💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡
本文给大家带来的教程是将YOLO26添加注意力机制。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和修改,并将修改后的完整代码放在文章的最后,方便大家一键运行,小白也可轻松上手实践。以帮助您更好地学习深度学习目标检测YOLO系列的挑战。
专栏地址:************YOLO11入门 + 改进涨点------点击即可跳转 欢迎订阅****************
目录
[2. DeBiFormer代码实现](#2. DeBiFormer代码实现)
[2.1 将DeBiFormer添加到YOLO26中](#2.1 将DeBiFormer添加到YOLO26中)
[2.2 更改init.py文件](#2.2 更改init.py文件)
[2.3 添加yaml文件](#2.3 添加yaml文件)
[2.4 在task.py中进行注册](#2.4 在task.py中进行注册)
[2.5 执行程序](#2.5 执行程序)
[3. 完整代码分享](#3. 完整代码分享)
[4. GFLOPs](#4. GFLOPs)
[5. 进阶](#5. 进阶)
1.论文

论文地址:DeBiFormer: Vision Transformer with Deformable Agent Bi-level Routing Attention
官方代码:官方代码仓库点击即可跳转
2. DeBiFormer代码实现
2.1 将DeBiFormer添加到YOLO26中
**关键步骤一:**在ultralytics\ultralytics\nn\modules下面新建文件夹models,在文件夹下新建DeBiFormer.py,粘贴下面代码
python
import torch
import torch.nn as nn
import torch.nn.functional as F
from collections import defaultdict, OrderedDict
from functools import partial
import numbers
import math
from timm.models.registry import register_model
from timm.models.layers import to_2tuple, trunc_normal_, DropPath
from timm.models.vision_transformer import _cfg
from einops import rearrange
from einops.layers.torch import Rearrange
# from fairscale.nn.checkpoint import checkpoint_wrapper
# Your model and other code here
class LayerNorm2d(nn.Module):
def __init__(self,
channels
):
super().__init__()
self.ln = nn.LayerNorm(channels)
def forward(self, x):
x = rearrange(x, "N C H W -> N H W C")
x = self.ln(x)
x = rearrange(x, "N H W C -> N C H W")
return x
def init_linear(m):
if isinstance(m, (nn.Conv2d, nn.Linear)):
nn.init.kaiming_normal_(m.weight)
if m.bias is not None: nn.init.zeros_(m.bias)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def to_4d(x,h,w):
return rearrange(x, 'b (h w) c -> b c h w',h=h,w=w)
#def to_4d(x,s,h,w):
# return rearrange(x, 'b (s h w) c -> b c s h w',s=s,h=h,w=w)
def to_3d(x):
return rearrange(x, 'b c h w -> b (h w) c')
#def to_3d(x):
# return rearrange(x, 'b c s h w -> b (s h w) c')
class Partial:
def __init__(self, module, *args, **kwargs):
self.module = module
self.args = args
self.kwargs = kwargs
def __call__(self, *args_c, **kwargs_c):
return self.module(*args_c, *self.args, **kwargs_c, **self.kwargs)
class LayerNormChannels(nn.Module):
def __init__(self, channels):
super().__init__()
self.norm = nn.LayerNorm(channels)
def forward(self, x):
x = x.transpose(1, -1)
x = self.norm(x)
x = x.transpose(-1, 1)
return x
class LayerNormProxy(nn.Module):
def __init__(self, dim):
super().__init__()
self.norm = nn.LayerNorm(dim)
def forward(self, x):
x = rearrange(x, 'b c h w -> b h w c')
x = self.norm(x)
return rearrange(x, 'b h w c -> b c h w')
class BiasFree_LayerNorm(nn.Module):
def __init__(self, normalized_shape):
super(BiasFree_LayerNorm, self).__init__()
if isinstance(normalized_shape, numbers.Integral):
normalized_shape = (normalized_shape,)
normalized_shape = torch.Size(normalized_shape)
assert len(normalized_shape) == 1
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.normalized_shape = normalized_shape
def forward(self, x):
sigma = x.var(-1, keepdim=True, unbiased=False)
return x / torch.sqrt(sigma+1e-5) * self.weight
class WithBias_LayerNorm(nn.Module):
def __init__(self, normalized_shape):
super(WithBias_LayerNorm, self).__init__()
if isinstance(normalized_shape, numbers.Integral):
normalized_shape = (normalized_shape,)
normalized_shape = torch.Size(normalized_shape)
assert len(normalized_shape) == 1
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.normalized_shape = normalized_shape
def forward(self, x):
mu = x.mean(-1, keepdim=True)
sigma = x.var(-1, keepdim=True, unbiased=False)
return (x - mu) / torch.sqrt(sigma+1e-5) * self.weight + self.bias
class LayerNorm(nn.Module):
def __init__(self, dim, LayerNorm_type):
super(LayerNorm, self).__init__()
if LayerNorm_type =='BiasFree':
self.body = BiasFree_LayerNorm(dim)
else:
self.body = WithBias_LayerNorm(dim)
def forward(self, x):
h, w = x.shape[-2:]
return to_4d(self.body(to_3d(x)), h, w)
#class LayerNorm(nn.Module):
# def __init__(self, dim, LayerNorm_type):
# super(LayerNorm, self).__init__()
# if LayerNorm_type =='BiasFree':
# self.body = BiasFree_LayerNorm(dim)
# else:
# self.body = WithBias_LayerNorm(dim)
# def forward(self, x):
# s, h, w = x.shape[-3:]
# return to_4d(self.body(to_3d(x)),s, h, w)
class DWConv(nn.Module):
def __init__(self, dim=768):
super(DWConv, self).__init__()
self.dwconv = nn.Conv2d(dim, dim, 3, 1, 1, bias=True, groups=dim)
def forward(self, x):
"""
x: NHWC tensor
"""
x = x.permute(0, 3, 1, 2) #NCHW
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1) #NHWC
return x
class ConvFFN(nn.Module):
def __init__(self, dim=768):
super(DWConv, self).__init__()
self.dwconv = nn.Conv2d(dim, dim, 1, 1, 0)
def forward(self, x):
"""
x: NHWC tensor
"""
x = x.permute(0, 3, 1, 2) #NCHW
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1) #NHWC
return x
class Attention(nn.Module):
"""
vanilla attention
"""
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
"""
args:
x: NHWC tensor
return:
NHWC tensor
"""
_, H, W, _ = x.size()
x = rearrange(x, 'n h w c -> n (h w) c')
#######################################
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
#######################################
x = rearrange(x, 'n (h w) c -> n h w c', h=H, w=W)
return x
class AttentionLePE(nn.Module):
"""
vanilla attention
"""
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., side_dwconv=5):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.lepe = nn.Conv2d(dim, dim, kernel_size=side_dwconv, stride=1, padding=side_dwconv//2, groups=dim) if side_dwconv > 0 else \
lambda x: torch.zeros_like(x)
def forward(self, x):
"""
args:
x: NHWC tensor
return:
NHWC tensor
"""
_, H, W, _ = x.size()
x = rearrange(x, 'n h w c -> n (h w) c')
#######################################
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
lepe = self.lepe(rearrange(x, 'n (h w) c -> n c h w', h=H, w=W))
lepe = rearrange(lepe, 'n c h w -> n (h w) c')
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = x + lepe
x = self.proj(x)
x = self.proj_drop(x)
#######################################
x = rearrange(x, 'n (h w) c -> n h w c', h=H, w=W)
return x
class nchwAttentionLePE(nn.Module):
"""
Attention with LePE, takes nchw input
"""
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., side_dwconv=5):
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.scale = qk_scale or self.head_dim ** -0.5
self.qkv = nn.Conv2d(dim, dim*3, kernel_size=1, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Conv2d(dim, dim, kernel_size=1)
self.proj_drop = nn.Dropout(proj_drop)
self.lepe = nn.Conv2d(dim, dim, kernel_size=side_dwconv, stride=1, padding=side_dwconv//2, groups=dim) if side_dwconv > 0 else \
lambda x: torch.zeros_like(x)
def forward(self, x:torch.Tensor):
"""
args:
x: NCHW tensor
return:
NCHW tensor
"""
B, C, H, W = x.size()
q, k, v = self.qkv.forward(x).chunk(3, dim=1) # B, C, H, W
attn = q.view(B, self.num_heads, self.head_dim, H*W).transpose(-1, -2) @ \
k.view(B, self.num_heads, self.head_dim, H*W)
attn = torch.softmax(attn*self.scale, dim=-1)
attn = self.attn_drop(attn)
# (B, nhead, HW, HW) @ (B, nhead, HW, head_dim) -> (B, nhead, HW, head_dim)
output:torch.Tensor = attn @ v.view(B, self.num_heads, self.head_dim, H*W).transpose(-1, -2)
output = output.permute(0, 1, 3, 2).reshape(B, C, H, W)
output = output + self.lepe(v)
output = self.proj_drop(self.proj(output))
return output
class TopkRouting(nn.Module):
"""
differentiable topk routing with scaling
Args:
qk_dim: int, feature dimension of query and key
topk: int, the 'topk'
qk_scale: int or None, temperature (multiply) of softmax activation
with_param: bool, wether inorporate learnable params in routing unit
diff_routing: bool, wether make routing differentiable
soft_routing: bool, wether make output value multiplied by routing weights
"""
def __init__(self, qk_dim, topk=4, qk_scale=None, param_routing=False, diff_routing=False):
super().__init__()
