期中总结:从神经元到 GPT------AI 架构全景回顾(Version B)
📚 《从零到一造大脑:AI架构入门之旅》专栏
专栏定位 :面向中学生、大学生和 AI 初学者的科普专栏,用大白话和生活化比喻带你从零理解人工智能
本系列共 42 篇,分为八大模块:
- 📖 模块一【AI 基础概念】(3 篇):AI/ML/DL 关系、学习方式、深度之谜
- 🧠 模块二【神经网络入门】(4 篇):神经元、权重、激活函数、MLP
- 🏗️ 模块三【深度学习核心】(6 篇):损失函数、梯度下降、反向传播、过拟合、Batch/Epoch/LR
- 🎯 模块四【注意力机制】(5 篇):从 Attention 到 Transformer
- 🔬 模块五【NCT 与 CATS-NET 案例】(8 篇):真实架构演进全记录
- 🔄 模块六【架构融合方法】(6 篇):如何设计混合架构
- ⚙️ 模块七【参数调优实战】(6 篇):学习率、正则化、超参数搜索
- 🚀 模块八【综合应用展望】(4 篇):未来趋势与职业规划
本文是模块四第 6 篇(期中总结),带你回顾前四模块的核心知识。
👨💻 作者简介:NeuroConscious Research Team,一群热爱 AI 科普的研究者,专注于神经科学启发的 AI架构设计与可解释性研究。理念:"再复杂的概念,也能用大白话讲清楚"。
💻 项目地址 :https://github.com/wyg5208/nct.git🌐 官网地址 :https://neuroconscious.link
📝 作者 CSDN :https://blog.csdn.net/yweng18
📦 NCT PyPI :https://pypi.org/project/neuroconscious-transformer/
⭐ 欢迎 Star⭐、Fork🍴、贡献代码🤝
📌 本文核心比喻 :盖一座"AI大厦",从地基到封顶
⏱️ 阅读时间 :约 25 分钟
🎯 学习目标:串联核心概念,建立 AI 架构全景图
📝 文章摘要
本文是专栏的期中总结,用"盖大楼"的比喻,系统回顾前 18 篇文章的核心知识。从神经元(砖块)到 Transformer(大厦结构),从损失函数(验收标准)到注意力机制(设计师的智慧),帮你搭建完整的 AI 架构认知框架。最后通过一个简化的 GPT 架构图,展示如何把"砖块"组合成"智能大厦"。
🎯 你需要先了解
阅读本文前,建议你:
-
✅ 已学过前 18 篇文章(至少浏览过)
-
✅ 了解神经网络的基本概念
-
✅ 对 AI 架构有好奇心
如果还没读前文,可以从第一篇开始补读。
📖 正文
一、AI 大厦的四层结构

🏗️ AI 大厦 = 四层结构
第一层:地基(模块一)
└→ 什么是 AI、ML、DL,它们之间的关系
第二层:砖块(模块二)
└→ 神经元、权重、激活函数、MLP
第三层:钢筋水泥(模块三)
└→ 损失函数、梯度下降、反向传播、优化技巧
第四层:设计图纸(模块四)
└→ 注意力机制、Transformer
第五层:完整大厦(本期预告)
└→ 模块五开始:真实架构 NCT

二、第一层地基:AI 基本概念回顾
2.1 三兄弟的关系
┌────────────────────────────────────────────────────────────┐
│ AI/ML/DL 关系图 │
├────────────────────────────────────────────────────────────┤
│ │
│ ┌───────────────┐ │
│ │ AI │ 人工智能:让机器像人一样聪明 │
│ │ (Artificial │ │
│ │ Intelligence)│ │
│ └───────┬───────┘ │
│ │ 包含 │
│ ↓ │
│ ┌───────────────┐ │
│ │ ML │ 机器学习:让机器从数据中学习规律 │
│ │Machine Learning│ │
│ └───────┬───────┘ │
│ │ 包含 │
│ ↓ │
│ ┌───────────────┐ │
│ │ DL │ 深度学习:用深层神经网络自动学习特征 │
│ │ Deep Learning │ │
│ └───────────────┘ │
│ │
└────────────────────────────────────────────────────────────┘2.2 三种学习方式
┌────────────────────────────────────────────────────────────┐
│ 三种学习方式 │
├────────────────────────────────────────────────────────────┤
│ │
│ 📚 监督学习 = 有老师教 │
│ • 有标签的训练数据 │
│ • 例:考试题+标准答案 │
│ • 应用:图像分类、语音识别 │
│ │
│ 🔍 无监督学习 = 自己探索 │
│ • 没有标签,让机器自己发现规律 │
│ • 例:按兴趣自动分组 │
│ • 应用:聚类、降维 │
│ │
│ 🎮 强化学习 = 试错成长 │
