
| 🔭 个人主页: 散峰而望 |
|---|
《C语言:从基础到进阶》《编程工具的下载和使用》《C语言刷题》
《C++》《算法竞赛从入门到获奖》《人工智能》《AI Agent》
愿为出海月,不做归山云
🎬博主简介



【基础算法】动态规划从入门到进阶:记忆化搜索、线性 DP、LIS/LCS 一网打尽
- 前言
- [1. 动态规划](#1. 动态规划)
-
- [1.1 入门:从记忆化搜索到动态规划](#1.1 入门:从记忆化搜索到动态规划)
-
- [1.1.1 下楼梯](#1.1.1 下楼梯)
- [1.1.2 数字三角形 Number Triangles](#1.1.2 数字三角形 Number Triangles)
- [2. 线性 DP](#2. 线性 DP)
-
- [2.1 基础线性 DP](#2.1 基础线性 DP)
-
- [2.1.1 台阶问题](#2.1.1 台阶问题)
- [2.1.2 最大子段和](#2.1.2 最大子段和)
- [2.1.3 传球游戏](#2.1.3 传球游戏)
- [2.1.4 乌龟棋](#2.1.4 乌龟棋)
- [2.2 路径类 DP](#2.2 路径类 DP)
-
- [2.2.1 矩阵的最小路径和](#2.2.1 矩阵的最小路径和)
- [2.2.2 「木」迷雾森林](#2.2.2 「木」迷雾森林)
- [2.2.3 过河卒](#2.2.3 过河卒)
- [2.2.4 方格取数](#2.2.4 方格取数)
- [2.3 经典线性 DP](#2.3 经典线性 DP)
-
- [2.3.1 最长上升子序列](#2.3.1 最长上升子序列)
- [2.3.2 【模板】最长上升子序列](#2.3.2 【模板】最长上升子序列)
- [2.3.3 合唱队形](#2.3.3 合唱队形)
- [2.3.4 牛可乐和最长公共子序列](#2.3.4 牛可乐和最长公共子序列)
- [2.3.5 编辑距离](#2.3.5 编辑距离)
- 结语
前言
动态规划(Dynamic Programming, DP)是一种高效解决复杂问题的算法思想,广泛应用于优化、组合数学和计算机科学领域。其核心思想是将问题分解为相互重叠的子问题,通过存储子问题的解避免重复计算,从而提升效率。
从简单的记忆化搜索到经典的线性 DP 问题,动态规划展现了强大的问题建模能力。无论是台阶问题、最长上升子序列,还是路径规划、编辑距离,动态规划都能提供清晰的解决框架。
本部分内容由浅入深,涵盖基础概念、线性 DP 模型及经典问题,帮助理解状态转移的设计与优化。通过实践例题,逐步掌握动态规划的分析方法,为后续更复杂的算法场景奠定基础。
1. 动态规划
-
入门门槛高 。初学动态规划时,可能会觉得这个概念抽象难懂 ,甚至有些解题过程看似"玄学"。这是正常现象,通常完成多道练习题后,就能逐渐掌握其解题逻辑。关键是要坚持练习,反复理解。
-
题型覆盖面广。动态规划不仅出现在算法基础部分,在进阶内容中也会深入讲解。其细分类型多达十余种,学习过程需要投入较多时间和精力。
-
解题难度大 。在算法竞赛中,非经典动态规划问题往往作为压轴难题出现,对解题能力要求较高。
虽然动态规划颇具挑战性,但想要在算法领域取得突破,这是必须攻克的重要知识点。后续讲解将采用循序渐进的方式,确保每位学习者都能跟上进度,逐步掌握这一核心算法。
1.1 入门:从记忆化搜索到动态规划
- 记忆化搜索
在搜索的过程中,如果搜索树中有很多重复的结点,此时可以通过一个 "备忘录" ,记录第一次搜索到的结果。当下一次搜索到这个结点时,直接在 "备忘录" 里面找结果。其中,搜索树中的一个一个结点,也称为一个一个状态。
比如经典的斐波那契数列问题:
cpp
int f[N]; // 备忘录
int fib(int n)
{
// 搜索之前先往备忘录里面瞅瞅
if(f[n] != -1) return f[n];
if(n == 0 || n == 1) return f[n] = n;
// 返回之前,把结果记录在备忘录中
f[n] = fib(n - 1) + fib(n - 2);
return f[n];
}- 递归改递推
在用记忆化搜索解决斐波那契问题时,如果关注 "备忘录" 的填写过程,会发现它是从左往右依次填写的。当 i 位置前面的格子填写完毕之后,就可以根据格子里面的值计算出 i 位置的值。所以,整个递归过程,我们也可以改写成循环的形式,也就是递推:
cpp
int f[N]; // f[i] 表示:第 i 个斐波那契数
int fib(int n)
{
// 初始化前两个格子
f[0] = 0; f[1] = 1;
// 按照递推公式计算后面的值
for(int i = 2; i <= n; i++)
{
f[i] = f[i - 1] + f[i - 2];
}
// 返回结果
return f[n];
}- 动态规划
动态规划(Dynamic Programming,简称DP)是一种解决多阶段决策问题的算法思想。其核心在于将复杂问题拆解为若干子问题,通过存储子问题的解(称为"状态")来避免重复计算,从而提升效率。这种算法巧妙融合了分治与剪枝的思想精髓。
无论是采用记忆化搜索 还是递推方式求解斐波那契数列,本质上都是在运用动态规划的原理。
注意:
- 动态规划中的相关概念其实远不止如此,还会有:重叠子问题、最优子结构、无后效性、有向无环图等等。
- 这些概念没有一段时间的沉淀是不可能完全理解的。可以等学过一段时间之后,再去接触这些概念。不过,这些概念即使不懂,也不影响做题.
在递推形式的动态规划中,常用下面的专有名词来表述:
1. 状态表示 :指 f 数组中,每一个格子代表的含义。其中,这个数组也会称为 dp 数组,或者 dp 表。比如:斐波那契中 f[i] 。
2. 状态转移方程 :指 f 数组中,每一个格子是如何用其余的格子推导出来的。比如:斐波那契中 f[i] = f[i - 1] + f[i - 2] 。
3. 初始化 :在填表之前,根据题目中的默认条件或者问题的默认初始状态,将 f 数组中若干格子先填上值。比如:斐波那契中 f[0] = 0, f[1] = 1 。
其实递推形式的动态规划中的各种表述,是可以对应到递归形式的:
- 状态表示 <---> 递归函数的意义;