self.topk = topk
self.qk_dim = qk_dim
self.scale = qk_scale or qk_dim ** -0.5
self.diff_routing = diff_routing
# TODO: norm layer before/after linear?
self.emb = nn.Linear(qk_dim, qk_dim) if param_routing else nn.Identity()
# routing activation
self.routing_act = nn.Softmax(dim=-1)
def forward(self, query:torch.Tensor, key:torch.Tensor)->tuple[torch.Tensor, torch.Tensor]:
"""
Args:
q, k: (n, p^2, c) tensor
Return:
r_weight, topk_index: (n, p^2, topk) tensor
"""
if not self.diff_routing:
query, key = query.detach(), key.detach()
query_hat, key_hat = self.emb(query), self.emb(key) # per-window pooling -> (n, p^2, c)
attn_logit = (query_hat*self.scale) @ key_hat.transpose(-2, -1) # (n, p^2, p^2)
topk_attn_logit, topk_index = torch.topk(attn_logit, k=self.topk, dim=-1) # (n, p^2, k), (n, p^2, k)
r_weight = self.routing_act(topk_attn_logit) # (n, p^2, k)
return r_weight, topk_index
class KVGather(nn.Module):
def __init__(self, mul_weight='none'):
super().__init__()
assert mul_weight in ['none', 'soft', 'hard']
self.mul_weight = mul_weight
def forward(self, r_idx:torch.Tensor, r_weight:torch.Tensor, kv:torch.Tensor):
"""
r_idx: (n, p^2, topk) tensor
r_weight: (n, p^2, topk) tensor
kv: (n, p^2, w^2, c_kq+c_v)
Return:
(n, p^2, topk, w^2, c_kq+c_v) tensor
"""
# select kv according to routing index
n, p2, w2, c_kv = kv.size()
topk = r_idx.size(-1)
# print(r_idx.size(), r_weight.size())
# FIXME: gather consumes much memory (topk times redundancy), write cuda kernel?
topk_kv = torch.gather(kv.view(n, 1, p2, w2, c_kv).expand(-1, p2, -1, -1, -1), # (n, p^2, p^2, w^2, c_kv) without mem cpy
dim=2,
index=r_idx.view(n, p2, topk, 1, 1).expand(-1, -1, -1, w2, c_kv) # (n, p^2, k, w^2, c_kv)
)
if self.mul_weight == 'soft':
topk_kv = r_weight.view(n, p2, topk, 1, 1) * topk_kv # (n, p^2, k, w^2, c_kv)
elif self.mul_weight == 'hard':
raise NotImplementedError('differentiable hard routing TBA')
# else: #'none'
# topk_kv = topk_kv # do nothing
return topk_kv
class QKVLinear(nn.Module):
def __init__(self, dim, qk_dim, bias=True):
super().__init__()
self.dim = dim
self.qk_dim = qk_dim
self.qkv = nn.Linear(dim, qk_dim + qk_dim + dim, bias=bias)
def forward(self, x):
q, kv = self.qkv(x).split([self.qk_dim, self.qk_dim+self.dim], dim=-1)
return q, kv
# q, k, v = self.qkv(x).split([self.qk_dim, self.qk_dim, self.dim], dim=-1)
# return q, k, v
class QKVConv(nn.Module):
def __init__(self, dim, qk_dim, bias=True):
super().__init__()
self.dim = dim
self.qk_dim = qk_dim
self.qkv = nn.Conv2d(dim, qk_dim + qk_dim + dim, 1, 1, 0)
def forward(self, x):
q, kv = self.qkv(x).split([self.qk_dim, self.qk_dim+self.dim], dim=1)
return q, kv
class BiLevelRoutingAttention(nn.Module):
"""
n_win: number of windows in one side (so the actual number of windows is n_win*n_win)
kv_per_win: for kv_downsample_mode='ada_xxxpool' only, number of key/values per window. Similar to n_win, the actual number is kv_per_win*kv_per_win.
topk: topk for window filtering
param_attention: 'qkvo'-linear for q,k,v and o, 'none': param free attention
param_routing: extra linear for routing
diff_routing: wether to set routing differentiable
soft_routing: wether to multiply soft routing weights
"""
def __init__(self, dim, num_heads=8, n_win=7, qk_dim=None, qk_scale=None,
kv_per_win=4, kv_downsample_ratio=4, kv_downsample_kernel=None, kv_downsample_mode='identity',
topk=4, param_attention="qkvo", param_routing=False, diff_routing=False, soft_routing=False, side_dwconv=3,
auto_pad=False):
super().__init__()
# local attention setting
self.dim = dim
self.n_win = n_win # Wh, Ww
self.num_heads = num_heads
self.qk_dim = qk_dim or dim
assert self.qk_dim % num_heads == 0 and self.dim % num_heads==0, 'qk_dim and dim must be divisible by num_heads!'
self.scale = qk_scale or self.qk_dim ** -0.5
################side_dwconv (i.e. LCE in ShuntedTransformer)###########
self.lepe = nn.Conv2d(dim, dim, kernel_size=side_dwconv, stride=1, padding=side_dwconv//2, groups=dim) if side_dwconv > 0 else \
lambda x: torch.zeros_like(x)
################ global routing setting #################
self.topk = topk
self.param_routing = param_routing
self.diff_routing = diff_routing
self.soft_routing = soft_routing
# router
assert not (self.param_routing and not self.diff_routing) # cannot be with_param=True and diff_routing=False
self.router = TopkRouting(qk_dim=self.qk_dim,
qk_scale=self.scale,
topk=self.topk,
diff_routing=self.diff_routing,
param_routing=self.param_routing)
if self.soft_routing: # soft routing, always diffrentiable (if no detach)
mul_weight = 'soft'
elif self.diff_routing: # hard differentiable routing
mul_weight = 'hard'
else: # hard non-differentiable routing
mul_weight = 'none'
self.kv_gather = KVGather(mul_weight=mul_weight)
# qkv mapping (shared by both global routing and local attention)
self.param_attention = param_attention
if self.param_attention == 'qkvo':
self.qkv = QKVLinear(self.dim, self.qk_dim)
self.wo = nn.Linear(dim, dim)
elif self.param_attention == 'qkv':
self.qkv = QKVLinear(self.dim, self.qk_dim)
self.wo = nn.Identity()
else:
raise ValueError(f'param_attention mode {self.param_attention} is not surpported!')
self.kv_downsample_mode = kv_downsample_mode
self.kv_per_win = kv_per_win
self.kv_downsample_ratio = kv_downsample_ratio
self.kv_downsample_kenel = kv_downsample_kernel
if self.kv_downsample_mode == 'ada_avgpool':
assert self.kv_per_win is not None
self.kv_down = nn.AdaptiveAvgPool2d(self.kv_per_win)
elif self.kv_downsample_mode == 'ada_maxpool':
assert self.kv_per_win is not None
self.kv_down = nn.AdaptiveMaxPool2d(self.kv_per_win)
elif self.kv_downsample_mode == 'maxpool':
assert self.kv_downsample_ratio is not None
self.kv_down = nn.MaxPool2d(self.kv_downsample_ratio) if self.kv_downsample_ratio > 1 else nn.Identity()
elif self.kv_downsample_mode == 'avgpool':
assert self.kv_downsample_ratio is not None
self.kv_down = nn.AvgPool2d(self.kv_downsample_ratio) if self.kv_downsample_ratio > 1 else nn.Identity()
elif self.kv_downsample_mode == 'identity': # no kv downsampling
self.kv_down = nn.Identity()
elif self.kv_downsample_mode == 'fracpool':
# assert self.kv_downsample_ratio is not None
# assert self.kv_downsample_kenel is not None
# TODO: fracpool
# 1. kernel size should be input size dependent
# 2. there is a random factor, need to avoid independent sampling for k and v
raise NotImplementedError('fracpool policy is not implemented yet!')
elif kv_downsample_mode == 'conv':
# TODO: need to consider the case where k != v so that need two downsample modules
raise NotImplementedError('conv policy is not implemented yet!')
else:
raise ValueError(f'kv_down_sample_mode {self.kv_downsaple_mode} is not surpported!')
# softmax for local attention
self.attn_act = nn.Softmax(dim=-1)
self.auto_pad=auto_pad
def forward(self, x, ret_attn_mask=False):
"""
x: NHWC tensor
Return:
NHWC tensor
"""
# NOTE: use padding for semantic segmentation
###################################################
if self.auto_pad:
N, H_in, W_in, C = x.size()
pad_l = pad_t = 0
pad_r = (self.n_win - W_in % self.n_win) % self.n_win
pad_b = (self.n_win - H_in % self.n_win) % self.n_win
x = F.pad(x, (0, 0, # dim=-1
pad_l, pad_r, # dim=-2
pad_t, pad_b)) # dim=-3
_, H, W, _ = x.size() # padded size
else:
N, H, W, C = x.size()
# This assertion is the reason for the error. Even if commented out,
# the rearrange operation will fail if dimensions are not divisible.
if H % self.n_win != 0 or W % self.n_win != 0:
raise ValueError(
f"Input height ({H}) and width ({W}) must be divisible by n_win ({self.n_win}). "
"Consider setting auto_pad=True."
