【备注】:本blog主要用于记录博主本人在准备leetcode的算法题的过程,其中选出的题主要来源于leetcode hot100,大部分为企业真实面试中的高频面试手撕题目,建议全代码熟练到背诵程度。
目录
- 1、长度最小的子数组(209题-中等)
- 2、二叉树中的最大路径和(124题-困难)
- [3、会议室 II(253题-中等)](#3、会议室 II(253题-中等))
- 4、无重叠区间(435题-中等)
- 5、最长递增子序列(253题-中等)
- 6、N皇后(51题-困难)
- 7、数组中的最长山脉(845题-中等)
- 8、螺旋遍历二维数组(146题-简单)
- 9、两数相加(236题-中等)
- 10、无重复字符的最长子串(3题-中等)
1、长度最小的子数组(209题-中等)
题目描述:
给定一个含有 n 个正整数的数组和一个正整数 target 。
找出该数组中满足其总和大于等于 target 的长度最小的 子数组 numsl, numsl+1, ..., numsr-1, numsr ,并返回其长度。如果不存在符合条件的子数组,返回 0 。
解题思路:
滑动窗口求解。用left 与 right记录窗口的左右端点,先滑动右侧端点同时计算窗口内的和s,当s>=target时进入判断,将当前长度(right-left+1)与答案进行比较,更新最小的为答案,然后s需要减去左端点的值,然后left需要右移,再判断s是否大于等于target。
代码实现:
python
class Solution:
def minSubArrayLen(self, target: int, nums: List[int]) -> int:
# 滑动窗口求解。用left 与 right记录窗口的左右端点,先滑动右侧端点同时计算窗口内的和s,当s>=target时进入判断,记录当前长度并与答案进行比较,更新最小的为答案,然后left需要右移,同时s需要减去左端点的值。
n = len(nums)
ans = n+1
left = 0
right = 0
s = 0
for right, x in enumerate(nums):
s += x
while s >= target:
ans = min(ans, right-left+1)
s -= nums[left]
left += 1
return ans if ans <=n else 0复杂度分析
时间复杂度:O(n),其中 n 为 nums 的长度。虽然写了个二重循环,但是内层循环中对 left 加一的总执行次数不会超过 n 次,所以总的时间复杂度为 O(n)。
空间复杂度:O(1),仅用到若干额外变量。
答疑:
请评论区留言。
2、二叉树中的最大路径和(124题-困难)
题目描述:
二叉树中的 路径 被定义为一条节点序列,序列中每对相邻节点之间都存在一条边。同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个 节点,且不一定经过根节点。
路径和 是路径中各节点值的总和。
给你一个二叉树的根节点 root ,返回其 最大路径和 。
解题思路:
树形DP,与543题的数的最大直径类似。dfs(node)表示求解节点node的最大路径和,可以分解为求左右子树的最大路径和,然后加上node.val表示该节点的最大路径和。递归边界:空节点时返回0。
本题有两个关键概念:
- 链:从下面的某个节点(不一定是叶子)到当前节点的路径。把这条链的节点值之和,作为 dfs 的返回值。如果节点值之和是负数,则返回 0(和 0 取最大值)。这个思想和 53. 最大子数组和 是一样的,如果左侧子数组的元素和是负数,就不和当前元素拼起来。
- 直径:等价于由两条(或者一条)链拼成的路径。我们枚举每个 node,假设直径在这里「拐弯」,也就是计算由左右两条从下面的某个节点(不一定是叶子)到 node 的链的节点值之和,去更新答案的最大值。
⚠注意:dfs 返回的是链的节点值之和,不是直径的节点值之和。
代码实现:
python
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def maxPathSum(self, root: Optional[TreeNode]) -> int:
# 思路:树形DP,与543题的数的最大直径类似。dfs(node)表示求解节点node的最大路径和,可以分解为求左右子树的最大路径和,然后加上node.val表示该节点的最大路径和。递归边界:空节点时返回0。
ans = -inf
def dfs(node):
if node is None:
return 0
l_val = dfs(node.left)
r_val = dfs(node.right)
nonlocal ans
