文章目录
-
- [真正开始学 LangChain 之前,我先把大模型、提示词、Embedding 和接入方式彻底搞懂](#真正开始学 LangChain 之前,我先把大模型、提示词、Embedding 和接入方式彻底搞懂)
- [一、为什么我没有一上来就写 LangChain 代码?](#一、为什么我没有一上来就写 LangChain 代码?)
-
- [1.1 我最先踩到的坑:把"框架"当成"知识本身"](#1.1 我最先踩到的坑:把“框架”当成“知识本身”)
- [1.2 LangChain 到底在"包"什么?](#1.2 LangChain 到底在“包”什么?)
- 二、先把"模型"这件事说透:它到底是什么?
-
- [2.1 模型不是"黑盒魔法",它本质上是从数据里学规律](#2.1 模型不是“黑盒魔法”,它本质上是从数据里学规律)
- [2.2 传统模型通常只擅长一件事](#2.2 传统模型通常只擅长一件事)
- [2.3 参数到底是什么](#2.3 参数到底是什么)
- 三、什么是大语言模型?为什么它突然什么都会一点?
-
- [3.1 大语言模型,先别急着往"高深"理解](#3.1 大语言模型,先别急着往“高深”理解)
- [3.2 为什么它不只是"自动补全",却又确实和"自动补全"有关?](#3.2 为什么它不只是“自动补全”,却又确实和“自动补全”有关?)
- [3.3 神经网络、自监督、半监督,这几个词到底该怎么理解?](#3.3 神经网络、自监督、半监督,这几个词到底该怎么理解?)
-
- [1. 神经网络:不是"模拟人脑",而是分层处理信息](#1. 神经网络:不是“模拟人脑”,而是分层处理信息)
- [2. 自监督学习:模型自己给自己出题](#2. 自监督学习:模型自己给自己出题)
- [3. 半监督学习:少量指导 + 大量自学](#3. 半监督学习:少量指导 + 大量自学)
- [3.4 现在应该认识哪些主流模型家族?](#3.4 现在应该认识哪些主流模型家族?)
- 四、大语言模型到底能做什么?又不能做什么?
-
- [4.1 它为什么会让人觉得"什么都会一点"?](#4.1 它为什么会让人觉得“什么都会一点”?)
-
- [1. 语言理解与生成](#1. 语言理解与生成)
- [2. 知识组织与表达](#2. 知识组织与表达)
- [3. 逻辑推理与代码生成](#3. 逻辑推理与代码生成)
- [4. 多模态理解](#4. 多模态理解)
- [4.2 但它并不是什么都能直接做好](#4.2 但它并不是什么都能直接做好)
-
- [1. 上下文窗口永远是有限的](#1. 上下文窗口永远是有限的)
- [2. 模型默认不知道你的私有数据](#2. 模型默认不知道你的私有数据)
- [3. 原生 API 本质上还是"一问一答"](#3. 原生 API 本质上还是“一问一答”)
- 五、提示词不是咒语,而是"接口契约"
-
- [5.1 Prompt 不是玄学,是工程约束](#5.1 Prompt 不是玄学,是工程约束)
- 5.2最常用的一套结构:CO-STAR框架
- [5.3 少样本提示:不要只下命令,要学会"举例子"](#5.3 少样本提示:不要只下命令,要学会“举例子”)
- [5.4 思维链提示:让模型先展开推理,再给结论](#5.4 思维链提示:让模型先展开推理,再给结论)
- [5.5 自我审查:把"生成"和"评审"拆开](#5.5 自我审查:把“生成”和“评审”拆开)
- 六、如果要真正接入大模型,有哪些方式?
-
- [6.1 先记结论:无非三条路](#6.1 先记结论:无非三条路)
- [6.2 API 接入:最适合初学者的第一步](#6.2 API 接入:最适合初学者的第一步)
- [6.3 SDK 接入:它不是新路线,只是更适合写代码](#6.3 SDK 接入:它不是新路线,只是更适合写代码)
- [6.4 本地部署:适合做实验,也适合理解"模型真的在我机器上跑"](#6.4 本地部署:适合做实验,也适合理解“模型真的在我机器上跑”)
- [6.5 如果我现在是零基础,我到底该怎么选?](#6.5 如果我现在是零基础,我到底该怎么选?)
-
- [阶段一:先用云端 API 跑通概念](#阶段一:先用云端 API 跑通概念)
- [阶段二:再用 Ollama 做本地实验](#阶段二:再用 Ollama 做本地实验)
- [阶段三:最后再统一交给 LangChain](#阶段三:最后再统一交给 LangChain)
- [七、什么是 Embedding?为什么它和 LangChain 几乎绑在一起?](#七、什么是 Embedding?为什么它和 LangChain 几乎绑在一起?)
-
- [7.1 这是我理解 AI 应用开发的第一个关键转折点](#7.1 这是我理解 AI 应用开发的第一个关键转折点)
- [7.2 Embedding 不是"生成文本",而是"表示文本"](#7.2 Embedding 不是“生成文本”,而是“表示文本”)
- [7.3 为什么向量能表示"语义相近"?](#7.3 为什么向量能表示“语义相近”?)
- [7.4 Embedding 最常见的应用场景有哪些?](#7.4 Embedding 最常见的应用场景有哪些?)
-
- [1. 语义搜索](#1. 语义搜索)
- [2. RAG(检索增强生成)](#2. RAG(检索增强生成))
- [3. 推荐系统](#3. 推荐系统)
- [4. 异常检测](#4. 异常检测)
- [7.5 常见的 Embedding 模型](#7.5 常见的 Embedding 模型)
- [7.6 Embedding 评测和模型平台](#7.6 Embedding 评测和模型平台)
- [八、LangChain 为什么会出现](#八、LangChain 为什么会出现)
-
- [8.1 原生模型调用的问题,到这里已经很明显了](#8.1 原生模型调用的问题,到这里已经很明显了)
- [8.2 对 LangChain 的理解,不再是"神奇框架"](#8.2 对 LangChain 的理解,不再是“神奇框架”)
- 九、从零开始怎么安排自己的学习路线?
