文章目录
- [1 概述](#1 概述)
- [2 网络结构](#2 网络结构)
-
- [2.1 特征提取(蒸馏)](#2.1 特征提取(蒸馏))
- [2.2 成本过滤(蒸馏)](#2.2 成本过滤(蒸馏))
- [2.3 视差细化(剪枝)](#2.3 视差细化(剪枝))
- [3 伪标签制作](#3 伪标签制作)
- [4 效果](#4 效果)
- [5 buildGwcVolume的c++实现](#5 buildGwcVolume的c++实现)
- 参考文献
1 概述
立体匹配领域有两条 不同的研究路径:
(1)计算机视觉基础模型的兴起推动立体匹配研究走向强大的零样本泛化。这种领先的零样本网络利用了来自计算密集型 基础模型的丰富先验,例如 DepthAnythingV2 或 DINO 模型。他们采用计算密集型架构,例如Disparity Transformer,来对远程上下文进行自注意力。迄今为止,此类限制阻碍了它们在任何受延迟限制的系统中的部署。
(2)实际应用的不可协商的约束要求计算高效的性能。为此类实时推理设计的架构 通过依赖轻量级骨干网、2D 卷积层和局部迭代细化模块来实现高帧速率。由于依赖于每个域的微调,此类方法很难推广。由于难以大规模获得所需的密集、高质量的GT深度,因此无法将这种有效的方法用作在野外环境中运行的具身智能的现成解决方案。
本文提出了 Fast-FoundationStereo,这是一种新颖的立体匹配架构,可以实现强大的零样本泛化和实时推理,并具有不同的精度与速度权衡,如图1-1所示。
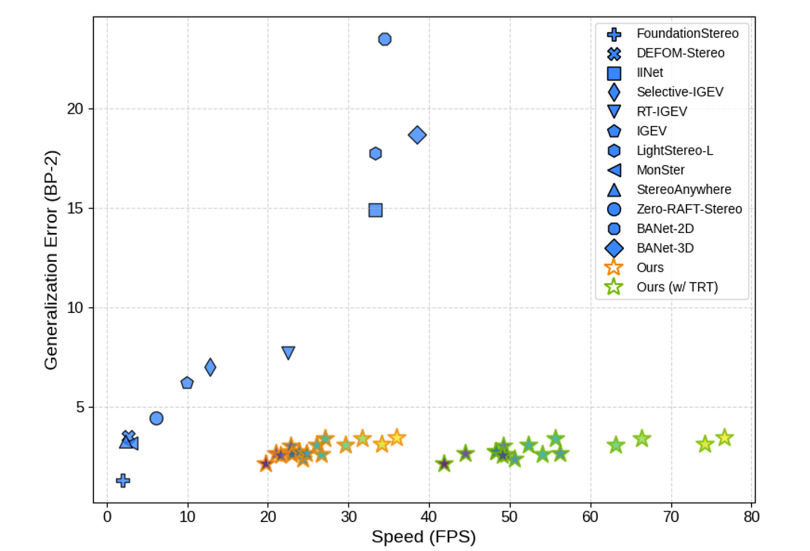
图1-1 不同SOTA模型的速度与精度对比(3090 GPU)
Fast-FoundationStereo可以简单概括为基于分而治之的蒸馏和剪枝 加速模型,并通过构造伪标签 的方式在额外的补充数据进行训练,促进知识蒸馏。
注意,本文的主要目的是让读者对Fast-FoundationStereo有哪些改动有一个大致的了解,因此不会对某些细节进行过多解释。
2 网络结构
本文基于FoundationStereo,将网络结构分为特征提取 、成本过滤 和视差细化 三个关键步骤,并分别采用不同的策略进行蒸馏和剪枝,称其为"分而治之"。
经过本文的加速之后,Fast-FoundationStereo各个模块相比于FoundationStereo的耗时减少可见图2-1。