)
###################################################
# patchify, (n, p^2, w, w, c), keep 2d window as we need 2d pooling to reduce kv size
x = rearrange(x, "n (j h) (i w) c -> n (j i) h w c", j=self.n_win, i=self.n_win)
#################qkv projection###################
# q: (n, p^2, w, w, c_qk)
# kv: (n, p^2, w, w, c_qk+c_v)
# NOTE: separte kv if there were memory leak issue caused by gather
q, kv = self.qkv(x)
# pixel-wise qkv
# q_pix: (n, p^2, w^2, c_qk)
# kv_pix: (n, p^2, h_kv*w_kv, c_qk+c_v)
q_pix = rearrange(q, 'n p2 h w c -> n p2 (h w) c')
kv_pix = self.kv_down(rearrange(kv, 'n p2 h w c -> (n p2) c h w'))
kv_pix = rearrange(kv_pix, '(n j i) c h w -> n (j i) (h w) c', j=self.n_win, i=self.n_win)
q_win, k_win = q.mean([2, 3]), kv[..., 0:self.qk_dim].mean([2, 3]) # window-wise qk, (n, p^2, c_qk), (n, p^2, c_qk)
##################side_dwconv(lepe)##################
# NOTE: call contiguous to avoid gradient warning when using ddp
lepe = self.lepe(rearrange(kv[..., self.qk_dim:], 'n (j i) h w c -> n c (j h) (i w)', j=self.n_win, i=self.n_win).contiguous())
lepe = rearrange(lepe, 'n c (j h) (i w) -> n (j h) (i w) c', j=self.n_win, i=self.n_win)
############ gather q dependent k/v #################
r_weight, r_idx = self.router(q_win, k_win) # both are (n, p^2, topk) tensors
kv_pix_sel = self.kv_gather(r_idx=r_idx, r_weight=r_weight, kv=kv_pix) #(n, p^2, topk, h_kv*w_kv, c_qk+c_v)
k_pix_sel, v_pix_sel = kv_pix_sel.split([self.qk_dim, self.dim], dim=-1)
# kv_pix_sel: (n, p^2, topk, h_kv*w_kv, c_qk)
# v_pix_sel: (n, p^2, topk, h_kv*w_kv, c_v)
######### do attention as normal ####################
k_pix_sel = rearrange(k_pix_sel, 'n p2 k w2 (m c) -> (n p2) m c (k w2)', m=self.num_heads) # flatten to BMLC, (n*p^2, m, topk*h_kv*w_kv, c_kq//m) transpose here?
v_pix_sel = rearrange(v_pix_sel, 'n p2 k w2 (m c) -> (n p2) m (k w2) c', m=self.num_heads) # flatten to BMLC, (n*p^2, m, topk*h_kv*w_kv, c_v//m)
q_pix = rearrange(q_pix, 'n p2 w2 (m c) -> (n p2) m w2 c', m=self.num_heads) # to BMLC tensor (n*p^2, m, w^2, c_qk//m)
# param-free multihead attention
attn_weight = (q_pix * self.scale) @ k_pix_sel # (n*p^2, m, w^2, c) @ (n*p^2, m, c, topk*h_kv*w_kv) -> (n*p^2, m, w^2, topk*h_kv*w_kv)
attn_weight = self.attn_act(attn_weight)
out = attn_weight @ v_pix_sel # (n*p^2, m, w^2, topk*h_kv*w_kv) @ (n*p^2, m, topk*h_kv*w_kv, c) -> (n*p^2, m, w^2, c)
out = rearrange(out, '(n j i) m (h w) c -> n (j h) (i w) (m c)', j=self.n_win, i=self.n_win,
h=H//self.n_win, w=W//self.n_win)
out = out + lepe
# output linear
out = self.wo(out)
# NOTE: use padding for semantic segmentation
# crop padded region
if self.auto_pad and (pad_r > 0 or pad_b > 0):
out = out[:, :H_in, :W_in, :].contiguous()
if ret_attn_mask:
return out, r_weight, r_idx, attn_weight
else:
return out
class TransformerMLPWithConv(nn.Module):
def __init__(self, channels, expansion, drop):
super().__init__()
self.dim1 = channels
self.dim2 = channels * expansion
self.linear1 = nn.Sequential(
nn.Conv2d(self.dim1, self.dim2, 1, 1, 0),
# nn.GELU(),
# nn.BatchNorm2d(self.dim2, eps=1e-5)
)
self.drop1 = nn.Dropout(drop, inplace=True)
self.act = nn.GELU()
# self.bn = nn.BatchNorm2d(self.dim2, eps=1e-5)
self.linear2 = nn.Sequential(
nn.Conv2d(self.dim2, self.dim1, 1, 1, 0),
# nn.BatchNorm2d(self.dim1, eps=1e-5)
)
self.drop2 = nn.Dropout(drop, inplace=True)
self.dwc = nn.Conv2d(self.dim2, self.dim2, 3, 1, 1, groups=self.dim2)
def forward(self, x):
x = self.linear1(x)
x = self.drop1(x)
x = x + self.dwc(x)
x = self.act(x)
# x = self.bn(x)
x = self.linear2(x)
x = self.drop2(x)
return x
class DeBiLevelRoutingAttention(nn.Module):
"""
n_win: number of windows in one side (so the actual number of windows is n_win*n_win)
kv_per_win: for kv_downsample_mode='ada_xxxpool' only, number of key/values per window. Similar to n_win, the actual number is kv_per_win*kv_per_win.
topk: topk for window filtering
param_attention: 'qkvo'-linear for q,k,v and o, 'none': param free attention
param_routing: extra linear for routing
diff_routing: wether to set routing differentiable
soft_routing: wether to multiply soft routing weights
"""
def __init__(self, dim, num_heads=8, n_win=7, qk_dim=None, qk_scale=None,
kv_per_win=4, kv_downsample_ratio=4, kv_downsample_kernel=None, kv_downsample_mode='identity',
topk=4, param_attention="qkvo", param_routing=False, diff_routing=False, soft_routing=False, side_dwconv=3,
auto_pad=False, param_size='small'):
super().__init__()
# local attention setting
self.dim = dim
self.n_win = n_win # Wh, Ww
self.num_heads = num_heads
self.qk_dim = qk_dim or dim
#############################################################
if param_size=='tiny':
if self.dim == 64 :
self.n_groups = 1
self.top_k_def = 16 # 2 128
self.kk = 9
self.stride_def = 8
self.expain_ratio = 3
self.q_size=to_2tuple(56)
if self.dim == 128 :
self.n_groups = 2
self.top_k_def = 16 # 4 256
self.kk = 7
self.stride_def = 4
self.expain_ratio = 3
self.q_size=to_2tuple(28)
if self.dim == 256 :
self.n_groups = 4
self.top_k_def = 4 # 8 512
self.kk = 5
self.stride_def = 2
self.expain_ratio = 3
self.q_size=to_2tuple(14)
if self.dim == 512 :
self.n_groups = 8
self.top_k_def = 49 # 8 512
self.kk = 3
self.stride_def = 1
self.expain_ratio = 3
self.q_size=to_2tuple(7)
#############################################################
if param_size=='small':
if self.dim == 64 :
self.n_groups = 1
self.top_k_def = 16 # 2 128
self.kk = 9
self.stride_def = 8
self.expain_ratio = 3
self.q_size=to_2tuple(56)
if self.dim == 128 :
self.n_groups = 2
self.top_k_def = 16 # 4 256
self.kk = 7
self.stride_def = 4
self.expain_ratio = 3
self.q_size=to_2tuple(28)
if self.dim == 256 :
self.n_groups = 4
self.top_k_def = 4 # 8 512
self.kk = 5
self.stride_def = 2
self.expain_ratio = 3
self.q_size=to_2tuple(14)
if self.dim == 512 :
self.n_groups = 8
self.top_k_def = 49 # 8 512
self.kk = 3
self.stride_def = 1
self.expain_ratio = 1
self.q_size=to_2tuple(7)
#############################################################
if param_size=='base':
if self.dim == 96 :
self.n_groups = 1
self.top_k_def = 16 # 2 128
self.kk = 9
self.stride_def = 8
self.expain_ratio = 3
self.q_size=to_2tuple(56)
if self.dim == 192 :
self.n_groups = 2
self.top_k_def = 16 # 4 256
self.kk = 7
self.stride_def = 4
self.expain_ratio = 3
self.q_size=to_2tuple(28)
if self.dim == 384 :
self.n_groups = 3
self.top_k_def = 4 # 8 512
self.kk = 5
self.stride_def = 2
self.expain_ratio = 3
self.q_size=to_2tuple(14)
if self.dim == 768 :
self.n_groups = 6
self.top_k_def = 49 # 8 512
self.kk = 3
self.stride_def = 1
self.expain_ratio = 3
self.q_size=to_2tuple(7)
self.q_h, self.q_w = self.q_size
self.kv_h, self.kv_w = self.q_h // self.stride_def, self.q_w // self.stride_def
self.n_group_channels = self.dim // self.n_groups
self.n_group_heads = self.num_heads // self.n_groups
self.n_group_channels = self.dim // self.n_groups
self.offset_range_factor = -1
self.head_channels = dim // num_heads
self.n_group_heads = self.num_heads // self.n_groups
#assert self.qk_dim % num_heads == 0 and self.dim % num_heads==0, 'qk_dim and dim must be divisible by num_heads!'
self.scale = qk_scale or self.qk_dim ** -0.5
self.rpe_table = nn.Parameter(
torch.zeros(self.num_heads, self.q_h * 2 - 1, self.q_w * 2 - 1)
)
trunc_normal_(self.rpe_table, std=0.01)
################side_dwconv (i.e. LCE in ShuntedTransformer)###########
self.lepe1 = nn.Conv2d(dim, dim, kernel_size=side_dwconv, stride=self.stride_def, padding=side_dwconv//2, groups=dim) if side_dwconv > 0 else \
lambda x: torch.zeros_like(x)
################ global routing setting #################
self.topk = topk
self.param_routing = param_routing
self.diff_routing = diff_routing
self.soft_routing = soft_routing
# router
#assert not (self.param_routing and not self.diff_routing) # cannot be with_param=True and diff_routing=False
self.router = TopkRouting(qk_dim=self.qk_dim,
qk_scale=self.scale,
topk=self.topk,
diff_routing=self.diff_routing,
param_routing=self.param_routing)
if self.soft_routing: # soft routing, always diffrentiable (if no detach)
mul_weight = 'soft'
elif self.diff_routing: # hard differentiable routing
mul_weight = 'hard'
else: # hard non-differentiable routing
mul_weight = 'none'
self.kv_gather = KVGather(mul_weight=mul_weight)
# qkv mapping (shared by both global routing and local attention)
self.param_attention = param_attention
if self.param_attention == 'qkvo':
#self.qkv = QKVLinear(self.dim, self.qk_dim)
self.qkv_conv = QKVConv(self.dim, self.qk_dim)
#self.wo = nn.Linear(dim, dim)
elif self.param_attention == 'qkv':
#self.qkv = QKVLinear(self.dim, self.qk_dim)
self.qkv_conv = QKVConv(self.dim, self.qk_dim)
#self.wo = nn.Identity()
else:
raise ValueError(f'param_attention mode {self.param_attention} is not surpported!')
