前言
循环神经网络RNN(Recurrent Neural Network)是一种专门用于处理序列数据的神经网络,与传统的前馈神经网络,如全连接网络,卷积网络不同,RNN具有循环连接,允许信息从上一个时间步,传递到下一个时间步,这种结构使得 RNN 能够"记住"过去的信息,并根据当前输入和记忆共同决定输出,可以运用于NLP,时间序列预测,语言识别和音乐生成当中
词嵌入层
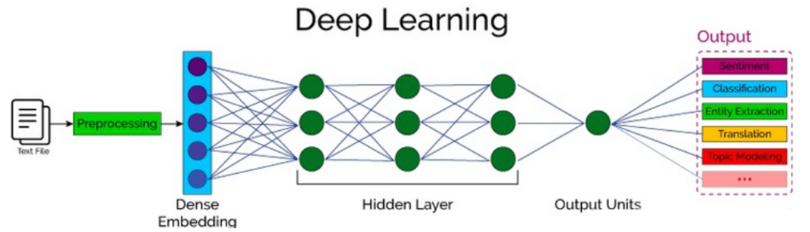
1. 核心作用
词嵌入层的核心是词→索引→低维向量 的映射,将文本词汇转换为低维稠密的数值向量,让文本从 "非结构化" 转为 "结构化数值",为 RNN 处理序列文本奠定基础。解决了传统编码(如 One-Hot)高维稀疏、难以学习的问题。
本质是用固定维度的向量(如 128 维)描述一个词的多维度特征(语义、词性、褒贬义、流行度等),这些特征由模型训练自动学习,而非人工定义
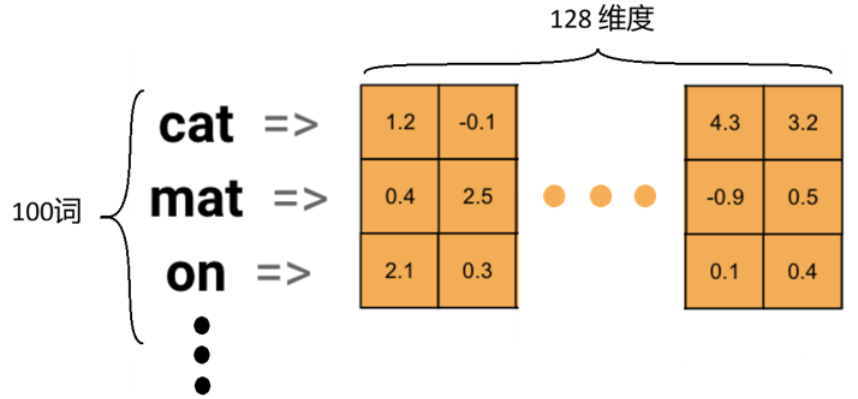
2. 词嵌入在RNN中的作用
- 输入表示:把文字转为神经网络可处理的数字向量;
- 降维:将几万维的 One-Hot 编码压缩为 50~300 维的稠密向量;
- 捕捉语义相似性:训练后,语义相近的词在向量空间中距离更近(余弦相似度高),让模型具备语义泛化能力。
3. 词嵌入工作流程
- 文本分词:将输入文本拆分为独立词汇(如中文用 jieba 分词)构建词库;
- 文字转索引:为词库中每个词分配唯一索引,构建词 - 索引映射(词表);
- 生成词向量 :通过词嵌入层将词汇索引映射为低维稠密词向量(初始可随机初始化或加载预训练词向量如 Word2Vec/GloVe,训练中可微调);
- 输入RNN:将词向量作为 RNN 的输入,进行序列处理。
4. PyTorch中的词嵌入层API
nn.Embedding(num_embeddings, embedding_dim)
num_embeddings:词库中词汇的总数量;embedding_dim:每个词对应的向量维度(如 4、128)。
python
import torch
import torch.nn as nn
import jieba
text = '北京冬奥的进度条已经过半,不少外国运动员在完成自己的比赛后踏上归途。'
words = jieba.lcut(text) # 分词
unique_words = list(set(words)) # 词库去重
embed = nn.Embedding(len(unique_words), 4) # 构建词嵌入层
# 遍历输出每个词的词向量
for i, word in enumerate(unique_words):
# 将输入i转为张量,通过嵌入层生成对应的词向量
word_vec = embed(torch.tensor(i))
print(word, word_vec)循环网络层
1. RNN网络原理
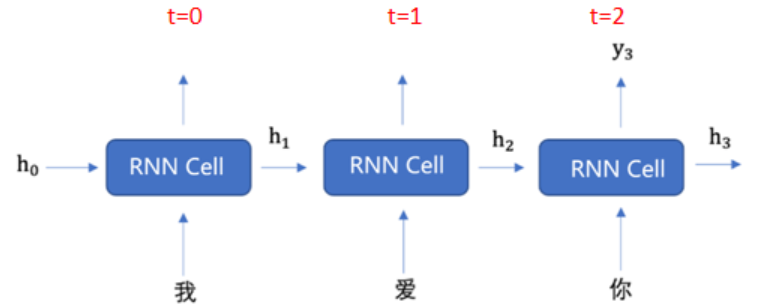
文本具有序列关系("我爱你"顺序颠倒意思不同),需要网络记住历史信息。针对序列数据的时序依赖特性 ,通过隐藏状态(h) 实现 "记忆功能",隐藏状态会在时间步之间传递,携带历史信息,结合当前时间步的输入,更新记忆并生成输出。
2. 核心特点
- 看似有多个 Cell,实际只有一个 Cell 被重复使用,所有时间步共享权重;
- 每个时间步做 3 件事:接收当前输入→更新隐藏状态(记忆)→给出当前输出。
3. 隐藏状态(Hidden State)作用
-
定义 :隐藏状态 ht 是一个向量,它总结了从序列开始到当前时间步 t 的所有历史信息,可以在时间步间传递。
-
三大作用:
-
- 记忆功能:存储序列的历史信息,传递到下一个时间步;
- 上下文理解:结合历史与当前输入,理解序列上下文;(例如:在"我喜欢吃___"中,隐藏状态包含了"喜欢"的信息,有助于预测"苹果"而非"汽车")。
