原创的论文,但Batch 归一化学习参数{\beta}^{1},{\beta}^{\left\lbrack2 \right\rbrack}等等和用于Momentum 、Adam 、RMSprop 算法中的\beta不同。

所以现在,这是你算法的新参数,接下来你可以使用想用的任何一种优化算法,比如使用梯度下降法来执行它。
举个例子,对于给定层,你会计算d{\beta}^{l},接着更新参数\beta为{\beta}^{l} = {\beta}^{l} - \alpha d{\beta}^{l}。你也可以使用Adam 或RMSprop 或Momentum,以更新参数\beta和\gamma,并不是只应用梯度下降法。
即使在之前的视频中,我已经解释过Batch 归一化是怎么操作的,计算均值和方差,减去均值,再除以方差,如果它们使用的是深度学习编程框架,通常你不必自己把Batch 归一化步骤应用于Batch 归一化层。因此,探究框架,可写成一行代码,比如说,在TensorFlow 框架中,你可以用这个函数(tf.nn.batch_normalization)来实现Batch 归一化,我们稍后讲解,但实践中,你不必自己操作所有这些具体的细节,但知道它是如何作用的,你可以更好的理解代码的作用。但在深度学习框架中,Batch归一化的过程,经常是类似一行代码的东西。
所以,到目前为止,我们已经讲了Batch 归一化,就像你在整个训练站点上训练一样,或就像你正在使用Batch 梯度下降法。
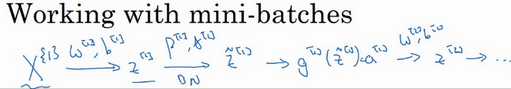
实践中,Batch 归一化通常和训练集的mini-batch 一起使用。你应用Batch 归一化的方式就是,你用第一个mini-batch (X^{\{1\}}),然后计算z^{1},这和上张幻灯片上我们所做的一样,应用参数w^{1}和b^{1},使用这个mini-batch (X^{\{1\}})。接着,继续第二个mini-batch (X^{\{2\}}),接着Batch 归一化会减去均值,除以标准差,由{\beta}^{1}和\gamma^{1}重新缩放,这样就得到了{\tilde{z}}^{1},而所有的这些都是在第一个mini-batch 的基础上,你再应用激活函数得到a^{1}。然后用w^{2}和b^{2}计算z^{2},等等,所以你做的这一切都是为了在第一个mini-batch (X^{\{1\}})上进行一步梯度下降法。

类似的工作,你会在第二个mini-batch (X^{\left\{2 \right\}})上计算z^{1},然后用Batch 归一化来计算{\tilde{z}}^{1},所以Batch 归一化的此步中,你用第二个mini-batch (X^{\left\{2 \right\}})中的数据使{\tilde{z}}^{1}归一化,这里的Batch 归一化步骤也是如此,让我们来看看在第二个mini-batch (X^{\left\{2 \right\}})中的例子,在mini-batch上计算z^{1}的均值和方差,重新缩放的\beta和\gamma得到z^{1},等等。
现在,我想澄清此参数的一个细节。先前我说过每层的参数是w^{l}和b^{l},还有{\beta}^{l}和\gamma^{l},请注意计算z的方式如下,z^{l} =w^{l}a^{\left\lbrack l - 1 \right\rbrack} +b^{l},但Batch 归一化做的是,它要看这个mini-batch ,先将z^{l}归一化,结果为均值0和标准方差,再由\beta和\\gamma重缩放,但这意味着,无论b{\[l\]}的值是多少,都是要被减去的,因为在\*\*Batch\*\*归一化的过程中,你要计算z{\[l\]}的均值,再减去平均值,在此例中的mini-batch中增加任何常数,数值都不会改变,因为加上的任何常数都将会被均值减去所抵消。
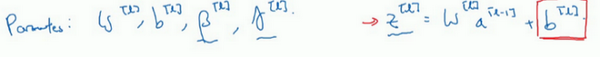
所以,如果你在使用Batch归一化,其实你可以消除这个参数(

),或者你也可以,暂时把它设置为0,那么,参数变成

,然后你计算归一化的

,

,你最后会用参数

,以便决定

的取值,这就是原因。
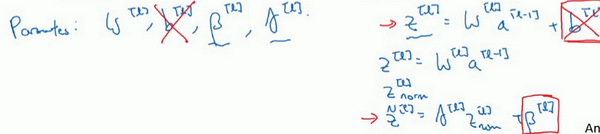
所以总结一下,因为Batch归一化超过了此层

的均值,

这个参数没有意义,所以,你必须去掉它,由

代替,这是个控制参数,会影响转移或偏置条件。
最后,请记住

的维数,因为在这个例子中,维数会是

,

的尺寸为

,如果是l层隐藏单元的数量,那

和

的维度也是

,因为这是你隐藏层的数量,你有

隐藏单元,所以

和
用来将每个隐藏层的均值和方差缩放为网络想要的值。
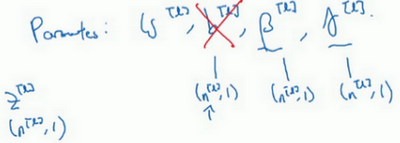
让我们总结一下关于如何用Batch 归一化来应用梯度下降法,假设你在使用mini-batch梯度下降法,你运行

到batch 数量的for 循环,你会在mini-batch

上应用正向prop ,每个隐藏层都应用正向prop ,用Batch归一化代替

为

。接下来,它确保在这个mini-batch中,

值有归一化的均值和方差,归一化均值和方差后是
,然后,你用反向prop计算

和

,及所有l层所有的参数,

和

。尽管严格来说,因为你要去掉

,这部分其实已经去掉了。最后,你更新这些参数:

,和以前一样,

,对于

也是如此

。
如果你已将梯度计算如下,你就可以使用梯度下降法了,这就是我写到这里的,但也适用于有Momentum 、RMSprop 、Adam 的梯度下降法。与其使用梯度下降法更新mini-batch ,你可以使用这些其它算法来更新,我们在之前几个星期中的视频中讨论过的,也可以应用其它的一些优化算法来更新由Batch归一化添加到算法中的

和

参数。

我希望,你能学会如何从头开始应用Batch 归一化,如果你想的话。如果你使用深度学习编程框架之一,我们之后会谈。,希望,你可以直接调用别人的编程框架,这会使Batch归一化的使用变得很容易。
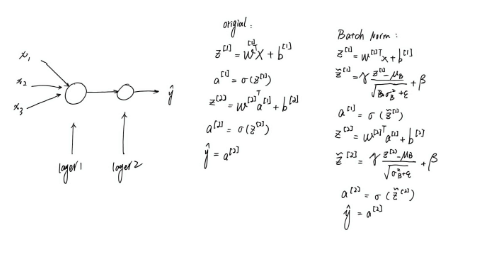
6.批量归一化原理
- 缓解梯度消失,深层网络更好训练
- 大幅提高学习率,收敛更快
- 减少对初始化权重依赖
- 轻微抑制过拟合(自带正则)
- 减少 Dropout、调参成本
1. 加速训练收敛
BN 将每层输入约束在稳定的分布范围内,梯度更新更有效率:
- 可以使用更大的学习率而不发散
- 减少了"层与层之间互相适应"的负担,收敛步数显著减少
- 实践中往往能将训练速度提升 数倍
2. 缓解梯度消失 / 爆炸
深层网络中,梯度在反向传播时容易指数级缩小或放大。BN 的作用:
- 归一化后激活值落在 sigmoid/tanh 敏感区域(非饱和区),梯度不消失
- 控制了每层输出的尺度,防止梯度在链式求导中爆炸
- 配合 ReLU 效果更佳,使深层网络(如 ResNet)得以训练
3. 降低对参数初始化的敏感性
没有 BN 时,权重初始化不当会导致:
- 激活值全部饱和 → 梯度为 0,网络无法学习
- 激活值尺度差异巨大 → 各层学习速率实际不平衡
有了 BN 后,即使初始化较差,网络也能自我纠正,大幅降低调参难度。
4. 轻微的正则化效果
BN 引入了一种隐式噪声:
每个样本的归一化依赖当前 batch 的均值和方差,而非"真实"的全局统计量
这个随机性类似 Dropout 的效果,有一定抑制过拟合的能力,实践中可以减少甚至去掉 Dropout。
5. 允许更大的网络和更深的结构
BN 是 ResNet、Inception、DenseNet 等深层架构得以成功训练的关键因素之一。在没有 BN 的年代,训练超过 20 层的网络极为困难。
6. 减少内部协变量偏移(ICS)
|-----------------------------|---------------------|
| 没有 BN | 有 BN |
| 前层参数更新 → 后层输入分布变化 → 后层需重新适应 | 每层输入分布被"钉住",层与层之间解耦 |
| 训练不稳定 | 训练过程更平滑 |
7.测试时的 Batch Norm
8.Softmax回归
Softmax 回归是逻辑回归在多分类问题上的推广,将输入映射为

个类别上的概率分布。

核心公式
给定输入

,先计算

个类别的 logit(原始得分):

再通过 Softmax 函数转化为概率:

满足:

直觉理解
原始得分 z 指数化 归一化
z₁ = 2.0 → e^2.0 = 7.39 → 7.39/23.51 = 0.314
z₂ = 3.0 → e^3.0 = 20.09 → 20.09/23.51 = 0.854 ← 最大概率
z₃ = -1.0 → e^-1 = 0.37 → 0.37/23.51 = 0.016指数化的作用:
- 放大差异(大的更大)
- 保证非负(可归一化为概率)
9.Softmax + 交叉熵损失 梯度下降推导
- 定义
设:
- 网络原始输出(logits):

- Softmax 输出概率:

-
真实标签:one-hot

- 交叉熵损失(单样本):

- **核心梯度:

最终合并结果(必考)

- 极简推导思路
(1)先求 Softmax 自身梯度:


(2)链式法则:

(3)代入交叉熵导数

(4)化简直接得到:

- 梯度下降更新
设上层权重为 W,


参数更新:

10.TensorFlow
lesson3:结构化机器学习项目(Structuring Machine Learning Projects)
Week1: 机器学习策略介绍
1.机器学习策略意义

我们从一个启发性的例子开始讲,假设你正在调试你的猫分类器,经过一段时间的调整,你的系统达到了90%准确率,但对你的应用程序来说还不够好。
你可能有很多想法去改善你的系统,比如,你可能想我们去收集更多的训练数据吧。或者你会说,可能你的训练集的多样性还不够,你应该收集更多不同姿势的猫咪图片,或者更多样化的反例集。或者你想再用梯度下降训练算法,训练久一点。或者你想尝试用一个完全不同的优化算法,比如Adam 优化算法。或者尝试使用规模更大或者更小的神经网络。或者你想试试dropout或者

正则化。或者你想修改网络的架构,比如修改激活函数,改变隐藏单元的数目之类的方法。
当你尝试优化一个深度学习系统时,你通常可以有很多想法可以去试,问题在于,如果你做出了错误的选择,你完全有可能白费6个月的时间,往错误的方向前进,在6个月之后才意识到这方法根本不管用。比如,我见过一些团队花了6个月时间收集更多数据,却在6个月之后发现,这些数据几乎没有改善他们系统的性能。所以,假设你的项目没有6个月的时间可以浪费,如果有快速有效的方法能够判断哪些想法是靠谱的,或者甚至提出新的想法,判断哪些是值得一试的想法,哪些是可以放心舍弃的。
我希望在这门课程中,可以教给你们一些策略,一些分析机器学习问题的方法,可以指引你们朝着最有希望的方向前进。这门课中,我会和你们分享我在搭建和部署大量深度学习产品时学到的经验和教训,我想这些内容是这门课程独有的。比如说,很多大学深度学习课程很少提到这些策略。事实上,机器学习策略在深度学习的时代也在变化,因为现在对于深度学习算法来说能够做到的事情,比上一代机器学习算法大不一样。我希望这些策略能帮助你们提高效率,让你们的深度学习系统更快投入实用。
2.正交化原则
三大作用
- 消除特征多重共线性
特征之间不再互相干扰,权重更稳定,模型更易收敛。
- 解耦信息
每个正交特征独立表达一种信息,信息利用率最大化。
- 简化计算、加速求逆
正交矩阵转置 = 逆矩阵,大幅降低线性运算复杂度。
3.单一评估指标
3.与优化指标
1.4 满足和优化指标(Satisficing and optimizing metrics)
要把你顾及到的所有事情组合成单实数评估指标有时并不容易,在那些情况里,我发现有时候设立满足和优化指标是很重要的,让我告诉你是什么意思吧。
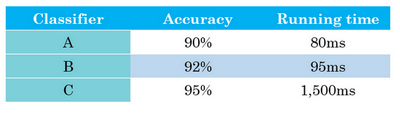
假设你已经决定你很看重猫分类器的分类准确度,这可以是F_1分数或者用其他衡量准确度的指标。但除了准确度之外,我们还需要考虑运行时间,就是需要多长时间来分类一张图。分类器A需要80毫秒,B需要95毫秒,C需要1500毫秒,就是说需要1.5秒来分类图像。

你可以这么做,将准确度和运行时间组合成一个整体评估指标。所以成本,比如说,总体成本是cost= accuracy - 0.5 \times\text{runningTime},这种组合方式可能太刻意,只用这样的公式来组合准确度和运行时间,两个数值的线性加权求和。
你还可以做其他事情,就是你可能选择一个分类器,能够最大限度提高准确度,但必须满足运行时间要求,就是对图像进行分类所需的时间必须小于等于100毫秒。所以在这种情况下,我们就说准确度是一个优化指标,因为你想要准确度最大化,你想做的尽可能准确,但是运行时间就是我们所说的满足指标,意思是它必须足够好,它只需要小于100毫秒,达到之后,你不在乎这指标有多好,或者至少你不会那么在乎。所以这是一个相当合理的权衡方式,或者说将准确度和运行时间结合起来的方式。实际情况可能是,只要运行时间少于100毫秒,你的用户就不会在乎运行时间是100毫秒还是50毫秒,甚至更快。

通过定义优化和满足指标,就可以给你提供一个明确的方式,去选择"最好的"分类器。在这种情况下分类器B最好,因为在所有的运行时间都小于100毫秒的分类器中,它的准确度最好。

所以更一般地说,如果你要考虑N个指标,有时候选择其中一个指标做为优化指标是合理的。所以你想尽量优化那个指标,然后剩下N-1个指标都是满足指标,意味着只要它们达到一定阈值,例如运行时间快于100毫秒,但只要达到一定的阈值,你不在乎它超过那个门槛之后的表现,但它们必须达到这个门槛。

这里是另一个例子,假设你正在构建一个系统来检测唤醒语,也叫触发词,这指的是语音控制设备。比如亚马逊Echo ,你会说"Alexa ",或者用"Okay Google "来唤醒谷歌设备,或者对于苹果设备,你会说"Hey Siri",或者对于某些百度设备,我们用"你好百度"唤醒。
对的,这些就是唤醒词,可以唤醒这些语音控制设备,然后监听你想说的话。所以你可能会在乎触发字检测系统的准确性,所以当有人说出其中一个触发词时,有多大概率可以唤醒你的设备。
你可能也需要顾及假阳性(false positive)的数量,就是没有人在说这个触发词时,它被随机唤醒的概率有多大?所以这种情况下,组合这两种评估指标的合理方式可能是最大化精确度。所以当某人说出唤醒词时,你的设备被唤醒的概率最大化,然后必须满足24小时内最多只能有1次假阳性,对吧?所以你的设备平均每天只会没有人真的在说话时随机唤醒一次。所以在这种情况下,准确度是优化指标,然后每24小时发生一次假阳性是满足指标,你只要每24小时最多有一次假阳性就满足了。

总结一下,如果你需要顾及多个指标,比如说,有一个优化指标,你想尽可能优化的,然后还有一个或多个满足指标,需要满足的,需要达到一定的门槛。现在你就有一个全自动的方法,在观察多个成本大小时,选出"最好的"那个。现在这些评估指标必须是在训练集或开发集或测试集上计算或求出来的。所以你还需要做一件事,就是设立训练集、开发集,还有测试集。在下一个视频里,我想和大家分享一些如何设置训练、开发和测试集的指导方针,我们下一个视频继续。
4.训练-验证-测试集分布
设立训练集,开发集和测试集的方式大大影响了你或者你的团队在建立机器学习应用方面取得进展的速度。同样的团队,即使是大公司里的团队,在设立这些数据集的方式,真的会让团队的进展变慢而不是加快,我们看看应该如何设立这些数据集,让你的团队效率最大化。

在这个视频中,我想集中讨论如何设立开发集和测试集,开发(dev )集也叫做开发集(development set ),有时称为保留交叉验证集(hold out cross validation set)。然后,机器学习中的工作流程是,你尝试很多思路,用训练集训练不同的模型,然后使用开发集来评估不同的思路,然后选择一个,然后不断迭代去改善开发集的性能,直到最后你可以得到一个令你满意的成本,然后你再用测试集去评估。
现在,举个例子,你要开发一个猫分类器,然后你在这些区域里运营,美国、英国、其他欧洲国家,南美洲、印度、中国,其他亚洲国家和澳大利亚,那么你应该如何设立开发集和测试集呢?
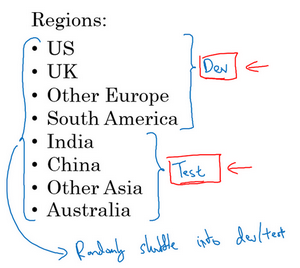
其中一种做法是,你可以选择其中4个区域,我打算使用这四个(前四个),但也可以是随机选的区域,然后说,来自这四个区域的数据构成开发集。然后其他四个区域,我打算用这四个(后四个),也可以随机选择4个,这些数据构成测试集。
事实证明,这个想法非常糟糕,因为这个例子中,你的开发集和测试集来自不同的分布。我建议你们不要这样,而是让你的开发集和测试集来自同一分布。我的意思是这样,你们要记住,我想就是设立你的开发集加上一个单实数评估指标,这就是像是定下目标,然后告诉你的团队,那就是你要瞄准的靶心,因为你一旦建立了这样的开发集和指标,团队就可以快速迭代,尝试不同的想法,跑实验,可以很快地使用开发集和指标去评估不同分类器,然后尝试选出最好的那个。所以,机器学习团队一般都很擅长使用不同方法去逼近目标,然后不断迭代,不断逼近靶心。所以,针对开发集上的指标优化。
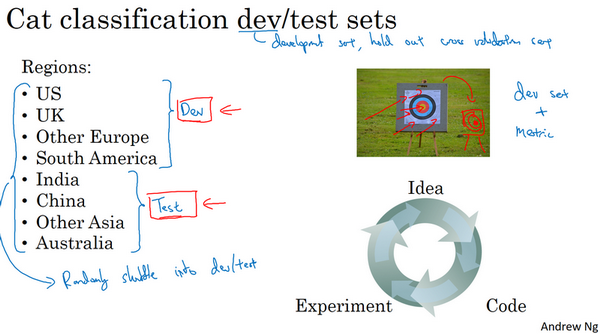
然后在左边的例子中,设立开发集和测试集时存在一个问题,你的团队可能会花上几个月时间在开发集上迭代优化,结果发现,当你们最终在测试集上测试系统时,来自这四个国家或者说下面这四个地区的数据(即测试集数据)和开发集里的数据可能差异很大,所以你可能会收获"意外惊喜",并发现,花了那么多个月的时间去针对开发集优化,在测试集上的表现却不佳。所以,如果你的开发集和测试集来自不同的分布,就像你设了一个目标,让你的团队花几个月尝试逼近靶心,结果在几个月工作之后发现,你说"等等",测试的时候,"我要把目标移到这里",然后团队可能会说"好吧,为什么你让我们花那么多个月的时间去逼近那个靶心,然后突然间你可以把靶心移到不同的位置?"。
所以,为了避免这种情况,我建议的是你将所有数据随机洗牌,放入开发集和测试集,所以开发集和测试集都有来自八个地区的数据,并且开发集和测试集都来自同一分布,这分布就是你的所有数据混在一起。
这里有另一个例子,这是个真实的故事,但有一些细节变了。所以我知道有一个机器学习团队,花了好几个月在开发集上优化,开发集里面有中等收入邮政编码的贷款审批数据。那么具体的机器学习问题是,输入x为贷款申请,你是否可以预测输出y,y是他们有没有还贷能力?所以这系统能帮助银行判断是否批准贷款。所以开发集来自贷款申请,这些贷款申请来自中等收入邮政编码,zip code就是美国的邮政编码。但是在这上面训练了几个月之后,团队突然决定要在,低收入邮政编码数据上测试一下。当然了,这个分布数据里面中等收入和低收入邮政编码数据是很不一样的,而且他们花了大量时间针对前面那组数据优化分类器,导致系统在后面那组数据中效果很差。所以这个特定团队实际上浪费了3个月的时间,不得不退回去重新做很多工作。

这里实际发生的事情是,这个团队花了三个月瞄准一个目标,三个月之后经理突然问"你们试试瞄准那个目标如何?",这新目标位置完全不同,所以这件事对于这个团队来说非常崩溃。
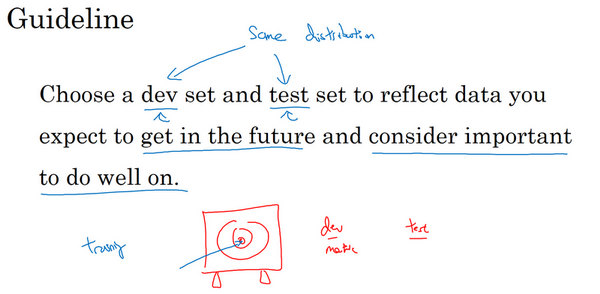
所以我建议你们在设立开发集和测试集时,要选择这样的开发集和测试集,能够反映你未来会得到的数据,认为很重要的数据,必须得到好结果的数据,特别是,这里的开发集和测试集可能来自同一个分布。所以不管你未来会得到什么样的数据,一旦你的算法效果不错,要尝试收集类似的数据,而且,不管那些数据是什么,都要随机分配到开发集和测试集上。因为这样,你才能将瞄准想要的目标,让你的团队高效迭代来逼近同一个目标,希望最好是同一个目标。
我们还没提到如何设立训练集,我们会在之后的视频里谈谈如何设立训练集,但这个视频的重点在于,设立开发集以及评估指标,真的就定义了你要瞄准的目标。我们希望通过在同一分布中设立开发集和测试集,你就可以瞄准你所希望的机器学习团队瞄准的目标。而设立训练集的方式则会影响你逼近那个目标有多快,但我们可以在另一个讲座里提到。我知道有一些机器学习团队,他们如果能遵循这个方针,就可以省下几个月的工作,所以我希望这些方针也能帮到你们。
5.验证集和测试集规模
6.何时调整评估指标与数据集
7.人类水平性能意义
8.可避免偏差
9.理解人类水平性能
10.超越人类水平表现
11.提升模型性能
Week2:快速搭建你的第一个系统,并进行迭代
1.误差分析
2.清除标注错误的数据
排除标注错误的数据对于实验的干扰
3.使用来自不同分布的数据进行训练与测试(跨分布训练与测试)
4.数据分布不匹配的偏差与方差
5.迁移学习
深度学习中,最强大的理念之一就是,有的时候神经网络可以从一个任务中习得知识,并将这些知识应用到另一个独立的任务中。所以例如,也许你已经训练好一个神经网络,能够识别像猫这样的对象,然后使用那些知识,或者部分习得的知识去帮助您更好地阅读x射线扫描图,这就是所谓的迁移学习。
我们来看看,假设你已经训练好一个图像识别神经网络,所以你首先用一个神经网络,并在(x,y)对上训练,其中x是图像,y是某些对象,图像是猫、狗、鸟或其他东西。如果你把这个神经网络拿来,然后让它适应或者说迁移,在不同任务中学到的知识,比如放射科诊断,就是说阅读X射线扫描图。你可以做的是把神经网络最后的输出层拿走,就把它删掉,还有进入到最后一层的权重删掉,然后为最后一层重新赋予随机权重,然后让它在放射诊断数据上训练。
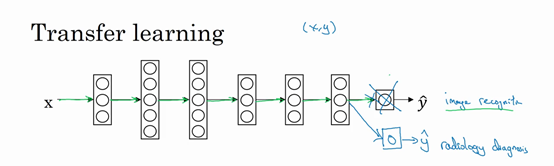
具体来说,在第一阶段训练过程中,当你进行图像识别任务训练时,你可以训练神经网络的所有常用参数,所有的权重,所有的层,然后你就得到了一个能够做图像识别预测的网络。在训练了这个神经网络后,要实现迁移学习,你现在要做的是,把数据集换成新的(x,y)对,现在这些变成放射科图像,而y是你想要预测的诊断,你要做的是初始化最后一层的权重,让我们称之为w^{L}和b^{L}随机初始化。
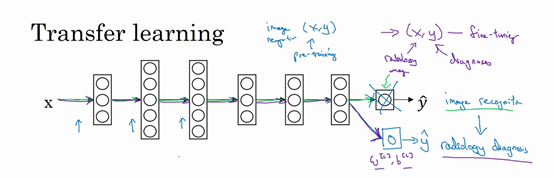
现在,我们在这个新数据集上重新训练网络,在新的放射科数据集上训练网络。要用放射科数据集重新训练神经网络有几种做法。你可能,如果你的放射科数据集很小,你可能只需要重新训练最后一层的权重,就是w^{L}和b^{L}并保持其他参数不变。如果你有足够多的数据,你可以重新训练神经网络中剩下的所有层。经验规则是,如果你有一个小数据集,就只训练输出层前的最后一层,或者也许是最后一两层。但是如果你有很多数据,那么也许你可以重新训练网络中的所有参数。如果你重新训练神经网络中的所有参数,那么这个在图像识别数据的初期训练阶段,有时称为预训练(pre-training ),因为你在用图像识别数据去预先初始化,或者预训练神经网络的权重。然后,如果你以后更新所有权重,然后在放射科数据上训练,有时这个过程叫微调(fine tuning)。如果你在深度学习文献中看到预训练和微调,你就知道它们说的是这个意思,预训练和微调的权重来源于迁移学习。
在这个例子中你做的是,把图像识别中学到的知识应用或迁移到放射科诊断上来,为什么这样做有效果呢?有很多低层次特征,比如说边缘检测、曲线检测、阳性对象检测(positive objects),从非常大的图像识别数据库中习得这些能力可能有助于你的学习算法在放射科诊断中做得更好,算法学到了很多结构信息,图像形状的信息,其中一些知识可能会很有用,所以学会了图像识别,它就可能学到足够多的信息,可以了解不同图像的组成部分是怎样的,学到线条、点、曲线这些知识,也许对象的一小部分,这些知识有可能帮助你的放射科诊断网络学习更快一些,或者需要更少的学习数据。
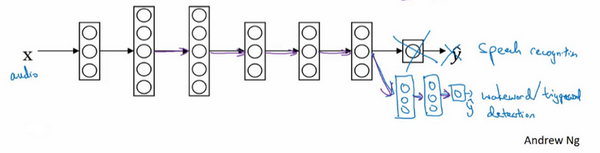
这里是另一个例子,假设你已经训练出一个语音识别系统,现在x是音频或音频片段输入,而y是听写文本,所以你已经训练了语音识别系统,让它输出听写文本。现在我们说你想搭建一个"唤醒词"或"触发词"检测系统,所谓唤醒词或触发词就是我们说的一句话,可以唤醒家里的语音控制设备,比如你说"Alexa "可以唤醒一个亚马逊Echo 设备,或用"OK Google "来唤醒Google 设备,用"Hey Siri"来唤醒苹果设备,用"你好百度"唤醒一个百度设备。要做到这点,你可能需要去掉神经网络的最后一层,然后加入新的输出节点,但有时你可以不只加入一个新节点,或者甚至往你的神经网络加入几个新层,然后把唤醒词检测问题的标签y喂进去训练。再次,这取决于你有多少数据,你可能只需要重新训练网络的新层,也许你需要重新训练神经网络中更多的层。
那么迁移学习什么时候是有意义的呢?迁移学习起作用的场合是,在迁移来源问题中你有很多数据,但迁移目标问题你没有那么多数据。例如,假设图像识别任务中你有1百万个样本,所以这里数据相当多。可以学习低层次特征,可以在神经网络的前面几层学到如何识别很多有用的特征。但是对于放射科任务,也许你只有一百个样本,所以你的放射学诊断问题数据很少,也许只有100次X射线扫描,所以你从图像识别训练中学到的很多知识可以迁移,并且真正帮你加强放射科识别任务的性能,即使你的放射科数据很少。
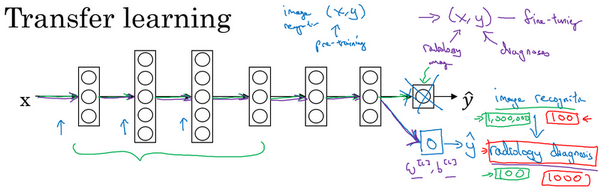
对于语音识别,也许你已经用10,000小时数据训练过你的语言识别系统,所以你从这10,000小时数据学到了很多人类声音的特征,这数据量其实很多了。但对于触发字检测,也许你只有1小时数据,所以这数据太小,不能用来拟合很多参数。所以在这种情况下,预先学到很多人类声音的特征人类语言的组成部分等等知识,可以帮你建立一个很好的唤醒字检测器,即使你的数据集相对较小。对于唤醒词任务来说,至少数据集要小得多。
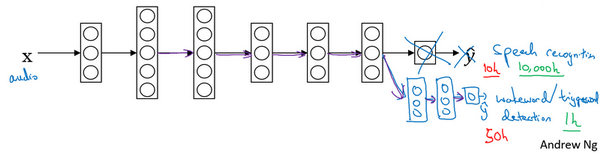
所以在这两种情况下,你从数据量很多的问题迁移到数据量相对小的问题。然后反过来的话,迁移学习可能就没有意义了。比如,你用100张图训练图像识别系统,然后有100甚至1000张图用于训练放射科诊断系统,人们可能会想,为了提升放射科诊断的性能,假设你真的希望这个放射科诊断系统做得好,那么用放射科图像训练可能比使用猫和狗的图像更有价值,所以这里(100甚至1000张图用于训练放射科诊断系统)的每个样本价值比这里(100张图训练图像识别系统)要大得多,至少就建立性能良好的放射科系统而言是这样。所以,如果你的放射科数据更多,那么你这100张猫猫狗狗或者随机物体的图片肯定不会有太大帮助,因为来自猫狗识别任务中,每一张图的价值肯定不如一张X射线扫描图有价值,对于建立良好的放射科诊断系统而言是这样。
所以,这是其中一个例子,说明迁移学习可能不会有害,但也别指望这么做可以带来有意义的增益。同样,如果你用10小时数据训练出一个语音识别系统。然后你实际上有10个小时甚至更多,比如说50个小时唤醒字检测的数据,你知道迁移学习有可能会有帮助,也可能不会,也许把这10小时数据迁移学习不会有太大坏处,但是你也别指望会得到有意义的增益。

所以总结一下,什么时候迁移学习是有意义的?如果你想从任务A学习并迁移一些知识到任务B,那么当任务A和任务B都有同样的输入x时,迁移学习是有意义的。在第一个例子中,A和B的输入都是图像,在第二个例子中,两者输入都是音频。当任务A的数据比任务B多得多时,迁移学习意义更大。所有这些假设的前提都是,你希望提高任务B的性能,因为任务B每个数据更有价值,对任务B来说通常任务A的数据量必须大得多,才有帮助,因为任务A里单个样本的价值没有比任务B单个样本价值大。然后如果你觉得任务A的低层次特征,可以帮助任务B的学习,那迁移学习更有意义一些。
而在这两个前面的例子中,也许学习图像识别教给系统足够多图像相关的知识,让它可以进行放射科诊断,也许学习语音识别教给系统足够多人类语言信息,能帮助你开发触发字或唤醒字检测器。
所以总结一下,迁移学习最有用的场合是,如果你尝试优化任务B的性能,通常这个任务数据相对较少,例如,在放射科中你知道很难收集很多X射线扫描图来搭建一个性能良好的放射科诊断系统,所以在这种情况下,你可能会找一个相关但不同的任务,如图像识别,其中你可能用1百万张图片训练过了,并从中学到很多低层次特征,所以那也许能帮助网络在任务B在放射科任务上做得更好,尽管任务B没有这么多数据。迁移学习什么时候是有意义的?它确实可以显著提高你的学习任务的性能,但我有时候也见过有些场合使用迁移学习时,任务A实际上数据量比任务B要少,这种情况下增益可能不多。
好,这就是迁移学习,你从一个任务中学习,然后尝试迁移到另一个不同任务中。从多个任务中学习还有另外一个版本,就是所谓的多任务学习,当你尝试从多个任务中并行学习,而不是串行学习,在训练了一个任务之后试图迁移到另一个任务,所以在下一个视频中,让我们来讨论多任务学习。
6.多任务学习
在迁移学习中,你的步骤是串行的,你从任务A里学习只是然后迁移到任务B。在多任务学习中,你是同时开始学习的,试图让单个神经网络同时做几件事情,然后希望这里每个任务都能帮到其他所有任务。

我们来看一个例子,假设你在研发无人驾驶车辆,那么你的无人驾驶车可能需要同时检测不同的物体,比如检测行人、车辆、停车标志,还有交通灯各种其他东西。比如在左边这个例子中,图像里有个停车标志,然后图像中有辆车,但没有行人,也没有交通灯。

如果这是输入图像x^{(i)},那么这里不再是一个标签 y^{(i)},而是有4个标签。在这个例子中,没有行人,有一辆车,有一个停车标志,没有交通灯。然后如果你尝试检测其他物体,也许 y^{(i)}的维数会更高,现在我们就先用4个吧,所以 y^{(i)}是个4×1向量。如果你从整体来看这个训练集标签和以前类似,我们将训练集的标签水平堆叠起来,像这样y^{(1)}一直到y^{(m)}:
Y = \begin{bmatrix}
| & | & | & \ldots & | \\
y^{(1)} & y^{(2)} & y^{(3)} & \ldots & y^{(m)} \\
| & | & | & \ldots & | \\
\end{bmatrix}
不过现在y^{(i)}是4×1向量,所以这些都是竖向的列向量,所以这个矩阵Y现在变成4×m矩阵。而之前,当y是单实数时,这就是1×m矩阵。
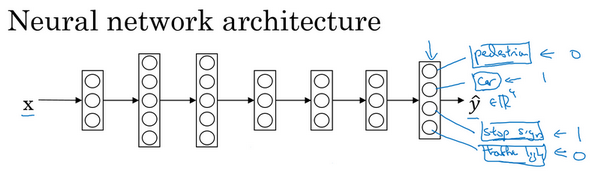
那么你现在可以做的是训练一个神经网络,来预测这些y值,你就得到这样的神经网络,输入x,现在输出是一个四维向量y。请注意,这里输出我画了四个节点,所以第一个节点就是我们想预测图中有没有行人,然后第二个输出节点预测的是有没有车,这里预测有没有停车标志,这里预测有没有交通灯,所以这里\hat y是四维的。
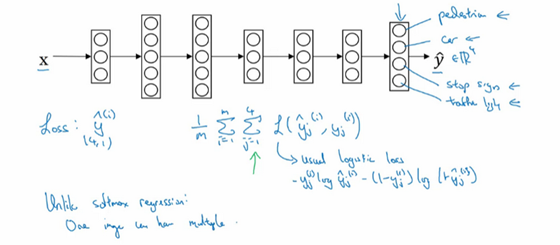
要训练这个神经网络,你现在需要定义神经网络的损失函数,对于一个输出\hat y,是个4维向量,对于整个训练集的平均损失:
\frac{1}{m}\sum_{i = 1}^{m}{\sum_{j = 1}^{4}{L(\hat y_{j}^{(i)},y_{j}^{(i)})}}
\sum_{j = 1}^{4}{L(\hat y_{j}^{(i)},y_{j}^{(i)})}这些单个预测的损失,所以这就是对四个分量的求和,行人、车、停车标志、交通灯,而这个标志L指的是logistic损失,我们就这么写:
L(\hat y_{j}^{(i)},y_{j}^{(i)}) = - y_{j}^{(i)}\log\hat y_{j}^{(i)} - (1 - y_{j}^{(i)})log(1 - \hat y_{j}^{(i)})
整个训练集的平均损失和之前分类猫的例子主要区别在于,现在你要对j=1到4求和,这与softmax 回归的主要区别在于,与softmax 回归不同,softmax将单个标签分配给单个样本。
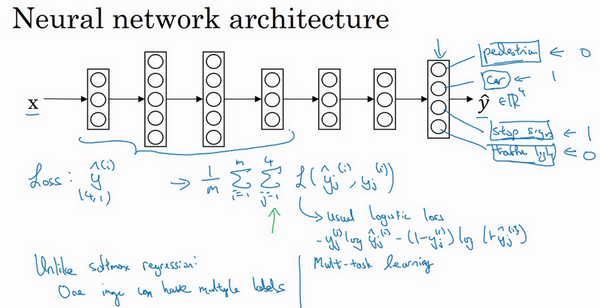
而这张图可以有很多不同的标签,所以不是说每张图都只是一张行人图片,汽车图片、停车标志图片或者交通灯图片。你要知道每张照片是否有行人、或汽车、停车标志或交通灯,多个物体可能同时出现在一张图里。实际上,在上一张幻灯片中,那张图同时有车和停车标志,但没有行人和交通灯,所以你不是只给图片一个标签,而是需要遍历不同类型,然后看看每个类型,那类物体有没有出现在图中。所以我就说在这个场合,一张图可以有多个标签。如果你训练了一个神经网络,试图最小化这个成本函数,你做的就是多任务学习。因为你现在做的是建立单个神经网络,观察每张图,然后解决四个问题,系统试图告诉你,每张图里面有没有这四个物体。另外你也可以训练四个不同的神经网络,而不是训练一个网络做四件事情。但神经网络一些早期特征,在识别不同物体时都会用到,然后你发现,训练一个神经网络做四件事情会比训练四个完全独立的神经网络分别做四件事性能要更好,这就是多任务学习的力量。
另一个细节,到目前为止,我是这么描述算法的,好像每张图都有全部标签。事实证明,多任务学习也可以处理图像只有部分物体被标记的情况。所以第一个训练样本,我们说有人,给数据贴标签的人告诉你里面有一个行人,没有车,但他们没有标记是否有停车标志,或者是否有交通灯。也许第二个例子中,有行人,有车。但是,当标记人看着那张图片时,他们没有加标签,没有标记是否有停车标志,是否有交通灯等等。也许有些样本都有标记,但也许有些样本他们只标记了有没有车,然后还有一些是问号。
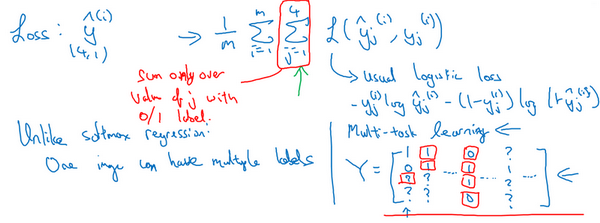
即使是这样的数据集,你也可以在上面训练算法,同时做四个任务,即使一些图像只有一小部分标签,其他是问号或者不管是什么。然后你训练算法的方式,即使这里有些标签是问号,或者没有标记,这就是对j从1到4求和,你就只对带0和1标签的j值求和,所以当有问号的时候,你就在求和时忽略那个项,这样只对有标签的值求和,于是你就能利用这样的数据集。
那么多任务学习什么时候有意义呢?当三件事为真时,它就是有意义的。
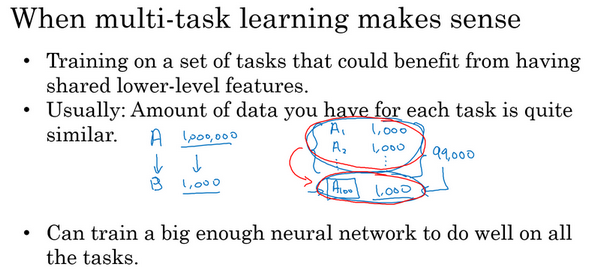
第一,如果你训练的一组任务,可以共用低层次特征。对于无人驾驶的例子,同时识别交通灯、汽车和行人是有道理的,这些物体有相似的特征,也许能帮你识别停车标志,因为这些都是道路上的特征。
第二,这个准则没有那么绝对,所以不一定是对的。但我从很多成功的多任务学习案例中看到,如果每个任务的数据量很接近,你还记得迁移学习时,你从A任务学到知识然后迁移到B任务,所以如果任务A有1百万个样本,任务B只有1000个样本,那么你从这1百万个样本学到的知识,真的可以帮你增强对更小数据集任务B的训练。那么多任务学习又怎么样呢?在多任务学习中,你通常有更多任务而不仅仅是两个,所以也许你有,以前我们有4个任务,但比如说你要完成100个任务,而你要做多任务学习,尝试同时识别100种不同类型的物体。你可能会发现,每个任务大概有1000个样本。所以如果你专注加强单个任务的性能,比如我们专注加强第100个任务的表现,我们用A100表示,如果你试图单独去做这个最后的任务,你只有1000个样本去训练这个任务,这是100项任务之一,而通过在其他99项任务的训练,这些加起来可以一共有99000个样本,这可能大幅提升算法性能,可以提供很多知识来增强这个任务的性能。不然对于任务A100,只有1000个样本的训练集,效果可能会很差。如果有对称性,这其他99个任务,也许能提供一些数据或提供一些知识来帮到这100个任务中的每一个任务。所以第二点不是绝对正确的准则,但我通常会看的是如果你专注于单项任务,如果想要从多任务学习得到很大性能提升,那么其他任务加起来必须要有比单个任务大得多的数据量。要满足这个条件,其中一种方法是,比如右边这个例子这样,或者如果每个任务中的数据量很相近,但关键在于,如果对于单个任务你已经有1000个样本了,那么对于所有其他任务,你最好有超过1000个样本,这样其他任务的知识才能帮你改善这个任务的性能。
最后多任务学习往往在以下场合更有意义,当你可以训练一个足够大的神经网络,同时做好所有的工作,所以多任务学习的替代方法是为每个任务训练一个单独的神经网络。所以不是训练单个神经网络同时处理行人、汽车、停车标志和交通灯检测。你可以训练一个用于行人检测的神经网络,一个用于汽车检测的神经网络,一个用于停车标志检测的神经网络和一个用于交通信号灯检测的神经网络。那么研究员Rich Carona几年前发现的是什么呢?多任务学习会降低性能的唯一情况,和训练单个神经网络相比性能更低的情况就是你的神经网络还不够大。但如果你可以训练一个足够大的神经网络,那么多任务学习肯定不会或者很少会降低性能,我们都希望它可以提升性能,比单独训练神经网络来单独完成各个任务性能要更好。
所以这就是多任务学习,在实践中,多任务学习的使用频率要低于迁移学习。我看到很多迁移学习的应用,你需要解决一个问题,但你的训练数据很少,所以你需要找一个数据很多的相关问题来预先学习,并将知识迁移到这个新问题上。但多任务学习比较少见,就是你需要同时处理很多任务,都要做好,你可以同时训练所有这些任务,也许计算机视觉是一个例子。在物体检测中,我们看到更多使用多任务学习的应用,其中一个神经网络尝试检测一大堆物体,比分别训练不同的神经网络检测物体更好。但我说,平均来说,目前迁移学习使用频率更高,比多任务学习频率要高,但两者都可以成为你的强力工具。
所以总结一下,多任务学习能让你训练一个神经网络来执行许多任务,这可以给你更高的性能,比单独完成各个任务更高的性能。但要注意,实际上迁移学习比多任务学习使用频率更高。我看到很多任务都是,如果你想解决一个机器学习问题,但你的数据集相对较小,那么迁移学习真的能帮到你,就是如果你找到一个相关问题,其中数据量要大得多,你就能以它为基础训练你的神经网络,然后迁移到这个数据量很少的任务上来。
今天我们学到了很多和迁移学习有关的问题,还有一些迁移学习和多任务学习的应用。但多任务学习,我觉得使用频率比迁移学习要少得多,也许其中一个例外是计算机视觉,物体检测。在那些任务中,人们经常训练一个神经网络同时检测很多不同物体,这比训练单独的神经网络来检测视觉物体要更好。但平均而言,我认为即使迁移学习和多任务学习工作方式类似。实际上,我看到用迁移学习比多任务学习要更多,我觉得这是因为你很难找到那么多相似且数据量对等的任务可以用单一神经网络训练。再次,在计算机视觉领域,物体检测这个例子是最显著的例外情况。
7.端到端的深度学习
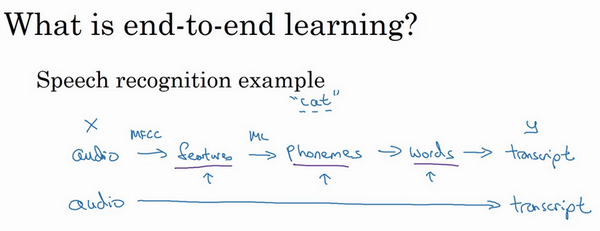
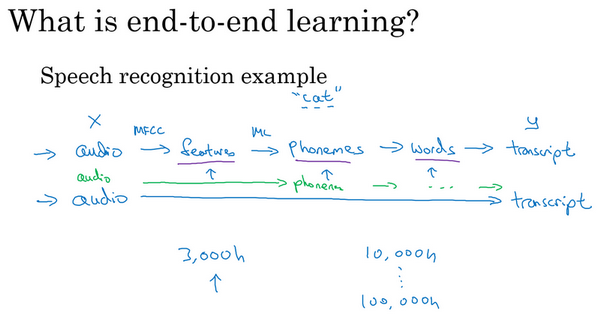
深度学习中最令人振奋的最新动态之一就是端到端深度学习的兴起,那么端到端学习到底是什么呢?简而言之,以前有一些数据处理系统或者学习系统,它们需要多个阶段的处理。那么端到端深度学习就是忽略所有这些不同的阶段,用单个神经网络代替它。