ans = max(ans, l_val + r_val + node.val) # 求出以节点node为直径的最大路径和
return max(max(l_val, r_val) + node.val, 0) # 返回节点node的最大链和,为后续的递归回父节点做记录(注意这里和 0 取最大值了)
dfs(root)
return ans复杂度分析
时间复杂度:O(n),其中 n 为二叉树的节点个数。
空间复杂度:O(n)。最坏情况下,二叉树退化成一条链,递归需要 O(n) 的栈空间。
答疑:
请评论区留言。
3、会议室 II(253题-中等)
题目描述:
给你一个会议时间安排的数组 intervals ,每个会议时间都会包括开始和结束的时间 intervalsi = starti, endi ,返回 所需会议室的最小数量 。
示例 1:
输入:intervals = \[0,30,5,10,15,20]
输出:2
解题思路:
把会议开始时间与结束时间视为独立的时间,会议开始用+1表示,会议结束用-1表示。将所有会议开始与结束时间统计好然后排序,用cur来表示当前进行的会议数量,遇到会议开始cur+1,遇到会议结束cur-1,同时不断更新最大的会议峰值ans。
代码实现:
python
class Solution:
def minMeetingRooms(self, intervals: List[List[int]]) -> int:
# 思路:把会议开始时间与结束时间视为独立的时间,会议开始用+1表示,会议结束用-1表示。将所有会议开始与结束时间统计好然后排序,用cur来表示当前进行的会议数量,遇到会议开始cur+=1,遇到会议结束cur -= 1,不断更新最大的会议峰值ans。
ans = cur = 0
envent = [(itv[0], 1) for itv in intervals] + [(itv[1], -1) for itv in intervals] # 将所有会议开始与结束的事件合并起来
envent.sort() # 必须要进行排序
for _, e in envent:
cur += e # 统计当前进行会议的事件数量
ans = max(ans, cur) # 更新会议的最大峰值
return ans复杂度分析
时间复杂度为 O(nlogn),主要由事件排序主导,因为创建和扫描事件仅需 O(n)。空间复杂度为O(n),因为需要将 n 个会议拆分为 2n 个事件存储,占用空间与会议数量成正比。
答疑:
请评论区留言。
4、 无重叠区间(435题-中等)
题目描述:
给定一个区间的集合 intervals ,其中 intervalsi = starti, endi 。返回 需要移除区间的最小数量,使剩余区间互不重叠 。
注意 只在一点上接触的区间是 不重叠的。例如 1, 2 和 2, 3 是不重叠的。
示例 1:
输入: intervals = \[1,2,2,3,3,4,1,3]
输出: 1
解释: 移除 1,3 后,剩下的区间没有重叠
解题思路:
贪心策略。根据区间的右端点进行排序,选取区间右端点最小的作为开始节点,不断遍历集合,比较当前遍历区间的左端点l是否比上个入选的区间右端点pre_r小,若pre_r<=l则该区间入选,更新入选区间的右端点pre_r,同时ans+1(ans记录的是入选区间的个数);否则不选择该区间。遍历完成返回len(intervals)-ans;
代码实现:
python
class Solution:
def eraseOverlapIntervals(self, intervals: List[List[int]]) -> int:
# 思路:贪心策略。根据区间的右端点进行排序,选取区间右端点最小的作为开始节点,不断遍历集合,比较当前遍历区间的左端点l是否比上个选区的区间右端点pre_r小,若pre_r>l则不选该区间,不更新pre_r;否则更新pre_r=r(当前区间的右端点),同时ans+1(ans记录的是入选区间的个数);遍历完成返回len(intervals)-ans;
ans = 0 # 记录入选区间的个数
pre_r = -inf # 初始化右端点=为负无穷
intervals.sort(key= lambda x:x[1]) # 根据区间的右端点进行排序
for l, r in intervals:
if pre_r <= l: # 当入选的区间右端点小于当前区间的左端点,则不重叠,入选当前区间
ans += 1
pre_r = r # 更新入选区间的右端点
return len(intervals) - ans # 返回需要去除的区间个数复杂度分析
时间复杂度:O(nlogn),其中 n 是 intervals 的长度。瓶颈在排序上。
空间复杂度:O(1)。不计入排序的栈开销。
答疑:
(1)问:为什么要排序?为什么要按照右端点排序?