- 连接不同时间步:通过循环连接,将各个时间步串联起来,使网络能够处理任意长度的序列。
4. 单个 RNN Cell(细胞/单元) 的工作
每个时间步做三件事:
- 接收当前输入 xt
- 更新隐藏状态(记忆)ht
- 给出输出 yt(可选)
4.1 内部:更新隐藏状态(核心,仅负责记忆更新)
当前时间步输入xt + 前一时刻隐藏状态ht−1 → 线性融合(全连接)→ tanh 激活 → 新隐藏状态ht
公式核心为:
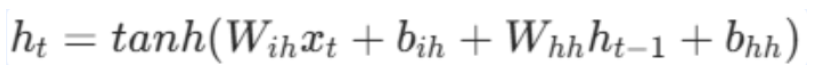
注释:
-
Wih / bih:表示输入数据的权重 / 偏置
-
Whh / bhh:表示输入隐藏状态的权重 / 偏置
-
ht-1:表示输入隐藏状态
-
ht:表示输出隐藏状态
-
tanh 激活:将隐藏状态值映射到 -1,1,保证数值稳定性。
4.2 外部:计算当前输出(用于任务预测)
当前隐藏状态ht → 全连接层 → 输出yt,公式为:
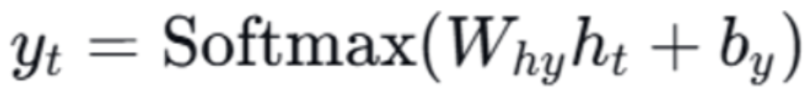
注释:
yt:对应词库中每个词的得分,经 softmax 归一化后为预测概率,概率最大的词即为当前时间步的预测结果;
Why/by:隐藏状态到输出的权重 / 偏置。
5. 循环结构
- RNN 在时间上展开后看似有很多个神经元,但实际上只有一个 Cell,它在每个时间步被重复调用。
- 每个时间步 Cell 的输入:
当前输入 xt + 上一时刻隐藏状态 ht−1 - 每个时间步 Cell 的输出:
当前隐藏状态 ht + 当前输出 yt(yt是可选项)
6. 任务类型
根据输入输出的序列特性,适配不同任务,核心分两类:
- 序列到序列(Seq2Seq):输入和输出都是序列,每个时间步的输出都重要(如机器翻译、文本生成);
- 序列到单值(Seq2Vec):输入是序列,仅最后一个时间步的输出重要(如情感分析、视频内容分类)。
7. PyTorch RNN API
7.1 构造函数
rnn = nn.RNN(input_size, hidden_size, num_layers)-
input_size:每个输入词的向量维度(例如词嵌入维度128) -
hidden_size:隐藏状态 h 的维度(记忆容量) -
num_layers:RNN层数(堆叠层数,越多理解越深但计算成本高)
7.2 输入数据格式
x:(seq_len, batch, input_size)
句子长度(时间步数),批量大小,词向量维度
h0:(num_layers, batch, hidden_size)
初始隐藏状态(通常全0)
7.3 输出数据格式
output:(seq_len, batch, hidden_size)
每个时间步最后一层的隐藏状态
hn:(num_layers, batch, hidden_size)
最后时间步所有层的隐藏状态
7.4 示例
python
import torch
import torch.nn as nn
# 实例化循环神经网络模型
rnn = nn.RNN(input_size=128, # 输入维度
hidden_size=256, # 隐藏层维度
num_layers=2 # 层数
)
inputs = torch.randn(5, 32, 128) # 输入数据,5个词,32个批次,128维词向量
h0 = torch.zeros(2, 32, 256) # 初始隐藏层状态,2层,32个批次,256维隐藏层状态
outputs, h_n = rnn(inputs, h0) # 前向传播,输出结果和最终隐藏层状态
print(outputs.shape) # 输出结果维度 torch.Size([5, 32, 256])
print(h_n.shape) # 最终隐藏层状态维度 torch.Size([2, 32, 256])