我们来看一些例子,以语音识别为例,你的目标是输入x,比如说一段音频,然后把它映射到一个输出y,就是这段音频的听写文本。所以传统上,语音识别需要很多阶段的处理。首先你会提取一些特征,一些手工设计的音频特征,也许你听过MFCC ,这种算法是用来从音频中提取一组特定的人工设计的特征。在提取出一些低层次特征之后,你可以应用机器学习算法在音频片段中找到音位,所以音位是声音的基本单位,比如说"Cat "这个词是三个音节构成的,Cu- 、Ah- 和 Tu-,算法就把这三个音位提取出来,然后你将音位串在一起构成独立的词,然后你将词串起来构成音频片段的听写文本。
所以和这种有很多阶段的流水线相比,端到端深度学习做的是,你训练一个巨大的神经网络,输入就是一段音频,输出直接是听写文本。AI 的其中一个有趣的社会学效应是,随着端到端深度学习系统表现开始更好,有一些花了大量时间或者整个事业生涯设计出流水线各个步骤的研究员,还有其他领域的研究员,不只是语言识别领域的,也许是计算机视觉,还有其他领域,他们花了大量的时间,写了很多论文,有些甚至整个职业生涯的一大部分都投入到开发这个流水线的功能或者其他构件上去了。而端到端深度学习就只需要把训练集拿过来,直接学到了x和y之间的函数映射,直接绕过了其中很多步骤。对一些学科里的人来说,这点相当难以接受,他们无法接受这样构建AI系统,因为有些情况,端到端方法完全取代了旧系统,某些投入了多年研究的中间组件也许已经过时了。
事实证明,端到端深度学习的挑战之一是,你可能需要大量数据才能让系统表现良好,比如,你只有3000小时数据去训练你的语音识别系统,那么传统的流水线效果真的很好。但当你拥有非常大的数据集时,比如10,000小时数据或者100,000小时数据,这样端到端方法突然开始很厉害了。所以当你的数据集较小的时候,传统流水线方法其实效果也不错,通常做得更好。你需要大数据集才能让端到端方法真正发出耀眼光芒。如果你的数据量适中,那么也可以用中间件方法,你可能输入还是音频,然后绕过特征提取,直接尝试从神经网络输出音位,然后也可以在其他阶段用,所以这是往端到端学习迈出的一小步,但还没有到那里。

这张图上是一个研究员做的人脸识别门禁,是百度的林元庆研究员做的。这是一个相机,它会拍下接近门禁的人,如果它认出了那个人,门禁系统就自动打开,让他通过,所以你不需要刷一个RFID 工卡就能进入这个设施。系统部署在越来越多的中国办公室,希望在其他国家也可以部署更多,你可以接近门禁,如果它认出你的脸,它就直接让你通过,你不需要带RFID工卡。

那么,怎么搭建这样的系统呢?你可以做的第一件事是,看看相机拍到的照片,对吧?我想我画的不太好,但也许这是相机照片,你知道,有人接近门禁了,所以这可能是相机拍到的图像x。有件事你可以做,就是尝试直接学习图像x到人物y身份的函数映射,事实证明这不是最好的方法。其中一个问题是,人可以从很多不同的角度接近门禁,他们可能在绿色位置,可能在蓝色位置。有时他们更靠近相机,所以他们看起来更大,有时候他们非常接近相机,那照片中脸就很大了。在实际研制这些门禁系统时,他不是直接将原始照片喂到一个神经网络,试图找出一个人的身份。
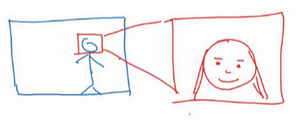
相反,迄今为止最好的方法似乎是一个多步方法,首先,你运行一个软件来检测人脸,所以第一个检测器找的是人脸位置,检测到人脸,然后放大图像的那部分,并裁剪图像,使人脸居中显示,然后就是这里红线框起来的照片,再喂到神经网络里,让网络去学习,或估计那人的身份。
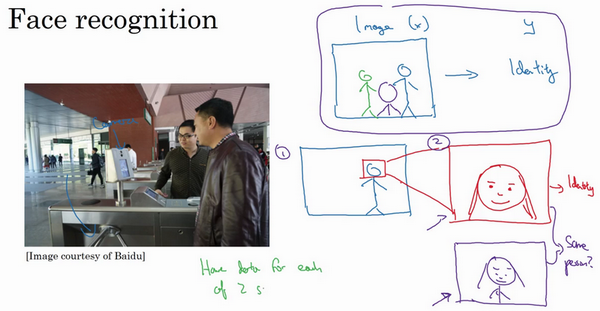
研究人员发现,比起一步到位,一步学习,把这个问题分解成两个更简单的步骤。首先,是弄清楚脸在哪里。第二步是看着脸,弄清楚这是谁。这第二种方法让学习算法,或者说两个学习算法分别解决两个更简单的任务,并在整体上得到更好的表现。
顺便说一句,如果你想知道第二步实际是怎么工作的,我这里其实省略了很多。训练第二步的方式,训练网络的方式就是输入两张图片,然后你的网络做的就是将输入的两张图比较一下,判断是否是同一个人。比如你记录了10,000个员工ID ,你可以把红色框起来的图像快速比较......也许是全部10,000个员工记录在案的ID,看看这张红线内的照片,是不是那10000个员工之一,来判断是否应该允许其进入这个设施或者进入这个办公楼。这是一个门禁系统,允许员工进入工作场所的门禁。
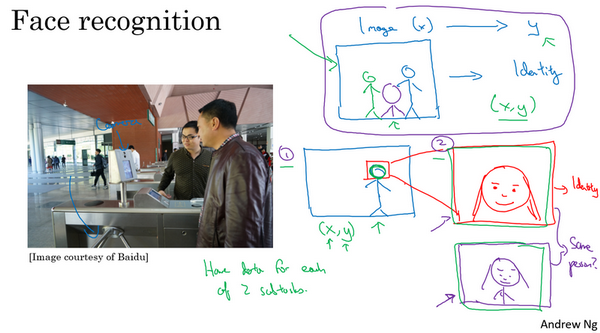
为什么两步法更好呢?实际上有两个原因。一是,你解决的两个问题,每个问题实际上要简单得多。但第二,两个子任务的训练数据都很多。具体来说,有很多数据可以用于人脸识别训练,对于这里的任务1来说,任务就是观察一张图,找出人脸所在的位置,把人脸图像框出来,所以有很多数据,有很多标签数据(x,y),其中x是图片,y是表示人脸的位置,你可以建立一个神经网络,可以很好地处理任务1。然后任务2,也有很多数据可用,今天,业界领先的公司拥有,比如说数百万张人脸照片,所以输入一张裁剪得很紧凑的照片,比如这张红色照片,下面这个,今天业界领先的人脸识别团队有至少数亿的图像,他们可以用来观察两张图片,并试图判断照片里人的身份,确定是否同一个人,所以任务2还有很多数据。相比之下,如果你想一步到位,这样(x,y)的数据对就少得多,其中x是门禁系统拍摄的图像,y是那人的身份,因为你没有足够多的数据去解决这个端到端学习问题,但你却有足够多的数据来解决子问题1和子问题2。
实际上,把这个分成两个子问题,比纯粹的端到端深度学习方法,达到更好的表现。不过如果你有足够多的数据来做端到端学习,也许端到端方法效果更好。但在今天的实践中,并不是最好的方法。
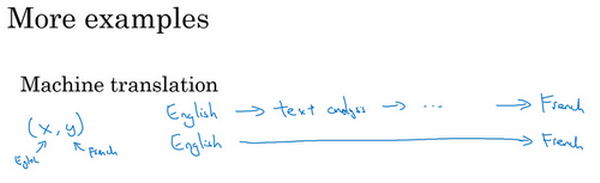
我们再来看几个例子,比如机器翻译。传统上,机器翻译系统也有一个很复杂的流水线,比如英语机翻得到文本,然后做文本分析,基本上要从文本中提取一些特征之类的,经过很多步骤,你最后会将英文文本翻译成法文。因为对于机器翻译来说的确有很多(英文,法文)的数据对,端到端深度学习在机器翻译领域非常好用,那是因为在今天可以收集x-y对的大数据集,就是英文句子和对应的法语翻译。所以在这个例子中,端到端深度学习效果很好。
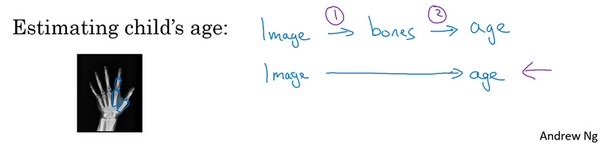
最后一个例子,比如说你希望观察一个孩子手部的X光照片,并估计一个孩子的年龄。你知道,当我第一次听到这个问题的时候,我以为这是一个非常酷的犯罪现场调查任务,你可能悲剧的发现了一个孩子的骨架,你想弄清楚孩子在生时是怎么样的。事实证明,这个问题的典型应用,从X射线图估计孩子的年龄,是我想太多了,没有我想象的犯罪现场调查脑洞那么大,结果这是儿科医生用来判断一个孩子的发育是否正常。
处理这个例子的一个非端到端方法,就是照一张图,然后分割出每一块骨头,所以就是分辨出那段骨头应该在哪里,那段骨头在哪里,那段骨头在哪里,等等。然后,知道不同骨骼的长度,你可以去查表,查到儿童手中骨头的平均长度,然后用它来估计孩子的年龄,所以这种方法实际上很好。
相比之下,如果你直接从图像去判断孩子的年龄,那么你需要大量的数据去直接训练。据我所知,这种做法今天还是不行的,因为没有足够的数据来用端到端的方式来训练这个任务。
你可以想象一下如何将这个问题分解成两个步骤,第一步是一个比较简单的问题,也许你不需要那么多数据,也许你不需要许多X射线图像来切分骨骼。而任务二,收集儿童手部的骨头长度的统计数据,你不需要太多数据也能做出相当准确的估计,所以这个多步方法看起来很有希望,也许比端对端方法更有希望,至少直到你能获得更多端到端学习的数据之前。
假设你正在搭建一个机器学习系统,你要决定是否使用端对端方法,我们来看看端到端深度学习的一些优缺点,这样你就可以根据一些准则,判断你的应用程序是否有希望使用端到端方法。

这里是应用端到端学习的一些好处,首先端到端学习真的只是让数据说话。所以如果你有足够多的(x,y)数据,那么不管从x到y最适合的函数映射是什么,如果你训练一个足够大的神经网络,希望这个神经网络能自己搞清楚,而使用纯机器学习方法,直接从x到y输入去训练的神经网络,可能更能够捕获数据中的任何统计信息,而不是被迫引入人类的成见。
例如,在语音识别领域,早期的识别系统有这个音位概念,就是基本的声音单元,如cat单词的"cat"的Cu-、Ah-和Tu-,我觉得这个音位是人类语言学家生造出来的,我实际上认为音位其实是语音学家的幻想,用音位描述语言也还算合理。但是不要强迫你的学习算法以音位为单位思考,这点有时没那么明显。如果你让你的学习算法学习它想学习的任意表示方式,而不是强迫你的学习算法使用音位作为表示方式,那么其整体表现可能会更好。
端到端深度学习的第二个好处就是这样,所需手工设计的组件更少,所以这也许能够简化你的设计工作流程,你不需要花太多时间去手工设计功能,手工设计这些中间表示方式。

那么缺点呢?这里有一些缺点,首先,它可能需要大量的数据。要直接学到这个x到y的映射,你可能需要大量(x,y)数据。我们在以前的视频里看过一个例子,其中你可以收集大量子任务数据,比如人脸识别,我们可以收集很多数据用来分辨图像中的人脸,当你找到一张脸后,也可以找得到很多人脸识别数据。但是对于整个端到端任务,可能只有更少的数据可用。所以x这是端到端学习的输入端,y是输出端,所以你需要很多这样的(x,y)数据,在输入端和输出端都有数据,这样可以训练这些系统。这就是为什么我们称之为端到端学习,因为你直接学习出从系统的一端到系统的另一端。
另一个缺点是,它排除了可能有用的手工设计组件。机器学习研究人员一般都很鄙视手工设计的东西,但如果你没有很多数据,你的学习算法就没办法从很小的训练集数据中获得洞察力。所以手工设计组件在这种情况,可能是把人类知识直接注入算法的途径,这总不是一件坏事。我觉得学习算法有两个主要的知识来源,一个是数据,另一个是你手工设计的任何东西,可能是组件,功能,或者其他东西。所以当你有大量数据时,手工设计的东西就不太重要了,但是当你没有太多的数据时,构造一个精心设计的系统,实际上可以将人类对这个问题的很多认识直接注入到问题里,进入算法里应该挺有帮助的。
所以端到端深度学习的弊端之一是它把可能有用的人工设计的组件排除在外了,精心设计的人工组件可能非常有用,但它们也有可能真的伤害到你的算法表现。例如,强制你的算法以音位为单位思考,也许让算法自己找到更好的表示方法更好。所以这是一把双刃剑,可能有坏处,可能有好处,但往往好处更多,手工设计的组件往往在训练集更小的时候帮助更大。

如果你在构建一个新的机器学习系统,而你在尝试决定是否使用端到端深度学习,我认为关键的问题是,你有足够的数据能够直接学到从x映射到y足够复杂的函数吗?我还没有正式定义过这个词"必要复杂度(complexity needed)"。但直觉上,如果你想从x到y的数据学习出一个函数,就是看着这样的图像识别出图像中所有骨头的位置,那么也许这像是识别图中骨头这样相对简单的问题,也许系统不需要那么多数据来学会处理这个任务。或给出一张人物照片,也许在图中把人脸找出来不是什么难事,所以你也许不需要太多数据去找到人脸,或者至少你可以找到足够数据去解决这个问题。相对来说,把手的X射线照片直接映射到孩子的年龄,直接去找这种函数,直觉上似乎是更为复杂的问题。如果你用纯端到端方法,需要很多数据去学习。
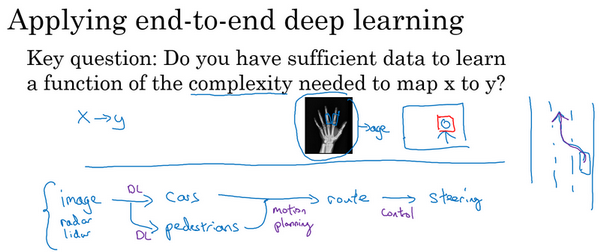
视频最后我讲一个更复杂的例子,你可能知道我一直在花时间帮忙主攻无人驾驶技术的公司drive.ai,无人驾驶技术的发展其实让我相当激动,你怎么造出一辆自己能行驶的车呢?好,这里你可以做一件事,这不是端到端的深度学习方法,你可以把你车前方的雷达、激光雷达或者其他传感器的读数看成是输入图像。但是为了说明起来简单,我们就说拍一张车前方或者周围的照片,然后驾驶要安全的话,你必须能检测到附近的车,你也需要检测到行人,你需要检测其他的东西,当然,我们这里提供的是高度简化的例子。
弄清楚其他车和形如的位置之后,你就需要计划你自己的路线。所以换句话说,当你看到其他车子在哪,行人在哪里,你需要决定如何摆方向盘在接下来的几秒钟内引导车子的路径。如果你决定了要走特定的路径,也许这是道路的俯视图,这是你的车,也许你决定了要走那条路线,这是一条路线,那么你就需要摆动你的方向盘到合适的角度,还要发出合适的加速和制动指令。所以从传感器或图像输入到检测行人和车辆,深度学习可以做得很好,但一旦知道其他车辆和行人的位置或者动向,选择一条车要走的路,这通常用的不是深度学习,而是用所谓的运动规划软件完成的。如果你学过机器人课程,你一定知道运动规划,然后决定了你的车子要走的路径之后。还会有一些其他算法,我们说这是一个控制算法,可以产生精确的决策确定方向盘应该精确地转多少度,油门或刹车上应该用多少力。

所以这个例子就表明了,如果你想使用机器学习或者深度学习来学习某些单独的组件,那么当你应用监督学习时,你应该仔细选择要学习的x到y映射类型,这取决于那些任务你可以收集数据。相比之下,谈论纯端到端深度学习方法是很激动人心的,你输入图像,直接得出方向盘转角,但是就目前能收集到的数据而言,还有我们今天能够用神经网络学习的数据类型而言,这实际上不是最有希望的方法,或者说这个方法并不是团队想出的最好用的方法。而我认为这种纯粹的端到端深度学习方法,其实前景不如这样更复杂的多步方法。因为目前能收集到的数据,还有我们现在训练神经网络的能力是有局限的。
lesson4:卷积神经网络(Convolutional Neural Networks)
Week1:卷积神经网络(Convolutional Neural Networks)
1.计算机视觉(Computer vision)
欢迎参加这次的卷积神经网络课程,计算机视觉是一个飞速发展的一个领域,这多亏了深度学习。深度学习与计算机视觉可以帮助汽车,查明周围的行人和汽车,并帮助汽车避开它们。还使得人脸识别技术变得更加效率和精准,你们即将能够体验到或早已体验过仅仅通过刷脸就能解锁手机或者门锁。当你解锁了手机,我猜手机上一定有很多分享图片的应用。在上面,你能看到美食,酒店或美丽风景的图片。有些公司在这些应用上使用了深度学习技术来向你展示最为生动美丽以及与你最为相关的图片。机器学习甚至还催生了新的艺术类型。深度学习之所以让我兴奋有下面两个原因,我想你们也是这么想的。
第一,计算机视觉的高速发展标志着新型应用产生的可能,这是几年前,人们所不敢想象的。通过学习使用这些工具,你也许能够创造出新的产品和应用。
其次,即使到头来你未能在计算机视觉上有所建树,但我发现,人们对于计算机视觉的研究是如此富有想象力和创造力,由此衍生出新的神经网络结构与算法,这实际上启发人们去创造出计算机视觉与其他领域的交叉成果。举个例子,之前我在做语音识别的时候,我经常从计算机视觉领域中寻找灵感,
并将其应用于我的文献当中。所以即使你在计算机视觉方面没有做出成果,我也希望你也可以将所学的知识应用到其他算法和结构。就介绍到这儿,让我们开始学习吧。
这是我们本节课将要学习的一些问题,你应该早就听说过图片分类,或者说图片识别。比如给出这张64×64的图片,让计算机去分辨出这是一只猫。

还有一个例子,在计算机视觉中有个问题叫做目标检测,比如在一个无人驾驶项目中,你不一定非得识别出图片中的物体是车辆,但你需要计算出其他车辆的位置,以确保自己能够避开它们。所以在目标检测项目中,首先需要计算出图中有哪些物体,比如汽车,还有图片中的其他东西,再将它们模拟成一个个盒子,或用一些其他的技术识别出它们在图片中的位置。注意在这个例子中,在一张图片中同时有多个车辆,每辆车相对与你来说都有一个确切的距离。

还有一个更有趣的例子,就是神经网络实现的图片风格迁移,比如说你有一张图片,但你想将这张图片转换为另外一种风格。所以图片风格迁移,就是你有一张满意的图片和一张风格图片,实际上右边这幅画是毕加索的画作,而你可以利用神经网络将它们融合到一起,描绘出一张新的图片。它的整体轮廓来自于左边,却是右边的风格,最后生成下面这张图片。这种神奇的算法创造出了新的艺术风格,所以在这门课程中,你也能通过学习做到这样的事情。
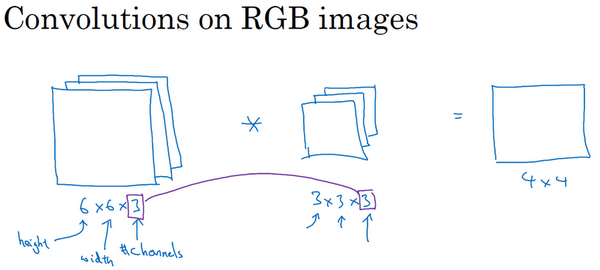
但在应用计算机视觉时要面临一个挑战,就是数据的输入可能会非常大。举个例子,在过去的课程中,你们一般操作的都是64×64的小图片,实际上,它的数据量是64×64×3,因为每张图片都有3个颜色通道。如果计算一下的话,可得知数据量为12288,所以我们的特征向量x维度为12288。这其实还好,因为64×64真的是很小的一张图片。
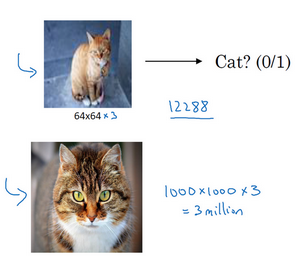
如果你要操作更大的图片,比如一张1000×1000的图片,它足有1兆那么大,但是特征向量的维度达到了1000×1000×3,因为有3个RGB通道,所以数字将会是300万。如果你在尺寸很小的屏幕上观察,可能察觉不出上面的图片只有64×64那么大,而下面一张是1000×1000的大图。
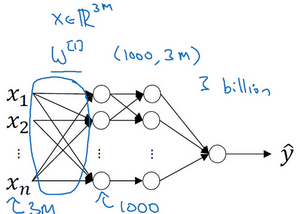
如果你要输入300万的数据量,这就意味着,特征向量x的维度高达300万。所以在第一隐藏层中,你也许会有1000个隐藏单元,而所有的权值组成了矩阵 W^{1}。如果你使用了标准的全连接网络,就像我们在第一门和第二门的课程里说的,这个矩阵的大小将会是1000×300万。因为现在x的维度为3m,3m通常用来表示300万。这意味着矩阵W^{1}会有30亿个参数,这是个非常巨大的数字。在参数如此大量的情况下,难以获得足够的数据来防止神经网络发生过拟合和竞争需求,要处理包含30亿参数的神经网络,巨大的内存需求让人不太能接受。
2.边缘检测
1.2 边缘检测示例(Edge detection example)
1.3 更多边缘检测内容(More edge detection)
3.填充(padding)
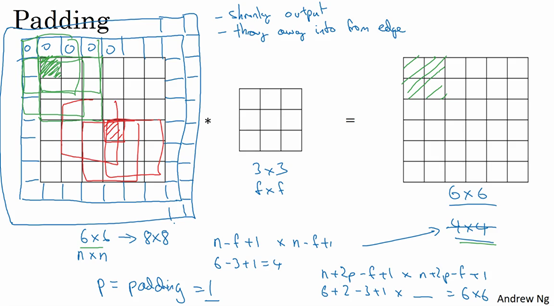
作用:
- 防止图像尺寸缩小,卷积后大小不变
- 保住边缘像素信息,不让边角特征丢失
- 统一输入输出尺寸,方便搭建深层网络
两种常用填充
- Same Padding 卷积前后尺寸不变 最常用,CNN 默认
- Valid Padding 不填充,只卷积有效区域,尺寸变小
填充方式:
- 零填充 Zero Padding:最常用,边缘补 0
- 镜像填充、复制填充(少用)
4.步长卷积
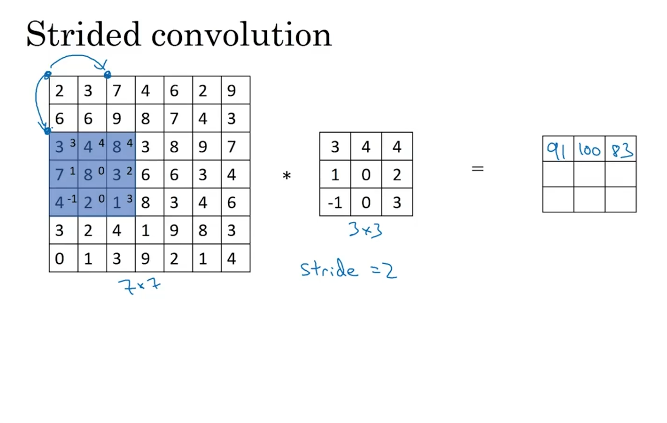
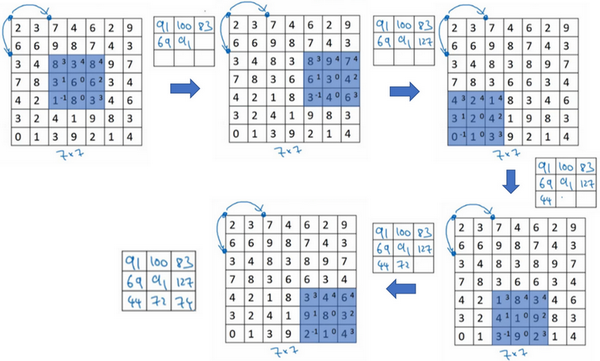
现在只剩下最后的一个细节了,如果商不是一个整数怎么办?在这种情况下,我们向下取整。⌊ ⌋这是向下取整的符号,这也叫做对z进行地板除(floor ),这意味着z向下取整到最近的整数。这个原则实现的方式是,你只在蓝框完全包括在图像或填充完的图像内部时,才对它进行运算。如果有任意一个蓝框移动到了外面,那你就不要进行相乘操作,这是一个惯例。你的3×3的过滤器必须完全处于图像中或者填充之后的图像区域内才输出相应结果,这就是惯例。因此正确计算输出维度的方法是向下取整,以免\frac{n + 2p - f}{s}不是整数。

总结一下维度情况,如果你有一个n×n的矩阵或者n×n的图像,与一个f×f的矩阵卷积,或者说f×f的过滤器。Padding是p,步幅为s没输出尺寸就是这样:

可以选择所有的数使结果是整数是挺不错的,尽管一些时候,你不必这样做,只要向下取整也就可以了。你也可以自己选择一些n,f,p和s的值来验证这个输出尺寸的公式是对的。
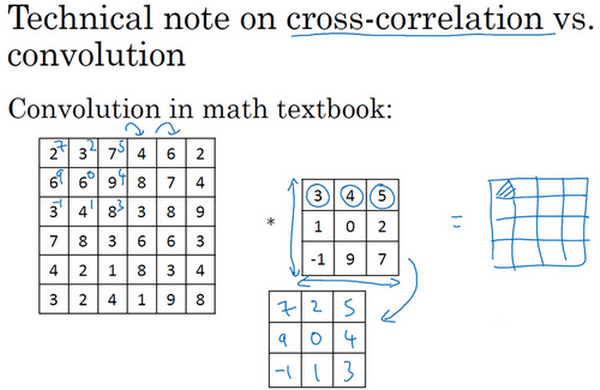
在讲下一部分之前,这里有一个关于互相关和卷积的技术性建议,这不会影响到你构建卷积神经网络的方式,但取决于你读的是数学教材还是信号处理教材,在不同的教材里符号可能不一致。如果你看的是一本典型的数学教科书,那么卷积的定义是做元素乘积求和,实际上还有一个步骤是你首先要做的,也就是在把这个6×6的矩阵和3×3的过滤器卷积之前,首先你将3×3的过滤器沿水平和垂直轴翻转,所以\begin{bmatrix}3 & 4 & 5 \\ 1 & 0 & 2 \\ - 1 & 9 & 7 \\ \end{bmatrix}变为\begin{bmatrix} 7& 2 & 5 \\ 9 & 0 & 4 \\ - 1 & 1 & 3 \\\end{bmatrix},这相当于将3×3的过滤器做了个镜像,在水平和垂直轴上(整理者注:此处应该是先顺时针旋转90得到\begin{bmatrix}-1 & 1 & 3 \\ 9 & 0 & 4 \\ 7 & 2 & 5 \\\end{bmatrix},再水平翻转得到\begin{bmatrix} 7& 2 & 5 \\ 9 & 0 & 4 \\ - 1& 1 & 3 \\\end{bmatrix})。然后你再把这个翻转后的矩阵复制到这里(左边的图像矩阵),你要把这个翻转矩阵的元素相乘来计算输出的4×4矩阵左上角的元素,如图所示。然后取这9个数字,把它们平移一个位置,再平移一格,以此类推。
所以我们在这些视频中定义卷积运算时,我们跳过了这个镜像操作。从技术上讲,我们实际上做的,我们在前面视频中使用的操作,有时被称为互相关(cross-correlation )而不是卷积(convolution)。但在深度学习文献中,按照惯例,我们将这(不进行翻转操作)叫做卷积操作。
总结来说,按照机器学习的惯例,我们通常不进行翻转操作。从技术上说,这个操作可能叫做互相关更好。但在大部分的深度学习文献中都把它叫做卷积运算,因此我们将在这些视频中使用这个约定。如果你读了很多机器学习文献的话,你会发现许多人都把它叫做卷积运算,不需要用到这些翻转。
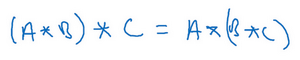
事实证明在信号处理中或某些数学分支中,在卷积的定义包含翻转,使得卷积运算符拥有这个性质,即(A*B)*C=A*(B*C),这在数学中被称为结合律。这对于一些信号处理应用来说很好,但对于深度神经网络来说它真的不重要,因此省略了这个双重镜像操作,就简化了代码,并使神经网络也能正常工作。
根据惯例,我们大多数人都叫它卷积,尽管数学家们更喜欢称之为互相关,但这不会影响到你在编程练习中要实现的任何东西,也不会影响你阅读和理解深度学习文献。
5.三维卷积
你已经知道如何对二维图像做卷积了,现在看看如何执行卷积不仅仅在二维图像上,而是三维立体上。
我们从一个例子开始,假如说你不仅想检测灰度图像的特征,也想检测RGB彩色图像的特征。彩色图像如果是6×6×3,这里的3指的是三个颜色通道,你可以把它想象成三个6×6图像的堆叠。为了检测图像的边缘或者其他的特征,不是把它跟原来的3×3的过滤器做卷积,而是跟一个三维的过滤器,它的维度是3×3×3,这样这个过滤器也有三层,对应红绿、蓝三个通道。
给这些起个名字(原图像),这里的第一个6代表图像高度,第二个6代表宽度,这个3代表通道的数目。同样你的过滤器也有一个高,宽和通道数,并且图像的通道数必须和过滤器的通道数匹配,所以这两个数(紫色方框标记的两个数)必须相等。下个幻灯片里,我们就会知道这个卷积操作是如何进行的了,这个的输出会是一个4×4的图像,注意是4×4×1,最后一个数不是3了。
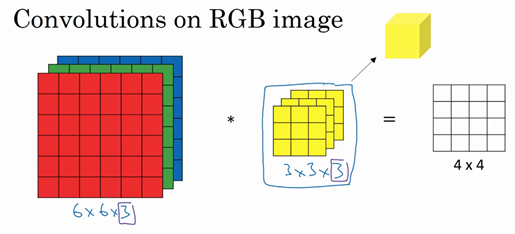
我们研究下这背后的细节,首先先换一张好看的图片。这个是6×6×3的图像,这个是3×3×3的过滤器,最后一个数字通道数必须和过滤器中的通道数相匹配。为了简化这个3×3×3过滤器的图像,我们不把它画成3个矩阵的堆叠,而画成这样,一个三维的立方体。
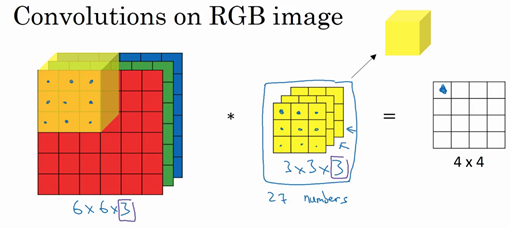
为了计算这个卷积操作的输出,你要做的就是把这个3×3×3的过滤器先放到最左上角的位置,这个3×3×3的过滤器有27个数,27个参数就是3的立方。依次取这27个数,然后乘以相应的红绿蓝通道中的数字。先取红色通道的前9个数字,然后是绿色通道,然后再是蓝色通道,乘以左边黄色立方体覆盖的对应的27个数,然后把这些数都加起来,就得到了输出的第一个数字。
如果要计算下一个输出,你把这个立方体滑动一个单位,再与这27个数相乘,把它们都加起来,就得到了下一个输出,以此类推。
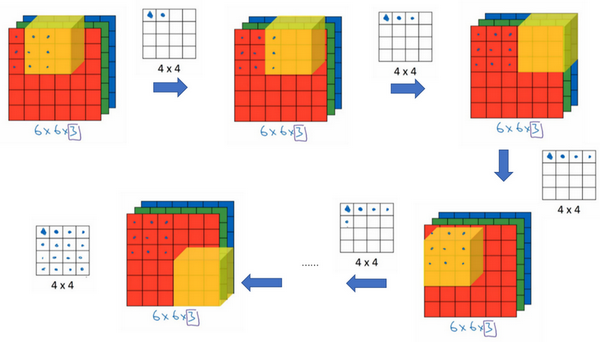
那么,这个能干什么呢?举个例子,这个过滤器是3×3×3的,如果你想检测图像红色通道的边缘,那么你可以将第一个过滤器设为\begin{bmatrix}1 & 0 & - 1 \\ 1 & 0 & - 1 \\ 1 & 0 & - 1 \\\end{bmatrix},和之前一样,而绿色通道全为0,\begin{bmatrix} 0& 0 & 0 \\ 0 &0 & 0 \\ 0 & 0 & 0 \\\end{bmatrix},蓝色也全为0。如果你把这三个堆叠在一起形成一个3×3×3的过滤器,那么这就是一个检测垂直边界的过滤器,但只对红色通道有用。
或者如果你不关心垂直边界在哪个颜色通道里,那么你可以用一个这样的过滤器,\begin{bmatrix}1 & 0 & - 1 \\ 1 & 0 & - 1 \\ 1 & 0 & - 1 \\ \end{bmatrix},\begin{bmatrix}1 & 0 & - 1 \\ 1 & 0 & - 1 \\ 1 & 0 & - 1 \\ \end{bmatrix},\begin{bmatrix}1 & 0 & - 1 \\ 1 & 0 & - 1 \\ 1 & 0 & - 1 \\\end{bmatrix},所有三个通道都是这样。所以通过设置第二个过滤器参数,你就有了一个边界检测器,3×3×3的边界检测器,用来检测任意颜色通道里的边界。参数的选择不同,你就可以得到不同的特征检测器,所有的都是3×3×3的过滤器。
按照计算机视觉的惯例,当你的输入有特定的高宽和通道数时,你的过滤器可以有不同的高,不同的宽,但是必须一样的通道数。理论上,我们的过滤器只关注红色通道,或者只关注绿色或者蓝色通道也是可行的。
再注意一下这个卷积立方体,一个6×6×6的输入图像卷积上一个3×3×3的过滤器,得到一个4×4的二维输出。
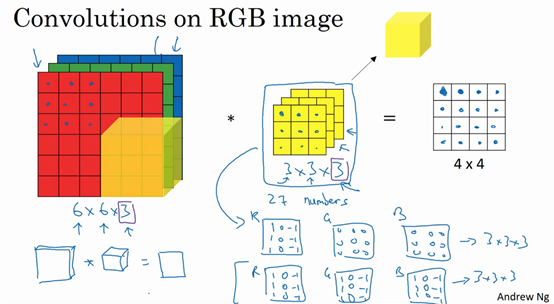
现在你已经了解了如何对立方体卷积,还有最后一个概念,对建立卷积神经网络至关重要。就是,如果我们不仅仅想要检测垂直边缘怎么办?如果我们同时检测垂直边缘和水平边缘,还有45°倾斜的边缘,还有70°倾斜的边缘怎么做?换句话说,如果你想同时用多个过滤器怎么办?
这是我们上一张幻灯片的图片,我们让这个6×6×3的图像和这个3×3×3的过滤器卷积,得到4×4的输出。(第一个)这可能是一个垂直边界检测器或者是学习检测其他的特征。第二个过滤器可以用橘色来表示,它可以是一个水平边缘检测器。
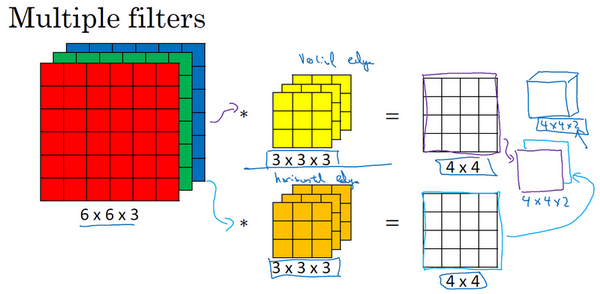
所以和第一个过滤器卷积,可以得到第一个4×4的输出,然后卷积第二个过滤器,得到一个不同的4×4的输出。我们做完卷积,然后把这两个4×4的输出,取第一个把它放到前面,然后取第二个过滤器输出,我把它画在这,放到后面。所以把这两个输出堆叠在一起,这样你就都得到了一个4×4×2的输出立方体,你可以把这个立方体当成,重新画在这,就是一个这样的盒子,所以这就是一个4×4×2的输出立方体。它用6×6×3的图像,然后卷积上这两个不同的3×3的过滤器,得到两个4×4的输出,它们堆叠在一起,形成一个4×4×2的立方体,这里的2的来源于我们用了两个不同的过滤器。
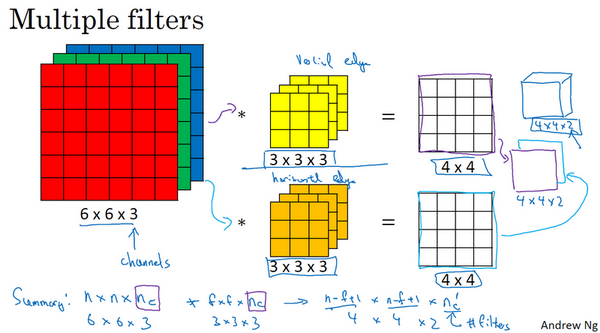
我们总结一下维度,如果你有一个n \times n \times n_{c}(通道数)的输入图像,在这个例子中就是6×6×3,这里的n_{c}就是通道数目,然后卷积上一个f×f×n_{c},这个例子中是3×3×3,按照惯例,这个(前一个n_{c})和这个(后一个n_{c})必须数值相同。然后你就得到了(n-f+1)×(n-f+1)×n_{c^{'}},这里n_{c^{'}}其实就是下一层的通道数,它就是你用的过滤器的个数,在我们的例子中,那就是4×4×2。我写下这个假设时,用的步幅为1,并且没有padding 。如果你用了不同的步幅或者padding,那么这个n-f+1数值会变化,正如前面的视频演示的那样。
这个对立方体卷积的概念真的很有用,你现在可以用它的一小部分直接在三个通道的RGB图像上进行操作。更重要的是,你可以检测两个特征,比如垂直和水平边缘或者10个或者128个或者几百个不同的特征,并且输出的通道数会等于你要检测的特征数。
对于这里的符号,我一直用通道数(n_{c})来表示最后一个维度,在文献里大家也把它叫做3维立方体的深度。这两个术语,即通道或者深度,经常被用在文献中。但我觉得深度容易让人混淆,因为你通常也会说神经网络的深度。所以,在这些视频里我会用通道这个术语来表示过滤器的第三个维度的大小。
6.卷积网络单层结构
今天我们要讲的是如何构建卷积神经网络的卷积层,下面来看个例子。
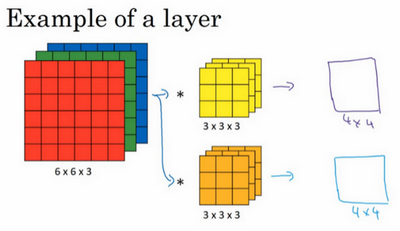
上节课,我们已经讲了如何通过两个过滤器卷积处理一个三维图像,并输出两个不同的4×4矩阵。假设使用第一个过滤器进行卷积,得到第一个4×4矩阵。使用第二个过滤器进行卷积得到另外一个4×4矩阵。
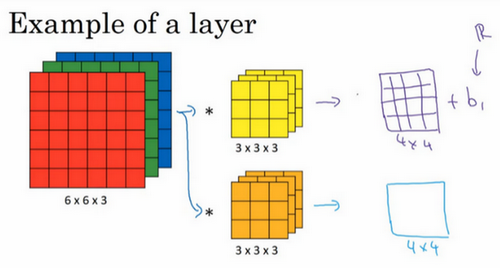
最终各自形成一个卷积神经网络层,然后增加偏差,它是一个实数,通过Python 的广播机制给这16个元素都加上同一偏差。然后应用非线性函数,为了说明,它是一个非线性激活函数ReLU,输出结果是一个4×4矩阵。
对于第二个4×4矩阵,我们加上不同的偏差,它也是一个实数,16个数字都加上同一个实数,然后应用非线性函数,也就是一个非线性激活函数ReLU,最终得到另一个4×4矩阵。然后重复我们之前的步骤,把这两个矩阵堆叠起来,最终得到一个4×4×2的矩阵。我们通过计算,从6×6×3的输入推导出一个4×4×2矩阵,它是卷积神经网络的一层,把它映射到标准神经网络中四个卷积层中的某一层或者一个非卷积神经网络中。
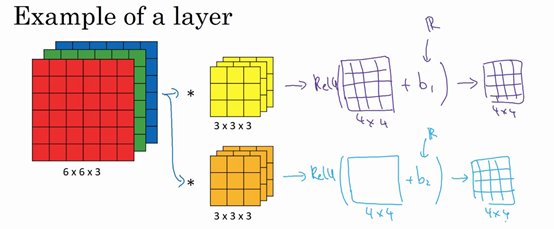
注意前向传播中一个操作就是z^{1} = W^{1}a^{0} + b^{1},其中a^{0} =x,执行非线性函数得到a^{1},即a^{1} = g(z^{1})。这里的输入是a^{\left\lbrack 0\right\rbrack},也就是x,这些过滤器用变量W^{1}表示。在卷积过程中,我们对这27个数进行操作,其实是27×2,因为我们用了两个过滤器,我们取这些数做乘法。实际执行了一个线性函数,得到一个4×4的矩阵。卷积操作的输出结果是一个4×4的矩阵,它的作用类似于W^{1}a^{0},也就是这两个4×4矩阵的输出结果,然后加上偏差。
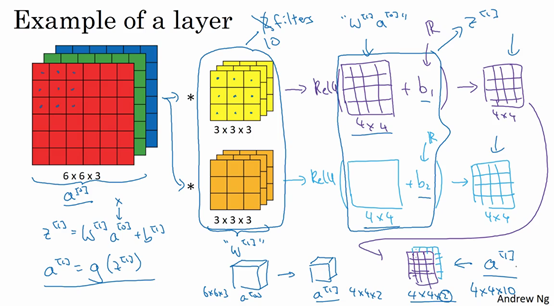
这一部分(图中蓝色边框标记的部分)就是应用激活函数ReLU之前的值,它的作用类似于z^{1},最后应用非线性函数,得到的这个4×4×2矩阵,成为神经网络的下一层,也就是激活层。
这就是a^{0}到a^{1}的演变过程,首先执行线性函数,然后所有元素相乘做卷积,具体做法是运用线性函数再加上偏差,然后应用激活函数ReLU。这样就通过神经网络的一层把一个6×6×3的维度a^{0}演化为一个4×4×2维度的a^{1},这就是卷积神经网络的一层。
示例中我们有两个过滤器,也就是有两个特征,因此我们才最终得到一个4×4×2的输出。但如果我们用了10个过滤器,而不是2个,我们最后会得到一个4×4×10维度的输出图像,因为我们选取了其中10个特征映射,而不仅仅是2个,将它们堆叠在一起,形成一个4×4×10的输出图像,也就是a^{\left\lbrack1 \right\rbrack}。
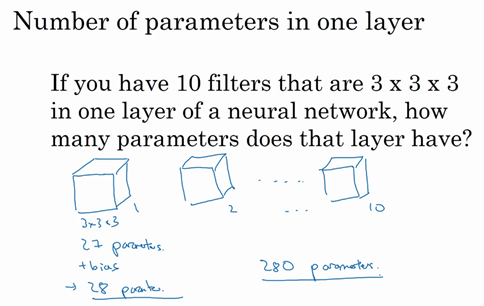
为了加深理解,我们来做一个练习。假设你有10个过滤器,而不是2个,神经网络的一层是3×3×3,那么,这一层有多少个参数呢?我们来计算一下,每一层都是一个3×3×3的矩阵,因此每个过滤器有27个参数,也就是27个数。然后加上一个偏差,用参数b表示,现在参数增加到28个。上一页幻灯片里我画了2个过滤器,而现在我们有10个,加在一起是28×10,也就是280个参数。
请注意一点,不论输入图片有多大,1000×1000也好,5000×5000也好,参数始终都是280个。用这10个过滤器来提取特征,如垂直边缘,水平边缘和其它特征。即使这些图片很大,参数却很少,这就是卷积神经网络的一个特征,叫作"避免过拟合"。你已经知道到如何提取10个特征,可以应用到大图片中,而参数数量固定不变,此例中只有28个,相对较少。
最后我们总结一下用于描述卷积神经网络中的一层(以l层为例),也就是卷积层的各种标记。