self.kv_downsample_mode = kv_downsample_mode
self.kv_per_win = kv_per_win
self.kv_downsample_ratio = kv_downsample_ratio
self.kv_downsample_kenel = kv_downsample_kernel
if self.kv_downsample_mode == 'ada_avgpool':
assert self.kv_per_win is not None
self.kv_down = nn.AdaptiveAvgPool2d(self.kv_per_win)
elif self.kv_downsample_mode == 'ada_maxpool':
assert self.kv_per_win is not None
self.kv_down = nn.AdaptiveMaxPool2d(self.kv_per_win)
elif self.kv_downsample_mode == 'maxpool':
assert self.kv_downsample_ratio is not None
self.kv_down = nn.MaxPool2d(self.kv_downsample_ratio) if self.kv_downsample_ratio > 1 else nn.Identity()
elif self.kv_downsample_mode == 'avgpool':
assert self.kv_downsample_ratio is not None
self.kv_down = nn.AvgPool2d(self.kv_downsample_ratio) if self.kv_downsample_ratio > 1 else nn.Identity()
elif self.kv_downsample_mode == 'identity': # no kv downsampling
self.kv_down = nn.Identity()
elif self.kv_downsample_mode == 'fracpool':
raise NotImplementedError('fracpool policy is not implemented yet!')
elif kv_downsample_mode == 'conv':
raise NotImplementedError('conv policy is not implemented yet!')
else:
raise ValueError(f'kv_down_sample_mode {self.kv_downsaple_mode} is not surpported!')
self.attn_act = nn.Softmax(dim=-1)
self.auto_pad=auto_pad
##########################################################################################
self.proj_q = nn.Conv2d(
dim, dim,
kernel_size=1, stride=1, padding=0
)
self.proj_k = nn.Conv2d(
dim, dim,
kernel_size=1, stride=1, padding=0
)
self.proj_v = nn.Conv2d(
dim, dim,
kernel_size=1, stride=1, padding=0
)
self.proj_out = nn.Conv2d(
dim, dim,
kernel_size=1, stride=1, padding=0
)
self.unifyheads1 = nn.Conv2d(
dim, dim,
kernel_size=1, stride=1, padding=0
)
self.conv_offset_q = nn.Sequential(
nn.Conv2d(self.n_group_channels, self.n_group_channels, (self.kk,self.kk), (self.stride_def,self.stride_def), (self.kk//2,self.kk//2), groups=self.n_group_channels, bias=False),
LayerNormProxy(self.n_group_channels),
nn.GELU(),
nn.Conv2d(self.n_group_channels, 1, 1, 1, 0, bias=False),
)
### FFN
self.norm = nn.LayerNorm(dim, eps=1e-6)
self.norm2 = nn.LayerNorm(dim, eps=1e-6)
self.mlp =TransformerMLPWithConv(dim, self.expain_ratio, 0.)
@torch.no_grad()
def _get_ref_points(self, H_key, W_key, B, dtype, device):
ref_y, ref_x = torch.meshgrid(
torch.linspace(0.5, H_key - 0.5, H_key, dtype=dtype, device=device),
torch.linspace(0.5, W_key - 0.5, W_key, dtype=dtype, device=device),
indexing='ij'
)
ref = torch.stack((ref_y, ref_x), -1)
ref[..., 1].div_(W_key).mul_(2).sub_(1)
ref[..., 0].div_(H_key).mul_(2).sub_(1)
ref = ref[None, ...].expand(B * self.n_groups, -1, -1, -1) # B * g H W 2
return ref
@torch.no_grad()
def _get_q_grid(self, H, W, B, dtype, device):
ref_y, ref_x = torch.meshgrid(
torch.arange(0, H, dtype=dtype, device=device),
torch.arange(0, W, dtype=dtype, device=device),
indexing='ij'
)
ref = torch.stack((ref_y, ref_x), -1)
ref[..., 1].div_(W - 1.0).mul_(2.0).sub_(1.0)
ref[..., 0].div_(H - 1.0).mul_(2.0).sub_(1.0)
ref = ref[None, ...].expand(B * self.n_groups, -1, -1, -1) # B * g H W 2
return ref
def forward(self, x, ret_attn_mask=False):
dtype, device = x.dtype, x.device
"""
x: NHWC tensor
Return:
NHWC tensor
"""
# NOTE: use padding for semantic segmentation
###################################################
if self.auto_pad:
N, H_in, W_in, C = x.size()
pad_l = pad_t = 0
pad_r = (self.n_win - W_in % self.n_win) % self.n_win
pad_b = (self.n_win - H_in % self.n_win) % self.n_win
x = F.pad(x, (0, 0, # dim=-1
pad_l, pad_r, # dim=-2
pad_t, pad_b)) # dim=-3
_, H, W, _ = x.size() # padded size
else:
N, H, W, C = x.size()
if H % self.n_win != 0 or W % self.n_win != 0:
raise ValueError(
f"Input height ({H}) and width ({W}) must be divisible by n_win ({self.n_win}). "
"Consider setting auto_pad=True."
)
#print("X_in")
#print(x.shape)
###################################################
#q=self.proj_q_def(x)
x_res = rearrange(x, "n h w c -> n c h w")
#################qkv projection###################
q,kv = self.qkv_conv(x.permute(0, 3, 1, 2))
q_bi = rearrange(q, "n c (j h) (i w) -> n (j i) h w c", j=self.n_win, i=self.n_win)
kv = rearrange(kv, "n c (j h) (i w) -> n (j i) h w c", j=self.n_win, i=self.n_win)
q_pix = rearrange(q_bi, 'n p2 h w c -> n p2 (h w) c')
kv_pix = self.kv_down(rearrange(kv, 'n p2 h w c -> (n p2) c h w'))
kv_pix = rearrange(kv_pix, '(n j i) c h w -> n (j i) (h w) c', j=self.n_win, i=self.n_win)
##################side_dwconv(lepe)##################
# NOTE: call contiguous to avoid gradient warning when using ddp
lepe1 = self.lepe1(rearrange(kv[..., self.qk_dim:], 'n (j i) h w c -> n c (j h) (i w)', j=self.n_win, i=self.n_win).contiguous())
################################################################# Offset Q
q_off = rearrange(q, 'b (g c) h w -> (b g) c h w', g=self.n_groups, c=self.n_group_channels)
offset_q = self.conv_offset_q(q_off).contiguous() # B * g 2 Sg HWg
Hk, Wk = offset_q.size(2), offset_q.size(3)
n_sample = Hk * Wk
Hg, Wg = Hk, Wk # FIX: Initialize Hg and Wg to non-padded dimensions
if self.offset_range_factor > 0:
offset_range = torch.tensor([1.0 / Hk, 1.0 / Wk], device=device).reshape(1, 2, 1, 1)
offset_q = offset_q.tanh().mul(offset_range).mul(self.offset_range_factor)
offset_q = rearrange(offset_q, 'b p h w -> b h w p') # B * g 2 Hg Wg -> B*g Hg Wg 2
reference = self._get_ref_points(Hk, Wk, N, dtype, device)
if self.offset_range_factor >= 0:
pos_k = offset_q + reference
else:
pos_k = (offset_q + reference).clamp(-1., +1.)
