这篇文章,我就结合自己的第一版代码,完整记录一下:
-
RAG 到底是什么
-
我的第一个 RAG 程序是怎么跑起来的
这篇文章非常适合刚开始接触 RAG 的同学阅读。
一、RAG 到底是什么?
RAG,全称是 Retrieval-Augmented Generation ,中文常翻译为:检索增强生成。
这个名字听起来有点"学术",但其实用一句大白话就能解释清楚:
先查资料,再回答问题。
普通大模型回答问题,主要依赖它训练时学到的知识。
但很多真实场景下,我们问的并不是公开通识,而是:
-
公司内部文档
-
个人知识库
-
某份业务制度
-
最新规则说明
这些内容,大模型训练时不一定见过。
这时候,单纯"问模型"就不够了。
所以才有了 RAG
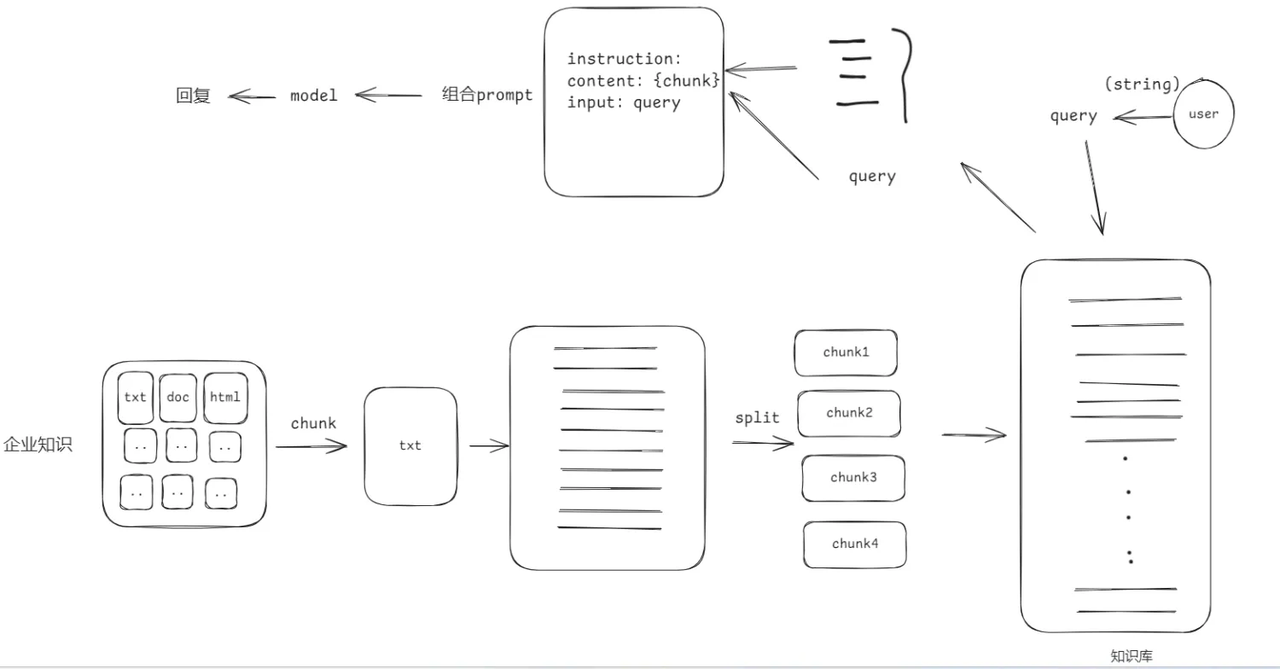
它通常分成两步:
1. Retrieval(检索)
先从你的文档库里,找到和问题最相关的内容。
2. Generation(生成)
再把这些检索结果作为上下文,喂给大模型,让模型基于资料回答。
所以,RAG 的本质不是让模型"记住更多知识",而是让模型在回答时:
有一个外挂数据源。
二、我的第一个 RAG 程序,做了什么?