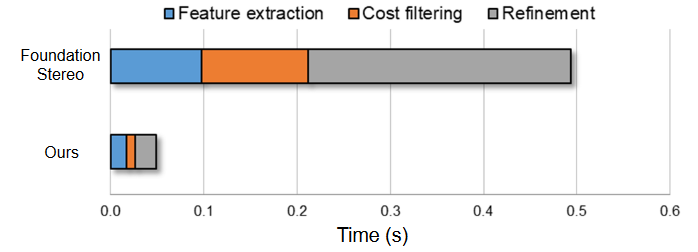
图2-1 模块耗时对比图
2.1 特征提取(蒸馏)
FoundationStereo的特征提取部分可以简单概括为DepthAnything V2和一个用于将单目特征适配到双目特征的适配器STA组成,这是一个双模块结构,详情可以参见我的另一篇博客。作者利用知识蒸馏 将 FoundationStereo 主干中的双模块替换为单个学生模块。选择这种方法是因为它与网络结构无关,并且允许构建在 ImageNet 上研究的完善的特征主干上。
作为替代方案,也考虑了模型剪枝,但它有两个缺点:
(1)需要保留双模块,而双模块受到其底层 ViT 计算瓶颈的限制;
(2) 如果不对互联网规模的图像进行重新训练,任何准确性的下降都将难以恢复。
在蒸馏过程中,FoundationStereo 的特征提取模块被冻结并用于预测多级特征金字塔 f ˉ ( i ) \bar{f}(i) fˉ(i),学生模型经过训练以通过 MSE 损失进行匹配 。在通道尺寸不匹配的情况下,添加线性投影层。尽管特征提取器仅采用单个图像作为输入,但在每个训练批次中都包含两个立体图像以保留统计相似性。
为了提供一系列具有不同速度精度权衡的立体匹配模型,训练了特征提取器的多种变体。图2-2可视化了提取特征的示例,表明它们捕获了相似的高频边缘和相对深度。

图2-3 特征可视化结果对比
那么特征提取的模型结构变成了什么样子呢?相比于FoundationStereo,仍旧保留了edgenext_small的部分,删除了dino的部分,并对self.conv4进行了简化。下图2-4展示了FoundationStereo(左)和FastFoundationStereo(右)特征提取部分的差异。
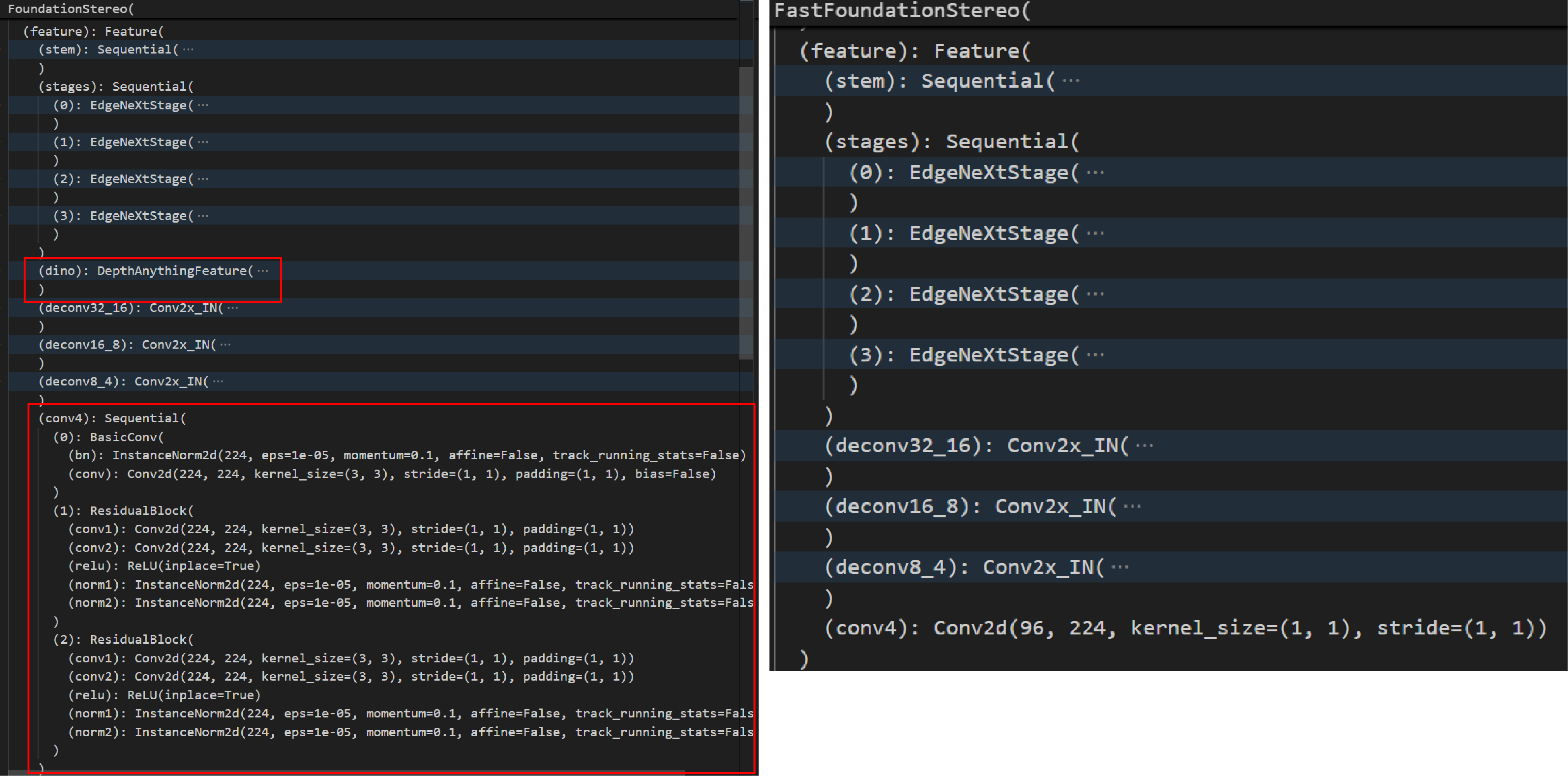
图2-4 FDS和Fast-FDS的self.feature部分差异
值得注意的是,特征抽取不光只有self.feature,还有抽取用于ConvGRU所需特征的上下文特征编码器self.cnet,这部分也进行了简化,如下图2-5所示。
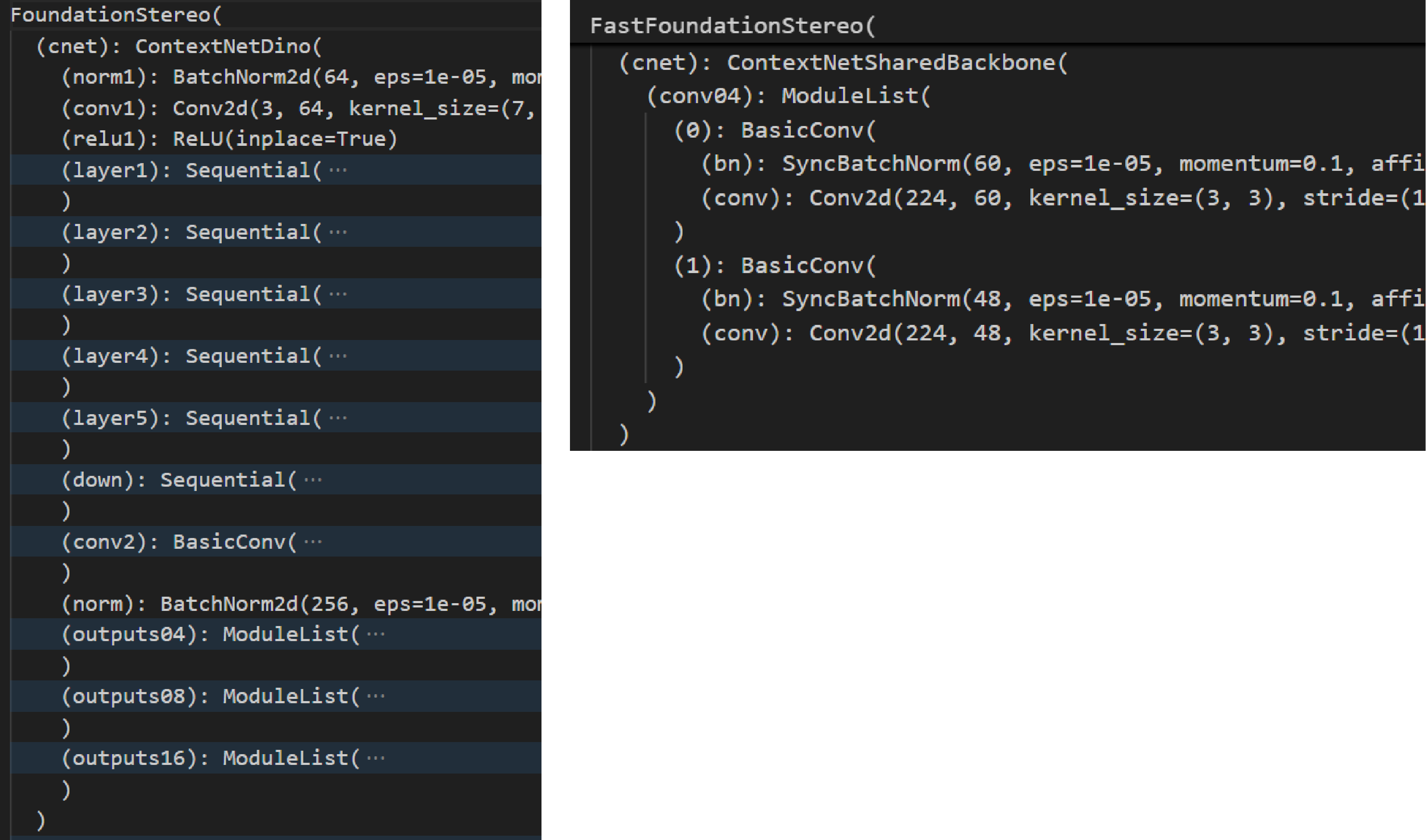
图2-5 FDS和Fast-FDS的self.cnet部分差异