x_sampled_q = F.grid_sample(
input=x_res.reshape(N * self.n_groups, self.n_group_channels, H, W),
grid=pos_k[..., (1, 0)], # y, x -> x, y
mode='bilinear', align_corners=True) # B * g, Cg, Hg, Wg
q_sampled = x_sampled_q.reshape(N, C, Hk, Wk)
######## Bi-LEVEL Gathering
if self.auto_pad:
q_sampled_nhwc = q_sampled.permute(0, 2, 3, 1)
Ng, H_old, W_old, Cg = q_sampled_nhwc.size()
pad_l = pad_t = 0
pad_rg = (self.n_win - W_old % self.n_win) % self.n_win
pad_bg = (self.n_win - H_old % self.n_win) % self.n_win
q_sampled_padded_nhwc = F.pad(q_sampled_nhwc, (0, 0, # dim=-1
pad_l, pad_rg, # dim=-2
pad_t, pad_bg)) # dim=-3
_, Hg, Wg, _ = q_sampled_padded_nhwc.size() # Re-assign Hg, Wg with padded size
q_sampled = q_sampled_padded_nhwc.permute(0, 3, 1, 2)
lepe1 = F.pad(lepe1.permute(0, 2, 3, 1), (0, 0, # dim=-1
pad_l, pad_rg, # dim=-2
pad_t, pad_bg)) # dim=-3
lepe1=lepe1.permute(0, 3, 1, 2)
pos_k = F.pad(pos_k.permute(0, 3, 1, 2), (pad_l, pad_rg, pad_t, pad_bg)).permute(0, 2, 3, 1)
queries_def = self.proj_q(q_sampled) #Linnear projection
queries_def = rearrange(queries_def, "n c (j h) (i w) -> n (j i) h w c", j=self.n_win, i=self.n_win).contiguous()
q_win, k_win = queries_def.mean([2, 3]), kv[..., 0:(self.qk_dim)].mean([2, 3])
r_weight, r_idx = self.router(q_win, k_win)
kv_gather = self.kv_gather(r_idx=r_idx, r_weight=r_weight, kv=kv_pix) # (n, p^2, topk, h_kv*w_kv, c )
k_gather, v_gather = kv_gather.split([self.qk_dim, self.dim], dim=-1)
### Bi-level Routing MHA
k = rearrange(k_gather, 'n p2 k hw (m c) -> (n p2) m c (k hw)', m=self.num_heads)
v = rearrange(v_gather, 'n p2 k hw (m c) -> (n p2) m (k hw) c', m=self.num_heads)
q_def = rearrange(queries_def, 'n p2 h w (m c)-> (n p2) m (h w) c',m=self.num_heads)
attn_weight = (q_def * self.scale) @ k
attn_weight = self.attn_act(attn_weight)
out = attn_weight @ v
if self.auto_pad:
out_def = rearrange(out, '(n j i) m (h w) c -> n (m c) (j h) (i w)', j=self.n_win, i=self.n_win, h=Hg//self.n_win, w=Wg//self.n_win).contiguous()
else:
out_def = rearrange(out, '(n j i) m (h w) c -> n (m c) (j h) (i w)', j=self.n_win, i=self.n_win, h=Hk//self.n_win, w=Wk//self.n_win).contiguous()
out_def = out_def + lepe1
out_def = self.unifyheads1(out_def)
out_def = q_sampled + out_def
out_def = out_def + self.mlp(self.norm2(out_def.permute(0, 2, 3, 1)).permute(0, 3, 1, 2)) # (N, C, H, W)
#############################################################################################
######## Deformable Gathering
#############################################################################################
out_def = self.norm(out_def.permute(0, 2, 3, 1)).permute(0, 3, 1, 2)
k = self.proj_k(out_def)
v = self.proj_v(out_def)
k_pix_sel = rearrange(k, 'n (m c) h w -> (n m) c (h w)', m=self.num_heads)
v_pix_sel = rearrange(v, 'n (m c) h w -> (n m) c (h w)', m=self.num_heads)
q_pix = rearrange(q, 'n (m c) h w -> (n m) c (h w)', m=self.num_heads)
attn = torch.einsum('b c m, b c n -> b m n', q_pix, k_pix_sel) # B * h, HW, Ns
attn = attn.mul(self.scale)
### Bias
rpe_table = self.rpe_table
rpe_bias = rpe_table[None, ...].expand(N, -1, -1, -1)
q_grid = self._get_q_grid(H, W, N, dtype, device)
displacement = (q_grid.reshape(N * self.n_groups, H * W, 2).unsqueeze(2) - pos_k.reshape(N * self.n_groups, Hg * Wg, 2).unsqueeze(1)).mul(0.5)
attn_bias = F.grid_sample(
input=rearrange(rpe_bias, 'b (g c) h w -> (b g) c h w', c=self.n_group_heads, g=self.n_groups),
grid=displacement[..., (1, 0)],
mode='bilinear', align_corners=True) # B * g, h_g, HW, Ns
attn_bias = attn_bias.reshape(N * self.num_heads, H * W, Hg*Wg)
attn = attn + attn_bias
###
attn = F.softmax(attn, dim=2)
out = torch.einsum('b m n, b c n -> b c m', attn, v_pix_sel)
out = out.reshape(N,C,H,W).contiguous()
out = self.proj_out(out).permute(0,2,3,1)
#############################################################################################
# NOTE: use padding for semantic segmentation
# crop padded region
if self.auto_pad and (pad_r > 0 or pad_b > 0):
out = out[:, :H_in, :W_in, :].contiguous()
if ret_attn_mask:
return out, r_weight, r_idx, attn_weight
else:
return out
def get_pe_layer(emb_dim, pe_dim=None, name='none'):
if name == 'none':
return nn.Identity()
else:
raise ValueError(f'PE name {name} is not surpported!')
class Block(nn.Module):
def __init__(self, dim, drop_path=0., layer_scale_init_value=-1,
num_heads=8, n_win=7, qk_dim=None, qk_scale=None,
kv_per_win=4, kv_downsample_ratio=4,
kv_downsample_kernel=None, kv_downsample_mode='ada_avgpool',
topk=4, param_attention="qkvo", param_routing=False,
diff_routing=False, soft_routing=False, mlp_ratio=4, param_size='small',mlp_dwconv=False,
side_dwconv=5, before_attn_dwconv=3, pre_norm=True, auto_pad=False):
super().__init__()
qk_dim = qk_dim or dim
# modules
if before_attn_dwconv > 0:
self.pos_embed1 = nn.Conv2d(dim, dim, kernel_size=before_attn_dwconv, padding=1, groups=dim)
self.pos_embed2 = nn.Conv2d(dim, dim, kernel_size=before_attn_dwconv, padding=1, groups=dim)
else:
self.pos_embed1 = nn.Identity()
self.pos_embed2 = nn.Identity()
self.norm1 = nn.LayerNorm(dim, eps=1e-6) # important to avoid attention collapsing
#if topk > 0:
if topk == 4:
self.attn1 = BiLevelRoutingAttention(dim=dim, num_heads=num_heads, n_win=n_win, qk_dim=qk_dim,
qk_scale=qk_scale, kv_per_win=kv_per_win, kv_downsample_ratio=kv_downsample_ratio,
kv_downsample_kernel=kv_downsample_kernel, kv_downsample_mode=kv_downsample_mode,
topk=1, param_attention=param_attention, param_routing=param_routing,
diff_routing=diff_routing, soft_routing=soft_routing, side_dwconv=side_dwconv,
auto_pad=auto_pad)
self.attn2 = DeBiLevelRoutingAttention(dim=dim, num_heads=num_heads, n_win=n_win, qk_dim=qk_dim,
qk_scale=qk_scale, kv_per_win=kv_per_win, kv_downsample_ratio=kv_downsample_ratio,
kv_downsample_kernel=kv_downsample_kernel, kv_downsample_mode=kv_downsample_mode,
topk=topk, param_attention=param_attention, param_routing=param_routing,
diff_routing=diff_routing, soft_routing=soft_routing, side_dwconv=side_dwconv,
auto_pad=auto_pad,param_size=param_size)
elif topk == 8:
self.attn1 = BiLevelRoutingAttention(dim=dim, num_heads=num_heads, n_win=n_win, qk_dim=qk_dim,
qk_scale=qk_scale, kv_per_win=kv_per_win, kv_downsample_ratio=kv_downsample_ratio,
kv_downsample_kernel=kv_downsample_kernel, kv_downsample_mode=kv_downsample_mode,
topk=4, param_attention=param_attention, param_routing=param_routing,
diff_routing=diff_routing, soft_routing=soft_routing, side_dwconv=side_dwconv,
auto_pad=auto_pad)
self.attn2 = DeBiLevelRoutingAttention(dim=dim, num_heads=num_heads, n_win=n_win, qk_dim=qk_dim,
qk_scale=qk_scale, kv_per_win=kv_per_win, kv_downsample_ratio=kv_downsample_ratio,
kv_downsample_kernel=kv_downsample_kernel, kv_downsample_mode=kv_downsample_mode,
topk=topk, param_attention=param_attention, param_routing=param_routing,
diff_routing=diff_routing, soft_routing=soft_routing, side_dwconv=side_dwconv,
auto_pad=auto_pad,param_size=param_size)
elif topk == 16:
self.attn1 = BiLevelRoutingAttention(dim=dim, num_heads=num_heads, n_win=n_win, qk_dim=qk_dim,
qk_scale=qk_scale, kv_per_win=kv_per_win, kv_downsample_ratio=kv_downsample_ratio,
kv_downsample_kernel=kv_downsample_kernel, kv_downsample_mode=kv_downsample_mode,
topk=16, param_attention=param_attention, param_routing=param_routing,
diff_routing=diff_routing, soft_routing=soft_routing, side_dwconv=side_dwconv,
auto_pad=auto_pad)
self.attn2 = DeBiLevelRoutingAttention(dim=dim, num_heads=num_heads, n_win=n_win, qk_dim=qk_dim,
qk_scale=qk_scale, kv_per_win=kv_per_win, kv_downsample_ratio=kv_downsample_ratio,
kv_downsample_kernel=kv_downsample_kernel, kv_downsample_mode=kv_downsample_mode,
topk=topk, param_attention=param_attention, param_routing=param_routing,
diff_routing=diff_routing, soft_routing=soft_routing, side_dwconv=side_dwconv,
auto_pad=auto_pad,param_size=param_size)
elif topk == -1:
self.attn = Attention(dim=dim)
elif topk == -2:
self.attn1 = DeBiLevelRoutingAttention(dim=dim, num_heads=num_heads, n_win=n_win, qk_dim=qk_dim,
qk_scale=qk_scale, kv_per_win=kv_per_win, kv_downsample_ratio=kv_downsample_ratio,
kv_downsample_kernel=kv_downsample_kernel, kv_downsample_mode=kv_downsample_mode,
topk=49, param_attention=param_attention, param_routing=param_routing,
diff_routing=diff_routing, soft_routing=soft_routing, side_dwconv=side_dwconv,
auto_pad=auto_pad,param_size=param_size)
self.attn2 = DeBiLevelRoutingAttention(dim=dim, num_heads=num_heads, n_win=n_win, qk_dim=qk_dim,
qk_scale=qk_scale, kv_per_win=kv_per_win, kv_downsample_ratio=kv_downsample_ratio,
kv_downsample_kernel=kv_downsample_kernel, kv_downsample_mode=kv_downsample_mode,
topk=49, param_attention=param_attention, param_routing=param_routing,
diff_routing=diff_routing, soft_routing=soft_routing, side_dwconv=side_dwconv,
auto_pad=auto_pad,param_size=param_size)
elif topk == 0:
self.attn = nn.Sequential(Rearrange('n h w c -> n c h w'), # compatiability
nn.Conv2d(dim, dim, 1), # pseudo qkv linear
nn.Conv2d(dim, dim, 5, padding=2, groups=dim), # pseudo attention
nn.Conv2d(dim, dim, 1), # pseudo out linear
Rearrange('n c h w -> n h w c')
)
self.norm2 = nn.LayerNorm(dim, eps=1e-6)
self.mlp1 = TransformerMLPWithConv(dim, mlp_ratio, 0.)
self.drop_path1 = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.drop_path2 = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm3 = nn.LayerNorm(dim, eps=1e-6)
self.norm4 = nn.LayerNorm(dim, eps=1e-6)
self.mlp2 =TransformerMLPWithConv(dim, mlp_ratio, 0.)