- 状态转移方程 <---> 递归函数的主函数体;
- 初始化 <---> 递归函数的递归出口。
4. 如何利用动态规划解决问题
第一种方式:记忆化搜索
- 先用递归的思想去解决问题;
- 若存在重复子问题,则将实现形式改为记忆化搜索。
第二种方式:直接使用递推形式的动态规划解决
该方式需按以下步骤依次执行:
(1) 定义状态表示 :
结合经验 与递归函数的语义 ,为 dp 数组赋予对应逻辑含义(若初次"尝试性"定义的状态能解决问题,则定义有效;反之需调整重试)。
(2) 推导状态转移方程 :
依据"状态表示"与题目条件,在 dp 表中分析当前状态如何由其他状态推导得到。
(3) 初始化 :
根据题目规则,先填充"显而易见"或"边界场景"下 dp 表的取值。
(4) 确定填表顺序 :
结合"状态转移方程"的依赖逻辑,明确 dp 表的填充先后顺序(如从左到右、从上到下等)。
(5) 确定最终结果 :
按照题目需求,在已填充完整的 dp 表中定位并提取最终结果。
1.1.1 下楼梯
算法原理:
因为上楼和下楼是一个可逆的过程,因此我们可以把下楼问题转化成上到第 n 个台阶,一共有多少种方案。
解法:动态规划
1. 状态表示
dp[i] 表示:走到第 i 个台阶的总方案数。
那最终结果就是在 dp[n] 处取到。
2. 状态转移方程
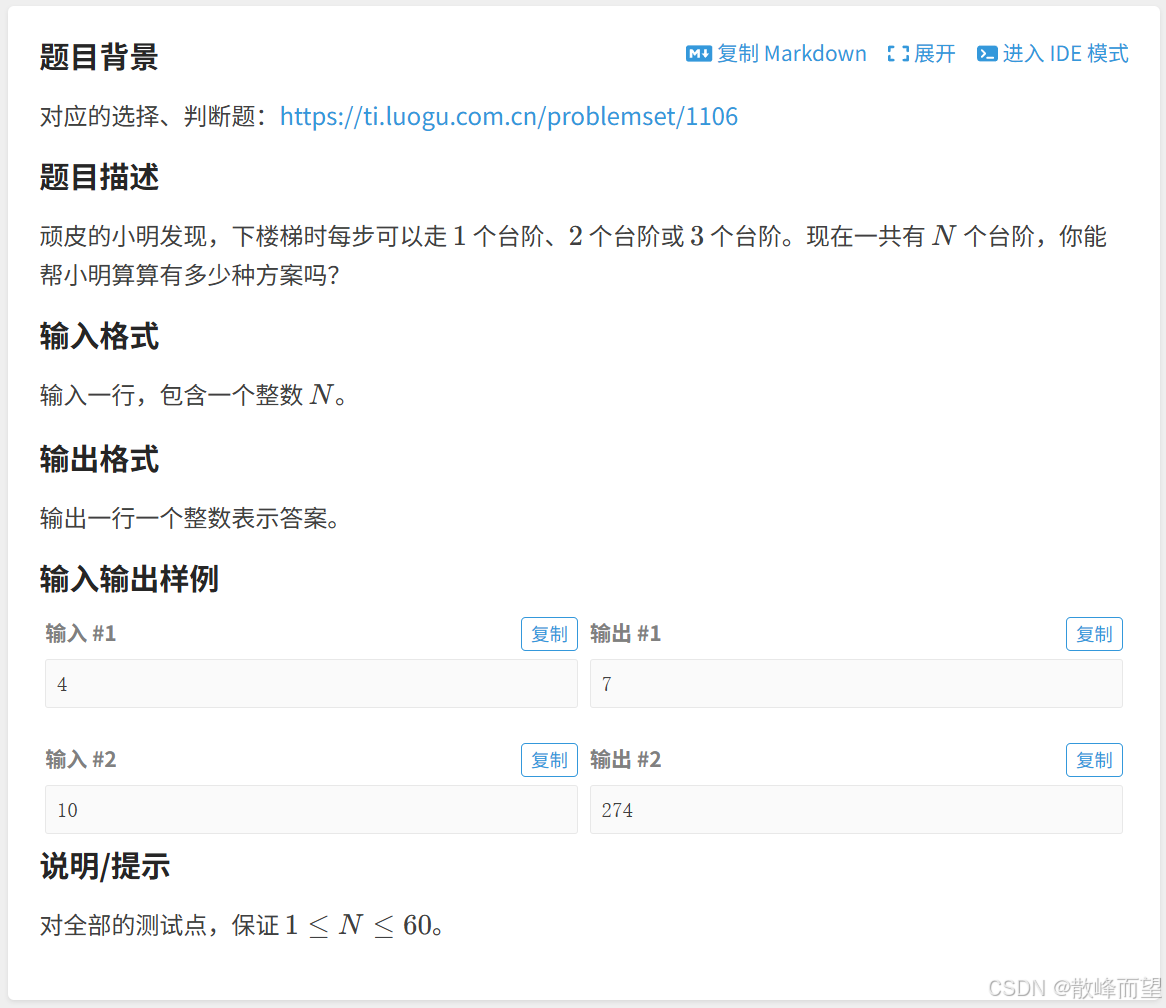
根据最后一步划分问题,走到第 i 个台阶的方式有三种:
a. 从 i-1 台阶向上走 1 个台阶,此时走到 i 台阶的方案就是 dp[i-1];
b. 从 i-2 台阶向上走 2 个台阶,此时走到 i 台阶的方案就是 dp[i-2];
c. 从 i-3 台阶向上走 3 个台阶,此时走到 i 台阶的方案就是 dp[i-3];
综上所述,dp[i] = dp[i-1] + dp[i-2] + dp[i-3]。
3. 初始化
填 i 位置的值时,至少需要前三个位置的值,因此需要初始化 dp[0] = 1,dp[1] = 1,dp[2] = 2,然后从 i = 3 开始填。
或者初始化 dp[1] = 1,dp[2] = 2,dp[3] = 4,然后从 i = 4 开始填。
4. 填表顺序:
明显是从左往右。
5. 动态规划的空间优化:
我们发现,在填写 dp[i] 的值时,我们仅仅需要前三个格子的值,第 i-4 个及其之前的格子的值已经毫无用处了。因此,可以用三个变量记录 i 位置之前三个格子的值,然后在填完 i 位置的值之后,滚动向后更新。
参考代码::
cpp
//代码一:普通
#include <iostream>
using namespace std;
typedef long long LL;
const int N = 65;
int n;
LL f[N];//f[N]表示有i个台阶的时候,一共有多少方案
int main()
{
cin >> n;
f[0] = 1, f[1] = 1, f[2] = 2;
for(int i = 3; i <= n; i++)
f[i] = f[i - 1] + f[i - 2] + f[i - 3];
cout << f[n] << endl;
return 0;
}
cpp
//代码二:空间优化
#include <iostream>
using namespace std;
typedef long long LL;
const int N = 65;
int n;
LL f[N];//f[N]表示有i个台阶的时候,一共有多少方案
int main()
{
cin >> n;
LL a = 1, b = 1, c = 2;
for(int i = 3; i <= n; i++)
{
LL t = a + b + c;
a = b;
b = c;
c = t;
}
if(n == 1) cout << b << endl;
else cout << c << endl;
return 0;
} 1.1.2 数字三角形 Number Triangles

算法原理:
动态规划经典的入门题。
1. 状态表示
d p i j dpij dpij 表示:走到 i , j i,j i,j 位置的最大权值。
那最终结果就是在 d p dp dp 表的第 n n n 行中,所有元素的最大值。
2. 状态转移方程
根据最后一步划分问题,走到 i , j i,j i,j 位置的方式有两种:
- a. 从 i − 1 , j i-1,j i−1,j 位置向下走一格,此时走到 i , j i,j i,j 位置的最大权值就是 d p i − 1 j dpi-1j dpi−1j;
- b. 从 i − 1 , j − 1 i-1,j-1 i−1,j−1 位置向右下走一格,此时走到 i , j i,j i,j 位置的最大权值就是 d p i − 1 j − 1 dpi-1j-1 dpi−1j−1;
综上所述,应该是两种情况的最大值再加上 i , j i,j i,j 位置的权值:
d p i j = max ( d p i − 1 j , d p i − 1 j − 1 ) + a i j dpij = \max(dpi-1j,\ dpi-1j-1) + aij dpij=max(dpi−1j, dpi−1j−1)+aij
3. 初始化
因为 d p dp dp 表被 0 0 0 包围着,并不影响我们的最终结果,因此可以直接填表。
思考,如果权值出现负数的话,需不需要初始化?
- 此时可以全都初始化为 − ∞ -\infty −∞,负无穷大在取 max \max max 之后,并不影响最终结果。
4. 填表顺序
从左往右填写每一行,每一行从左往右。
5. 动态规划的空间优化
我们发现,在填写第 i i i 行的值时,我们仅仅需要前一行的值,并不需要第 i − 2 i-2 i−2 以及之前行的值。因此,我们可以只用一个一维数组来记录上一行的结果,然后在这个数组上更新当前行的值。
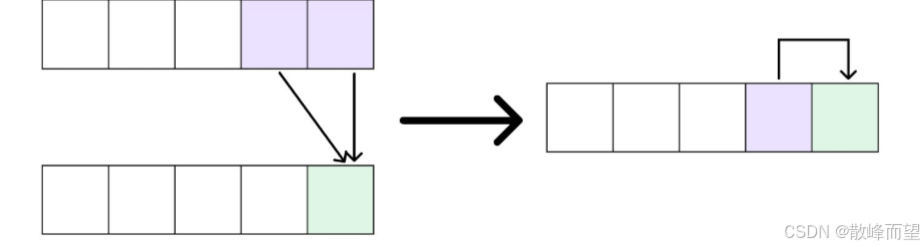
需要注意,当用因为我们当前这个位置的值需要左上角位置的值,因此滚动数组优化的时候,要改变第二维的遍历顺序。
参考代码:
cpp
