摘要
《cuRoboV2: Dynamics-Aware Motion Generation with Depth-Fused Distance Fields for High-DoF Robots》
让机器人在复杂环境中自主、安全、高效地运动,是机器人学领域的核心挑战。当前的运动生成方法存在明显的割裂:有的规划器速度快但忽略动力学,生成的轨迹无法在真实机器人上执行;有的反应式控制器反应灵敏但依赖简化的几何模型,无法利用高保真传感器数据;有的算法在小规模机器人上表现优异,但难以扩展至复杂的人形机器人。
由NVIDIA的研究团队提出的 cuRoboV2,正是为了解决这些根本性难题而生的统一框架。它通过三项核心创新,打通了从感知到运动执行的整个链路:
- B样条轨迹优化:使用B样条作为优化空间,自动保证轨迹平滑,并能直接优化扭矩等动力学约束,从而生成物理上可执行的轨迹。
- GPU原生感知管线:通过一种全新的GPU加速TSDF/ESDF(截断有符号距离场/欧几里得有符号距离场)构建方法,能以毫米级分辨率、极快的速度生成覆盖整个工作空间的稠密距离场,为实时碰撞检测提供基础。
- 可扩展的全身计算:为高自由度机器人(如人形机器人)专门设计了可并行的运动学、动力学和自碰撞检测算法,使其在复杂机器人上的计算速度比现有方法快数十倍。
实验证明,cuRoboV2不仅在标准操作任务上表现卓越(如负载3kg下的规划成功率高达99.7%),还能成功应用于48自由度人形机器人的运动重定向,生成物理上可行的参考运动,并将下游强化学习策略的跟踪误差降低21%。此外,通过精心的代码架构设计,LLM(大语言模型)能协助完成高达73%的新模块开发,展现了人机协作的巨大潜力。
1. 引言:机器人运动生成的三座大山
想象一下,你让一个机器人去拿一杯水。这看似简单的动作背后,机器人需要解决一系列问题:怎么走最安全(避开桌角、不撞到自己)、怎么走最省力(关节扭矩不能超限)、以及如何根据你手的实时位置调整动作。现有的方法在处理这些问题时,通常面临三大瓶颈:
- 可行性鸿沟:许多快速规划器(如基于采样的RRT)只关注路径的几何形状,输出的是一条由直线段构成的关节路径。它假设机器人有无限大的扭矩,可以瞬间加速或停止。当机器人需要搬运重物时,这种路径往往会导致电机过载,轨迹无法执行。后处理(如时间优化)虽然能缓解,但通常会破坏原有的安全保证。
- 感知-反应权衡:反应式控制器(如MPC)能快速响应环境变化,但为了确保实时性,它们通常将机器人简化为球体或立方体,无法处理来自深度相机的海量点云数据。而基于学习的策略虽然能直接处理视觉输入,但缺乏严格的安全保证,且泛化能力差,换一个环境就需要重新训练。
- 可扩展性之墙:许多在7自由度单臂机器人上表现优异的算法,一旦应用到12自由度的双臂系统或48自由度的人形机器人上,就会因计算量爆炸而收敛缓慢,甚至完全失效。