# tricks: layer scale & pre_norm/post_norm
if layer_scale_init_value > 0:
self.use_layer_scale = True
self.gamma1 = nn.Parameter(layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.gamma2 = nn.Parameter(layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.gamma3 = nn.Parameter(layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.gamma4 = nn.Parameter(layer_scale_init_value * torch.ones((dim)), requires_grad=True)
else:
self.use_layer_scale = False
self.pre_norm = pre_norm
def forward(self, x):
"""
x: NCHW tensor
"""
# conv pos embedding
x = x + self.pos_embed1(x)
# permute to NHWC tensor for attention & mlp
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
# attention & mlp
if self.pre_norm:
# The original code had a mix of with/without layer_scale logic.
# Simplified to a single path for clarity, assuming pre_norm is always used.
attn_output1 = self.attn1(self.norm1(x))
x = x + self.drop_path1(self.gamma1 * attn_output1 if self.use_layer_scale else attn_output1)
mlp_input = self.norm2(x).permute(0, 3, 1, 2)
mlp_output1 = self.mlp1(mlp_input).permute(0, 2, 3, 1)
x = x + self.drop_path1(self.gamma2 * mlp_output1 if self.use_layer_scale else mlp_output1)
# conv pos embedding
x = x + self.pos_embed2(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
attn_output2 = self.attn2(self.norm3(x))
x = x + self.drop_path2(self.gamma3 * attn_output2 if self.use_layer_scale else attn_output2)
mlp_input2 = self.norm4(x).permute(0, 3, 1, 2)
mlp_output2 = self.mlp2(mlp_input2).permute(0, 2, 3, 1)
x = x + self.drop_path2(self.gamma4 * mlp_output2 if self.use_layer_scale else mlp_output2)
else: # Post-norm path (following original structure)
if self.use_layer_scale:
x = self.norm1(x + self.drop_path1(self.gamma1 * self.attn1(x)))
x = self.norm2(x + self.drop_path1(self.gamma2 * self.mlp1(x)))
x = x + self.pos_embed2(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
x = self.norm3(x + self.drop_path2(self.gamma3 * self.attn2(x)))
x = self.norm4(x + self.drop_path2(self.gamma4 * self.mlp2(x)))
else:
x = self.norm1(x + self.drop_path1(self.attn1(x)))
x_mlp = self.mlp1(self.norm2(x).permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
x = x + self.drop_path1(x_mlp)
x = x + self.pos_embed2(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
x = self.norm3(x + self.drop_path2(self.attn2(x)))
x_mlp2 = self.mlp2(self.norm4(x).permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
x = x + self.drop_path2(x_mlp2)
# permute back
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
return x
class DeBiFormer(nn.Module):
def __init__(self, depth=[3, 4, 8, 3], in_chans=3, num_classes=1000, embed_dim=[64, 128, 320, 512],
head_dim=64, qk_scale=None, representation_size=None,
drop_path_rate=0., drop_rate=0.,
use_checkpoint_stages=[],
########
n_win=7,
kv_downsample_mode='ada_avgpool',
kv_per_wins=[2, 2, -1, -1],
topks=[8, 8, -1, -1],
side_dwconv=5,
layer_scale_init_value=-1,
qk_dims=[None, None, None, None],
param_routing=False, diff_routing=False, soft_routing=False,
pre_norm=True,
pe=None,
pe_stages=[0],
before_attn_dwconv=3,
auto_pad=False,
#-----------------------
kv_downsample_kernels=[4, 2, 1, 1],
kv_downsample_ratios=[4, 2, 1, 1], # -> kv_per_win = [2, 2, 2, 1]
mlp_ratios=[4, 4, 4, 4],
param_attention='qkvo',
param_size='small',
mlp_dwconv=False, **kwargs):
"""
Args:
depth (list): depth of each stage
in_chans (int): number of input channels
num_classes (int): number of classes for classification head
embed_dim (list): embedding dimension of each stage
head_dim (int): head dimension
... (other args)
"""
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.in_chans = in_chans
self.num_stages = len(depth)
############ downsample layers (patch embeddings) ######################
self.downsample_layers = nn.ModuleList()
# NOTE: uniformer uses two 3*3 conv, while in many other transformers this is one 7*7 conv
stem = nn.Sequential(
nn.Conv2d(in_chans, embed_dim[0] // 2, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)),
nn.BatchNorm2d(embed_dim[0] // 2),
nn.GELU(),
nn.Conv2d(embed_dim[0] // 2, embed_dim[0], kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)),
nn.BatchNorm2d(embed_dim[0]),
)
if (pe is not None) and 0 in pe_stages:
stem.append(get_pe_layer(emb_dim=embed_dim[0], name=pe))
if use_checkpoint_stages:
# stem = checkpoint_wrapper(stem)
pass
self.downsample_layers.append(stem)
for i in range(self.num_stages - 1):
downsample_layer = nn.Sequential(
nn.Conv2d(embed_dim[i], embed_dim[i+1], kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)),
nn.BatchNorm2d(embed_dim[i+1])
)
if (pe is not None) and i+1 in pe_stages:
downsample_layer.append(get_pe_layer(emb_dim=embed_dim[i+1], name=pe))
if use_checkpoint_stages:
# downsample_layer = checkpoint_wrapper(downsample_layer)
pass
self.downsample_layers.append(downsample_layer)
##########################################################################
self.stages = nn.ModuleList() # 4 feature resolution stages, each consisting of multiple residual blocks
nheads= [dim // head_dim for dim in qk_dims]
dp_rates=[x.item() for x in torch.linspace(0, drop_path_rate, sum(depth))]
cur = 0
for i in range(self.num_stages):
stage = nn.Sequential(
*[Block(dim=embed_dim[i], drop_path=dp_rates[cur + j],
layer_scale_init_value=layer_scale_init_value,
topk=topks[i],
num_heads=nheads[i],
n_win=n_win,
qk_dim=qk_dims[i],
qk_scale=qk_scale,
kv_per_win=kv_per_wins[i],
kv_downsample_ratio=kv_downsample_ratios[i],
kv_downsample_kernel=kv_downsample_kernels[i],
kv_downsample_mode=kv_downsample_mode,
param_attention=param_attention,
param_size=param_size,
param_routing=param_routing,
diff_routing=diff_routing,
soft_routing=soft_routing,
mlp_ratio=mlp_ratios[i],
mlp_dwconv=mlp_dwconv,
side_dwconv=side_dwconv,
before_attn_dwconv=before_attn_dwconv,
pre_norm=pre_norm,
auto_pad=auto_pad) for j in range(depth[i])],
)
if i in use_checkpoint_stages:
# stage = checkpoint_wrapper(stage)
pass
self.stages.append(stage)
cur += depth[i]
##########################################################################
self.norm = nn.BatchNorm2d(embed_dim[-1])
# Classifier head (kept for standalone classification tasks)
self.head = nn.Linear(embed_dim[-1], num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
# --- Add width_list calculation ---
self.width_list = []
try:
# Set model to evaluation mode
self.eval()
# Use a standard image size for the dummy forward pass
dummy_input = torch.randn(1, self.in_chans, 224, 224)
with torch.no_grad():
# The forward method now returns a list of features
features = self.forward(dummy_input)
# The width_list should contain the channel dimension of each feature map
self.width_list = [f.size(1) for f in features]
# Set model back to training mode
self.train()
except Exception as e:
# Fallback in case of an error during the dummy pass
print(f"Error during dummy forward pass for width_list calculation: {e}")
print("Setting width_list to embed_dims as fallback.")