2.2 成本过滤(蒸馏)
成本过滤部分就是代码中的self.cost_agg函数,这部分的输入 V C V_C VC的维度已经更小,作者认为直接修剪成本过滤模块只会提高一些速度,但是导致严重性能下降。因此放弃了剪枝的策略。
作者也避免了直接知识蒸馏,因为它需要手动设计成本过滤模块替代方案,而与特征提取模块相比,这些替代方案的探索较少。作者最终利用神经架构搜索(NAS)来自动发现非直观的模块设计。
对于作者通过NAS进行模块设计,这里不做详细的介绍,感兴趣的读者可以查阅原文。简而言之,作者会通过块式候选构建 ,得到 C = C 1 ⋅ C 2 ⋅ ⋅ ⋅ C N C = C_1·C_2···C_N C=C1⋅C2⋅⋅⋅CN 可能的成本过滤模块候选集,然后分别进行搜索,每个块都被视为独立的网络进行监督,最终通过求解候选块的最优组合来找到学生成本过滤模块。
2.3 视差细化(剪枝)
给定初始视差图 d 0 d_0 d0(由过滤后的成本体预测)和隐藏特征(从上下文网络初始化),ConvGRU 模块逐步细化视差图。图2-3展示了依赖图和数据流。在每次迭代中,ConvGRU 模块都会消耗视差 d k − 1 d_{k−1} dk−1、 h k − 1 h_{k−1} hk−1 并预测它们的更新值 d k d_k dk、 h k h_k hk,从而产生循环依赖性。细化模块中的这种显着冗余促进了结构化剪枝的使用,这是一种简单而有效的技术,可以受益于 TensorRT 等 GPU 硬件加速技术。
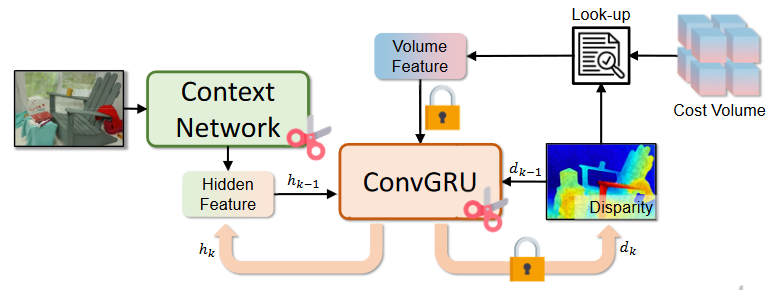
构建循环依赖图
结构化剪枝的第一步是识别层之间的相互依赖性,因为一层的深度或通道剪枝会改变馈送到相邻层的中间特征维度。除了可以通过跟踪计算流程自动构建的正常相邻层依赖关系之外,考虑到立体匹配中细化模块的独特属性,还引入了三个修剪约束:
(1)在ConvGRU模块中,预测视差图和凸上采样掩模的最终层保留固定的输出通道尺寸;
(2)在ConvGRU模块内,消耗 h k − 1 h_{k−1} hk−1的层的输入通道和输出 h k h_k hk的层的输出通道是相互依赖的,因此被联合剪枝;
(3)使用索引体特征的运动编码器保留固定的输入通道尺寸。
剪枝和再训练