这一层是卷积层,用f^{l}表示过滤器大小,我们说过过滤器大小为f×f,上标\lbrack l\rbrack表示l层中过滤器大小为f×f。通常情况下,上标\lbrack l\rbrack用来标记l层。用p^{l}来标记padding 的数量,padding 数量也可指定为一个valid 卷积,即无padding 。或是same 卷积,即选定padding,如此一来,输出和输入图片的高度和宽度就相同了。用s^{l}标记步幅。
这一层的输入会是某个维度的数据,表示为n \times n \times n_{c},n_{c}某层上的颜色通道数。
我们要稍作修改,增加上标\lbrack l -1\rbrack,即n^{\left\lbrack l - 1 \right\rbrack} \times n^{\left\lbrack l -1 \right\rbrack} \times n_{c}^{\left\lbrack l - 1\right\rbrack},因为它是上一层的激活值。
此例中,所用图片的高度和宽度都一样,但它们也有可能不同,所以分别用上下标H和W来标记,即n_{H}^{\left\lbrack l - 1 \right\rbrack} \times n_{W}^{\left\lbrack l - 1 \right\rbrack} \times n_{c}^{\left\lbrack l - 1\right\rbrack}。那么在第l层,图片大小为n_{H}^{\left\lbrack l - 1 \right\rbrack} \times n_{W}^{\left\lbrack l - 1 \right\rbrack} \times n_{c}^{\left\lbrack l - 1\right\rbrack},l层的输入就是上一层的输出,因此上标要用\lbrack l - 1\rbrack。神经网络这一层中会有输出,它本身会输出图像。其大小为n_{H}^{l} \times n_{W}^{l} \times n_{c}^{l},这就是输出图像的大小。
前面我们提到过,这个公式给出了输出图片的大小,至少给出了高度和宽度,\lfloor\frac{n+2p - f}{s} + 1\rfloor(注意:(\frac{n + 2p - f}{s} +1)直接用这个运算结果,也可以向下取整)。在这个新表达式中,l层输出图像的高度,即n_{H}^{l} = \lfloor\frac{n_{H}^{\left\lbrack l - 1 \right\rbrack} +2p^{l} - f^{l}}{s^{l}} +1\rfloor,同样我们可以计算出图像的宽度,用W替换参数H,即n_{W}^{l} = \lfloor\frac{n_{W}^{\left\lbrack l - 1 \right\rbrack} +2p^{l} - f^{l}}{s^{l}} +1\rfloor,公式一样,只要变化高度和宽度的参数我们便能计算输出图像的高度或宽度。这就是由n_{H}^{\left\lbrack l - 1 \right\rbrack}推导n_{H}^{l}以及n_{W}^{\left\lbrack l - 1\right\rbrack}推导n_{W}^{l}的过程。
那么通道数量又是什么?这些数字从哪儿来的?我们来看一下。输出图像也具有深度,通过上一个示例,我们知道它等于该层中过滤器的数量,如果有2个过滤器,输出图像就是4×4×2,它是二维的,如果有10个过滤器,输出图像就是4×4×10。输出图像中的通道数量就是神经网络中这一层所使用的过滤器的数量。如何确定过滤器的大小呢?我们知道卷积一个6×6×3的图片需要一个3×3×3的过滤器,因此过滤器中通道的数量必须与输入中通道的数量一致。因此,输出通道数量就是输入通道数量,所以过滤器维度等于f^{l} \times f^{l} \times n_{c}^{\left\lbrack l - 1 \right\rbrack}。

应用偏差和非线性函数之后,这一层的输出等于它的激活值a^{l},也就是这个维度(输出维度)。a^{l}是一个三维体,即n_{H}^{l} \times n_{W}^{l} \times n_{c}^{l}。当你执行批量梯度下降或小批量梯度下降时,如果有m个例子,就是有m个激活值的集合,那么输出A^{l} = m \times n_{H}^{l} \times n_{W}^{l} \times n_{c}^{l}。如果采用批量梯度下降,变量的排列顺序如下,首先是索引和训练示例,然后是其它三个变量。
该如何确定权重参数,即参数W呢?过滤器的维度已知,为f^{l} \times f^{l} \times n_{c}^{l - 1},这只是一个过滤器的维度,有多少个过滤器,这(n_{c}^{l})是过滤器的数量,权重也就是所有过滤器的集合再乘以过滤器的总数量,即f^{l} \times f^{l} \times n_{c}^{l - 1} \times n_{c}^{l},损失数量L就是l层中过滤器的个数。
最后我们看看偏差参数,每个过滤器都有一个偏差参数,它是一个实数。偏差包含了这些变量,它是该维度上的一个向量。后续课程中我们会看到,为了方便,偏差在代码中表示为一个1×1×1×n_{c}^{l}的四维向量或四维张量。
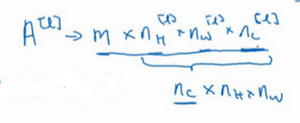
7.简单卷积网络示例
1.8 简单卷积网络示例(A simple convolution network example)
8.池化层
除了卷积层,卷积网络也经常使用池化层来缩减模型的大小,提高计算速度,同时提高所提取特征的鲁棒性,我们来看一下。
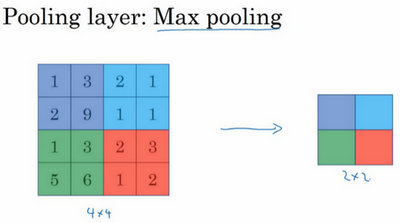
先举一个池化层的例子,然后我们再讨论池化层的必要性。假如输入是一个4×4矩阵,用到的池化类型是最大池化(max pooling)。执行最大池化的树池是一个2×2矩阵。执行过程非常简单,把4×4的输入拆分成不同的区域,我把这个区域用不同颜色来标记。对于2×2的输出,输出的每个元素都是其对应颜色区域中的最大元素值。
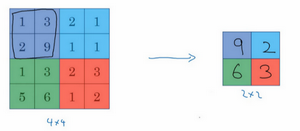
左上区域的最大值是9,右上区域的最大元素值是2,左下区域的最大值是6,右下区域的最大值是3。为了计算出右侧这4个元素值,我们需要对输入矩阵的2×2区域做最大值运算。这就像是应用了一个规模为2的过滤器,因为我们选用的是2×2区域,步幅是2,这些就是最大池化的超参数。
因为我们使用的过滤器为2×2,最后输出是9。然后向右移动2个步幅,计算出最大值2。然后是第二行,向下移动2步得到最大值6。最后向右移动3步,得到最大值3。这是一个2×2矩阵,即f=2,步幅是2,即s=2。
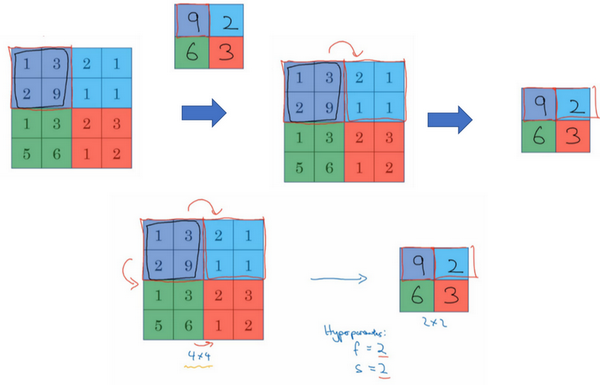
这是对最大池化功能的直观理解,你可以把这个4×4输入看作是某些特征的集合,也许不是。你可以把这个4×4区域看作是某些特征的集合,也就是神经网络中某一层的非激活值集合。数字大意味着可能探测到了某些特定的特征,左上象限具有的特征可能是一个垂直边缘,一只眼睛,或是大家害怕遇到的CAP特征。显然左上象限中存在这个特征,这个特征可能是一只猫眼探测器。然而,右上象限并不存在这个特征。最大化操作的功能就是只要在任何一个象限内提取到某个特征,它都会保留在最大化的池化输出里。所以最大化运算的实际作用就是,如果在过滤器中提取到某个特征,那么保留其最大值。如果没有提取到这个特征,可能在右上象限中不存在这个特征,那么其中的最大值也还是很小,这就是最大池化的直观理解。
必须承认,人们使用最大池化的主要原因是此方法在很多实验中效果都很好。尽管刚刚描述的直观理解经常被引用,不知大家是否完全理解它的真正原因,不知大家是否理解最大池化效率很高的真正原因。
其中一个有意思的特点就是,它有一组超参数,但并没有参数需要学习。实际上,梯度下降没有什么可学的,一旦确定了f和s,它就是一个固定运算,梯度下降无需改变任何值。
我们来看一个有若干个超级参数的示例,输入是一个5×5的矩阵。我们采用最大池化法,它的过滤器参数为3×3,即f=3,步幅为1,s=1,输出矩阵是3×3.之前讲的计算卷积层输出大小的公式同样适用于最大池化,即\frac{n + 2p - f}{s} + 1,这个公式也可以计算最大池化的输出大小。
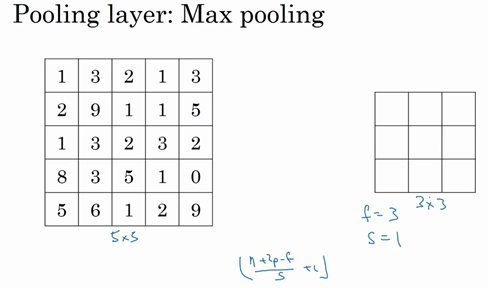
此例是计算3×3输出的每个元素,我们看左上角这些元素,注意这是一个3×3区域,因为有3个过滤器,取最大值9。然后移动一个元素,因为步幅是1,蓝色区域的最大值是9.继续向右移动,蓝色区域的最大值是5。然后移到下一行,因为步幅是1,我们只向下移动一个格,所以该区域的最大值是9。这个区域也是9。这两个区域的最大值都是5。最后这三个区域的最大值分别为8,6和9。超参数f=3,s=1,最终输出如图所示。
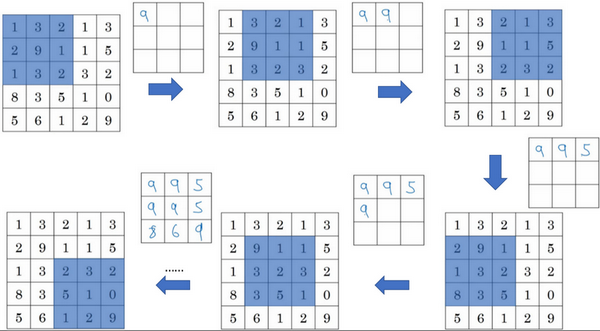
以上就是一个二维输入的最大池化的演示,如果输入是三维的,那么输出也是三维的。例如,输入是5×5×2,那么输出是3×3×2。计算最大池化的方法就是分别对每个通道执行刚刚的计算过程。如上图所示,第一个通道依然保持不变。对于第二个通道,我刚才画在下面的,在这个层做同样的计算,得到第二个通道的输出。一般来说,如果输入是5×5×n_{c},输出就是3×3×n_{c},n_{c}个通道中每个通道都单独执行最大池化计算,以上就是最大池化算法。
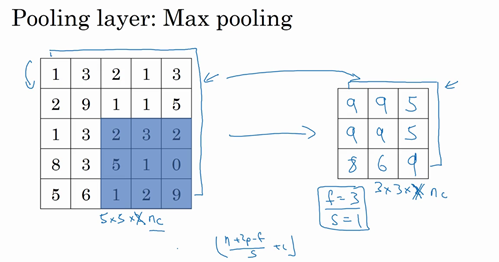
另外还有一种类型的池化,平均池化,它不太常用。我简单介绍一下,这种运算顾名思义,选取的不是每个过滤器的最大值,而是平均值。示例中,紫色区域的平均值是3.75,后面依次是1.25、4和2。这个平均池化的超级参数f=2,s=2,我们也可以选择其它超级参数。
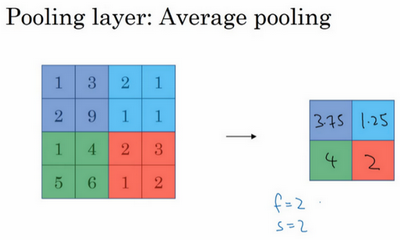
目前来说,最大池化比平均池化更常用。但也有例外,就是深度很深的神经网络,你可以用平均池化来分解规模为7×7×1000的网络的表示层,在整个空间内求平均值,得到1×1×1000,一会我们看个例子。但在神经网络中,最大池化要比平均池化用得更多。
总结一下,池化的超级参数包括过滤器大小f和步幅s,常用的参数值为f=2,s=2,应用频率非常高,其效果相当于高度和宽度缩减一半。也有使用f=3,s=2的情况。至于其它超级参数就要看你用的是最大池化还是平均池化了。你也可以根据自己意愿增加表示padding 的其他超级参数,虽然很少这么用。最大池化时,往往很少用到超参数padding ,当然也有例外的情况,我们下周会讲。大部分情况下,最大池化很少用padding 。目前p最常用的值是0,即p=0。最大池化的输入就是n_{H} \times n_{W} \times n_{c},假设没有padding,则输出\lfloor\frac{n_{H} - f}{s} +1\rfloor \times \lfloor\frac{n_{w} - f}{s} + 1\rfloor \times n_{c}。输入通道与输出通道个数相同,因为我们对每个通道都做了池化。需要注意的一点是,池化过程中没有需要学习的参数。执行反向传播时,反向传播没有参数适用于最大池化。只有这些设置过的超参数,可能是手动设置的,也可能是通过交叉验证设置的。
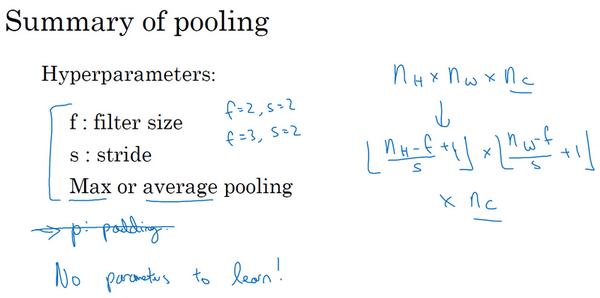
除了这些,池化的内容就全部讲完了。最大池化只是计算神经网络某一层的静态属性,没有什么需要学习的,它只是一个静态属性。
关于池化我们就讲到这儿,现在我们已经知道如何构建卷积层和池化层了。下节课,我们会分析一个更复杂的可以引进全连接层的卷积网络示例。
9.卷积的优势
主要优势:参数共享和稀疏连接
Week2:实例探究(Deep convolutional models: case studies)
1.经典网络
LeNet
Yann LeCun 手写字识别
首先看看LeNet-5 的网络结构,假设你有一张32×32×1的图片,LeNet-5 可以识别图中的手写数字,比如像这样手写数字7。LeNet-5 是针对灰度图片训练的,所以图片的大小只有32×32×1。实际上LeNet-5 的结构和我们上周讲的最后一个范例非常相似,使用6个5×5的过滤器,步幅为1。由于使用了6个过滤器,步幅为1,padding为0,输出结果为28×28×6,图像尺寸从32×32缩小到28×28。然后进行池化操作,在这篇论文写成的那个年代,人们更喜欢使用平均池化,而现在我们可能用最大池化更多一些。在这个例子中,我们进行平均池化,过滤器的宽度为2,步幅为2,图像的尺寸,高度和宽度都缩小了2倍,输出结果是一个14×14×6的图像。我觉得这张图片应该不是完全按照比例绘制的,如果严格按照比例绘制,新图像的尺寸应该刚好是原图像的一半。

接下来是卷积层,我们用一组16个5×5的过滤器,新的输出结果有16个通道。LeNet-5 的论文是在1998年撰写的,当时人们并不使用padding ,或者总是使用valid卷积,这就是为什么每进行一次卷积,图像的高度和宽度都会缩小,所以这个图像从14到14缩小到了10×10。然后又是池化层,高度和宽度再缩小一半,输出一个5×5×16的图像。将所有数字相乘,乘积是400。
下一层是全连接层,在全连接层中,有400个节点,每个节点有120个神经元,这里已经有了一个全连接层。但有时还会从这400个节点中抽取一部分节点构建另一个全连接层,就像这样,有2个全连接层。
最后一步就是利用这84个特征得到最后的输出,我们还可以在这里再加一个节点用来预测\hat{y}的值,\hat{y}有10个可能的值,对应识别0-9这10个数字。在现在的版本中则使用softmax 函数输出十种分类结果,而在当时,LeNet-5网络在输出层使用了另外一种,现在已经很少用到的分类器。
相比现代版本,这里得到的神经网络会小一些,只有约6万个参数。而现在,我们经常看到含有一千万到一亿个参数的神经网络,比这大1000倍的神经网络也不在少数。
不管怎样,如果我们从左往右看,随着网络越来越深,图像的高度和宽度在缩小,从最初的32×32缩小到28×28,再到14×14、10×10,最后只有5×5。与此同时,随着网络层次的加深,通道数量一直在增加,从1增加到6个,再到16个。
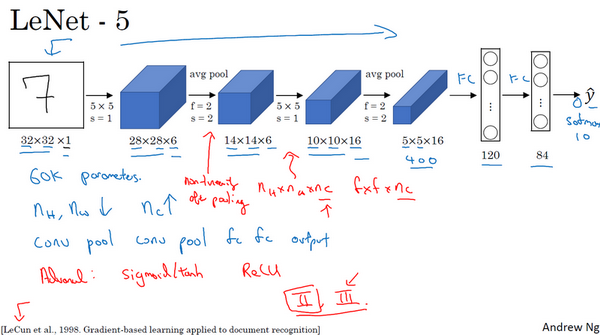
这个神经网络中还有一种模式至今仍然经常用到,就是一个或多个卷积层后面跟着一个池化层,然后又是若干个卷积层再接一个池化层,然后是全连接层,最后是输出,这种排列方式很常用。
对于那些想尝试阅读论文的同学,我再补充几点。接下来的部分主要针对那些打算阅读经典论文的同学,所以会更加深入。这些内容你完全可以跳过,算是对神经网络历史的一种回顾吧,听不懂也不要紧。
读到这篇经典论文时,你会发现,过去,人们使用sigmod 函数和tanh 函数,而不是ReLu 函数,这篇论文中使用的正是sigmod 函数和tanh函数。这种网络结构的特别之处还在于,各网络层之间是有关联的,这在今天看来显得很有趣。
比如说,你有一个n_{H} \times n_{W} \times n_{C}的网络,有n_{C}个通道,使用尺寸为f×f×n_{C}的过滤器,每个过滤器的通道数和它上一层的通道数相同。这是由于在当时,计算机的运行速度非常慢,为了减少计算量和参数,经典的LeNet-5网络使用了非常复杂的计算方式,每个过滤器都采用和输入模块一样的通道数量。论文中提到的这些复杂细节,现在一般都不用了。
我认为当时所进行的最后一步其实到现在也还没有真正完成,就是经典的LeNet-5 网络在池化后进行了非线性函数处理,在这个例子中,池化层之后使用了sigmod 函数。如果你真的去读这篇论文,这会是最难理解的部分之一,我们会在后面的课程中讲到。
AlexNet
- 首次使用 ReLU 激活函数 替代 Sigmoid,解决深层网络梯度消失,收敛更快。
- 双 GPU 并行训练 模型拆分两半分别跑两块显卡,大幅提速。
- 局部响应归一化 LRN 增强局部特征对比度(后来被 BatchNorm 淘汰)。
- 重叠池化(步长<池化核) 池化核 3×3,步长 2,保留更多特征,抑制过拟合。
- 强力正则化:Dropout + 数据增强
-
- Dropout:全连接层随机失活神经元防过拟合
-
- 裁剪、翻转、调色提升数据集
VGGNet
核心思想 :小卷积核使得网络更深更规整
- 抛弃大卷积核,只用 3×3 小卷积 连续2 个 3×3 = 1 个 5×5 感受野 连续3 个 3×3 = 1 个 7×7感受野
- 优势:
-
- 参数量更少
-
- 非线性更强
-
- 训练更容易
- 网络结构极度规整 统一模板:连续 3×3 卷积堆叠 + 2×2 最大池化
2.残差网络
3.残差网络原理
4.网络中的网络与1x1卷积
- 1×1 卷积 :卷积核尺寸为 1×1,不改变空间尺寸(H×W) ,仅作用于通道维度。
- 输入:H×W×C_{in};输出:H×W×C_{out};卷积核:1×1×C_{in}×C_{out}。
-
本质:对每个空间位置的C_{in}个通道做线性组合 + 非线性激活 ,等价于逐像素全连接层 。
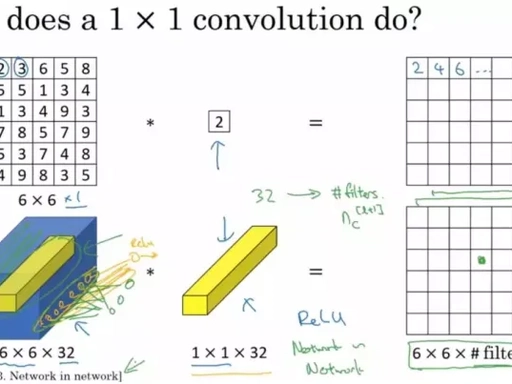
核心作用:
- 通道维度升降维:灵活增减通道数,实现信息压缩或扩充。
-
- 降维:28×28×192 \xrightarrow{1×1,32} 28×28×32,计算量可降一个数量级。
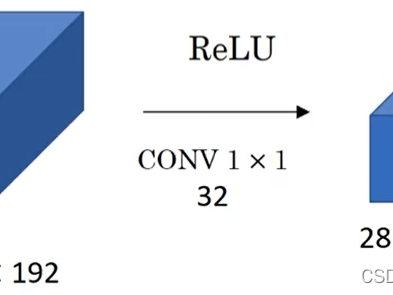
- 降维:28×28×192 \xrightarrow{1×1,32} 28×28×32,计算量可降一个数量级。
- 跨通道信息融合:学习通道间的非线性交互,增强特征表达。
- 保持空间分辨率:不改变 H、W,适合高密度预测任务(如分割、检测)。
5.Inception网络(GoogLeNet)
- 核心:多尺度卷积并行融合,解决单一卷积感受野单一问题
- 主打:参数量小、精度高、计算高效
核心:Inception 模块(精髓)
同一输入并行 4 条分支,最后通道拼接
- 1×1 卷积:提取细粒度特征 + 降维
- 1×1→3×3:先降维再 3×3 卷积,减少计算量
- 1×1→5×5:大感受野,抓全局特征
- 3×3 池化→1×1:池化降采样再升维融合
设计目的
- 同时获取不同大小感受野特征
- 用1×1 卷积降维,大幅压缩计算量
- 避免单纯堆卷积导致参数量暴涨
- 多尺度特征融合:大小目标特征一网打尽
- 1×1 卷积极致降维:以小计算量换高性能
- 摒弃笨重全连接:GAP 轻量化设计
6.迁移学习
7.数据增强
Week3:目标检测(Object detection)
1.目标定位
大家好,欢迎回来,这一周我们学习的主要内容是对象检测,它是计算机视觉领域中一个新兴的应用方向,相比前两年,它的性能越来越好。在构建对象检测之前,我们先了解一下对象定位,首先我们看看它的定义。
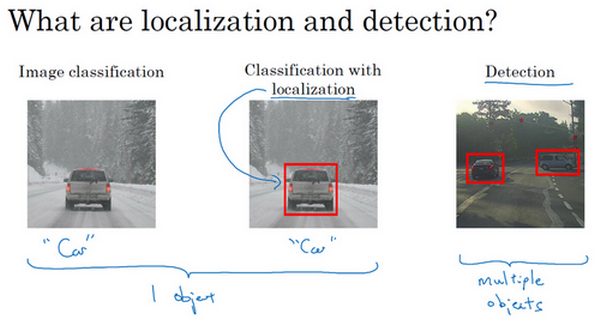
图片分类任务我们已经熟悉了,就是算法遍历图片,判断其中的对象是不是汽车,这就是图片分类。这节课我们要学习构建神经网络的另一个问题,即定位分类问题。这意味着,我们不仅要用算法判断图片中是不是一辆汽车,还要在图片中标记出它的位置,用边框或红色方框把汽车圈起来,这就是定位分类问题。其中"定位"的意思是判断汽车在图片中的具体位置。这周后面几天,我们再讲讲当图片中有多个对象时,应该如何检测它们,并确定出位置。比如,你正在做一个自动驾驶程序,程序不但要检测其它车辆,还要检测其它对象,如行人、摩托车等等,稍后我们再详细讲。
本周我们要研究的分类定位问题,通常只有一个较大的对象位于图片中间位置,我们要对它进行识别和定位。而在对象检测问题中,图片可以含有多个对象,甚至单张图片中会有多个不同分类的对象。因此,图片分类的思路可以帮助学习分类定位,而对象定位的思路又有助于学习对象检测,我们先从分类和定位开始讲起。
图片分类问题你已经并不陌生了,例如,输入一张图片到多层卷积神经网络。这就是卷积神经网络,它会输出一个特征向量,并反馈给softmax单元来预测图片类型。
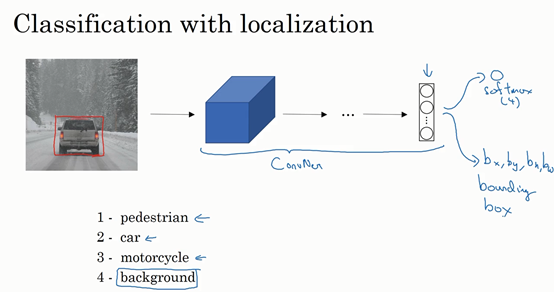
如果你正在构建汽车自动驾驶系统,那么对象可能包括以下几类:行人、汽车、摩托车和背景,这意味着图片中不含有前三种对象,也就是说图片中没有行人、汽车和摩托车,输出结果会是背景对象,这四个分类就是softmax函数可能输出的结果。
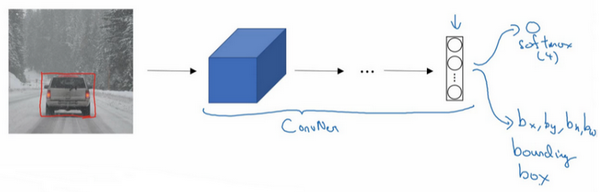
这就是标准的分类过程,如果你还想定位图片中汽车的位置,该怎么做呢?我们可以让神经网络多输出几个单元,输出一个边界框。具体说就是让神经网络再多输出4个数字,标记为b_{x},b_{y},b_{h}和b_{w},这四个数字是被检测对象的边界框的参数化表示。
我们先来约定本周课程将使用的符号表示,图片左上角的坐标为(0,0),右下角标记为(1,1)。要确定边界框的具体位置,需要指定红色方框的中心点,这个点表示为(b_{x},b_{y}),边界框的高度为b_{h},宽度为b_{w}。因此训练集不仅包含神经网络要预测的对象分类标签,还要包含表示边界框的这四个数字,接着采用监督学习算法,输出一个分类标签,还有四个参数值,从而给出检测对象的边框位置。此例中,b_{x}的理想值是0.5,因为它表示汽车位于图片水平方向的中间位置;b_{y}大约是0.7,表示汽车位于距离图片底部\frac{3}{10}的位置;b_{h}约为0.3,因为红色方框的高度是图片高度的0.3倍;b_{w}约为0.4,红色方框的宽度是图片宽度的0.4倍。
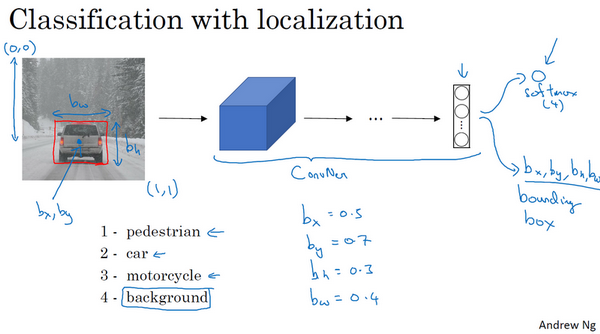
下面我再具体讲讲如何为监督学习任务定义目标标签 y。
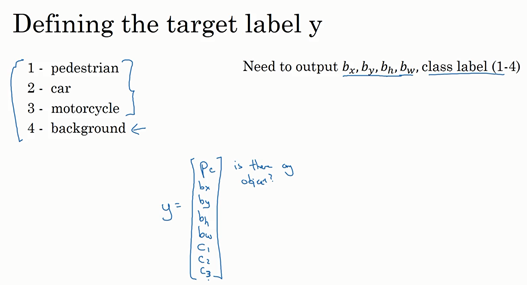
请注意,这有四个分类,神经网络输出的是这四个数字和一个分类标签,或分类标签出现的概率。目标标签y的定义如下:y= \ \begin{bmatrix} p_{c} \\ b_{x} \\ b_{y} \\ b_{h} \\ b_{w} \\ c_{1} \\ c_{2}\\ c_{3} \\\end{bmatrix}
它是一个向量,第一个组件p_{c}表示是否含有对象,如果对象属于前三类(行人、汽车、摩托车),则p_{c}= 1,如果是背景,则图片中没有要检测的对象,则p_{c} =0。我们可以这样理解p_{c},它表示被检测对象属于某一分类的概率,背景分类除外。
如果检测到对象,就输出被检测对象的边界框参数b_{x}、b_{y}、b_{h}和b_{w}。最后,如果存在某个对象,那么p_{c}=1,同时输出c_{1}、c_{2}和c_{3},表示该对象属于1-3类中的哪一类,是行人,汽车还是摩托车。鉴于我们所要处理的问题,我们假设图片中只含有一个对象,所以针对这个分类定位问题,图片最多只会出现其中一个对象。
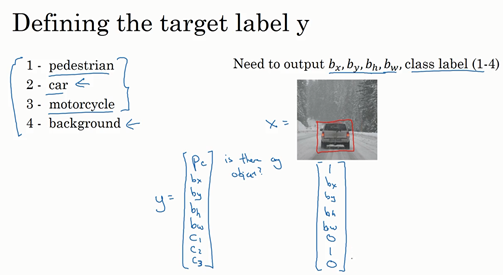
我们再看几个样本,假如这是一张训练集图片,标记为x,即上图的汽车图片。而在y当中,第一个元素p_{c} =1,因为图中有一辆车,b_{x}、b_{y}、b_{h}和b_{w}会指明边界框的位置,所以标签训练集需要标签的边界框。图片中是一辆车,所以结果属于分类2,因为定位目标不是行人或摩托车,而是汽车,所以c_{1}= 0,c_{2} = 1,c_{3} =0,c_{1}、c_{2}和c_{3}中最多只有一个等于1。
这是图片中只有一个检测对象的情况,如果图片中没有检测对象呢?如果训练样本是这样一张图片呢?
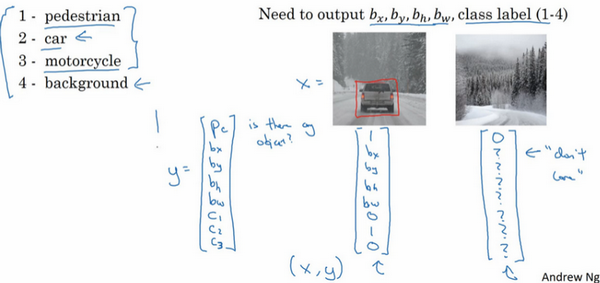
这种情况下,p_{c} =0,y的其它参数将变得毫无意义,这里我全部写成问号,表示"毫无意义"的参数,因为图片中不存在检测对象,所以不用考虑网络输出中边界框的大小,也不用考虑图片中的对象是属于c_{1}、c_{2}和c_{3}中的哪一类。针对给定的被标记的训练样本,不论图片中是否含有定位对象,构建输入图片x和分类标签y的具体过程都是如此。这些数据最终定义了训练集。
最后,我们介绍一下神经网络的损失函数,其参数为类别y和网络输出\hat{y},如果采用平方误差策略,则L\left(\hat{y},y \right) = \left( \hat{y_1} - y_{1} \right)^{2} + \left(\hat{y_2} - y_{2}\right)^{2} + \ldots\left( \hat{y_8} - y_{8}\right)^{2},损失值等于每个元素相应差值的平方和。
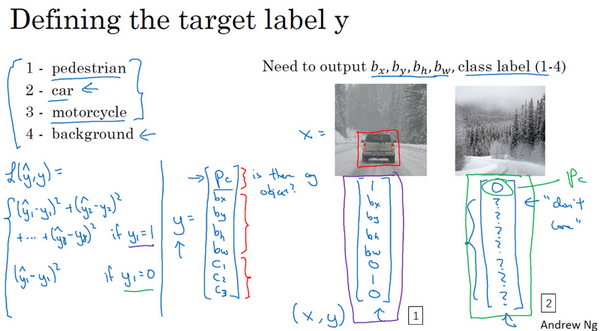
如果图片中存在定位对象,那么y_{1} = 1,所以y_{1} =p_{c},同样地,如果图片中存在定位对象,p_{c} =1,损失值就是不同元素的平方和。
另一种情况是,y_{1} = 0,也就是p_{c} = 0,损失值是\left(\hat{y_1} - y_{1}\right)^{2},因为对于这种情况,我们不用考虑其它元素,只需要关注神经网络输出p_{c}的准确度。
回顾一下,当y_{1} =1时,也就是这种情况(编号1),平方误差策略可以减少这8个元素预测值和实际输出结果之间差值的平方。如果y_{1}=0,y 矩阵中的后7个元素都不用考虑(编号2),只需要考虑神经网络评估y_{1}(即p_{c})的准确度。
为了让大家了解对象定位的细节,这里我用平方误差简化了描述过程。实际应用中,你可以不对c_{1}、c_{2}、c_{3}和softmax激活函数应用对数损失函数,并输出其中一个元素值,通常做法是对边界框坐标应用平方差或类似方法,对p_{c}应用逻辑回归函数,甚至采用平方预测误差也是可以的。
2.特征点检测
上节课,我们讲了如何利用神经网络进行对象定位,即通过输出四个参数值b_{x}、b_{y}、b_{h}和b_{w}给出图片中对象的边界框。更概括地说,神经网络可以通过输出图片上特征点的(x,y)坐标来实现对目标特征的识别,我们看几个例子。

假设你正在构建一个人脸识别应用,出于某种原因,你希望算法可以给出眼角的具体位置。眼角坐标为(x,y),你可以让神经网络的最后一层多输出两个数字l_{x}和l_{y},作为眼角的坐标值。如果你想知道两只眼睛的四个眼角的具体位置,那么从左到右,依次用四个特征点来表示这四个眼角。对神经网络稍做些修改,输出第一个特征点(l_{1x},l_{1y}),第二个特征点(l_{2x},l_{2y}),依此类推,这四个脸部特征点的位置就可以通过神经网络输出了。

也许除了这四个特征点,你还想得到更多的特征点输出值,这些(图中眼眶上的红色特征点)都是眼睛的特征点,你还可以根据嘴部的关键点输出值来确定嘴的形状,从而判断人物是在微笑还是皱眉,也可以提取鼻子周围的关键特征点。为了便于说明,你可以设定特征点的个数,假设脸部有64个特征点,有些点甚至可以帮助你定义脸部轮廓或下颌轮廓。选定特征点个数,并生成包含这些特征点的标签训练集,然后利用神经网络输出脸部关键特征点的位置。
具体做法是,准备一个卷积网络和一些特征集,将人脸图片输入卷积网络,输出1或0,1表示有人脸,0表示没有人脸,然后输出(l_{1x},l_{1y})......直到(l_{64x},l_{64y})。这里我用l代表一个特征,这里有129个输出单元,其中1表示图片中有人脸,因为有64个特征,64×2=128,所以最终输出128+1=129个单元,由此实现对图片的人脸检测和定位。这只是一个识别脸部表情的基本构造模块,如果你玩过Snapchat 或其它娱乐类应用,你应该对AR (增强现实)过滤器多少有些了解,Snapchat过滤器实现了在脸上画皇冠和其他一些特殊效果。检测脸部特征也是计算机图形效果的一个关键构造模块,比如实现脸部扭曲,头戴皇冠等等。当然为了构建这样的网络,你需要准备一个标签训练集,也就是图片x和标签y的集合,这些点都是人为辛苦标注的。
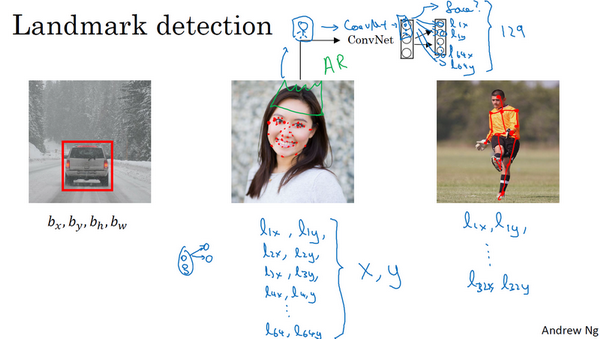
最后一个例子,如果你对人体姿态检测感兴趣,你还可以定义一些关键特征点,如胸部的中点,左肩,左肘,腰等等。然后通过神经网络标注人物姿态的关键特征点,再输出这些标注过的特征点,就相当于输出了人物的姿态动作。当然,要实现这个功能,你需要设定这些关键特征点,从胸部中心点(l_{1x},l_{1y})一直往下,直到(l_{32x},l_{32y})。
一旦了解如何用二维坐标系定义人物姿态,操作起来就相当简单了,批量添加输出单元,用以输出要识别的各个特征点的(x,y)坐标值。要明确一点,特征点1的特性在所有图片中必须保持一致,就好比,特征点1始终是右眼的外眼角,特征点2是右眼的内眼角,特征点3是左眼内眼角,特征点4是左眼外眼角等等。所以标签在所有图片中必须保持一致,假如你雇用他人或自己标记了一个足够大的数据集,那么神经网络便可以输出上述所有特征点,你可以利用它们实现其他有趣的效果,比如判断人物的动作姿态,识别图片中的人物表情等等。
3.目标检测
学过了对象定位和特征点检测,今天我们来构建一个对象检测算法。这节课,我们将学习如何通过卷积网络进行对象检测,采用的是基于滑动窗口的目标检测算法。

假如你想构建一个汽车检测算法,步骤是,首先创建一个标签训练集,也就是x和y表示适当剪切的汽车图片样本,这张图片(编号1)x是一个正样本,因为它是一辆汽车图片,这几张图片(编号2、3)也有汽车,但这两张(编号4、5)没有汽车。出于我们对这个训练集的期望,你一开始可以使用适当剪切的图片,就是整张图片x几乎都被汽车占据,你可以照张照片,然后剪切,剪掉汽车以外的部分,使汽车居于中间位置,并基本占据整张图片。有了这个标签训练集,你就可以开始训练卷积网络了,输入这些适当剪切过的图片(编号6),卷积网络输出y,0或1表示图片中有汽车或没有汽车。训练完这个卷积网络,就可以用它来实现滑动窗口目标检测,具体步骤如下。

假设这是一张测试图片,首先选定一个特定大小的窗口,比如图片下方这个窗口,将这个红色小方块输入卷积神经网络,卷积网络开始进行预测,即判断红色方框内有没有汽车。

滑动窗口目标检测算法接下来会继续处理第二个图像,即红色方框稍向右滑动之后的区域,并输入给卷积网络,因此输入给卷积网络的只有红色方框内的区域,再次运行卷积网络,然后处理第三个图像,依次重复操作,直到这个窗口滑过图像的每一个角落。
为了滑动得更快,我这里选用的步幅比较大,思路是以固定步幅移动窗口,遍历图像的每个区域,把这些剪切后的小图像输入卷积网络,对每个位置按0或1进行分类,这就是所谓的图像滑动窗口操作。

重复上述操作,不过这次我们选择一个更大的窗口,截取更大的区域,并输入给卷积神经网络处理,你可以根据卷积网络对输入大小调整这个区域,然后输入给卷积网络,输出0或1。

再以某个固定步幅滑动窗口,重复以上操作,遍历整个图像,输出结果。
然后第三次重复操作,这次选用更大的窗口。
如果你这样做,不论汽车在图片的什么位置,总有一个窗口可以检测到它。

比如,将这个窗口(编号1)输入卷积网络,希望卷积网络对该输入区域的输出结果为1,说明网络检测到图上有辆车。
这种算法叫作滑动窗口目标检测,因为我们以某个步幅滑动这些方框窗口遍历整张图片,对这些方形区域进行分类,判断里面有没有汽车。
滑动窗口目标检测算法也有很明显的缺点,就是计算成本,因为你在图片中剪切出太多小方块,卷积网络要一个个地处理。如果你选用的步幅很大,显然会减少输入卷积网络的窗口个数,但是粗糙间隔尺寸可能会影响性能。反之,如果采用小粒度或小步幅,传递给卷积网络的小窗口会特别多,这意味着超高的计算成本。
所以在神经网络兴起之前,人们通常采用更简单的分类器进行对象检测,比如通过采用手工处理工程特征的简单的线性分类器来执行对象检测。至于误差,因为每个分类器的计算成本都很低,它只是一个线性函数,所以滑动窗口目标检测算法表现良好,是个不错的算法。然而,卷积网络运行单个分类人物的成本却高得多,像这样滑动窗口太慢。除非采用超细粒度或极小步幅,否则无法准确定位图片中的对象。
4.滑动窗口的卷积实现
为了构建滑动窗口的卷积应用,首先要知道如何把神经网络的全连接层转化成卷积层。我们先讲解这部分内容,下一张幻灯片,我们将按照这个思路来演示卷积的应用过程。
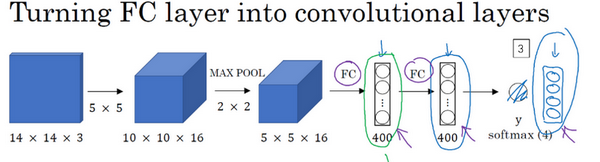
假设对象检测算法输入一个14×14×3的图像,图像很小,不过演示起来方便。在这里过滤器大小为5×5,数量是16,14×14×3的图像在过滤器处理之后映射为10×10×16。然后通过参数为2×2的最大池化操作,图像减小到5×5×16。然后添加一个连接400个单元的全连接层,接着再添加一个全连接层,最后通过softmax 单元输出y。为了跟下图区分开,我先做一点改动,用4个数字来表示y,它们分别对应softmax单元所输出的4个分类出现的概率。这4个分类可以是行人、汽车、摩托车和背景或其它对象。
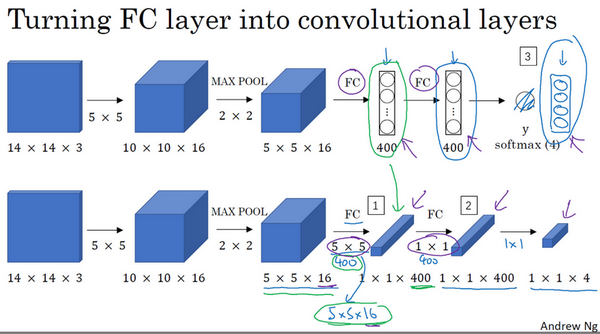
现在我要演示的就是如何把这些全连接层转化为卷积层,画一个这样的卷积网络,它的前几层和之前的一样,而对于下一层,也就是这个全连接层,我们可以用5×5的过滤器来实现,数量是400个(编号1所示),输入图像大小为5×5×16,用5×5的过滤器对它进行卷积操作,过滤器实际上是5×5×16,因为在卷积过程中,过滤器会遍历这16个通道,所以这两处的通道数量必须保持一致,输出结果为1×1。假设应用400个这样的5×5×16过滤器,输出维度就是1×1×400,我们不再把它看作一个含有400个节点的集合,而是一个1×1×400的输出层。从数学角度看,它和全连接层是一样的,因为这400个节点中每个节点都有一个5×5×16维度的过滤器,所以每个值都是上一层这些5×5×16激活值经过某个任意线性函数的输出结果。
我们再添加另外一个卷积层(编号2所示),这里用的是1×1卷积,假设有400个1×1的过滤器,在这400个过滤器的作用下,下一层的维度是1×1×400,它其实就是上个网络中的这一全连接层。最后经由1×1过滤器的处理,得到一个softmax激活值,通过卷积网络,我们最终得到这个1×1×4的输出层,而不是这4个数字(编号3所示)。
以上就是用卷积层代替全连接层的过程,结果这几个单元集变成了1×1×400和1×1×4的维度。
参考论文:Sermanet, Pierre, et al. "OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks." Eprint Arxiv (2013).
掌握了卷积知识,我们再看看如何通过卷积实现滑动窗口对象检测算法。讲义中的内容借鉴了屏幕下方这篇关于OverFeat 的论文,它的作者包括Pierre Sermanet ,David Eigen ,张翔 ,Michael Mathieu ,Rob Fergus ,Yann LeCun。