答:选择右端点最小的区间 A 后,左端点小于 A 的右端点的区间都与 A 相交,都不能选。因此,为了方便计算下一个可以选的区间,按照右端点从小到大排序。排序后,intervals0 一定可以选,并且下一个可以选的区间是第一个左端点 ≥intervals01 的区间。
5、最长递增子序列(253题-中等)
题目描述:
给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。
子序列 是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,3,6,2,7 是数组 0,3,1,6,2,2,7 的子序列。
示例 1:
输入:nums = 10,9,2,5,3,7,101,18
输出:4
解释:最长递增子序列是 2,3,7,101,因此长度为 4 。
解题思路:
贪心+二分查找。即维护一个g\[\]数组(该数组是递增数组),gn以长度为n+1的递增子序列的末尾元素的最小值,然后二分遍历nums来更新g数组(设遍历nums位置为j),用二分查找第一个大于numsj的位置,若j长度等于g\[\]数组长度,即x不在数组g中(即x比g中所有元素都大),则直接将x添加到g的末尾,否则将gj更新为x=numsj的值(贪心思想,为了让后续稍微大的元素都可以插入该数组)
代码实现:
python
class Solution:
def lengthOfLIS(self, nums: List[int]) -> int:
# 思路:贪心+二分查找。即维护一个g[]数组(该数组是递增数组),g[n]以长度为n+1的递增子序列的末尾元素的最小值,然后二分遍历nums来更新g数组(设遍历nums位置为j),用二分查找第一个大于nums[j]的位置,若j长度等于g[]数组长度,即x不在数组g中(即x比g中所有元素都大),则直接将x添加到g的末尾,否则将g[j]更新为x=nums[j]的值(贪心思想,为了让后续稍微大的元素都可以插入该数组)
g = []
for x in nums:
j = bisect_left(g, x) # bisect()表示二分查找x插入的位置,_left表示第一个大于等于x的位置,_right表示大于x的位置
if j == len(g): # 若j长度等于g[]数组长度,即x还未在数组g中,则直接将x添加到g的末尾。
g.append(x)
else:
g[j] = x # 在g中找到比x大的位置,用贪心思想更新g数组为更小值,以便后续可以插入更多元素
return len(g)复杂度分析
时间复杂度:O(nlogn),其中 n 为 nums 的长度。
空间复杂度:O(1)。
答疑:
6、N皇后(51题-困难)
题目描述:
按照国际象棋的规则,皇后可以攻击与之处在同一行或同一列或同一斜线上的棋子。
n 皇后问题 研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
给你一个整数 n ,返回所有不同的 n 皇后问题 的解决方案。
每一种解法包含一个不同的 n 皇后问题 的棋子放置方案,该方案中 'Q' 和 '.' 分别代表了皇后和空位。
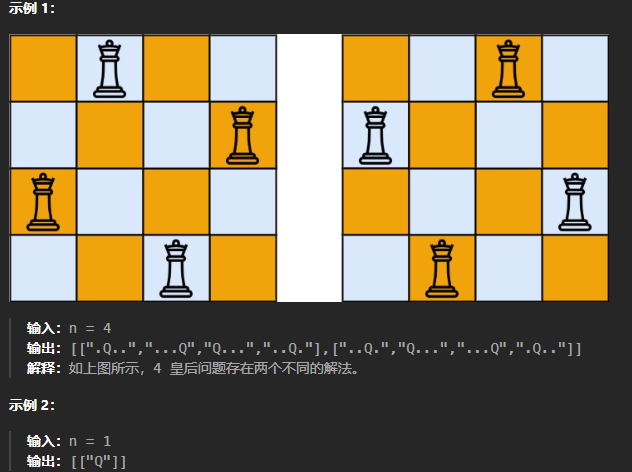
解题思路:
n皇后只能在不同行与不同列,问题转换为每一行的皇后应该选择哪一列的排列问题。注意到在(r,c)位置的皇后的对角线:左上右下的r-c都相同,右上左下的r+c值都相同,不能放其他皇后。dfs®表示在递归放置第r行的皇后,用queue记录放置皇后的位置其中queuei表示第i行的皇后应该放置在值queuei的位置,用on_path记录当前列是否被选过了,用diag记录两侧对角线位置是否放置了皇后,若当前列on_path未被选过且左上与右上位置未放置皇后,则选择该位置放置皇后。递归遍历下一行dfs(i+1)并还原递归现场,避免后续回溯时影响其他递归情况。若第c不满足条件时则继续遍历下一列是否满足。
