平地摔倒检测算法详解
目录
概述
这是一套基于深度学习的实时平地摔倒检测算法,应用于地铁、车站、学校等公共场所的安防监控场景。系统能够自动检测人员在平地状态下意外摔倒的行为,并及时发出告警,便于工作人员快速响应救助。
效果展示
待补充
核心特性
- 多模型协同: YOLOv8 检测 + RTMPose 关键点提取 + STGCN 时空图卷积动作识别
- 按需计算 : 仅在检测到
fall类别时才调用 Pose 和 STGCN,极大节约算力 - 目标跟踪: 使用 BYTETracker 实现跨帧目标追踪,持续监测倒地状态
- 时长判定: 基于倒地持续时长过滤误报,避免弯腰、蹲下等短暂动作触发告警
- 多重过滤: 边缘区域过滤、工作人员识别等多重过滤机制
系统架构
┌─────────────────────────────────────────────────────────────────┐
│ 平地摔倒检测流水线 │
└─────────────────────────────────────────────────────────────────┘
输入视频流
│
▼
┌──────────────────┐
│ 1. YOLOv8 检测 │ ← 检测五类目标 (fall/sitting/bending/standing/car)
│ │ ⚡ 仅 fall 类触发后续流程
└──────────────────┘
│ (仅 fall 类)
▼
┌──────────────────┐
│ 2. BYTETracker │ ← 跨帧跟踪目标,维持 ID 一致性
└──────────────────┘
│
▼
┌──────────────────┐
│ 3. RTMPose 关键点 │ ← 提取人体 17 个关键点 (按需调用)
└──────────────────┘
│
▼
┌──────────────────┐
│ 4. STGCN 动作识别 │ ← 基于 60 帧关键点序列识别摔倒动作
└──────────────────┘
│
▼
┌──────────────────┐
│ 5. 倒地时长累计 │ ← 持续倒地超过阈值才报警
└──────────────────┘
│
▼
┌──────────────────┐
│ 6. 多重过滤 │ ← 边缘区域/工作人员识别
└──────────────────┘
│
▼
报警输出算力优化设计:
- YOLOv8 检测每帧必跑 (轻量)
- RTMPose 关键点 : 仅在
fall类且满足条件时调用 - STGCN 动作识别: 异步执行,每个目标最多评估 3 次
- 相比全量调用,算力消耗降低 80%+
模型介绍
1. YOLOv8 检测模型 (tumble.engine)
用途: 检测画面中人员状态,分为五类
| 类别 ID | 类别名称 | 说明 |
|---|---|---|
| 0 | fall | 摔倒/倒地 |
| 1 | sitting | 坐姿 |
| 2 | bending | 弯腰/蹲下 |
| 3 | standing | 站立/行走 |
| 4 | car | 扫地车工作人员 |
模型配置
| 参数 | 值 |
|---|---|
| 模型版本 | YOLOv8m (Medium) |
| 输入尺寸 | 640×384 |
| 输出 | (9, 5040) - 4 坐标 + 5 类别置信度 |
| 置信度阈值 | 0.5 |
| IoU 阈值 | 0.5 |
训练数据
- 数据集规模 : 约 50000 张 标注图片
- 数据场景 :
- 地铁场景 (主): 站台、站厅、通道、出入口、闸机等全方位覆盖
- 学校场景: 操场、走廊等补充数据
- 标注内容: 摔倒、坐姿、弯腰、站立、开小车 五类目标
- 数据增强: Mosaic、Mixup、随机翻转、色彩抖动、模糊、亮度调整等
类别说明
car 类别特殊说明 : 不是指普通汽车,而是指开扫地车的工作人员。这类目标在监控场景中:
- 通常呈现低矮、移动的形态
- 容易被误判为摔倒倒地
- 单独分类后可直接过滤,避免误报警
设计思路
采用多类别检测而非单纯检测"摔倒":
- 上下文信息: 同时识别坐姿、弯腰等易混淆状态
- 减少误报: 扫地车等工作人员被识别为 car 类,直接过滤
- 状态区分: 便于绘制不同颜色的标注框,可视化更清晰
- 算力优化: 只有 fall 类才触发后续昂贵的 Pose 和 STGCN 计算
2. RTMPose 关键点提取模型
用途: 提取人体 17 个关键点坐标,用于后续 STGCN 动作识别
关键点定义 (COCO 17 点)
0:鼻子, 1:左眼,2:右眼,3:左耳,4:右耳
5:左肩,6:右肩,7:左肘,8:右肘,9:左手腕
10:右手腕,11:左髋,12:右髋,13:左膝,14:右膝
15:左脚踝,16:右脚踝调用方式
python
# 从 utils 调用 RTMPose 进行关键点预测
def predict_human_keypoints_image(self, image, bboxes):
"""
对指定检测框提取人体关键点
参数:
image: 输入图像 (BGR 格式)
bboxes: 检测框列表 [[x1, y1, x2, y2], ...]