假设向滑动窗口卷积网络输入14×14×3的图片,为了简化演示和计算过程,这里我们依然用14×14的小图片。和前面一样,神经网络最后的输出层,即softmax单元的输出是1×1×4,我画得比较简单,严格来说,14×14×3应该是一个长方体,第二个10×10×16也是一个长方体,但为了方便,我只画了正面。所以,对于1×1×400的这个输出层,我也只画了它1×1的那一面,所以这里显示的都是平面图,而不是3D图像。
假设输入给卷积网络的图片大小是14×14×3,测试集图片是16×16×3,现在给这个输入图片加上黄色条块,在最初的滑动窗口算法中,你会把这片蓝色区域输入卷积网络(红色笔标记)生成0或1分类。接着滑动窗口,步幅为2个像素,向右滑动2个像素,将这个绿框区域输入给卷积网络,运行整个卷积网络,得到另外一个标签0或1。继续将这个橘色区域输入给卷积网络,卷积后得到另一个标签,最后对右下方的紫色区域进行最后一次卷积操作。我们在这个16×16×3的小图像上滑动窗口,卷积网络运行了4次,于是输出了了4个标签。
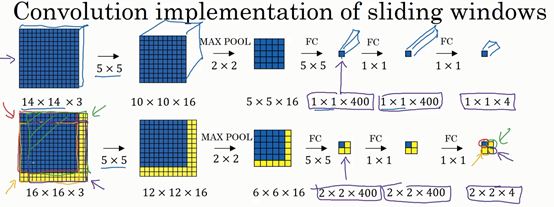
结果发现,这4次卷积操作中很多计算都是重复的。所以执行滑动窗口的卷积时使得卷积网络在这4次前向传播过程中共享很多计算,尤其是在这一步操作中(编号1),卷积网络运行同样的参数,使得相同的5×5×16过滤器进行卷积操作,得到12×12×16的输出层。然后执行同样的最大池化(编号2),输出结果6×6×16。照旧应用400个5×5的过滤器(编号3),得到一个2×2×400的输出层,现在输出层为2×2×400,而不是1×1×400。应用1×1过滤器(编号4)得到另一个2×2×400的输出层。再做一次全连接的操作(编号5),最终得到2×2×4的输出层,而不是1×1×4。最终,在输出层这4个子方块中,蓝色的是图像左上部分14×14的输出(红色箭头标识),右上角方块是图像右上部分(绿色箭头标识)的对应输出,左下角方块是输入层左下角(橘色箭头标识),也就是这个14×14区域经过卷积网络处理后的结果,同样,右下角这个方块是卷积网络处理输入层右下角14×14区域(紫色箭头标识)的结果。
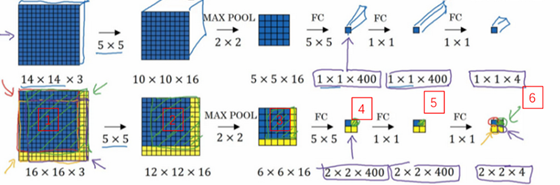
如果你想了解具体的计算步骤,以绿色方块为例,假设你剪切出这块区域(编号1),传递给卷积网络,第一层的激活值就是这块区域(编号2),最大池化后的下一层的激活值是这块区域(编号3),这块区域对应着后面几层输出的右上角方块(编号4,5,6)。
所以该卷积操作的原理是我们不需要把输入图像分割成四个子集,分别执行前向传播,而是把它们作为一张图片输入给卷积网络进行计算,其中的公共区域可以共享很多计算,就像这里我们看到的这个4个14×14的方块一样。
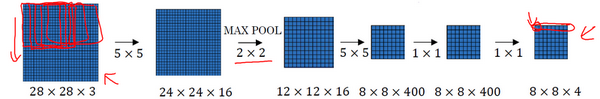
下面我们再看一个更大的图片样本,假如对一个28×28×3的图片应用滑动窗口操作,如果以同样的方式运行前向传播,最后得到8×8×4的结果。跟上一个范例一样,以14×14区域滑动窗口,首先在这个区域应用滑动窗口,其结果对应输出层的左上角部分。接着以大小为2的步幅不断地向右移动窗口,直到第8个单元格,得到输出层的第一行。然后向图片下方移动,最终输出这个8×8×4的结果。因为最大池化参数为2,相当于以大小为2的步幅在原始图片上应用神经网络。


总结一下滑动窗口的实现过程,在图片上剪切出一块区域,假设它的大小是14×14,把它输入到卷积网络。继续输入下一块区域,大小同样是14×14,重复操作,直到某个区域识别到汽车。
但是正如在前一页所看到的,我们不能依靠连续的卷积操作来识别图片中的汽车,比如,我们可以对大小为28×28的整张图片进行卷积操作,一次得到所有预测值,如果足够幸运,神经网络便可以识别出汽车的位置。
5.边界框预测
1.图像预处理
- 统一缩放到固定尺寸(如 640×640、416×416)
- 归一化、转张量、送入网络
2.网格划分(最关键)
把整张图均匀分成 S×S 个网格
- 物体中心落在哪个网格 ,就由这个网格负责预测该物体
3.每个网格预测内容
每个网格输出:
- B 个边界框(x,y,w,h)
- 框置信度:有无物体 + 框准不准
- C 个类别概率:属于哪一类
4.网络前向推理
骨干网络提取特征 → 多尺度特征融合 →
直接回归出所有框坐标、置信度、类别
5.后处理(筛框)
- 置信度筛选:删掉低分框
- 非极大值抑制 NMS
同一物体多个重叠框,只留分数最高那个
- 最终输出:目标类别 + 矩形框位置
6.前向传播与反向传播在卷积中的作用
一、卷积层前向传播(正向算结果)
- 作用
输入图像 → 逐层卷积、池化、激活 → 算出预测值 ,得到损失
-
流程
-
输入特征图 x
-
卷积核 w 滑动窗口做加权求和
z = x * w + b
-
过激活函数(ReLU/Sigmoid)a=\sigma(z)
-
池化下采样缩小尺寸
-
层层传到最后一层,输出预测类别
-
计算损失函数(交叉熵 / MSE)
-
核心特点
- 权值共享:整张图共用同一组卷积核
- 滑动窗口逐区域计算局部特征
二、卷积层反向传播(反向更新权重)
- 作用
从损失 loss 往回倒推,求每个卷积核权重、偏置的梯度 ,用梯度下降更新参数
-
三大反向过程
-
损失向后传梯度
从输出层开始,逐层把误差传回卷积层
-
池化层反向
- 最大池化:误差只传回最大值位置
- 平均池化:误差均分回原窗口
- 卷积层反向(最重点)
- 求偏置 b 梯度:所有位置误差直接求和
- 求卷积核 w 梯度:用误差图与输入特征图做卷积
- 求输入特征梯度:误差图翻转卷积核再卷积
-
参数更新
w = w - \eta \cdot \nabla w
b = b - \eta \cdot \nabla b
\eta 学习率
-
三、整体在 CNN 里完整运用流程
- 前向传播 图片输入 → 卷积提取特征 → 激活 → 池化 → 全连接 → 输出预测 → 计算 loss
- 判断是否收敛 loss 大 → 继续训练;loss 小 → 停止
- 反向传播 loss 反向回传 → 逐层算出卷积核、全连接权重梯度 → 更新所有卷积核权重
- 反复循环:前向算损失 → 反向更权重,直到模型收敛
7.交并比
你如何判断对象检测算法运作良好呢?在本视频中,你将了解到并交比函数,可以用来评价对象检测算法。在下一个视频中,我们用它来插入一个分量来进一步改善检测算法,我们开始吧。

在对象检测任务中,你希望能够同时定位对象,所以如果实际边界框是这样的,你的算法给出这个紫色的边界框,那么这个结果是好还是坏?所以交并比(loU)函数做的是计算两个边界框交集和并集之比。两个边界框的并集是这个区域,就是属于包含两个边界框区域(绿色阴影表示区域),而交集就是这个比较小的区域(橙色阴影表示区域),那么交并比就是交集的大小,这个橙色阴影面积,然后除以绿色阴影的并集面积。
一般约定,在计算机检测任务中,如果loU≥0.5,就说检测正确,如果预测器和实际边界框完美重叠,loU 就是1,因为交集就等于并集。但一般来说只要loU≥0.5,那么结果是可以接受的,看起来还可以。一般约定,0.5是阈值,用来判断预测的边界框是否正确。一般是这么约定,但如果你希望更严格一点,你可以将loU 定得更高,比如说大于0.6或者更大的数字,但loU越高,边界框越精确。
所以这是衡量定位精确度的一种方式,你只需要统计算法正确检测和定位对象的次数,你就可以用这样的定义判断对象定位是否准确。再次,0.5是人为约定,没有特别深的理论依据,如果你想更严格一点,可以把阈值定为0.6。有时我看到更严格的标准,比如0.6甚至0.7,但很少见到有人将阈值降到0.5以下。
人们定义loU 这个概念是为了评价你的对象定位算法是否精准,但更一般地说,loU衡量了两个边界框重叠地相对大小。如果你有两个边界框,你可以计算交集,计算并集,然后求两个数值的比值,所以这也可以判断两个边界框是否相似,我们将在下一个视频中再次用到这个函数,当我们讨论非最大值抑制时再次用到。
好,这就是loU ,或者说交并比,不要和借据中提到的我欠你钱的这个概念所混淆,如果你借钱给别人,他们会写给你一个借据,说:"我欠你这么多钱(I own you this much money )。",这也叫做loU。这是完全不同的概念,这两个概念重名。
现在介绍了loU 交并比的定义之后,在下一个视频中,我想讨论非最大值抑制,这个工具可以让YOLO算法输出效果更好,我们下一个视频继续。
8.非极大值抑制
到目前为止你们学到的对象检测中的一个问题是,你的算法可能对同一个对象做出多次检测,所以算法不是对某个对象检测出一次,而是检测出多次。非极大值抑制这个方法可以确保你的算法对每个对象只检测一次,我们讲一个例子。

假设你需要在这张图片里检测行人和汽车,你可能会在上面放个19×19网格,理论上这辆车只有一个中点,所以它应该只被分配到一个格子里,左边的车子也只有一个中点,所以理论上应该只有一个格子做出有车的预测。

实践中当你运行对象分类和定位算法时,对于每个格子都运行一次,所以这个格子(编号1)可能会认为这辆车中点应该在格子内部,这几个格子(编号2、3)也会这么认为。对于左边的车子也一样,所以不仅仅是这个格子,如果这是你们以前见过的图像,不仅这个格(编号4)子会认为它里面有车,也许这个格子(编号5)和这个格子(编号6)也会,也许其他格子也会这么认为,觉得它们格子内有车。
我们分步介绍一下非极大抑制是怎么起效的,因为你要在361个格子上都运行一次图像检测和定位算法,那么可能很多格子都会举手说我的p_{c},我这个格子里有车的概率很高,而不是361个格子中仅有两个格子会报告它们检测出一个对象。所以当你运行算法的时候,最后可能会对同一个对象做出多次检测,所以非极大值抑制做的就是清理这些检测结果。这样一辆车只检测一次,而不是每辆车都触发多次检测。
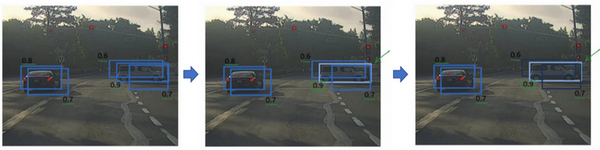
所以具体上,这个算法做的是,首先看看每次报告每个检测结果相关的概率p_{c},在本周的编程练习中有更多细节,实际上是p_{c}乘以c_{1}、c_{2}或c_{3}。现在我们就说,这个p_{c}检测概率,首先看概率最大的那个,这个例子(右边车辆)中是0.9,然后就说这是最可靠的检测,所以我们就用高亮标记,就说我这里找到了一辆车。这么做之后,非极大值抑制就会逐一审视剩下的矩形,所有和这个最大的边框有很高交并比,高度重叠的其他边界框,那么这些输出就会被抑制。所以这两个矩形p_{c}分别是0.6和0.7,这两个矩形和淡蓝色矩形重叠程度很高,所以会被抑制,变暗,表示它们被抑制了。
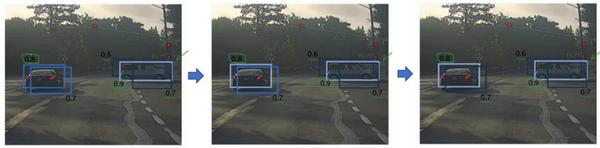
接下来,逐一审视剩下的矩形,找出概率最高,p_{c}最高的一个,在这种情况下是0.8,我们就认为这里检测出一辆车(左边车辆),然后非极大值抑制算法就会去掉其他loU值很高的矩形。所以现在每个矩形都会被高亮显示或者变暗,如果你直接抛弃变暗的矩形,那就剩下高亮显示的那些,这就是最后得到的两个预测结果。
所以这就是非极大值抑制,非最大值意味着你只输出概率最大的分类结果,但抑制很接近,但不是最大的其他预测结果,所以这方法叫做非极大值抑制。
我们来看看算法的细节,首先这个19×19网格上执行一下算法,你会得到19×19×8的输出尺寸。不过对于这个例子来说,我们简化一下,就说你只做汽车检测,我们就去掉c_{1}、c_{2}和c_{3},然后假设这条线对于19×19的每一个输出,对于361个格子的每个输出,你会得到这样的输出预测,就是格子中有对象的概率(p_{c}),然后是边界框参数(b_{x}、b_{y}、b_{h}和b_{w})。如果你只检测一种对象,那么就没有c_{1}、c_{2}和c_{3}这些预测分量。多个对象处于同一个格子中的情况,我会放到编程练习中,你们可以在本周末之前做做。

现在要实现非极大值抑制,你可以做的第一件事是,去掉所有边界框,我们就将所有的预测值,所有的边界框p_{c}小于或等于某个阈值,比如p_{c}≤0.6的边界框去掉。
我们就这样说,除非算法认为这里存在对象的概率至少有0.6,否则就抛弃,所以这就抛弃了所有概率比较低的输出边界框。所以思路是对于这361个位置,你输出一个边界框,还有那个最好边界框所对应的概率,所以我们只是抛弃所有低概率的边界框。

接下来剩下的边界框,没有抛弃没有处理过的,你就一直选择概率p_{c}最高的边界框,然后把它输出成预测结果,这个过程就是上一张幻灯片,取一个边界框,让它高亮显示,这样你就可以确定输出做出有一辆车的预测。

接下来去掉所有剩下的边界框,任何没有达到输出标准的边界框,之前没有抛弃的边界框,把这些和输出边界框有高重叠面积和上一步输出边界框有很高交并比的边界框全部抛弃。所以while循环的第二步是上一张幻灯片变暗的那些边界框,和高亮标记的边界重叠面积很高的那些边界框抛弃掉。在还有剩下边界框的时候,一直这么做,把没处理的都处理完,直到每个边界框都判断过了,它们有的作为输出结果,剩下的会被抛弃,它们和输出结果重叠面积太高,和输出结果交并比太高,和你刚刚输出这里存在对象结果的重叠程度过高。
在这张幻灯片中,我只介绍了算法检测单个对象的情况,如果你尝试同时检测三个对象,比如说行人、汽车、摩托,那么输出向量就会有三个额外的分量。事实证明,正确的做法是独立进行三次非极大值抑制,对每个输出类别都做一次,但这个细节就留给本周的编程练习吧,其中你可以自己尝试实现,我们可以自己试试在多个对象类别检测时做非极大值抑制。
9. 锚框(Anchor Boxes)
到目前为止,对象检测中存在的一个问题是每个格子只能检测出一个对象,如果你想让一个格子检测出多个对象,你可以这么做,就是使用anchor box这个概念,我们从一个例子开始讲吧。
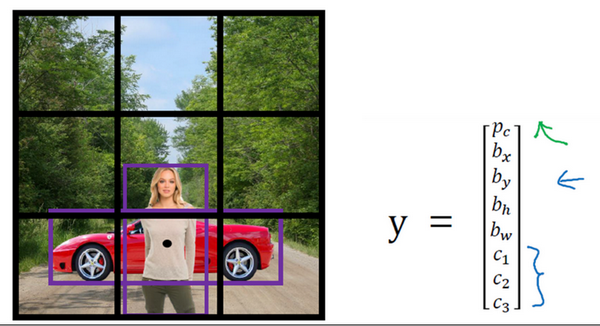
假设你有这样一张图片,对于这个例子,我们继续使用3×3网格,注意行人的中点和汽车的中点几乎在同一个地方,两者都落入到同一个格子中。所以对于那个格子,如果 y 输出这个向量y= \ \begin{bmatrix} p_{c} \\ b_{x} \\ b_{y} \\ b_{h} \\ b_{w} \\ c_{1} \\ c_{2}\\ c_{3} \\\end{bmatrix},你可以检测这三个类别,行人、汽车和摩托车,它将无法输出检测结果,所以我必须从两个检测结果中选一个。
而anchor box 的思路是,这样子,预先定义两个不同形状的anchor box ,或者anchor box 形状,你要做的是把预测结果和这两个anchor box 关联起来。一般来说,你可能会用更多的anchor box ,可能要5个甚至更多,但对于这个视频,我们就用两个anchor box,这样介绍起来简单一些。
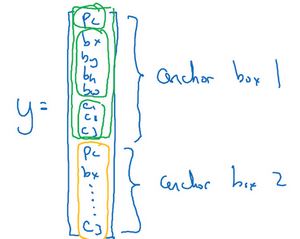
你要做的是定义类别标签,用的向量不再是上面这个\begin{bmatrix} p_{c} & b_{x} &b_{y} & b_{h} & b_{w} & c_{1} & c_{2} & c_{3} \\\end{bmatrix}^{T},而是重复两次,y= \begin{bmatrix} p_{c} & b_{x} & b_{y} &b_{h} & b_{w} & c_{1} & c_{2} & c_{3} & p_{c} & b_{x} & b_{y} & b_{h} & b_{w} &c_{1} & c_{2} & c_{3} \\\end{bmatrix}^{T},前面的p_{c},b_{x},b_{y},b_{h},b_{w},c_{1},c_{2},c_{3}(绿色方框标记的参数)是和anchor box 1 关联的8个参数,后面的8个参数(橙色方框标记的元素)是和anchor box 2 相关联。因为行人的形状更类似于anchor box 1 的形状,而不是anchor box 2的形状,所以你可以用这8个数值(前8个参数),这么编码p_{c} =1,是的,代表有个行人,用b_{x},b_{y},b_{h}和b_{w}来编码包住行人的边界框,然后用c_{1},c_{2},c_{3}(c_{1}= 1,c_{2} = 0,c_{3} = 0)来说明这个对象是个行人。
然后是车子,因为车子的边界框比起anchor box 1 更像anchor box 2的形状,你就可以这么编码,这里第二个对象是汽车,然后有这样的边界框等等,这里所有参数都和检测汽车相关(p_{c}= 1,b_{x},b_{y},b_{h},b_{w},c_{1} = 0,c_{2} = 1,c_{3} = 0)。

总结一下,用anchor box之前,你做的是这个,对于训练集图像中的每个对象,都根据那个对象中点位置分配到对应的格子中,所以输出y就是3×3×8,因为是3×3网格,对于每个网格位置,我们有输出向量,包含p_{c},然后边界框参数b_{x},b_{y},b_{h}和b_{w},然后c_{1},c_{2},c_{3}。
现在用到anchor box 这个概念,是这么做的。现在每个对象都和之前一样分配到同一个格子中,分配到对象中点所在的格子中,以及分配到和对象形状交并比最高的anchor box 中。所以这里有两个anchor box ,你就取这个对象,如果你的对象形状是这样的(编号1,红色框),你就看看这两个anchor box ,anchor box 1 形状是这样(编号2,紫色框),anchor box 2 形状是这样(编号3,紫色框),然后你观察哪一个anchor box 和实际边界框(编号1,红色框)的交并比更高,不管选的是哪一个,这个对象不只分配到一个格子,而是分配到一对,即(grid cell,anchor box )对,这就是对象在目标标签中的编码方式。所以现在输出 y 就是3×3×16,上一张幻灯片中你们看到 y 现在是16维的,或者你也可以看成是3×3×2×8,因为现在这里有2个anchor box,而 y 是8维的。y 维度是8,因为我们有3个对象类别,如果你有更多对象,那么y 的维度会更高。
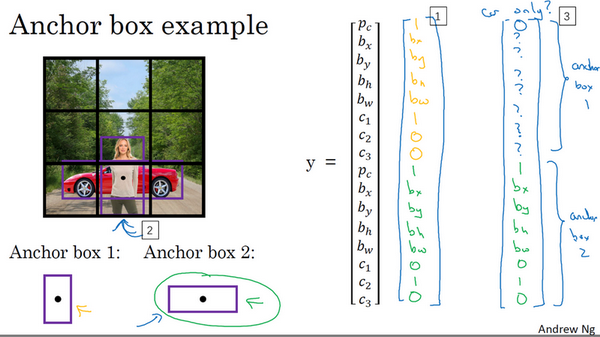
所以我们来看一个具体的例子,对于这个格子(编号2),我们定义一下y:
y =\begin{bmatrix} p_{c} & b_{x} & b_{y} & b_{h} & b_{w} & c_{1} & c_{2} & c_{3} &p_{c} & b_{x} & b_{y} & b_{h} & b_{w} & c_{1} & c_{2} & c_{3} \\\end{bmatrix}^{T}。
所以行人更类似于anchor box 1 的形状,所以对于行人来说,我们将她分配到向量的上半部分。是的,这里存在一个对象,即p_{c}= 1,有一个边界框包住行人,如果行人是类别1,那么 c_{1} = 1,c_{2} = 0,c_{3} =0(编号1所示的橙色参数)。车子的形状更像anchor box 2,所以这个向量剩下的部分是 p_{c} = 1,然后和车相关的边界框,然后c_{1} = 0,c_{2} = 1,c_{3} =0(编号1所示的绿色参数)。所以这就是对应中下格子的标签 y,这个箭头指向的格子(编号2所示)。
现在其中一个格子有车,没有行人,如果它里面只有一辆车,那么假设车子的边界框形状是这样,更像anchor
box 2 ,如果这里只有一辆车,行人走开了,那么anchor box 2 分量还是一样的,要记住这是向量对应anchor box 2 的分量和anchor box 1 对应的向量分量,你要填的就是,里面没有任何对象,所以 p_{c} =0,然后剩下的就是don't care-s(即?)(编号3所示)。
现在还有一些额外的细节,如果你有两个anchor box,但在同一个格子中有三个对象,这种情况算法处理不好,你希望这种情况不会发生,但如果真的发生了,这个算法并没有很好的处理办法,对于这种情况,我们就引入一些打破僵局的默认手段。还有这种情况,两个对象都分配到一个格子中,而且它们的anchor box形状也一样,这是算法处理不好的另一种情况,你需要引入一些打破僵局的默认手段,专门处理这种情况,希望你的数据集里不会出现这种情况,其实出现的情况不多,所以对性能的影响应该不会很大。
这就是anchor box 的概念,我们建立anchor box 这个概念,是为了处理两个对象出现在同一个格子的情况,实践中这种情况很少发生,特别是如果你用的是19×19网格而不是3×3的网格,两个对象中点处于361个格子中同一个格子的概率很低,确实会出现,但出现频率不高。也许设立anchor box 的好处在于anchor box能让你的学习算法能够更有征对性,特别是如果你的数据集有一些很高很瘦的对象,比如说行人,还有像汽车这样很宽的对象,这样你的算法就能更有针对性的处理,这样有一些输出单元可以针对检测很宽很胖的对象,比如说车子,然后输出一些单元,可以针对检测很高很瘦的对象,比如说行人。
最后,你应该怎么选择anchor box 呢?人们一般手工指定anchor box 形状,你可以选择5到10个anchor box 形状,覆盖到多种不同的形状,可以涵盖你想要检测的对象的各种形状。还有一个更高级的版本,我就简单说一句,你们如果接触过一些机器学习,可能知道后期YOLO 论文中有更好的做法,就是所谓的k-平均算法 ,可以将两类对象形状聚类,如果我们用它来选择一组anchor box ,选择最具有代表性的一组anchor box ,可以代表你试图检测的十几个对象类别,但这其实是自动选择anchor box的高级方法。如果你就人工选择一些形状,合理的考虑到所有对象的形状,你预计会检测的很高很瘦或者很宽很胖的对象,这应该也不难做。
10.YOLO
Week4:语义分割(Semantic segmentation)
1.U-Net语义分割
2.转置卷积
Week5:人脸识别(Face recognition)
1.孪生网络
上个视频中你学到的函数d的作用就是输入两张人脸,然后告诉你它们的相似度。实现这个功能的一个方式就是用Siamese网络,我们看一下。
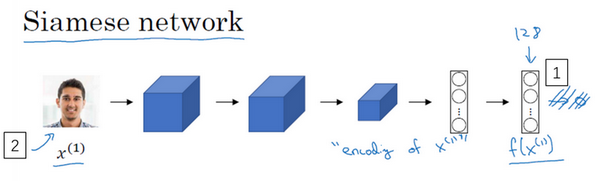
你经常看到这样的卷积网络,输入图片x^{(1)},然后通过一些列卷积,池化和全连接层,最终得到这样的特征向量(编号1)。有时这个会被送进softmax 单元来做分类,但在这个视频里我们不会这么做。我们关注的重点是这个向量(编号1),假如它有128个数,它是由网络深层的全连接层计算出来的,我要给这128个数命个名字,把它叫做f(x^{(1)})。你可以把f(x^{(1)})看作是输入图像x^{(1)}的编码,取这个输入图像(编号2),在这里是Kian的图片,然后表示成128维的向量。
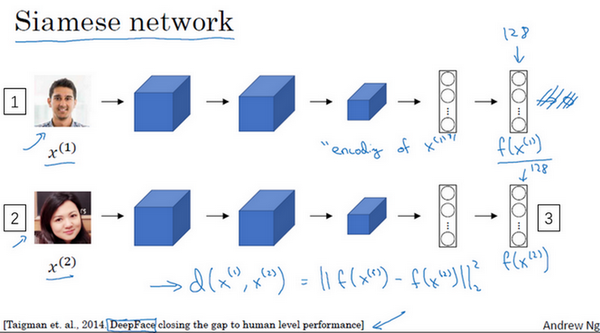
建立一个人脸识别系统的方法就是,如果你要比较两个图片的话,例如这里的第一张(编号1)和第二张图片(编号2),你要做的就是把第二张图片喂给有同样参数的同样的神经网络,然后得到一个不同的128维的向量(编号3),这个向量代表或者编码第二个图片,我要把第二张图片的编码叫做f(x^{(2)})。这里我用x^{(1)}和x^{(2)}仅仅代表两个输入图片,他们没必要非是第一个和第二个训练样本,可以是任意两个图片。
最后如果你相信这些编码很好地代表了这两个图片,你要做的就是定义d,将x^{(1)}和x^{(2)}的距离定义为这两幅图片的编码之差的范数,d( x^{( 1)},x^{( 2)}) =|| f( x^{( 1)}) - f( x^{( 2)})||_{2}^{2}。
对于两个不同的输入,运行相同的卷积神经网络,然后比较它们,这一般叫做Siamese 网络架构。这里提到的很多观点,都来自于Yaniv Taigman ,Ming Yang ,Marc' Aurelio Ranzato ,Lior Wolf 的这篇论文,他们开发的系统叫做DeepFace。
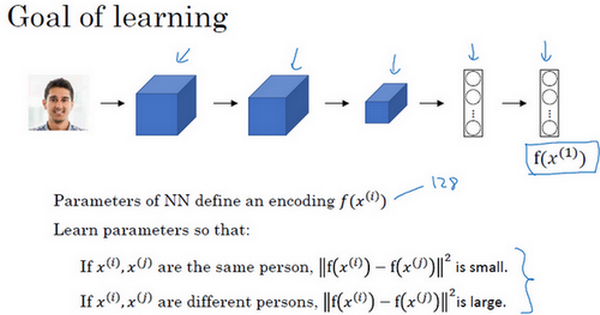
怎么训练这个Siamese神经网络呢?不要忘了这两个网络有相同的参数,所以你实际要做的就是训练一个网络,它计算得到的编码可以用于函数d,它可以告诉你两张图片是否是同一个人。更准确地说,神经网络的参数定义了一个编码函数f(x^{(i)}),如果给定输入图像x^{(i)},这个网络会输出x^{(i)}的128维的编码。你要做的就是学习参数,使得如果两个图片x^{( i)}和x^{( j)}是同一个人,那么你得到的两个编码的距离就小。前面几个幻灯片我都用的是x^{(1)}和x^{( 2)},其实训练集里任意一对x^{(i)}和x^{(j)}都可以。相反,如果x^{(i)}和x^{(j)}是不同的人,那么你会想让它们之间的编码距离大一点。
如果你改变这个网络所有层的参数,你会得到不同的编码结果,你要做的就是用反向传播来改变这些所有的参数,以确保满足这些条件。
你已经了解了Siamese网络架构,并且知道你想要网络输出什么,即什么是好的编码。但是如何定义实际的目标函数,能够让你的神经网络学习并做到我们刚才讨论的内容呢?在下一个视频里,我们会看到如何用三元组损失函数达到这个目的。
2. 三元组损失
要想通过学习神经网络的参数来得到优质的人脸图片编码,方法之一就是定义三元组损失函数然后应用梯度下降。

我们看下这是什么意思,为了应用三元组损失函数,你需要比较成对的图像,比如这个图片,为了学习网络的参数,你需要同时看几幅图片,比如这对图片(编号1和编号2),你想要它们的编码相似,因为这是同一个人。然而假如是这对图片(编号3和编号4),你会想要它们的编码差异大一些,因为这是不同的人。
用三元组损失的术语来说,你要做的通常是看一个 Anchor 图片,你想让Anchor 图片和Positive 图片(Positive 意味着是同一个人)的距离很接近。然而,当Anchor 图片与Negative 图片(Negative意味着是非同一个人)对比时,你会想让他们的距离离得更远一点。

这就是为什么叫做三元组损失,它代表你通常会同时看三张图片,你需要看Anchor 图片、Postive 图片,还有Negative 图片,我要把Anchor 图片、Positive 图片和Negative图片简写成A、P、N。
把这些写成公式的话,你想要的是网络的参数或者编码能够满足以下特性,也就是说你想要|| f(A) - f(P) ||^{2},你希望这个数值很小,准确地说,你想让它小于等f(A)和f(N)之间的距离,或者说是它们的范数的平方(即:|| f(A) - f(P)||^{2} \leq ||f(A) - f(N)||^{2})。(|| f(A) - f(P) ||^{2})当然这就是d(A,P),(|| f(A) - f(N) ||^{2})这是d(A,N),你可以把d 看作是距离(distance)函数,这也是为什么我们把它命名为d。
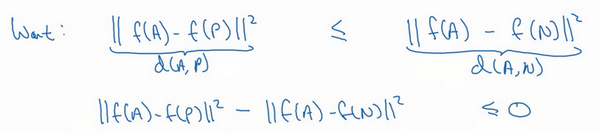
现在如果我把方程右边项移到左边,最终就得到:
|| f(A) - f(P)||^{2} \leq ||f(A) - f(N)||^{2}
现在我要对这个表达式做一些小的改变,有一种情况满足这个表达式,但是没有用处,就是把所有的东西都学成0,如果f总是输出0,即0-0≤0,这就是0减去0还等于0,如果所有图像的f都是一个零向量,那么总能满足这个方程。所以为了确保网络对于所有的编码不会总是输出0,也为了确保它不会把所有的编码都设成互相相等的。另一种方法能让网络得到这种没用的输出,就是如果每个图片的编码和其他图片一样,这种情况,你还是得到0-0。
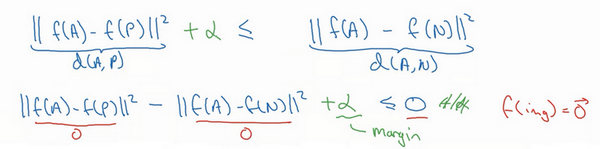
为了阻止网络出现这种情况,我们需要修改这个目标,也就是,这个不能是刚好小于等于0,应该是比0还要小,所以这个应该小于一个-a值(即|| f(A) - f(P)||^{2} -||f(A) - f(N)||^{2} \leq -a),这里的a是另一个超参数,这个就可以阻止网络输出无用的结果。按照惯例,我们习惯写+a(即|| f(A) - f(P)||^{2} -||f(A) - f(N)||^{2} +a\leq0),而不是把-a写在后面,它也叫做间隔(margin ),这个术语你会很熟悉,如果你看过关于支持向量机 (SVM)的文献,没看过也不用担心。我们可以把上面这个方程(|| f(A) - f(P)||^{2} -||f(A) - f(N)||^{2})也修改一下,加上这个间隔参数。haox
举个例子,假如间隔设置成0.2,如果在这个例子中,d(A,P) =0.5,如果 Anchor 和 Negative 图片的d,即d(A,N)只大一点,比如说0.51,条件就不能满足。虽然0.51也是大于0.5的,但还是不够好,我们想要d(A,N)比d(A,P)大很多,你会想让这个值(d(A,N))至少是0.7或者更高,或者为了使这个间隔,或者间距至少达到0.2,你可以把这项调大或者这个调小,这样这个间隔a,超参数a 至少是0.2,在d(A,P)和d(A,N)之间至少相差0.2,这就是间隔参数a的作用。它拉大了Anchor 和Positive 图片对和Anchor 与Negative 图片对之间的差距。取下面的这个方框圈起来的方程式,在下个幻灯片里,我们会更公式化表示,然后定义三元组损失函数。

三元组损失函数的定义基于三张图片,假如三张图片A、P、N,即Anchor 样本、Positive 样本和Negative 样本,其中Positive 图片和Anchor 图片是同一个人,但是Negative 图片和Anchor不是同一个人。
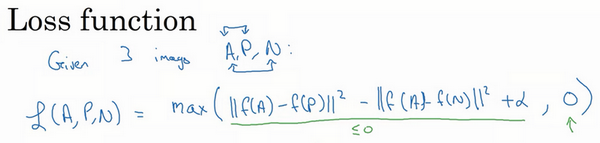
接下来我们定义损失函数,这个例子的损失函数,它的定义基于三元图片组,我先从前一张幻灯片复制过来一些式子,就是|| f( A) - f( P)||^{2} -||f( A) - f( N)||^{2} +a \leq0。所以为了定义这个损失函数,我们取这个和0的最大值:
L( A,P,N) = max(|| f( A) - f( P)||^{2} -|| f( A) - f( N)||^{2} + a,0)
这个max函数的作用就是,只要这个|| f( A) - f( P)||^{2} -|| f( A) - f( N)||^{2} + a\leq0,那么损失函数就是0。只要你能使画绿色下划线部分小于等于0,只要你能达到这个目标,那么这个例子的损失就是0。
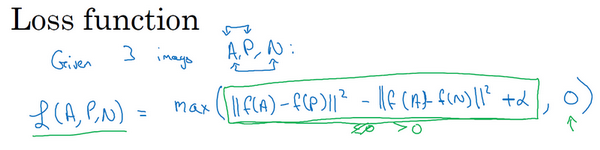
另一方面如果这个|| f( A) - f( P)||^{2} -|| f( A) - f( N)||^{2} + a\leq0,然后你取它们的最大值,最终你会得到绿色下划线部分(即|| f(A) - f( P)||^{2} -|| f( A) - f( N)||^{2} +a)是最大值,这样你会得到一个正的损失值。通过最小化这个损失函数达到的效果就是使这部分|| f( A) - f( P)||^{2} -||f( A) - f( N)||^{2} +a成为0,或者小于等于0。只要这个损失函数小于等于0,网络不会关心它负值有多大。
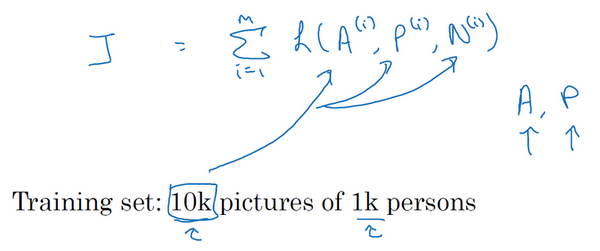
这是一个三元组定义的损失,整个网络的代价函数应该是训练集中这些单个三元组损失的总和。假如你有一个10000个图片的训练集,里面是1000个不同的人的照片,你要做的就是取这10000个图片,然后生成这样的三元组,然后训练你的学习算法,对这种代价函数用梯度下降,这个代价函数就是定义在你数据集里的这样的三元组图片上。
注意,为了定义三元组的数据集你需要成对的A和P,即同一个人的成对的图片,为了训练你的系统你确实需要一个数据集,里面有同一个人的多个照片。这是为什么在这个例子中,我说假设你有1000个不同的人的10000张照片,也许是这1000个人平均每个人10张照片,组成了你整个数据集。如果你只有每个人一张照片,那么根本没法训练这个系统。当然,训练完这个系统之后,你可以应用到你的一次学习问题上,对于你的人脸识别系统,可能你只有想要识别的某个人的一张照片。但对于训练集,你需要确保有同一个人的多个图片,至少是你训练集里的一部分人,这样就有成对的Anchor 和Positive图片了。

现在我们来看,你如何选择这些三元组来形成训练集。一个问题是如果你从训练集中,随机地选择A、P和N,遵守A和P是同一个人,而A和N是不同的人这一原则。有个问题就是,如果随机的选择它们,那么这个约束条件(d(A,P) + a \leq d(A,N))很容易达到,因为随机选择的图片,A和N比A和P差别很大的概率很大。我希望你还记得这个符号d(A,P)就是前几个幻灯片里写的|| f(A) - f(P)||^{2},d(A,N)就是||f(A) -f(N)||^{2},d(A,P) + a \leq d(A,N)即|| f( A) - f( P)||^{2} + a \leq|| f(A) - f( N)||^{2}。但是如果A和N是随机选择的不同的人,有很大的可能性||f(A) - f(N)||^{2}会比左边这项||f( A) - f(P)||^{2}大,而且差距远大于a,这样网络并不能从中学到什么。
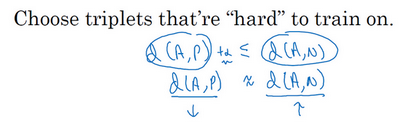
所以为了构建一个数据集,你要做的就是尽可能选择难训练的三元组A、P和N。具体而言,你想要所有的三元组都满足这个条件(d(A,P) + a \leq d(A,N)),难训练的三元组就是,你的A、P和N的选择使得d(A,P)很接近d(A,N),即d(A,P) \approx d(A,N),这样你的学习算法会竭尽全力使右边这个式子变大(d(A,N)),或者使左边这个式子(d(A,P))变小,这样左右两边至少有一个a的间隔。并且选择这样的三元组还可以增加你的学习算法的计算效率,如果随机的选择这些三元组,其中有太多会很简单,梯度算法不会有什么效果,因为网络总是很轻松就能得到正确的结果,只有选择难的三元组梯度下降法才能发挥作用,使得这两边离得尽可能远。
如果你对此感兴趣的话,这篇论文中有更多细节,作者是Florian Schroff , Dmitry Kalenichenko , James Philbin ,他们建立了这个叫做FaceNet的系统,我视频里许多的观点都是来自于他们的工作。
• Florian Schroff, Dmitry Kalenichenko, James Philbin (2015). FaceNet: A Unified Embedding forFace Recognition and Clustering
顺便说一下,这有一个有趣的事实,关于在深度学习领域,算法是如何命名的。如果你研究一个特定的领域,假如说"某某"领域,通常会将系统命名为"某某"网络或者深度"某某",我们一直讨论人脸识别,所以这篇论文叫做FaceNet (人脸网络),上个视频里你看到过DeepFace(深度人脸)。"某某"网络或者深度"某某",是深度学习领域流行的命名算法的方式,你可以看一下这篇论文,如果你想要了解更多的关于通过选择最有用的三元组训练来加速算法的细节,这是一个很棒的论文。
总结一下,训练这个三元组损失你需要取你的训练集,然后把它做成很多三元组,这就是一个三元组(编号1),有一个Anchor 图片和Positive 图片,这两个(Anchor 和Positive )是同一个人,还有一张另一个人的Negative 图片。这是另一组(编号2),其中Anchor 和Positive 图片是同一个人,但是Anchor 和Negative不是同一个人,等等。

定义了这些包括A、P和N图片的数据集之后,你还需要做的就是用梯度下降最小化我们之前定义的代价函数J,这样做的效果就是反向传播到网络中的所有参数来学习到一种编码,使得如果两个图片是同一个人,那么它们的d就会很小,如果两个图片不是同一个人,它们的d 就会很大。
这就是三元组损失,并且如何用它来训练网络输出一个好的编码用于人脸识别。现在的人脸识别系统,尤其是大规模的商业人脸识别系统都是在很大的数据集上训练,超过百万图片的数据集并不罕见,一些公司用千万级的图片,还有一些用上亿的图片来训练这些系统。这些是很大的数据集,即使按照现在的标准,这些数据集并不容易获得。幸运的是,一些公司已经训练了这些大型的网络并且上传了模型参数。所以相比于从头训练这些网络,在这一领域,由于这些数据集太大,这一领域的一个实用操作就是下载别人的预训练模型,而不是一切都要从头开始。但是即使你下载了别人的预训练模型,我认为了解怎么训练这些算法也是有用的,以防针对一些应用你需要从头实现这些想法。
3.人脸验证与二分类
Triplet loss是一个学习人脸识别卷积网络参数的好方法,还有其他学习参数的方法,让我们看看如何将人脸识别当成一个二分类问题。
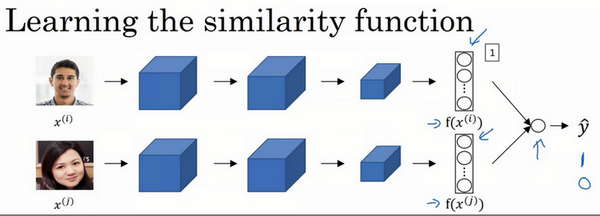
另一个训练神经网络的方法是选取一对神经网络,选取Siamese 网络,使其同时计算这些嵌入,比如说128维的嵌入(编号1),或者更高维,然后将其输入到逻辑回归单元,然后进行预测,如果是相同的人,那么输出是1,若是不同的人,输出是0。这就把人脸识别问题转换为一个二分类问题,训练这种系统时可以替换Triplet loss的方法。
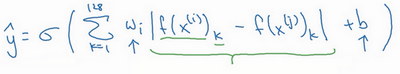
最后的逻辑回归单元是怎么处理的?输出\hat y会变成,比如说sigmoid函数应用到某些特征上,相比起直接放入这些编码(f(x^{(i)}),f( x^{(j)})),你可以利用编码之间的不同。
\hat y = \sigma(\sum_{k = 1}^{128}{w_{i}| f( x^{( i)}){k} - f( x^{( j)}){k}| + b})
我解释一下,符号f( x^{( i)}){k}代表图片x^{(i)}的编码,下标k代表选择这个向量中的第k个元素,| f(x^{( i)}){k} - f( x^{( j)}){k}|对这两个编码取元素差的绝对值。你可能想,把这128个元素当作特征,然后把他们放入逻辑回归中,最后的逻辑回归可以增加参数w{i}和b,就像普通的逻辑回归一样。你将在这128个单元上训练合适的权重,用来预测两张图片是否是一个人,这是一个很合理的方法来学习预测0或者1,即是否是同一个人。
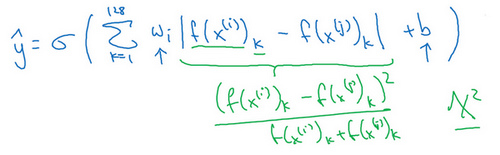
还有其他不同的形式来计算绿色标记的这部分公式(| f( x^{( i)}){k} - f( x^{( j)}){k}|),比如说,公式可以是\frac{(f( x^{( i)}){k} - f(x^{( j)}){k})^{2}}{f(x^{( i)}){k} + f( x^{( j)}){k}},这个公式也被叫做\chi^{2}公式,是一个希腊字母\chi,也被称为\chi平方相似度。
• Yaniv Taigman, Ming Yang, Marc'Aurelio Ranzato, Lior Wolf (2014). DeepFace:Closing the gap to human-level performance in face verification
这些公式及其变形在这篇DeepFace论文中有讨论,我之前也引用过。
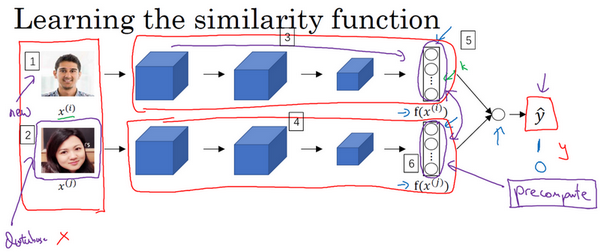
但是在这个学习公式中,输入是一对图片,这是你的训练输入x(编号1、2),输出y是0或者1,取决于你的输入是相似图片还是非相似图片。与之前类似,你正在训练一个Siamese网络,意味着上面这个神经网络拥有的参数和下面神经网络的相同(编号3和4所示的网络),两组参数是绑定的,这样的系统效果很好。
之前提到一个计算技巧可以帮你显著提高部署效果,如果这是一张新图片(编号1),当员工走进门时,希望门可以自动为他们打开,这个(编号2)是在数据库中的图片,不需要每次都计算这些特征(编号6),不需要每次都计算这个嵌入,你可以提前计算好,那么当一个新员工走近时,你可以使用上方的卷积网络来计算这些编码(编号5),然后使用它,和预先计算好的编码进行比较,然后输出预测值\hat y。
因为不需要存储原始图像,如果你有一个很大的员工数据库,你不需要为每个员工每次都计算这些编码。这个预先计算的思想,可以节省大量的计算,这个预训练的工作可以用在Siamese 网路结构中,将人脸识别当作一个二分类问题,也可以用在学习和使用Triplet loss函数上,我在之前的视频中描述过。
总结一下,把人脸验证当作一个监督学习,创建一个只有成对图片的训练集,不是三个一组,而是成对的图片,目标标签是1表示一对图片是一个人,目标标签是0表示图片中是不同的人。利用不同的成对图片,使用反向传播算法去训练神经网络,训练Siamese神经网络。

4 内容代价函数(Content cost function)

风格迁移网络的代价函数有一个内容代价部分,还有一个风格代价部分。
J( G) = \alpha J_{\text{content}}( C,G) + \beta J_{\text{style}}(S,G)
我们先定义内容代价部分,不要忘了这就是我们整个风格迁移网络的代价函数,我们看看内容代价函数应该是什么。

假如说,你用隐含层l来计算内容代价,如果l是个很小的数,比如用隐含层1,这个代价函数就会使你的生成图片像素上非常接近你的内容图片。然而如果你用很深的层,那么那就会问,内容图片里是否有狗,然后它就会确保生成图片里有一个狗。所以在实际中,这个层l在网络中既不会选的太浅也不会选的太深。因为你要自己做这周结束的编程练习,我会让你获得一些直觉,在编程练习中的具体例子里通常l会选择在网络的中间层,既不太浅也不很深,然后用一个预训练的卷积模型,可以是VGG网络或者其他的网络也可以。