-
- [9.1 第一步:先建立"地图感"](#9.1 第一步:先建立“地图感”)
- [9.2 第二步:先写最小原生调用,不急着上框架](#9.2 第二步:先写最小原生调用,不急着上框架)
- [9.3 第三步:再把这些原子能力交给 LangChain 统一管理](#9.3 第三步:再把这些原子能力交给 LangChain 统一管理)
- [9.4 第四步:最后再进入 LangGraph](#9.4 第四步:最后再进入 LangGraph)
- 十、本篇总结
真正开始学 LangChain 之前,我先把大模型、提示词、Embedding 和接入方式彻底搞懂
💬 开篇 :很多人学 LangChain,一上来就先背
PromptTemplate、ChatModel、Retriever、Agent这些名词,结果越学越乱。我一开始也差点走这条路,后来才发现,LangChain 本质上只是把模型调用、提示词设计、检索、工具调用和工作流编排这些东西组织起来的框架。基础概念没搞懂,后面看再多 API 也只是"会抄不会用"。官方文档现在对两者的定位也很明确:LangChain 更像构建 LLM 应用和 Agent 的高层框架,而 LangGraph 更偏底层的 Agent 编排与运行时,强调有状态、长流程、可恢复执行;并且 LangGraph 并不强制依赖 LangChain,只是两者经常一起出现。 (LangChain 文档)👍 这篇我想解决的问题:如果我现在只会 C++,Python 基础很弱,对 AI 的理解停留在"会聊天、会生成代码",那我到底应该先把哪些底层认知搭起来,后面学 LangChain 才不会发懵?
🚀 这篇的定位:这不是一篇"立刻开写 LangChain 代码"的文章,而是一篇正式进入框架之前的"地图篇"。我会先把模型、大语言模型、提示词、Embedding、模型接入方式讲透,最后再解释:为什么学到这里,最终一定会自然走到 LangChain。
一、为什么我没有一上来就写 LangChain 代码?
1.1 我最先踩到的坑:把"框架"当成"知识本身"
我最开始接触这条路线的时候,很容易产生一个错觉:
好像学 LangChain = 学 AI 应用开发。
但后来我很快就发现,这个理解是反的。
LangChain 从来不是"能力的来源",它只是"组织能力的方式"。真正干活的,仍然是下面这些东西:
- 模型:负责理解输入、生成输出
- 提示词:负责把任务描述清楚
- Embedding:负责把文本变成向量,好做语义检索
- 检索系统:负责把外部知识找回来
- 工具调用:负责让模型不只会"说",还会"做"
- 工作流/状态管理:负责把复杂任务拆成多步来执行
也就是说,LangChain 更像什么?
如果拿我熟悉的 C++ 服务器开发来类比,它并不像"网络通信原理"本身,而更像是你把 socket、epoll、线程池、缓冲区、定时器这些零散能力封装成一套更容易写业务的框架。
框架能提高开发效率,但框架不是底层原理。
所以我现在觉得,真正正确的学习顺序应该是:
bash
先懂模型 -> 再懂提示词 -> 再懂 Embedding 和检索 -> 再看框架如何把它们串起来如果这一步顺序反了,后面你看到的一堆类名、组件名、链式调用,都会变成抽象空壳。
1.2 LangChain 到底在"包"什么?
官方文档现在对 LangChain 的描述非常直接:它是一个帮助开发者更快构建 LLM 应用和 Agent 的框架,提供预构建的 Agent 架构和大量模型集成;而 LangGraph 则是更低层的编排框架,重点是 durable execution(持久化执行) 、streaming(流式) 、human-in-the-loop(人类介入) 和 stateful agents(有状态 Agent) 。 (LangChain 文档)
这句话翻译成人话,就是:
- LangChain 更像"拿来就能开始搭东西的工程层"
- LangGraph 更像"控制复杂执行流程的运行时层"
所以后面你会反复看到这样一种关系:
模型调用
提示词设计
Embedding
检索/RAG
工具调用
LangChain
LangGraph
这张图我建议你先记住。
因为后面整个系列,几乎都在围绕这条线展开。
二、先把"模型"这件事说透:它到底是什么?
2.1 模型不是"黑盒魔法",它本质上是从数据里学规律
如果我要用一句最朴素的话来解释模型,那就是:
模型,就是一个从数据里学会规律,然后根据输入给出输出的函数或程序。
注意这里最关键的不是"程序",而是"学会规律"。
例如我给它很多组数据:
bash
输入:[1, 2, 3] 输出:2
输入:[4, 5, 6] 输出:5
输入:[7, 8, 9] 输出:8它如果最终学会了"输出永远是中间那个数",那以后你再给它:
bash
输入:[8, 9, 10]它就会输出:
bash
9这就是模型最基本的工作方式。
所以你会发现,模型不是数据库,也不是 if-else 规则表,而是一个通过训练学到了某种输入到输出映射关系的系统。
2.2 传统模型通常只擅长一件事
在大语言模型出现之前,我们对"模型"的认知通常更接近下面这种形式:
| 类型 | 典型任务 |
|---|---|
| 图像分类模型 | 判断图片里是不是猫 |
| 情感分析模型 | 判断评论是好评还是差评 |
| 天气预测模型 | 预测明天是否下雨 |
| 推荐模型 | 给用户推荐更可能感兴趣的内容 |
这类模型有一个共同点:
它们通常只对某个具体任务特别擅长。
你训练一个"识别猫"的模型,它不一定会翻译;
你训练一个"垃圾邮件分类"的模型,它也不会写代码。
这就是传统任务型模型的基本特点:
- 任务单一
- 往往需要比较明确的标注数据
- 目标很清晰,输入输出边界也很清晰
这类模型到今天仍然非常重要,只是大语言模型把"通用能力"这件事大幅往前推了一步。
2.3 参数到底是什么
一说到模型,大家很快就会碰到"参数"这个词。
你可以先把参数理解成:
模型在训练过程中学到的、决定它行为方式的一堆内部数字。
这些数字本身不需要你去手工改,它们是模型在看了海量数据之后慢慢调出来的。
参数越多,不一定就绝对更强,但通常意味着模型有机会表达更复杂的规律。
当然,我这里故意说得很朴素。因为对现在这个阶段来说,最重要的不是你立刻推导神经网络公式,而是先建立直觉:
参数不是"配置项",而是模型真正学到知识后沉淀下来的内部状态。
有了这个直觉,后面你再看"7B""72B""671B"这类名字时,就不会只把它们当成营销数字了。
三、什么是大语言模型?为什么它突然什么都会一点?