为了确定要删除哪些层或通道,使用一阶泰勒展开来评估它们的重要性。具体来说,输入通过多次细化迭代端到端地前馈到完整的教师模型,并为细化模块累积梯度。对细化模块中每个参数的重要性进行全局排序 ,并对最不重要的 α \alpha α参数进行剪枝,其中 α ∈ ( 0 , 1 ) α \in (0, 1) α∈(0,1)是剪枝比率。修剪后,使用下式所示的损失重新训练端到端的细化模块(同时冻结教师模型的其余部分)以恢复性能。
L = ∑ k = 1 K γ K − k ∣ ∣ d k − d ˉ ∣ ∣ 1 + λ ∑ i = 1 L ∣ ∣ x i − x ˉ i ∣ ∣ 2 2 (2-1) L = \sum_{k=1}^K \gamma^{K-k}|| d_k - \bar{d} ||1 + \lambda \sum{i=1}^L || x_i - \bar{x}_i ||^2_2 \tag{2-1} L=k=1∑KγK−k∣∣dk−dˉ∣∣1+λi=1∑L∣∣xi−xˉi∣∣22(2-1)
其中 x i x_i xi 和 x ˉ i \bar{x}_i xˉi 是 L L L 层中每一层的每层潜在特征(分别是学生和教师); d ˉ \bar{d} dˉ 是真实视差; k k k是迭代次数; γ = 0.9 γ = 0.9 γ=0.9 指数级增加权重以监督迭代细化的视差; λ = 0.1 λ = 0.1 λ=0.1 为蒸馏目标的权重。初始视差监督被排除在外,因为它不受细化模块的影响。
3 伪标签制作
作者为了提高蒸馏模型的效果,额外将Stereo4D的数据补充到训练集。注意,Fast-FoundationStereo的训练数据包含了FoundationStereo的数据集,并多了基于Stereo4D制作的伪标签数据。
伪标签的制作过程如下图3-1所示,整过过程可以总结为
(1)给定来自Stereo4D的校正立体对
(2)FoundationStereo生成左图深度图和法向图
(3)UniDepth V2生成左图深度图和法向图
(4)计算法向图之间的余弦相似度,得到一致性掩码
(5)分割并屏蔽天空区域
(6)剩余一致性掩码对应的FoundationStereo的深度图作为伪标签
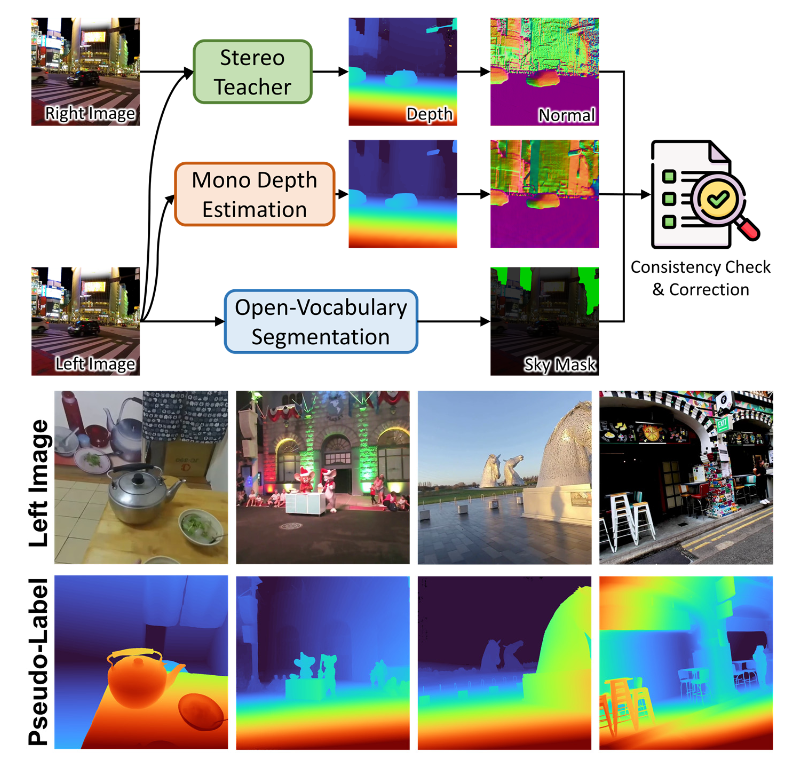
图3-1 伪标签制作流程图
生成的伪标签示例如下图3-2所示,其中一致性掩码占比较少的图片被过滤。
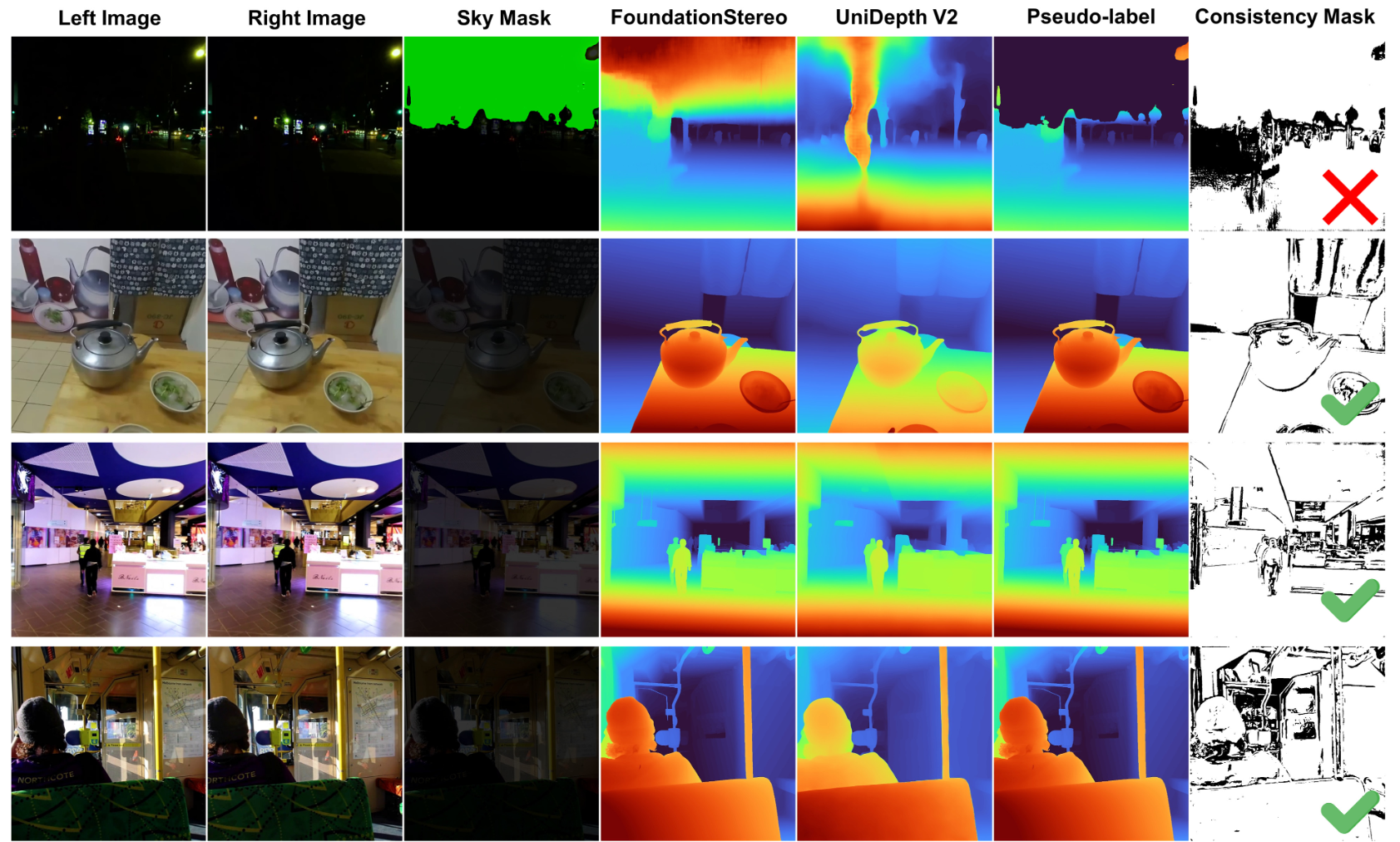