现在你需要衡量假如有一个内容图片和一个生成图片他们在内容上的相似度,我们令这个a^{lC}和a^{lG},代表这两个图片C和G的l层的激活函数值。如果这两个激活值相似,那么就意味着两个图片的内容相似。
我们定义这个
J_{\text{content}}( C,G) = \frac{1}{2}|| a^{lC} - a^{lG}||^{2}
为两个激活值不同或者相似的程度,我们取l层的隐含单元的激活值,按元素相减,内容图片的激活值与生成图片相比较,然后取平方,也可以在前面加上归一化或者不加,比如\frac{1}{2}或者其他的,都影响不大,因为这都可以由这个超参数a来调整(J(G) =a J_{\text{content}}( C,G) + \beta J_{\text{style}}(S,G))。
要清楚我这里用的符号都是展成向量形式的,这个就变成了这一项(a^{l\lbrack C\rbrack})减这一项(a^{l\lbrack C\rbrack})的L2范数的平方,在把他们展成向量后。这就是两个激活值间的差值平方和,这就是两个图片之间l层激活值差值的平方和。后面如果对J(G)做梯度下降来找G的值时,整个代价函数会激励这个算法来找到图像G,使得隐含层的激活值和你内容图像的相似。
这就是如何定义风格迁移网络的内容代价函数,接下来让我们学习风格代价函数。
5. 风格代价函数(Style cost function)
在上节视频中,我们学习了如何为神经风格迁移定义内容代价函数,这节课我们来了解风格代价函数。那么图片的风格到底是什么意思呢?
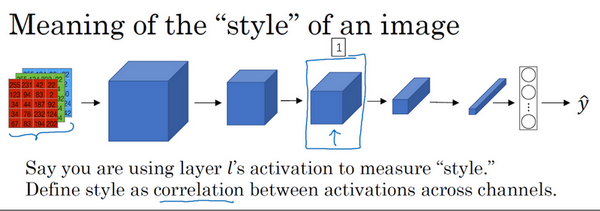
这么说吧,比如你有这样一张图片,你可能已经对这个计算很熟悉了,它能算出这里是否含有不同隐藏层。现在你选择了某一层l(编号1),比如这一层去为图片的风格定义一个深度测量,现在我们要做的就是将图片的风格定义为l层中各个通道之间激活项的相关系数。

我来详细解释一下,现在你将l层的激活项取出,这是个 n_{H} \times n_{W} \times n_{C}的激活项,它是一个三维的数据块。现在问题来了,如何知道这些不同通道之间激活项的相关系数呢?
为了解释这些听起来很含糊不清的词语,现在注意这个激活块,我把它的不同通道渲染成不同的颜色。在这个例子中,假如我们有5个通道为了方便讲解,我将它们染成了五种颜色。一般情况下,我们在神经网络中会有许多通道,但这里只用5个通道,会更方便我们理解。
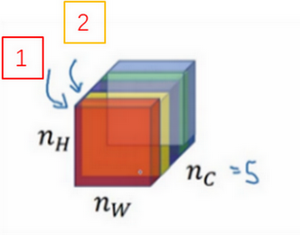
为了能捕捉图片的风格,你需要进行下面这些操作,首先,先看前两个通道,前两个通道(编号1、2)分别是图中的红色和黄色部分,那我们该如何计算这两个通道间激活项的相关系数呢?
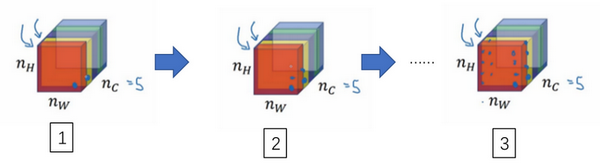
举个例子,在视频的左下角在第一个通道中含有某个激活项,第二个通道也含有某个激活项,于是它们组成了一对数字(编号1所示)。然后我们再看看这个激活项块中其他位置的激活项,它们也分别组成了很多对数字(编号2,3所示),分别来自第一个通道,也就是红色通道和第二个通道,也就是黄色通道。现在我们得到了很多个数字对,当我们取得这两个n_{H}\times n_{W}的通道中所有的数字对后,现在该如何计算它们的相关系数呢?它是如何决定图片风格的呢?
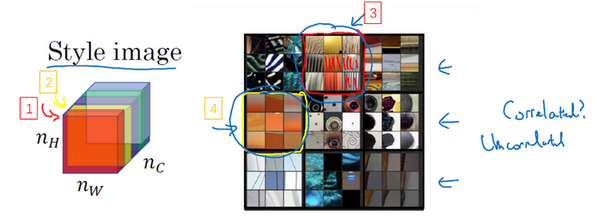
我们来看一个例子,这是之前视频中的一个可视化例子,它来自一篇论文,作者是Matthew Zeile 和Rob Fergus 我之前有提到过。我们知道,这个红色的通道(编号1)对应的是这个神经元,它能找出图片中的特定位置是否含有这些垂直的纹理(编号3),而第二个通道也就是黄色的通道(编号2),对应这个神经元(编号4),它可以粗略地找出橙色的区域。什么时候两个通道拥有高度相关性呢?如果它们有高度相关性,那么这幅图片中出现垂直纹理的地方(编号2),那么这块地方(编号4)很大概率是橙色的。如果说它们是不相关的,又是什么意思呢?显然,这意味着图片中有垂直纹理的地方很大概率不是橙色的。而相关系数描述的就是当图片某处出现这种垂直纹理时,该处又同时是橙色的可能性。
相关系数这个概念为你提供了一种去测量这些不同的特征的方法,比如这些垂直纹理,这些橙色或是其他的特征去测量它们在图片中的各个位置同时出现或不同时出现的频率。
如果我们在通道之间使用相关系数来描述通道的风格,你能做的就是测量你的生成图像中第一个通道(编号1)是否与第二个通道(编号2)相关,通过测量,你能得知在生成的图像中垂直纹理和橙色同时出现或者不同时出现的频率,这样你将能够测量生成的图像的风格与输入的风格图像的相似程度。
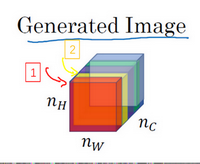
现在我们来证实这种说法,对于这两个图像,也就是风格图像与生成图像,你需要计算一个风格矩阵,说得更具体一点就是用l层来测量风格。
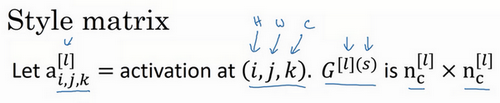
我们设a_{i,\ j,\ k}^{l},设它为隐藏层l中(i,j,k)位置的激活项,i,j,k分别代表该位置的高度、宽度以及对应的通道数。现在你要做的就是去计算一个关于l层和风格图像的矩阵,即G^{l(S)}(l表示层数,S表示风格图像),这(G^{l( S)})是一个n_{c} \times n_{c}的矩阵,同样地,我们也对生成的图像进行这个操作。
但是现在我们先来定义风格图像,设这个关于l层和风格图像的,G是一个矩阵,这个矩阵的高度和宽度都是l层的通道数。在这个矩阵中k和k'元素被用来描述k通道和k'通道之间的相关系数。具体地:
G_{kk^{'}}^{l( S)} = \sum_{i = 1}^{n_{H}^{l}}{\sum_{j = 1}^{n_{W}^{l}}{a_{i,\ j,\ k}^{l(S)}a_{i,\ j,\ k^{'}}^{l(S)}}}
用符号i,j表示下界,对i,j,k位置的激活项a_{i,\ j,\ k}^{l},乘以同样位置的激活项,也就是i, j,k'位置的激活项,即a_{i,j,k^{'}}^{l},将它们两个相乘。然后i和j分别加到l层的高度和宽度,即n_{H}^{l}和n_{W}^{l},将这些不同位置的激活项都加起来。(i,j,k)和(i,j,k')中x坐标和y坐标分别对应高度和宽度,将k通道和k'通道上这些位置的激活项都进行相乘。我一直以来用的这个公式,严格来说,它是一种非标准的互相关函数,因为我们没有减去平均数,而是将它们直接相乘。
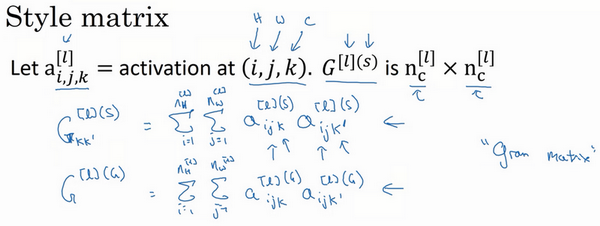
这就是输入的风格图像所构成的风格矩阵,然后,我们再对生成图像做同样的操作。
G_{kk^{'}}^{l( G)} = \sum_{i = 1}^{n_{H}^{l}}{\sum_{j = 1}^{n_{W}^{l}}{a_{i,\ j,\ k}^{l(G)}a_{i,\ j,\ k^{'}}^{l(G)}}}
a_{i,\ j,\ k}^{l(S)}和a_{i, j,k}^{l(G)}中的上标(S)和(G)分别表示在风格图像S中的激活项和在生成图像G的激活项。我们之所以用大写字母G来代表这些风格矩阵,是因为在线性代数中这种矩阵有时也叫Gram矩阵,但在这里我只把它们叫做风格矩阵。
所以你要做的就是计算出这张图像的风格矩阵,以便能够测量出刚才所说的这些相关系数。更正规地来表示,我们用a_{i,j,k}^{l}来记录相应位置的激活项,也就是l层中的i,j,k位置,所以i代表高度,j代表宽度,k代表着l中的不同通道。之前说过,我们有5个通道,所以k就代表这五个不同的通道。
对于这个风格矩阵,你要做的就是计算这个矩阵也就是G^{l}矩阵,它是个n_{c} \times n_{c}的矩阵,也就是一个方阵。记住,因为这里有n_{c}个通道,所以矩阵的大小是n_{c}\times n_{c}。以便计算每一对激活项的相关系数,所以G_{\text{kk}^{'}}^{l}可以用来测量k通道与k'通道中的激活项之间的相关系数,k和k'会在1到n_{c}之间取值,n_{c}就是l层中通道的总数量。
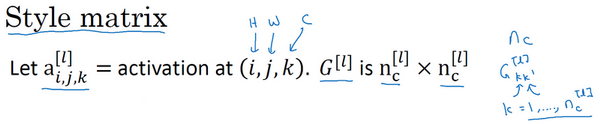
当在计算G^{l}时,我写下的这个符号(下标kk')只代表一种元素,所以我要在右下角标明是kk'元素,和之前一样i,j从一开始往上加,对应(i,j,k)位置的激活项与对应(i, j, k')位置的激活项相乘。记住,这个i和j是激活块中对应位置的坐标,也就是该激活项所在的高和宽,所以i会从1加到n_{H}^{l},j会从1加到n_{W}^{l},k和k'则表示对应的通道,所以k和k'值的范围是从1开始到这个神经网络中该层的通道数量n_{C}^{l}。这个式子就是把图中各个高度和宽度的激活项都遍历一遍,并将k和k'通道中对应位置的激活项都进行相乘,这就是G_{{kk}^{'}}^{l}的定义。通过对k和k'通道中所有的数值进行计算就得到了G矩阵,也就是风格矩阵。
G_{kk^{'}}^{l} = \sum_{i = 1}^{n_{H}^{l}}{\sum_{j = 1}^{n_{W}^{l}}{a_{i,\ j,\ k}^{l}a_{i,\ j,\ k^{'}}^{l}}}
要注意,如果两个通道中的激活项数值都很大,那么G_{{kk}^{'}}^{l}也会变得很大,对应地,如果他们不相关那么G_{{kk}^{'}}^{l}就会很小。严格来讲,我一直使用这个公式来表达直觉想法,但它其实是一种非标准的互协方差,因为我们并没有减去均值而只是把这些元素直接相乘,这就是计算图像风格的方法。
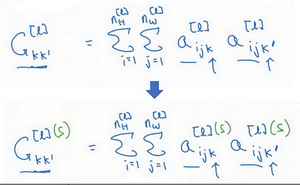
G_{kk^{'}}^{l( S)} = \sum_{i = 1}^{n_{H}^{l}}{\sum_{j = 1}^{n_{W}^{l}}{a_{i,\ j,\ k}^{l(S)}a_{i,\ j,\ k^{'}}^{l(S)}}}
你要同时对风格图像S和生成图像G都进行这个运算,为了区分它们,我们在它的右上角加一个(S),表明它是风格图像S,这些都是风格图像S中的激活项,之后你需要对生成图像也做相同的运算。
G_{kk^{'}}^{l( G)} = \sum_{i = 1}^{n_{H}^{l}}{\sum_{j = 1}^{n_{W}^{l}}{a_{i,\ j,\ k}^{l(G)}a_{i,\ j,\ k^{'}}^{l(G)}}}
和之前一样,再把公式都写一遍,把这些都加起来,为了区分它是生成图像,在这里放一个(G)。
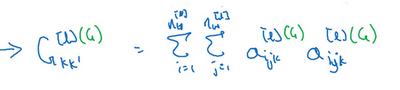
现在,我们有2个矩阵,分别从风格图像S和生成图像G。

再提醒一下,我们一直使用大写字母G来表示矩阵,是因为在线性代数中,这种矩阵被称为Gram 矩阵,但在本视频中我把它叫做风格矩阵,我们取了Gram矩阵的首字母G来表示这些风格矩阵。

最后,如果我们将S和G代入到风格代价函数中去计算,这将得到这两个矩阵之间的误差,因为它们是矩阵,所以在这里加一个F(Frobenius范数,编号1所示),这实际上是计算两个矩阵对应元素相减的平方的和,我们把这个式子展开,从k和k'开始作它们的差,把对应的式子写下来,然后把得到的结果都加起来,作者在这里使用了一个归一化常数,也就是\frac{1}{2n_{H}^{ll}n_{W}^{l}n_{C}^{l}},再在外面加一个平方,但是一般情况下你不用写这么多,一般我们只要将它乘以一个超参数\beta就行。

最后,这是对l层定义的风格代价函数,和之前你见到的一样,这是两个矩阵间一个基本的Frobenius范数,也就是S图像和G图像之间的范数再乘上一个归一化常数,不过这不是很重要。实际上,如果你对各层都使用风格代价函数,会让结果变得更好。如果要对各层都使用风格代价函数,你可以这么定义代价函数,把各个层的结果(各层的风格代价函数)都加起来,这样就能定义它们全体了。我们还需要对每个层定义权重,也就是一些额外的超参数,我们用\lambda^{l}来表示,这样将使你能够在神经网络中使用不同的层,包括之前的一些可以测量类似边缘这样的低级特征的层,以及之后的一些能测量高级特征的层,使得我们的神经网络在计算风格时能够同时考虑到这些低级和高级特征的相关系数。这样,在基础的训练中你在定义超参数时,可以尽可能的得到更合理的选择。
为了把这些东西封装起来,你现在可以定义一个全体代价函数:
J(G) = a J_{\text{content}( C,G)} + \beta J_{{style}}(S,G)
之后用梯度下降法,或者更复杂的优化算法来找到一个合适的图像G,并计算J(G)的最小值,这样的话,你将能够得到非常好看的结果,你将能够得到非常漂亮的结果。
lesson5:序列模型(Sequence Models)
Week1:循环序列模型(Recurrent Neural Networks)
1.序列模型意义
在本课程中你将学会序列模型,它是深度学习中最令人激动的内容之一。循环神经网络(RNN)之类的模型在语音识别、自然语言处理和其他领域中引起变革。在本节课中,你将学会如何自行创建这些模型。我们先看一些例子,这些例子都有效使用了序列模型。
在进行语音识别时,给定了一个输入音频片段 X,并要求输出对应的文字记录 Y。这个例子里输入和输出数据都是序列模型,因为 X是一个按时播放的音频片段,输出 Y是一系列单词。所以之后将要学到的一些序列模型,如循环神经网络等等在语音识别方面是非常有用的。
音乐生成问题是使用序列数据的另一个例子,在这个例子中,只有输出数据 Y是序列,而输入数据可以是空集,也可以是个单一的整数,这个数可能指代你想要生成的音乐风格,也可能是你想要生成的那首曲子的头几个音符。输入的 X可以是空的,或者就是个数字,然后输出序列 Y。
在处理情感分类时,输入数据 X是序列,你会得到类似这样的输入:"There is nothing to like in this movie.",你认为这句评论对应几星?
系列模型在DNA 序列分析中也十分有用,你的DNA 可以用A 、C 、G 、T 四个字母来表示。所以给定一段DNA序列,你能够标记出哪部分是匹配某种蛋白质的吗?
在机器翻译过程中,你会得到这样的输入句:"Voulez-vou chante avecmoi?"(法语:要和我一起唱么?),然后要求你输出另一种语言的翻译结果。
在进行视频行为识别时,你可能会得到一系列视频帧,然后要求你识别其中的行为。
在进行命名实体识别时,可能会给定一个句子要你识别出句中的人名。
所以这些问题都可以被称作使用标签数据 (X,Y)作为训练集的监督学习。但从这一系列例子中你可以看出序列问题有很多不同类型。有些问题里,输入数据 X和输出数据Y都是序列,但就算在那种情况下,X和Y有时也会不一样长。或者像上图编号1所示和上图编号2的X和Y有相同的数据长度。在另一些问题里,只有 X或者只有Y是序列。
2.数学符号
比如说你想要建立一个序列模型,它的输入语句是这样的:"Harry Potter and Herminoe Granger invented a new spell. ",(这些人名都是出自于J.K.Rowling 笔下的系列小说Harry Potter)。假如你想要建立一个能够自动识别句中人名位置的序列模型,那么这就是一个命名实体识别问题,这常用于搜索引擎,比如说索引过去24小时内所有新闻报道提及的人名,用这种方式就能够恰当地进行索引。命名实体识别系统可以用来查找不同类型的文本中的人名、公司名、时间、地点、国家名和货币名等等。

现在给定这样的输入数据x,假如你想要一个序列模型输出y,使得输入的每个单词都对应一个输出值,同时这个y能够表明输入的单词是否是人名的一部分。技术上来说这也许不是最好的输出形式,还有更加复杂的输出形式,它不仅能够表明输入词是否是人名的一部分,它还能够告诉你这个人名在这个句子里从哪里开始到哪里结束。比如Harry Potter (上图编号1所示)、Hermione Granger(上图标号2所示)。
更简单的那种输出形式:
这个输入数据是9个单词组成的序列,所以最终我们会有9个特征集和来表示这9个单词,并按序列中的位置进行索引,x^{<1>}、x^{<2>}、x^{<3>}等等一直到x^{<9>}来索引不同的位置,我将用x^{<t>}来索引这个序列的中间位置。t意味着它们是时序序列,但不论是否是时序序列,我们都将用t来索引序列中的位置。
输出数据也是一样,我们还是用y^{<1>}、y^{<2>}、y^{<3>}等等一直到y^{<9>}来表示输出数据。同时我们用T_{x}来表示输入序列的长度,这个例子中输入是9个单词,所以T_{x}= 9。我们用T_{y}来表示输出序列的长度。在这个例子里T_{x} =T_{y},上个视频里你知道T_{x}和T_{y}可以有不同的值。
你应该记得我们之前用的符号,我们用x^{(i)}来表示第i个训练样本,所以为了指代第t个元素,或者说是训练样本i的序列中第t个元素用x^{\left(i \right) <t>}这个符号来表示。如果T_{x}是序列长度,那么你的训练集里不同的训练样本就会有不同的长度,所以T_{x}^{(i)}就代表第i个训练样本的输入序列长度。同样y^{\left( i \right) < t>}代表第i个训练样本中第t个元素,T_{y}^{(i)}就是第i个训练样本的输出序列的长度。
所以在这个例子中,T_{x}^{(i)}=9,但如果另一个样本是由15个单词组成的句子,那么对于这个训练样本,T_{x}^{(i)}=15。
既然我们这个例子是NLP ,也就是自然语言处理,这是我们初次涉足自然语言处理,一件我们需要事先决定的事是怎样表示一个序列里单独的单词,你会怎样表示像Harry这样的单词,x^{<1>}实际应该是什么?
接下来我们讨论一下怎样表示一个句子里单个的词。想要表示一个句子里的单词,第一件事是做一张词表,有时也称为词典,意思是列一列你的表示方法中用到的单词。这个词表(下图所示)中的第一个词是a ,也就是说词典中的第一个单词是a ,第二个单词是Aaron ,然后更下面一些是单词and ,再后面你会找到Harry ,然后找到Potter ,这样一直到最后,词典里最后一个单词可能是Zulu。
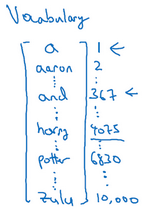
因此a 是第一个单词,Aaron 是第二个单词,在这个词典里,and 出现在367这个位置上,Harry 是在4075这个位置,Potter 在6830,词典里的最后一个单词Zulu可能是第10,000个单词。所以在这个例子中我用了10,000个单词大小的词典,这对现代自然语言处理应用来说太小了。对于商业应用来说,或者对于一般规模的商业应用来说30,000到50,000词大小的词典比较常见,但是100,000词的也不是没有,而且有些大型互联网公司会用百万词,甚至更大的词典。许多商业应用用的词典可能是30,000词,也可能是50,000词。不过我将用10,000词大小的词典做说明,因为这是一个很好用的整数。
如果你选定了10,000词的词典,构建这个词典的一个方法是遍历你的训练集,并且找到前10,000个常用词,你也可以去浏览一些网络词典,它能告诉你英语里最常用的10,000个单词,接下来你可以用one-hot表示法来表示词典里的每个单词。
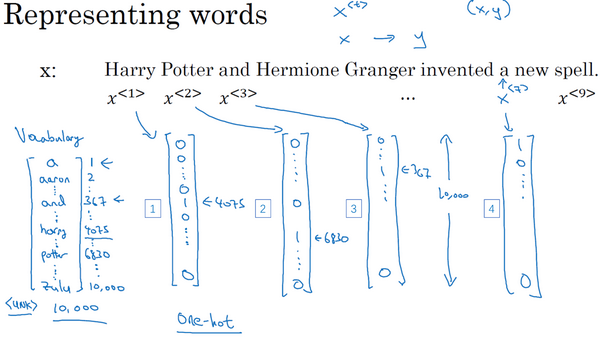
举个例子,在这里x^{<1>}表示Harry 这个单词,它就是一个第4075行是1,其余值都是0的向量(上图编号1所示),因为那是Harry在这个词典里的位置。
同样x^{<2>}是个第6830行是1,其余位置都是0的向量(上图编号2所示)。
and在词典里排第367,所以x^{<3>}就是第367行是1,其余值都是0的向量(上图编号3所示)。如果你的词典大小是10,000的话,那么这里的每个向量都是10,000维的。
因为a 是字典第一个单词,x^{<7>}对应a,那么这个向量的第一个位置为1,其余位置都是0的向量(上图编号4所示)。
所以这种表示方法中,x^{<t>}指代句子里的任意词,它就是个one-hot 向量,因为它只有一个值是1,其余值都是0,所以你会有9个one-hot向量来表示这个句中的9个单词,目的是用这样的表示方式表示X,用序列模型在X和目标输出Y之间学习建立一个映射。我会把它当作监督学习的问题,我确信会给定带有(x,y)标签的数据。
那么还剩下最后一件事,我们将在之后的视频讨论,如果你遇到了一个不在你词表中的单词,答案就是创建一个新的标记,也就是一个叫做Unknow Word的伪造单词,用<**UNK**>作为标记,来表示不在词表中的单词,我们之后会讨论更多有关这个的内容。
3.循环神经网络模型
- 为什么不用标准网络?
一、是输入和输出数据在不同例子中可以有不同的长度,不是所有的例子都有着同样输入长度T_{x}或是同样输出长度的T_{y}。即使每个句子都有最大长度,也许你能够填充(pad )或零填充(zero pad )使每个输入语句都达到最大长度,但仍然看起来不是一个好的表达方式。
二、一个像这样单纯的神经网络结构,它并不共享从文本的不同位置上学到的特征。具体来说,如果神经网络已经学习到了在位置1出现的Harry 可能是人名的一部分,那么如果Harry 出现在其他位置,比如x^{<t>}时,它也能够自动识别其为人名的一部分的话,这就很棒了。这可能类似于你在卷积神经网络中看到的,你希望将部分图片里学到的内容快速推广到图片的其他部分,而我们希望对序列数据也有相似的效果。和你在卷积网络中学到的类似,用一个更好的表达方式也能够让你减少模型中参数的数量。
之前我们提到过这些(上图编号1所示的x^{<1>}......x^{<t>}......x^{< T_{x}>})都是10,000维的one-hot向量,因此这会是十分庞大的输入层。如果总的输入大小是最大单词数乘以10,000,那么第一层的权重矩阵就会有着巨量的参数。但循环神经网络就没有上述的两个问题。
-
什么是循环神经网络?
我们先建立一个(下图编号1所示)。如果你以从左到右的顺序读这个句子,第一个单词就是,假如说是x^{<1>},我们要做的就是将第一个词输入一个神经网络层,我打算这样画,第一个神经网络的隐藏层,我们可以让神经网络尝试预测输出,判断这是否是人名的一部分。循环神经网络做的是,当它读到句中的第二个单词时,假设是x^{<2>},它不是仅用x^{<2>}就预测出{\hat{y}}^{<2>},他也会输入一些来自时间步1的信息。具体而言,时间步1的激活值就会传递到时间步2。然后,在下一个时间步,循环神经网络输入了单词x^{<3>},然后它尝试预测输出了预测结果{\hat{y}}^{<3>},等等,一直到最后一个时间步,输入了x^{<T_{x}>},然后输出了{\hat{y}}^{< T_{y} >}。至少在这个例子中T_{x} =T_{y},同时如果T_{x}和T_{y}不相同,这个结构会需要作出一些改变。所以在每一个时间步中,循环神经网络传递一个激活值到下一个时间步中用于计算。
要开始整个流程,在零时刻需要构造一个激活值a^{<0>},这通常是零向量。有些研究人员会随机用其他方法初始化a^{<0>},不过使用零向量作为零时刻的伪激活值是最常见的选择,因此我们把它输入神经网络。
在一些研究论文中或是一些书中你会看到这类神经网络,用这样的图形来表示(上图编号2所示),在每一个时间步中,你输入x^{<t>}然后输出y^{<t>}。然后为了表示循环连接有时人们会像这样画个圈,表示输回网络层,有时他们会画一个黑色方块,来表示在这个黑色方块处会延迟一个时间步。我个人认为这些循环图很难理解,所以在本次课程中,我画图更倾向于使用左边这种分布画法(上图编号1所示)。不过如果你在教材中或是研究论文中看到了右边这种图表的画法(上图编号2所示),它可以在心中将这图展开成左图那样。
循环神经网络是从左向右扫描数据,同时每个时间步的参数也是共享的,所以下页幻灯片中我们会详细讲述它的一套参数,我们用W_{\text{ax}}来表示管理着从x^{<1>}到隐藏层的连接的一系列参数,每个时间步使用的都是相同的参数W_{\text{ax}}。而激活值也就是水平联系是由参数W_{aa}决定的,同时每一个时间步都使用相同的参数W_{aa},同样的输出结果由W_{\text{ya}}决定。
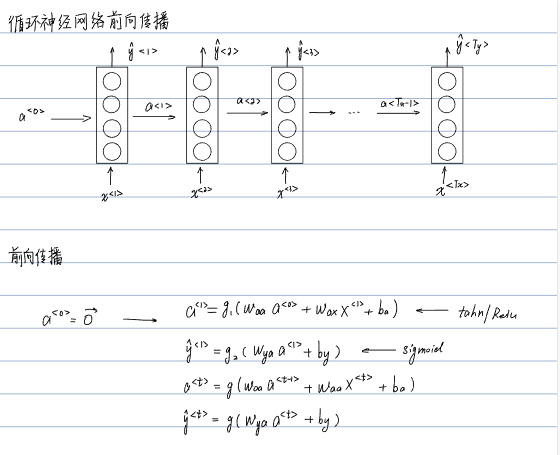
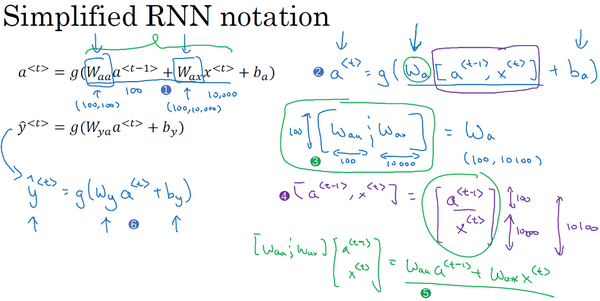
接下来为了简化这些符号,我要将这部分(W_{\text{aa}}a^{<t -1>} +W_{\text{ax}}x^{<t>})(上图编号1所示)以更简单的形式写出来,我把它写做a^{<t>} =g(W_{a}\left\lbrack a^{< t-1 >},x^{<t>} \right\rbrack +b_{a})(上图编号2所示),那么左右两边划线部分应该是等价的。所以我们定义W_{a}的方式是将矩阵W_{aa}和矩阵W_{{ax}}水平并列放置, {{W}_{aa}}\\vdots {{W}_{ax}}=W_{a}(上图编号3所示)。举个例子,如果a是100维的,然后延续之前的例子,x是10,000维的,那么W_{aa}就是个(100,100)维的矩阵,W_{ax}就是个(100,10,000)维的矩阵,因此如果将这两个矩阵堆起来,W_{a}就会是个(100,10,100)维的矩阵。
用这个符号(\left\lbrack a^{< t - 1 >},x^{< t >}\right\rbrack)的意思是将这两个向量堆在一起,我会用这个符号表示,即\begin{bmatrix}a^{< t-1 >} \\ x^{< t >} \\\end{bmatrix}(上图编号4所示),最终这就是个10,100维的向量。你可以自己检查一下,用这个矩阵乘以这个向量,刚好能够得到原来的量,因为此时,矩阵 {{W}_{aa}}\\vdots {{W}_{ax}}乘以\begin{bmatrix} a^{< t - 1 >} \\ x^{< t >} \\ \end{bmatrix},刚好等于W_{{aa}}a^{<t-1>} + W_{{ax}}x^{<t>},刚好等于之前的这个结论(上图编号5所示)。这种记法的好处是我们可以不使用两个参数矩阵W_{{aa}}和W_{{ax}},而是将其压缩成一个参数矩阵W_{a},所以当我们建立更复杂模型时这就能够简化我们要用到的符号。
同样对于这个例子(\hat y^{<t>} = g(W_{ya}a^{<t>} +b_{y})),我会用更简单的方式重写,\hat y^{< t >} = g(W_{y}a^{< t >} +b_{y})(上图编号6所示)。现在W_{y}和b_{y}符号仅有一个下标,它表示在计算时会输出什么类型的量,所以W_{y}就表明它是计算y类型的量的权重矩阵,而上面的W_{a}和b_{a}则表示这些参数是用来计算a类型或者说是激活值的。
RNN前向传播示意图:
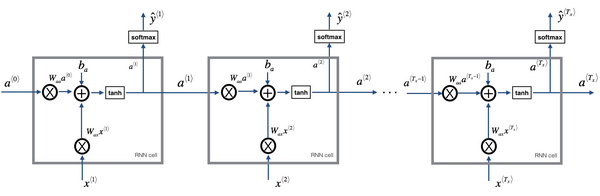
好就这么多,你现在知道了基本的循环神经网络,下节课我们会一起来讨论反向传播,以及你如何能够用RNN进行学习。
- 反向传播
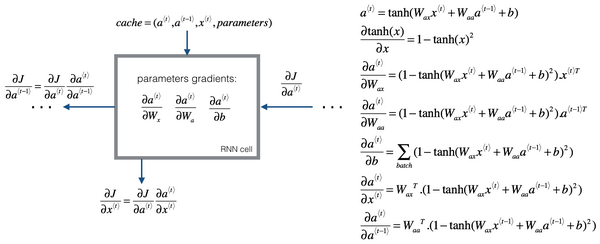
4.不同类型的RNN
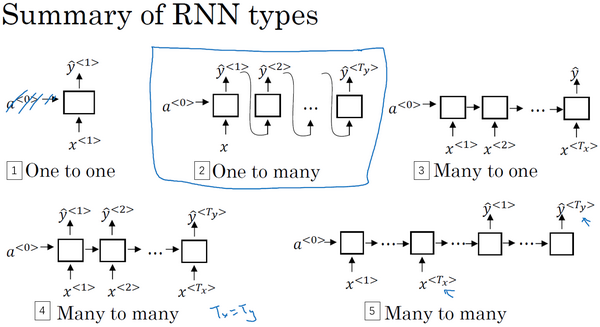
5.语言模型和序列生成
在自然语言处理中,构建语言模型是最基础的也是最重要的工作之一,并且能用RNN 很好地实现。在本视频中,你将学习用RNN构建一个语言模型,在本周结束的时候,还会有一个很有趣的编程练习,你能在练习中构建一个语言模型,并用它来生成莎士比亚文风的文本或其他类型文本。

所以什么是语言模型呢?比如你在做一个语音识别系统,你听到一个句子,"the apple and pear(pair) salad was delicious. ",所以我究竟说了什么?我说的是 "the apple and pair salad ",还是"the apple and pear salad "?(pear 和pair是近音词)。你可能觉得我说的应该更像第二种,事实上,这就是一个好的语音识别系统要帮助输出的东西,即使这两句话听起来是如此相似。而让语音识别系统去选择第二个句子的方法就是使用一个语言模型,他能计算出这两句话各自的可能性。
举个例子,一个语音识别模型可能算出第一句话的概率是P( \text{The apple and pair salad}) = 3.2 \times 10^{-13},而第二句话的概率是P\left(\text{The apple and pear salad} \right) = 5.7 \times 10^{-10},比较这两个概率值,显然我说的话更像是第二种,因为第二句话的概率比第一句高出1000倍以上,这就是为什么语音识别系统能够在这两句话中作出选择。
所以语言模型所做的就是,它会告诉你某个特定的句子它出现的概率是多少,根据我所说的这个概率,假设你随机拿起一张报纸,打开任意邮件,或者任意网页或者听某人说下一句话,并且这个人是你的朋友,这个你即将从世界上的某个地方得到的句子会是某个特定句子的概率是多少,例如"the apple and pear salad"。它是两种系统的基本组成部分,一个刚才所说的语音识别系统,还有机器翻译系统,它要能正确输出最接近的句子。而语言模型做的最基本工作就是输入一个句子,准确地说是一个文本序列,y^{<1>},y^{<2>}一直到y^{<T_{y}>}。对于语言模型来说,用y来表示这些序列比用x来表示要更好,然后语言模型会估计某个句子序列中各个单词出现的可能性。
那么如何建立一个语言模型呢?为了使用RNN 建立出这样的模型,你首先需要一个训练集,包含一个很大的英文文本语料库(corpus)或者其它的语言,你想用于构建模型的语言的语料库。语料库是自然语言处理的一个专有名词,意思就是很长的或者说数量众多的英文句子组成的文本。

假如说,你在训练集中得到这么一句话,"Cats average 15 hours of sleep a day. "(猫一天睡15小时),你要做的第一件事就是将这个句子标记化,意思就是像之前视频中一样,建立一个字典,然后将每个单词都转换成对应的one-hot 向量,也就是字典中的索引。可能还有一件事就是你要定义句子的结尾,一般的做法就是增加一个额外的标记,叫做EOS (上图编号1所示),它表示句子的结尾,这样能够帮助你搞清楚一个句子什么时候结束,我们之后会详细讨论这个。EOS 标记可以被附加到训练集中每一个句子的结尾,如果你想要你的模型能够准确识别句子结尾的话。在本周的练习中我们不需要使用这个EOS 标记,不过在某些应用中你可能会用到它,不过稍后就能见到它的用处。于是在本例中我们,如果你加了EOS 标记,这句话就会有9个输入,有y^{<1>},y^{<2>}一直到y^{<9>}。在标记化的过程中,你可以自行决定要不要把标点符号看成标记,在本例中,我们忽略了标点符号,所以我们只把day看成标志,不包括后面的句号,如果你想把句号或者其他符号也当作标志,那么你可以将句号也加入你的字典中。
现在还有一个问题如果你的训练集中有一些词并不在你的字典里,比如说你的字典有10,000个词,10,000个最常用的英语单词。现在这个句,"The Egyptian Mau is a bread of cat. "其中有一个词Mau ,它可能并不是预先的那10,000个最常用的单词,在这种情况下,你可以把Mau 替换成一个叫做UNK 的代表未知词的标志,我们只针对UNK 建立概率模型,而不是针对这个具体的词Mau。
完成标识化的过程后,这意味着输入的句子都映射到了各个标志上,或者说字典中的各个词上。下一步我们要构建一个RNN来构建这些序列的概率模型。在下一张幻灯片中会看到的一件事就是最后你会将x^{<t>}设为y^{<t-1>}。
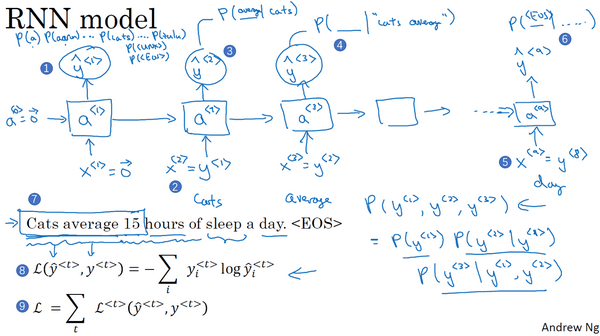
现在我们来建立RNN 模型,我们继续使用"Cats average 15 hours of sleep a day. "这个句子来作为我们的运行样例,我将会画出一个RNN 结构。在第0个时间步,你要计算激活项a^{<1>},它是以x^{<1 >}作为输入的函数,而x^{<1>}会被设为全为0的集合,也就是0向量。在之前的a^{<0>}按照惯例也设为0向量,于是a^{<1>}要做的就是它会通过softmax 进行一些预测来计算出第一个词可能会是什么,其结果就是\hat y^{<1>}(上图编号1所示),这一步其实就是通过一个softmax 层来预测字典中的任意单词会是第一个词的概率,比如说第一个词是a的概率有多少,第一个词是Aaron 的概率有多少,第一个词是cats 的概率又有多少,就这样一直到Zulu 是第一个词的概率是多少,还有第一个词是UNK (未知词)的概率有多少,还有第一个词是句子结尾标志的概率有多少,表示不必阅读。所以\hat y^{<1>}的输出是softmax 的计算结果,它只是预测第一个词的概率,而不去管结果是什么。在我们的例子中,最终会得到单词Cats 。所以softmax层输出10,000种结果,因为你的字典中有10,000个词,或者会有10,002个结果,因为你可能加上了未知词,还有句子结尾这两个额外的标志。
然后RNN 进入下个时间步,在下一时间步中,仍然使用激活项a^{<1>},在这步要做的是计算出第二个词会是什么。现在我们依然传给它正确的第一个词,我们会告诉它第一个词就是Cats ,也就是\hat y^{<1>},告诉它第一个词就是Cats ,这就是为什么y^{<1>} = x^{<2>}(上图编号2所示)。然后在第二个时间步中,输出结果同样经过softmax 层进行预测,RNN 的职责就是预测这些词的概率(上图编号3所示),而不会去管结果是什么,可能是b或者arron ,可能是Cats 或者Zulu 或者UNK (未知词)或者EOS 或者其他词,它只会考虑之前得到的词。所以在这种情况下,我猜正确答案会是average ,因为句子确实就是Cats average开头的。
然后再进行RNN 的下个时间步,现在要计算a^{<3>}。为了预测第三个词,也就是15,我们现在给它之前两个词,告诉它Cats average 是句子的前两个词,所以这是下一个输入,x^{<3>} = y^{<2>},输入average 以后,现在要计算出序列中下一个词是什么,或者说计算出字典中每一个词的概率(上图编号4所示),通过之前得到的Cats 和average,在这种情况下,正确结果会是15,以此类推。
一直到最后,没猜错的话,你会停在第9个时间步,然后把x^{<9>}也就是y^{<8>}传给它(上图编号5所示),也就是单词day ,这里是a^{<9>},它会输出y^{<9>},最后的得到结果会是EOS 标志,在这一步中,通过前面这些得到的单词,不管它们是什么,我们希望能预测出EOS句子结尾标志的概率会很高(上图编号6所示)。
所以RNN 中的每一步都会考虑前面得到的单词,比如给它前3个单词(上图编号7所示),让它给出下个词的分布,这就是RNN如何学习从左往右地每次预测一个词。
接下来为了训练这个网络,我们要定义代价函数。于是,在某个时间步t,如果真正的词是y^{<t>},而神经网络的softmax 层预测结果值是y^{<t>},那么这(上图编号8所示)就是softmax损失函数,L\left( \hat y^{<t>},y^{<t>}>\right) = - \sum_{i}^{}{y_{i}^{<t>}\log\hat y_{i}^{<t>}}。而总体损失函数(上图编号9所示)L = \sum_{t}^{}{L^{< t >}\left( \hat y^{<t>},y^{<t>} \right)},也就是把所有单个预测的损失函数都相加起来。
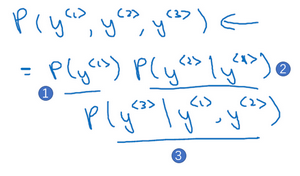
如果你用很大的训练集来训练这个RNN ,你就可以通过开头一系列单词像是Cars average 15 或者Cars average 15 hours of 来预测之后单词的概率。现在有一个新句子,它是y^{<1>},y^{<2>},y^{<3>},为了简单起见,它只包含3个词(如上图所示),现在要计算出整个句子中各个单词的概率,方法就是第一个softmax 层会告诉你y^{<1>}的概率(上图编号1所示),这也是第一个输出,然后第二个softmax 层会告诉你在考虑y^{<1>}的情况下y^{<2>}的概率(上图编号2所示),然后第三个softmax层告诉你在考虑y^{<1>}和y^{<2>}的情况下y^{<3>}的概率(上图编号3所示),把这三个概率相乘,最后得到这个含3个词的整个句子的概率。

6.新序列采样
7.循环神经网络的梯度消失
你已经了解了RNN 时如何工作的了,并且知道如何应用到具体问题上,比如命名实体识别,比如语言模型,你也看到了怎么把反向传播用于RNN 。其实,基本的RNN算法还有一个很大的问题,就是梯度消失的问题。这节课我们会讨论,在下几节课我们会讨论一些方法用来解决这个问题。
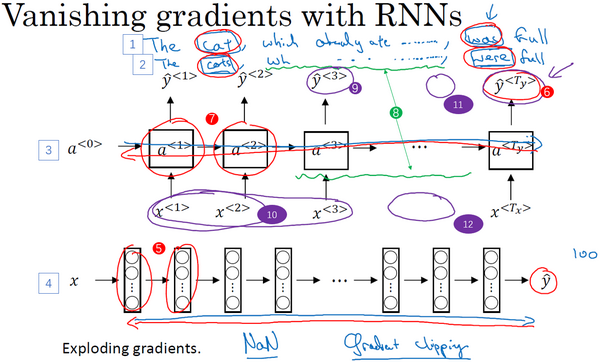
你已经知道了RNN 的样子,现在我们举个语言模型的例子,假如看到这个句子(上图编号1所示),"The cat, which already ate ......, was full. ",前后应该保持一致,因为cat 是单数,所以应该用was 。"The cats, which ate ......, were full. "(上图编号2所示),cats 是复数,所以用were 。这个例子中的句子有长期的依赖,最前面的单词对句子后面的单词有影响。但是我们目前见到的基本的RNN模型(上图编号3所示的网络模型),不擅长捕获这种长期依赖效应,解释一下为什么。
你应该还记得之前讨论的训练很深的网络,我们讨论了梯度消失的问题。比如说一个很深很深的网络(上图编号4所示),100层,甚至更深,对这个网络从左到右做前向传播然后再反向传播。我们知道如果这是个很深的神经网络,从输出

得到的梯度很难传播回去,很难影响靠前层的权重,很难影响前面层(编号5所示的层)的计算。
对于有同样问题的RNN ,首先从左到右前向传播,然后反向传播。但是反向传播会很困难,因为同样的梯度消失的问题,后面层的输出误差(上图编号6所示)很难影响前面层(上图编号7所示的层)的计算。这就意味着,实际上很难让一个神经网络能够意识到它要记住看到的是单数名词还是复数名词,然后在序列后面生成依赖单复数形式的was 或者were 。而且在英语里面,这中间的内容(上图编号8所示)可以任意长,对吧?所以你需要长时间记住单词是单数还是复数,这样后面的句子才能用到这些信息。也正是这个原因,所以基本的RNN 模型会有很多局部影响,意味着这个输出\hat y^{<3>}(上图编号9所示)主要受\hat y^{<3>}附近的值(上图编号10所示)的影响,上图编号11所示的一个数值主要与附近的输入(上图编号12所示)有关,上图编号6所示的输出,基本上很难受到序列靠前的输入(上图编号10所示)的影响,这是因为不管输出是什么,不管是对的,还是错的,这个区域都很难反向传播到序列的前面部分,也因此网络很难调整序列前面的计算。这是基本的RNN 算法的一个缺点,我们会在下几节视频里处理这个问题。如果不管的话,RNN会不擅长处理长期依赖的问题。