3.1 大语言模型,先别急着往"高深"理解
所谓大语言模型,英文叫 Large Language Model,LLM 。
如果不用论文腔,而是用最容易抓住本质的话来解释:
它本质上是一个规模特别大、通过海量文本训练出来的"下一个词预测器"。
这个说法听起来好像太简单了,但它就是关键。
比如你输入一句话:
bash
今天天气真____模型会根据前文判断,后面最可能出现的词是什么。
如果它能非常准确地一次次预测"下一个词",那把这个过程不断重复下去,就能生成:
- 一句话
- 一段回答
- 一篇文章
- 一段代码
- 一段对话
所以从底层机制上看,LLM 做的事情并没有神秘到脱离语言本身 。
它只是把"预测下一个词"这件事,做到了极其复杂、极其大规模的程度。
3.2 为什么它不只是"自动补全",却又确实和"自动补全"有关?
因为当模型规模足够大、训练数据足够多时,它在做"下一个词预测"的过程中,会被迫学会很多更底层的东西:
- 语法
- 语义
- 逻辑关系
- 常识知识
- 代码模式
- 文档结构
- 多轮对话上下文
也就是说,它表面上是在做"预测下一个词",但它为了把这个预测做好,实际上学到了大量语言世界里的隐含规律。
这就像什么?
你本来只是在做完形填空。
但如果你把全世界的小说、论文、网页、代码、问答、论坛、技术文档全拿来做完形填空,做了无数次之后,你自然就会开始理解语言背后的很多东西。
所以我们现在可以这样理解 LLM:
表面任务是补全,底层结果是获得了一种通用的语言理解与生成能力。
3.3 神经网络、自监督、半监督,这几个词到底该怎么理解?
1. 神经网络:不是"模拟人脑",而是分层处理信息
"神经网络"这个词一开始很容易把人带偏,好像它是在复制人脑。
更实用的理解方式是:
它是一种由大量可训练参数组成的分层信息处理结构。
前一层先提取一些简单特征,后一层在前一层基础上组合出更复杂的特征。
图像里可能是边缘、纹理、轮廓;
文本里可能是词、短语、句法模式、语义关系。
所以神经网络的重点不在"像不像脑子",而在于:
- 它是分层的
- 它可以训练
- 它能从数据里学出复杂模式
2. 自监督学习:模型自己给自己出题
LLM 一个特别重要的地方在于:
它不主要依赖"人工一条一条打标签"的方式来学。
它更常见的做法是:
直接拿海量原始文本,让模型自己从文本内部构造训练任务。
最典型的方式就是:
- 遮住一句话里的某个词
- 或者根据前文预测后文
- 让模型去猜最可能的内容
这就叫自监督学习。
说白了就是:
老师没给标准答案,但数据本身就能提供训练信号。
3. 半监督学习:少量指导 + 大量自学
半监督你可以理解成折中方案:
- 先给模型一些带标签的数据,让它知道大方向
- 再让它在大量无标签数据上继续学习
这很像有人先带你入门,再让你自己大量练习。
这几个词不要背定义,记住感觉就够了:
- 神经网络:一套可训练的分层结构
- 自监督:自己给自己出题
- 半监督:先带一段,再自己学很长一段
3.4 现在应该认识哪些主流模型家族?
模型迭代非常快,所以我不建议把"排行榜"当学习重点。
更重要的是:你至少要知道现在生态里有哪些主流路线,后面看到名字别陌生。
我自己会先这样认识它们:
- OpenAI GPT 系列 :OpenAI 现在在官方模型文档里把
gpt-5.4作为复杂推理和编码任务的默认起点,同时也明确新项目优先考虑使用 Responses API 来接入模型。 (OpenAI开发者) - Google Gemini 系列 :
gemini-2.5-pro当前官方定位是更擅长复杂推理、长上下文和多模态输入的模型,支持文本、图片、音频、视频和 PDF 等多种输入形式。 (Google AI for Developers) - DeepSeek 系列 :DeepSeek 官方文档强调它的 API 和 OpenAI 兼容,当前常见的
deepseek-chat与deepseek-reasoner分别对应非思考模式和思考模式,API 文档中给出的上下文长度为 128K。 (深度搜索API文档) - Qwen 系列 :在国内开源生态里,Qwen 是几乎绕不开的一条线;Qwen 官方近一段时间也在持续推出新一代基础模型以及专门的 Embedding 系列。 (Qwen)
你会发现,我这里没有展开讲谁"绝对最强"。
因为对初学者来说,第一步不是追榜,而是先建立判断标准:
- 这个模型偏 通用对话 还是偏 推理?
- 它是偏 闭源 API 还是偏 开源可部署?
- 它是否支持 多模态?
- 它在你的任务里更看重 速度、成本、推理质量、上下文长度 中的哪一个?
学会按这四个维度看模型,比死记几个型号有用得多。
四、大语言模型到底能做什么?又不能做什么?
4.1 它为什么会让人觉得"什么都会一点"?