//代码一:普通
#include <iostream>
using namespace std;
const int N = 1010;
int n;
int a[N][N];
int f[N][N];//f[i][j]表示从[1,1]到[i,j]所有方案的最大值
int main()
{
cin >> n;
for(int i = 1; i <= n; i++)
for(int j = 1; j <= i; j++)
cin >> a[i][j];
for(int i = 1; i <= n; i++)
for(int j = 1; j <= i; j++)
f[i][j] = max(f[i - 1][j], f[i - 1][j - 1]) + a[i][j];
int ret = 0;
for(int j = 1; j <= n; j++)
ret = max(ret, f[n][j]);
cout << ret << endl;
}
cpp
//代码二:空间规划
#include <iostream>
using namespace std;
const int N = 1010;
int n;
int a[N][N];
int f[N];//f[i][j]表示从[1,1]到[i,j]所有方案的最大值
int main()
{
cin >> n;
for(int i = 1; i <= n; i++)
for(int j = 1; j <= i; j++)
cin >> a[i][j];
for(int i = 1; i <= n; i++)
for(int j = i; j >= 1; j--)
f[j] = max(f[j], f[j - 1]) + a[i][j];
int ret = 0;
for(int j = 1; j <= n; j++)
ret = max(ret, f[j]);
cout << ret << endl;
} 2. 线性 DP
线性 DP(线性动态规划)是动态规划中最基础且应用最广泛的一种类型。其核心特征在于状态转移方程仅依赖于前一个或少数几个相邻状态,且这些状态之间存在明显的线性递推关系。这种线性特性使得问题的解决过程可以按照特定的顺序(如从左到右、从上到下等)逐步推进。
在实现方式上,线性 DP 通常采用一维或二维数组来存储中间状态值:
- 一维 DP:适用于状态转移仅依赖前一个或前几个状态的情况。例如经典的《下楼梯》问题,其中dpi表示到达第i级台阶的方法数,其状态转移方程为
dp[i] = dp[i-1] + dp[i-2] - 二维 DP:适用于状态转移涉及两个维度的情况。如《数字三角形》问题,使用dpij表示从顶点到第i行第j列元素的最大路径和,其状态转移需考虑左上和右上两个方向:
dp[i][j] = max(dp[i-1][j-1], dp[i-1][j]) + a[i][j]
线性 DP 的优势在于其清晰的递推结构和相对较低的空间复杂度,是学习更复杂动态规划问题的重要基础。
2.1 基础线性 DP
2.1.1 台阶问题
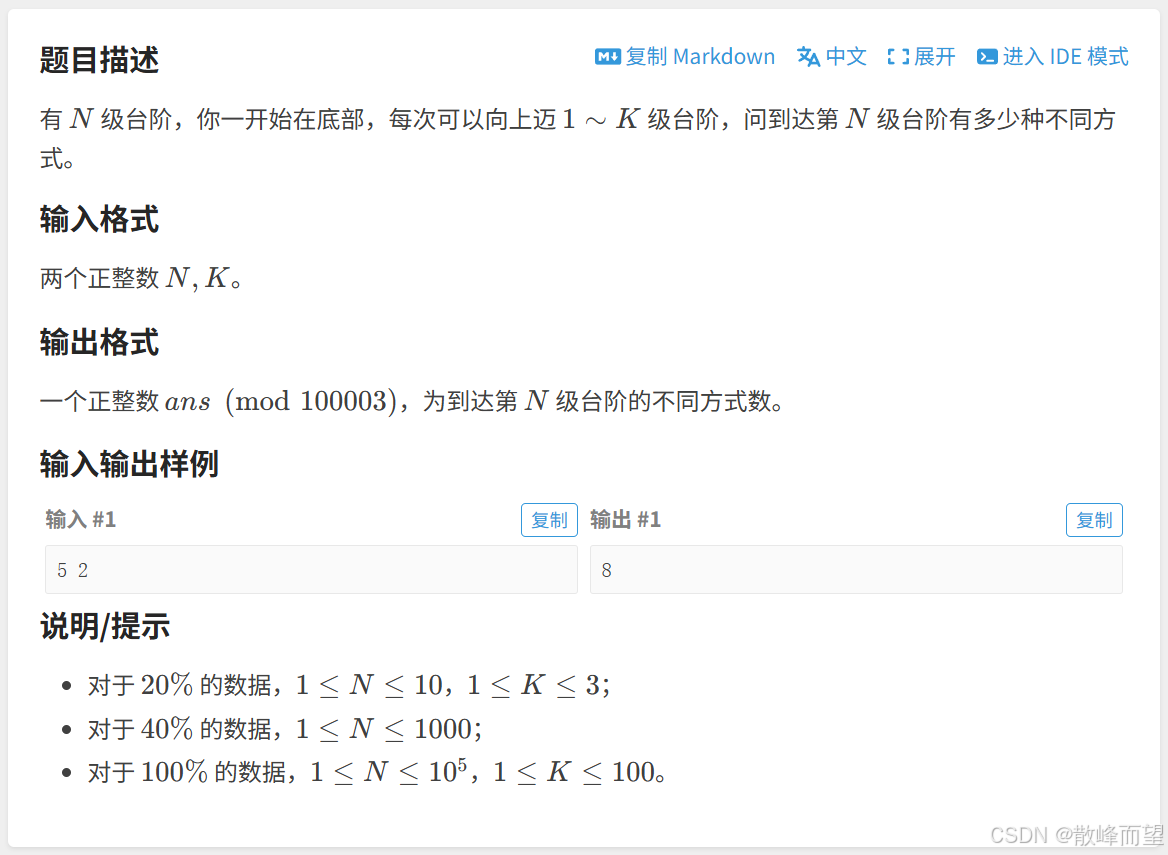
算法原理:
斐波那契数列模型
-
状态表示 :
dp[i]表示:走到i位置的方案数。那么
dp[n]就是我们要的结果。 -
状态转移方程 :
可以从
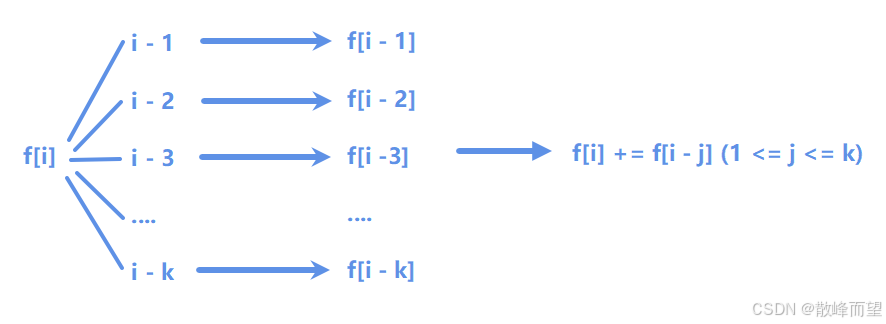
i-k ≤ j ≤ i-1区间内的台阶走到i位置,那么总方案数就是所有的dp[j]累加在一起。
注意 :i-k不能小于0。
-
初始化 :
dp[0] = 1,起始位置,为了让后续填表有意义。 -
填表顺序 :
从左往右。
-
最终结果 :
dpn 。
参考代码:
cpp
#include <iostream>
using namespace std;
const int N = 1e5 + 10, MOD = 1e5 + 3;
int n, k;
int f[N];
int main()
{
cin >> n >> k;
f[0] = 1;
for(int i = 1; i <= n; i++)
{
for(int j = 1; j <= k && i - j >= 0; j++)
{
f[i] = (f[i] + f[i - j]) % MOD;
}
}
cout << f[n] << endl;
return 0;
} 2.1.2 最大子段和
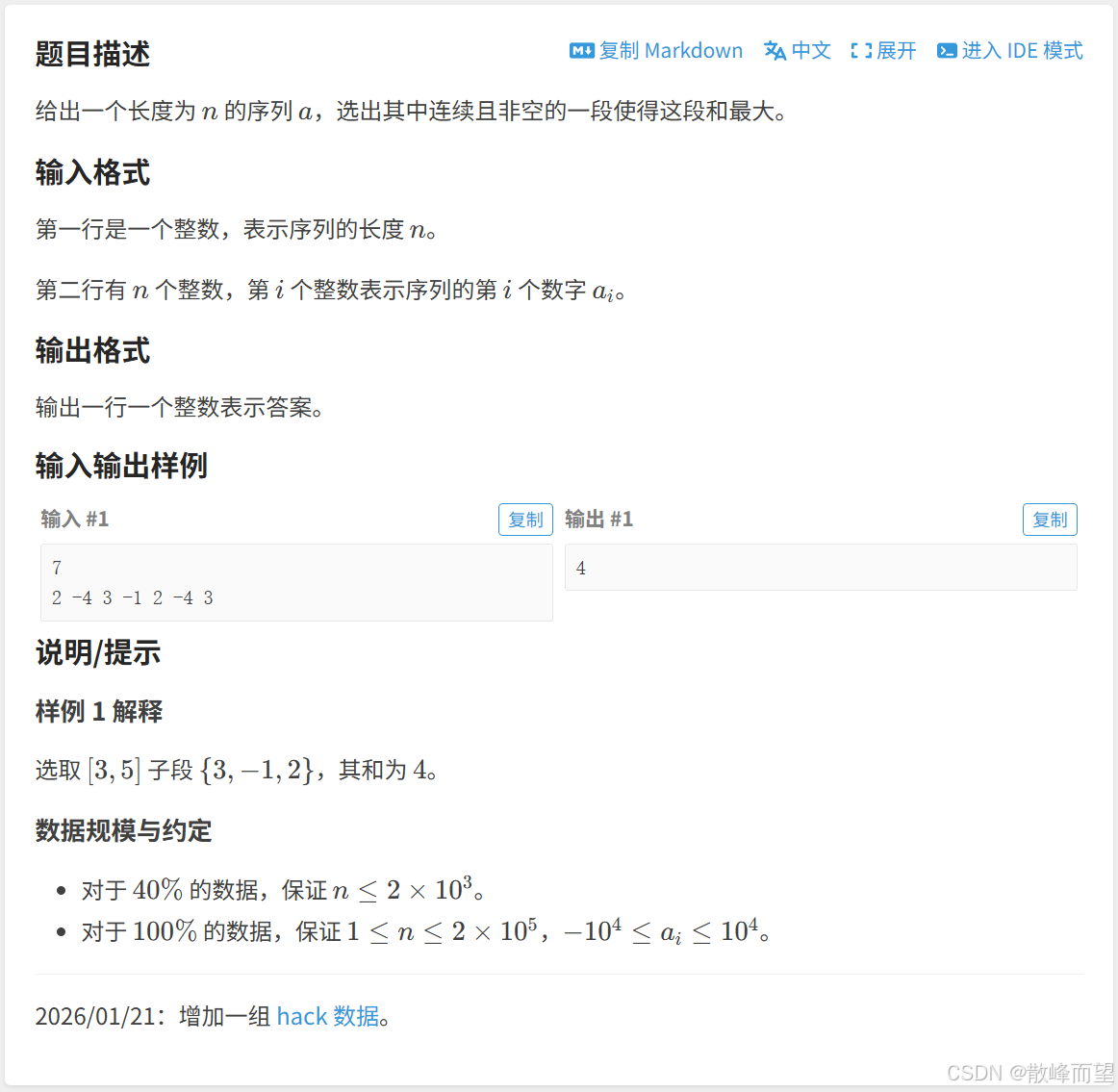
算法原理:
- 状态表示 :
dp[i]表示:以i位置元素为结尾的「所有子数组」中和的最大值。
那我们的最终结果应该是 dp 表里面的最大值。
- 状态转移方程 :
dp[i]的所有可能可以分为以下两种:
a. 子数组的长度为 1:此时 dp[i] = a[i] ;
b. 子数组的长度大于 1:此时 dp[i] 应该等于以i-1为结尾的「所有子数组」中和的最大值再加上 a[i],也就是 dp[i-1] + a[i]。
应该是两种情况下的最大值,因此可得转移方程:
dp[i] = max(a[i], dp[i-1] + a[i])。
-
初始化 :
把第一个格子初始化为
0,往后填数的时候就不会影响最终结果。 -
填表顺序 :
根据「状态转移方程」易得,填表顺序为「从左往右」。
-
最终结果:
整个数组的最大值。
参考代码:
cpp
#include <iostream>
using namespace std;
const int N = 2e5 + 10;
int n;
int f[N];
int main()
{
cin >> n;
int ret = -1e9;
for(int i = 1; i <= n; i++)
{
int x; cin >> x;
f[i] = max(x, f[i - 1] + x);
ret = max(ret, f[i]);
}
cout << ret << endl;
return 0;
} 2.1.3 传球游戏

算法原理:
-
状态表示
f[i][j]表示传了i次,落在第j个人手里时的总方案数。那么
f[m][1]就是我们想要的结果。 -
状态转移方程