cuRoboV2 正是为了打破这三座大山而生的统一框架。它用一套完整的GPU原生计算方案,将轨迹规划、碰撞检测、动力学计算和感知融合无缝地整合在一起。
2. 三大核心技术解析
2.1 核心一:B样条轨迹优化------让轨迹天生平滑
传统的轨迹优化方法,通常直接优化每个时间步的关节位置。这会导致优化变量数量巨大,且生成的轨迹可能不平滑(速度和加速度不连续),需要额外添加正则化项来"惩罚"不光滑。
cuRoboV2 的B样条优化方法则完全不同。它将整条轨迹表示为一组B样条控制点(每个关节对应一组)。B样条是一种数学曲线,具有两个关键特性:
- 天生平滑:3次B样条保证了位置、速度和加速度的连续变化,无需额外的平滑惩罚项。
- 局部支撑性 :改变一个控制点,只会影响轨迹的一小段(如图1所示)。这使得优化问题更加稀疏和稳定。
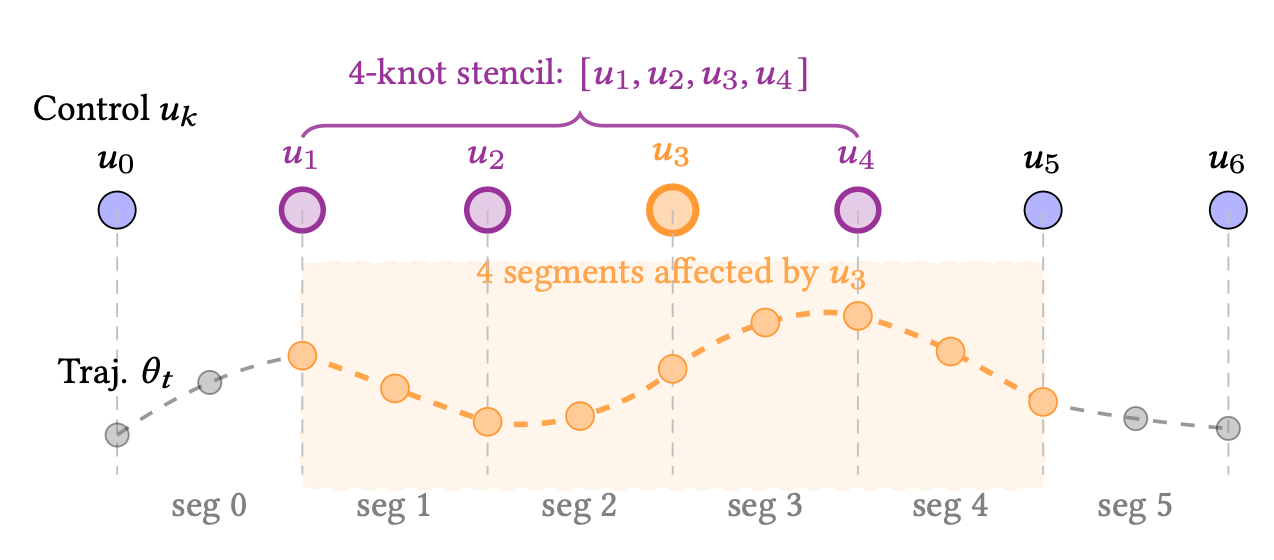
通过这种表示,优化器可以直接在平滑的轨迹空间中进行搜索。更重要的是,论文还引入了一个可微的逆动力学模型,允许优化器直接计算每个时间步的关节扭矩,并将"扭矩超限"作为惩罚项加入损失函数。这样一来,优化出的轨迹不仅能避开障碍物,还能保证在任何负载下都不会超过电机的物理极限。
2.2 核心二:GPU原生感知管线------毫米级精度的实时碰撞检测
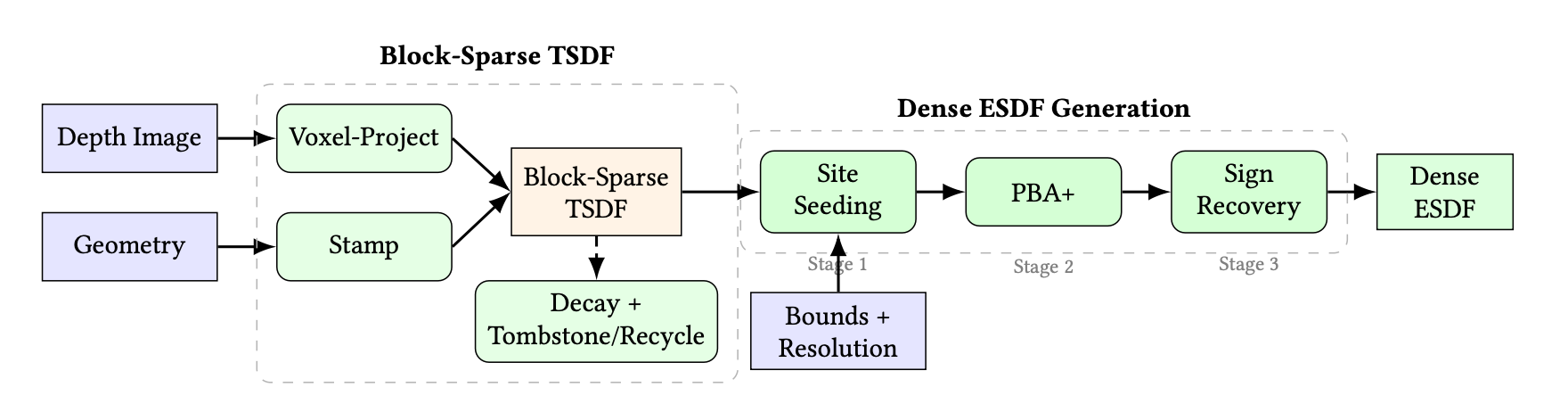
要让机器人安全地移动,它必须实时知道周围环境的几何信息。传统的做法是构建一个TSDF(截断有符号距离场),但它通常只存储靠近物体表面的信息。对于运动规划,我们需要的是ESDF(欧几里得有符号距离场),它能告诉机器人空间中任意一点到最近物体的距离和方向。
cuRoboV2 的感知管线有两个核心创新:
-
块稀疏TSDF与"体素中心"投影:
- 块稀疏存储:将三维空间划分为一个个小的"块",只分配那些有物体表面通过的块。这使得内存占用大幅降低(比nvblox少8倍)。
- 体素中心投影 :深度图像融合时,传统方法由每个像素发起,去更新它影响的所有体素,这需要大量的原子操作,导致性能瓶颈。cuRoboV2反其道而行之:每个体素一个线程,它将自身的三维坐标投影回深度图像,读取该像素的深度值,然后更新自己的距离场。这个过程是并行的、无锁的,速度极快。
-
按需生成的稠密ESDF:
- "收集"策略种子点:在将稀疏TSDF转换为稠密ESDF时,传统"散射"策略是遍历所有TSDF体素,找到表面体素后写入ESDF。这会导致线程数随场景变化,无法被CUDA图捕获。cuRoboV2采用"收集"策略:固定为每个ESDF体素启动一个线程,用7点模板去TSDF中查找是否存在表面,从而确定该ESDF体素是否为种子点。这使得工作负载恒定,能被CUDA图完美捕获,实现确定性延迟。
- PBA+距离传播:使用并行带状算法(PBA+)进行距离传播,它通过三个独立的轴对齐扫描,精确地计算出整个空间的欧几里得距离场,速度比传统的迭代算法快10倍。