self.width_list = list(self.embed_dim)
self.train()
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, (nn.Conv2d, nn.ConvTranspose2d)):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
if m.groups > 0:
fan_out //= m.groups
if fan_out > 0:
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
else:
m.weight.data.normal_(0, 0.02)
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1.0)
nn.init.constant_(m.bias, 0)
@torch.jit.ignore
def no_weight_decay(self):
no_decay = set()
for name, param in self.named_parameters():
if 'norm' in name or 'bias' in name or 'rpe_table' in name:
no_decay.add(name)
return no_decay
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim[-1], num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
feature_outputs = []
for i in range(self.num_stages):
x = self.downsample_layers[i](x)
x = self.stages[i](x)
feature_outputs.append(x)
# The last feature map is normalized differently in the original code,
# but for feature extraction, it might be better to return it before the final norm.
# Let's stick to the collected features. The last one is already in the list.
# If a final normalized feature is needed, it can be done by the consumer.
# x = self.norm(x)
return feature_outputs
def forward(self, x):
# This now returns a list of feature maps, compatible with frameworks like YOLO
x = self.forward_features(x)
return x
@register_model
def debi_tiny(pretrained=False, **kwargs):
model = DeBiFormer(
depth=[1, 1, 4, 1],
embed_dim=[64, 128, 256, 512],
mlp_ratios=[3, 3, 3, 3],
param_size='tiny',
drop_path_rate=0.1, # Drop rate
#------------------------------
n_win=7,
kv_downsample_mode='identity',
kv_per_wins=[-1, -1, -1, -1],
topks=[4, 8, 16, -2],
side_dwconv=5,
before_attn_dwconv=3,
auto_pad=True, # <<<--- 修正點
layer_scale_init_value=-1,
qk_dims=[64, 128, 256, 512],
head_dim=32,
param_routing=False, diff_routing=False, soft_routing=False,
pre_norm=True,
pe=None,
**kwargs)
model.default_cfg = _cfg()
return model
@register_model
def debi_small(pretrained=False, **kwargs):
model = DeBiFormer(
depth=[2, 2, 9, 3],
embed_dim=[64, 128, 256, 512],
mlp_ratios=[3, 3, 3, 2],
param_size='small',
drop_path_rate=0.3, # Drop rate
#------------------------------
n_win=7,
kv_downsample_mode='identity',
kv_per_wins=[-1, -1, -1, -1],
topks=[4, 8, 16, -2],
side_dwconv=5,
before_attn_dwconv=3,
auto_pad=True, # <<<--- 修正點
layer_scale_init_value=-1,
qk_dims=[64, 128, 256, 512],
head_dim=32,
param_routing=False, diff_routing=False, soft_routing=False,
pre_norm=True,
pe=None,
**kwargs)
model.default_cfg = _cfg()
return model
@register_model
def debi_base(pretrained=False, **kwargs):
model = DeBiFormer(
depth=[2, 2, 9, 2],
embed_dim=[96, 192, 384, 768],
mlp_ratios=[3, 3, 3, 3],
param_size='base',
drop_path_rate=0.4, # Drop rate
#------------------------------
n_win=7,
kv_downsample_mode='identity',
kv_per_wins=[-1, -1, -1, -1],
topks=[4, 8, 16, -2],
side_dwconv=5,
before_attn_dwconv=3,
auto_pad=True, # <<<--- 修正點
layer_scale_init_value=-1,
qk_dims=[96, 192, 384, 768],
head_dim=32,
param_routing=False, diff_routing=False, soft_routing=False,
pre_norm=True,
pe=None,
**kwargs)
model.default_cfg = _cfg()
return model
if __name__ == '__main__':
# Test to ensure the modifications work as expected
img_h, img_w = 640, 640
print("--- Creating DeBiFormer Tiny model ---")
model = debi_tiny(in_chans=3)
print("Model created successfully.")
print("Calculated width_list:", model.width_list)
# Test forward pass
input_tensor = torch.rand(2, 3, img_h, img_w)
print(f"\n--- Testing DeBiFormer Tiny forward pass (Input: {input_tensor.shape}) ---")
model.eval()
try:
with torch.no_grad():
output_features = model(input_tensor)
print("Forward pass successful.")
assert isinstance(output_features, list), "Output should be a list of tensors"
print("Output is a list, as expected.")
print("Output feature shapes:")
for i, features in enumerate(output_features):
print(f"Stage {i+1}: {features.shape}")
# Verify width_list matches runtime output
runtime_widths = [f.size(1) for f in output_features]
print("\nRuntime output feature channels:", runtime_widths)
assert model.width_list == runtime_widths, "Width list mismatch!"
print("Width list verified successfully.")
# --- Test deepcopy ---
print("\n--- Testing deepcopy ---")
import copy
copied_model = copy.deepcopy(model)
print("Deepcopy successful.")
# Optional: Test copied model forward pass
with torch.no_grad():
output_copied = copied_model(input_tensor)
print("Copied model forward pass successful.")
assert len(output_copied) == len(output_features)
for i in range(len(output_features)):
assert output_copied[i].shape == output_features[i].shape
print("Copied model output shapes verified.")
except Exception as e:
print(f"\nError during testing: {e}")
import traceback
traceback.print_exc()2.2 更改init.py文件
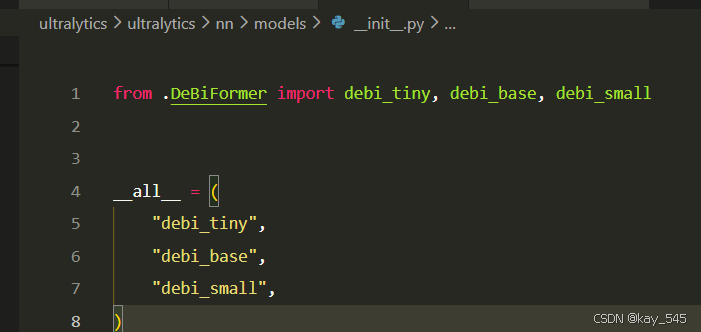
**关键步骤二:**在文件ultralytics\ultralytics\nn\modules\models文件夹下新建__init__.py文件,先导入函数

python
from .DeBiFormer import debi_tiny, debi_base, debi_small然后在下面的__all__中声明函数
2.3 添加yaml文件
**关键步骤三:**在/ultralytics/ultralytics/cfg/models/26下面新建文件yolo26_DeBiFormer.yaml文件,粘贴下面的内容
- 目标检测
python
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# Ultralytics YOLO26 object detection model with P3/8 - P5/32 outputs
# Model docs: https://docs.ultralytics.com/models/yolo26
# Task docs: https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
end2end: True # whether to use end-to-end mode
reg_max: 1 # DFL bins
scales: # model compound scaling constants, i.e. 'model=yolo26n.yaml' will call yolo26.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 260 layers, 2,572,280 parameters, 2,572,280 gradients, 6.1 GFLOPs
s: [0.50, 0.50, 1024] # summary: 260 layers, 10,009,784 parameters, 10,009,784 gradients, 22.8 GFLOPs
m: [0.50, 1.00, 512] # summary: 280 layers, 21,896,248 parameters, 21,896,248 gradients, 75.4 GFLOPs
l: [1.00, 1.00, 512] # summary: 392 layers, 26,299,704 parameters, 26,299,704 gradients, 93.8 GFLOPs
x: [1.00, 1.50, 512] # summary: 392 layers, 58,993,368 parameters, 58,993,368 gradients, 209.5 GFLOPs
# YOLO26n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, debi_tiny, []]
- [-1, 1, SPPF, [1024, 5]] # 5
- [-1, 2, C2PSA, [1024]] # 6
# YOLO26n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 3], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, True]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 2], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, True]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, True]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 6], 1, Concat, [1]] # cat head P5
- [-1, 1, C3k2, [1024, True, 0.5, True]] # 22 (P5/32-large)