图3-2 伪标签示例图
4 效果
Fast-FoundationStereo的效果与FoundationStereo非常接近,也就是有着极佳的效果。
在公开数据集与其他SOTA模型的指标对比可见表4-1。
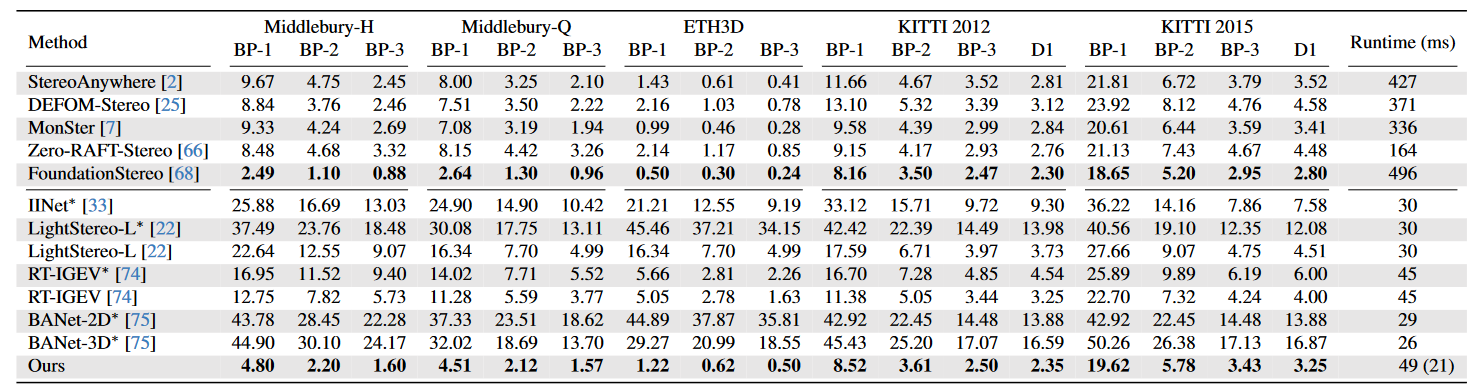
表4-1 SOTA模型指标对比
在公开数据集与其他SOTA模型的可视化效果对比可见图4-1。

图4-1 SOTA模型可视化结果对比
在非朗伯曲面,不同SOTA模型的指标对比可见表4-1。
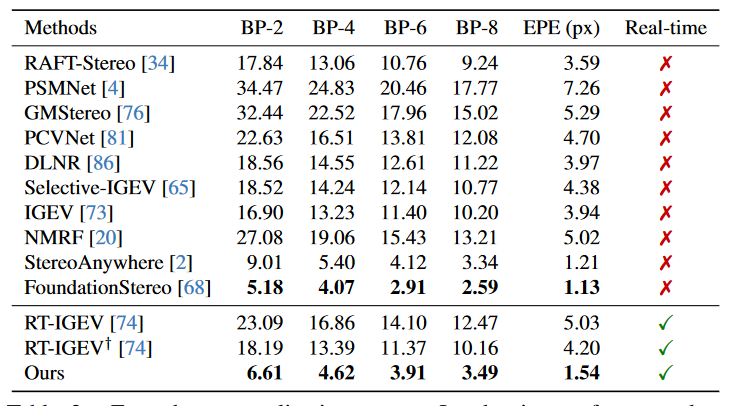
表4-2 非朗伯曲面SOTA模型指标对比
5 buildGwcVolume的c++实现
其实,许多读者应该并没有那么关心Fast-FoundationStereo是如何通过蒸馏和剪枝实现出来的,这其实是实验的结果加上一些人为的解释,也很少有人有能力去参考该方案对其他模型进行蒸馏和剪枝。
更多人关心的是我该如何使用该模型。官方的部署代码是通过python调用tensorrt的,并且由于group wise correlation无法简单地导出Onnx,将模型的特征抽取和得到GwcVolume后的处理导出为两个独立的onnx,并把构建GwcVolume的部分通过python调用triton来实现。但我们实际部署模型的时候,往往都是纯c++的,所以这里再额外分享一段使用c++和cuda写的构建GwcVolume的代码,希望对某些读者有一定帮助。
cpp
template<typename scalar_t>
__device__ __forceinline__ float to_float_device(scalar_t v) {
return static_cast<float>(v);
}
template<>
__device__ __forceinline__ float to_float_device<half>(half v) {
return __half2float(v);
}
template<typename scalar_t>
__global__ void gwc_volume_kernel(
const scalar_t* __restrict__ ref_feat, // [B, C, H, W]