- 符号恢复:对于没有表面通过的体素,通过采样相邻体素的几何SDF来确定其内部或外部。
这种设计使得cuRoboV2能以20毫米的分辨率、1.5毫秒的极快速度生成整个工作空间的ESDF,为下游规划器提供O(1)的查询能力,直接将规划时间缩短了19%。
2.3 核心三:可扩展的全身计算------征服高自由度机器人
对于人形机器人,计算复杂度呈指数级增长。一个48自由度的机器人,其自碰撞对的数量高达16万对(7自由度机械臂只有818对)。cuRoboV2通过一系列GPU优化技术攻克了这些挑战:
- 自适应运动学前向传播:根据机器人复杂度,自动选择单内核或双内核计算。对于复杂机器人,将最耗时的计算(如碰撞球位置、工具姿态)分配给大量线程并行处理。
- 拓扑感知的梯度反向传播:利用预计算的"链接祖先"表,将梯度计算限制在受影响的关节链上,而不是遍历所有关节,实现O(1)的复杂度。
- 稀疏雅可比矩阵计算:同样利用预计算的"影响"缓存,快速判断一个关节是否影响末端执行器,只计算相关的雅可比列。
- Map-Reduce自碰撞检测:将16万对碰撞检测任务分发给多个线程块,每个块在共享内存中找出最严重的穿透对,最后再通过一个归约内核找出全局最严重的穿透。这大大减少了内存带宽压力,将计算转化为计算密集型任务。
- 可微逆动力学引擎:实现了基于RNEA的可微逆动力学,支持运行时动态改变负载,且能扩展到48自由度的人形机器人(而GRiD和Newton等现有GPU实现在这点上会失败或效率低下)。通过直接优化扭矩,解决了之前规划器无法保证扭矩极限的问题。
3. 实验成果:数据说话
论文在多个维度上对cuRoboV2进行了详尽的评估,结果令人信服。
3.1 动力学感知规划:扛住3公斤重物
在包含2600个问题的标准数据集上,cuRoboV2表现出色。当机器人需要搬运3公斤的负载时,cuRoboV2的成功率高达99.7% ,而其他方法(如cuRobo、VAMP)的成功率跌至72-77%。这表明,只有将动力学约束(扭矩限制)纳入规划过程,才能保证生成的轨迹在真实世界中是可行的。
3.2 高自由度逆运动学:征服48自由度人形机器人
在标准逆运动学(IK)任务上,cuRoboV2在48自由度的Unitree G1人形机器人上达到了100%的成功率。当加入自碰撞避免约束后,cuRoboV2仍然能达到 99.6%的成功率,而cuRobo和PyRoki直接完全失败。这证明了其专用算法在复杂机器人上的巨大优势。
3.3 人形机器人重定向:让模仿学习更可靠
将人类动作(如爬行)重定向到人形机器人上,并用于训练强化学习策略。结果显示:
- 约束满足率:cuRoboV2的IK模式达到89.5%,远超PyRoki(61.2%)和mink(40.6%)。