我自己把 LLM 的能力先粗分成四类。
1. 语言理解与生成
这是最直观的能力:
- 写文章
- 改写文案
- 总结材料
- 翻译
- 写邮件
- 做问答
很多人第一次接触大模型,最容易停留在这一层。
但如果只把它当"高级写作工具",其实是低估它了。
2. 知识组织与表达
大模型并不等于搜索引擎,但它在训练中吸收了大量文本信息,所以它对很多知识点能做出一种"压缩后的重组表达"。
比如你问它:
- 某个概念是什么
- 两个技术的区别是什么
- 一个复杂问题有哪些角度
- 一段长材料的核心脉络是什么
它往往能先帮你搭出认知框架。
这里我特别强调一点:
不要把大模型当数据库,但可以把它当一个很强的"知识组织器"。
3. 逻辑推理与代码生成
这也是我们程序员最关心的一层。
模型不只会"说漂亮话",它还可以:
- 写函数
- 补全项目代码
- 重构代码
- 解释报错
- 给出算法思路
- 规划任务步骤
现在很多模型都把"代码能力""复杂推理能力"当成核心卖点。OpenAI 当前把 gpt-5.4 定位为复杂推理和编码任务的默认起点;Google 对 gemini-2.5-pro 的官方描述也直接强调它在代码、数学和 STEM 问题上的推理能力。
4. 多模态理解
"多模态"这个词你后面会反复见到,它的意思并不复杂:
不只是读文本,还能看图、看文档、处理音视频。
这一点现在已经不是"实验室概念"了。
OpenAI 当前模型文档写得很明确:最新模型支持文本和图像输入;Gemini 2.5 Pro 也支持文本、图片、音频、视频和 PDF 等输入;Gemini 的嵌入接口甚至已经能把文本、图片、视频、音频和文档映射到统一的向量空间。
4.2 但它并不是什么都能直接做好
这个地方特别重要,因为很多人学到这里会开始"神化"模型。
1. 上下文窗口永远是有限的
不管模型多强,一次请求能吃进去的输入始终是有限的 。
只是不同模型这个上限不同。
比如:
- OpenAI 当前文档里,
gpt-5.4给出的上下文窗口是 1,050,000 tokens - Gemini 2.5 Pro 文档给出的输入上限是 1,048,576 tokens
- DeepSeek 当前 API 文档里给出的上下文长度是 128K
这些数字已经很大了,但它依然是有限的 。
所以你不能天真地认为:"我把整个公司知识库一口气塞进去,不就完了?"
这也是为什么后面一定会出现:
- 文本切块
- 检索
- RAG
- 上下文压缩
- 工作流拆分
2. 模型默认不知道你的私有数据
模型训练再强,也不代表它知道:
- 你公司的内部制度
- 你的项目代码库最新状态
- 你自己的笔记
- 你本地的 PDF 文档
- 昨天刚发生的内部业务变更
这就是为什么后面 AI 应用开发里,一个特别大的主题叫:
让模型接触到它原本不知道的外部知识。
3. 原生 API 本质上还是"一问一答"
虽然现在官方 API 已经比最早复杂很多,像 OpenAI 的 Responses API 已经支持会话状态、函数调用以及文件搜索、网页搜索、computer use 等工具能力,但对开发者来说,本质问题仍然没有变:
复杂任务不是靠一次调用自然长出来的,而是要靠你自己设计执行流程。
比如这个任务:
读取一份财报 -> 提炼要点 -> 结合外部资料补充背景 -> 输出结构化摘要 -> 再生成 PPT 大纲
这就已经不是一个"随便问一句"的问题了。
它是一个多步任务。
而一旦任务多步,你就马上会遇到:
- 状态怎么传
- 中间结果怎么保存
- 哪一步调用什么工具
- 出错怎么重试
- 结果格式怎么约束
到这里,框架的意义才真正开始出现。
五、提示词不是咒语,而是"接口契约"
5.1 Prompt 不是玄学,是工程约束
很多人一说提示词,就容易走两个极端:
- 要么觉得提示词就是"随便问一句话"
- 要么觉得提示词是一种神秘咒语,谁掌握秘密词汇谁就厉害
我现在更认可的理解是:
提示词,本质上是你和模型之间的接口契约。
它要解决的是:
你到底有没有把任务说清楚。
你可以把模型想成一个能力很强,但不会主动猜你心思的系统。
你给的信息越模糊,它输出的空间就越大;
你给的信息越清楚,它就越容易沿着你想要的方向输出。
这件事和我们熟悉的网络协议很像。
比如 HTTP 为什么要有:
- 方法
- 路径
- Header
- Body
- 状态码
本质上都是为了减少歧义。
而提示词,也是在做同一件事:
减少歧义,明确任务边界,约束输出格式。
5.2最常用的一套结构:CO-STAR框架
写提示词时,最常用的不是"追求花哨",而是先强迫自己把下面六件事写清楚:
- Context:背景是什么
- Objective:目标是什么
- Steps:希望它按什么步骤做
- Tone:语气和风格是什么
- Audience:输出给谁看
- Response :结果用什么格式返回
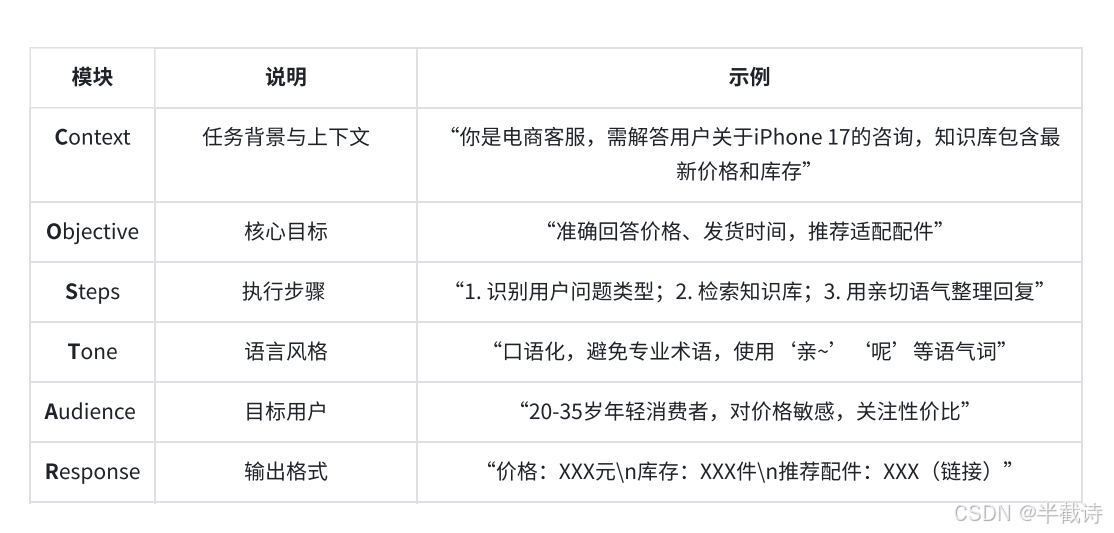
你会发现,这其实已经很像在写接口文档了。
比如一句很糟糕的话:
bash
帮我写一个更健康的饮食建议它的问题不是模型笨,而是你给的信息几乎没有约束:
- 什么人?