我的这版程序很简单,但已经完整跑通了一个最小 RAG 闭环:
-
从 PDF 中提取文本
-
把长文本切成多个小块
-
用 Embedding 模型把文本块转成向量
-
把向量写入 ChromaDB
-
用户提问时,先做向量检索
-
取出最相关的几段文本
-
拼进 Prompt,交给大模型生成答案
也就是说,这份程序已经不是一个"概念代码",而是一个真正能工作的最小版知识库问答系统。
三、先看原始代码
这是我最开始写的版本:
python
from dotenv import load_dotenv
from openai import OpenAI
from pdfminer.high_level import extract_pages
from pdfminer.layout import LTTextContainer
import chromadb
import os
#读取pdf文档
def extract_text_from_pdf(filename, page_number=None):
full_text = ''
# 1. 循环读取每一页
for num, page in enumerate(extract_pages(filename)):
# 如果指定了页码,且当前页超过了指定页码,就停止
if page_number is not None and num >= page_number:
break
# 2. 读取当前页的所有文本块
for i in page:
if isinstance(i, LTTextContainer):
text = i.get_text()
clean_text = text.replace('\n', '').replace(' ', '')
full_text += clean_text
pre=split_text(full_text,chunk_size=100,strike=90)
return pre
#按照固定字符分割字符串
def split_text(text,chunk_size,strike):
return [text[i:i+chunk_size] for i in range(0,len(text),strike)]
class MyVectorDBConnector:
def __init__(self, collection_name):
client = chromadb.PersistentClient(path=r"/Users/huz/code/python/hello agent")
# 创建一个 collection
self.collection = client.get_or_create_collection(name=collection_name)
# 使用智谱的模型进行向量化
def get_embeddings(self, texts, model="text-embedding-v2"):
'''封装 qwen 的 Embedding 模型接口'''
data = client.embeddings.create(input=texts, model=model).data
return [x.embedding for x in data]
def add_documents(self, documents):
'''向 collection 中添加文档与向量'''
self.collection.add(
embeddings=self.get_embeddings(documents),
documents=documents,
ids=[f"id{i}" for i in range(len(documents))]
)
def search(self, query, top_n):
'''检索向量数据库'''
results = self.collection.query(
query_embeddings=self.get_embeddings([query]),
