目录
[3.2 内存缓存](#3.2 内存缓存)
[4.1 上下文窗口](#4.1 上下文窗口)
[4.2 Token](#4.2 Token)
[4.5 消息过滤](#4.5 消息过滤)
一.核心组件(Components)

二.消息(Messages)

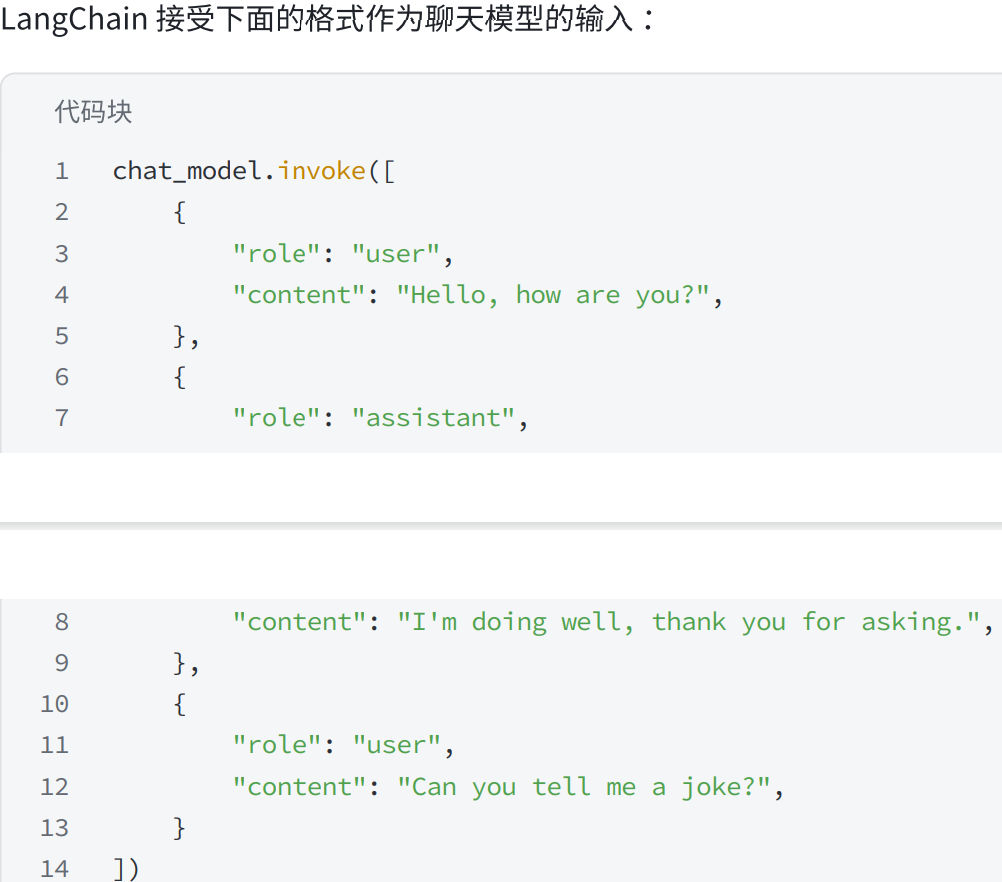
1.LLM消息结构


2.LangChain消息


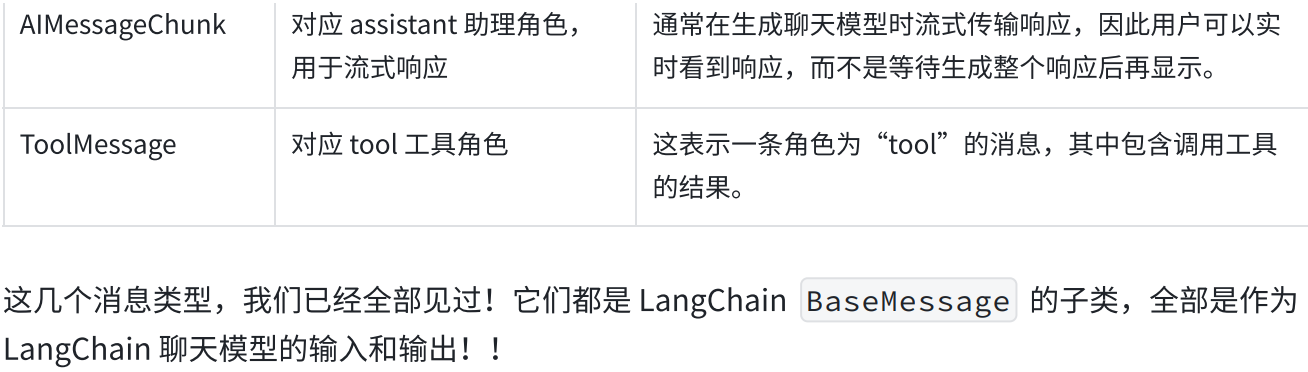
2.1BaseMessage抽象消息类


2.2对话模式

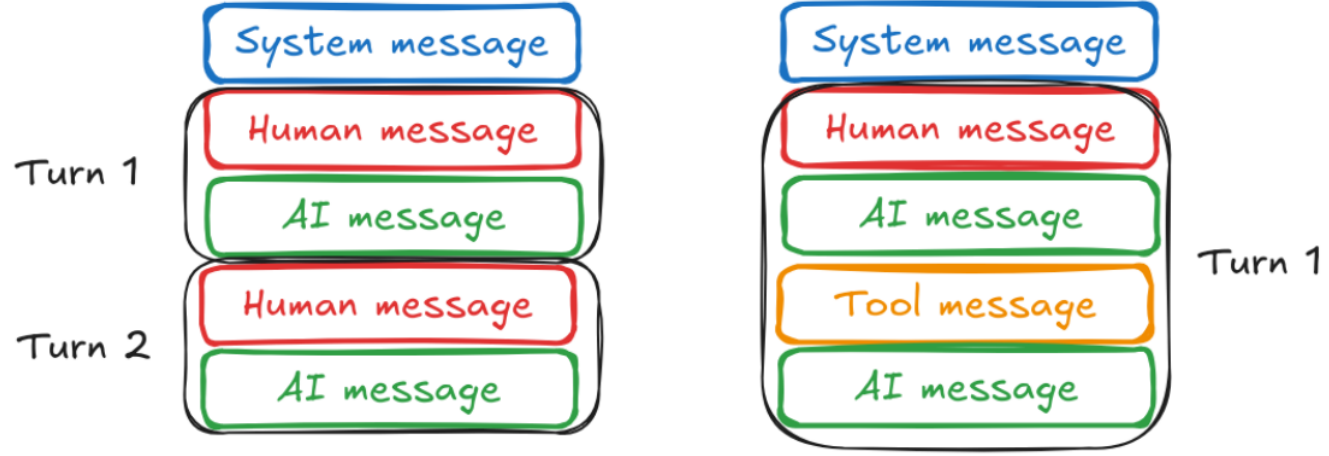
3.缓存历史消息
3.1多轮对话

cpp
