iptables vs IPVS:kube-proxy 代理 Service 到底差在哪?
在 K8s 里,Service 之所以能"像一个固定入口一样"把流量稳稳转到后端 Pod,背后离不开 kube-proxy。
但 kube-proxy 有两种常见模式:iptables 和 IPVS。很多人第一次听到都会想:不都能把 ClusterIP 转到 Pod 吗?能用不就行了?
小集群里确实差别不大,可一旦 Service 多、Pod 多、扩缩容频繁,差距就会慢慢冒出来------你会开始感受到"谁更稳、谁更扛规模、谁更省心"。
把它们理解成两种引流方式就够了:
-
iptables:像在路口贴很多"改道通知",靠规则链把流量拐到 Pod
-
IPVS:像直接装了一套"内核负载均衡器",靠转发表按算法分流
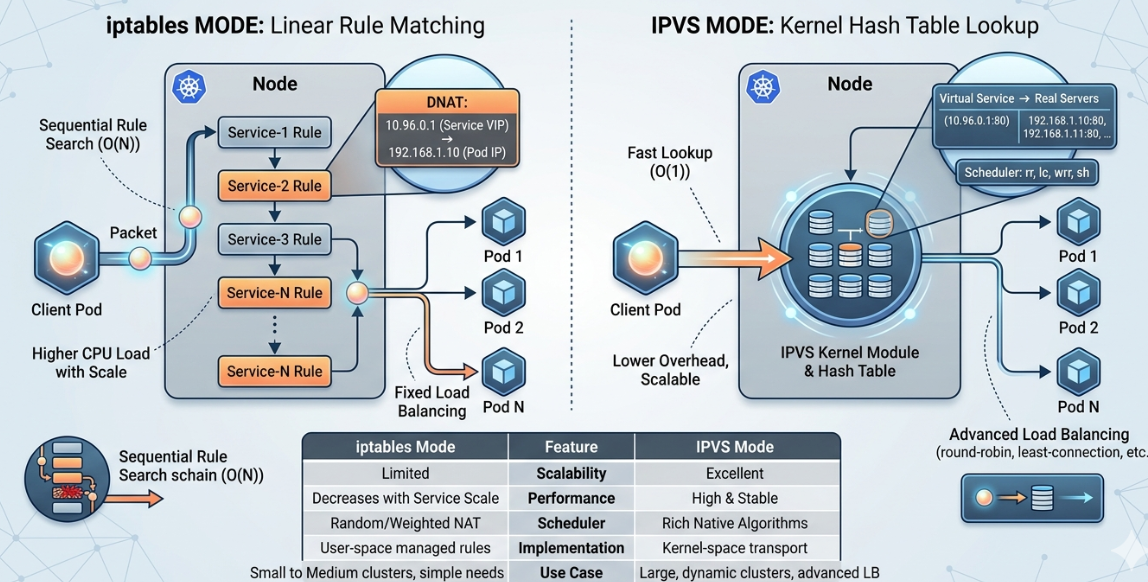
iptables 模式:靠 NAT 规则把请求"改写"到某个 Pod
iptables 模式的核心思路很直白:在每个节点上写一堆 NAT(DNAT)规则。当你访问 Service(ClusterIP:Port) 时,内核命中规则,把目标地址改成某个 PodIP:Port,于是流量就被转走了。
它的优点很"务实":
-
默认就能用:兼容性强,几乎所有 Linux 环境都能跑
-
排障路径直观:看规则链基本能顺着转发逻辑追下去
-
历史成熟:生态稳定,心智负担低
但它的短板也很现实,尤其规模上来之后:
-
Service/Endpoint 越多,规则链越长
-
链越长,匹配成本越高(说白了就是要"过更多关卡")
-
扩缩容、滚动更新频繁时,规则更新更"重",更容易变成性能负担
所以 iptables 的体验往往是:小规模很舒服,大规模开始变得"重",尤其在变更频繁的时候更明显。
IPVS 模式:把 Service 做成"转发表",内核按算法转发
IPVS(IP Virtual Server)是 Linux 内核里的四层负载均衡能力。kube-proxy 使用 IPVS 时,会把 Service 和后端 Pod 组织成一张"虚拟服务 → 真实服务器"的表,让内核按调度算法直接转发。
这套方式更像传统 LB,因此优势也更"LB 化":
-
性能更稳:面对大量 Service/Endpoint 更不容易抖
-
更适合大规模:偏"查表式转发",而不是长链匹配
-
调度算法更丰富:轮询、加权轮询、最少连接、源地址哈希等
-
Endpoint 频繁变化时,更新更像"改表项",通常更轻一些
当然它也不是零成本:
-
依赖内核 IPVS 模块和相关工具
-
排障思路不同:不能只看 iptables,需要会看 IPVS 表(以及必要时看连接状态)
你可以把 IPVS 想象成:不是到处贴通知,而是直接建了一套"交通指挥系统",车来了按表分流。
关键差异一页看懂(写给想快速做决策的人)
转发机制
-
iptables:规则链匹配 + NAT 改写(偏"规则堆出来的转发")
-
IPVS:内核转发表 + 调度算法(偏"查表式转发")
规模增长后的表现
-
iptables:规则变多、更新变重,性能更容易受影响
-
IPVS:更稳、更扛大规模 Service/Endpoint
扩缩容/滚动更新频繁时
-
iptables:可能需要更新大量规则,开销更明显
-
IPVS:更多是更新表项,通常更轻、更平滑
排障习惯
-
iptables:看 NAT 链路规则
-
IPVS:看虚拟服务/真实服务器表与连接状态
怎么选?别玄学,按场景就够了
-
集群规模不大、Service 不多:iptables 足够省心,默认能跑,维护成本低
-
集群规模大、服务多、变更频繁:IPVS 更稳,越到后面越能体现价值
-
你希望调度策略更像传统 LB、更可控:也更偏向 IPVS
归根结底,它们都能把 Service 流量转到 Pod,区别在于:
iptables 靠"规则链"硬撑,IPVS 靠"内核 LB 转发表"更专业。
规模小你可能感觉不出来,规模大你就知道为什么有人坚持要换了。