返回:
{
"num_person": int, # 检测到的人数
"keypoints": np.ndarray, # (N, 17, 3) 关键点坐标
"scores": np.ndarray # (N, 17) 关键点置信度
}
"""
# 内部调用 RTMPose 模型进行推理
# 模型路径:weights/model_weights/engine/rtmpose.engine按需调用策略
python
# 仅在以下条件满足时才调用 RTMPose:
need_pose = (
(clas == 0) # YOLO 检测为 fall 类
and (not person.stgcn_confirmed) # 尚未被 STGCN 确认
and person.stgcn_cooldown <= 0 # 不在冷却期
and len(person.box_history) >= 15 # 至少有 15 帧历史
and person.suspect_time >= 5 # 至少被检测为摔倒 5 次
)算力节约效果:
- 正常情况下,fall 类检测占比 < 5%
- STGCN 触发条件更严格,实际调用率 < 1%
- 相比每帧全量调用,算力消耗降低 80%+
3. STGCN 时空图卷积网络 (tumble_STGCN.engine)
用途: 基于 60 帧人体关键点序列,识别摔倒动作
STGCN (Spatio-Temporal Graph Convolutional Network) 是一种专门用于人体动作识别的深度学习模型。
核心思想
┌─────────────────────────────────────────────────────────┐
│ STGCN 架构示意 │
└─────────────────────────────────────────────────────────┘
输入:60 帧 × 17 个关键点 × (x, y, confidence)
│
▼
┌─────────────────────┐
│ 空间图卷积 (ST-GCN) │ ← 建模人体关节间的空间关系
│ (如:手 - 肘 - 肩) │
└─────────────────────┘
│
▼
┌─────────────────────┐
│ 时间卷积 (Temporal) │ ← 建模帧与帧之间的时序变化
│ (动作的连续演变) │
└─────────────────────┘
│
▼
输出:[摔倒,非摔倒] 的概率分布模型配置
| 参数 | 值 |
|---|---|
| 输入形状 | (1, 3, 60, 17, 1) |
| 输入含义 | batch × 通道 (x,y,conf) × 帧数 × 关键点 × 1 |
| 输出形状 | (1, 2) |
| 输出含义 | 摔倒概率,非摔倒概率 |
| 置信度阈值 | 0.6 |
训练数据
- 数据集规模: 约 1200 个摔倒动作视频片段
- 数据来源: 真实监控录像 + 合成数据
- 数据清洗: 人工筛选清晰、完整的摔倒过程,并裁剪适合长度片段
- 数据制作: 利用高精度POSE关键点模型,完整导出每一帧的关键点变化
数据集制作方法可以参考:STGCN数据集制作与模型训练