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
# 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
# 第一次对话
result = model.invoke([HumanMessage(content="Hi! I'm Bob")])
result.pretty_print()
# 第二次对话
result = model.invoke([HumanMessage(content="What's my name?")])
result.pretty_print()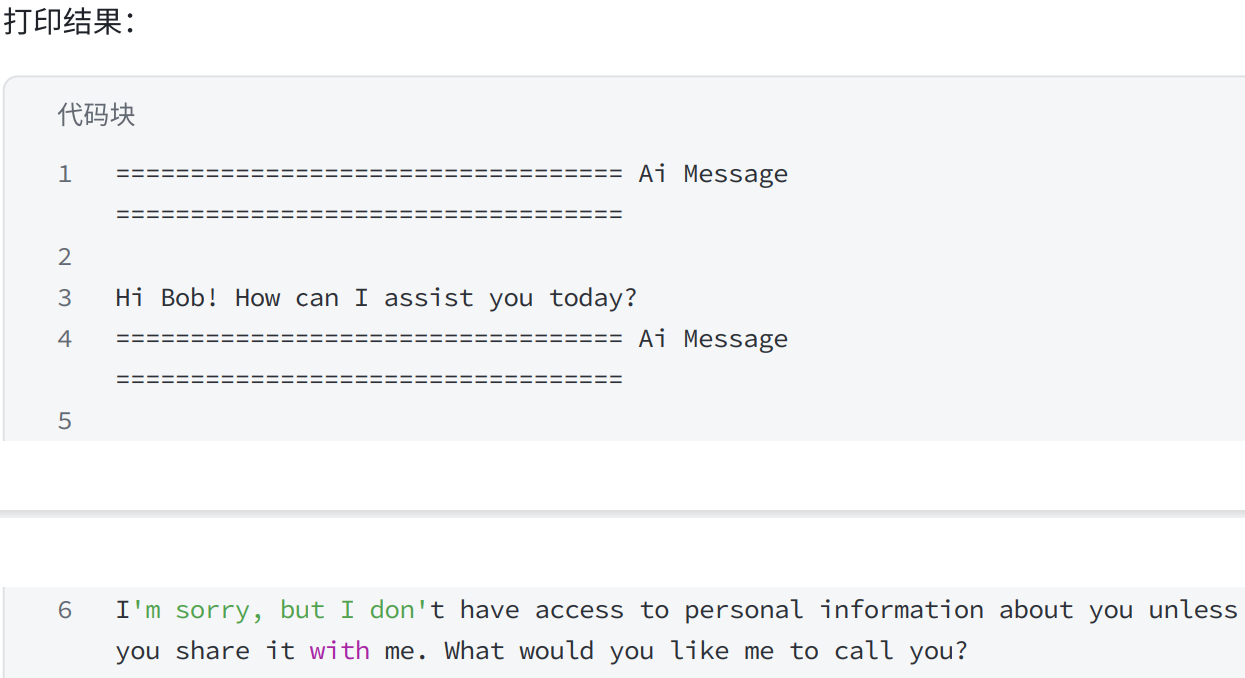