因为是一个环形结构,第一个位置和最后一个位置可以特殊处理:
- a. 当 2 ≤ j ≤ n − 1 2 \leq j \leq n-1 2≤j≤n−1 时,可以从 j − 1 j-1 j−1 或者 j + 1 j+1 j+1 传到该位置,那么总方案数就是 f i − 1 j − 1 + f i − 1 j + 1 fi-1j-1 + fi-1j+1 fi−1j−1+fi−1j+1;
- b. 当 j = 1 j = 1 j=1 时,可以从 n n n 或者 2 2 2 传到该位置,那么总方案数就是 f i − 1 n + f i − 1 2 fi-1n + fi-12 fi−1n+fi−12;
- c. 当 j = n j = n j=n 时,可以从 n − 1 n-1 n−1 或者 1 1 1 传到该位置,那么总方案数就是 f i − 1 1 + f i − 1 n − 1 fi-11 + fi-1n-1 fi−11+fi−1n−1。
-
初始化
刚开始的状态设置为 1,让后续填表是正确的,即:
f 0 1 = 1 f01 = 1 f01=1 -
填表顺序
一定要先循环次数,再循环位置。因为我们更新状态是从低次数更新高次数,也就是第一行更新第二行。因此填表顺序应该是从上往下每一行,行的顺序无所谓。
-
最终结果:
f[m][1]。
参考代码:
cpp
#include <iostream>
using namespace std;
const int N = 40;
int n, m;
int f[N][N];//f[i][j]表示:传递i次后,落在j号同学方案数
int main()
{
cin >> n >> m;
f[0][1] = 1;
for(int i = 1; i <= m; i++)
{
//第一个人
f[i][1] = f[i - 1][n] + f[i - 1][2];
//中间同学
for(int j = 2; j < n; j++)
{
f[i][j] = f[i - 1][j - 1] + f[i - 1][j + 1];
}
//第n个人
f[i][n] = f[i - 1][n - 1] + f[i - 1][1];
}
cout << f[m][1] << endl;
return 0;
} 2.1.4 乌龟棋
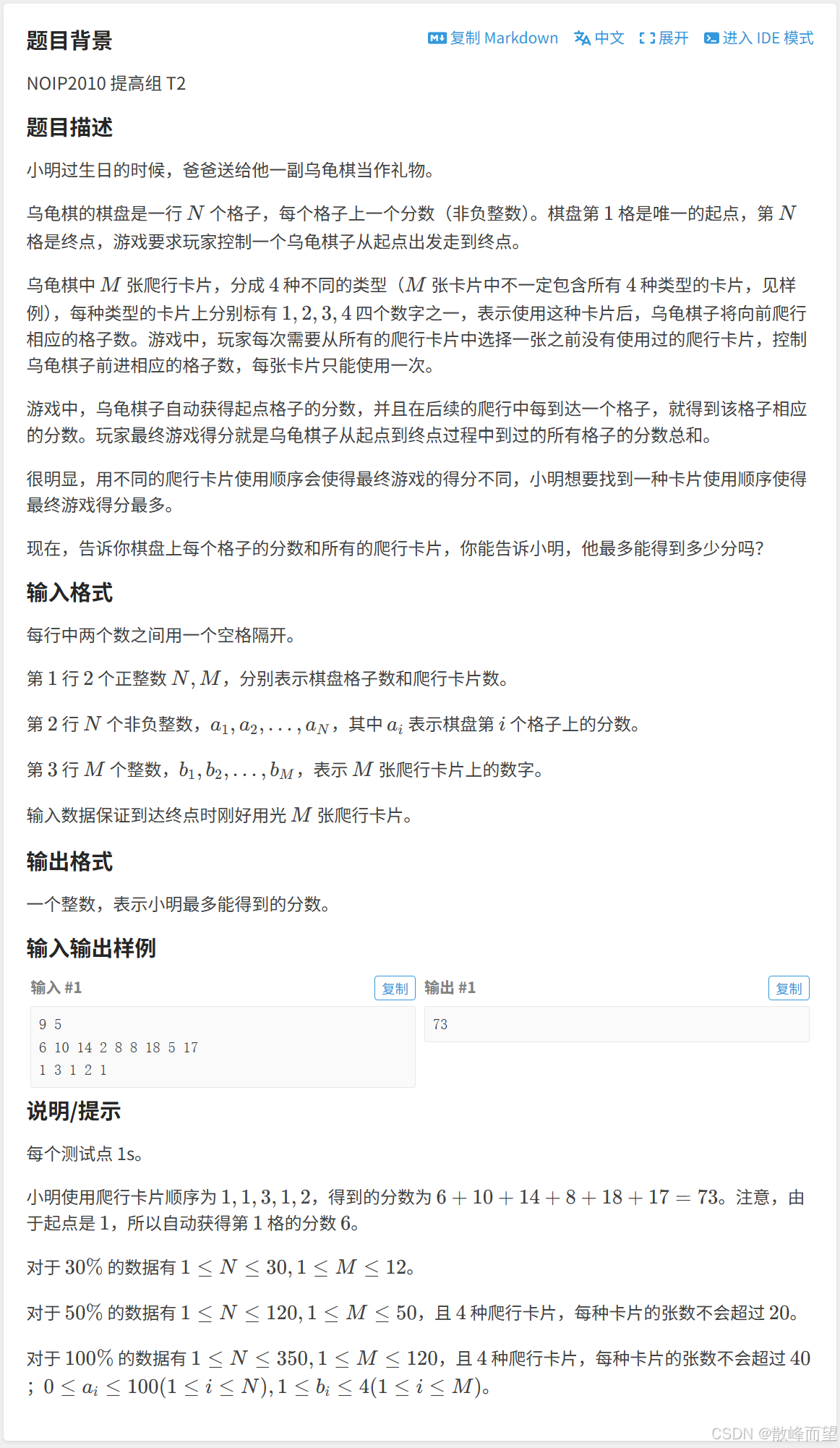
算法原理:
- 状态表示:
f[i][a][b][c][d] 表示:走到 i 位置时,编号为 1 2 3 4 的卡片分别用了 a b c d 张,此时的最大分数。
我们发现,当 1 2 3 4 用的卡片数确定之后,走到的位置 i 可以计算出来,其中 i = 1 + a + 2b + 3c + 4d 。
因此状态表示可以优化掉一维,变成 f[a][b][c][d] ,表示:编号为 1 2 3 4 的卡片分别用了 a b c d 张,此时的最大分数。
- 状态转移方程:
设根据最后一次用的卡片种类,分情况讨论:
a. 如果 a > 0,并且最后一张用 1 卡片,最大分数为:f[a-1][b][c][d] + nums[i] ;
b. 如果 b > 0,并且最后一张用 2 卡片,最大分数为:f[a][b-1][c][d] + nums[i] ;
c. 如果 c > 0,并且最后一张用 3 卡片,最大分数为:f[a][b][c-1][d] + nums[i] ;
d. 如果 d > 0,并且最后一张用 4 卡片,最大分数为:f[a][b][c][d-1] + nums[i] ;
综上所述,取四种情况里面的最大值即可。
- 初始化:
一张卡片也不用的情况下,可以获得第一个格子的分数,f[0][0][0][0] = nums[1] 。
- 填表顺序:
从小到大枚举每种卡片使用的张数即可。
- 最终结果 :
f[cnt[1]][cnt[2]][cnt[3]][cnt[4]] ,cnt 表示当前这张牌有多少张。
参考代码:
cpp
#include <iostream>
using namespace std;
const int N = 360, M = 50;
int n, m;
int x[N], cnt[5];
int f[M][M][M][M];
int main()
{
cin >> n >> m;
for(int i = 1; i <= n; i++) cin >> x[i];
for(int i = 1; i <= m; i++)
{
int t; cin >> t;
cnt[t]++;
}
//初始化
f[0][0][0][0] = x[1];
for(int a = 0; a <= cnt[1]; a++)
for(int b = 0; b <= cnt[2]; b++)
for(int c = 0; c <= cnt[3]; c++)
for(int d = 0; d <= cnt[4]; d++)
{
int i = 1 + a + 2 * b + 3 * c + 4 * d;
int& t = f[a][b][c][d];
if(a) t = max(t, f[a - 1][b][c][d] + x[i]);
if(b) t = max(t, f[a][b - 1][c][d] + x[i]);
if(c) t = max(t, f[a][b][c - 1][d] + x[i]);
if(d) t = max(t, f[a][b][c][d - 1] + x[i]);
}
cout << f[cnt[1]][cnt[2]][cnt[3]][cnt[4]] << endl;
return 0;
} 2.2 路径类 DP
路径类 DP 是线性 DP 的一种,它是在一个 n * m 的矩阵中设置一个行走规则,研究从起点走到终点的方案数、最小路径和或者最大路径和等等的问题。
入门阶段的《数字三角形》其实就是路径类 DP。
2.2.1 矩阵的最小路径和

算法原理:
- 状态表示:
d p i j dpij dpij 表示:到达 i , j i, j i,j 位置处,最小路径和是多少。
那我们的最终结果就是 d p n m dpnm dpnm。
- 状态转移:
到达 i , j i, j i,j 位置之前的一小步,有两种情况:
i. 从 i − 1 , j i-1, j i−1,j 向下走一步,转移到 i , j i, j i,j 位置;
ii. 从 i , j − 1 i, j-1 i,j−1 向右走一步,转移到 i , j i, j i,j 位置。
由于到 i , j i, j i,j 位置存在上述两种情况,且我们需要找最小路径 ,因此只需取这两种情况的最小值,再加上 i , j i, j i,j 位置本身的值,即:
d p i j = min ( d p i − 1 j , d p i j − 1 ) + a i j dpij = \min(dpi-1j, dpij-1) + aij dpij=min(dpi−1j,dpij−1)+aij
- 初始化:
第一行和第一列需要初始化,原因是直接按状态转移方程计算时会触发"越界访问"。
若将整张动态规划表初始化为无穷大 ,再将 d p 0 1 dp01 dp01 和 d p 1 0 dp10 dp10 的值设为 0 0 0,后续按规则填表即可得到正确结果。
- 填表顺序:
结合「状态转移方程」的依赖逻辑,填表顺序为:从上往下 遍历每一行,且每一行内部从左往右 依次计算每个位置的 d p dp dp 值。
参考代码:
cpp
#include <iostream>
#include <cstring>
using namespace std;
const int N = 510;
int n, m;
int f[N][N];
int main()
{
cin >> n >> m;
//初始化
memset(f, 0x3f, sizeof f);
f[0][1] = 0;
for(int i = 1; i <= n; i++)
for(int j = 1; j <= m; j++)
{
int x; cin >> x;
f[i][j] = min(f[i - 1][j], f[i][j - 1]) + x;
}
cout << f[n][m] << endl;
return 0;
} 2.2.2 「木」迷雾森林
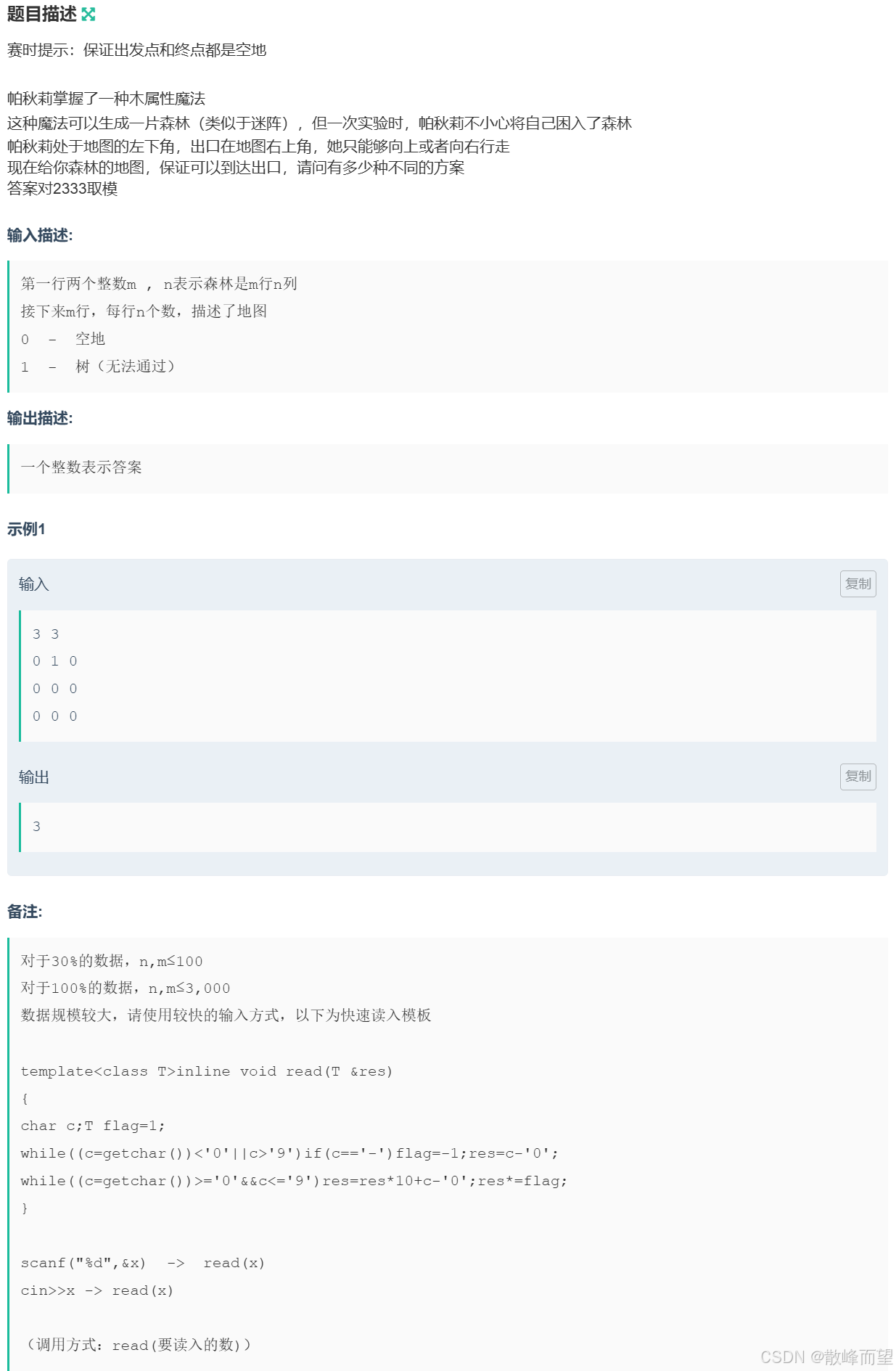
算法原理:
- 状态表示 :
f i j fij fij 表示:到达 i , j i, j i,j 位置时,有多少种方案。
那么 f 1 m f1m f1m 就是我们要的结果。
- 状态转移方程 :
a. 若 i , j i,j i,j 位置是空地 ,到达 i , j i,j i,j 位置有两种方式:
- 从 i + 1 , j i + 1, j i+1,j 向上走一步,此时的方案数为 f i + 1 j fi + 1j fi+1j;
- 从 i , j − 1 i, j - 1 i,j−1 向右走一步,此时的方案数为 f i j − 1 fij - 1 fij−1。
两者总和就是到达 i , j i,j i,j 位置的总方案数。
b. 若 i , j i,j i,j 位置是树
无法走到该位置,因此 f i j = 0 fij = 0 fij=0。
- 初始化 :
可以在原始矩阵的规模上多加上一行和一列 ,把 f n + 1 1 fn + 11 fn+11 或者 f n 0 fn0 fn0 初始化为 1 1 1,这样后续填表就会有意义。
- 填表顺序 :
从下往上每一行,每一行从左往右。
- 最终结果 :
f[1][m] 。
参考代码:
cpp
#include <iostream>
using namespace std;
const int N = 3010, MOD = 2333;
int n, m;
int a[N][N];
int f[N][N];
int main()
{
scanf("%d%d", &n, &m);
for(int i = 1; i <= n; i++)
for(int j = 1; j <= m; j++)
scanf("%d", &a[i][j]);
f[n][0] = 1;
for(int i = n; i >= 1; i--)
for(int j = 1; j <= n; j++)
{
if(a[i][j] == 0)
{
f[i][j] = (f[i + 1][j] + f[i][j - 1]) % MOD;
}
}
cout << f[1][m] << endl;
return 0;
}2.2.3 过河卒

算法原理:
- 状态表示:
f[i][j] 表示:到达 [i,j] 位置的方案数。
那么 f[n][m] 就是我们要的结果。
- 状态转移方程:
a. 如果 [i,j] 位置能走到,到达 [i,j] 位置之前的一小步,有两种情况:
- 从
[i-1,j]向下走一步,走到[i,j],此时的方案数为f[i-1][j]; - 从
[i,j-1]向右走一步,走到[i,j],此时的方案数为f[i][j-1];
那么总方案数 f[i][j] = f[i-1][j] + f[i][j-1] 。
b. 如果 [i,j] 位置走不到,f[i][j] = 0 。
马控制的距离,我们可以用曼哈顿距离 且 a != i, b != j 来判断,以及马所在的点也不能跳。
- 初始化:
我们可以给原始的矩阵多加一行多加一列,n, m, x, y 全部 +1 ,这样填任何一个位置都不会越界。
然后初始化 f[1][0] = 1 或者 f[0][1] = 1 ,保证后续填表正确即可。
- 填表顺序:
从上往下每一行,每一行从左往右。
- 最终结果 :
f[n][m] 。
参考代码:
cpp
#include <iostream>
using namespace std;
typedef long long LL;
const int N = 25;
int n, m, a, b;
LL f[N][N];
bool check(int i, int j)
{
return (i == a && j == b) || (i != a && j != b && abs(i - a) + abs(j - b) == 3);
}
int main()
{
cin >> n >> m >> a >> b;
n++, m++, a++, b++;
//初始化
f[0][1] = 1;
