解决Conda环境下RTX 50系列显卡PyTorch+Transformers+PEFT微调报错
文章目录
- [解决Conda环境下RTX 50系列显卡PyTorch+Transformers+PEFT微调报错](#解决Conda环境下RTX 50系列显卡PyTorch+Transformers+PEFT微调报错)
-
- [1. 问题背景与现象描述](#1. 问题背景与现象描述)
- [2. 核心原因分析:CUDA兼容性的三层逻辑](#2. 核心原因分析:CUDA兼容性的三层逻辑)
- [3. 解决方案与环境配置](#3. 解决方案与环境配置)
-
- [3.1 核心软硬件信息 (环境清单)](#3.1 核心软硬件信息 (环境清单))
- [3.2 基础环境安装与代码隔离](#3.2 基础环境安装与代码隔离)
- [3.3 完整依赖记录 (requirements.txt)](#3.3 完整依赖记录 (requirements.txt))
- [4. Windows 平台训练避坑指南](#4. Windows 平台训练避坑指南)
声明:本文记录了个人在配置 Conda 环境过程中遇到的问题与解决思路,文中涉及的软硬件环境及操作步骤仅供参考与学习。
1. 问题背景与现象描述
在搭建大模型微调环境(GPU PyTorch + Transformers + PEFT)时,常规的 PyTorch 安装方案会触发严重的兼容性问题。
具体的错误日志如下:
shell
UserWarning: NVIDIA GeForce RTX 5060 Laptop GPU with CUDA capability sm_120 is not compatible with the current PyTorch installation. The current PyTorch install supports CUDA capabilities sm_50 sm_60 sm_61 sm_70 sm_75 sm_80 sm_86 sm_90. If you want to use the NVIDIA GeForce RTX 5060 Laptop GPU GPU with PyTorch, please check the instructions at [https://pytorch.org/get-started/locally/](https://pytorch.org/get-started/locally/) queued_call() NVIDIA GeForce RTX 5060 Laptop GPU 2.11.0+cu1262. 核心原因分析:CUDA兼容性的三层逻辑
经梳理分析,上述报错的核心在于 GPU 架构的不兼容。
- Driver(显卡驱动):✅ 向下兼容。新版本的显卡驱动可以运行旧版本的 CUDA 程序。
- CUDA Runtime(如 cu126 / cu128):⚠️ 部分兼容。高版本的 CUDA Runtime(如 cu128)通常可以运行低版本(如 cu126)编译的程序,但这层兼容性不涉及对新物理硬件架构的直接支持。
- GPU 架构(核心症结) :❌ 不兼容。RTX 50 系列显卡的底层架构版本为
sm_120。而当前主流稳定版(Stable)的 PyTorch 最高仅编译支持到sm_90(即 RTX 40 系列的 Ada Lovelace 架构)。新 GPU 架构无法被旧的深度学习框架底层库自动识别与支持。
3. 解决方案与环境配置
针对 sm_120 架构的兼容性问题,目前验证可行的解决方案是使用适配新架构的 PyTorch Nightly (开发版)。
3.1 核心软硬件信息 (环境清单)
以下为成功运行微调链路的核心硬件与基础环境配置记录:
| 环境维度 | 配置详情 | 补充说明 |