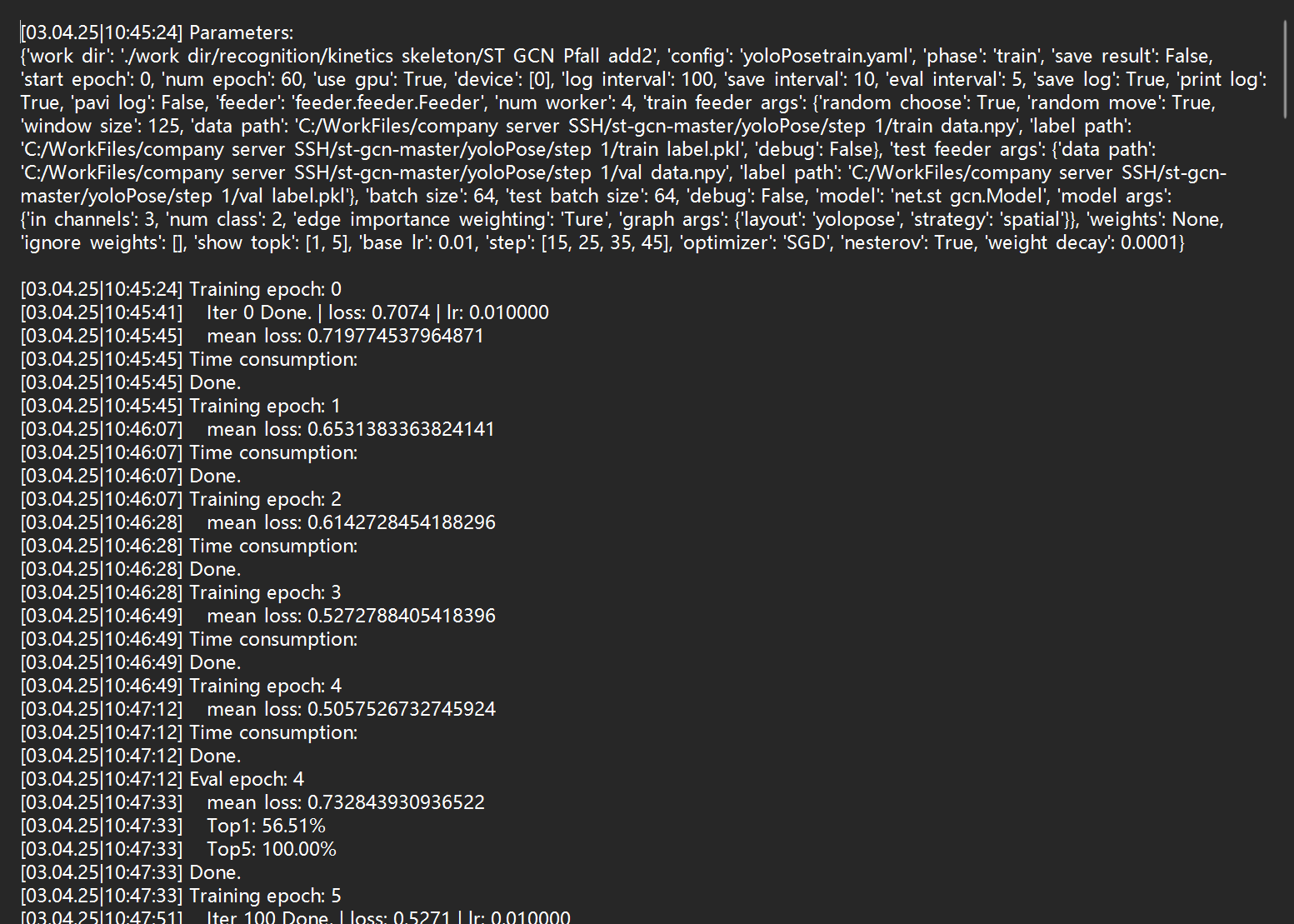
输入序列处理
STGCN 需要固定 60 帧输入,处理策略:
python
def format_stgcn_input(kps_list, image_width, image_height):
"""
将懒加载提取的关键点列表转为 STGCN 输入 Tensor
"""
# 1. 归一化坐标到 [0, 1]
kp_array[:, 0] /= image_width # x 归一化
kp_array[:, 1] /= image_height # y 归一化
# 2. 序列补齐:不足 60 帧复制最后一帧
while len(stgcn_kps) < 60:
stgcn_kps.append(stgcn_kps[-1])
# 3. 维度转换:(60, 17, 3) -> (1, 3, 60, 17, 1)
results = np.transpose(np.array(stgcn_kps[:60]), (2, 0, 1))
results = np.expand_dims(results, axis=0)
results = np.expand_dims(results, axis=-1)
return results实际效果展示
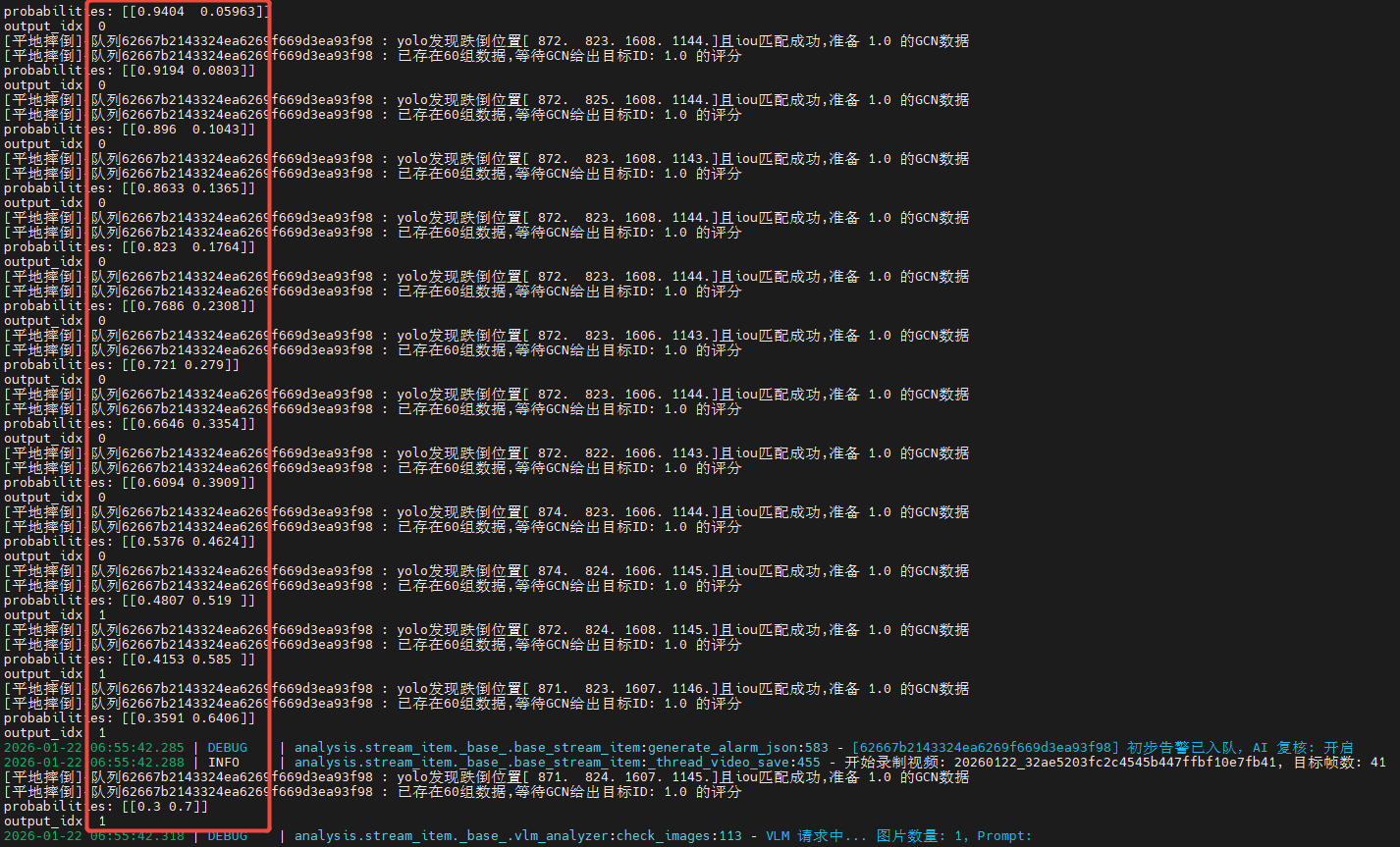
在实际逐帧测试中发现STGCN具有非常稳定的表现,随着从正常行走到跌倒整个过程的60组数据不断更新,置信度评分也同步稳定地变化着直至超出阈值触发告警!