for(int i = 1; i <= n; i++)
for(int j = 1; j <= m; j++)
{
if(check(i, j)) continue;
f[i][j] = f[i - 1][j] + f[i][j - 1];
}
cout << f[n][m] << endl;
}2.2.4 方格取数

算法原理:
贪心 + 两次 dp 是错误的,因为两次最优不等于全局最优,可以举出反例。正解应该是同时去走两条路,两者相互影响,所以放在一起考虑。
- 状态表示 :
需要知道当前这两条路径走到什么位置,因此需要四维 f i 1 j 1 i 2 j 2 fi_1j_1i_2j_2 fi1j1i2j2 来表示第一条路走到 i 1 , j 1 i_1, j_1 i1,j1、第二条路走到 i 2 j 2 i_2j_2 i2j2。
但我们发现,因为两者是同时出发的,所以横纵坐标之和是一个定值。也就是说,只要知道了横纵坐标之和,以及两者的横坐标,就可以计算出纵坐标,状态表示就可以优化掉一维。
优化后的状态表示: f s t i 1 i 2 fsti_1i_2 fsti1i2 表示:第一条路在 i 1 , s t − i 1 i_1, st - i_1 i1,st−i1,第二条路在 i 2 , s t − i 2 i_2, st - i_2 i2,st−i2 时,两者的路径最大和。那我们的最终结果就是 f n × 2 n n fn \\times 2nn fn×2nn。
- 状态转移方程 :
第一条路可以从上 i 1 − 1 , s t − i 1 i_1 - 1, st - i_1 i1−1,st−i1 或者左 i 1 , s t − i 1 − 1 i_1, st - i_1 - 1 i1,st−i1−1 走到 i 1 , s t − i 1 i_1, st - i_1 i1,st−i1 位置;第二条路可以从上 i 2 − 1 , s t − i 2 i_2 - 1, st - i_2 i2−1,st−i2 或者左 i 2 , s t − i 2 − 1 i_2, st - i_2 - 1 i2,st−i2−1 走到 i 2 , s t − i 2 i_2, st - i_2 i2,st−i2 位置。排列组合一下一共 4 种情况,分别是:
- 上 + 上,此时的最大和为: f s t − 1 i 1 − 1 i 2 − 1 fst - 1i_1 - 1i_2 - 1 fst−1i1−1i2−1;
- 上 + 左,此时的最大和为: f s t − 1 i 1 − 1 i 2 fst - 1i_1 - 1i_2 fst−1i1−1i2;
- 左 + 上,此时的最大和为: f s t − 1 i 1 i 2 − 1 fst - 1i_1i_2 - 1 fst−1i1i2−1;
- 左 + 左,此时的最大和为: f s t − 1 i 1 i 2 fst - 1i_1i_2 fst−1i1i2;
取上面四种情况的最大值,然后再加上 a i 1 j 1 ai_1j_1 ai1j1 和 a i 2 j 2 ai_2j_2 ai2j2。但是要注意,如果两个路径当前在同一位置时,只用加上一个 a i 1 j 1 ai_1j_1 ai1j1 即可。
-
初始化 :
算的是路径和,0 不会影响最终结果,直接填表。
-
填表顺序 :
先从小到大循环横纵坐标之和,然后依次从小到大循环两者的横坐标。
参考代码:
cpp
#include <iostream>
using namespace std;
const int N = 15;
int n;
int a[N][N];
int f[N * 2][N][N];
int main()
{
cin >> n;
int x, y, w;
while(cin >> x >> y >> w, x)
{
a[x][y] = w;
}
for(int s = 2; s <= n + n; s++)
{
for(int i1 = 1; i1 <= n; i1++)
{
for(int i2 = 1; i2 <= n; i2++)
{
int j1 = s - i1, j2 = s - i2;
if(j1 <= 0 || j1 > n || j2 <= 0 || j2 > n) continue;
int t = f[s - 1][i1][i2];
t = max(t, f[s - 1][i1][i2 - 1]);
t = max(t, f[s - 1][i1 - 1][i2]);
t = max(t, f[s - 1][i1 - 1][i2 - 1]);
if(i1 == i2)
{
f[s][i1][i2] = t + a[i1][j1];
}
else
{
f[s][i1][i2] = t + a[i1][j1] + a[i2][j2];
}
}
}
}
cout << f[n + n][n][n] << endl;
return 0;
}2.3 经典线性 DP
经典线性 DP 问题有两个:最长上升子序列(简称:LIS)以及最长公共子序列(简称:LCS),这两道题目的很多方面都是可以作为经验,运用到别的题目中。比如:解题思路,定义状态表示的方式,推到状态转移方程的技巧等等。
因此,这两道经典问题是一定需要掌握的。
2.3.1 最长上升子序列
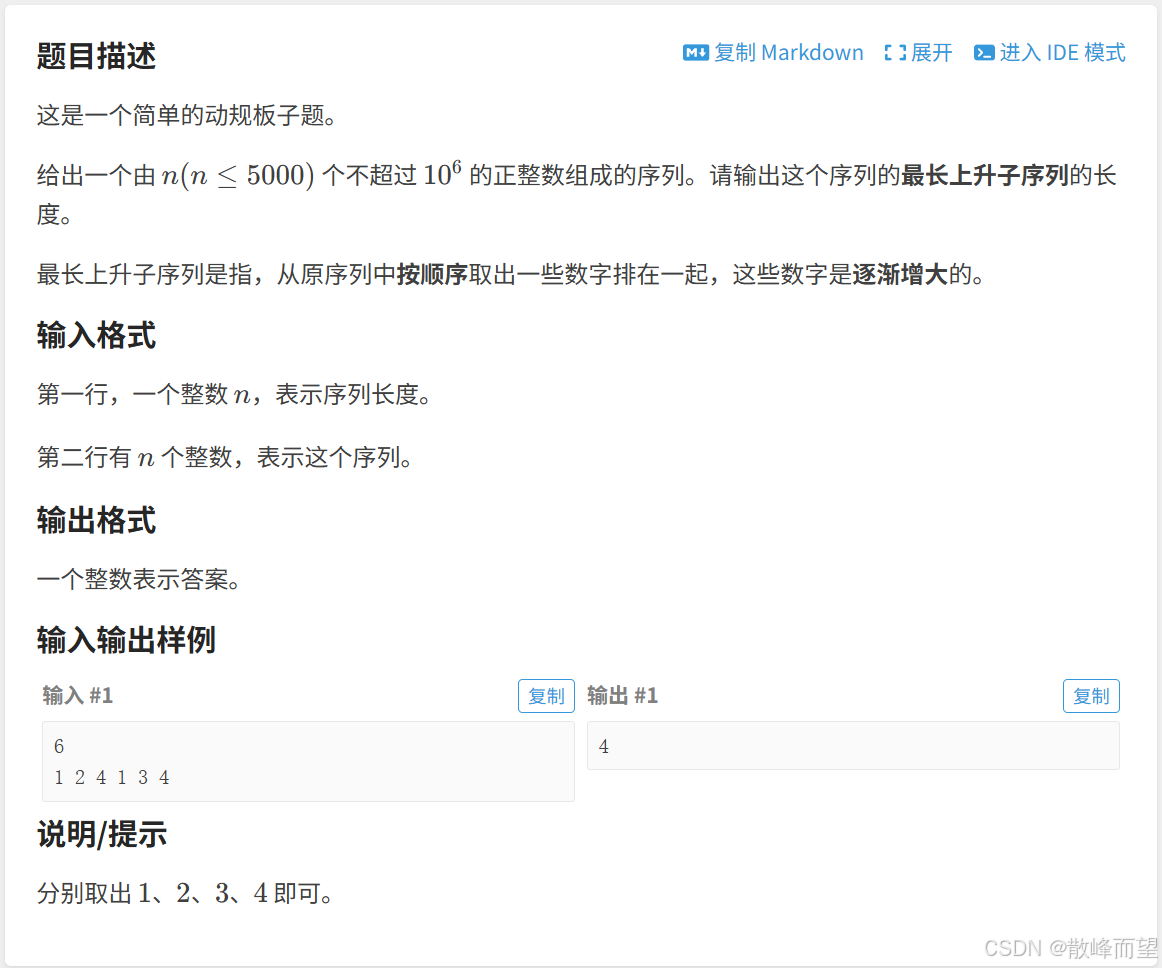
算法原理:
- 状态表示 :
dp[i] 表示:以 i 位置元素为结尾的「所有子序列」中,最长递增子序列的长度。
最终结果就是整张 dp 表里面的最大值。
- 状态转移方程 :
对于 dp[i] ,我们可以根据「子序列的构成方式」,进行分类讨论:
- 子序列长度为
1:只能自己玩了,此时dp[i]=1; - 子序列长度大于
1:a[i]可以跟在前面某些数后面形成子序列。设前面的某一个数的下标为j,其中1 ≤ j < i-1。只要a[j] < a[i],i位置元素跟在j元素后面就可以形成递增序列,长度为dp[j]+1。
因此,我们仅需找到满足要求的最大的 dp[j]+1 即可。
综上,dp[i] = max(dp[j] + 1, dp[i]),其中 1 ≤ j < i && nums[j] < nums[i]。