n_results=top_n
)
return results
class RAG_Bot:
def __init__(self,vector_db,n_results):
self.vector_db = vector_db
self.n_results = n_results
def get_completion(self, prompt, model="qwen-plus"):
messages = [{"role": "user", "content": prompt}]
response = client.chat.completions.create(
model = model,
messages = messages,
temperature = 0,
)
return response.choices[0].message.content
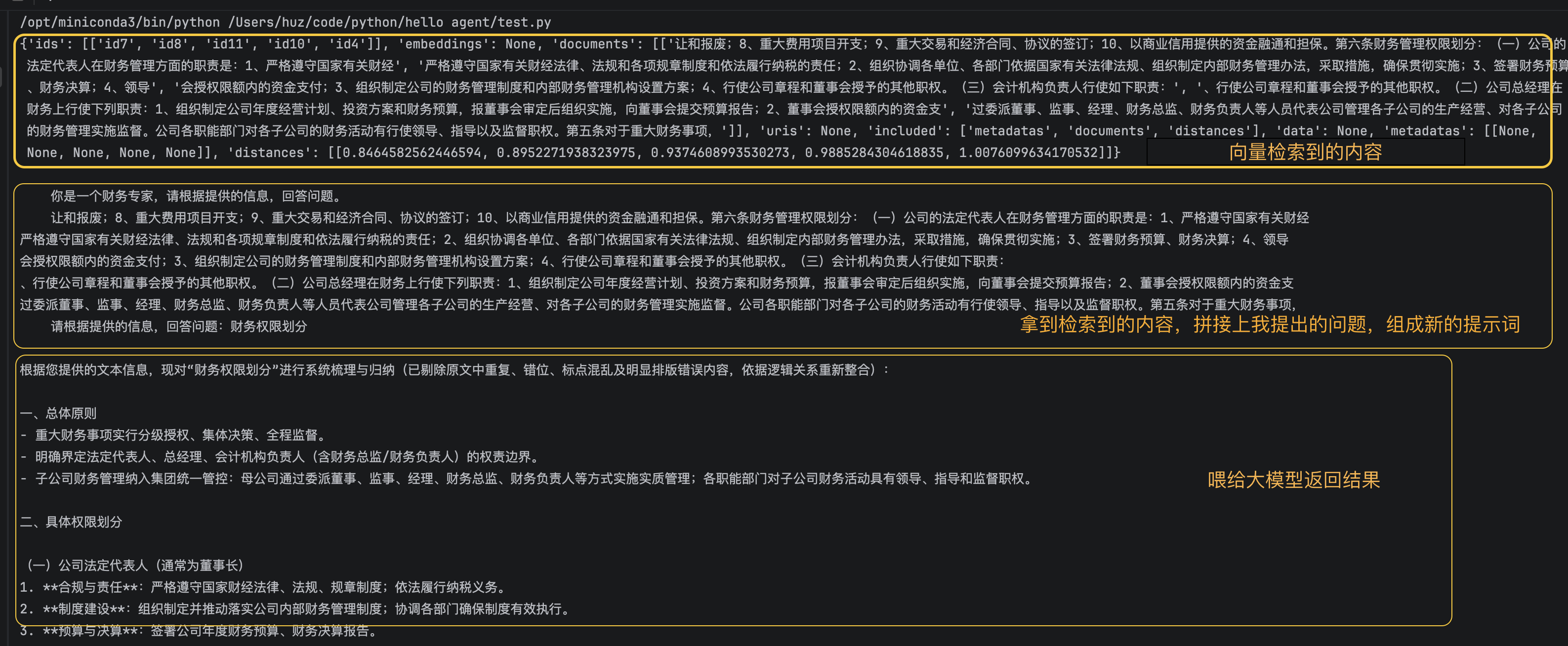
def chat(self,query):
#1.检索
results = self.vector_db.search(query,self.n_results)
print(results)
#2.构建提示词
prompt = prompt_template.replace("__INFO__", "\n".join(results['documents'][0])).replace("__QUERY__", query)
print(prompt)
#调用llm
return self.get_completion(prompt)
if __name__ == '__main__':
load_dotenv()
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
filename = '财务管理文档.pdf'
text =extract_text_from_pdf(filename,2)
prompt_template = '''
你是一个财务专家,请根据提供的信息,回答问题。
__INFO__
请根据提供的信息,回答问题:__QUERY__
'''
vector_db = MyVectorDBConnector("my_collection")
# 2. 添加文档
vector_db.add_documents(text)
rag_bot = RAG_Bot(vector_db,5)
query="财务权限划分"
response=rag_bot.chat(query)
print(response)虽然它很朴素,但已经把 RAG 的主链路跑通了。
四、这份代码的核心流程,拆开来看其实很清楚
1)先从 PDF 中读出文本
第一步是读取 PDF:
python
def extract_text_from_pdf(filename, page_number=None):
full_text = ''
for num, page in enumerate(extract_pages(filename)):
if page_number is not None and num >= page_number:
break
for i in page:
if isinstance(i, LTTextContainer):
text = i.get_text()
clean_text = text.replace('\n', '').replace(' ', '')
full_text += clean_text
pre=split_text(full_text,chunk_size=100,strike=90)
return pre这里用的是 pdfminer,它可以逐页解析 PDF,并提取文本内容。
这一步的目标很明确:
先把"PDF 文档"变成"程序能处理的纯文本"。
如果没有这一步,后面的切分、向量化、检索都无从谈起。
2)再把长文本切成小块
对应的切分函数是:
python