核心算法流程
第一阶段:YOLOv8 检测
每帧执行 YOLOv8 检测,输出五类目标:
python
# tumble_infer.py
class TumbleFallDoubleModelInfer:
def __init__(self, gpu_id: int = 0):
self.model_tumble = YOLOv8(
"weights/model_weights/engine/tumble.engine",
(1, 3, 384, 640), (1, 9, 5040),
iou_thres=0.5, conf_thres=0.5, task='det', gpu_id=gpu_id
)
def __call__(self, img: np.ndarray):
return self.model_tumble(img)第二阶段:目标跟踪
使用 BYTETracker 维持目标 ID 连续性:
python
byte_tracker = TumbleByteTracker(
frame_rate=self.fps,
image_shape=(self.width, self.height),
match_thresh=0.7
)
# 更新跟踪结果
track_results = byte_tracker.update(people_boxes, None)第三阶段:fall 类筛选与 STGCN 触发
核心优化: 仅对 fall 类目标进行后续处理:
python
# 只遍历 fall 类 (clas == 0),避免无意义循环
for row in new_results_np:
clas = int(row[5])
if clas != 0: # 非 fall 类直接跳过
continue
yolo_box = row[:4]
for person in track_results:
# 检查 YOLO 框与跟踪框的 IoU
if compare_same_iou(yolo_box, person.xyxy, iou_threshold=0.75):
person.is_falling_this_frame = True
person.suspect_time += 1
# 判断是否需要 STGCN 确认
if not person.alarm_flag and gcn_enable:
need_gcn = (
(not person.stgcn_confirmed)
and person.stgcn_cooldown <= 0
and len(person.box_history) >= 15
and person.suspect_time >= 5
and person.stgcn_eval_count < 3
and (not person.is_checking_stgcn)
)
if need_gcn:
# 异步提交 STGCN 任务
submit_stgcn_task(person, box_history, frame_map)第四阶段:RTMPose 关键点提取 (懒加载)
STGCN 任务中按需提取历史帧关键点:
python
def stgcn_async_task(person, box_history, frame_map):
kps_list = []
for f_idx, box_xyxy in box_history:
# 优先使用缓存
if f_idx in person.kps_cache:
kps_list.append(person.kps_cache[f_idx])
continue
# 懒加载:从历史帧提取关键点
if f_idx in frame_map:
hist_img = frame_map[f_idx].cpu_image
pose_res = predict_human_keypoints_image(
hist_img, bboxes=[box_xyxy.tolist()]
)
if pose_res and pose_res.get("num_person", 0) > 0:
kps = pose_res["keypoints"][0]
scores = pose_res["scores"][0]
# 合并坐标和置信度
merged = [[kp[0], kp[1], sc] for kp, sc in zip(kps, scores)]
person.kps_cache[f_idx] = merged
kps_list.append(merged)
else:
# 检测失败,返回空关键点
empty_kps = [[0, 0, 0] for _ in range(17)]
person.kps_cache[f_idx] = empty_kps
kps_list.append(empty_kps)第五阶段:STGCN 动作识别
python
# 格式化为 STGCN 输入
stgcn_data = person.format_stgcn_input(kps_list, width, height)