│ • 做对了奖励,做错了惩罚 │
│ • 例:下棋、玩游戏 │
│ • 应用:游戏 AI、机器人控制 │
│ │
└────────────────────────────────────────────────────────────┘三、第二层砖块:神经网络基础
3.1 神经元 = AI 的最小单位
单个神经元的工作原理:
输入 x1 ──→ [w1] ──┐
│
输入 x2 ──→ [w2] ──→ ⊕ → [激活函数] → 输出 y
│ ↑
输入 x3 ──→ [w3] ──┘ │
│
偏置 b
公式:y = activation(w1*x1 + w2*x2 + w3*x3 + b)记忆口诀:
神经元,三步走:
加权求和加偏置,
激活函数来开门。3.2 激活函数 = 神经元的开关
┌────────────────────────────────────────────────────────────┐
│ 常见激活函数 │
├────────────────────────────────────────────────────────────┤
│ │
│ 🔌 ReLU(最常用) │
│ • 公式:y = max(0, x) │
│ • 特点:简单高效,防止梯度消失 │
│ • 类比:电灯开关,开就是1,关就是0 │
│ │
│ 📈 Sigmoid │
│ • 公式:y = 1/(1+e^(-x)) │
│ • 特点:输出0-1,概率解释 │
│ • 类比:百分比,比如70%相信 │
│ │
│ 🌊 Tanh │
│ • 公式:y = (e^x - e^(-x))/(e^x + e^(-x)) │
│ • 特点:输出-1到1,零居中 │
│ • 类比:温度计,可正可负 │
│ │
└────────────────────────────────────────────────────────────┘3.3 多层感知机 = 砖块垒成墙
MLP(多层感知机)结构:
输入层 隐藏层 1 隐藏层 2 输出层
│ │ │ │
○ ─────────→ ○ ─────────→ ○ ─────────→ ○
│ │ │ │
○ ─────────→ ○ ─────────→ ○ ─────────→ ○
│ │ │ │
○ ─────────→ ○ ─────────→ ○ ─────────→ ○
│ │ │ │
特点:
• 多层结构:输入 → 隐藏 → 输出
• 每层多个神经元:并行处理
• 全连接:每层都连到下一层四、第三层钢筋水泥:训练核心
4.1 损失函数 = 验收标准
损失函数 = 预测值和真实值的差距
┌────────────────────────────────────────────────────────────┐
│ 常见损失函数 │
├────────────────────────────────────────────────────────────┤
│ │
│ 🎯 MSE(均方误差)------ 回归任务 │
│ • 公式:L = (预测值 - 真实值)² │
│ • 类比:射击打靶,离靶心越远分数越低 │
│ │
│ 📊 Cross-Entropy ------ 分类任务 │
│ • 公式:L = -Σ 真实概率 × log(预测概率) │
│ • 类比:考试选择题,选错得0分,选对得满分 │
│ │
│ 🏆 Hinge Loss ------ SVM │
│ • 公式:L = max(0, 1 - y*预测) │
│ • 类比:拔河比赛,赢了得1分,输了得0分 │
│ │
└────────────────────────────────────────────────────────────┘4.2 梯度下降 = 蒙眼下山
梯度下降 = 找到最低点的过程
山峰 ⛰️
↑
│ *
│ * *
│ * * ← 当前所在
│ * *
│* *
└──────────→ 水平方向
蒙眼人的策略:
1. 脚踩地面,感受坡度(计算梯度)
2. 向最陡的下坡方向迈一步(梯度下降)
3. 重复直到感觉不到下坡(到达最低点)
数学表达:
新位置 = 旧位置 - 学习率 × 梯度关键公式:
θ_new = θ_old - α * ∂L/∂θ
其中:
• θ = 参数(权重)
• α = 学习率(步长)
• ∂L/∂θ = 损失函数的梯度4.3 反向传播 = 责任追溯
反向传播 = 从输出倒推到输入,计算每个参数的责任
前向传播(做预测):
输入 → [层1] → [层2] → [层3] → 输出
反向传播(算责任):
输出 ← [层3责任] ← [层2责任] ← [层1责任] ← 输入
链式法则:
∂L/∂θ = ∂L/∂y × ∂y/∂z × ∂z/∂θ
类比:公司出了质量问题,要追溯责任:
CEO → 总监 → 经理 → 员工4.4 过拟合 vs 欠拟合 = 背答案 vs 没学会
┌────────────────────────────────────────────────────────────┐
│ 拟合状态三兄弟 │
├────────────────────────────────────────────────────────────┤