cpp
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage
# 定义⼤模型
model = ChatOpenAI(model="gpt-4o-mini")
# 记录消息
messages = [
HumanMessage(content="Hi! I'm Bob"),
AIMessage(content="Hello Bob! How can I assist you today?"),
HumanMessage(content="What's my name?"),
]
model.invoke(messages).pretty_print()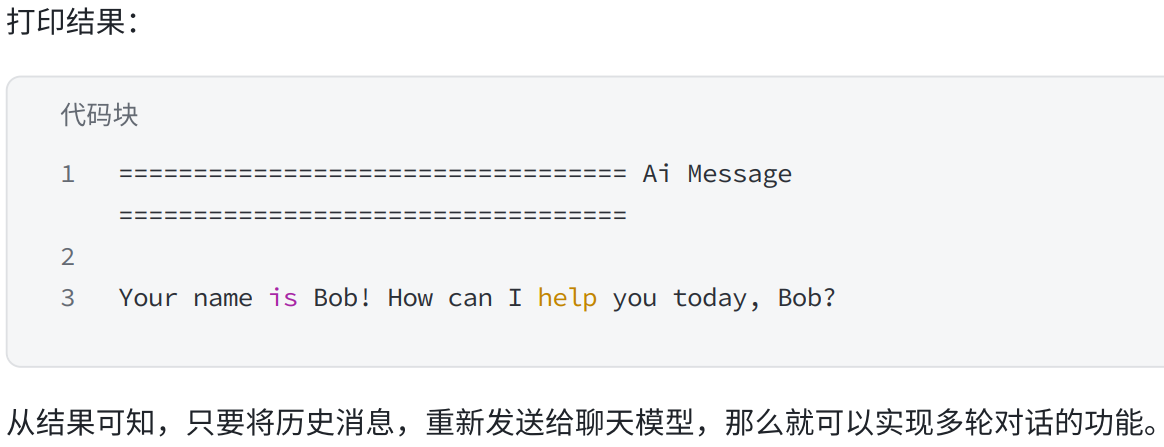
3.2 内存缓存

cpp
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage
from langchain_core.chat_history import BaseChatMessageHistory, InMemoryChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
# 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
store = {}
# 接受一个 session_id 并返回一个消息历史对象。
# 这个 session_id 用于区分不同的对话,并应作为配置的一部分在调用新链时传入
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
# InMemoryChatMessageHistory() 将消息存储在内存列表中。
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
# 包装 model,管理聊天消息历史记录
with_message_history = RunnableWithMessageHistory(model, get_session_history)
config = {"configurable": {"session_id": "1"}}
with_message_history.invoke(
[HumanMessage(content="Hi! I'm Bob")],
config=config,
).pretty_print()
with_message_history.invoke(
[HumanMessage(content="What's my name?")],
config=config,
).pretty_print()


4.管理历史消息
4.1 上下文窗口
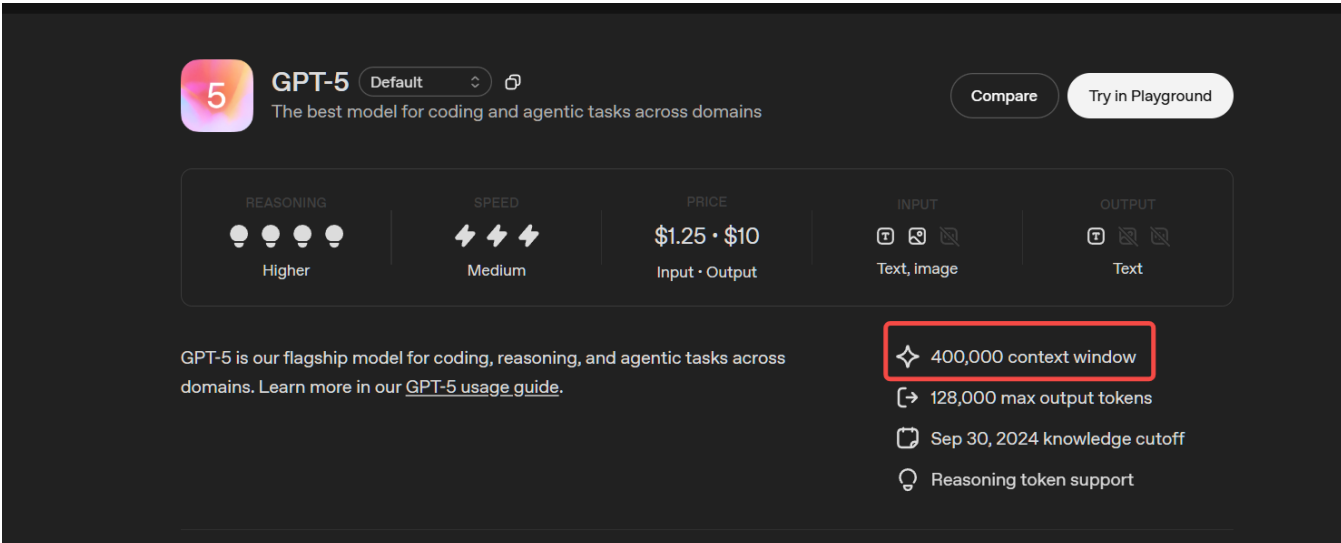
4.2 Token



4.3消息裁剪


cpp
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage, trim_messages
# 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
# 历史消息记录
messages = [
SystemMessage(content="you're a good assistant"),
HumanMessage(content="hi! I'm bob"),
AIMessage(content="hi!"),
HumanMessage(content="I like vanilla ice cream"),
AIMessage(content="nice"),
HumanMessage(content="whats 2 + 2"),
AIMessage(content="4"),
HumanMessage(content="thanks"),
AIMessage(content="no problem!"),
HumanMessage(content="having fun?"),
AIMessage(content="yes!"),
HumanMessage(content="What's my name?"),
]
print(model.invoke(messages))