def split_text(text,chunk_size,strike):
return [text[i:i+chunk_size] for i in range(0,len(text),strike)]这个函数虽然简单,但在 RAG 里非常重要,对文档进行分片。
因为向量检索通常不是对整本 PDF 做的,而是对文档中的片段 做的。
如果你把整本文件一次性丢进去,会有两个明显问题:
1.文档粒度太大,一页文档有很多内容,不可能都变成提示词。
2.无论如何提问,都会把整个文档拿出来,显然不是我们想要的。
所以就要对文档进行切割,切割方式有很多,按句子、段落、固定字符等,因为是第一个rag,先用最简单的固定字符切割,然后通过重叠部分字符来减弱跨语义。
3)Embedding:把文本变成向量
接下来是向量化部分:
python
def get_embeddings(self, texts, model="text-embedding-v2"):
data = client.embeddings.create(input=texts, model=model).data
return [x.embedding for x in data]这是整个 RAG 里最关键的一步之一。
Embedding 模型的作用,就是把一段自然语言文本,映射成一组高维数字向量。
这样系统就可以比较"语义相似度",而不是只做关键词匹配。
比如下面这些问题,表面文字可能不同,但意思接近:
-
财务权限划分
-
谁负责财务审批
-
财务权限归谁管理
Embedding 的作用,就是让这些表达在向量空间里彼此靠近。
这也是为什么 RAG 能做"语义检索"。
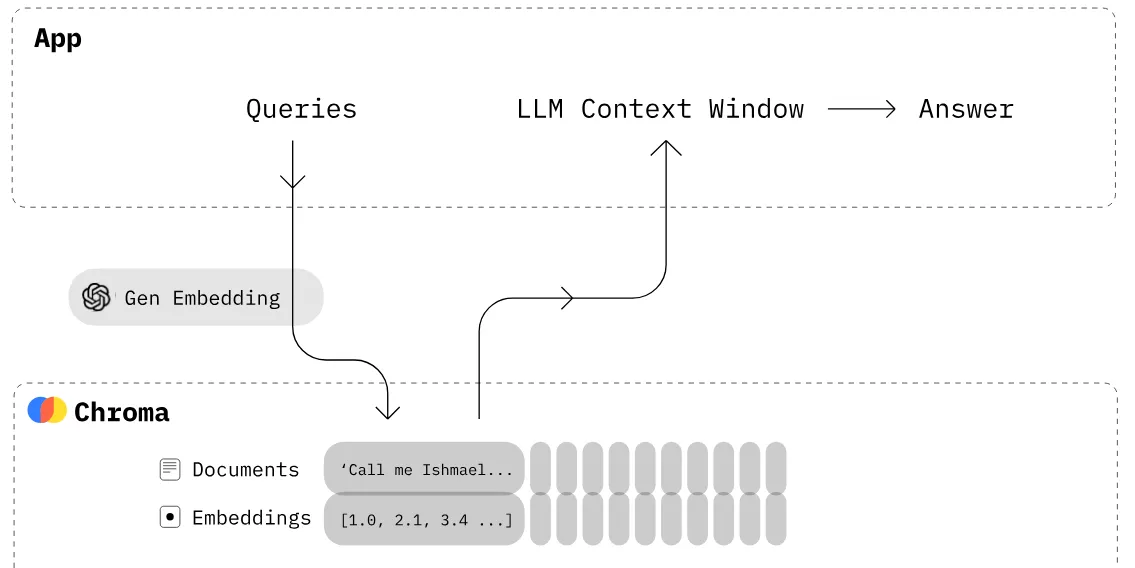
4)把向量写入 ChromaDB
然后是文档写库:
python
def add_documents(self, documents):
self.collection.add(
embeddings=self.get_embeddings(documents),
documents=documents,
ids=[f"id{i}" for i in range(len(documents))]
)我这里使用的是 ChromaDB 。
对于 RAG 初学者来说,它是一个非常友好的选择:
-
本地即可运行
-
API 简单
-
非常适合快速验证
-
做最小 Demo 成本很低
这一步完成后,文本块及其向量就进入了可检索状态。
5)提问时,先做向量检索
检索逻辑如下:
python
def search(self, query, top_n):
results = self.collection.query(
query_embeddings=self.get_embeddings([query]),
n_results=top_n
)
return results注意这里不是直接用原始问题去做字符串匹配,而是:
-
先把用户问题转成向量
-
再去向量库中寻找最接近的几个文本块
-
返回这些文本块作为"参考资料"
这就是 RAG 中的 Retrieval。
6)把检索结果拼进 Prompt,再交给大模型回答
最后是问答部分:
python
def chat(self,query):
results = self.vector_db.search(query,self.n_results)
print(results)
prompt = prompt_template.replace("__INFO__", "\n".join(results['documents'][0])).replace("__QUERY__", query)
print(prompt)
return self.get_completion(prompt)这里的思路也很标准:
-
用户提问
-
系统先查资料
-
把查到的资料塞进 Prompt
-
再交给大模型生成答案
也就是说,大模型并不是在"裸答",而是在"开卷答题"。
这正是 RAG 的价值所在。