│ │
│ 📝 欠拟合 = 压根没学会 │
│ • 训练集、测试集表现都不好 │
│ • 模型太简单,学得太少 │
│ • 解决方案:加深网络、增加特征 │
│ │
│ ✅ 正常拟合 = 学会了 │
│ • 训练集、测试集表现都不错 │
│ • 模型复杂度适中 │
│ │
│ 📖 过拟合 = 背答案 │
│ • 训练集表现很好,测试集表现差 │
│ • 模型太复杂,学得太死 │
│ • 解决方案:正则化、Dropout、数据增强 │
│ │
└────────────────────────────────────────────────────────────┘4.5 Batch、Epoch、Learning Rate
训练三要素 = 三把钥匙
🔑 Batch(批次大小)
• 一次喂多少数据给模型
• 小-batch:快但不稳
• 大-batch:稳但慢
• 类比:一口吃一个馒头 vs 一口吃半个馒头
🔑 Epoch(轮次)
• 把所有数据都看一遍叫一个Epoch
• 需要多个Epoch才能学会
• 类比:考试前要复习好几轮
🔑 Learning Rate(学习率)
• 决定每一步迈多大
• 太大:跳过最低点(震荡)
• 太小:爬行太慢
• 类比:下山步子太大容易摔倒,太小又太慢
典型配置:
• Batch = 32
• Epoch = 10-100
• Learning Rate = 0.001五、第四层设计图纸:注意力机制
5.1 从 RNN 到 Transformer 的演进
架构演进时间线:
RNN 时代 Transformer 时代
(1990s) (2017-至今)
│ │
├─ 序列处理 ├─ 全局注意力
├─ 顺序计算 ├─ 并行计算
├─ 长距离依赖困难 ├─ 长距离直接相连
├─ 梯度消失 ├─ 稳定训练
│ │
└─ 2017: Attention Is All You Need
Transformer 诞生
关键里程碑:
• 2017:Transformer 论文发布
• 2018:BERT(Encoder)
• 2019:GPT-2(Decoder)
• 2020:GPT-3(1750亿参数)
• 2022:ChatGPT
• 2023-2024:GPT-4、多模态5.2 注意力机制核心公式
注意力 = 关注重点的能力
┌────────────────────────────────────────────────────────────┐
│ Attention 计算流程 │
├────────────────────────────────────────────────────────────┤
│ │
│ Step 1: 准备 Q、K、V │
│ Q(Query)= 我要查询什么 │
│ K(Key) = 我有什么关键词 │
│ V(Value)= 关键词对应的内容 │
│ │
│ Step 2: 计算相似度 │
│ score = Q · K^T / √d │
│ (点积后缩放,防止数值过大) │
│ │
│ Step 3: 归一化 │
│ weight = softmax(score) │
│ (把所有分数变成0-1的概率分布) │
│ │
│ Step 4: 加权求和 │
│ output = weight × V │
│ (按重要性加权,得到最终结果) │
│ │
└────────────────────────────────────────────────────────────┘
完整公式:
Attention(Q, K, V) = softmax(QK^T / √d_k) × V5.3 自注意力 = 词与词对话
自注意力的核心:每个词都可以看所有词
输入句子:"The cat sat on the mat"
可视化:
The cat sat on the mat
──────────────────────────────────────
The 0.1 0.2 0.1 0.1 0.1 0.5 ← mat 最重要
cat 0.1 0.1 0.2 0.1 0.1 0.5 ← 和 sat、mat 关联
sat 0.1 0.4 0.1 0.2 0.1 0.2 ← cat 是主语
on 0.1 0.1 0.1 0.1 0.2 0.5 ← mat 是地点
the 0.2 0.1 0.1 0.1 0.1 0.5 ← mat 最重要
mat 0.1 0.2 0.1 0.3 0.1 0.2 ← on 是介词
类比:开会讨论,每个人都要听所有人的意见5.4 多头注意力 = 多个专家同时思考
多头注意力 = 8个脑袋同时工作
每个头关注不同方面:
Head 1(语法):The → cat(主语关系)
Head 2(语义):cat → sat(主谓关系)
Head 3(语义):sat → on(谓宾关系)
Head 4(语法):on → mat(介宾关系)
Head 5(位置):on → the(位置接近)
Head 6(位置):the → mat(位置接近)
Head 7(长距离):The → mat(首尾呼应)
Head 8(其他):...