- [[12, 15, 18], 1, Detect, [nc]] # Detect(P3, P4, P5)- 语义分割
python
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# Ultralytics YOLO26 object detection model with P3/8 - P5/32 outputs
# Model docs: https://docs.ultralytics.com/models/yolo26
# Task docs: https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
end2end: True # whether to use end-to-end mode
reg_max: 1 # DFL bins
scales: # model compound scaling constants, i.e. 'model=yolo26n.yaml' will call yolo26.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 260 layers, 2,572,280 parameters, 2,572,280 gradients, 6.1 GFLOPs
s: [0.50, 0.50, 1024] # summary: 260 layers, 10,009,784 parameters, 10,009,784 gradients, 22.8 GFLOPs
m: [0.50, 1.00, 512] # summary: 280 layers, 21,896,248 parameters, 21,896,248 gradients, 75.4 GFLOPs
l: [1.00, 1.00, 512] # summary: 392 layers, 26,299,704 parameters, 26,299,704 gradients, 93.8 GFLOPs
x: [1.00, 1.50, 512] # summary: 392 layers, 58,993,368 parameters, 58,993,368 gradients, 209.5 GFLOPs
# YOLO26n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, debi_tiny, []]
- [-1, 1, SPPF, [1024, 5]] # 5
- [-1, 2, C2PSA, [1024]] # 6
# YOLO26n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 3], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, True]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 2], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, True]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, True]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 6], 1, Concat, [1]] # cat head P5
- [-1, 1, C3k2, [1024, True, 0.5, True]] # 22 (P5/32-large)
- [[12, 15, 18], 1, Segment, [nc, 32, 256]]- 旋转目标检测
python
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# Ultralytics YOLO26 object detection model with P3/8 - P5/32 outputs
# Model docs: https://docs.ultralytics.com/models/yolo26
# Task docs: https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
end2end: True # whether to use end-to-end mode
reg_max: 1 # DFL bins
scales: # model compound scaling constants, i.e. 'model=yolo26n.yaml' will call yolo26.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 260 layers, 2,572,280 parameters, 2,572,280 gradients, 6.1 GFLOPs
s: [0.50, 0.50, 1024] # summary: 260 layers, 10,009,784 parameters, 10,009,784 gradients, 22.8 GFLOPs
m: [0.50, 1.00, 512] # summary: 280 layers, 21,896,248 parameters, 21,896,248 gradients, 75.4 GFLOPs
l: [1.00, 1.00, 512] # summary: 392 layers, 26,299,704 parameters, 26,299,704 gradients, 93.8 GFLOPs
x: [1.00, 1.50, 512] # summary: 392 layers, 58,993,368 parameters, 58,993,368 gradients, 209.5 GFLOPs
# YOLO26n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, debi_tiny, []]
- [-1, 1, SPPF, [1024, 5]] # 5
- [-1, 2, C2PSA, [1024]] # 6
# YOLO26n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 3], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, True]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 2], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, True]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, True]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 6], 1, Concat, [1]] # cat head P5
- [-1, 1, C3k2, [1024, True, 0.5, True]] # 22 (P5/32-large)
- [[12, 15, 18], 1, OBB, [nc, 1]] # Detect(P3, P4, P5)温馨提示:本文只是对yolo26基础模型上添加模块,如果要对yolo11n/l/m/x进行添加则只需要指定对应的depth_multiple 和 width_multiple
python
end2end: True # whether to use end-to-end mode
reg_max: 1 # DFL bins
scales: # model compound scaling constants, i.e. 'model=yolo26n.yaml' will call yolo26.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 260 layers, 2,572,280 parameters, 2,572,280 gradients, 6.1 GFLOPs
s: [0.50, 0.50, 1024] # summary: 260 layers, 10,009,784 parameters, 10,009,784 gradients, 22.8 GFLOPs
m: [0.50, 1.00, 512] # summary: 280 layers, 21,896,248 parameters, 21,896,248 gradients, 75.4 GFLOPs
l: [1.00, 1.00, 512] # summary: 392 layers, 26,299,704 parameters, 26,299,704 gradients, 93.8 GFLOPs
x: [1.00, 1.50, 512] # summary: 392 layers, 58,993,368 parameters, 58,993,368 gradients, 209.5 GFLOPs2.4 在task.py中进行注册
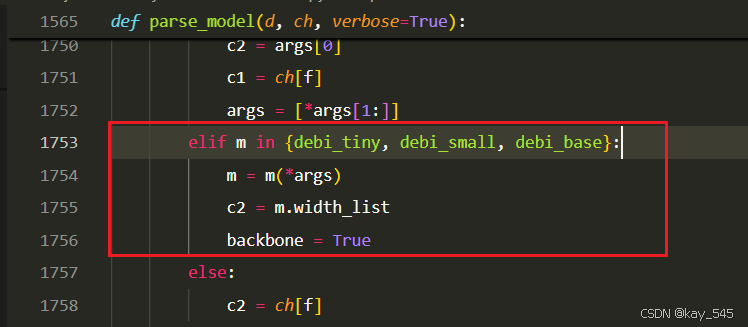
**关键步骤四:**在parse_model函数中进行注册,添加DeBiFormer
先在task.py导入函数

然后在task.py文件下找到parse_model这个函数,如下图,添加DeBiFormer
python
elif m in {debi_tiny, debi_small, debi_base}:
m = m(*args)
c2 = m.width_list
backbone = True2.5 执行程序
关键步骤五: 在ultralytics文件中新建train.py,将model的参数路径设置为yolo26_DeBiFormer.yaml的路径即可 【注意是在外边的Ultralytics下新建train.py】
python
from ultralytics import YOLO
import warnings
warnings.filterwarnings('ignore')
from pathlib import Path
if __name__ == '__main__':
# 加载模型
model = YOLO("ultralytics/cfg/26/yolo26.yaml") # 你要选择的模型yaml文件地址
# Use the model
results = model.train(data=r"你的数据集的yaml文件地址",
epochs=100, batch=16, imgsz=640, workers=4, name=Path(model.cfg).stem) # 训练模型🚀运行程序,如果出现下面的内容则说明添加成功🚀
python
from n params module arguments
0 -1 1 21495598 debi_tiny []
1 -1 1 394240 ultralytics.nn.modules.block.SPPF [512, 256, 5]
2 -1 1 249728 ultralytics.nn.modules.block.C2PSA [256, 256, 1]
3 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
4 [-1, 3] 1 0 ultralytics.nn.modules.conv.Concat [1]
5 -1 1 136192 ultralytics.nn.modules.block.C3k2 [512, 128, 1, True]
6 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
7 [-1, 2] 1 0 ultralytics.nn.modules.conv.Concat [1]
8 -1 1 34304 ultralytics.nn.modules.block.C3k2 [256, 64, 1, True]
9 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
10 [-1, 9] 1 0 ultralytics.nn.modules.conv.Concat [1]
11 -1 1 95232 ultralytics.nn.modules.block.C3k2 [192, 128, 1, True]
12 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
13 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
14 -1 1 463104 ultralytics.nn.modules.block.C3k2 [384, 256, 1, True, 0.5, True]
15 [12, 15, 18] 1 309656 ultralytics.nn.modules.head.Detect [80, 1, True, [64, 128, 256]]
YOLO26_DeBiFormer summary: 591 layers, 23,362,758 parameters, 23,362,758 gradients, 524.1 GFLOPs3. 完整代码分享
++主页侧边++
4. GFLOPs
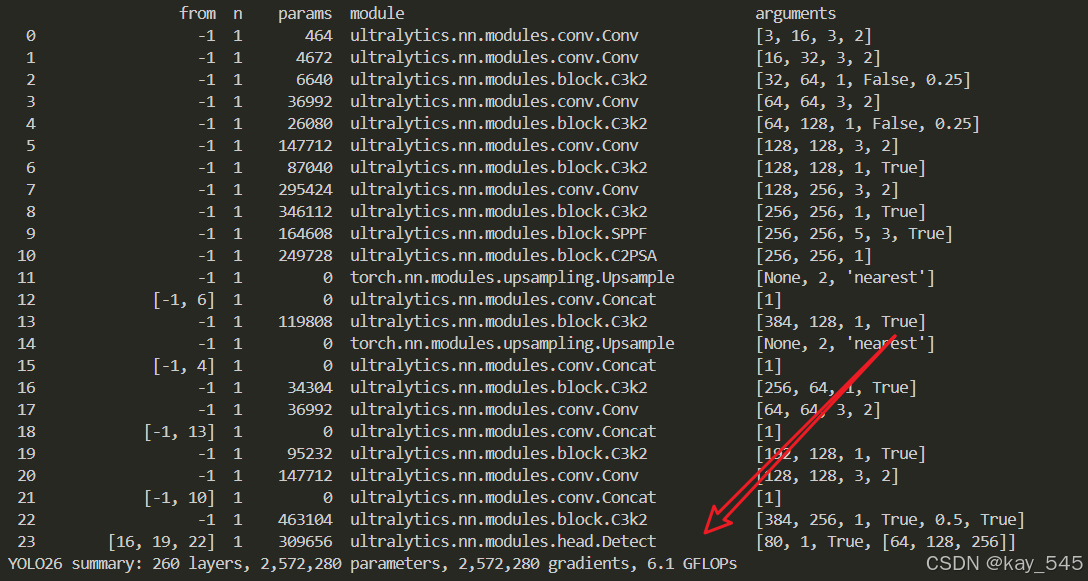
关于GFLOPs的计算方式可以查看 :百面算法工程师 | 卷积基础知识------Convolution
未改进的YOLO26n GFLOPs
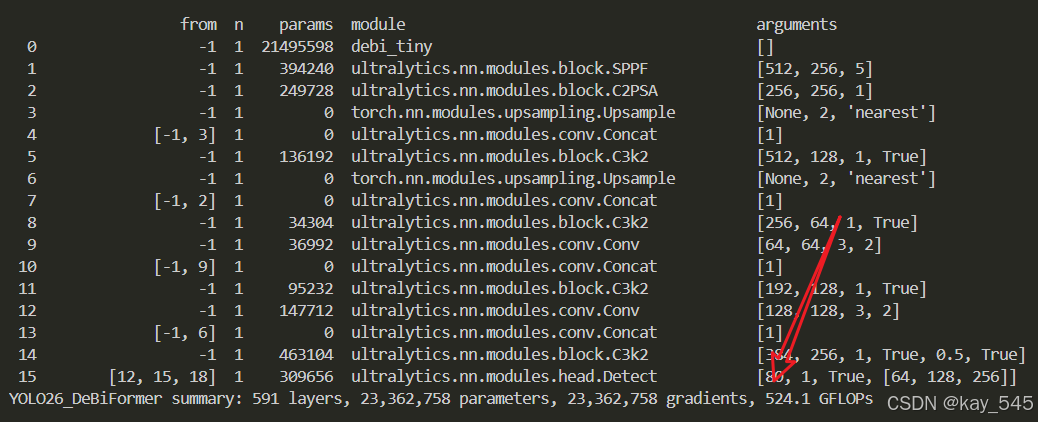
改进后的GFLOPs
5. 进阶
可以与其他的注意力机制或者损失函数等结合,进一步提升检测效果
6.总结
通过以上的改进方法,我们成功提升了模型的表现。这只是一个开始,未来还有更多优化和技术深挖的空间。在这里,我想隆重向大家推荐我的专栏------<专栏地址:YOLO11入门 + 改进涨点------点击即可跳转 欢迎订阅****>。这个专栏专注于前沿的深度学习技术,特别是目标检测领域的最新进展,不仅包含对YOLO11的深入解析和改进策略,还会定期更新来自各大顶会(如CVPR、NeurIPS等)的论文复现和实战分享。
为什么订阅我的专栏? ------专栏地址:YOLO11入门 + 改进涨点------点击即可跳转 欢迎订阅****
-
前沿技术解读:专栏不仅限于YOLO系列的改进,还会涵盖各类主流与新兴网络的最新研究成果,帮助你紧跟技术潮流。
-
详尽的实践分享 :所有内容实践性也极强。每次更新都会附带代码和具体的改进步骤,保证每位读者都能迅速上手。
-
问题互动与答疑 :订阅我的专栏后,你将可以随时向我提问,获取及时的答疑。
-
实时更新,紧跟行业动态:不定期发布来自全球顶会的最新研究方向和复现实验报告,让你时刻走在技术前沿。
专栏适合人群:
-
对目标检测、YOLO系列网络有深厚兴趣的同学
-
希望在用YOLO算法写论文的同学
-
对YOLO算法感兴趣的同学等