- 什么目标?
- 要不要免责声明?
- 输出成几条?
- 是按餐次给建议还是按营养素给建议?
- 要不要避免医疗化表述?
如果换成下面这种写法,结果通常会稳定很多:
bash
角色:你是一名提供通用健康信息的营养顾问。
背景:用户 30 岁,男性,久坐办公,每周力量训练 3 次。
目标:给出适合减脂增肌的日常饮食建议。
要求:
1. 先声明内容仅供一般参考,不能替代专业医疗建议
2. 核心原则围绕控制总热量和提高蛋白质摄入
3. 分早餐、午餐、晚餐、训练加餐分别给建议
4. 输出格式要清晰,使用标题和项目符号看起来写长了,其实不是"更复杂",而是更完整。
5.3 少样本提示:不要只下命令,要学会"举例子"
很多时候,光讲规则不如直接给范例。
这叫 Few-shot Prompting,也就是少样本提示。
本质上你不是在"命令"模型,而是在"示范"你要的格式和逻辑。
这对于下面这些场景特别有用:
- 固定格式抽取
- 固定风格仿写
- 复杂标签分类
- 结构化输出
比如我让模型分析客户反馈,如果我只说:
bash
请分析这条用户反馈那模型可能会发挥得很散。
但如果我先给它两个标准示例,它就会明显稳很多:
bash
示例1:
反馈:这款笔记本续航太差,宣传 10 小时,实际才 4 小时
输出:
产品:笔记本
情感:负面
问题:续航远低于宣传
示例2:
反馈:客服响应很快,帮我解决了激活问题
输出:
产品:客服服务
情感:正面
问题:无
现在请分析:
反馈:我刚买的耳机,用了一周左边就没声音了这就是少样本提示最核心的价值:
别只告诉模型规则,直接给它范本。
5.4 思维链提示:让模型先展开推理,再给结论
当问题开始涉及数学、逻辑、多步骤推理时,一个很常见的技巧就是:
不要让它直接报答案,而是要求它先分步分析。
这类方法后来被系统化地总结为 Chain-of-Thought Prompting(思维链提示) 。2022 年关于 CoT 的经典论文指出:当给大型语言模型提供"带推理过程的示例"时,它在算术、常识和符号推理等任务上的表现会明显提升;同年的另一篇论文又进一步说明,哪怕不提供示例,只是在提示词里加入类似 "Let's think step by step" 这样的引导,也可能显著改善零样本推理效果。 (arXiv)
翻译成人话就是:
- Few-shot-CoT:给它示例,而且示例里包含"推理过程"
- Zero-shot-CoT:不给示例,但要求它"一步步思考"
例如:
bash
罗杰有 5 个网球,又买了 2 盒,每盒 3 个。
请一步步推理,并给出最后答案。模型往往会输出:
bash
1. 罗杰原来有 5 个网球
2. 新买了 2 盒,每盒 3 个,所以新增 2 × 3 = 6 个
3. 总数 = 5 + 6 = 11
答案:11这比它直接甩给你一个数字更可靠,也更容易检查。
不过我这里也想提醒一句:
思维链不是让你沉迷"让模型写得越长越好"。
真正的重点是:
- 当任务复杂时,给它明确的中间步骤
- 让它不要跳步
- 让它先分析、后作答
这是一种很实用的工程习惯。
5.5 自我审查:把"生成"和"评审"拆开
这是我很喜欢的一种方法。
很多人写提示词只停留在:
bash
帮我写一个函数但更稳的方式其实是两步走:
- 先生成
- 再让它审查自己
比如:
bash
步骤一:写一个 Python 函数 find_max,用来求列表最大值
步骤二:请从健壮性和可读性两个角度审查你刚才写的代码
要求:
1. 如果输入空列表会怎样?
2. 有没有命名不清晰的问题?
3. 请给出优化后的版本这个技巧背后的思想很简单:
第一次输出时,它在"当作者";第二次输出时,它在"当审稿人"。
把这两种角色拆开,质量通常会更高。
后面学 LangChain Agent、工作流编排的时候,这种"生成 -> 检查 -> 修正"的思路会反复出现。
六、如果要真正接入大模型,有哪些方式?
6.1 先记结论:无非三条路
现在主流接入方式,其实就三种:
- 直接调云端 API
- 本地部署开源模型
- 使用 SDK(本质上是对 API 的封装)
看起来像三种,实际上 SDK 只是把 API 调用写得更符合代码习惯。
真正的分野,还是:
- 用别人的云端模型服务
- 自己在本地或私有服务器上跑模型
6.2 API 接入:最适合初学者的第一步
对刚入门的人来说,最推荐先走 API 接入 。
原因很简单:
- 环境最省心
- 最快看到结果
- 最容易理解"模型调用"这件事本身
- 后面切到 LangChain 也最丝滑
以 OpenAI 为例,官方现在的 quickstart 里依然是推荐通过官方 SDK 发起第一次请求;同时,官方也明确建议新项目优先考虑 Responses API,而不是老的 Chat Completions 作为默认起点。
如果我 Python 写一个最小可运行版本,大概是这样:
python
from openai import OpenAI
# 创建客户端对象
client = OpenAI(api_key="你的_API_Key")
# 发起一次最简单的模型调用
response = client.responses.create(
model="gpt-5.4",
input="请用三句话介绍一下什么是大语言模型"
)
print(response.output_text)上面这几行你可以这样理解:
from openai import OpenAI:导入官方 Python SDKclient = OpenAI(...):创建一个"客户端对象",后面所有请求都通过它发出client.responses.create(...):告诉服务端"帮我生成一次响应"model="gpt-5.4":指定模型input="...":给模型的输入response.output_text:把最终返回的文本拿出来打印
是不是很像一次"远程函数调用"?