代码实现:
python
class Solution:
def solveNQueens(self, n: int) -> List[List[str]]:
# 思路:n皇后只能在不同行与不同列,问题转换为每一行的皇后应该选择哪一列的排列问题。注意到在(r,c)位置的皇后的对角线:左上右下的r-c都相同,右上左下的r+c值都相同,不能放其他皇后。dfs(r)表示在递归放置第r行的皇后,用queue记录放置皇后的位置其中queue[i]表示第i行的皇后应该放置在值queue[i]的位置,用on_path记录当前列是否被选过了,用diag记录两侧对角线位置是否放置了皇后,若当前列on_path未被选过且左上与右上位置未放置皇后,则选择该位置放置皇后。递归遍历下一行dfs(i+1)并还原递归现场,避免后续回溯时影响其他递归情况。若第c不满足条件时则继续遍历下一列是否满足。
ans = []
queens = [0]*n
on_path = [False]*n
diag1 = [False] * (2*n -1) # 记录r+c
diag2 = [False] * (2*n -1) # 记录r-c
def dfs(r): # 放置当前第r行的皇后
# 递归边界条件,当所有列的皇后已经放置完成,则开始写入答案中。
if r == n:
ans.append(['.'*c + 'Q' + '.'*(n-c-1) for c in queens]) # queue[c]表示皇后应该放置在第c列,所以'Q'前边右c个'.',后边有n-c-1个'.'.
return # 退出递归
for c in range(n): # 对于每次递归(第r行)而言,遍历所有列寻找合适位置进行放置皇后
if not on_path[c] and not diag1[r+c] and not diag2[r-c]: # 当前列与对角线都没有皇后,可以放置皇后
queens[r] = c
on_path[c] = diag1[r+c] = diag2[r-c] = True
dfs(r+1) # 开始递归下一列
on_path[c] = diag1[r+c] = diag2[r-c] = False # 恢复现场,避免后续回溯时影响其他递归情况。
dfs(0)
return ans复杂度分析
时间复杂度:O(n^2 * n!)。搜索树中至多有 O(n!) 个叶子,每个叶子生成答案每次需要 O(n^2) 的时间,所以时间复杂度为 O(n^2 * n!)。
空间复杂度:O(n)。返回值的空间不计入。
答疑:
评论区留言。
7、数组中的最长山脉(845题-中等)
题目描述:
把符合下列属性的数组 arr 称为 山脉数组 :
- arr.length >= 3
- 存在下标 i(0 < i < arr.length - 1),满足:
arr0 < arr1 < ... < arri - 1 < arri
arri > arri + 1 > ... > arrarr.length - 1
给出一个整数数组 arr,返回最长山脉子数组的长度。如果不存在山脉子数组,返回 0 。
示例 1:
输入:arr = 2,1,4,7,3,2,5
输出:5
解释:最长的山脉子数组是 1,4,7,3,2,长度为 5。
解题思路:
找山顶,然后从山顶往两端进行拓展。如何判断一个节点是否可以作为山顶?:当arri>arrl and arri>arrr(即山顶元素值大于左右两端值);然后遍历左右两端:当arrl>arrl-1时l-=1、arrr>arrr+1时l+=1;随后更新答案ans为最大的ans=max(ans, r-l+1)。
代码实现:
python
class Solution:
def longestMountain(self, arr: List[int]) -> int:
# 思路:找山顶,然后从山顶往两端进行拓展。如何判断一个节点是否可以作为山顶?:当arr[i]>arr[l] and arr[i]>arr[r](即山顶元素值大于左右两端值);然后遍历左右两端:当arr[l]>arr[l-1]时l-=1、arr[r]>arr[r+1]时l+=1;随后更新答案ans为最大的ans=max(ans, r-l+1)。
n = len(arr)
ans = 0
for i in range(1, n-1): # 从1开始到n-2结束,遍历所有数判断是否可以作为山顶。
l = i-1
r = i+1
if arr[i] > arr[l] and arr[i] > arr[r]: # 当arr[i]可以作为山顶时
while l>0 and arr[l] > arr[l-1]: # 左边为递减时继续遍历
l -= 1
while r < n-1 and arr[r] > arr[r+1]: # 右边为递减时继续遍历
r += 1
ans = max(ans, r-l+1) # 更新答案为最大山脉
return ans复杂度分析
时间复杂度 O(n²):最坏情况每个山顶向两侧扩展 O(n)。
空间复杂度 O(1)。
答疑:
请评论区留言。
8、螺旋遍历二维数组(146题-简单)
题目描述:
给定一个二维数组 array,请返回「螺旋遍历」该数组的结果。
螺旋遍历:从左上角开始,按照 向右、向下、向左、向上 的顺序 依次 提取元素,然后再进入内部一层重复相同的步骤,直到提取完所有元素。
示例 1:
输入:array = \[1,2,3,8,9,4,7,6,5]
输出:1,2,3,4,5,6,7,8,9
解题思路:
按照右、下、左、上的顺序走,步数变化(m表示行n表示列)为n、m-1、n-1、m-2;第二轮为n-2、m-3、n-3、m-4,所以列的变化是n→n-1、行的变化是m-1→m-2;所以每次转弯时转90°时,令n, m = m-1, n即可实现步长控制。直到答案的长度等于矩阵大小。
代码实现:
python
DIR = (0, 1), (1, 0), (0, -1), (-1, 0) # 分别表示右、下、左、上(第一维dx控制上下, 第二维dy控制左右)
class Solution:
def spiralArray(self, array: List[List[int]]) -> List[int]:
# 思路:按照右、下、左、上的顺序走,步数变化(m表示行n表示列)为n、m-1、n-1、m-2;第二轮为n-2、m-3、n-3、m-4;每次转弯时转90°。直到答案的长度等于矩阵大小。
if not array:
return []
ans = []
m, n = len(array), len(array[0])
size = m*n
i, j, di = 0, -1, 0 # 表示初始从(0,-1)开始向右进行移动
while len(ans) < size: # ans长度未到达size时继续遍历
dx, dy = DIR[di] # 根据di方向进行移动
for numb in range(n):
i += dx
j += dy # 先走一步
ans.append(array[i][j])
di = (di + 1)%4 # 转弯90°
n, m = m-1, n # 步数变化n → m-1 → n-1 → m-2,下一轮也是如此变化
return ans复杂度分析
时间复杂度:O(mn),其中 m 和 n 分别为 array 的行数和列数。
空间复杂度:O(1)。返回值不计入。
答疑:
请评论区留言。
9、两数相加(236题-中等)
题目描述:
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