- 初始化 :
不用单独初始化,每次填表的时候,先把这个位置的数改成1即可。
- 填表顺序 :
显而易见,填表顺序「从左往右」。
- 最终结果 :
整个序列长度最大值。
「提示」
子数组 : 不可拆,要连续。
子序列 :可以不连续。
参考代码:
cpp
#include <iostream>
using namespace std;
const int N = 5010;
int n;
int a[N];
int f[N];
int main()
{
cin >> n;
for(int i = 1; i <= n; i++) cin >> a[i];
int ret = 0;
for(int i = 1; i <= n; i++)
{
f[i] = 1;//长度为1的子序列
for(int j = 1; j < i; j++)
{
if(a[j] < a[i])
{
f[i] = max(f[i], f[j] + 1);
}
}
ret = max(ret, f[i]);
}
cout << ret << endl;
return 0;
} 2.3.2 【模板】最长上升子序列
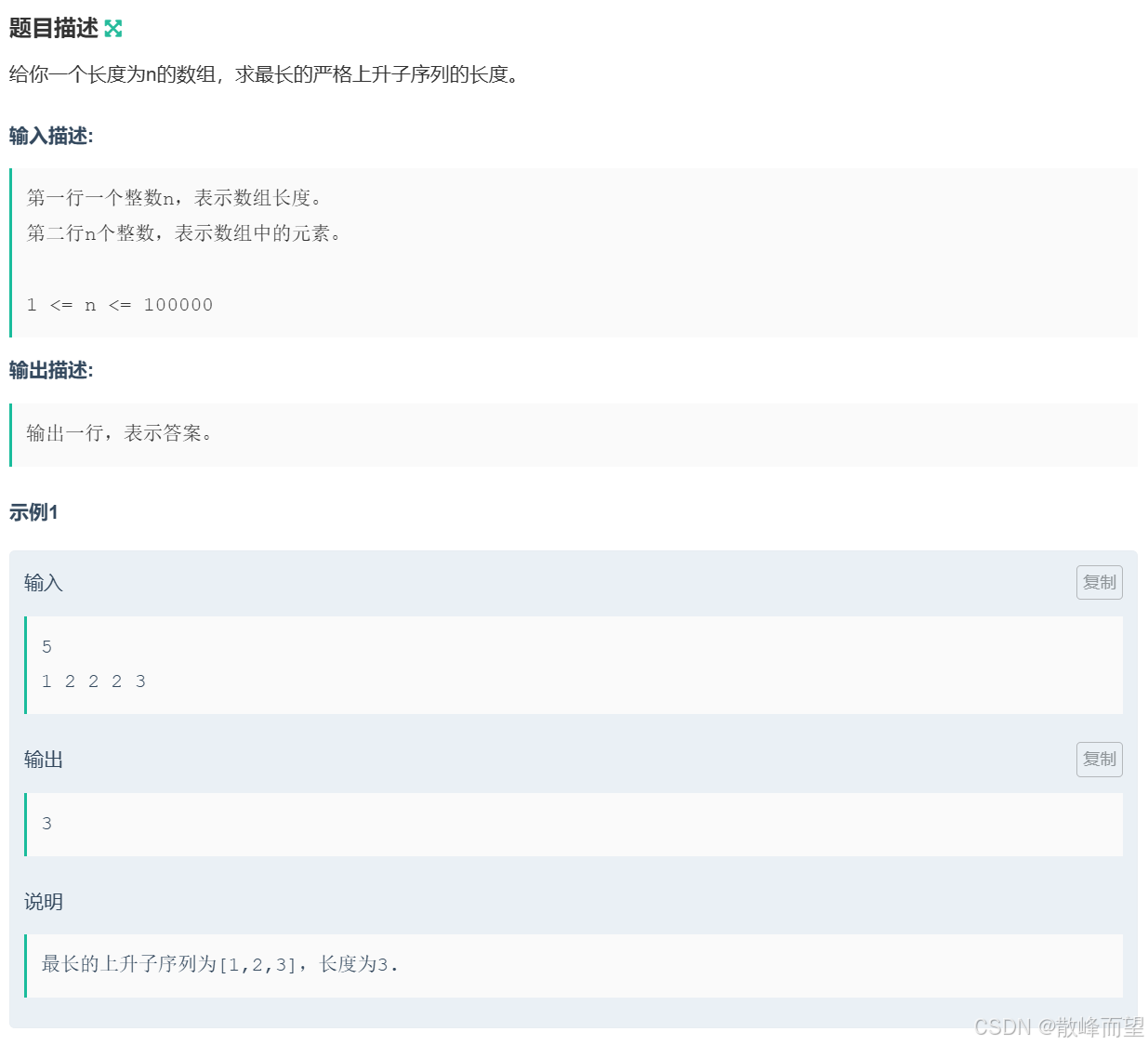
算法原理:
利用贪心 + 二分优化动态规划:
- 我们在考虑最长 递增子序列的长度的时候,其实并不关心这个序列长什么样子,我们只是关心最后一个元素是谁。这样新来一个元素之后,我们就可以判断是否可以拼接到它的后面。
- 因此,我们可以创建一个数组,统计长度为 x 的递增子序列中,最后一个元素是谁。为了尽可能的让这个序列更长,我们仅需统计长度为 x 的所有递增序列中最后一个元素的「最小值」。
- 统计的过程中发现,数组中的数呈现「递增」趋势,因此可以使用「二分」来查找插入位置。
参考代码:
cpp
#include <iostream>
using namespace std;
const int N = 1e5 + 10;
int n;
int a[N];
int f[N], len;
int main()
{
cin >> n;
for(int i = 1; i <= n; i++) cin >> a[i];
for(int i = 1; i <= n; i++)
{
//处理边界情况
if(len == 0 || a[i] > f[len]) f[++len] = a[i];
else
{
//二分插入
int l = 1, r = len;
while(l < r)
{
int mid = (l + r) / 2;
if(f[mid] >= a[i]) r = mid;
else l = mid + 1;
}
f[l] = a[i];
}
}
cout << len << endl;
return 0;
}2.3.3 合唱队形
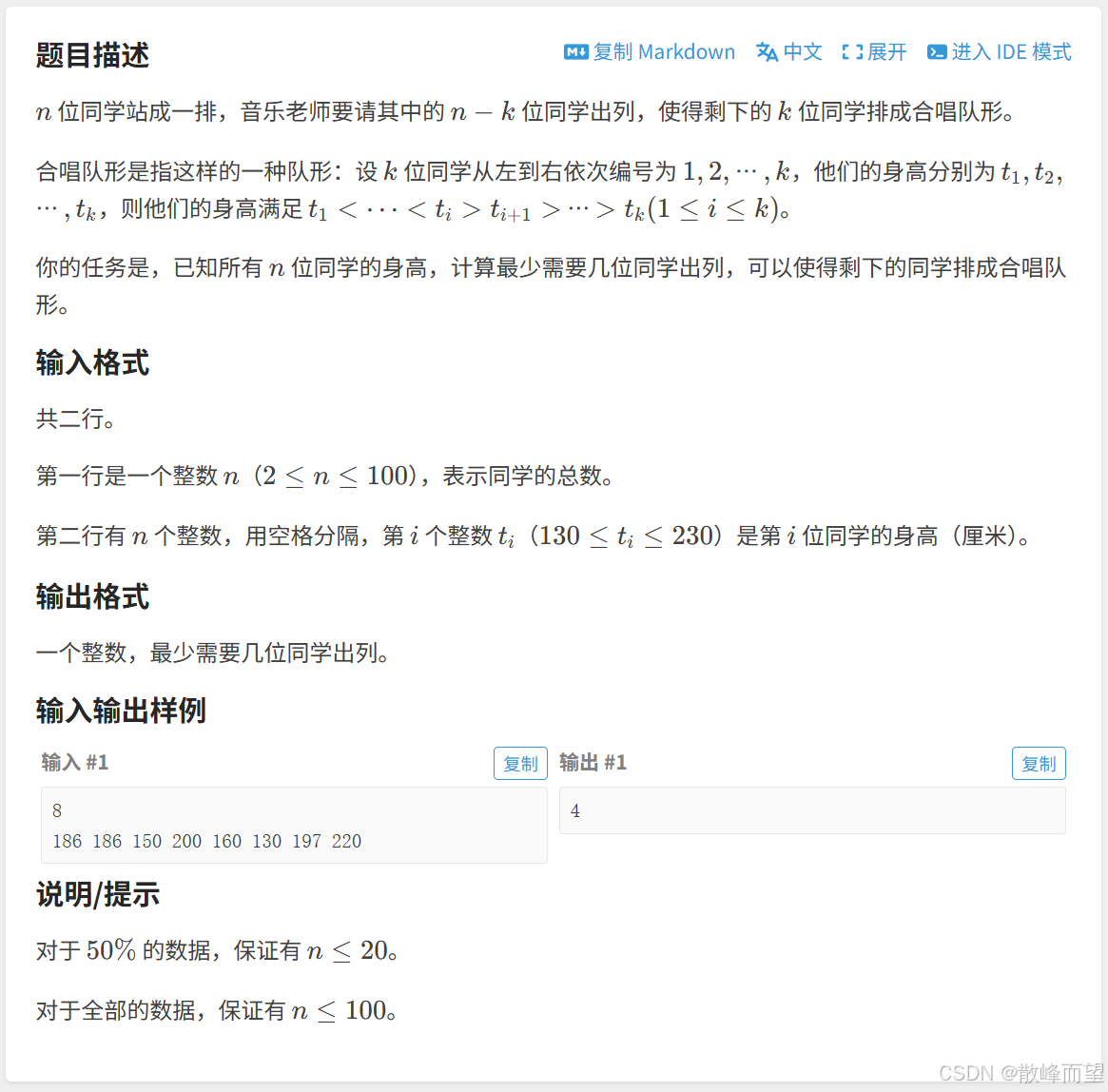
算法原理:
对于每一个位置 i ,计算:
- 从左往右看:以 i 为结尾的最长上升子序列 f i \boldsymbol{fi} fi;
- 从右往左看:以 i 为结尾的最长上升子序列 g i \boldsymbol{gi} gi;
最终结果就是所有 f i + g i − 1 \boldsymbol{fi + gi - 1} fi+gi−1 里面的最大值。
参考代码:
cpp
#include <iostream>
using namespace std;
const int N = 110;
int n;
int a[N];
int f[N], g[N];
int main()
{
cin >> n;
for(int i = 1; i <= n; i++) cin >> a[i];
//从左往右
for(int i = 1; i <= n; i++)
{
f[i] = 1;
for(int j = 1; j < i; j++)
{
if(a[j] < a[i])
{
f[i] = max(f[i], f[j] + 1);
}
}
}
//从右往左
for(int i = n; i >= 1; i--)
{
g[i] = 1;
for(int j = n; j > i; j--)
{
if(a[j] < a[i])
{
g[i] = max(g[i], g[j] + 1);
}
}
}
int ret = 0;
for(int i = 1; i <= n; i++)
{
ret = max(ret, f[i] + g[i] - 1);
}
cout << n - ret << endl;
return 0;
} 2.3.4 牛可乐和最长公共子序列
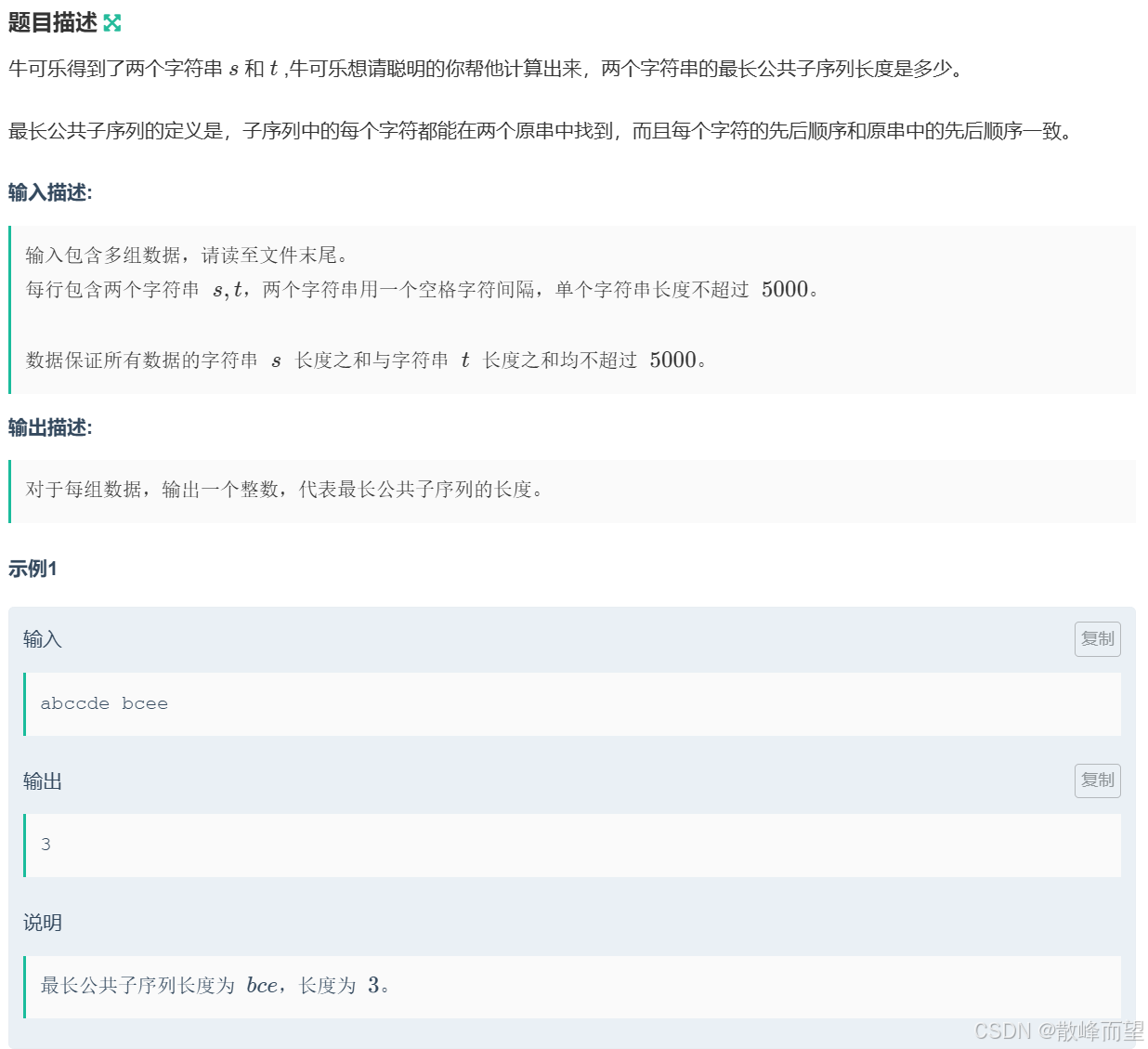
算法原理:
- 状态表示 :
dp[i][j] 表示:s1 的 [1,i] 区间以及 s2 的 [1,j] 区间内的所有的子序列中,最长公共子序列的长度。
那么 dp[n][m] 就是我们要的结果。
- 状态转移方程 :
对于 dp[i][j] ,我们可以根据 s1[i] 与 s2[j] 的字符分情况讨论:
a. 两个字符相同 s1[i] = s2[j] :那么最长公共子序列就在 s1 的 [1,i-1] 以及 s2 的 [1,j-1] 区间上找到一个最长的,然后再加上 s1[i] 即可。因此 dp[i][j] = dp[i-1][j-1] + 1 ;
b. 两个字符不同 s1[i] ≠ s2[j] :那么最长公共子序列一定不会同时以 s1[i] 和 s2[j] 结尾。那么我们找最长公共子序列时,有下面三种策略:
- 去
s1的[1,i-1]以及s2的[1,j]区间内找:此时最大长度为dp[i-1][j]; - 去
s1的[1,i]以及s2的[1,j-1]区间内找:此时最大长度为dp[i][j-1]; - 去
s1的[1,i-1]以及s2的[1,j-1]区间内找:此时最大长度为dp[i-1][j-1]。
我们要三者的最大值即可。但是我们仔细观察会发现,第三种包含在第一种和第二种情况里面,但是我们求的是最大值,并不影响最终结果。因此只需求前两种情况下的最大值即可。
综上,状态转移方程为:
if (s1[i] = s2[j]) dp[i][j] = dp[i-1][j-1] + 1;