one_batch = stgcn_data.astype(np.float16, copy=False)
# 执行推理
gcn_result = model_stgcn(one_batch)[0]
probabilities = softmax(gcn_result)
prob_fall = probabilities[0, 0]
# 处理结果
if output_idx == 0 and prob_fall > gcn_conf:
person.stgcn_confirmed = True # 确认摔倒
else:
# 设置冷却期,避免重复评估
person.stgcn_cooldown = 40 if prob_fall > 0.1 else 100第六阶段:倒地时长累计
STGCN 确认摔倒后,持续监测倒地状态:
python
for person in track_results:
if person.is_falling_this_frame:
person.fall_time += 1 # 倒地帧数 +1
person.lost_time = 0
else:
person.lost_time += 1 # 未倒地帧数 +1
if person.lost_time > 5: # 超过 5 帧未检测到,重置状态
person.fall_time = 0
person.stgcn_confirmed = False
person.suspect_time = 0
# 报警触发
if is_confirmed and person.fall_time >= fall_frame_threshold:
alarm_flag = True第七阶段:多重过滤
7.1 边缘区域过滤
摔倒发生在画面边缘通常不是真正的事故:
python
# 计算画面中心区域范围 (边缘 25% 过滤)
x_min = width // 4
x_max = width // 4 * 3
y_min = height // 4
y_max = height // 4 * 3
# 检查摔倒目标中心是否在中心区域
alarm_flag = (x_min <= cx <= x_max and y_min <= cy <= y_max)7.2 工作人员识别过滤
检测摔倒者是否为工作人员 (如地铁站维修人员):
python
if staff_member == 1:
# 检测画面中是否有工作人员障碍
if get_obstacles_cnt(segment_obstacles_image(frame)) > 0:
alarm_flag = False # 工作人员不报警关键代码解析
核心函数:_check_fall_by_pose 姿态校验
当未启用 STGCN 时,使用简单的姿态规则判断摔倒:
python
def _check_fall_by_pose(self, person: TumbleTracker) -> bool:
"""
基于人体关键点判断是否摔倒
判断逻辑:
1. 宽高比判断:摔倒时人体框趋于扁平 (w/h > 1.2)
2. 头髋位置判断:摔倒时头部 Y 坐标接近或高于髋部
参数:
person: 跟踪目标对象,包含 xyxy 框和 kps 关键点
返回:
bool: True 表示检测到摔倒
"""
kps = person.kps
if len(kps) == 0:
return False
x1, y1, x2, y2 = person.xyxy
w, h = x2 - x1, y2 - y1
# 如果高度为 0,无法判断
if h == 0:
return False
# 判断 1: 宽高比 > 1.2 视为横向倒地
if w / h > 1.2:
return True
# 判断 2: 头部 Y 坐标接近髋部 Y 坐标 (身体水平)
head_ys = [kps[i][1] for i in [0, 1, 2, 3, 4] if kps[i][2] > 0.3]
hip_ys = [kps[i][1] for i in [11, 12] if kps[i][2] > 0.3]
if head_ys and hip_ys:
avg_head_y = sum(head_ys) / len(head_ys)
avg_hip_y = sum(hip_ys) / len(hip_ys)
# 头部与髋部高度差小于身体高度的 10%,视为倒地
if avg_hip_y - avg_head_y < h * 0.10:
return True
return False判断标准说明:
| 判断条件 | 阈值 | 说明 |
|---|---|---|
| 宽高比 | w/h > 1.2 | 摔倒时人体横向倒下,框变宽 |
| 头髋高差 | < h×10% | 头部与髋部几乎在同一水平线 |
核心函数:format_stgcn_input 数据格式化