你在本地代码里写一句方法调用,实际上背后发生的是:
bash
你的代码 -> SDK -> HTTP 请求 -> 云端模型服务 -> 返回 JSON -> SDK 封装 -> 你拿到结果所以从工程角度看,模型调用并不神秘,它首先是一种网络请求。
OpenAI 当前文档也给了非常明确的模型建议:如果你不知道从哪里开始,先用 gpt-5.4;如果你更看重延迟和成本,可以考虑更小的 gpt-5.4-mini 或 gpt-5.4-nano。
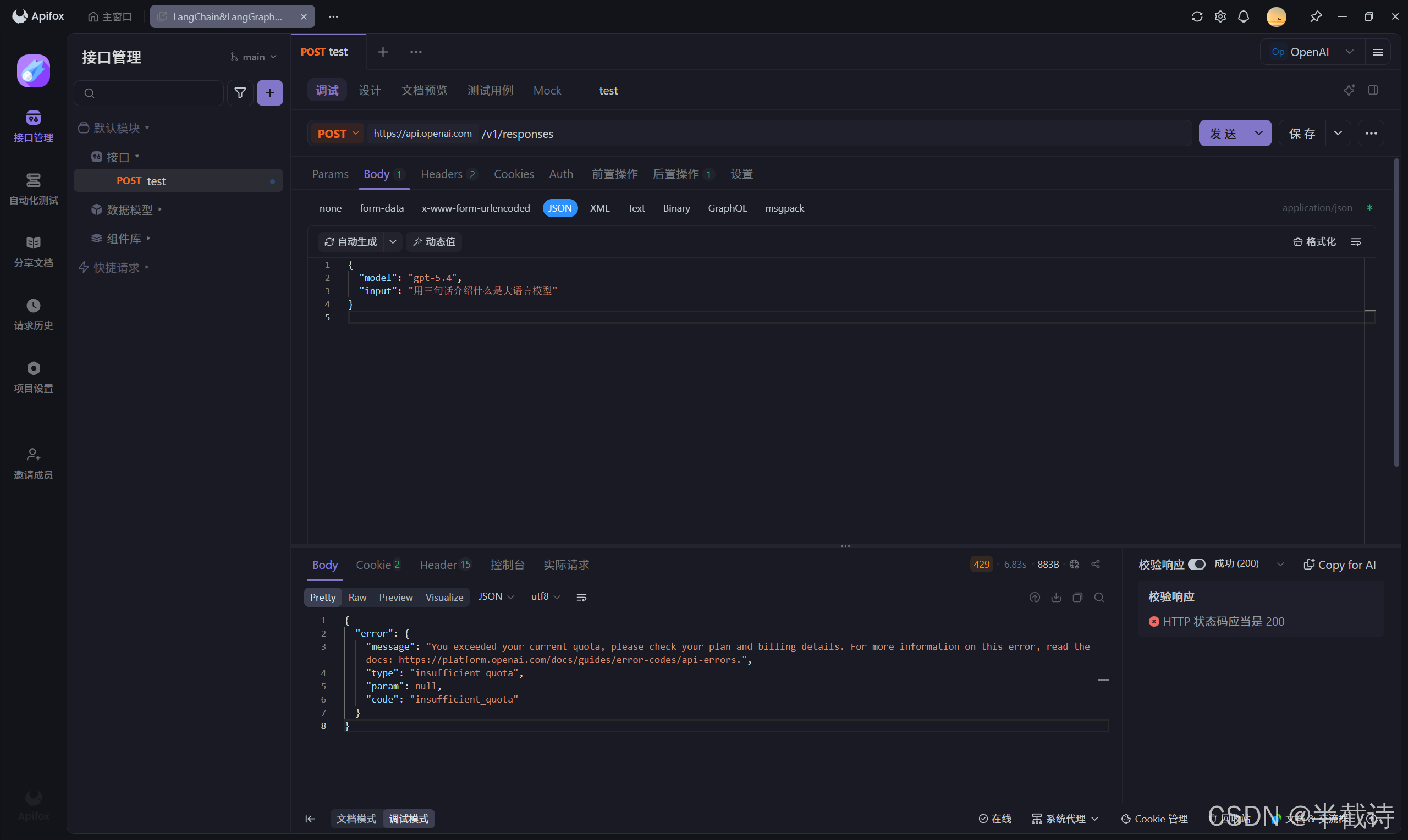
这里我使用的是apifox,因为没充值所以没额度,返回的是429错误码,只是演示一下,不过可以通过/v1/models接口看一下OPenAI的可以调用模型有哪些
6.3 SDK 接入:它不是新路线,只是更适合写代码
很多初学者会问:
"API 接入"和"SDK 接入"不是两种不同方式吗?
严格说,不是。
SDK 只是官方帮你把 HTTP 细节包装起来了。
你当然可以自己手写 requests.post(),甚至手写 curl。
但真实开发里,绝大多数时候更推荐直接用 SDK,因为它有几个明显好处:
- 代码更短
- 参数更清晰
- 返回结果有更稳定的对象结构
- 后续维护更方便
所以你以后看到:
- OpenAI Python SDK
- Gemini SDK
- 各家 OpenAI-compatible SDK
本质上都是在做同一件事:
让你更舒服地调接口。
6.4 本地部署:适合做实验,也适合理解"模型真的在我机器上跑"
如果说 API 接入是最适合上手的方式,
那本地部署最吸引人的地方就是:
模型就在我自己的机器上跑。
这个过程对理解 AI 应用开发也很有价值,因为你会第一次真正意识到:
- 模型是会占磁盘的
- 模型运行要吃 CPU / 内存 / 显存
- 模型大小和速度、效果是强相关的
- "能跑起来"和"跑得好"是两回事
现在本地部署的入门工具里,Ollama 是非常常见的一条路线。官方文档说明它支持 macOS、Windows 和 Linux;Windows 下最简单的安装方式是 OllamaSetup.exe 安装器,而且不要求管理员权限;如果你不想让模型下载到默认目录,还可以通过设置 OLLAMA_MODELS 环境变量修改模型存储位置。 (Ollama 文档)
跑通本地模型最简单的一步,按官方示例其实就是:
bash
ollama run gemma3或者先执行:
bash
ollama进入交互菜单,再选择模型。官方 quickstart 和 CLI 文档都给了这种最小路径;同时,Ollama 当前文档里也明确提到它可以很方便地跑包括 DeepSeek-R1、Qwen3 等在内的开源模型。 (Ollama 文档)
这里我特别提醒一个初学者容易误解的点:
本地部署不等于更高级。
很多时候,本地部署只是更自由、更可控;
而如果你的目标是先把 LangChain 学起来,云端 API 通常仍然是最顺手的。
6.5 如果我现在是零基础,我到底该怎么选?