尽管我们一直在讨论梯度消失问题,但是,你应该记得我们在讲很深的神经网络时,我们也提到了梯度爆炸,我们在反向传播的时候,随着层数的增多,梯度不仅可能指数型的下降,也可能指数型的上升。事实上梯度消失在训练RNN 时是首要的问题,尽管梯度爆炸也是会出现,但是梯度爆炸很明显,因为指数级大的梯度会让你的参数变得极其大,以至于你的网络参数崩溃。所以梯度爆炸很容易发现,因为参数会大到崩溃,你会看到很多NaN ,或者不是数字的情况,这意味着你的网络计算出现了数值溢出。如果你发现了梯度爆炸的问题,一个解决方法就是用梯度修剪。梯度修剪的意思就是观察你的梯度向量,如果它大于某个阈值,缩放梯度向量,保证它不会太大,这就是通过一些最大值来修剪的方法。所以如果你遇到了梯度爆炸,如果导数值很大,或者出现了NaN,就用梯度修剪,这是相对比较鲁棒的,这是梯度爆炸的解决方法。然而梯度消失更难解决,这也是我们下几节视频的主题。
总结一下,在前面的课程,我们了解了训练很深的神经网络时,随着层数的增加,导数有可能指数型的下降或者指数型的增加,我们可能会遇到梯度消失或者梯度爆炸的问题。加入一个RNN 处理1,000个时间序列的数据集或者10,000个时间序列的数据集,这就是一个1,000层或者10,000层的神经网络,这样的网络就会遇到上述类型的问题。梯度爆炸基本上用梯度修剪就可以应对,但梯度消失比较棘手。我们下节会介绍GRU,门控循环单元网络,这个网络可以有效地解决梯度消失的问题,并且能够使你的神经网络捕获更长的长期依赖,我们去下个视频一探究竟吧。
8.GRU
1.解决什么问题
解决原始 RNN 梯度消失、长序列记不住的问题
只用两个门控制记忆流动
2.两大核心门
- 更新门 Update Gate 决定:保留多少旧记忆 + 放入多少新信息 值越大,越保留前面的信息
- 重置门 Reset Gate 决定:忘掉多少过去记忆 值越小,越清空过往信息
3.GRU 内部流程
- 重置门筛选过往无用信息
- 结合当前输入,生成候选新记忆
- 更新门融合旧记忆 + 新记忆
- 得到当前时刻最终隐藏状态
4.结构对比
- RNN:无门控,长短记忆都弱
- LSTM:3 个门,精度高、慢
- GRU:2 个门,速度快、工业常用

9.LSTM
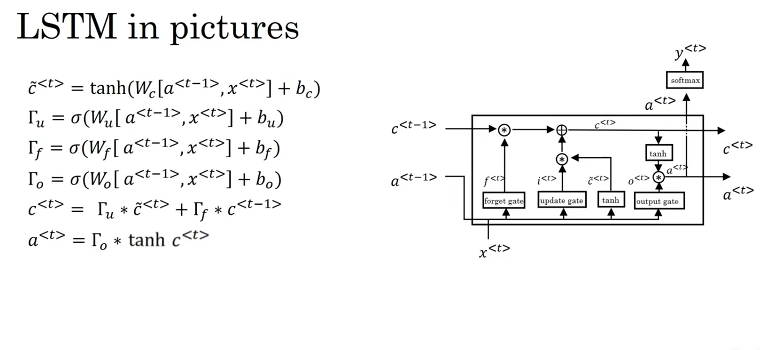
LSTM前向传播图:
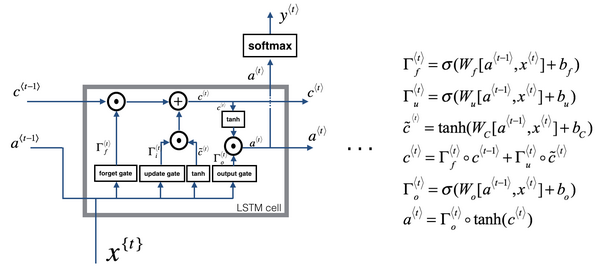
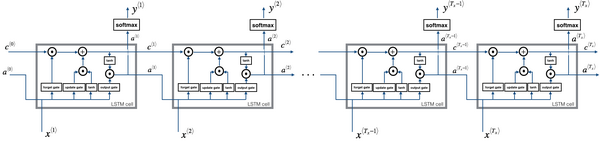
LSTM反向传播计算:
门求偏导:




参数求偏导 :




为了计算

需要各自对

求和。
最后,计算隐藏状态、记忆状态和输入的偏导数:



这就是LSTM ,我们什么时候应该用GRU ?什么时候用LSTM ?这里没有统一的准则。而且即使我先讲解了GRU ,在深度学习的历史上,LSTM 也是更早出现的,而GRU 是最近才发明出来的,它可能源于Pavia 在更加复杂的LSTM模型中做出的简化。研究者们在很多不同问题上尝试了这两种模型,看看在不同的问题不同的算法中哪个模型更好,所以这不是个学术和高深的算法,我才想要把这两个模型展示给你。
GRU的优点是这是个更加简单的模型,所以更容易创建一个更大的网络,而且它只有两个门,在计算性上也运行得更快,然后它可以扩大模型的规模。
但是LSTM 更加强大和灵活,因为它有三个门而不是两个。如果你想选一个使用,我认为LSTM 在历史进程上是个更优先的选择,所以如果你必须选一个,我感觉今天大部分的人还是会把LSTM 作为默认的选择来尝试。虽然我认为最近几年GRU 获得了很多支持,而且我感觉越来越多的团队也正在使用GRU,因为它更加简单,而且还效果还不错,它更容易适应规模更加大的问题。
10.双向RNN
现在,你已经了解了大部分RNN 模型的关键的构件,还有两个方法可以让你构建更好的模型,其中之一就是双向RNN 模型,这个模型可以让你在序列的某点处不仅可以获取之前的信息,还可以获取未来的信息,我们会在这个视频里讲解。第二个就是深层的RNN ,我们会在下个视频里见到,现在先从双向RNN开始吧。
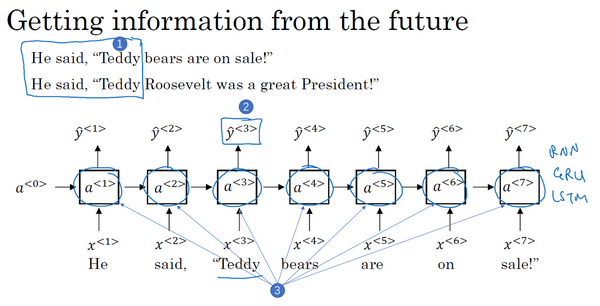
为了了解双向RNN 的动机,我们先看一下之前在命名实体识别中已经见过多次的神经网络。这个网络有一个问题,在判断第三个词Teddy (上图编号1所示)是不是人名的一部分时,光看句子前面部分是不够的,为了判断\hat y^{<3>}(上图编号2所示)是0还是1,除了前3个单词,你还需要更多的信息,因为根据前3个单词无法判断他们说的是Teddy熊 ,还是前美国总统Teddy Roosevelt ,所以这是一个非双向的或者说只有前向的RNN 。我刚才所说的总是成立的,不管这些单元(上图编号3所示)是标准的RNN 块,还是GRU 单元或者是LSTM单元,只要这些构件都是只有前向的。
那么一个双向的RNN 是如何解决这个问题的?下面解释双向RNN的工作原理。为了简单,我们用四个输入或者说一个只有4个单词的句子,这样输入只有4个,x^{<1>}到x^{<4>}。从这里开始的这个网络会有一个前向的循环单元叫做{\overrightarrow{a}}^{<1>},{\overrightarrow{a}}^{<2>},{\overrightarrow{a}}^{<3>}还有{\overrightarrow{a}}^{<4>},我在这上面加个向右的箭头来表示前向的循环单元,并且他们这样连接(下图编号1所示)。这四个循环单元都有一个当前输入

输入进去,得到预测的\hat y^{<1>},\hat y^{<2>},\hat y^{<3>}和\hat y^{<4>}。
到目前为止,我还没做什么,仅仅是把前面幻灯片里的RNN画在了这里,只是在这些地方画上了箭头。我之所以在这些地方画上了箭头是因为我们想要增加一个反向循环层,这里有个{\overleftarrow{a}}^{<1>},左箭头代表反向连接,{\overleftarrow{a}}^{<2>}反向连接,{\overleftarrow{a}}^{<3>}反向连接,{\overleftarrow{a}}^{<4>}反向连接,所以这里的左箭头代表反向连接。
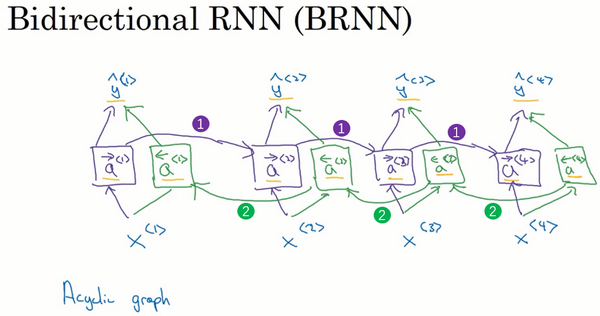
同样,我们把网络这样向上连接,这个

反向连接就依次反向向前连接(上图编号2所示)。这样,这个网络就构成了一个无环图。给定一个输入序列x^{<1>}到x^{<4>},这个序列首先计算前向的{\overrightarrow{a}}^{<1>},然后计算前向的{\overrightarrow{a}}^{<2>},接着{\overrightarrow{a}}^{<3>},{\overrightarrow{a}}^{<4>}。而反向序列从计算{\overleftarrow{a}}^{<4>}开始,反向进行,计算反向的{\overleftarrow{a}}^{<3>}。你计算的是网络激活值,这不是反向而是前向的传播,而图中这个前向传播一部分计算是从左到右,一部分计算是从右到左。计算完了反向的{\overleftarrow{a}}^{<3>},可以用这些激活值计算反向的{\overleftarrow{a}}^{<2>},然后是反向的{\overleftarrow{a}}^{<1>},把所有这些激活值都计算完了就可以计算预测结果了。
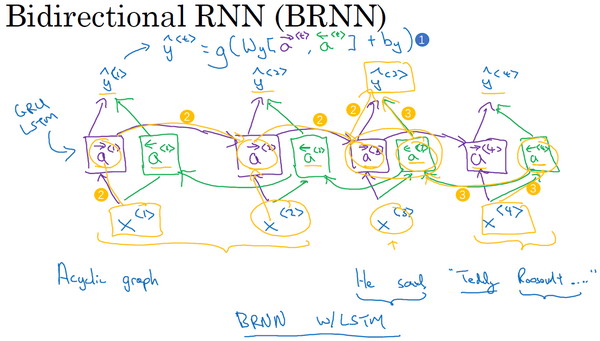
举个例子,为了预测结果,你的网络会有如\hat y^{<t>},\hat y^{<t>} =g(W_{g}\left\lbrack {\overrightarrow{a}}^{< t >},{\overleftarrow{a}}^{< t >} \right\rbrack +b_{y})(上图编号1所示)。比如你要观察时间3这里的预测结果,信息从x^{<1>}过来,流经这里,前向的{\overrightarrow{a}}^{<1>}到前向的{\overrightarrow{a}}^{<2>},这些函数里都有表达,到前向的{\overrightarrow{a}}^{<3>}再到\hat y^{<3>}(上图编号2所示的路径),所以从x^{<1>},x^{<2>},x^{<3>}来的信息都会考虑在内,而从x^{<4>}来的信息会流过反向的{\overleftarrow{a}}^{<4>},到反向的{\overleftarrow{a}}^{<3>}再到\hat y^{<3>}(上图编号3所示的路径)。这样使得时间3的预测结果不仅输入了过去的信息,还有现在的信息,这一步涉及了前向和反向的传播信息以及未来的信息。给定一个句子"He said Teddy Roosevelt... "来预测Teddy是不是人名的一部分,你需要同时考虑过去和未来的信息。
这就是双向循环神经网络,并且这些基本单元不仅仅是标准RNN 单元,也可以是GRU 单元或者LSTM 单元。事实上,很多的NLP 问题,对于大量有自然语言处理问题的文本,有LSTM 单元的双向RNN 模型是用的最多的。所以如果有NLP 问题,并且文本句子都是完整的,首先需要标定这些句子,一个有LSTM 单元的双向RNN模型,有前向和反向过程是一个不错的首选。
以上就是双向RNN 的内容,这个改进的方法不仅能用于基本的RNN 结构,也能用于GRU 和LSTM 。通过这些改变,你就可以用一个用RNN 或GRU 或LSTM 构建的模型,并且能够预测任意位置,即使在句子的中间,因为模型能够考虑整个句子的信息。这个双向RNN 网络模型的缺点就是你需要完整的数据的序列,你才能预测任意位置。比如说你要构建一个语音识别系统,那么双向RNN 模型需要你考虑整个语音表达,但是如果直接用这个去实现的话,你需要等待这个人说完,然后获取整个语音表达才能处理这段语音,并进一步做语音识别。对于实际的语音识别的应用通常会有更加复杂的模块,而不是仅仅用我们见过的标准的双向RNN 模型。但是对于很多自然语言处理的应用,如果你总是可以获取整个句子,这个标准的双向RNN算法实际上很高效。
11.深度RNN
目前你学到的不同RNN 的版本,每一个都可以独当一面。但是要学习非常复杂的函数,通常我们会把RNN 的多个层堆叠在一起构建更深的模型。这节视频里我们会学到如何构建这些更深的RNN。
一个标准的神经网络,首先是输入

,然后堆叠上隐含层,所以这里应该有激活值,比如说第一层是

,接着堆叠上下一层,激活值

,可以再加一层

,然后得到预测值

。深层的RNN网络跟这个有点像,用手画的这个网络(下图编号1所示),然后把它按时间展开就是了,我们看看。
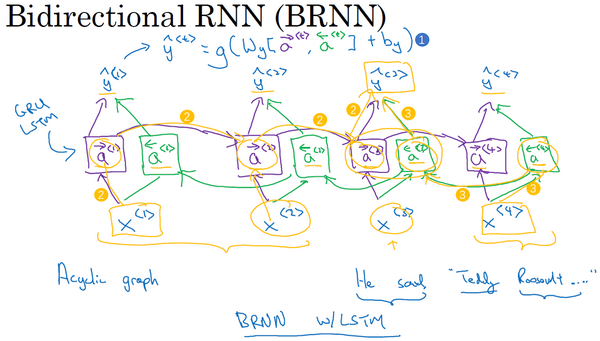
这是我们一直见到的标准的RNN (上图编号3所示方框内的RNN),只是我把这里的符号稍微改了一下,不再用原来的a^{<0 >}表示0时刻的激活值了,而是用a^{\lbrack 1\rbrack <0>}来表示第一层(上图编号4所示),所以我们现在用a^{\lbrack l\rbrack <t>}来表示第l层的激活值,这个

表示第

个时间点,这样就可以表示。第一层第一个时间点的激活值a^{\lbrack 1\rbrack <1>},这(a^{\lbrack 1\rbrack <2>})就是第一层第二个时间点的激活值,a^{\lbrack 1\rbrack <3>}和a^{\lbrack 1\rbrack <4>}。然后我们把这些(上图编号4方框内所示的部分)堆叠在上面,这就是一个有三个隐层的新的网络。
我们看个具体的例子,看看这个值(a^{\lbrack 2\rbrack <3>},上图编号5所示)是怎么算的。激活值a^{\lbrack 2\rbrack <3>}有两个输入,一个是从下面过来的输入(上图编号6所示),还有一个是从左边过来的输入(上图编号7所示),a^{\lbrack 2\rbrack < 3 >} = g(W_{a}^{\left\lbrack 2 \right\rbrack}\left\lbrack a^{\left\lbrack 2 \right\rbrack < 2 >},a^{\left\lbrack 1 \right\rbrack < 3 >} \right\rbrack + b_{a}^{\left\lbrack 2 \right\rbrack}),这就是这个激活值的计算方法。参数

和

在这一层的计算里都一样,相对应地第一层也有自己的参数

和

。
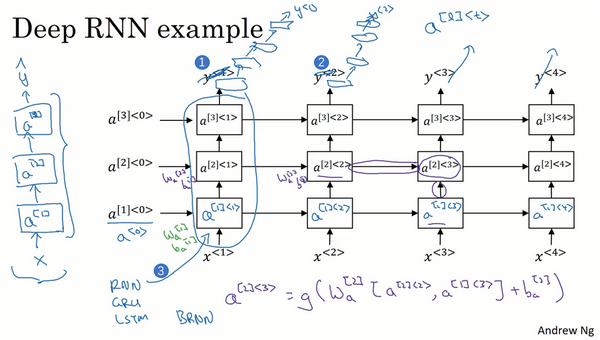
对于像左边这样标准的神经网络,你可能见过很深的网络,甚至于100层深,而对于RNN 来说,有三层就已经不少了。由于时间的维度,RNN 网络会变得相当大,即使只有很少的几层,很少会看到这种网络堆叠到100层。但有一种会容易见到,就是在每一个上面堆叠循环层,把这里的输出去掉(上图编号1所示),然后换成一些深的层,这些层并不水平连接,只是一个深层的网络,然后用来预测y^{<1>}。同样这里(上图编号2所示)也加上一个深层网络,然后预测y^{<2>}。这种类型的网络结构用的会稍微多一点,这种结构有三个循环单元,在时间上连接,接着一个网络在后面接一个网络,当然y^{<3>}和y^{<4>}也一样,这是一个深层网络,但没有水平方向上的连接,所以这种类型的结构我们会见得多一点。通常这些单元(上图编号3所示)没必要非是标准的RNN ,最简单的RNN 模型,也可以是GRU 单元或者LSTM 单元,并且,你也可以构建深层的双向RNN 网络。由于深层的RNN训练需要很多计算资源,需要很长的时间,尽管看起来没有多少循环层,这个也就是在时间上连接了三个深层的循环层,你看不到多少深层的循环层,不像卷积神经网络一样有大量的隐含层。
Week2:自然语言处理与词嵌入(Natural Language Processing and Word Embeddings)
1.词表示
上周我们学习了RNN 、GRU 单元和LSTM 单元。本周你会看到我们如何把这些知识用到NLP 上,用于自然语言处理,深度学习已经给这一领域带来了革命性的变革。其中一个很关键的概念就是词嵌入(word embeddings ),这是语言表示的一种方式,可以让算法自动的理解一些类似的词,比如男人对女人,比如国王对王后,还有其他很多的例子。通过词嵌入的概念你就可以构建NLP应用了,即使你的模型标记的训练集相对较小。这周的最后我们会消除词嵌入的偏差,就是去除不想要的特性,或者学习算法有时会学到的其他类型的偏差。
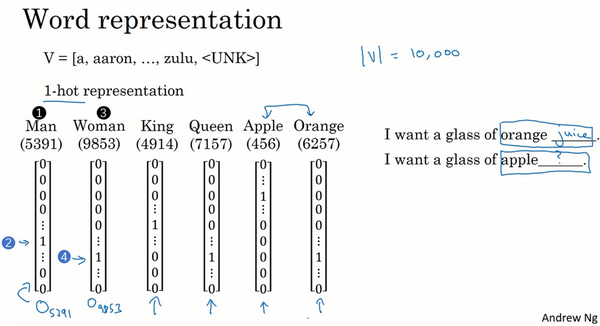
现在我们先开始讨论词汇表示,目前为止我们一直都是用词汇表来表示词,上周提到的词汇表,可能是10000个单词,我们一直用one-hot 向量来表示词。比如如果man(上图编号1所示)在词典里是第5391个,那么就可以表示成一个向量,只在第5391处为1(上图编号2所示),我们用

代表这个量,这里的

代表one-hot 。接下来,如果woman是编号9853(上图编号3所示),那么就可以用

来表示,这个向量只在9853处为1(上图编号4所示),其他为0,其他的词king 、queen 、apple 、orange都可以这样表示出来这种表示方法的一大缺点就是它把每个词孤立起来,这样使得算法对相关词的泛化能力不强。
举个例子,假如你已经学习到了一个语言模型,当你看到"I want a glass of orange ___ ",那么下一个词会是什么?很可能是juice 。即使你的学习算法已经学到了"I want a glass of orange juice "这样一个很可能的句子,但如果看到"I want a glass of apple ___ ",因为算法不知道apple 和orange 的关系很接近,就像man 和woman ,king 和queen 一样。所以算法很难从已经知道的orange juice 是一个常见的东西,而明白apple juice 也是很常见的东西或者说常见的句子。这是因为任何两个one-hot 向量的内积都是0,如果你取两个向量,比如king 和queen ,然后计算它们的内积,结果就是0。如果用apple 和orange 来计算它们的内积,结果也是0。很难区分它们之间的差别,因为这些向量内积都是一样的,所以无法知道apple 和orange 要比king 和orange ,或者queen 和orange相似地多。
换一种表示方式会更好,如果我们不用one-hot 表示,而是用特征化的表示来表示每个词,man ,woman ,king ,queen ,apple ,orange或者词典里的任何一个单词,我们学习这些词的特征或者数值。
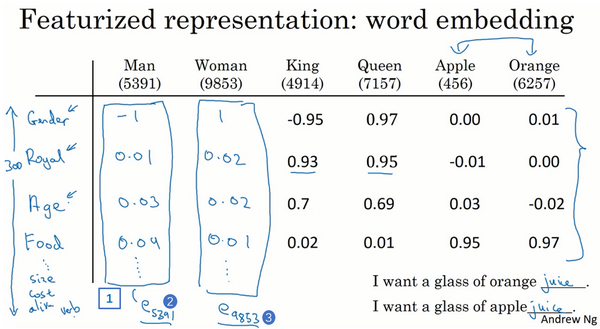
举个例子,对于这些词,比如我们想知道这些词与Gender (性别 )的关系。假定男性的性别为-1,女性的性别为+1,那么man 的性别值可能就是-1,而woman 就是-1。最终根据经验king 就是-0.95,queen 是+0.97,apple 和orange没有性别可言。
另一个特征可以是这些词有多Royal (高贵 ),所以这些词,man ,woman 和高贵没太关系,所以它们的特征值接近0。而king 和queen 很高贵,apple 和orange跟高贵也没太大关系。
那么Age (年龄 )呢?man 和woman 一般没有年龄的意思,也许man 和woman 隐含着成年人的意思,但也可能是介于young 和old 之间,所以它们(man 和woman )的值也接近0。而通常king 和queen 都是成年人,apple 和orange跟年龄更没什么关系了。
还有一个特征,这个词是否是Food (食物 ),man 不是食物,woman 不是食物,king 和queen 也不是,但apple 和orange是食物。
当然还可以有很多的其他特征,从Size (尺寸大小 ),Cost (花费多少 ),这个东西是不是alive (活的 ),是不是一个Action (动作 ),或者是不是Noun (名词 )或者是不是Verb (动词),还是其他的等等。
所以你可以想很多的特征,为了说明,我们假设有300个不同的特征,这样的话你就有了这一列数字(上图编号1所示),这里我只写了4个,实际上是300个数字,这样就组成了一个300维的向量来表示man这个词。接下来,我想用

这个符号来表示,就像这样(上图编号2所示)。同样这个300维的向量,我用

代表这个300维的向量用来表示woman 这个词(上图编号3所示),这些其他的例子也一样。现在,如果用这种表示方法来表示apple 和orange 这些词,那么apple 和orange 的这种表示肯定会非常相似,可能有些特征不太一样,因为orange 的颜色口味,apple 的颜色口味,或者其他的一些特征会不太一样,但总的来说apple 和orange 的大部分特征实际上都一样,或者说都有相似的值。这样对于已经知道orange juice 的算法很大几率上也会明白apple
juice这个东西,这样对于不同的单词算法会泛化的更好。
后面的几个视频,我们会找到一个学习词嵌入的方式,这里只是希望你能理解这种高维特征的表示能够比one-hot 更好的表示不同的单词。而我们最终学习的特征不会像这里一样这么好理解,没有像第一个特征是性别,第二个特征是高贵,第三个特征是年龄等等这些,新的特征表示的东西肯定会更难搞清楚。尽管如此,接下来要学的特征表示方法却能使算法高效地发现apple 和orange 会比king 和orange ,queen 和orange更加相似。
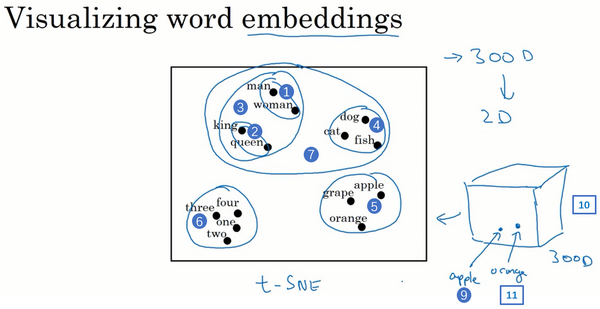
如果我们能够学习到一个300维的特征向量,或者说300维的词嵌入,通常我们可以做一件事,把这300维的数据嵌入到一个二维空间里,这样就可以可视化了。常用的可视化算法是t-SNE算法 ,来自于Laurens van der Maaten 和 Geoff Hinton 的论文。如果观察这种词嵌入的表示方法,你会发现man 和woman 这些词聚集在一块(上图编号1所示),king 和queen聚集在一块(上图编号2所示),这些都是人,也都聚集在一起(上图编号3所示)。动物都聚集在一起(上图编号4所示),水果也都聚集在一起(上图编号5所示),像1、2、3、4这些数字也聚集在一起(上图编号6所示)。如果把这些生物看成一个整体,他们也聚集在一起(上图编号7所示)。
在网上你可能会看到像这样的图用来可视化,300维或者更高维度的嵌入。希望你能有个整体的概念,这种词嵌入算法对于相近的概念,学到的特征也比较类似,在对这些概念可视化的时候,这些概念就比较相似,最终把它们映射为相似的特征向量。这种表示方式用的是在300维空间里的特征表示,这叫做嵌入(embeddings )。之所以叫嵌入的原因是,你可以想象一个300维的空间,我画不出来300维的空间,这里用个3维的代替(上图编号8所示)。现在取每一个单词比如orange ,它对应一个3维的特征向量,所以这个词就被嵌在这个300维空间里的一个点上了(上图编号9所示),apple 这个词就被嵌在这个300维空间的另一个点上了(上图编号10所示)。为了可视化,t-SNE算法把这个空间映射到低维空间,你可以画出一个2维图像然后观察,这就是这个术语嵌入的来源。
2.词嵌入应用
一、基本概念
1.定义
把自然语言里的单词 ,映射成低维、稠密、实数型向量 ,让计算机能理解文字语义,是 NLP 深度学习的底层基础。
2.为什么不用独热编码(One-Hot)
- 独热:一个单词对应只有一位为 1,其余全 0
- 缺点
-
- 维度极高,词汇量大就维度爆炸
-
- 向量极度稀疏,浪费算力
-
- 没有任何语义关系,词语之间无距离概念
- 举例:苹果、香蕉、橘子独热向量毫无关联
3.词嵌入优势
- 维度可控(常见 50/100/200/300 维)
- 稠密向量,信息密度高
- 语义相似 → 向量空间距离近
- 支持向量运算:国王 - 男人 + 女人≈女王
二、核心原理
1.核心思想
同一个上下文里经常一起出现的词,语义越相近,向量越接近
通过上下文预测的任务,自动学习单词含义。
2.向量含义
词向量每一维没有人工定义含义,是模型自动学到的语义特征:
- 有的维度代表性别
- 有的维度代表职业
- 有的维度代表情绪、动作、物品属性等
三、两大训练模型(Word2Vec)
1.CBOW 连续词袋模型
输入:周围上下文单词 → 输出:预测中心词
- 输入:窗口内多个周边词
- 目标:猜出中间是什么词
- 特点
-
- 训练速度快
-
- 小数据集效果好
-
- 对高频词友好
2.Skip-Gram 跳元模型
输入:中心单词 → 输出:预测周围上下文词
- 输入:单个中心词
- 目标:猜出它前后会出现哪些词
- 特点
-
- 大数据集表现更好
-
- 擅长学习低频词、生僻词
-
- 日常工业使用更多
3.训练流程统一步骤
- 对语料分词,建立全局词汇表
- 设定滑动窗口大小,截取上下文
- 初始化随机词向量矩阵
- 搭建简单神经网络做预测
- 反向传播不断更新词向量
- 训练结束,取出矩阵即为词嵌入向量表
四、数学简单理解
- 词向量矩阵:

-
- V:词汇总数
-
- d:词向量维度
- 查词向量:单词编号索引矩阵一行,直接取出向量
- 句子输入流程: 分词 → 转词 ID → 查表得到词向量 → 拼接送入 RNN/GRU/LSTM/Transformer
五、主流词嵌入类型
- Word2Vec 最经典,静态词向量,无上下文区分
- GloVe 结合全局词共现统计 + 局部上下文,效果优于 Word2Vec
- FastText 加入子词特征,能训练未登录词、形近词
- 动态词嵌入(主流现在) ELMo、BERT、RoBERTa 同一单词不同上下文生成不同向量,解决一词多义
六、优缺点
1.优点
- 把文字转为模型可计算数值
- 自动学习语义、语法、搭配关系
- 大幅降低输入维度,提升训练效率
- 可迁移预训练向量,小样本也能用
2.缺点(静态词嵌入通病)
- 无法解决一词多义 例:
bat蝙蝠 / 球棒,bank银行 / 河岸共用一个向量
- 向量固定,不随语境变化
- 无法捕捉长距离深层语义
七、在 RNN/GRU 中完整使用流程
- 文本数据分词
- 映射为单词数字索引
- 进入Embedding 嵌入层,查表转为词向量
- 词向量序列依次送入 GRU/RNN
- GRU 提取时序语义特征
- 最后接全连接层完成分类、预测、生成等任务
3.词嵌入的特性
- 稠密低维性
- 区别于独热稀疏高维
- 单词映射成低维实数稠密向量(50/100/300 维)
- 参数量小、计算高效,避免维度灾难
- 语义相似性(最核心)
- 语义越相近,向量空间距离越近
- 近义词、同类词向量聚集在一起
- 例:猫、狗、宠物向量距离很近
- 具备语义推理能力
词向量支持线性代数运算
- 国王 - 男人 + 女人 ≈ 女王
- 北京 - 中国 + 日本 ≈ 东京 能学到性别、国别、职业、时态等抽象关系
- 上下文关联性
- 训练依靠窗口上下文共现
- 经常一起出现的词,向量相似度高
- 自动学习词语搭配、语序习惯
4.词嵌入学习
假如你在构建一个语言模型,并且用神经网络来实现这个模型。于是在训练过程中,你可能想要你的神经网络能够做到比如输入:"I want a glass of orange ___. ",然后预测这句话的下一个词。在每个单词下面,我都写上了这些单词对应词汇表中的索引。实践证明,建立一个语言模型是学习词嵌入的好方法,我提出的这些想法是源于Yoshua Bengio ,Rejean Ducharme ,Pascal Vincent ,Rejean Ducharme ,Pascal Vincent 还有Christian Jauvin。
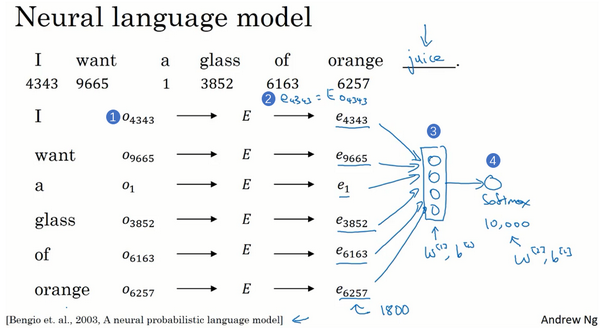
下面我将介绍如何建立神经网络来预测序列中的下一个单词,让我为这些词列一个表格,"I want a glass of orange ",我们从第一个词I 开始,建立一个one-hot 向量表示这个单词I 。这是一个one-hot向量(上图编号1所示),在第4343个位置是1,它是一个10,000维的向量。然后要做的就是生成一个参数矩阵

,然后用

乘以

,得到嵌入向量

,这一步意味着

是由矩阵

乘以one-hot 向量得到的(上图编号2所示)。然后我们对其他的词也做相同的操作,单词want在第9665个,我们将

与这个one-hot向量(

)相乘得到嵌入向量

。对其他单词也是一样,a 是字典中的第一个词,因为a是第一个字母,由

得到

。同样地,其他单词也这样操作。
于是现在你有许多300维的嵌入向量。我们能做的就是把它们全部放进神经网络中(上图编号3所示),经过神经网络以后再通过softmax 层(上图编号4所示),这个softmax 也有自己的参数,然后这个softmax 分类器会在10,000个可能的输出中预测结尾这个单词。假如说在训练集中有juice 这个词,训练过程中softmax 的目标就是预测出单词juice,就是结尾的这个单词。这个隐藏层(上图编号3所示)有自己的参数,我这里用

和

来表示,这个softmax层(上图编号4所示)也有自己的参数

和

。如果它们用的是300维大小的嵌入向量,而这里有6个词,所以用6×300,所以这个输入会是一个1800维的向量,这是通过将这6个嵌入向量堆在一起得到的。
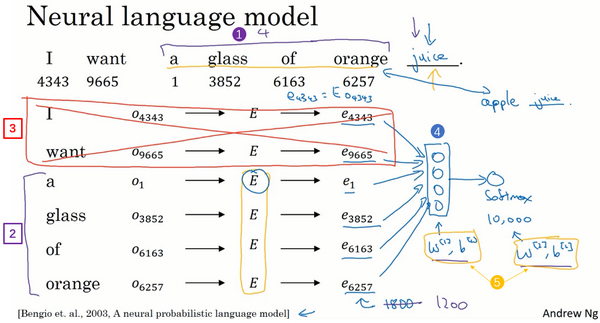
实际上更常见的是有一个固定的历史窗口,举个例子,你总是想预测给定四个单词(上图编号1所示)后的下一个单词,注意这里的4是算法的超参数。这就是如何适应很长或者很短的句子,方法就是总是只看前4个单词,所以说我只用这4个单词(上图编号2所示)而不去看这几个词(上图编号3所示)。如果你一直使用一个4个词的历史窗口,这就意味着你的神经网络会输入一个1200维的特征变量到这个层中(上图编号4所示),然后再通过softmax来预测输出,选择有很多种,用一个固定的历史窗口就意味着你可以处理任意长度的句子,因为输入的维度总是固定的。所以这个模型的参数就是矩阵

,对所有的单词用的都是同一个矩阵

,而不是对应不同的位置上的不同单词用不同的矩阵。然后这些权重(上图编号5所示)也都是算法的参数,你可以用反向传播来进行梯度下降来最大化训练集似然,通过序列中给定的4个单词去重复地预测出语料库中下一个单词什么。
事实上通过这个算法能很好地学习词嵌入,原因是,如果你还记得我们的orange jucie ,apple juice 的例子,在这个算法的激励下,apple 和orange 会学到很相似的嵌入,这样做能够让算法更好地拟合训练集,因为它有时看到的是orange juice ,有时看到的是apple juice 。如果你只用一个300维的特征向量来表示所有这些词,算法会发现要想最好地拟合训练集,就要使apple (苹果 )、orange (橘子 )、grape (葡萄 )和pear (梨 )等等,还有像durian (榴莲)这种很稀有的水果都拥有相似的特征向量。
这就是早期最成功的学习词嵌入,学习这个矩阵

的算法之一。现在我们先概括一下这个算法,看看我们该怎样来推导出更加简单的算法。现在我想用一个更复杂的句子作为例子来解释这些算法,假设在你的训练集中有这样一个更长的句子:"I want a glass of orange juice to go along with my cereal. "。我们在上个幻灯片看到的是算法预测出了某个单词juice,我们把它叫做目标词(下图编号1所示),它是通过一些上下文,在本例中也就是这前4个词(下图编号2所示)推导出来的。如果你的目标是学习一个嵌入向量,研究人员已经尝试过很多不同类型的上下文。如果你要建立一个语言模型,那么一般选取目标词之前的几个词作为上下文。但如果你的目标不是学习语言模型本身的话,那么你可以选择其他的上下文。
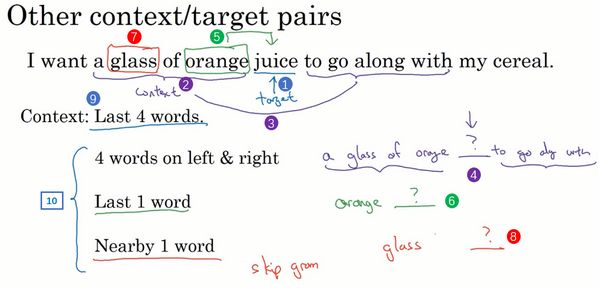
比如说,你可以提出这样一个学习问题,它的上下文是左边和右边的四个词,你可以把目标词左右各4个词作为上下文(上图编号3所示)。这就意味着我们提出了一个这样的问题,算法获得左边4个词,也就是a glass of orange ,还有右边四个词to go along with,然后要求预测出中间这个词(上图编号4所示)。提出这样一个问题,这个问题需要将左边的还有右边这4个词的嵌入向量提供给神经网络,就像我们之前做的那样来预测中间的单词是什么,来预测中间的目标词,这也可以用来学习词嵌入。
或者你想用一个更简单的上下文,也许只提供目标词的前一个词,比如只给出orange 这个词来预测orange 后面是什么(上图编号5所示),这将会是不同的学习问题。只给出一个词orange来预测下一个词是什么(上图编号6所示),你可以构建一个神经网络,只把目标词的前一个词或者说前一个词的嵌入向量输入神经网络来预测该词的下一个词。
还有一个效果非常好的做法就是上下文是附近一个单词,它可能会告诉你单词glass (上图编号7所示)是一个邻近的单词。或者说我看见了单词glass ,然后附近有一个词和glass 位置相近,那么这个词会是什么(上图编号8所示)?这就是用附近的一个单词作为上下文。我们将在下节视频中把它公式化,这用的是一种Skip-Gram模型的思想。这是一个简单算法的例子,因为上下文相当的简单,比起之前4个词,现在只有1个,但是这种算法依然能工作得很好。
5.Word2Vec
- CBOW
- Skip-gram
6.负采样
1.为什么需要负采样
Word2Vec 输出层是全词汇表分类
假设词表有 10 万个词,每次预测都要算10 万维 Softmax
- 计算量爆炸
- 训练极慢
核心痛点:正常只需要区分「正确上下文词」和「错误词」,没必要遍历全部词汇。
2.负采样思想
- 只保留1 个正样本(真实上下文词)
- 随机抽 K 个负样本(不是上下文的词)
- 只训练这
1+K个词,抛弃其余所有词
- 极大降低计算开销,加速收敛
常用取值:K=5~20
3.正负样本定义
以 Skip-Gram 举例:
- 中心词 w
- 正样本:窗口内真实相邻词(目标词)
- 负样本 :从词典里随机挑不在窗口内的词
训练目标:
让模型拉近正样本 ,推开负样本
4.损失函数(极简)
不再做多分类交叉熵,改用二元逻辑回归损失
对每个样本判断:是不是上下文词

-

:中心词向量
-

:正样本词向量
-

:负样本词向量
-

:sigmoid
含义:
- 让正样本相似度越高越好
- 让负样本相似度越低越好
7.GloVe 词向量 最全讲解(面试必背)
一、全称
Global Vectors for Word Representation
二、诞生背景
- Word2Vec 只看局部上下文窗口 ,缺少全局统计信息
- 传统共现矩阵维度太大、没法直接用
- GloVe 融合两者优点 : 全局词共现统计 + 局部上下文语义
三、核心思想
-
先统计整个语料,构建词 - 词共现矩阵

:词i出现在词j上下文的总次数
- 利用共现概率比值学习词之间语义关系
- 让词向量的点积 ≈ 共现概率对数
- 最终向量同时具备全局信息 + 局部语义
四、核心原理(最简)
设两个词向量

目标拟合:

-

:全局共现次数
- b:偏置项 用最小二乘损失拟合全局共现关系
五、训练逻辑
- 遍历全部文本,统计任意两词相邻次数,得到全局共现矩阵
- 给高频、低频词加权重衰减,平衡训练
- 迭代更新词向量,拟合共现对数关系
- 训练结束得到全局语义更强的词向量
六、和 Word2Vec 本质区别
- Word2Vec 局部滑动窗口预测,无全局统计 ,属于预测式
- GloVe 基于全局共现矩阵 建模,属于统计回归式
七、GloVe 优势
- 同时利用全局 + 局部信息,语义表达更强
- 语义推理能力更强(类比关系更准)
- 收敛稳定,泛化效果优于普通 Word2Vec
- 对低频次词语义学习更好
8. 词嵌入去偏
词嵌入去偏,核心是消除词向量中从训练语料继承的社会偏见(性别 / 种族 / 职业等),同时尽量保留原始语义,避免下游任务性能大幅下降。
一、为什么会有偏见(Bias)
词向量(Word2Vec/GloVe)从真实文本学习共现,会复刻社会刻板印象:
- 类比错误:
man:woman ≈ doctor:nurse(性别职业偏见)
- 关联偏差:
程序员→男性、护士→女性、领导→男性
- 危害:下游任务(招聘、医疗、司法)产生歧视性输出,违背公平性
二、偏见的本质(向量空间视角)
偏见不是随机噪声,而是向量空间中存在一个 "偏见方向"(如性别轴):
- 性别词对:
(he-she)、(male-female)、(man-woman)的向量差近似平行 ,共同构成性别偏见方向
- 中性词(如 doctor、teacher)在该方向上有投影,导致偏见关联
- 去偏目标:抹去中性词在偏见方向的分量,同时保留非偏见维度语义
三、经典去偏方法
1.Hard Debias(硬去偏,2016,最经典)
核心:PCA 找偏见子空间,投影消除
步骤:
- 选对立词对 (性别 / 种族),计算向量差并平均,得到偏见方向 b (b = \frac{1}{N}\sum_{i=1}^N (e_{a_i} - e_{b_i}))
- 对中性词 (如 doctor)做正交投影,消除 b 方向分量: (e_{\text{debiased}} = e - (e \cdot b)b)
- 对身份词 (如 she、Black)做均衡化 ,缩小偏见方向差异 优点:简单高效、速度快;缺点:强假设偏见是单一线性方向,易过删语义
2.INLP(迭代线性去偏,2020)
核心:训练分类器识别偏见→投影让分类器失效→迭代
步骤:
- 用线性分类器(如逻辑回归)预测偏见属性(性别 / 种族)
- 计算分类器权重的零空间投影矩阵 P,使分类器无法预测:(W(Px)=0)
- 迭代多次 ,逐步消除线性可检测偏见 优点:自动学习偏见方向,无需手动选词对;缺点:计算成本高
3.Soft Debias(软去偏)
核心:损失函数加入偏见惩罚项,训练时弱化偏见
在 GloVe/Word2Vec 损失中加偏见正则项:

- BiasPenalty:衡量词向量与偏见方向的关联度
- λ:平衡语义保留与去偏强度 优点:训练时同步去偏,适配大模型;缺点:易欠去偏或损失语义
4.数据增强去偏(CDA)
核心:反事实改写语料,打破偏见关联
- 性别词替换:
he↔she、man↔woman,生成均衡语料
- 职业词均衡:增加女性科学家、男性护士等样本 优点:从源头减少偏见,无向量修改;缺点:成本高、需大量人工
四、偏见度量(如何评估去偏效果)
1.WEFAT(词嵌入关联测试,最常用)
- 计算目标词集 (如职业)与偏见属性词集(男 / 女)的余弦相似度差
- 分数绝对值越小→偏见越小;0 为无偏
2.类比测试(Analogy)
- 检查
man:woman::X:Y是否符合公平预期
3.下游任务公平性
- 去偏后模型在招聘、简历筛选等任务中性别 / 种族歧视率是否下降
五、优缺点对比
|-------------|--------------|------------|
| 方法 | 优点 | 缺点 |
| Hard Debias | 简单、快速、易实现 | 线性假设、易过删语义 |
| INLP | 自动学偏见、效果好 | 计算慢、需多次迭代 |
| Soft Debias | 训练同步去偏、适配大模型 | 易欠去偏、调参难 |
| CDA | 源头去偏、无向量损失 | 成本高、依赖数据 |
Week3:序列模型和注意力机制(Sequence models & Attention mechanism)
1.基础模型
在这一周,你将会学习seq2seq (sequence to sequence )模型,从机器翻译到语音识别,它们都能起到很大的作用,从最基本的模型开始。之后你还会学习集束搜索(Beam search )和注意力模型(Attention Model),一直到最后的音频模型,比如语音。
现在就开始吧,比如你想通过输入一个法语句子,比如这句 "Jane visite I'Afrique en septembre. ",将它翻译成一个英语句子,"Jane is visiting Africa in September."。和之前一样,我们用x^{<1>} 一直到x^{< 5>}来表示输入的句子的单词,然后我们用y^{<1>}到y^{<6>}来表示输出的句子的单词,那么,如何训练出一个新的网络来输入序列