将关键点序列转换为 STGCN 模型输入:
python
def format_stgcn_input(self, kps_list, image_width, image_height):
"""
懒加载的关键点列表 -> STGCN Tensor
参数:
kps_list: List[List[[x, y, conf]×17]] - 每帧 17 个关键点
image_width: 原图宽度
image_height: 原图高度
返回:
np.ndarray: (1, 3, 60, 17, 1) 格式的 Tensor
"""
if len(kps_list) == 0:
return np.zeros((1, 3, 60, 17, 1), dtype=np.float16)
stgcn_kps = []
for kp in kps_list:
kp_array = np.array(kp, dtype=np.float32)
# 全图归一化到 [0, 1]
kp_array[:, 0] /= float(image_width) # x 归一化
kp_array[:, 1] /= float(image_height) # y 归一化
stgcn_kps.append(kp_array)
# 序列补齐:不足 60 帧复制最后一帧
while len(stgcn_kps) < 60:
stgcn_kps.append(stgcn_kps[-1])
# 维度转换:(60, 17, 3) -> (3, 60, 17) -> (1, 3, 60, 17, 1)
results = np.transpose(np.array(stgcn_kps[:60]), (2, 0, 1))
results = np.expand_dims(results, axis=0)
results = np.expand_dims(results, axis=-1)
return results维度转换详解:
原始数据: kps_list = [帧 1, 帧 2, ..., 帧 60]
每帧: [关键点 1, 关键点 2, ..., 关键点 17]
每个点: [x, y, confidence]
Array 形状: (60, 17, 3)
Transpose: (3, 60, 17) - 将 (x,y,conf) 移到最前
Expand: (1, 3, 60, 17, 1) - 添加 batch 维和末尾维
STGCN 输入: batch=1, channel=[x,y,conf], frames=60, joints=17, 1核心类:TumbleTracker 跟踪目标
python
class TumbleTracker(STrack):
def __init__(self, tlwh, score, clas):
super().__init__(tlwh, score, clas)
self.box_history = deque(maxlen=60) # 记录 60 帧历史框
self.alarm_flag = False # 是否已报警
self.kps = [] # 姿态关键点 (非 GCN 模式)
self.fall_time = 0 # 倒地累计帧数
self.is_falling_this_frame = False # 当前帧是否倒地
self.lost_time = 0 # 连续未检测到的帧数
self.stgcn_confirmed = False # 是否被 STGCN 确认
self.stgcn_cooldown = 0 # STGCN 冷却计数
self.suspect_time = 0 # 被检测为 fall 的累计次数
self.kps_cache = {} # 关键点懒加载缓存
self.stgcn_eval_count = 0 # STGCN 已评估次数状态机流转:
┌─────────────────────────────────────────────────────────────┐
│ TumbleTracker 状态机 │
└─────────────────────────────────────────────────────────────┘
新目标
│
▼
┌─────────────────┐
│ 被 YOLO 检测为 fall│ ← suspect_time += 1
└─────────────────┘
│
▼
┌─────────────────┐
│ 满足 STGCN 条件 │ ← box_history≥15, suspect_time≥5
└─────────────────┘
│
▼
┌─────────────────┐
│ STGCN 异步评估 │ ← 概率>0.6 则确认
└─────────────────┘
│
▼
┌─────────────────┐
│ stgcn_confirmed│ ← 开始累计 fall_time