我自己的建议非常明确:
阶段一:先用云端 API 跑通概念
因为这一阶段你最需要的不是"折腾环境",而是搞懂:
- 模型调用是什么
- Prompt 在哪一层起作用
- 返回结果长什么样
- 多轮对话和单轮对话怎么区分
阶段二:再用 Ollama 做本地实验
这一阶段的重点是理解:
- 开源模型怎么拉取
- 模型大小和资源消耗的关系
- 本地 API 是什么感觉
- 本地模型和云端模型的差异
阶段三:最后再统一交给 LangChain
因为到了这时候,你才知道 LangChain 到底在帮你省哪部分事情。
否则你会有一种错觉,以为:
"我在学框架。"
但其实你只是把问题暂时藏到了框架背后。
七、什么是 Embedding?为什么它和 LangChain 几乎绑在一起?
7.1 这是我理解 AI 应用开发的第一个关键转折点
如果说大语言模型让我第一次意识到"机器可以像人一样组织语言",
那 Embedding 则让我第一次真正理解:
机器不是在"懂文字",它是在处理向量。
这句话很关键。
因为计算机天然擅长的是数字,不是文字。
所以当我们想让系统比较两句话"意思像不像"、一段文档和一个问题"相关不相关"时,必须先把文本转换成计算机更容易处理的数值形式。
这个过程,就叫 Embedding(嵌入)。
7.2 Embedding 不是"生成文本",而是"表示文本"
这里必须和大语言模型区分开。
- 大语言模型:更偏生成式,核心目标是产出新的内容
- Embedding 模型:更偏表示型,核心目标是把输入映射成向量
这两者最大的区别在于"目标"不同。
比如你给 LLM 一句话:
bash
笔记本电脑充不进电怎么办?它会尝试回答你。
但你把这句话交给 Embedding 模型,它不会回答你。
它会返回一长串数字,比如:
bash
[0.0123, -0.0831, 0.4412, ...]这串数字本身不是答案,它是这句话在"语义空间"里的位置坐标。
用一个类比:
LLM 像作者,Embedding 像测绘员。
前者负责写,后者负责定位。
7.3 为什么向量能表示"语义相近"?
因为一个好的 Embedding 模型会尽量满足这样一件事:
- 语义相近的文本,向量距离更近
- 语义差很远的文本,向量距离更远
例如:
bash
"笔记本电脑充不进电"
"电脑电池无法充电"虽然这两句话字面不完全一样,但它们表达的意思很接近,所以理想情况下,它们的向量也应该比较接近。
反过来:
bash
"笔记本电脑充不进电"
"今天晚饭吃什么"语义关系很远,向量距离就应该更大。
所以 Embedding 真正的价值是:
把"语义关系"转成"数学距离"。
一旦语义能变成数学问题,后面的检索、排序、聚类、推荐,就都能做了。
最常见的相似度计算方式就是余弦相似度:
bash
similarity(A, B) = A · B / (||A|| × ||B||)你不用现在就死记公式,只要记住它的含义:
- 越接近 1,越相似
- 越接近 0,越不相关
- 越接近 -1,方向越相反
7.4 Embedding 最常见的应用场景有哪些?
OpenAI 的 Embeddings 指南和 Gemini 的 Embeddings 文档都把语义搜索、分类、聚类这类任务列为 Embedding 的核心用途;OpenAI 还明确提到它适用于搜索、聚类、推荐、异常检测、分类等场景。
我自己会把它归纳成四个最重要的方向:
1. 语义搜索
传统搜索更像关键词匹配。
Embedding 搜索更像"按意思找"。
这意味着就算用户问的问题和文档里的原句不完全一样,系统也有机会找到语义上真正相关的内容。
2. RAG(检索增强生成)
这是后面一定会频繁碰到的模式。
完整流程大概是:
用户问题
问题向量化
知识库文档
文档向量化
相似度检索
召回最相关片段
和用户问题一起喂给 LLM
生成更准确的回答
RAG 为什么火?
因为它解决了两个特别现实的问题:
- 模型原本不知道你的私有知识
- 模型原本知识可能过时
所以你先用 Embedding 找到最相关的资料片段,再把这些片段交给 LLM,让它"带资料回答",准确率通常就会上去。
3. 推荐系统
如果把用户偏好和内容都表示成向量,那么"你喜欢什么"和"什么东西适合你"就可以转成相似度问题。
4. 异常检测
正常数据在向量空间里往往会聚成一团。
一个离大家都很远的数据点,就可能是异常样本。
所以你会发现,Embedding 根本不是某个小技巧,
它其实是很多 AI 应用的底层通用能力。
7.5 常见的 Embedding 模型
和大语言模型一样,我依然不建议一上来就追榜。
先认识"路线"比记"名次"重要。
现在我会先这样看:
- OpenAI :官方 Embeddings 指南明确给出了
text-embedding-3-small和text-embedding-3-large这两条主线,默认维度分别是 1536 和 3072,同时text-embedding-3系列支持通过dimensions参数控制输出维度;Embedding 接口对单条输入长度也有明确限制,当前官方说明是所有 Embedding 模型单条输入不超过 8192 tokens。 - Google Gemini :当前 Gemini 文档中,
gemini-embedding-001仍然可用于纯文本场景,而最新的gemini-embedding-2-preview已经是多模态 Embedding,能把文本、图片、视频、音频和文档映射到统一向量空间。 (Google AI for Developers) - 阿里云百炼 / Qwen 生态 :当前官方文档在文本场景推荐
text-embedding-v4;对于多模态融合检索,则可以使用qwen3-vl-embedding、qwen2.5-vl-embedding等模型,而且这些模型支持不同维度配置。 (阿里云帮助中心) - 本地路线 :如果你走 Ollama,本地也可以通过
/api/embed生成 Embedding,接口支持传入model、input,并可设置dimensions。 (Ollama 文档)
这时候你应该开始意识到一个事实:
后面只要你一看到"知识库问答""RAG""向量数据库""语义检索",几乎必然都绕不开 Embedding。