if (s1[i] ≠ s2[j]) dp[i][j] = max(dp[i-1][j], dp[i][j-1])。- 初始化 :
直接填表即可。
- 填表顺序 :
根据「状态转移方程」得:从上往下填写每一行,每一行从左往右。
参考代码:
cpp
#include <iostream>
using namespace std;
const int N = 5010;
string s, t;
int f[N][N];
int main()
{
while(cin >> s >> t)
{
int n = s.size(), m = t.size();
for(int i = 1; i <= n; i++)
for(int j = 1; j <= m; j++)
{
if(s[i - 1] == t[j - 1]) f[i][j] = f[i - 1][j - 1] + 1;
else f[i][j] = max(f[i - 1][j], f[i][j - 1]);
}
cout << f[n][m] << endl;
}
return 0;
}2.3.5 编辑距离
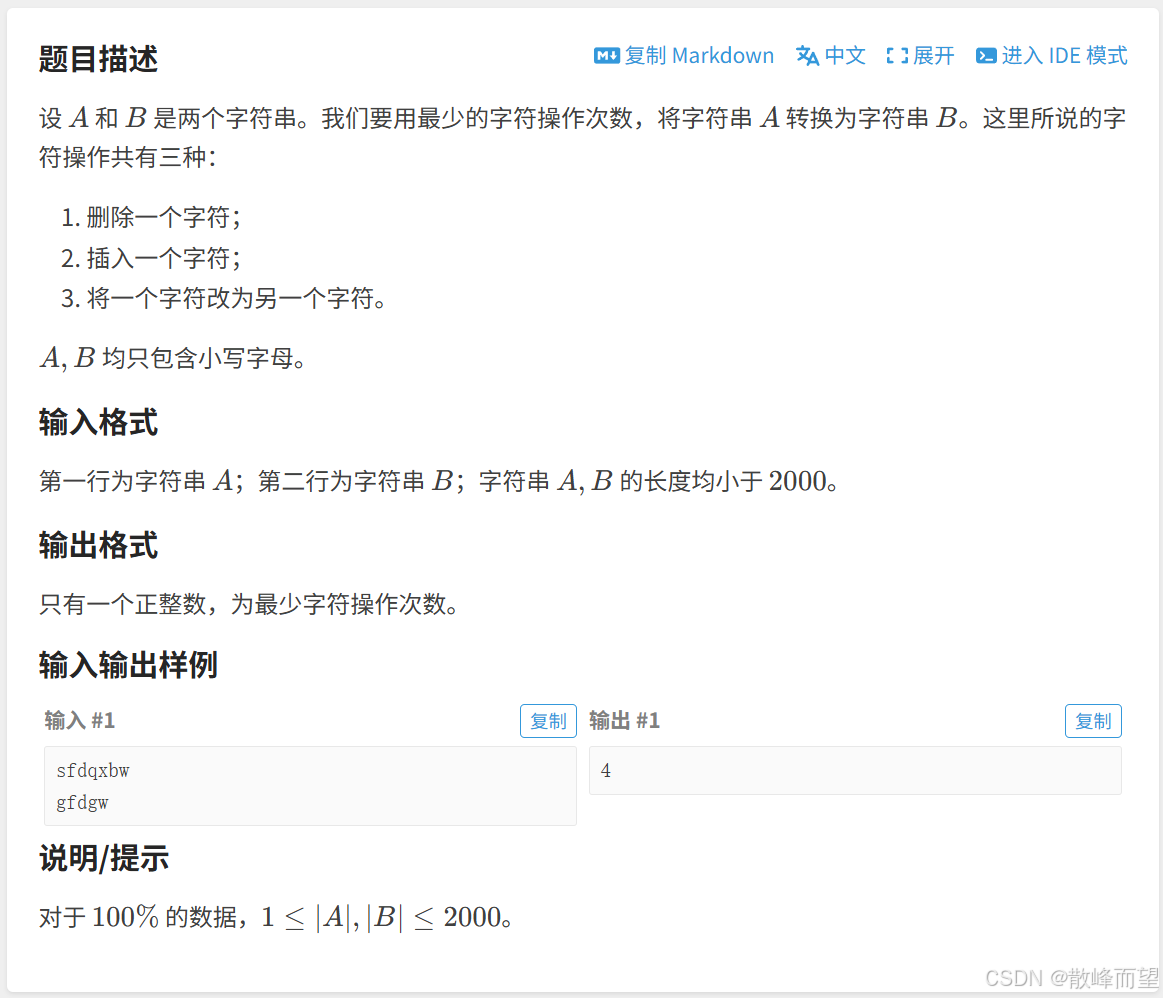
算法原理:
与最长公共子序列的分析方式类似。
- 状态表示:
dp[i][j] 表示:字符串 A 中 [1, i] 区间与字符串 B 中 [1, j] 区间内的编辑距离。
那么 dp[n][m] 就是我们要的结果。
- 状态转移方程:
对于 dp[i][j],我们可以根据 A[i] 与 B[j] 的字符分情况讨论:
a. 两个字符相同 A[i] = B[j]:那么 dp[i][j] 就是 A 的 [1, i-1] 以及 B 的 [1, j-1] 区间内编辑距离,因此 dp[i][j] = dp[i-1][j-1];
b. 两个字符不同 A[i] ≠ B[j]:那么对于 A 字符串,我们可以进行下面三种操作:
-
删除
A[i]:此时dp[i][j]就是 A 的[1, i-1]以及 B 的[1, j]区间内的编辑距离,因此dp[i][j] = dp[i-1][j] + 1; -
插入一个字符:在字符串 A 的后面插入一个
B[j],此时的dp[i][j]就是 A 的[1, i]以及 B 的[1, j-1]区间内的编辑距离,因此dp[i][j] = dp[i][j-1] + 1; -
将
A[i]替换成B[j]:此时的dp[i][j]就是 A 的[1, i-1]以及 B 的[1, j-1]区间内的编辑距离,因此dp[i][j] = dp[i-1][j-1] + 1。
我们要三者的最小值即可。
- 初始化:
需要注意,当 i, j 等于 0 的时候,这些状态也是有意义的。我们可以全部删除,或者全部插入让两者相同。
因此需要初始化第一行 dp[0][j] = j(1 ≤ j ≤ m),第一列 dp[i][0] = i(1 ≤ i ≤ n) 。
- 填表顺序:
初始化完之后,从 [1, 1] 位置开始从上往下每一行,每一行从左往右填表即可。
参考代码:
cpp
#include <iostream>
using namespace std;
const int N = 2010;
string a, b;
int f[N][N];
int main()
{
cin >> a >> b;
int n = a.size(), m = b.size();
a = " " + a, b = " " + b;
//初始化
for(int i = 1; i <= n; i++) f[i][0] = i;
for(int j = 1; j <= m; j++) f[0][j] = j;
for(int i = 1; i <= n; i++)
for(int j = 1; j <= m; j++)
{
if(a[i] == b[j]) f[i][j] = f[i - 1][j - 1];
else f[i][j] = min(min(f[i - 1][j], f[i][j - 1]), f[i - 1][j - 1]) + 1;
}
cout << f[n][m] << endl;
return 0;
}结语
动态规划(Dynamic Programming, DP)是一种通过将复杂问题分解为子问题来优化求解的方法,其核心思想包括状态定义 、状态转移方程 和边界条件。以下是对常见动态规划问题的分类与关键点总结:
从记忆化搜索到动态规划
记忆化搜索(递归+缓存)是动态规划的直观实现方式,通过保存子问题的解避免重复计算。例如:
- 下楼梯问题 :定义
f(n)为到第n阶的方案数,转移方程为f(n) = f(n-1) + f(n-2),边界条件f(0)=1, f(1)=1。 - 数字三角形 :从底层向上递推,
dp[i][j] = max(dp[i+1][j], dp[i+1][j+1]) + triangle[i][j]。
线性动态规划
线性 DP 问题通常按顺序处理状态,典型场景包括:
- 台阶问题:一维状态转移,类似斐波那契数列。
- 最大子段和 :状态定义为以当前元素结尾的最大和,
dp[i] = max(nums[i], dp[i-1] + nums[i])。 - 传球游戏 :环形依赖需处理模运算,状态设计为
dp[step][player]。
路径类动态规划
在网格或矩阵中,路径问题常使用二维状态:
- 矩阵最小路径和 :
dp[i][j] = min(dp[i-1][j], dp[i][j-1]) + grid[i][j]。 - 过河卒:需处理障碍点,状态转移受限。
- 方格取数 :双线程 DP,状态设计为
dp[k][i][j](k为步数)。
经典线性 DP 问题
- 最长上升子序列 (LIS) :
dp[i]表示以i结尾的 LIS 长度,需遍历之前所有元素更新。 - 编辑距离 :状态
dp[i][j]表示字符串前缀的转换代价,分插入、删除、替换三种操作。
动态规划的学习需通过大量练习掌握状态设计的技巧,从简单问题入手逐步理解重叠子问题与最优子结构。实际应用中,需注意空间优化(如滚动数组)和边界条件处理。
愿诸君能一起共渡重重浪,终见缛彩遥分地,繁光远缀天。