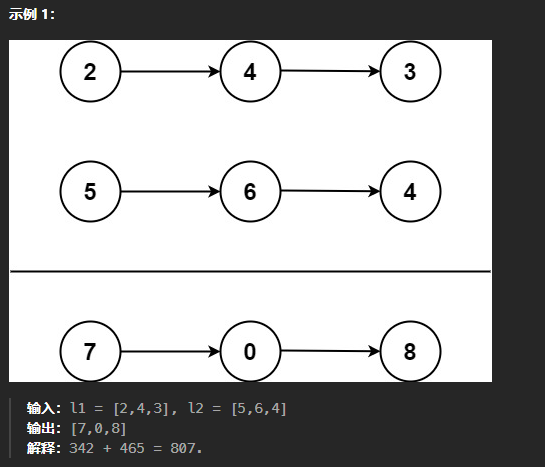
解题思路:
用carry当作进位数,若两个数组非空或者carry不为0时,计算当前数组之和。然后取余数作为新的节点,取进数作为carry的新值。直到两个链表都为空或者carry为空。
代码实现:
python
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def addTwoNumbers(self, l1: Optional[ListNode], l2: Optional[ListNode]) -> Optional[ListNode]:
# 思路:用carry当作进位数,若两个数组非空或者carry不为0时,计算当前数组之和。然后取余数作为新的节点,取进数作为carry的新值。直到两个链表都为空或者carry为空。
carry = 0 # 初始化进位数为0
cur = dummy = ListNode()
while l1 or l2 or carry != 0: # 考虑carry不为0为了防止最后一次计算时需要进位,此时进位需要创建新节点。
if l1: # 当l1不为空链表时,计算进位数与当前节点之和
carry += l1.val
l1 = l1.next
if l2: # 当l1不为空链表时,计算进位数与当前节点之和
carry += l2.val
l2 = l2.next
cur.next = ListNode(carry % 10) # 取当前和的余数作为新节点
cur = cur.next
carry //= 10 # 取当前和的进位数作为新的进位数,为下轮更新做准备
return dummy.next复杂度分析
时间复杂度:O(n),其中 n 为 l1长度和 l2长度的最大值。
空间复杂度:O(1)。返回值不计入。
答疑:
请评论区留言。
10、无重复字符的最长子串(3题-中等)
题目描述:
给定一个字符串 s ,请你找出其中不含有重复字符的 最长 子串 的长度。
示例 1:
输入: s = "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。注意 "bca" 和 "cab" 也是正确答案。
解题思路:
滑动窗口求解。用一个字典cnt记录当前当前字符串x的个数,用ans记录无重复字符串的最长长度,右窗口不断滑动,当遇到cntx>=2时说明当前窗口有重复的字符串,左窗口需要右移同时cnts\[left] -= 1 ,移动到cntx不满足>=2的条件为止, 然后更新答案为最大值。
代码实现:
python
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
# 滑动窗口求解。用一个字典cnt记录当前当前字符串x的个数,用ans记录无重复字符串的最长长度,右窗口不断滑动,当遇到cnt[x]>=2时说明当前窗口有重复的字符串,左窗口需要右移同时cnt[left] -= 1 ,移动到cnt[x]不满足>=2的条件为止, 然后更新答案为最大值。
cnt = defaultdict(int)
left = 0
ans = 0
for right, c in enumerate(s):
cnt[c] += 1
while cnt[c] >= 2:
cnt[s[left]] -= 1
left += 1
ans = max(ans, right - left + 1)
return ans复杂度分析
时间复杂度:O(n),其中 n 为 s 的长度。注意 left 至多增加 n 次,所以整个二重循环至多循环 O(n) 次。
空间复杂度:O(∣Σ∣),其中 ∣Σ∣ 为字符集合的大小,本题中字符均为 ASCII 字符,所以 ∣Σ∣≤128。
答疑:
请评论区留言。