cpp
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage, trim_messages
# 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
# 历史消息记录
messages = [
SystemMessage(content="you're a good assistant"),
HumanMessage(content="hi! I'm bob"),
AIMessage(content="hi!"),
HumanMessage(content="I like vanilla ice cream"),
AIMessage(content="nice"),
HumanMessage(content="whats 2 + 2"),
AIMessage(content="4"),
HumanMessage(content="thanks"),
AIMessage(content="no problem!"),
HumanMessage(content="having fun?"),
AIMessage(content="yes!"),
HumanMessage(content="What's my name?"),
]
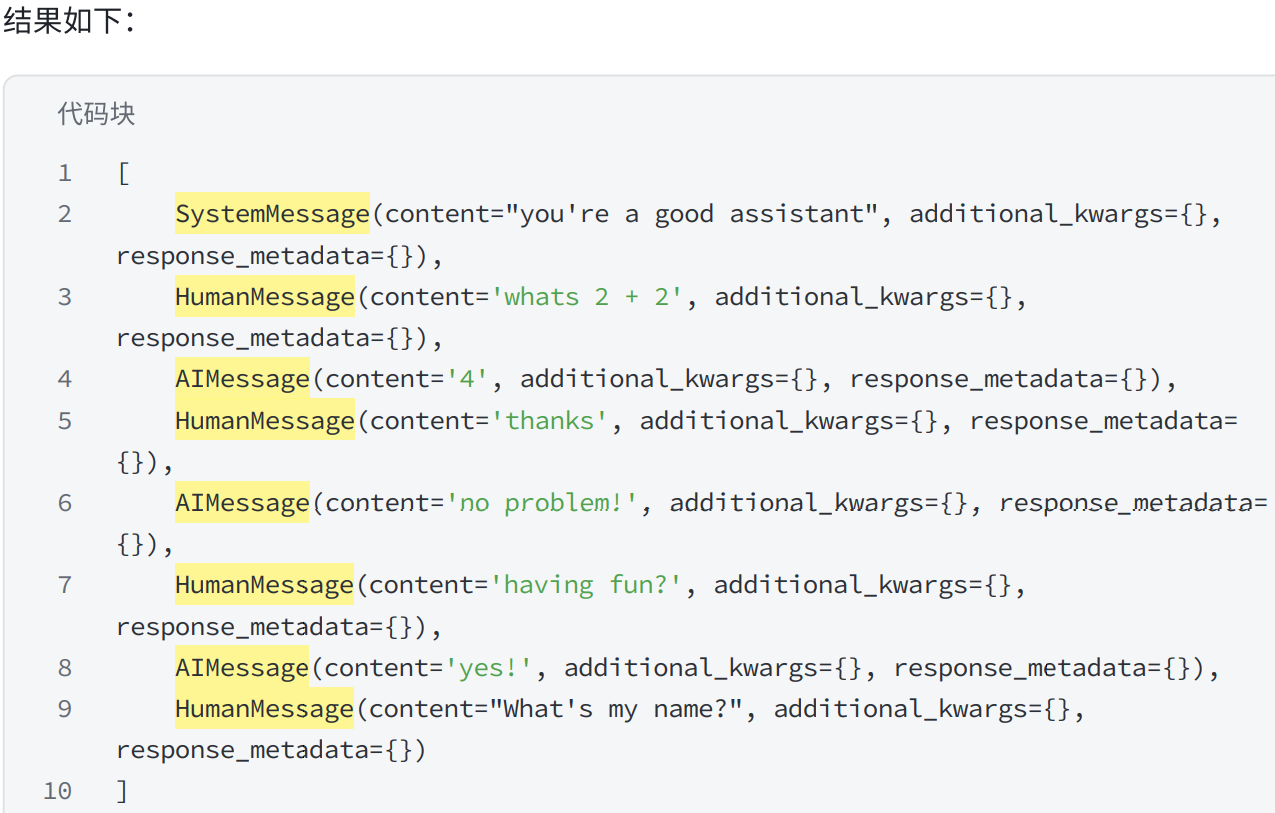
# 使用 trim_messages 减少发送给模型的消息数量
trimmer = trim_messages(
max_tokens=65, # 修剪消息的最大令牌数,根据你想要的谈话长度来调整
strategy="last", # 修剪策略:
# "last" (默认):保留最后的消息。
# "first":保留最早的消息。
token_counter=model, # 传入一个函数或一个语言模型(因为语言模型有消息令牌计数方法)
include_system=True, # 如果想始终保留初始系统消息,可以指定
allow_partial=False, # 是否允许拆分消息的内容
start_on="human" # 如果需要确保我们的第一条消息(不包括系统消息)始终是特定类型,可以指定 start_on
)
chain = trimmer | model
print(chain.invoke(messages))