和输出序列

呢?
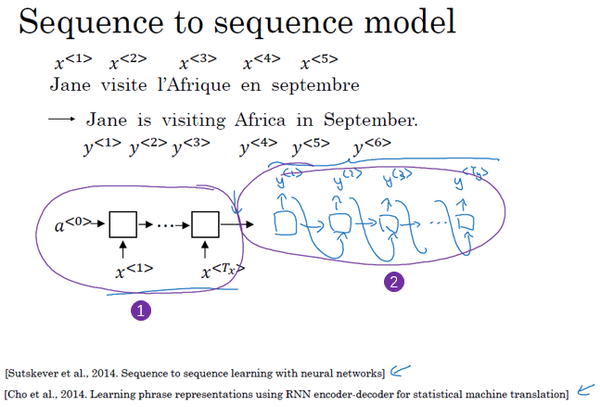
这里有一些方法,这些方法主要都来自于两篇论文,作者是Sutskever ,Oriol Vinyals 和 Quoc Le ,另一篇的作者是Kyunghyun Cho ,Bart van Merrienboer ,Caglar Gulcehre ,Dzmitry Bahdanau ,Fethi Bougares ,Holger Schwen 和 Yoshua Bengio。
首先,我们先建立一个网络,这个网络叫做编码网络(encoder network )(上图编号1所示),它是一个RNN 的结构, RNN 的单元可以是GRU 也可以是LSTM 。每次只向该网络中输入一个法语单词,将输入序列接收完毕后,这个RNN网络会输出一个向量来代表这个输入序列。之后你可以建立一个解码网络,我把它画出来(上图编号2所示),它以编码网络的输出作为输入,编码网络是左边的黑色部分(上图编号1所示),之后它可以被训练为每次输出一个翻译后的单词,一直到它输出序列的结尾或者句子结尾标记,这个解码网络的工作就结束了。和往常一样我们把每次生成的标记都传递到下一个单元中来进行预测,就像之前用语言模型合成文本时一样。
深度学习在近期最卓越的成果之一就是这个模型确实有效,在给出足够的法语和英语文本的情况下,如果你训练这个模型,通过输入一个法语句子来输出对应的英语翻译,这个模型将会非常有效。这个模型简单地用一个编码网络来对输入的法语句子进行编码,然后用一个解码网络来生成对应的英语翻译。
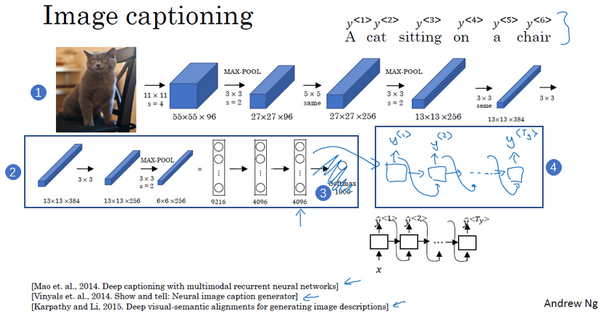
还有一个与此类似的结构被用来做图像描述,给出一张图片,比如这张猫的图片(上图编号1所示),它能自动地输出该图片的描述,一只猫坐在椅子上,那么你如何训练出这样的网络?通过输入图像来输出描述,像这个句子一样。
方法如下,在之前的卷积网络课程中,你已经知道了如何将图片输入到卷积神经网络中,比如一个预训练的AlexNet 结构(上图编号2方框所示),然后让其学习图片的编码,或者学习图片的一系列特征。现在幻灯片所展示的就是AlexNet 结构,我们去掉最后的softmax 单元(上图编号3所示),这个预训练的AlexNet 结构会给你一个4096维的特征向量,向量表示的就是这只猫的图片,所以这个预训练网络可以是图像的编码网络。现在你得到了一个4096维的向量来表示这张图片,接着你可以把这个向量输入到RNN中(上图编号4方框所示),RNN要做的就是生成图像的描述,每次生成一个单词,这和我们在之前将法语译为英语的机器翻译中看到的结构很像,现在你输入一个描述输入的特征向量,然后让网络生成一个输出序列,或者说一个一个地输出单词序列。
事实证明在图像描述领域,这种方法相当有效,特别是当你想生成的描述不是特别长时。据我所知,这种模型首先是由Junhua Mao ,Wei Xu ,Yi Yang ,Jiang Wang ,Zhiheng Huang 和Alan Yuille 提出的,尽管有几个团队都几乎在同一时间构造出了非常相似的模型,因为还有另外两个团队也在同一时间得出了相似的结论。我觉得有可能Mao 的团队和Oriol Vinyals ,Alexander Toshev ,Samy Bengio 和Dumitru Erhan ,还有Andrej Karpathy 和Fei-Fei Yi是同一个团队。
现在你知道了基本的seq2seq 模型是怎样运作的,以及image to sequence模型或者说图像描述模型是怎样运作的。不过这两个模型运作方式有一些不同,主要体现在如何用语言模型合成新的文本,并生成对应序列的方面。一个主要的区别就是你大概不会想得到一个随机选取的翻译,你想要的是最准确的翻译,或者说你可能不想要一个随机选取的描述,你想要的是最好的最贴切的描述,我们将在下节视频中介绍如何生成这些序列。
2. 选择最可能的句子
在seq2seq机器翻译模型和我们在第一周课程所用的语言模型之间有很多相似的地方,但是它们之间也有许多重要的区别,让我们来一探究竟。
你可以把机器翻译想成是建立一个条件语言模型,在语言模型中上方是一个我们在第一周所建立的模型,这个模型可以让你能够估计句子的可能性,这就是语言模型所做的事情。你也可以将它用于生成一个新的句子,如果你在图上的该处(下图编号1所示),有x^{<1>}和x^{<2>},那么在该例中x^{<2>} = y^{<1>},但是x^{<1>}、x^{<2>}等在这里并不重要。为了让图片看起来更简洁,我把它们先抹去,可以理解为x^{<1>}是一个全为0的向量,然后x^{<2>}、x^{<3>}等都等于之前所生成的输出,这就是所说的语言模型。
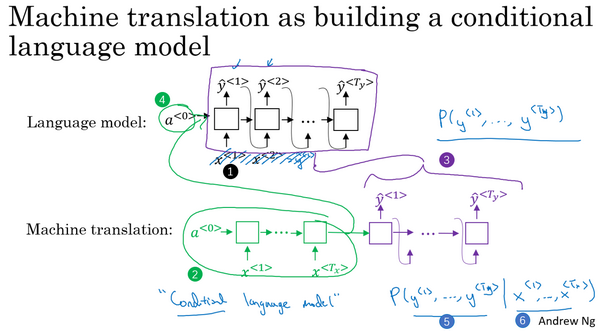
而机器翻译模型是下面这样的,我这里用两种不同的颜色来表示,即绿色和紫色,用绿色(上图编号2所示)表示encoder 网络,用紫色(上图编号3所示)表示decoder 网络。你会发现decoder 网络看起来和刚才所画的语言模型几乎一模一样,机器翻译模型其实和语言模型非常相似,不同在于语言模型总是以零向量(上图编号4所示)开始,而encoder 网络会计算出一系列向量(上图编号2所示)来表示输入的句子。有了这个输入句子,decoder 网络就可以以这个句子开始,而不是以零向量开始,所以我把它叫做条件语言模型(conditional language model )。相比语言模型,输出任意句子的概率,翻译模型会输出句子的英文翻译(上图编号5所示),这取决于输入的法语句子(上图编号6所示)。换句话说,你将估计一个英文翻译的概率,比如估计这句英语翻译的概率,"Jane is visiting Africa in September. ",这句翻译是取决于法语句子,"Jane visite I'Afrique en septembre.",这就是英语句子相对于输入的法语句子的可能性,所以它是一个条件语言模型。

现在,假如你想真正地通过模型将法语翻译成英文,通过输入的法语句子模型将会告诉你各种英文翻译所对应的可能性。

在这里是法语句子"Jane visite l'Afrique en septembre.",而它将告诉你不同的英语翻译所对应的概率。显然你不想让它随机地进行输出,如果你从这个分布中进行取样得到

,可能取样一次就能得到很好的翻译,"Jane is visiting Africa in September. "。但是你可能也会得到一个截然不同的翻译,"Jane is going to be visiting Africa in September. ",这句话听起来有些笨拙,但它不是一个糟糕的翻译,只是不是最好的而已。有时你也会偶然地得到这样的翻译,"In September, Jane will visit Africa. ",或者有时候你还会得到一个很糟糕的翻译,"Her African friend welcomed Jane in September."。所以当你使用这个模型来进行机器翻译时,你并不是从得到的分布中进行随机取样,而是你要找到一个英语句子

(上图编号1所示),使得条件概率最大化。所以在开发机器翻译系统时,你需要做的一件事就是想出一个算法,用来找出合适的

值,使得该项最大化,而解决这种问题最通用的算法就是束搜索(Beam Search),你将会在下节课见到它。
不过在了解束搜索之前,你可能会问一个问题,为什么不用贪心搜索(Greedy Search)呢?贪心搜索是一种来自计算机科学的算法,生成第一个词的分布以后,它将会根据你的条件语言模型挑选出最有可能的第一个词进入你的机器翻译模型中,在挑选出第一个词之后它将会继续挑选出最有可能的第二个词,然后继续挑选第三个最有可能的词,这种算法就叫做贪心搜索,但是你真正需要的是一次性挑选出整个单词序列,从y^{<1>}、y^{<2>}到y^{<T_{y}>}来使得整体的概率最大化。所以这种贪心算法先挑出最好的第一个词,在这之后再挑最好的第二词,然后再挑第三个,这种方法其实并不管用,为了证明这个观点,我们来考虑下面两种翻译。

第一串(上图编号1所示)翻译明显比第二个(上图编号2所示)好,所以我们希望机器翻译模型会说第一个句子的

比第二个句子要高,第一个句子对于法语原文来说更好更简洁,虽然第二个也不错,但是有些啰嗦,里面有很多不重要的词。但如果贪心算法挑选出了"Jane is "作为前两个词,因为在英语中going 更加常见,于是对于法语句子来说"Jane is going "相比"Jane is visiting "会有更高的概率作为法语的翻译,所以很有可能如果你仅仅根据前两个词来估计第三个词的可能性,得到的就是going,最终你会得到一个欠佳的句子,在

模型中这不是一个最好的选择。
我知道这种说法可能比较粗略,但是它确实是一种广泛的现象,当你想得到单词序列y^{<1>}、y^{<2>}一直到最后一个词总体的概率时,一次仅仅挑选一个词并不是最佳的选择。当然,在英语中各种词汇的组合数量还有很多很多,如果你的字典中有10,000个单词,并且你的翻译可能有10个词那么长,那么可能的组合就有10,000的10次方这么多,这仅仅是10个单词的句子,从这样大一个字典中来挑选单词,所以可能的句子数量非常巨大,不可能去计算每一种组合的可能性。所以这时最常用的办法就是用一个近似的搜索算法,这个近似的搜索算法做的就是它会尽力地,尽管不一定总会成功,但它将挑选出句子

使得条件概率最大化,尽管它不能保证找到的

值一定可以使概率最大化,但这已经足够了。
最后总结一下,在本视频中,你看到了机器翻译是如何用来解决条件语言模型问题的,这个模型和之前的语言模型一个主要的区别就是,相比之前的模型随机地生成句子,在该模型中你要找到最有可能的英语句子,最可能的英语翻译,但是可能的句子组合数量过于巨大,无法一一列举,所以我们需要一种合适的搜索算法,让我们在下节课中学习集束搜索。
3.束搜索 (Beam Search)
这节视频中你会学到集束搜索(beam search)算法,上节视频中我们讲了对于机器翻译来说,给定输入,比如法语句子,你不会想要输出一个随机的英语翻译结果,你想要一个最好的,最可能的英语翻译结果。对于语音识别也一样,给定一个输入的语音片段,你不会想要一个随机的文本翻译结果,你想要最好的,最接近原意的翻译结果,集束搜索就是解决这个最常用的算法。这节视频里,你会明白怎么把集束搜索算法应用到你自己的工作中,就用我们的法语句子的例子来试一下集束搜索吧。
"Jane visite l'Afrique en Septembre. "(法语句子),我们希望翻译成英语,"Jane is visiting Africa in September".(英语句子),集束搜索算法首先做的就是挑选要输出的英语翻译中的第一个单词。这里我列出了10,000个词的词汇表(下图编号1所示),为了简化问题,我们忽略大小写,所有的单词都以小写列出来。在集束搜索的第一步中我用这个网络部分,绿色是编码部分(下图编号2所示),紫色是解码部分(下图编号3所示),来评估第一个单词的概率值,给定输入序列

,即法语作为输入,第一个输出

的概率值是多少。
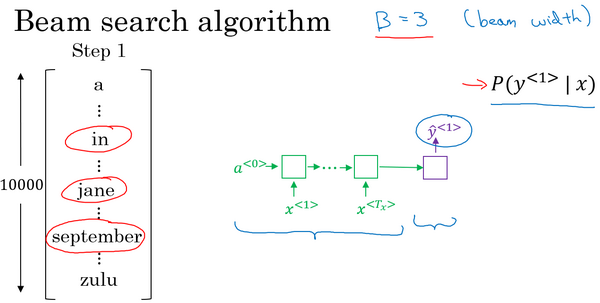
贪婪算法只会挑出最可能的那一个单词,然后继续。而集束搜索则会考虑多个选择,集束搜索算法会有一个参数B ,叫做集束宽(beam width )。在这个例子中我把这个集束宽设成3,这样就意味着集束搜索不会只考虑一个可能结果,而是一次会考虑3个,比如对第一个单词有不同选择的可能性,最后找到in 、jane 、september ,是英语输出的第一个单词的最可能的三个选项,然后集束搜索算法会把结果存到计算机内存里以便后面尝试用这三个词。如果集束宽设的不一样,如果集束宽这个参数是10的话,那么我们跟踪的不仅仅3个,而是10个第一个单词的最可能的选择。所以要明白,为了执行集束搜索的第一步,你需要输入法语句子到编码网络,然后会解码这个网络,这个softmax层(上图编号3所示)会输出10,000个概率值,得到这10,000个输出的概率值,取前三个存起来。
让我们看看集束搜索算法的第二步,已经选出了in 、jane 、september 作为第一个单词三个最可能的选择,集束算法接下来会针对每个第一个单词考虑第二个单词是什么,单词in 后面的第二个单词可能是a 或者是aaron ,我就是从词汇表里把这些词列了出来,或者是列表里某个位置,september ,可能是列表里的 visit ,一直到字母z ,最后一个单词是zulu(下图编号1所示)。
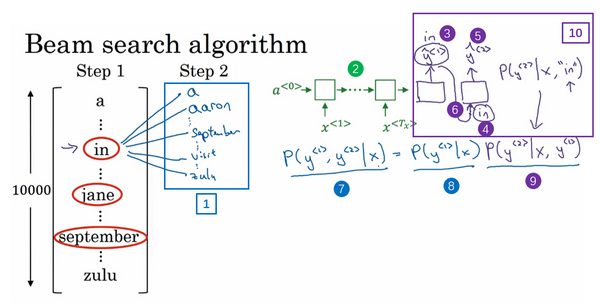
为了评估第二个词的概率值,我们用这个神经网络的部分,绿色是编码部分(上图编号2所示),而对于解码部分,当决定单词in 后面是什么,别忘了解码器的第一个输出y^{<1>},我把y^{<1>}设为单词in (上图编号3所示),然后把它喂回来,这里就是单词in (上图编号4所示),因为它的目的是努力找出第一个单词是in 的情况下,第二个单词是什么。这个输出就是y^{<2>}(上图编号5所示),有了这个连接(上图编号6所示),就是这里的第一个单词in (上图编号4所示)作为输入,这样这个网络就可以用来评估第二个单词的概率了,在给定法语句子和翻译结果的第一个单词in的情况下。
注意,在第二步里我们更关心的是要找到最可能的第一个和第二个单词对,所以不仅仅是第二个单词有最大的概率,而是第一个、第二个单词对有最大的概率(上图编号7所示)。按照条件概率的准则,这个可以表示成第一个单词的概率(上图编号8所示)乘以第二个单词的概率(上图编号9所示),这个可以从这个网络部分里得到(上图编号10所示),对于已经选择的in 、jane 、september这三个单词,你可以先保存这个概率值(上图编号8所示),然后再乘以第二个概率值(上图编号9所示)就得到了第一个和第二个单词对的概率(上图编号7所示)。
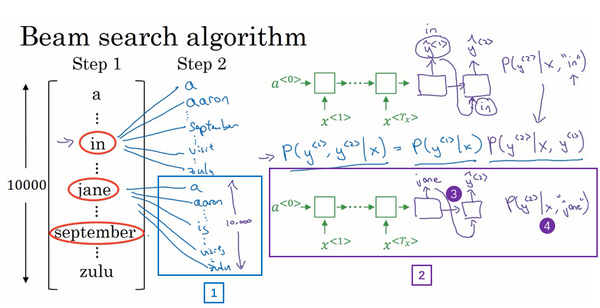
现在你已经知道在第一个单词是in的情况下如何评估第二个单词的概率,现在第一个单词是jane ,道理一样,句子可能是"jane a "、"jane aaron ",等等到"jane is "、"jane visits "等等(上图编号1所示)。你会用这个新的网络部分(上图编号2所示),我在这里画一条线,代表从y^{<1>},即jane ,y^{< 1 >}连接jane(上图编号3所示),那么这个网络部分就可以告诉你给定输入

和第一个词是jane下,第二个单词的概率了(上图编号4所示),和上面一样,你可以乘以P(y^{<1>}|x)得到P(y^{<1>},y^{<2>}|x)。
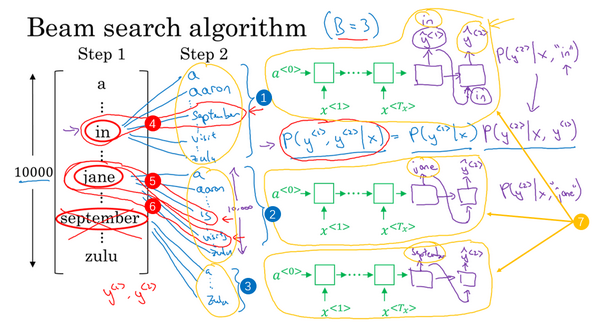
针对第二个单词所有10,000个不同的选择,最后对于单词september 也一样,从单词a 到单词zulu ,用这个网络部分,我把它画在这里。来看看如果第一个单词是september ,第二个单词最可能是什么。所以对于集束搜索的第二步,由于我们一直用的集束宽为3,并且词汇表里有10,000个单词,那么最终我们会有3乘以10,000也就是30,000个可能的结果,因为这里(上图编号1所示)是10,000,这里(上图编号2所示)是10,000,这里(上图编号3所示)是10,000,就是集束宽乘以词汇表大小,你要做的就是评估这30,000个选择。按照第一个词和第二个词的概率,然后选出前三个,这样又减少了这30,000个可能性,又变成了3个,减少到集束宽的大小。假如这30,000个选择里最可能的是"in September "(上图编号4所示)和"jane is "(上图编号5所示),以及"jane visits"(上图编号6所示),画的有点乱,但这就是这30,000个选择里最可能的三个结果,集束搜索算法会保存这些结果,然后用于下一次集束搜索。
注意一件事情,如果集束搜索找到了第一个和第二个单词对最可能的三个选择是"in September "或者"jane is "或者"jane visits ",这就意味着我们去掉了september作为英语翻译结果的第一个单词的选择,所以我们的第一个单词现在减少到了两个可能结果,但是我们的集束宽是3,所以还是有y^{<1>},y^{<2>}对的三个选择。
在我们进入集束搜索的第三步之前,我还想提醒一下因为我们的集束宽等于3,每一步我们都复制3个,同样的这种网络来评估部分句子和最后的结果,由于集束宽等于3,我们有三个网络副本(上图编号7所示),每个网络的第一个单词不同,而这三个网络可以高效地评估第二个单词所有的30,000个选择。所以不需要初始化30,000个网络副本,只需要使用3个网络的副本就可以快速的评估softmax的输出,即y^{<2>}的10,000个结果。
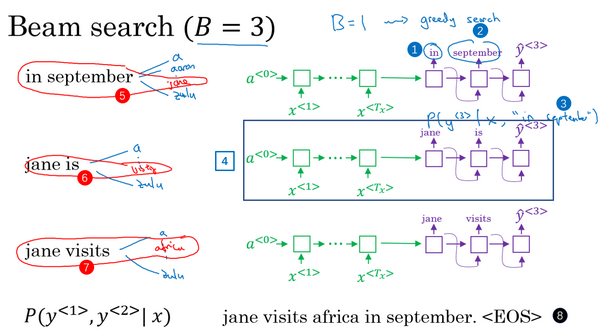
让我们快速解释一下集束搜索的下一步,前面说过前两个单词最可能的选择是"in September "和"jane is "以及"jane visits",对于每一对单词我们应该保存起来,给定输入

,即法语句子作为

的情况下,y^{<1>}和y^{<2>}的概率值和前面一样,现在我们考虑第三个单词是什么,可以是"in September a ",可以是"in September aaron ",一直到"in September zulu "。为了评估第三个单词可能的选择,我们用这个网络部分,第一单词是in (上图编号1所示),第二个单词是september(上图编号2所示),所以这个网络部分可以用来评估第三个单词的概率,在给定输入的法语句子

和给定的英语输出的前两个单词"in September "情况下(上图编号3所示)。对于第二个片段来说也一样,就像这样一样(上图编号4所示),对于"jane visits "也一样,然后集束搜索还是会挑选出针对前三个词的三个最可能的选择,可能是"in september jane "(上图编号5所示),"Jane is visiting "也很有可能(上图编号6所示),也很可能是"Jane visits Africa"(上图编号7所示)。
然后继续,接着进行集束搜索的第四步,再加一个单词继续,最终这个过程的输出一次增加一个单词,集束搜索最终会找到"Jane visits africa in september"这个句子,终止在句尾符号(上图编号8所示),用这种符号的系统非常常见,它们会发现这是最有可能输出的一个英语句子。在本周的练习中,你会看到更多的执行细节,同时,你会运用到这个集束算法,在集束宽为3时,集束搜索一次只考虑3个可能结果。注意如果集束宽等于1,只考虑1种可能结果,这实际上就变成了贪婪搜索算法,上个视频里我们已经讨论过了。但是如果同时考虑多个,可能的结果比如3个,10个或者其他的个数,集束搜索通常会找到比贪婪搜索更好的输出结果。
你已经了解集束搜索是如何工作的了,事实上还有一些额外的提示和技巧的改进能够使集束算法更高效,我们在下个视频中一探究竟。
4.BLEU
1.作用
用来自动评判生成句子好不好
对比:模型生成句 vs 人工标准参考句
数值越高 = 翻译 / 生成质量越好
2.核心思想
统计n 元词组重合度
- 1-gram:单个词匹配
- 2-gram:连续两个词匹配
- 3-gram、4-gram 越长越看重语序流畅度
3.两大组成
- 精确率 Precision
统计生成句子里,出现在参考句中的n 元词组占比
问题:容易出现短句凑高分(只翻几个关键词)
- 简短惩罚 BP(Brevity Penalty)
专门打压过短句子
- 生成句太短 → 直接扣分
- 长度接近参考句 → 不惩罚
4.计算公式