最后拼接:
[Head1输出 | Head2输出 | ... | Head8输出] → 线性变换 → 输出
类比:装修房子
• 木工负责地板
• 电工负责布线
• 水管工负责水管
• 最后组装成完整房子5.5 Transformer 架构全景图
完整 Transformer 架构:
输入
│
┌──────────┴──────────┐
↓ ↓
┌──────────────┐ ┌──────────────┐
│ Encoder │ │ Decoder │
│ (编码器) │ ───→ │ (解码器) │
└──────────────┘ └──────────────┘
│ │
│ ┌───────────┘
│ ↓
│ ┌──────────────┐
│ │ Output │
│ │ (输出) │
│ └──────────────┘
│ │
└─────────┘
│
输出
Encoder:理解输入(如 BERT)
• 多层 Self-Attention + FFN
• 双向理解上下文
Decoder:生成输出(如 GPT)
• Self-Attention + Cross-Attention
• 自回归生成下一个词六、知识串联:迷你 GPT 实战
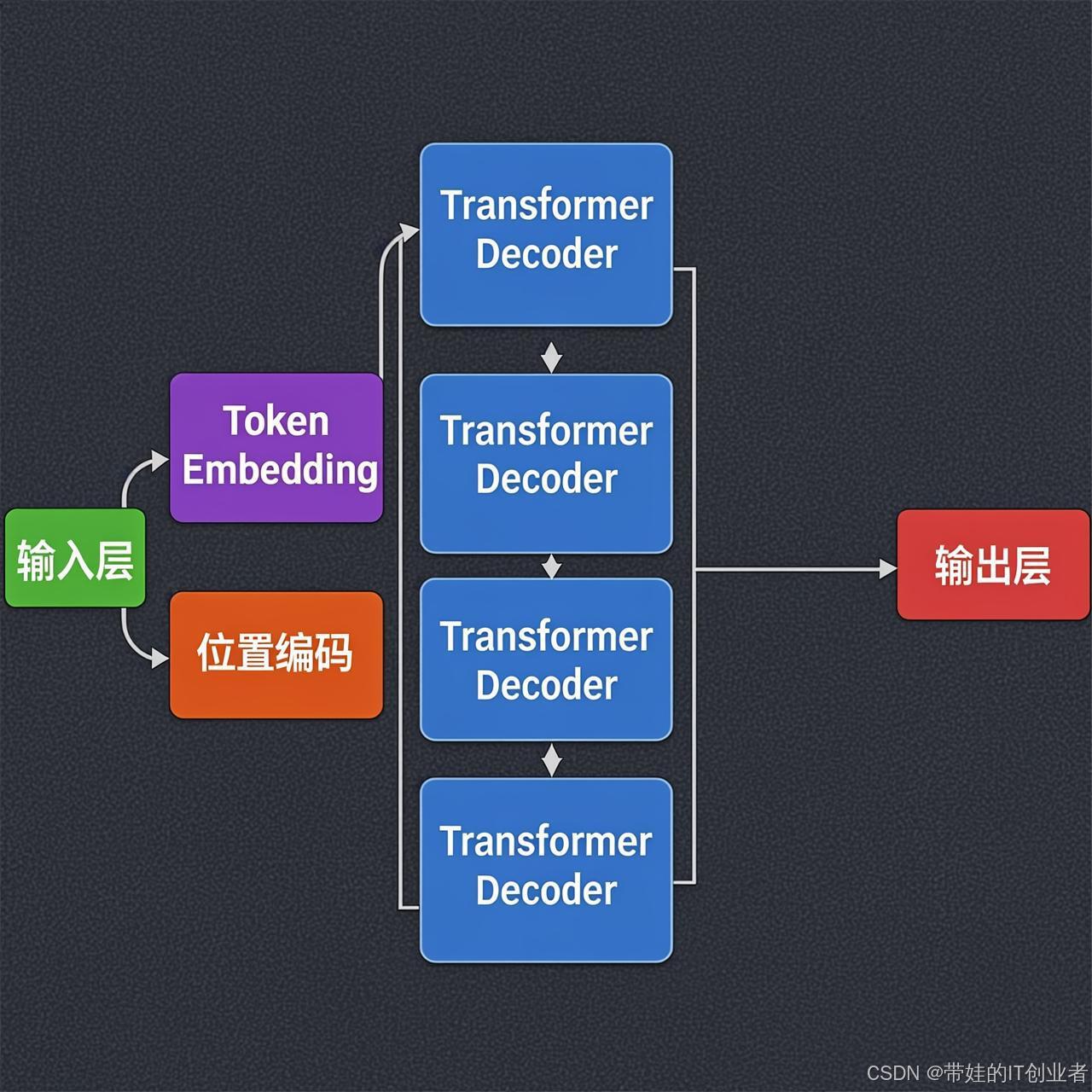
6.1 GPT 的核心组件
GPT 架构简化版:
┌────────────────────────────────────────────────────────────┐
│ Mini GPT 结构 │
├────────────────────────────────────────────────────────────┤
│ │
│ 输入:"今天天气真" │
│ │ │
│ ↓ │
│ ┌─────────────────┐ │
│ │ Token Embedding│ ← 词转向量 │
│ │ + Position │ ← 位置编码 │