- 下游策略性能:使用cuRoboV2生成的参考运动训练的机器人,其跟踪误差(MPJPE)比PyRoki低21%,且不同训练种子间的方差比mink低12倍。这说明,高质量的、满足物理约束的参考运动,能显著提升下游强化学习策略的质量和稳定性。
3.4 感知管线性能:又快又省内存
与业界领先的nvblox库相比,cuRoboV2在生成ESDF时,速度最快可达10倍 ,内存占用最多可节省8倍。同时,碰撞召回率高达99%,几乎不遗漏任何障碍物。
4. LLM辅助开发:代码架构的力量
论文一个独特而有趣的部分,是探讨了如何通过重构代码来赋能LLM编程助手。cuRoboV2的开发过程展示了,一个结构清晰、自文档化、模块化的代码库是LLM高效协作的前提。
通过将配置从YAML移到Python数据类(dataclass)、实现短小精悍的模块、编写详尽的文档字符串和测试用例,cuRoboV2的代码变得"对LLM友好"。在重构完成后,LLM(Claude Opus)在开发后期阶段贡献了高达**73%**的新代码,包括复杂的RNEA CUDA内核、统一场景碰撞系统和PBA ESDF管线。
这揭示了人机协作的新模式:人类负责顶层设计、架构决策和调试LLM难以处理的"判断"问题,而LLM则高效地执行具体实现、代码迁移和优化工作。
5. 局限性与未来展望
尽管cuRoboV2取得了巨大成功,论文也坦诚地指出了其局限性:
- 感知鲁棒性:当前的机器人分割方法(利用碰撞球)依赖于深度估计的准确性,存在局限性。未来可以引入基于RGB的学习型分割方法,提高鲁棒性。
- 视野限制:单目相机存在视野盲区,未来可探索多相机融合,实现更完整的场景重建。
- LLM协作的边界:虽然LLM能编写和优化CUDA代码,但它在理解编译器中间表示(如区分虚拟和物理寄存器压力)方面仍有困难,这需要人类的专业知识来干预和判断。
- MPC与全局规划的结合:目前MPC主要用于局部避障,未来可以将全局规划器生成的路径作为MPC的"引导",实现更智能、更高效的反应式全身控制。
6. 结语
cuRoboV2 不仅是一个性能卓越的机器人运动生成框架,更是一次对现代机器人软件栈设计哲学的深刻思考。它向我们展示了:
- 统一框架的力量:通过将B样条优化、GPU原生感知和高性能全身计算整合到一个框架中,解决了碎片化方法带来的"可行性鸿沟"、"感知-反应权衡"和"可扩展性之墙"三大难题。
- "软硬协同"设计的价值:从头为GPU设计的算法,能最大化利用硬件性能,使得原本"不可能"的任务(如48自由度机器人的实时碰撞检测IK)变为现实。
- "对LLM友好"的代码架构是未来的重要方向:一个结构良好、易于理解的代码库,不仅能提升人类开发者的效率,更能成为与AI协同工作的理想平台,解锁前所未有的开发速度。
对于机器人领域的研究者和工程师而言,cuRoboV2提供了一个极具参考价值的范式:如何构建一个从感知到执行,既注重理论优雅又注重工程实用性的完整系统。其代码和设计理念,无疑将推动整个领域向着更安全、更高效、更智能的方向发展。