- (p_n):n 元精确率
- (w_n):权重(常用均分)
- BP:短句惩罚因子
5.取值范围
- 范围:0 ~ 1
- 越接近 1:和标准答案越像,质量越高
- 日常翻译:0.3~0.6 属于不错水平
6.优点
- 计算快、全自动、不用人工打分
- 通用标准,论文 / 比赛统一用
- 支持多参考译文对比
- 适合批量评测模型
7.致命缺点
- 只看表面词组匹配,不懂语义 语序颠倒、意思相反也可能高分
- 不考虑同义词、转述 意思一样用词不同直接低分
- 无法评估流畅度、逻辑性、语法错误
- 对口语、创意生成、对话评测效果很差
- 重复用词容易拉高分数
5.注意力机制
6.Transformer
Transformer模型详解,Attention is all you need_哔哩哔哩_bilibili
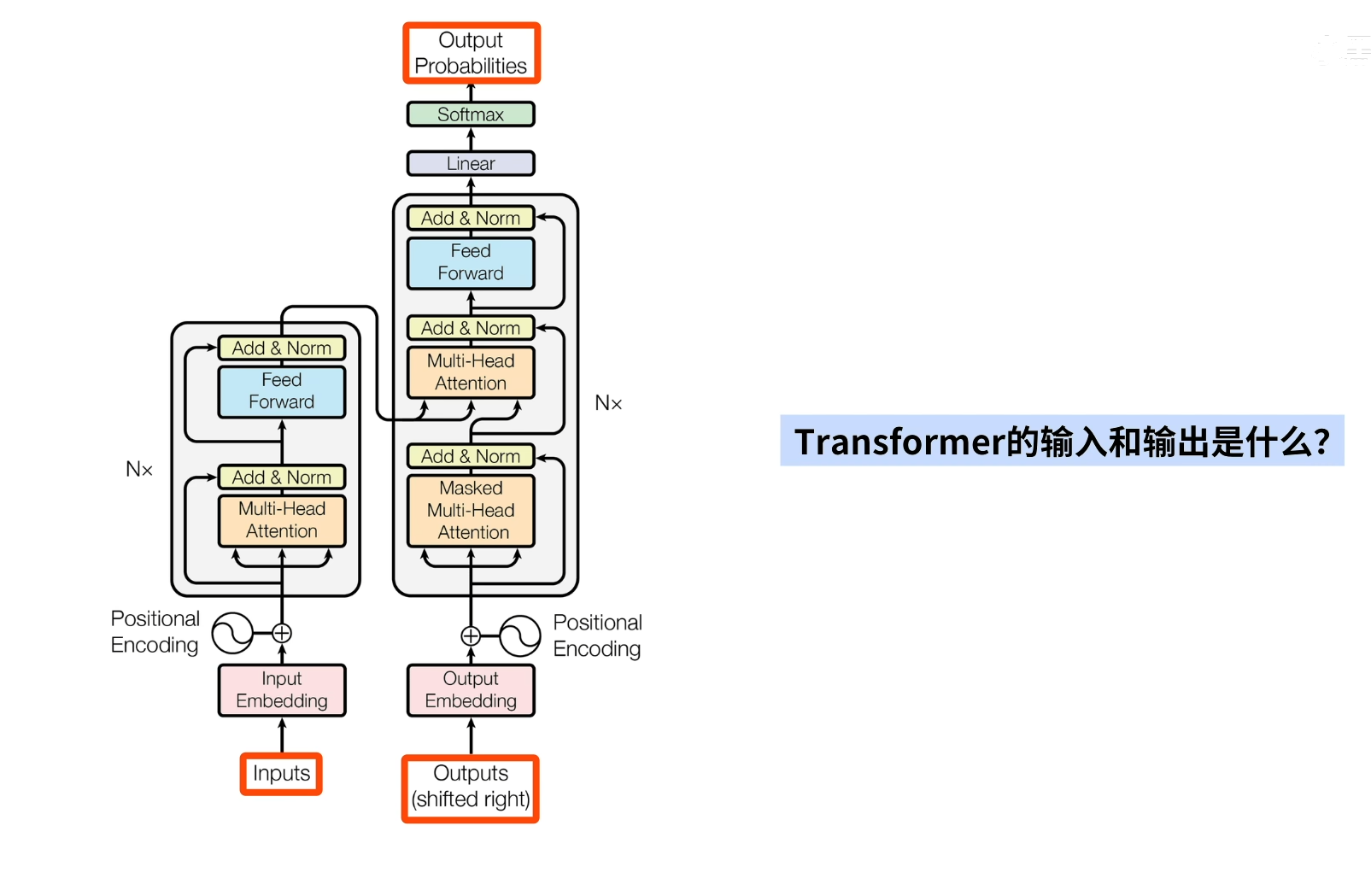
大模型基础 完整版.pdf 输入:inputs、outputs(shifted right) 输出:output probabilities
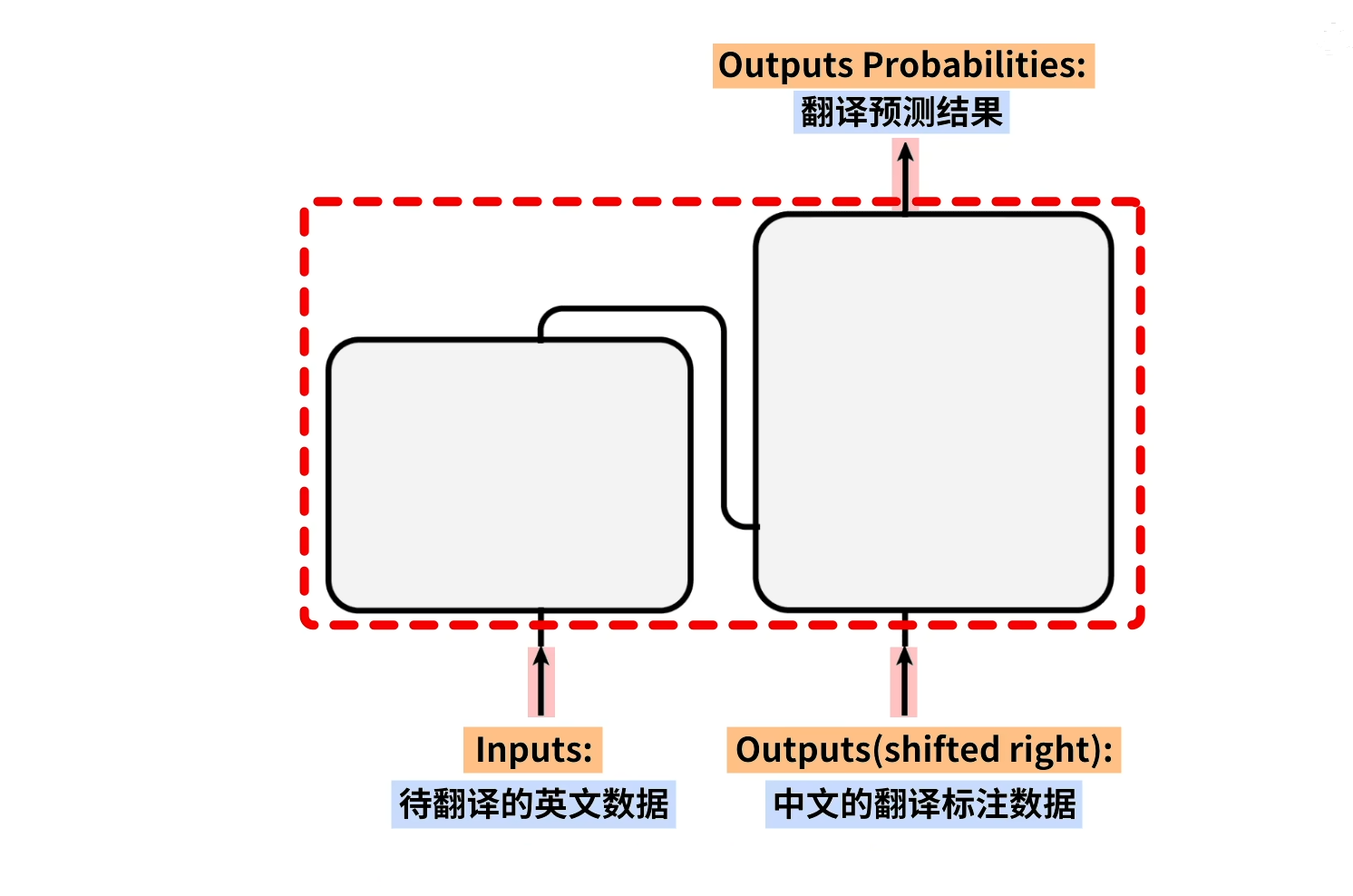
:::tips 假设要翻译一个句子,这里inputs输入的就是待翻译的英文数据,outputs(shifted right)输入的就是中文翻译标注数据。然后outputs probabilities输出的便是翻译预测的结果(注意:这里的outputs probabilities是错误的代表模型实际的输出可能会和中文翻译标注数据有出入)。 :::
:::tips inputs和outputs(shifted right)输入的数据会被词向量层处理 :::
:::tips 这里inputs的"Are you OK?"被转化成为一个4x4的矩阵,每一行代表一个单词。 :::
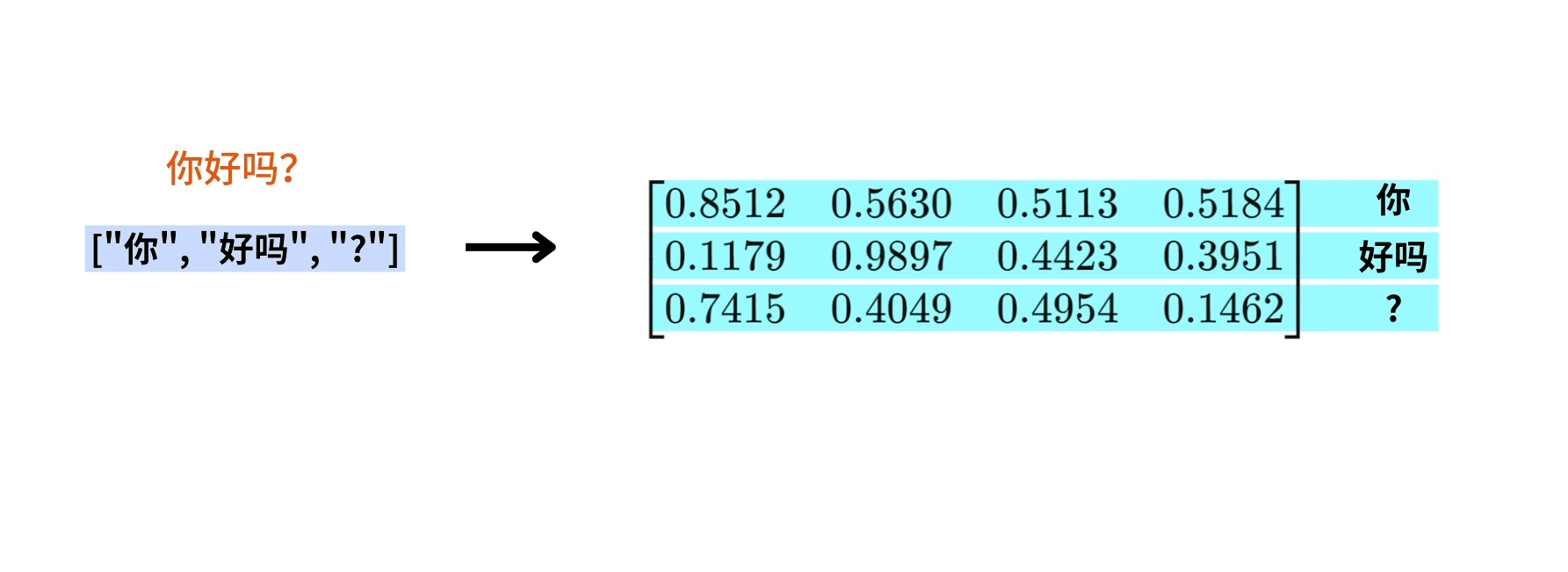
:::tips 相同的,outputs(shifted right)的"你好吗?"也会被转化为向量。 ::: positional encoding
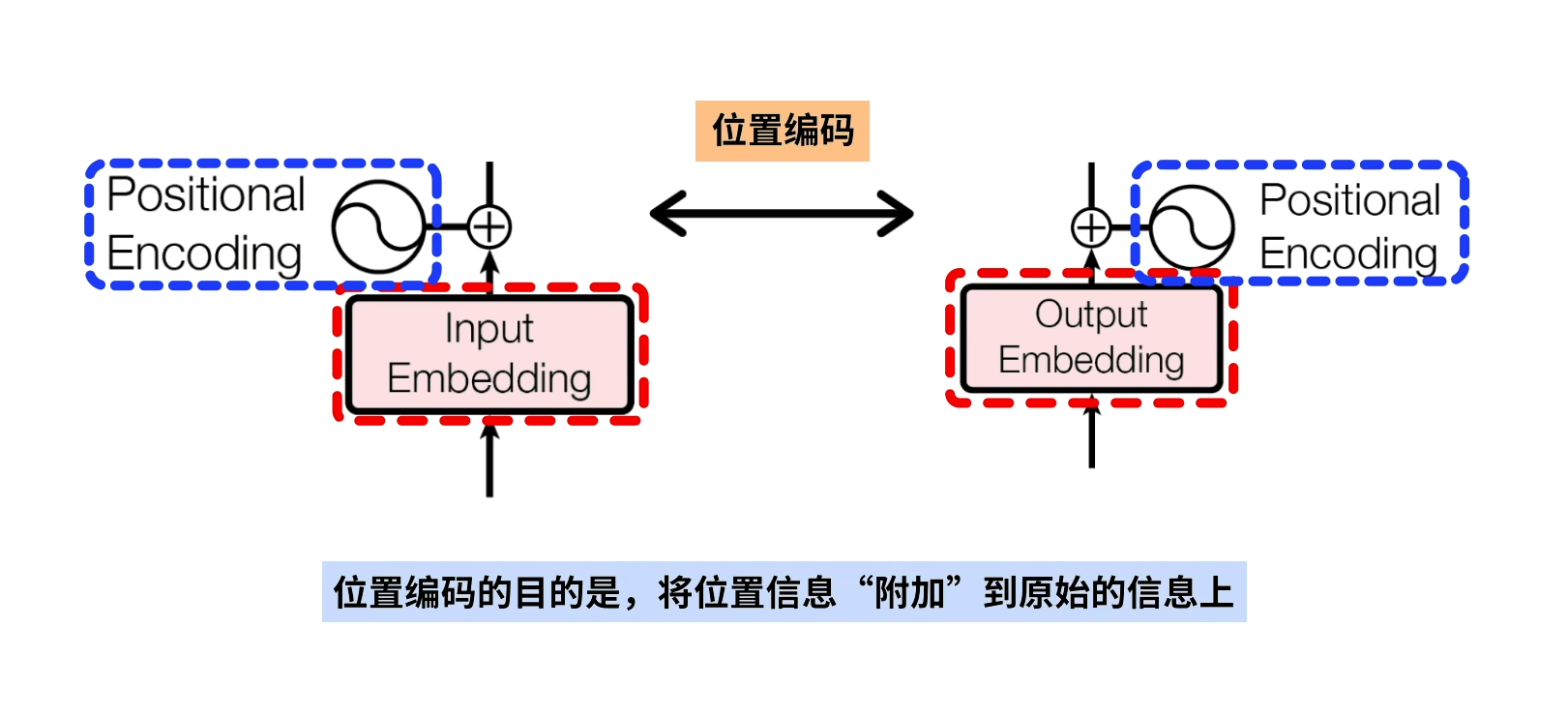
:::tips 如图所示,这就是positional encoding干的事情,embedding之后每个词会转化为他所对应的哪些向量,然后各个词(向量)的位置信息靠positional encoding完成。 :::
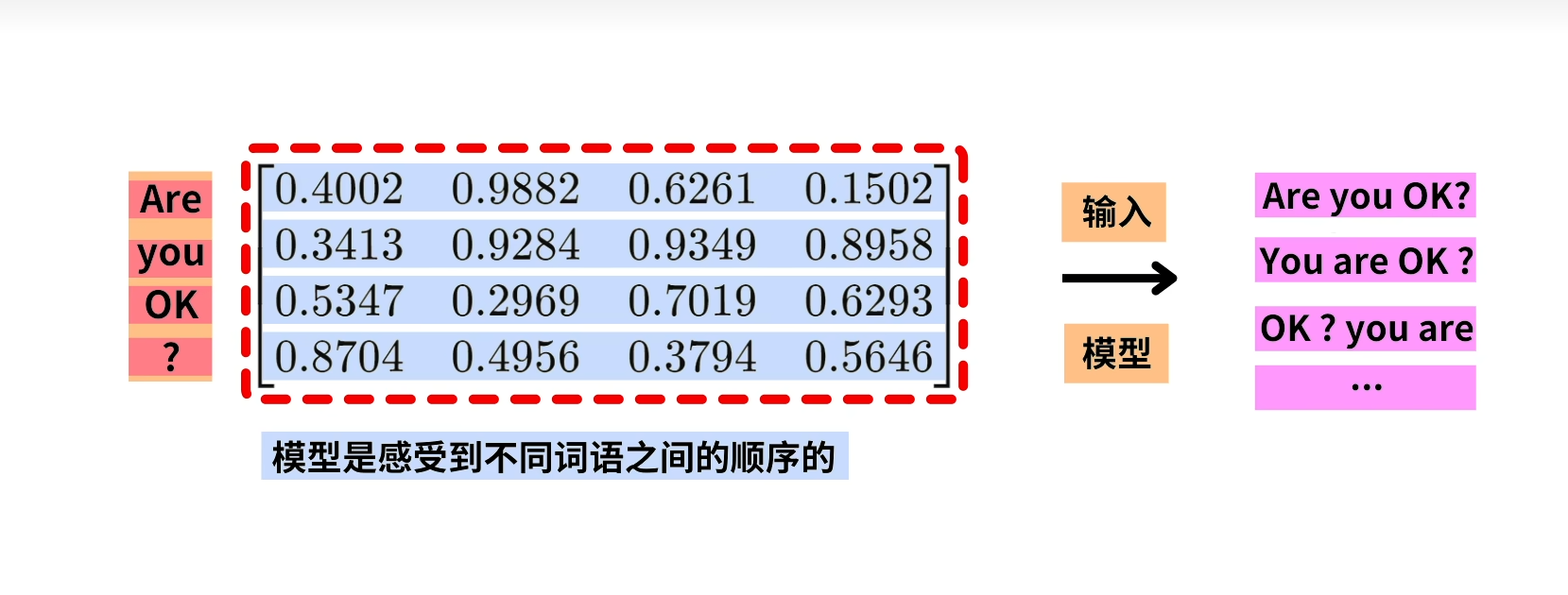
:::tips 模型感受不到不同词语之间的顺序的,所以可能会被理解成 ok?you are等。所以positional encoding 才显得有他的重要之处。 :::
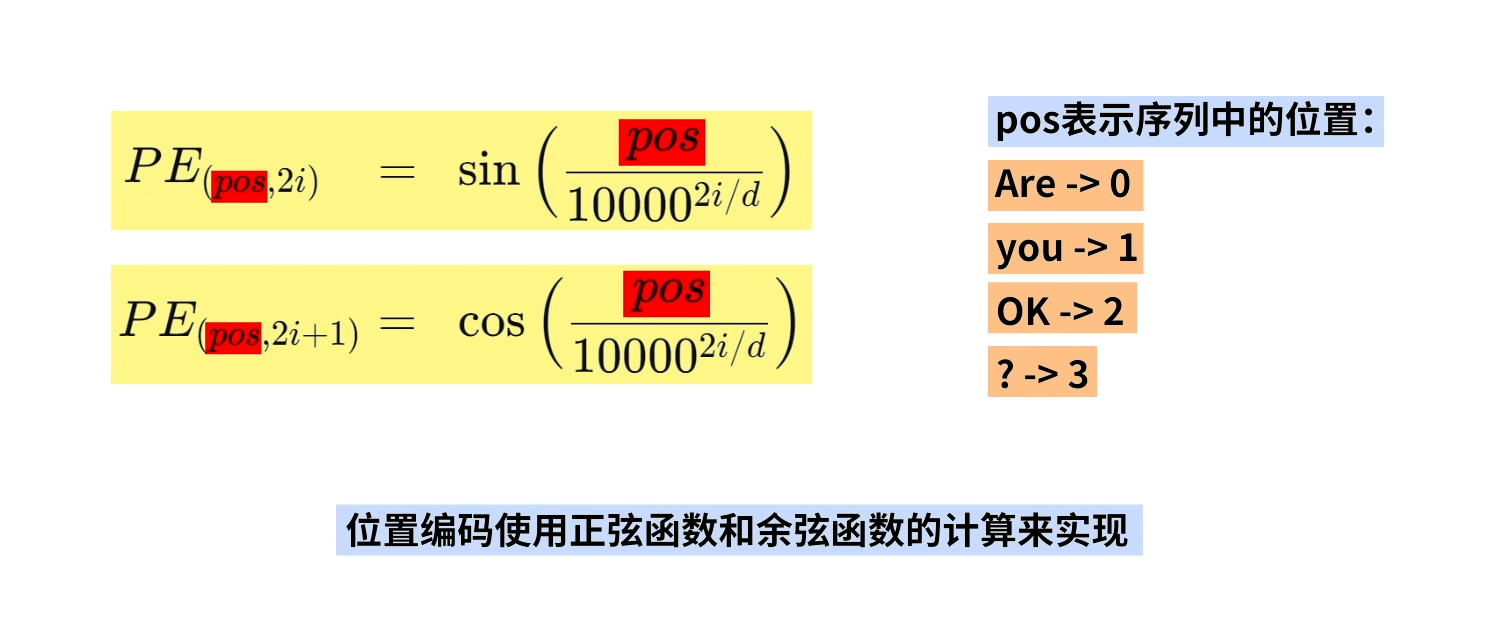
:::tips 在Transformer模型中,位置编码(Positional Encoding)用于为模型提供序列中各元素的位置信息。由于Transformer缺乏处理序列顺序的内在机制,位置编码显得尤为重要。 使用正弦和余弦函数来计算位置编码具有以下优势: 1. 唯一性和区分性 :正弦和余弦函数的不同频率确保了每个位置的编码在各维度上都是唯一的,从而使模型能够区分不同位置的元素。 (blog.csdn.net) 2. 平滑性和连续性 :正弦和余弦函数的平滑变化使得相邻位置的编码在数值上变化平缓,有助于模型捕捉相邻元素之间的关系。 (blog.csdn.net) 3. 周期性 :正弦和余弦函数的周期性特性使得位置编码在不同长度的序列中具有一致性,避免了随着序列长度增加而导致的编码值过大或过小的问题。 (cnblogs.com) 综上所述,正弦和余弦函数的这些特性使其成为计算位置编码的理想选择,帮助Transformer模型有效地理解和处理序列数据中的位置信息。 :::
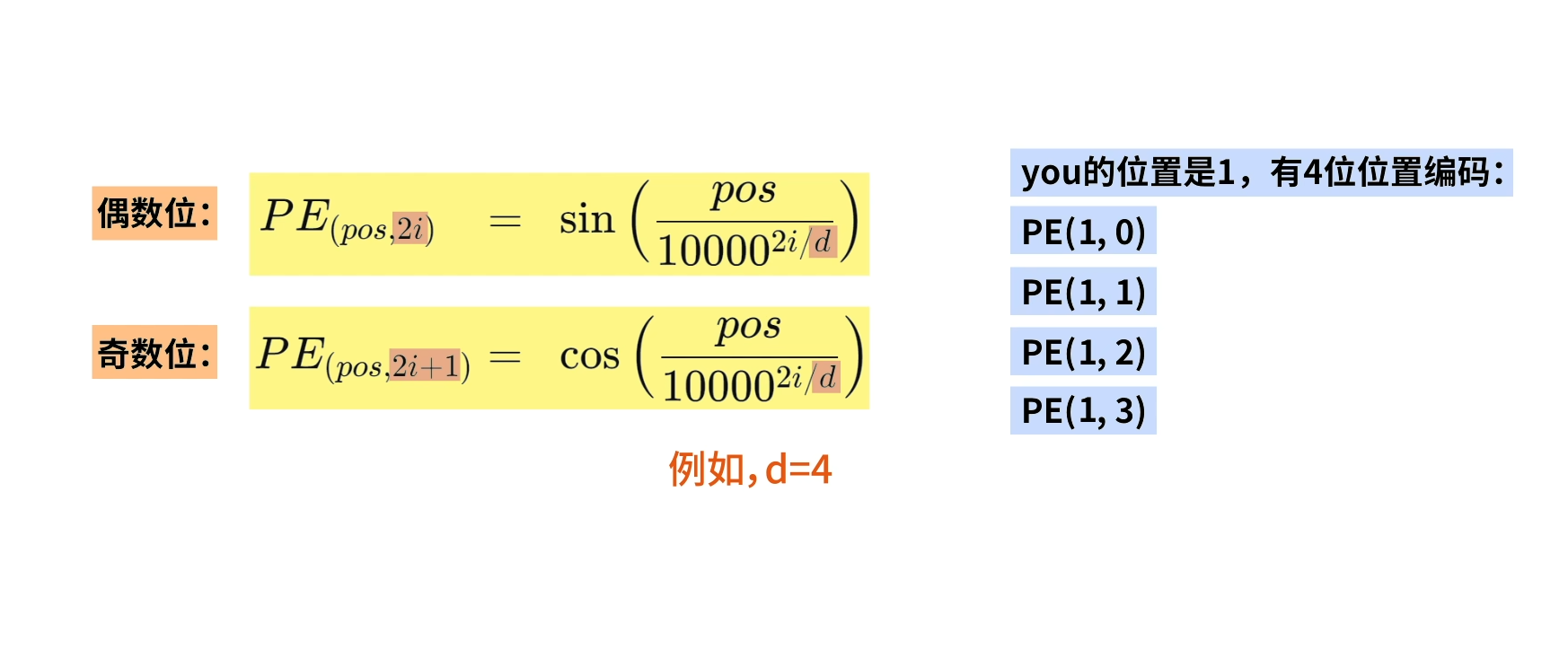
:::tips 2i代表偶数维度,2i+1代表奇数维度。d代表总维度。 :::
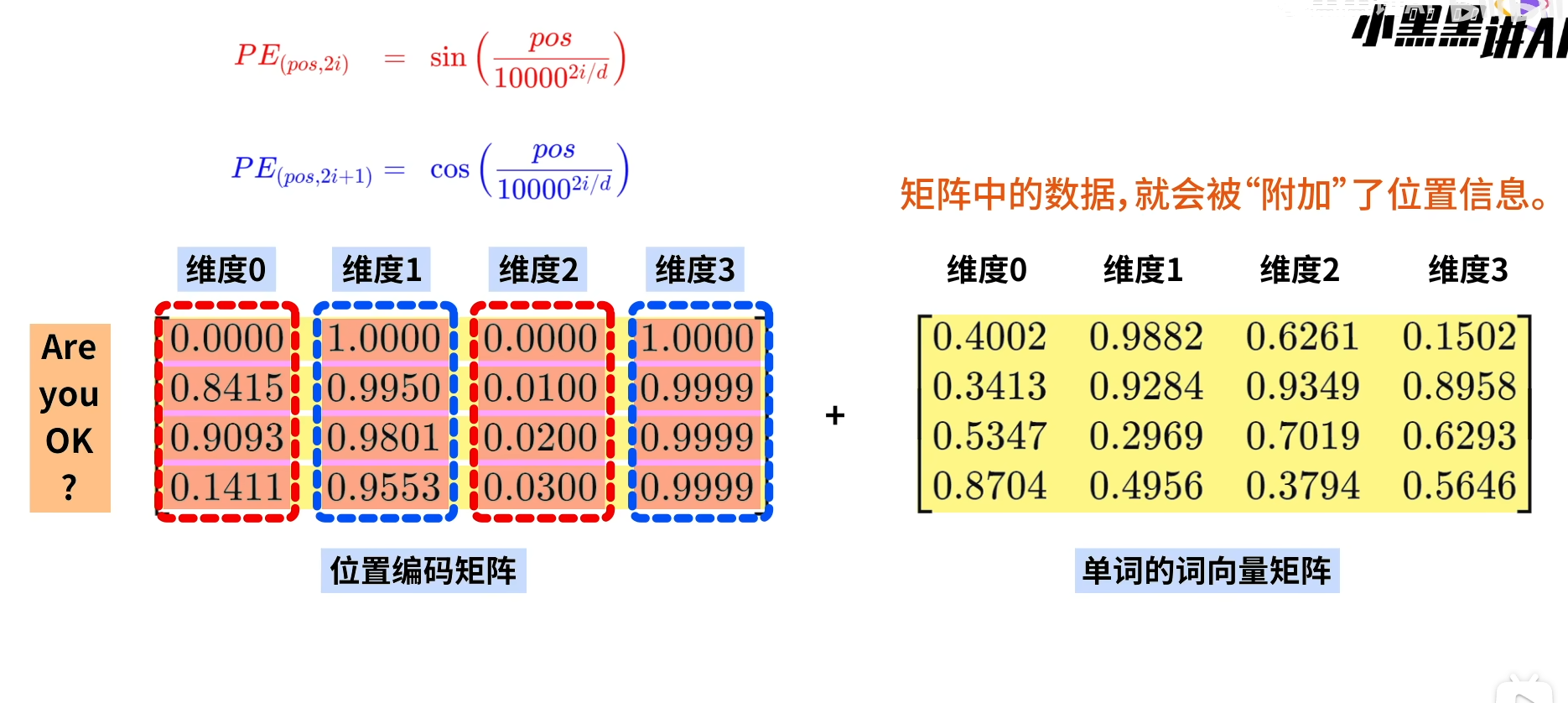
:::tips 可见生成的位置编码矩阵加上单词的词向量矩阵,就会让原来单词的词向量矩阵附加上位置信息。 ::: 编码器与解码器
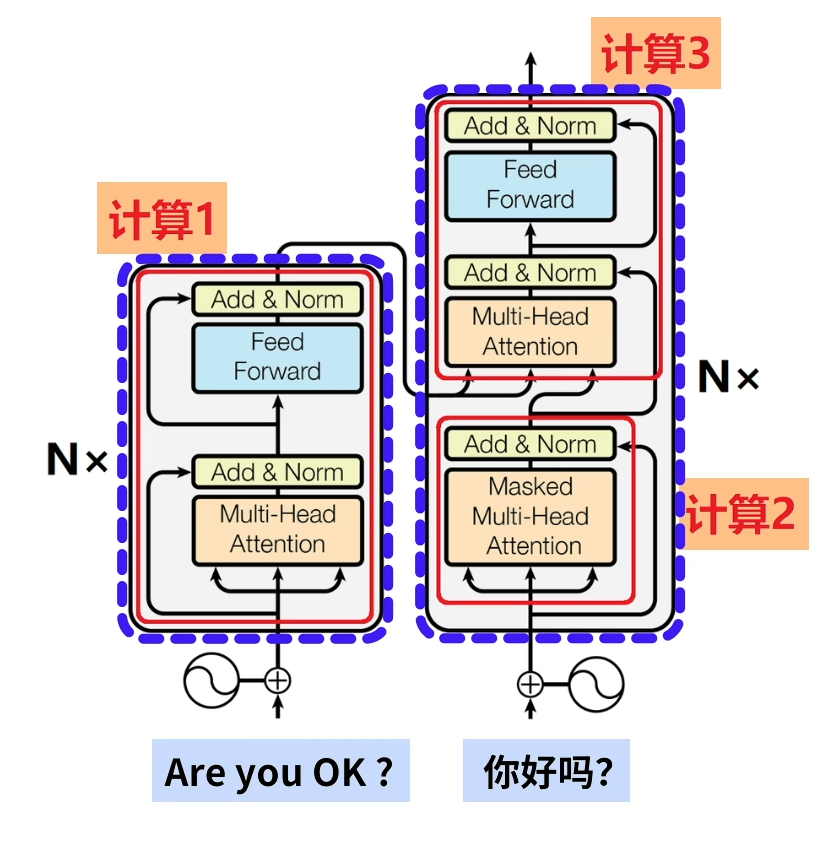
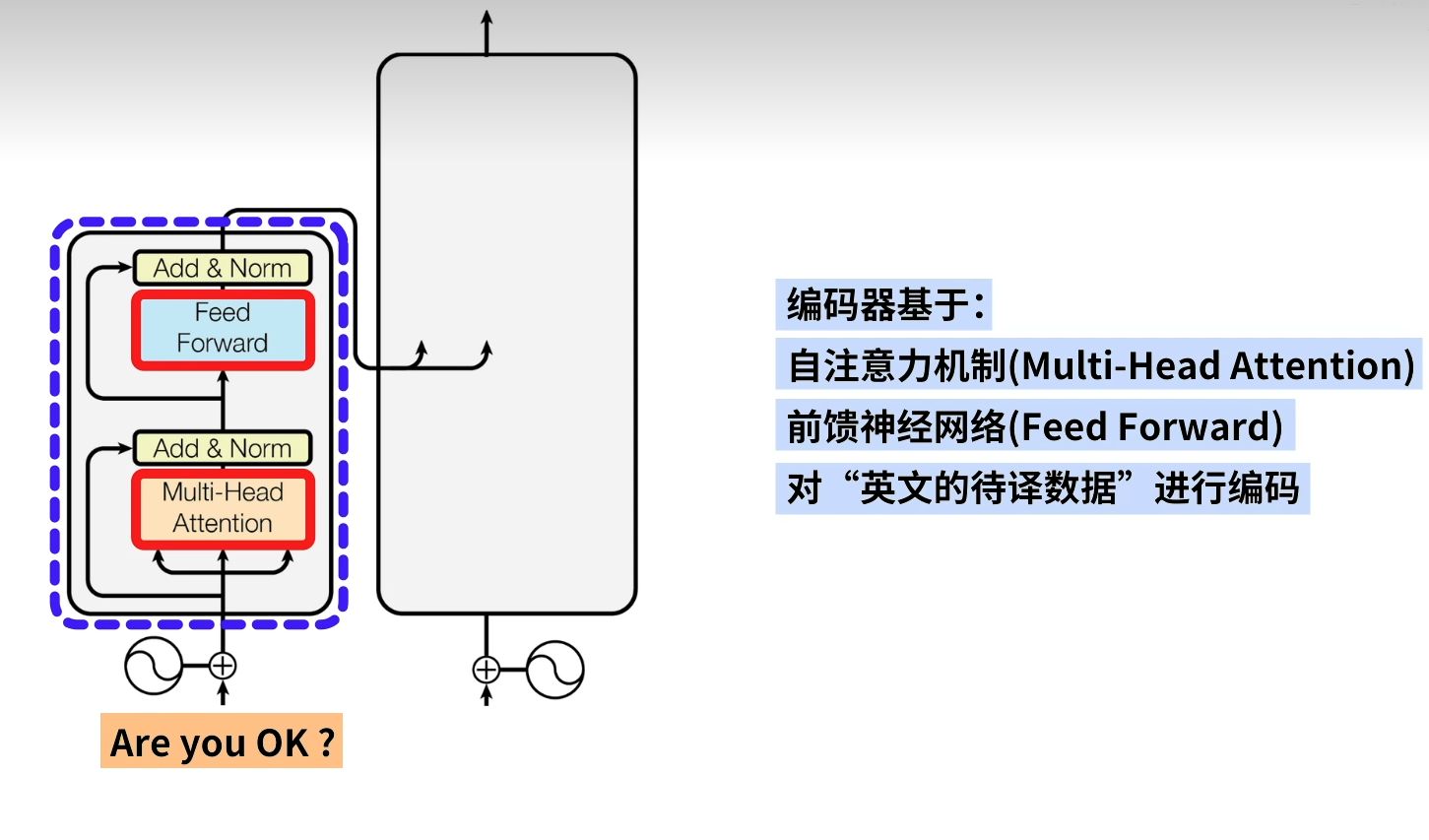
:::tips 计算1主要的作用如上图所示 :::
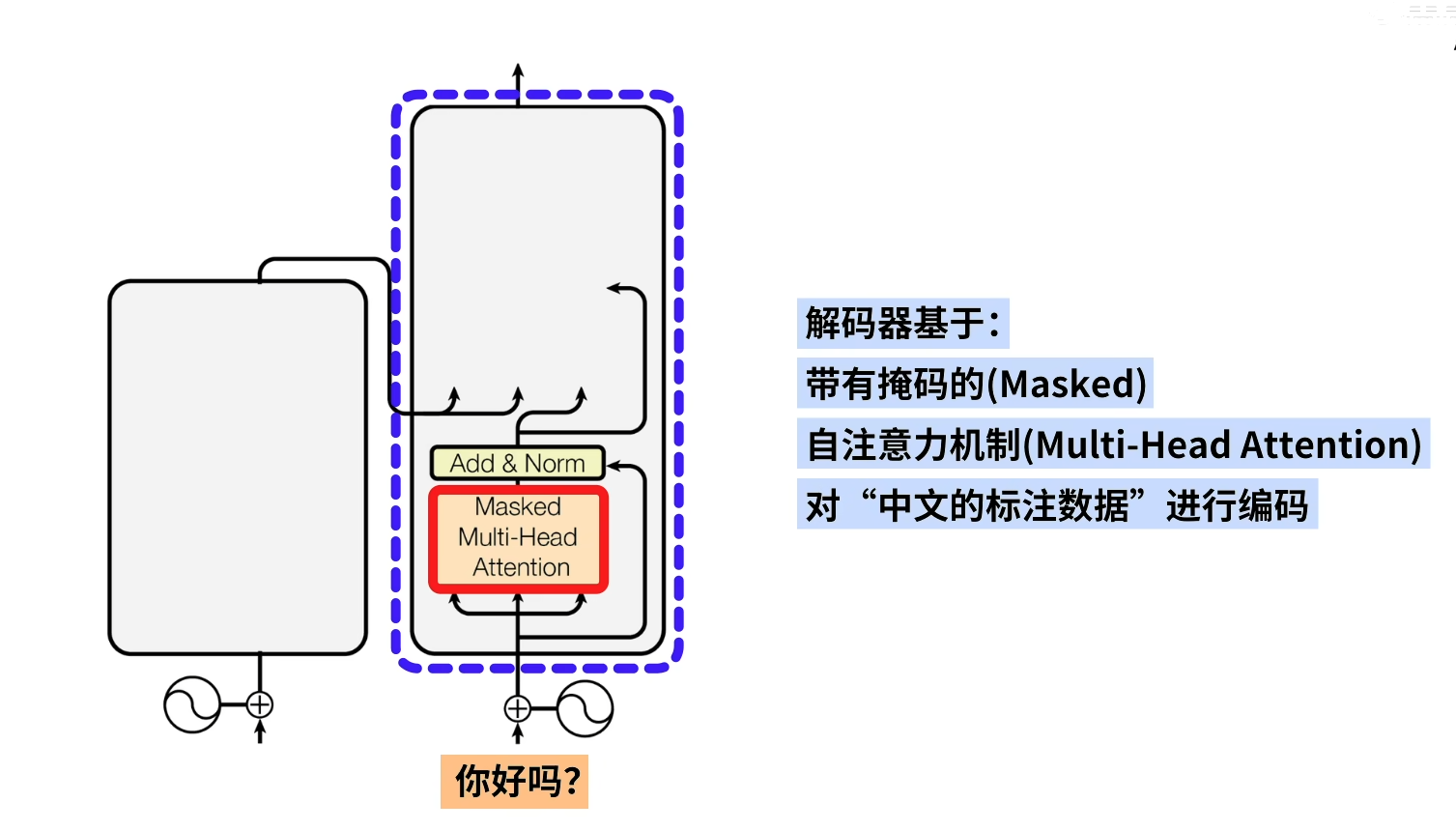
:::tips 计算2主要的作用如上图所示 :::
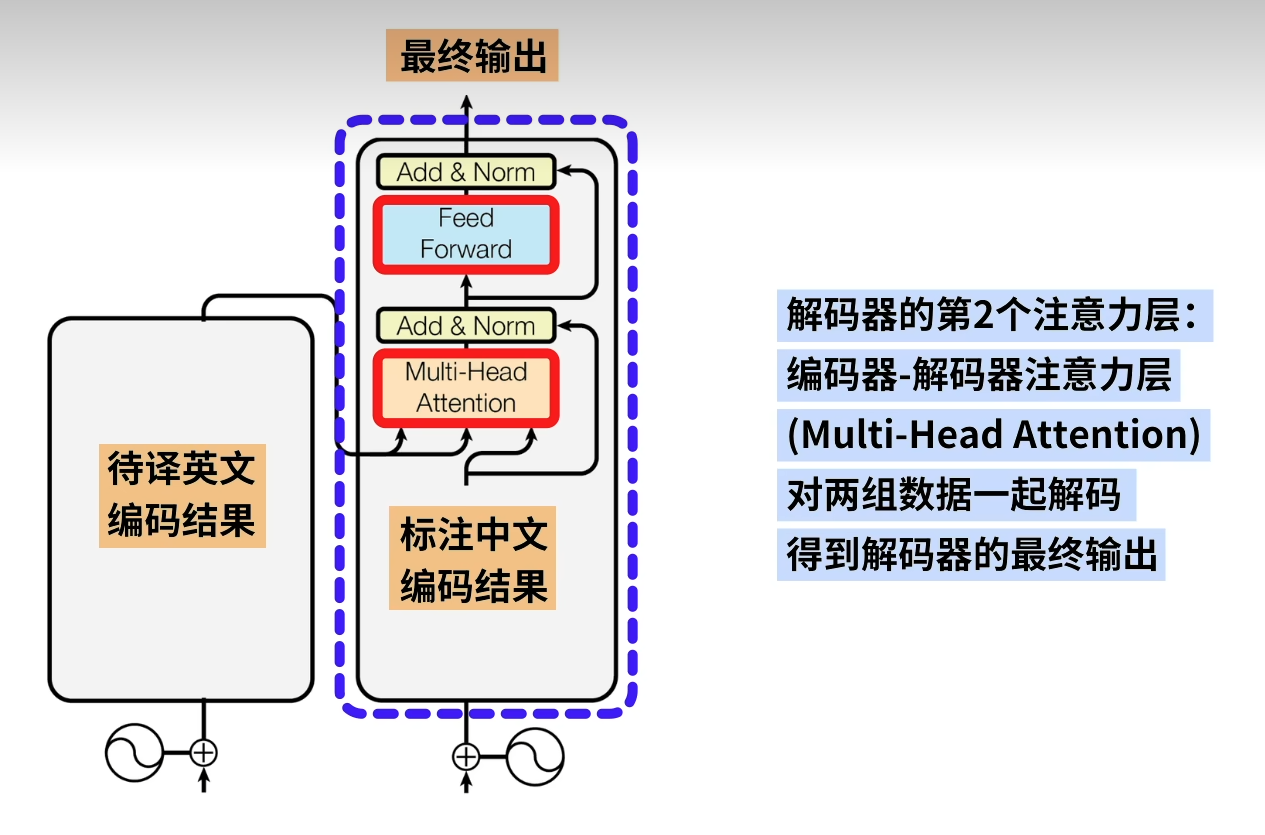
:::tips 计算3主要的作用如上图所示 :::
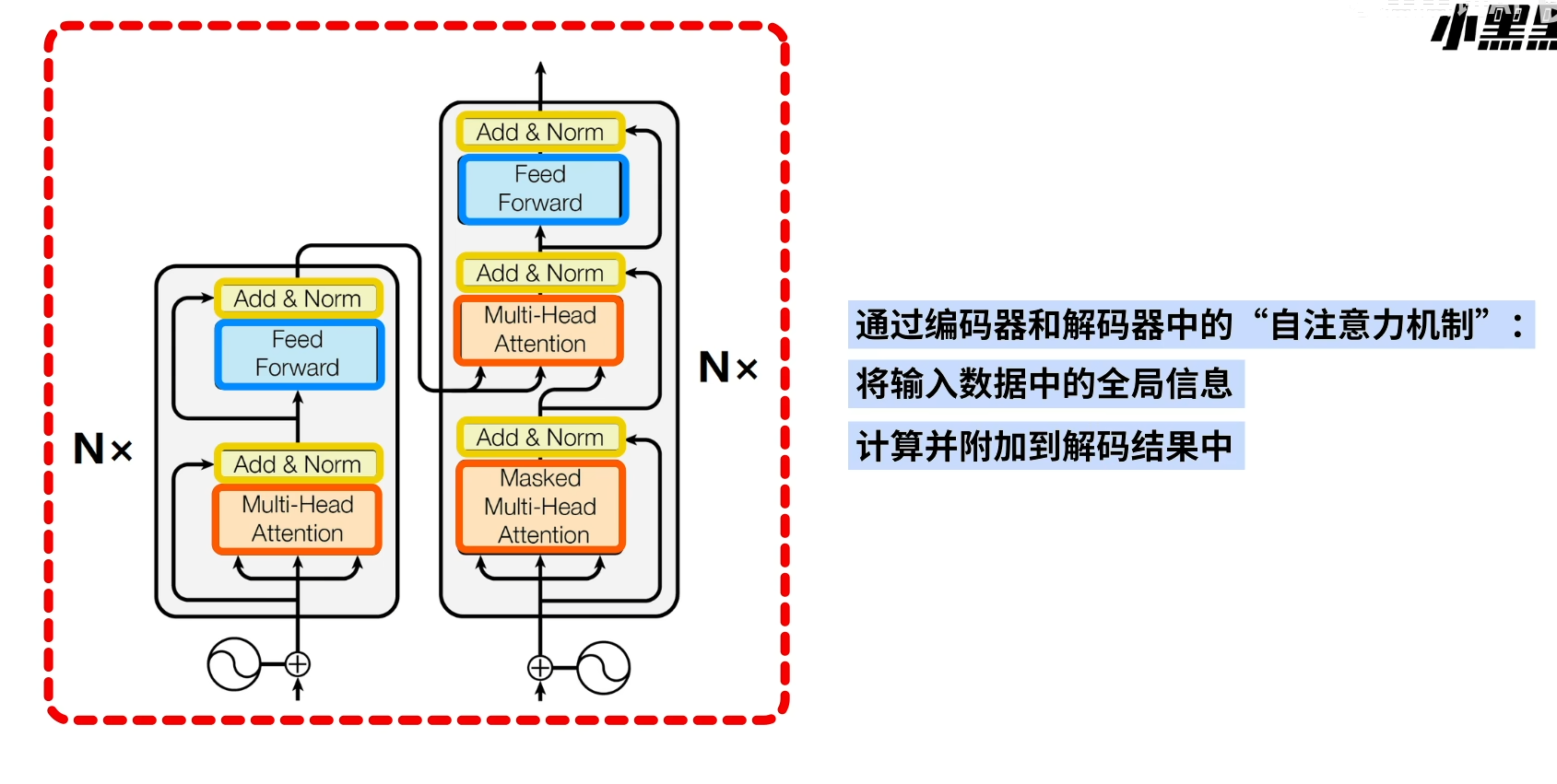
多头注意力机制(muti head self attention)
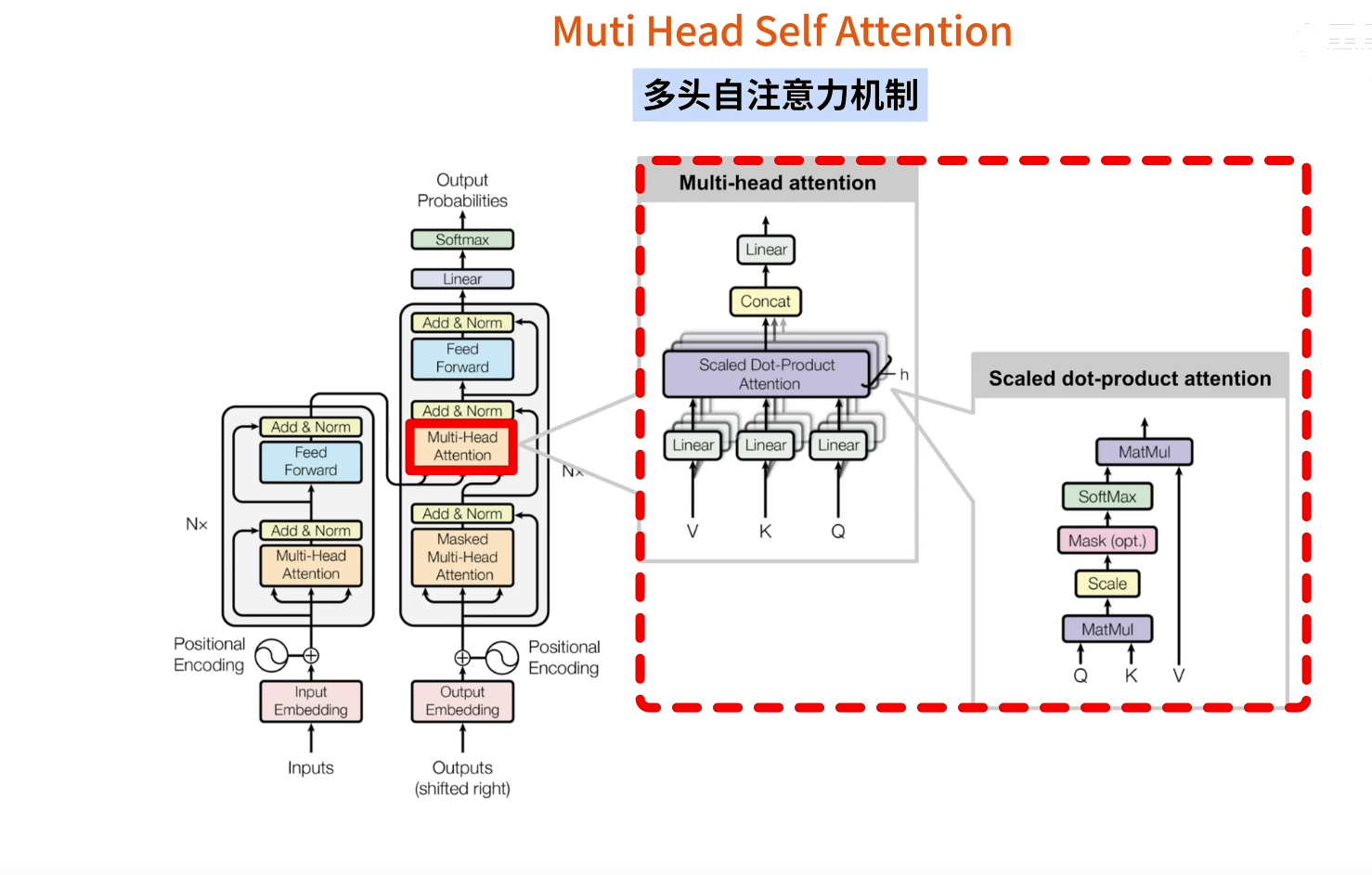
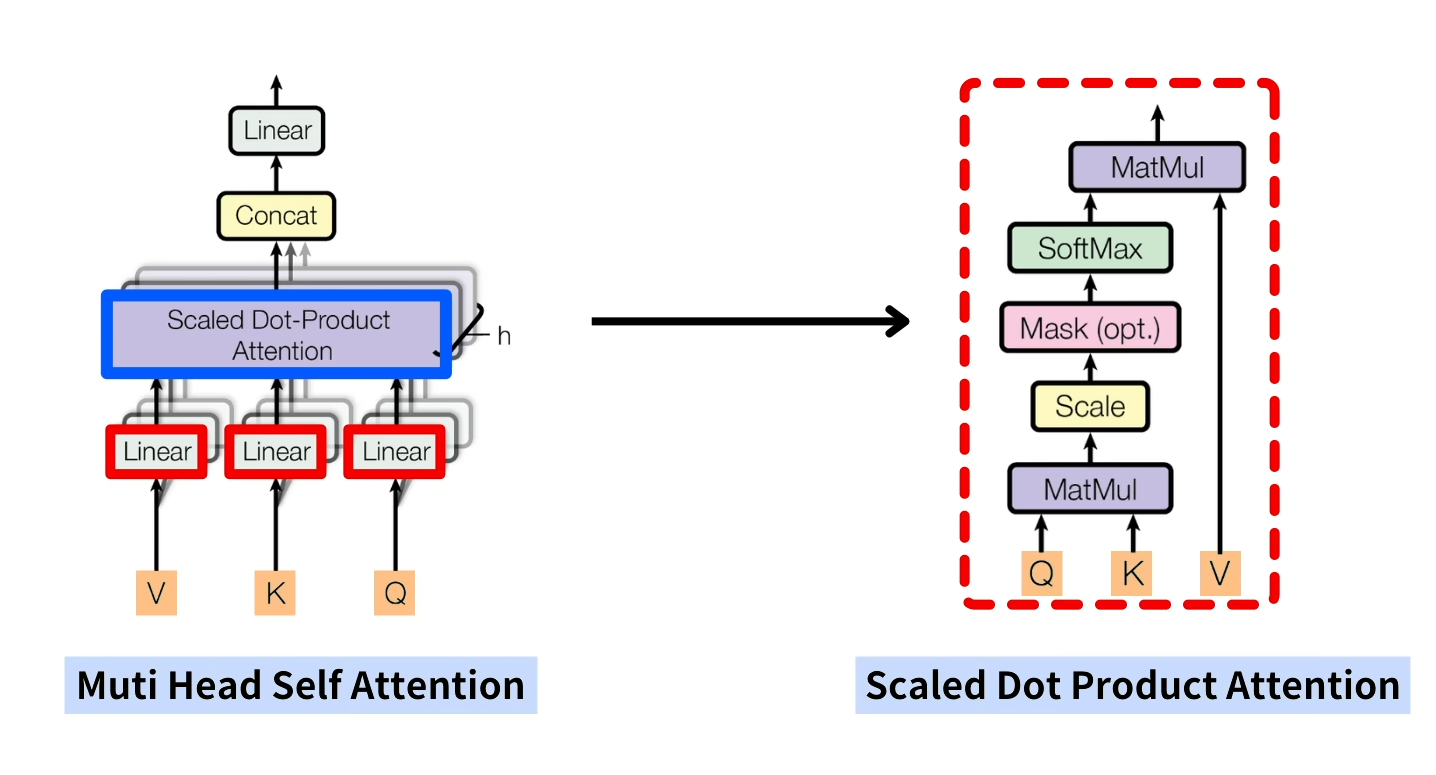
:::tips 对Q K V进行特征变化,然后用Scaled Dot Product Attention 对特征变换之后的Q K V进行组合 :::
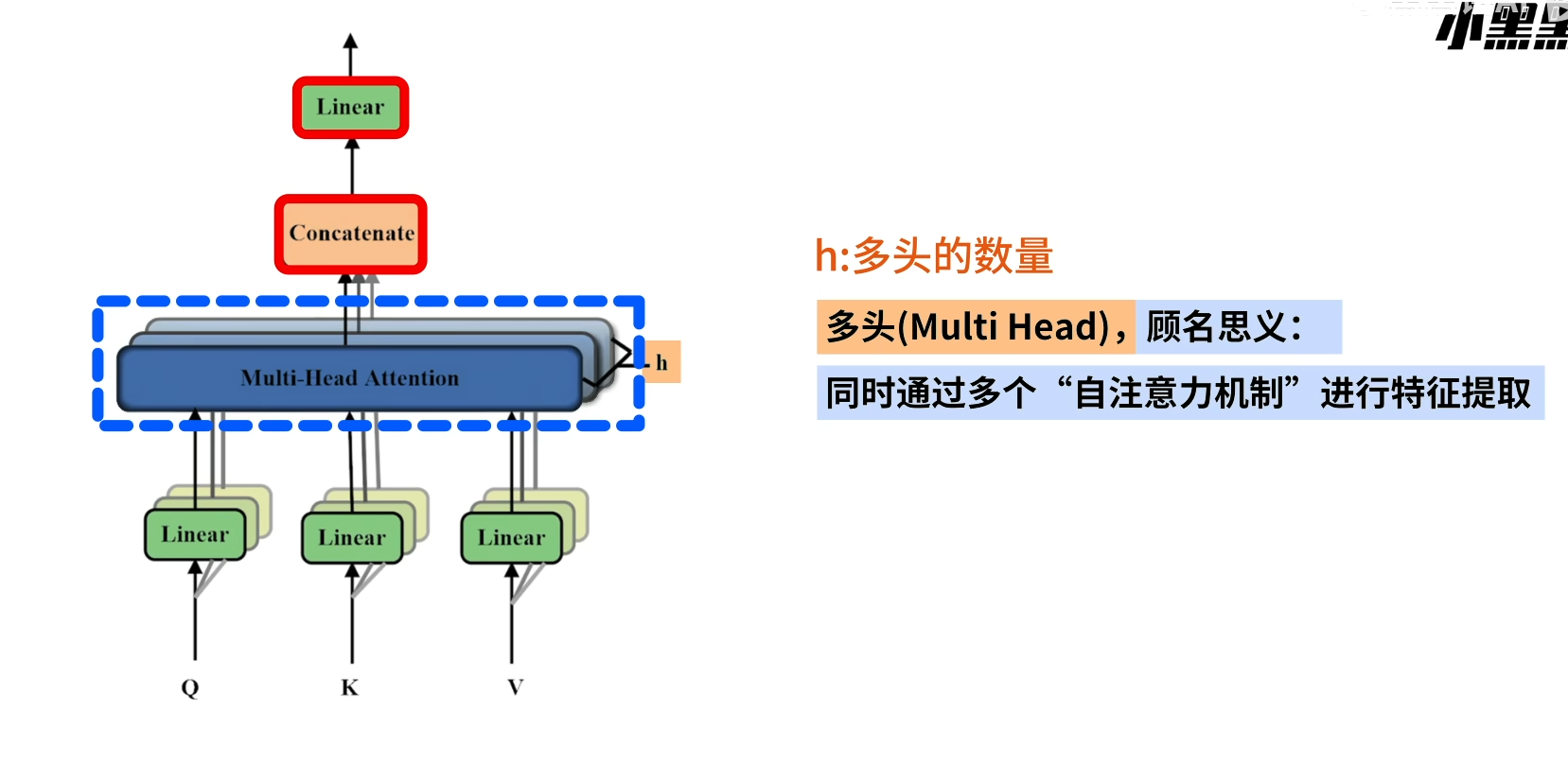
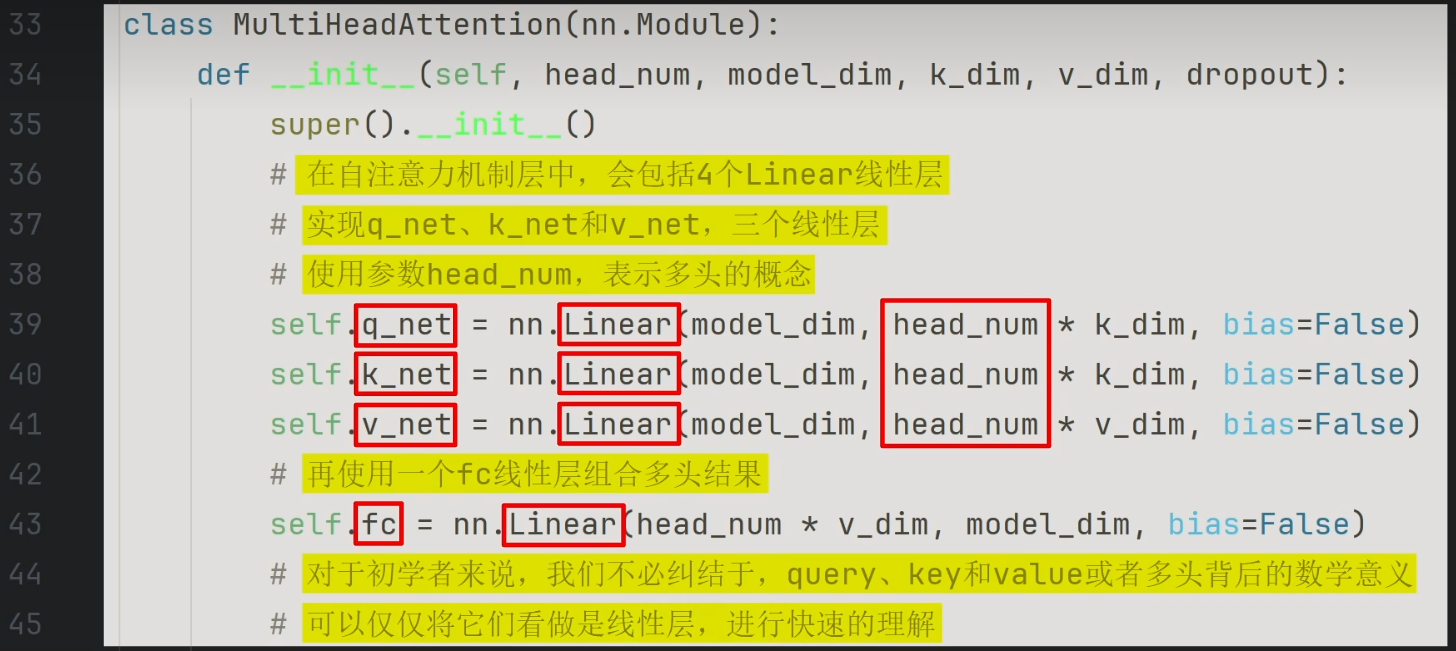

:::tips x与三个线性层进行线性计算得到三组结果 :::
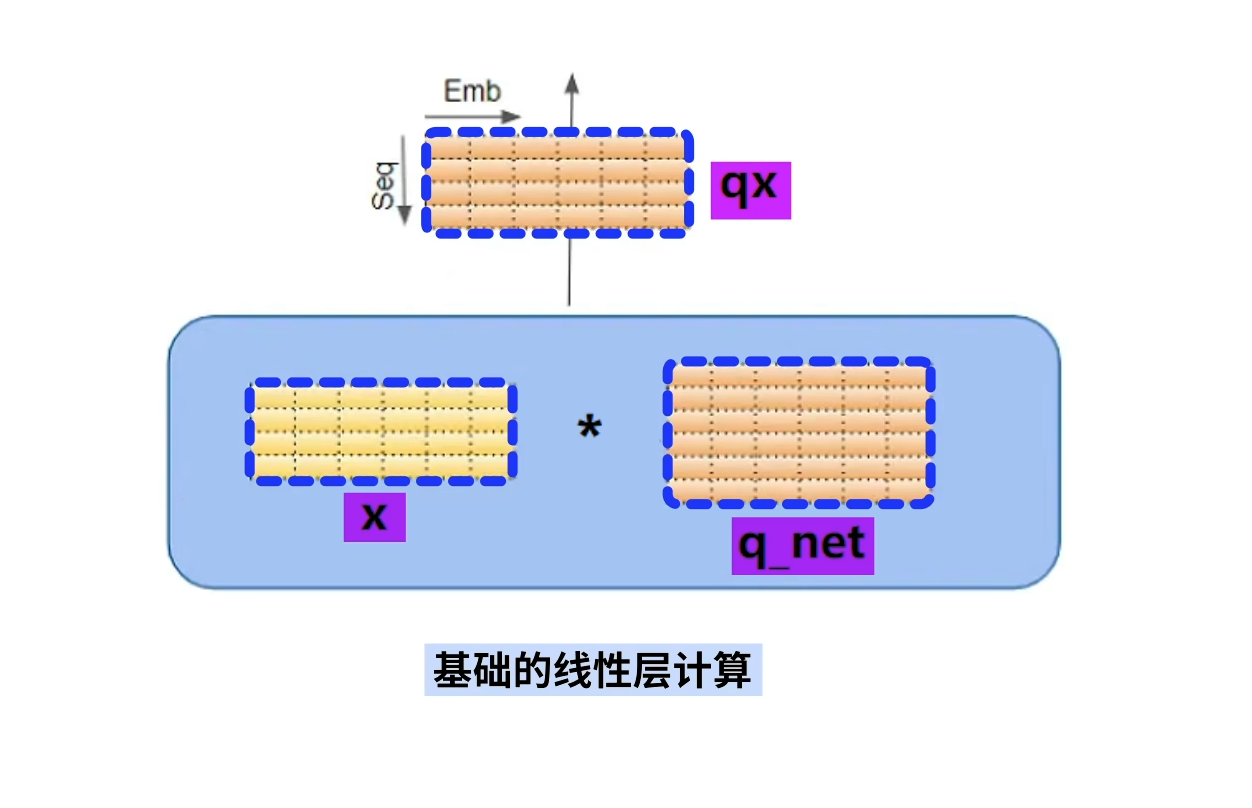

:::tips 带入这个公式中得到一个最终的注意力结果,这就是softmax的作用。 :::
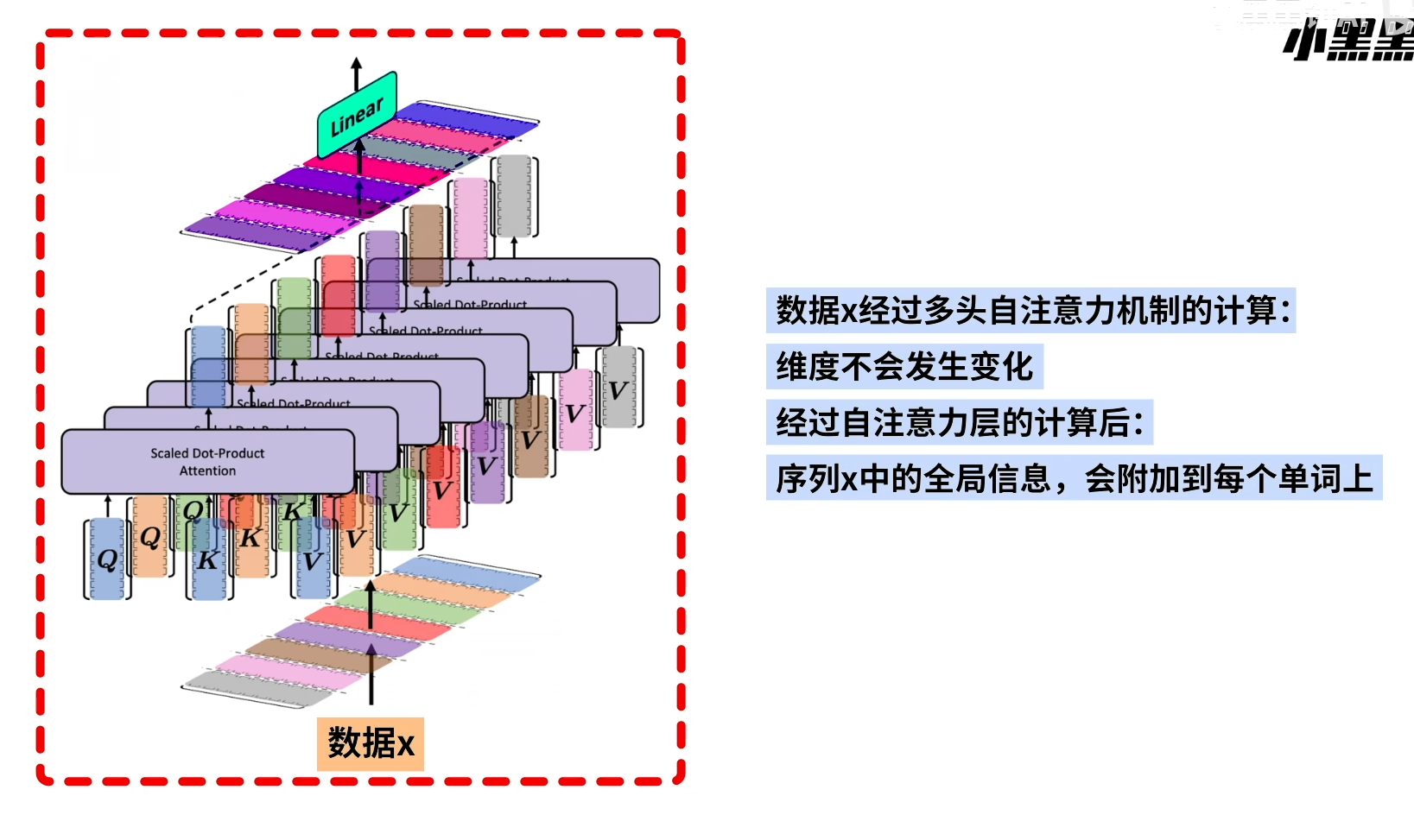
:::tips 最后通过linear层将注意力结果进行合并输出。 :::