4.4基于消息数的修剪

cpp
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage, trim_messages
# 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
# 历史消息记录
messages = [
SystemMessage(content="you're a good assistant"),
HumanMessage(content="hi! I'm bob"),
AIMessage(content="hi!"),
HumanMessage(content="I like vanilla ice cream"),
AIMessage(content="nice"),
HumanMessage(content="whats 2 + 2"),
AIMessage(content="4"),
HumanMessage(content="thanks"),
AIMessage(content="no problem!"),
HumanMessage(content="having fun?"),
AIMessage(content="yes!"),
HumanMessage(content="What's my name?"),
]
# 使用 trim_messages 减少发送给模型的消息数量
trimmer = trim_messages(
max_tokens=11, # 最大消息数
strategy="last", # 修剪策略:
# "last"(默认):保留最后的消息。可获取消息列表中的最后一个 max_tokens
# "first":保留最早的消息。
token_counter=len, # 根据消息数裁剪
include_system=True, # 如果想始终保留初始系统消息,可以指定
allow_partial=False, # 是否允许拆分消息的内容
start_on="human", # 如果需要确保我们的第一条消息(不包括系统消息)始终是特定类型,可以指定 start_on
)
print(trimmer.invoke(messages))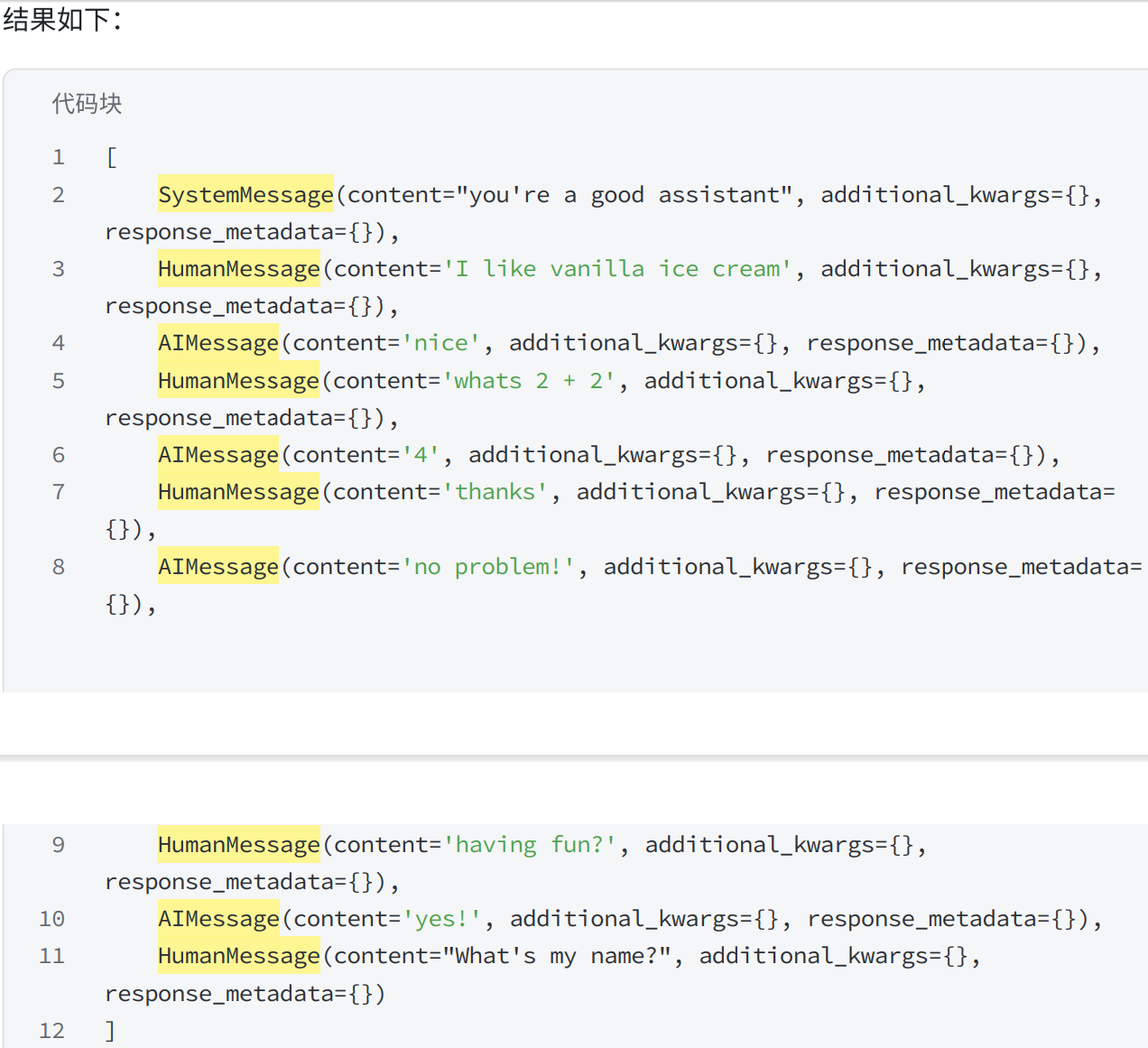
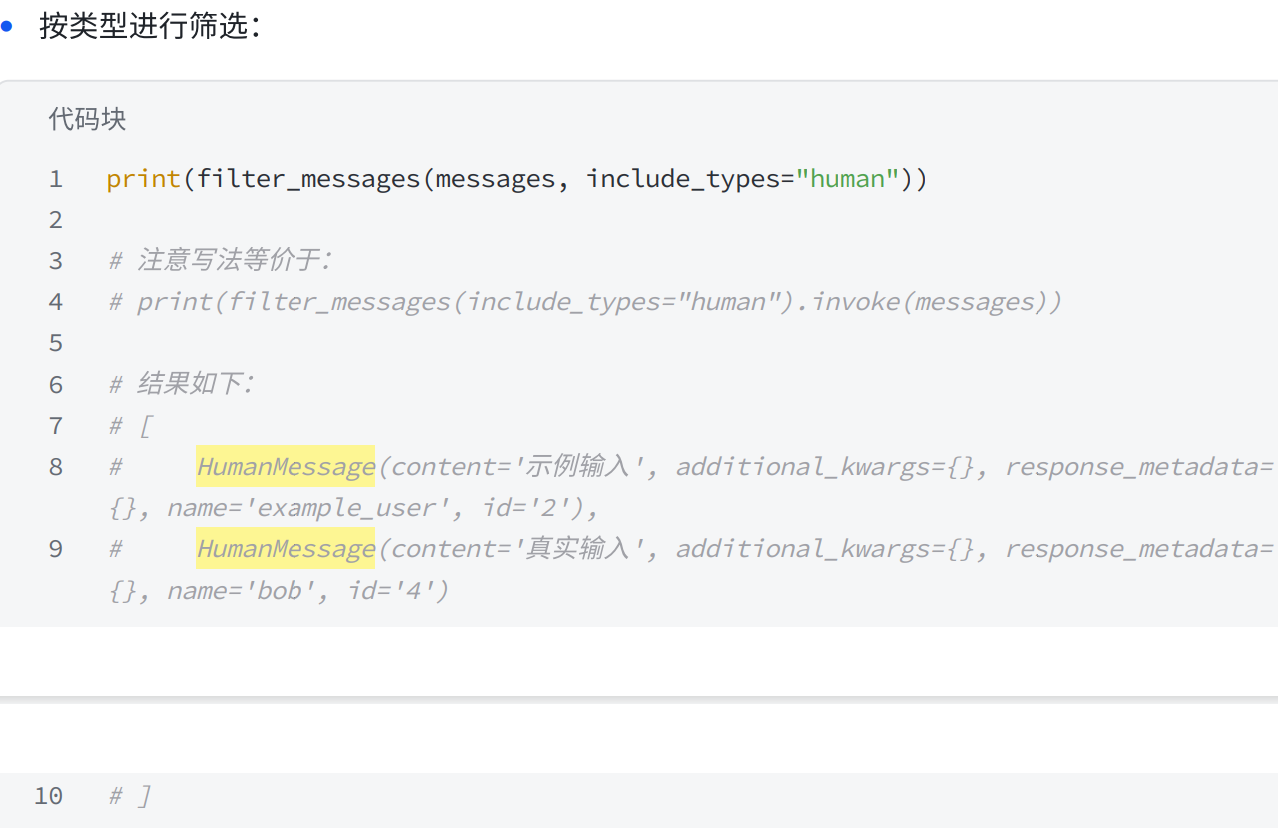
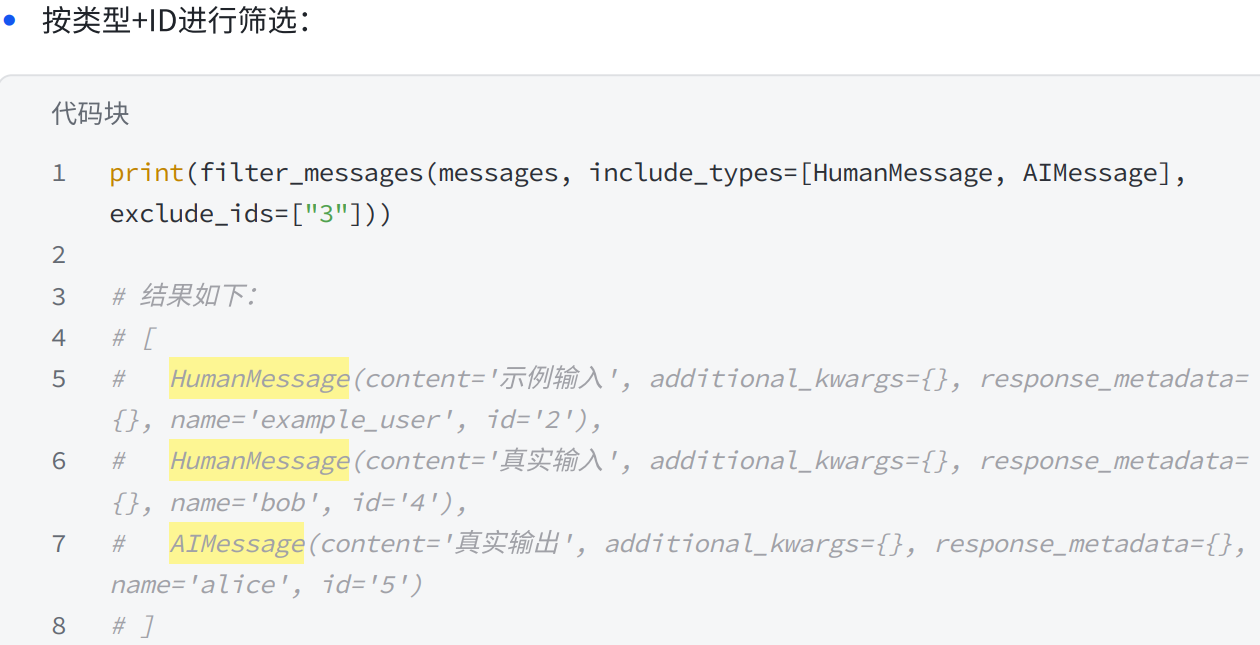
4.5 消息过滤