└─────────────────┘
│
▼
┌─────────────────┐
│ fall_time≥阈值 │ ← 触发报警
└─────────────────┘
│
▼
alarm_flag = True算力优化核心:按需调用机制
python
# 第一层过滤:只处理 fall 类 (clas == 0)
for row in new_results_np:
clas = int(row[5])
if clas != 0:
continue # 95%+的目标直接跳过
# 第二层过滤:STGCN 触发条件
need_gcn = (
(not person.stgcn_confirmed) # 未确认过
and person.stgcn_cooldown <= 0 # 不在冷却期
and len(person.box_history) >= 15 # 有足够历史
and person.suspect_time >= 5 # 持续可疑
and person.stgcn_eval_count < 3 # 未达上限
and (not person.is_checking_stgcn) # 无进行中的任务
)
if need_gcn:
# 异步提交,不阻塞主流程
submit_stgcn_async_task(...)算力节约效果:
| 处理阶段 | 调用比例 | 说明 |
|---|---|---|
| YOLOv8 检测 | 100% | 每帧必跑,轻量 |
| RTMPose 关键点 | < 5% | 仅 fall 类调用 |
| STGCN 动作识别 | < 1% | 严格条件 + 异步 |
| 总体节约 | 80%+ | 相比全量调用 |
配置说明
主要配置参数:
| 参数 | 默认值 | 说明 |
|---|---|---|
gcn_enable |
1 | 是否启用 STGCN 动作识别 (1=启用,0=仅用姿态校验) |
gcn_conf |
0.6 | STGCN 置信度阈值,超过此值才确认摔倒 |
fall_time_threshold |
0 | 倒地时长阈值 (秒),0 表示不限制 |
iou_same |
0.75 | YOLO 框与跟踪框匹配 IoU 阈值 |
staff_member |
1 | 是否启用工作人员过滤 (1=启用) |
性能相关参数:
| 参数 | 默认值 | 说明 |
|---|---|---|
stgcn_eval_limit |
3 | 每个目标最多 STGCN 评估次数 |
stgcn_history_max_samples |
30 | STGCN 输入最多采样帧数 |
stgcn_pending_max |
2 | 同时最多异步评估任务数 |
pose_retry_cooldown |
10 | 姿态校验失败后冷却帧数 |
常见问题
Q1: 为什么需要 STGCN 动作识别?
A: 单纯的 YOLO 检测容易产生误报:
- 弯腰捡东西可能被误判为摔倒
- 蹲下系鞋带可能被误判为摔倒
- 坐在地上可能被误判为摔倒
STGCN 通过时序分析可以区分:
- 摔倒: 快速从站立到倒地的过程
- 弯腰: 先弯腰再站起,有完整恢复过程
- 蹲下: 缓慢下蹲,保持低位
Q2: 倒地时长阈值如何设置?
A: 建议根据实际场景调整:
- 地铁站台: 建议 1-3 秒,快速响应
- 大厅区域: 建议 3-5 秒,减少误报
- 特殊场景: 设为 0 表示不限制时长
Q3: 为什么不启用 STGCN 时误报率高?
A: 仅用姿态校验时:
- 只能基于单帧判断 (宽高比、头髋位置)
- 无法区分弯腰、蹲下、坐下等动作
- 容易受遮挡、视角影响
建议生产环境启用 STGCN以获得更高准确率。
Q4: 边缘区域过滤的作用?
A: 画面边缘的摔倒通常是:
- 正在上下车/上下楼梯
- 进出监控区域
- 非事故性倒地
通过过滤边缘区域,可减少大量误报。
Q5: 算力优化是如何实现的?
A: 多层按需调用机制:
- 第一层: 仅 fall 类触发后续流程 (95%+目标直接跳过)
- 第二层: STGCN 严格触发条件 (历史帧数、可疑次数等)
- 第三层: 异步执行 + 冷却机制 + 评估次数限制
- 懒加载: 关键点只在需要时提取并缓存
相比每帧全量调用 Pose 和 STGCN,算力消耗降低 80%+。
总结
本算法采用检测→跟踪→RTMPose 关键点→STGCN 确认→时长累计→多重过滤的级联方案,核心设计思想:
- 分层过滤: 从粗到细逐步筛选,减少无效计算
- 按需计算: 仅 fall 类触发 Pose 和 STGCN,算力节约 80%+
- 时序分析: STGCN 基于 60 帧序列识别摔倒动作,准确率高
- 状态持续: 跟踪器维持目标状态,支持跨帧累计倒地时长
- 异步评估: STGCN 异步执行,不阻塞主流程
- 多重保障: 边缘过滤、工作人员识别等多重过滤
本算法适合地铁、学校等公共场所的平地摔倒行为实时监测场景,能够有效平衡响应速度与误报率。