const scalar_t* __restrict__ tar_feat, // [B, C, H, W]
float* __restrict__ output_volume, // [B, G, D, H, W]
int B, int C, int H, int W,
int max_disp, int num_groups, int K,
bool normalize)
{
const int idx = blockIdx.x * blockDim.x + threadIdx.x;
const int total_elems = B * num_groups * max_disp * H * W;
if (idx >= total_elems) return;
int tmp = idx;
const int w = tmp % W;
tmp /= W;
const int h = tmp % H;
tmp /= H;
const int d = tmp % max_disp;
tmp /= max_disp;
const int g = tmp % num_groups;
const int b = tmp / num_groups;
const int w_src = w - d;
if (w_src < 0 || b >= B || h >= H || w >= W || w_src >= W) {
output_volume[idx] = 0.0f;
return;
}
float acc = 0.0f;
float ref_norm_sq = 0.0f;
float tar_norm_sq = 0.0f;
const int base_c = g * K;
for (int k = 0; k < K; ++k) {
const int c_idx = base_c + k;
const int ref_idx = ((b * C + c_idx) * H + h) * W + w;
const int tar_idx = ((b * C + c_idx) * H + h) * W + w_src;
const float ref_val = to_float_device<scalar_t>(ref_feat[ref_idx]);
const float tar_val = to_float_device<scalar_t>(tar_feat[tar_idx]);