│ │ Encoding │ │
│ └────────┬────────┘ │
│ ↓ │
│ ┌─────────────────────────────────────────┐ │
│ │ Transformer Decoder 层 │ ×N 层 │
│ │ ┌─────────────────────────────────────┐ │ │
│ │ │ Masked Self-Attention │ │ │
│ │ │ (只能看前面的词) │ │ │
│ │ └─────────────────────────────────────┘ │ │
│ │ ↓ │ │
│ │ ┌─────────────────────────────────────┐ │ │
│ │ │ Feed Forward Network │ │ │
│ │ │ (逐位前馈网络) │ │ │
│ │ └─────────────────────────────────────┘ │ │
│ └─────────────────────────────────────────┘ │
│ ↓ │
│ ┌─────────────────┐ │
│ │ Linear + Softmax│ ← 预测下一个词 │
│ └────────┬────────┘ │
│ ↓ │
│ 输出:预测下一个词是"好" │
│ │
└────────────────────────────────────────────────────────────┘6.2 GPT 训练过程
GPT 训练 = 预测下一个词
训练数据:"今天天气真好"
训练方式:
Step 1: 输入"今天天气真" → 预测"好"
Step 2: 输入"今天天气真好" → 预测"<EOS>"
...
损失函数 = Cross-Entropy
• 目标:让"好"的概率最大化
• 自监督学习,不需要人工标注6.3 为什么 GPT 这么强?