python
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage,
filter_messages
# 历史消息记录
messages = [
SystemMessage("你是⼀个聊天助⼿", id="1"),
HumanMessage("⽰例输⼊", id="2"),
AIMessage("⽰例输出", id="3"),
HumanMessage("真实输⼊", id="4"),
AIMessage("真实输出", id="5"),
]
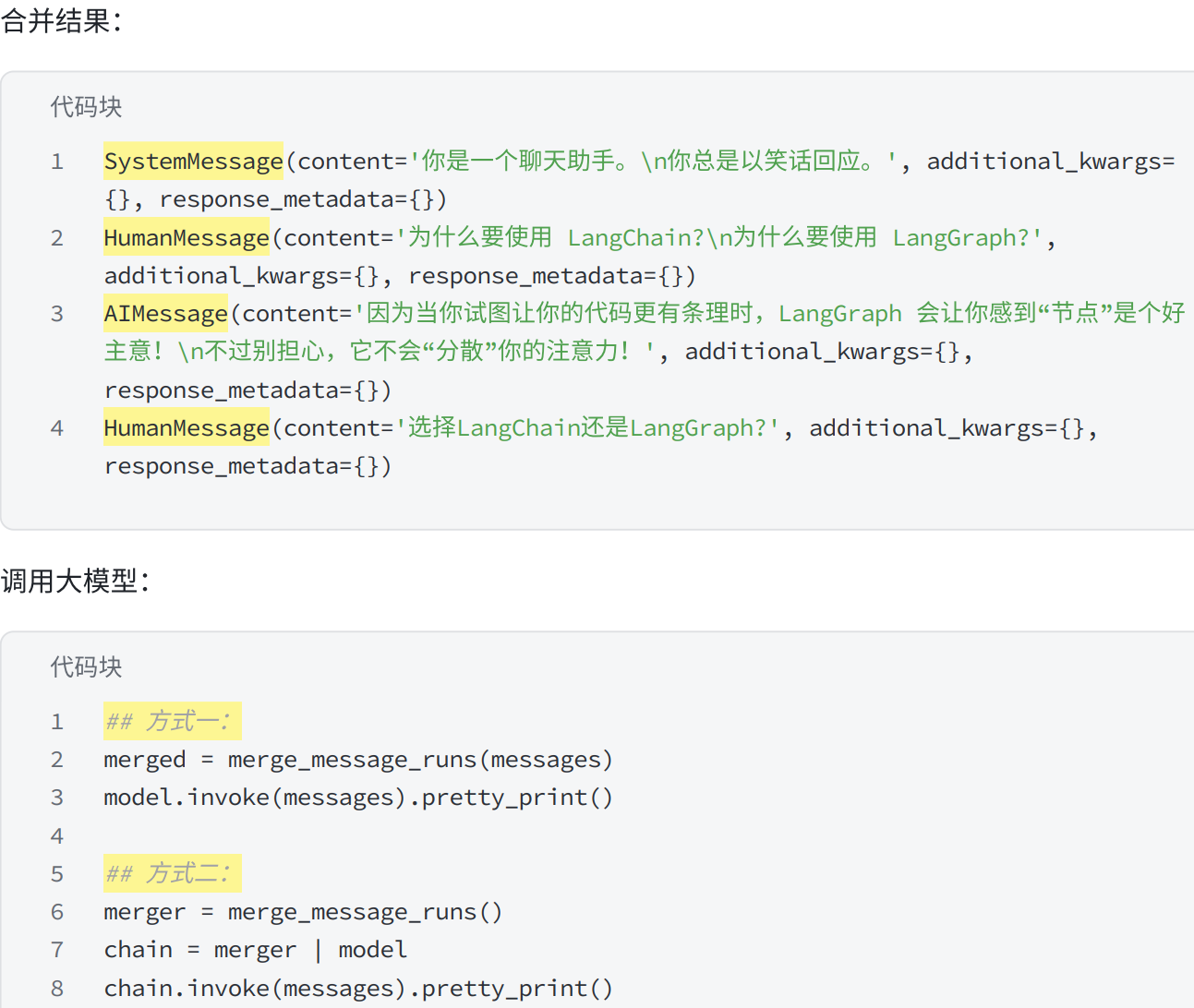
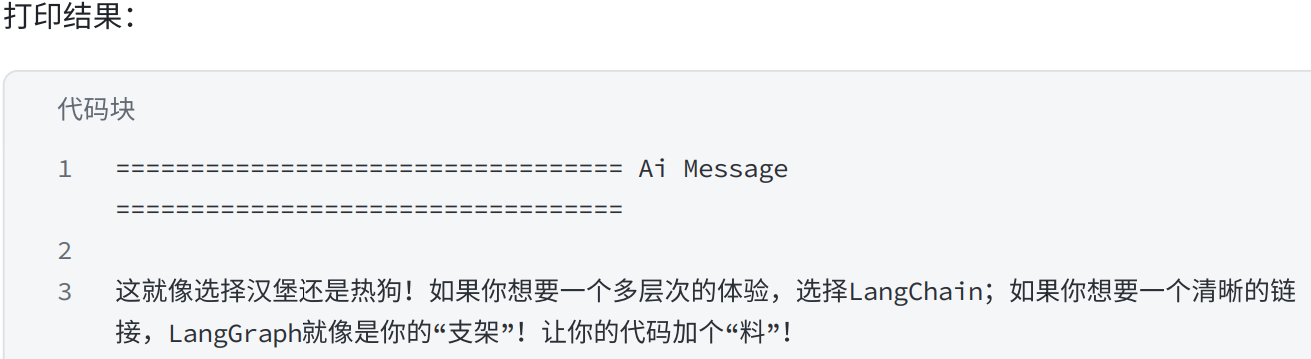
4.6消息合并