if (!isfinite(ref_val) || !isfinite(tar_val)) {
output_volume[idx] = 0.0f;
return;
}
acc += ref_val * tar_val;
if (normalize) {
ref_norm_sq += ref_val * ref_val;
tar_norm_sq += tar_val * tar_val;
}
}
if (normalize) {
constexpr float kEps = 1e-6f;
ref_norm_sq = fmaxf(ref_norm_sq, 0.0f);
tar_norm_sq = fmaxf(tar_norm_sq, 0.0f);
const float denom = sqrtf(ref_norm_sq) * sqrtf(tar_norm_sq) + kEps;
acc = (isfinite(denom) && denom > kEps) ? (acc / denom) : 0.0f;
}
output_volume[idx] = isfinite(acc) ? acc : 0.0f;
}
void TrtRunner::buildGwcVolume(
void* features_left, void* features_right, void* output_volume,
int batch, int channels, int height, int width,
int max_disp, int num_groups, bool normalize,
nvinfer1::DataType feature_dtype,
cudaStream_t stream)
{
assert(features_left != nullptr);
assert(features_right != nullptr);
assert(output_volume != nullptr);
assert(channels % num_groups == 0);
const int K = channels / num_groups;
const int total_elems = batch * num_groups * max_disp * height * width;
dim3 block(256);
dim3 grid((total_elems + block.x - 1) / block.x);
if (feature_dtype == nvinfer1::DataType::kHALF) {
gwc_volume_kernel<half><<<grid, block, 0, stream>>>(
static_cast<const half*>(features_left),
static_cast<const half*>(features_right),
static_cast<float*>(output_volume),
batch, channels, height, width,
max_disp, num_groups, K, normalize
);
} else if (feature_dtype == nvinfer1::DataType::kFLOAT) {
gwc_volume_kernel<float><<<grid, block, 0, stream>>>(
static_cast<const float*>(features_left),
static_cast<const float*>(features_right),
static_cast<float*>(output_volume),
batch, channels, height, width,
max_disp, num_groups, K, normalize
);
} else {
throw std::runtime_error("Unsupported feature dtype for GWC volume");
}
cudaError_t err = cudaGetLastError();
if (err != cudaSuccess) {
std::cerr << "GWC kernel launch failed: " << cudaGetErrorString(err) << std::endl;
throw std::runtime_error("GWC kernel launch failed");
}
}参考文献
1 Fast-FoundationStereo: Real-Time Zero-Shot Stereo Matching