GPT 强大的秘密:
┌────────────────────────────────────────────────────────────┐
│ GPT 成功要素 │
├────────────────────────────────────────────────────────────┤
│ │
│ 1️⃣ 大量数据 │
│ • 互联网海量文本 │
│ • 学会语言规律 │
│ │
│ 2️⃣ 大量参数 │
│ • GPT-1: 1.1亿 │
│ • GPT-2: 15亿 │
│ • GPT-3: 1750亿 │
│ • 足够容量记忆复杂模式 │
│ │
│ 3️⃣ Transformer 架构 │
│ • 并行训练效率高 │
│ • 长距离依赖建模能力强 │
│ │
│ 4️⃣ 下一个词预测 │
│ • 自监督学习,充分利用无标签数据 │
│ • 学会语言的一切规律 │
│ │
│ 5️⃣ 上下文学习 │
│ • 可以从少量示例中学习新任务 │
│ • 不需要重新训练 │
│ │
└────────────────────────────────────────────────────────────┘七、前四模块知识地图
┌─────────────────────────────────────────────────────────────────────────┐
│ AI 架构知识地图 │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ ┌───────────────┐ │
│ │ 模块一 │ │
│ │ AI/ML/DL │ │
│ │ 基础概念 │ │
│ └───────┬───────┘ │
│ ↓ │
│ ┌───────────────┐ │
│ │ 模块二 │ │
│ │ 神经元/权重 │ │
│ │ /激活函数 │ │
│ └───────┬───────┘ │
│ ↓ │
│ ┌───────────────┐ │
│ │ 模块三 │ │
│ │ 损失/梯度/ │ │
│ │ 反向传播 │ │
│ └───────┬───────┘ │
│ ↓ │
│ ┌───────────────┐ │
│ │ 模块四 │ │
│ │ 注意力/ │ │
│ │ Transformer │ │
│ └───────┬───────┘ │
│ ↓ │
│ ┌───────────────┐ │
│ │ 模块五 │ │
│ │ NCT 真实架构 │ ← 下一模块 │
│ │ (预告) │ │
│ └───────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────────────┘八、常见问题解答
Q1:为什么要多层网络?一层不够吗?
答:一层网络表达能力有限。多层网络可以:
-
逐层抽象特征(边缘→形状→物体→概念)
-
用更少参数表达更复杂函数
-
类比:一栋楼比一块砖能做的事多
Q2:ReLU 负半轴为 0,会不会丢失信息?
答:不会。
-
负值通常代表"不重要的特征"
-
ReLU 让网络学会"忽略"这些
-
保留正值(重要特征)更有效
Q3:为什么 Transformer 替代了 RNN?
答:Transformer 有三大优势:
-
并行:所有位置同时计算
-
长依赖:直接相连,无信息衰减
-
稳定:梯度更稳定,训练更容易
Q4:GPT 和 BERT 有什么区别?
答:
┌────────────────────────────────────────────────────────────┐
│ GPT vs BERT │
├────────────────────────────────────────────────────────────┤
│ │
│ GPT(生成式预训练) │
│ • Decoder-only │
│ • 单向注意力(只能看前面) │
│ • 自回归生成 │
│ • 适合:文本生成、对话 │
│ │
│ BERT(双向编码器表示) │
│ • Encoder-only │
│ • 双向注意力(看前后) │
│ • 填空任务 │
│ • 适合:文本分类、NER、问答 │
│ │
└────────────────────────────────────────────────────────────┘💡 一句话总结
🎯 核心结论
AI 大厦 = 砖块(神经元) + 水泥(训练) + 图纸(注意力)
从简单到复杂,从理论到实践,构建你的 AI 知识体系。
记忆口诀:
AI 学习三兄弟,监督无监督强化。
神经元是砖块,激活函数来开门。
梯度下降找最低,反向传播算责任。
注意力机制最牛,Transformer 盖高楼。✍️ 课后作业
连线题(每题 10 分)
将左边概念与右边解释连线:
1. 神经元 A. 预测值和真实值的差距
2. 损失函数 B. 神经元的开关
3. 激活函数 C. AI 的最小单位
4. 梯度下降 D. 每个词看所有词
5. 自注意力 E. 蒙眼下山找最低点答案:1-C, 2-A, 3-B, 4-E, 5-D
画图题(20 分)
用箭头和框图画出 Transformer 的基本结构,标注 Encoder 和 Decoder。
📝 下一篇预告
🚀 下一篇文章
题目 :NCT 是什么------让 AI 拥有意识的尝试
我们会学到:
- NCT 框架的设计理念
- 如何将神经科学融入 AI
- NCT vs 普通 Transformer 的区别
📌 本文属《从零到一造大脑:AI架构入门之旅》专栏第四模块第六篇(期中总结)
作者:NeuroConscious Research Team
更新时间:2026 年 3 月
版本号:V1.0-B(图文并茂版)