|---|---|---|
| 硬件显卡 | NVIDIA RTX 50 系列 | 硬件过新(架构 sm_120),官方稳定版暂无适配 |
| 操作系统 | Windows 11 | 需注意多进程加载兼容性(详见第4节) |
| 环境管理 | Conda (Python 3.13.12) | 实际环境版本记录。新建环境示例:conda create -n pytorch-gpu python=3.13.12 |
| 核心框架 | PyTorch Nightly 开发版 | 版本号须为 torch==2.12.0.dev* 系列 |
| CUDA支持 | cu130 |
配合 Nightly 版使用 |
3.2 基础环境安装与代码隔离
在开始安装前,建议务必使用 Conda 创建独立的虚拟环境。
大模型微调的依赖包(尤其是与 CUDA 相关的底层库)较为繁杂,易与系统中原有的 Python 环境发生版本冲突。做好代码与环境隔离,是避免后续兼容性问题的首要步骤。
shell
# 1. 创建独立环境,实现代码隔离
conda create -n pytorch-gpu python=3.13.12 -y
# 2. 激活 conda 环境
conda activate pytorch-gpu
# 3. 安装适配 RTX 50 的 PyTorch 开发版(从官网复制)
pip3 install --pre torch torchvision --index-url [https://download.pytorch.org/whl/nightly/cu130](https://download.pytorch.org/whl/nightly/cu130)- 安装包官网:PyTorch
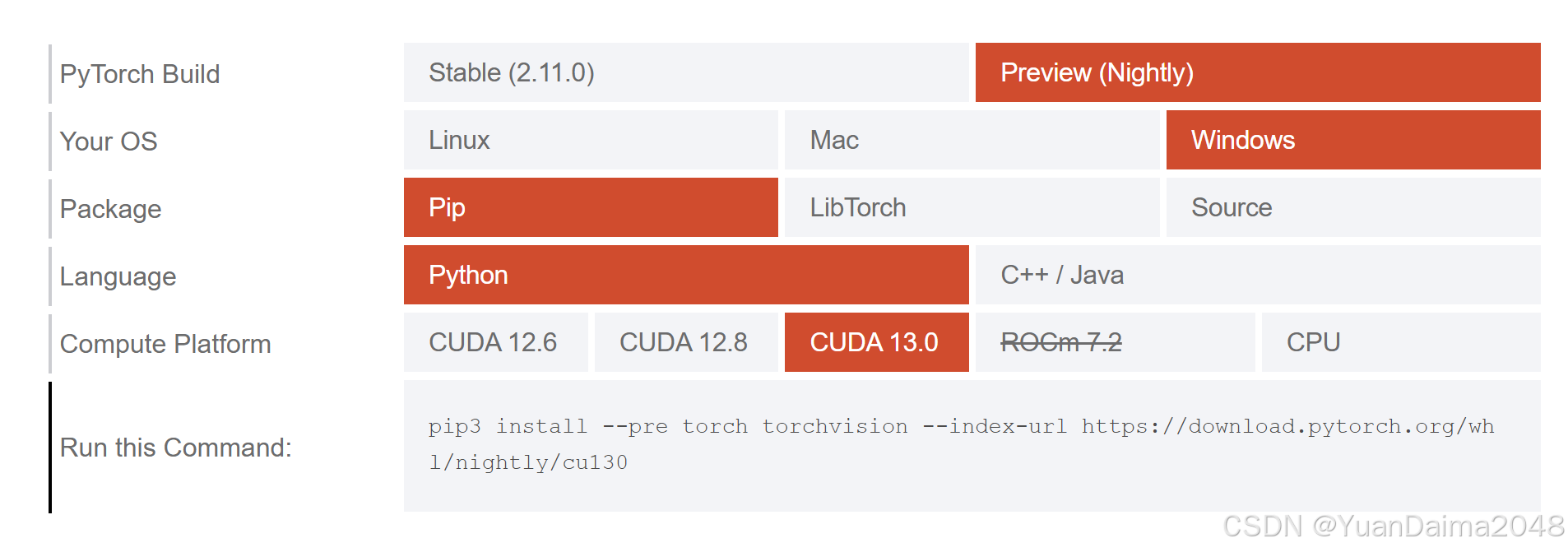
3.3 完整依赖记录 (requirements.txt)
为保证整个大模型微调链路(特别是 LoRA 微调)的稳定运行,需严格控制 Transformers 及相关生态包的版本。
以下为实际安装并验证通过的依赖版本记录(适配 RTX 50 环境的 requirements.txt):
py
# ===================== LLM微调核心依赖 (RTX50专用) =====================
# 适配 Windows + PyTorch Nightly (CUDA130) | 仅保留训练核心包
torch==2.12.0.dev20260331+cu130
torchvision==0.27.0.dev20260331+cu130
# HuggingFace 核心训练框架
transformers==5.4.0
datasets==4.8.4
evaluate==0.4.6
accelerate==1.13.0
tokenizers==0.22.2
# LoRA 微调核心
peft==0.18.1
# 数据处理与评估核心
scikit-learn==1.8.0
scipy==1.17.1执行安装:
shell
pip install -r requirements.txt4. Windows 平台训练避坑指南
在 Windows 系统下使用上述环境进行模型训练时,除了架构兼容性外,还需特别注意多进程数据加载的问题。
核心建议 :在使用 Trainer 或自行编写 DataLoader 时,必须将 num_workers 设置为 0。
- 原因 :Windows 下的 Python 多进程机制(
spawn)与 Unix/Linux(fork)不同,在加载复杂模型或大数据集时极易引发进程崩溃或死锁。 - 对策 :确保代码中包含
dataloader_num_workers=0(这是 Windows 系统下进行深度学习训练的基础兼容性设定)。