7.6 Embedding 评测和模型平台
如果你后面想选 Embedding 模型,迟早会遇到 MTEB 这个名字。
Hugging Face 上的官方 MTEB Leaderboard 现在已经覆盖 100+ 模型、1000+ 语言与多种任务类型,是 Embedding 方向里很常见的参考基准。 (Hugging Face)
而模型平台方面,至少先认识两类:
- Hugging Face :全球最常见的模型社区与分发平台之一,首页现在也明确写着它提供大量模型、推理接口和部署能力。 (Hugging Face)
- ModelScope 魔搭社区 :国内很常见的一体化模型平台,官方首页直接把自己的定位写成"模型探索、体验、推理、训练、部署和应用的一站式服务"。 (模型范围)
现在不用马上把这些平台玩熟。
但至少知道:
- 模型从哪里找
- 文档从哪里看
- 开源模型和 API 服务通常在哪些平台汇聚
这会让你后面少走很多弯路。
八、LangChain 为什么会出现
8.1 原生模型调用的问题,到这里已经很明显了
我们把前面的内容串起来看,就会发现:
即便我已经掌握了:
- 怎么调 LLM
- 怎么写 Prompt
- 怎么调 Embedding
- 怎么做向量检索
我仍然会遇到一大堆工程问题:
- 不同模型厂商的接入方式不统一
- 消息格式不统一
- 工具调用要自己组织
- 检索、重排、记忆、输出解析要自己拼
- 多步任务的状态管理会越来越乱
- 出错重试、日志、流式输出、回调也会越来越难写
说白了:
原生 API 能用,但一旦项目稍微复杂一点,就会开始写大量"胶水代码"。
而 LangChain 的价值,就在于把这些高频胶水层统一起来。
官方文档也明确说明,LangChain 提供了预构建的 Agent 架构和模型集成,并支持主流模型提供商;这意味着你不再需要每换一个模型就推翻一遍上层应用结构。 (LangChain 文档)
8.2 对 LangChain 的理解,不再是"神奇框架"
我现在更愿意这样定义它:
LangChain = 一套面向 LLM 应用开发的通用抽象层。
它帮我统一的,其实是这些东西:
- 模型接口
- 消息格式
- Prompt 组织
- Embedding 接口
- 检索器
- 工具定义
- Agent 架构
- 输出解析
- 回调与流式处理
而 LangGraph 的意义则更进一步,它关心的是:
- 多节点执行
- 有状态任务流
- 中断与恢复
- 更复杂的 Agent 编排
官方文档甚至直接建议:如果你刚开始接触 Agent,想先用更高层抽象,可以先从 LangChain 的 agents 开始;如果你要构建更低层、更长流程、更强调状态和编排的 Agent,再进入 LangGraph。 (LangChain 文档)
这套关系一旦想清楚,后面你再学框架就不会迷糊了。
在已经知道底层零件是干什么的基础上,学会用框架把它们组装成真正可维护的应用。
九、从零开始怎么安排自己的学习路线?
9.1 第一步:先建立"地图感"
也就是你现在看到的这篇文章要解决的事情:
- 模型是什么
- LLM 为什么能聊天、写代码
- Prompt 为什么重要
- Embedding 为什么是检索基础
- 原生 API 和本地部署分别是什么
- LangChain 和 LangGraph 分别处在哪一层
这一步最怕的不是"记不住",
而是没有整体地图。
一旦没有地图,后面每个名词都像散点。
9.2 第二步:先写最小原生调用,不急着上框架
我建议真正动手时,先做三件最小事:
- 用 Python 跑通一次云端模型调用
- 用本地工具跑通一次开源模型
- 跑通一次 Embedding,把一段文本变成向量
为什么一定要先做这三件事?
因为它们能让你第一次真正摸到:
- 输入是什么
- 输出是什么
- 模型接口长什么样
- Embedding 返回的到底是什么东西
只要这三件事你亲手跑通过,
后面学 LangChain 的时候,很多抽象层就不再是"纸上谈兵"。
9.3 第三步:再把这些原子能力交给 LangChain 统一管理
等你知道模型、提示词、Embedding、检索到底是什么之后,再去看 LangChain:
ChatModelPromptTemplateEmbeddingsRetrieverToolAgent
你会明显轻松很多。
因为这时你知道:
这些不是新概念,
它们只是对你已经懂的东西做了一次统一包装。
9.4 第四步:最后再进入 LangGraph
LangGraph 不适合在"什么都没懂"的阶段硬上。
因为它更像"编排层""状态层""工作流层"。
只有当你已经知道:
- 一个节点里通常做什么
- 模型调用和工具调用怎么区分
- 为什么任务要拆多步
- 为什么要保存状态
你再学图结构编排,才会觉得它真的解决问题。
否则只会觉得:
- 节点很多
- 边很多
- 状态很多
- 看着很高级,但不知道在干嘛
十、本篇总结
这一篇我真正想做的,不是立刻开始写 LangChain 代码,
而是先把后面整个系列最容易混淆的底层概念全部摆正。
这一篇讲完之后,至少应该建立起这些认知:
- 模型本质上是从数据中学习规律的系统
- 大语言模型的底层核心可以先理解为"极强的下一个词预测器"
- 提示词不是玄学,而是和模型沟通的接口契约
- 原生模型调用可以通过 API、本地部署、SDK 三种路径理解
- Embedding不是用来生成内容,而是用来把语义映射为向量
- 检索、RAG、推荐、异常检测这些能力,很多都建立在 Embedding 之上
- LangChain的意义不是制造新能力,而是把这些零散能力统一成更好开发的抽象层
- LangGraph则更进一步,负责复杂 Agent 的状态化编排和运行时控制
如果要用一句话概括这篇文章,那就是:
在真正学习 LangChain 之前,我先得明白:框架只是外壳,模型、提示词、Embedding 和检索,才是这条技术路线真正的地基。
💬 预告:之后我们会开始真正动手,把本地环境和最小代码链路跑起来:先从最基础的 Python 认知补齐开始,再分别跑通一次云端模型调用、一次本地模型调用,以及一次 Embedding 调用。只有把这些最小原子动作亲手做出来,后面进入 LangChain 才不会空转。