python
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage, merge_message_runs
# 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
# 历史消息记录
messages = [
SystemMessage("你是一个聊天助手。"),
SystemMessage("你总是以笑话回应。"),
HumanMessage("为什么要使用 LangChain?"),
HumanMessage("为什么要使用 LangGraph?"),
AIMessage("因为当你试图让你的代码更有条理时,LangGraph 会让你感到"节点"是个好主意!"),
AIMessage("不过别担心,它不会"分散"你的注意力!"),
HumanMessage("选择LangChain还是LangGraph?"),
]
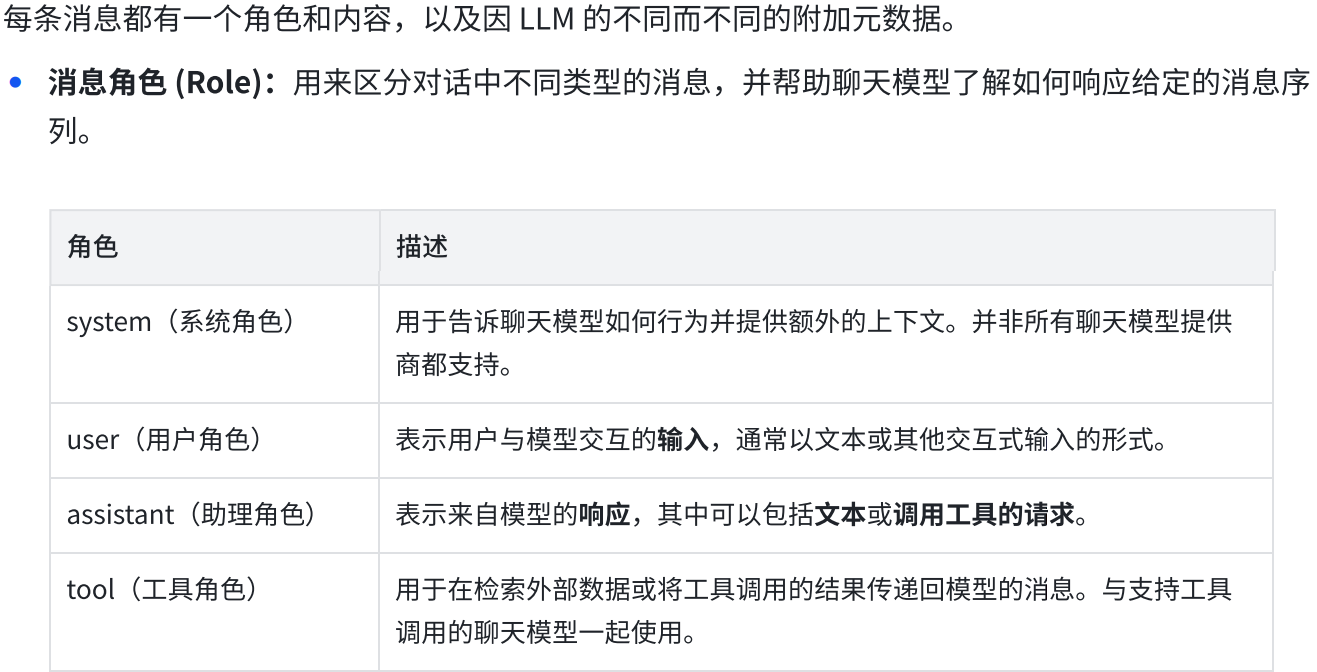
merged = merge_message_runs(messages)
# 打印合并后的每个消息
print("\n".join([repr(x) for x in merged]))