Generative Recommenders, GRs 生成式推荐系统:生成建模框架中的顺序转换任务 sequential transduction tasks
within a generative modeling framework
scaling law扩展法则:生成推荐系统的模型质量随着训练计算的增长而呈幂律扩展
1 引言
DLRM不足
1.扩展性差
2.大规模词汇持续变化
3.计算成本高
核心排序和检索任务可以通过适当的新特征空间重新表述为生成建模问题
贡献
- 生成推荐系统(GRs):排序和检索,重新表述为GR中的纯顺序转换任务,使得模型训练可以以顺序生成的方式进行
- 顺序转换架构------层次化顺序转换单元(HSTU):修改了大规模非静态词汇的注意力机制
- 新的算法M-FALCON:通过微批处理和缓存优化摊销计算成本
2 推荐作为顺序转换任务GR
2.1 统一DLRM中的异质特征空间
将DLRM中大量的分类和连续特征统一编码为时间序列
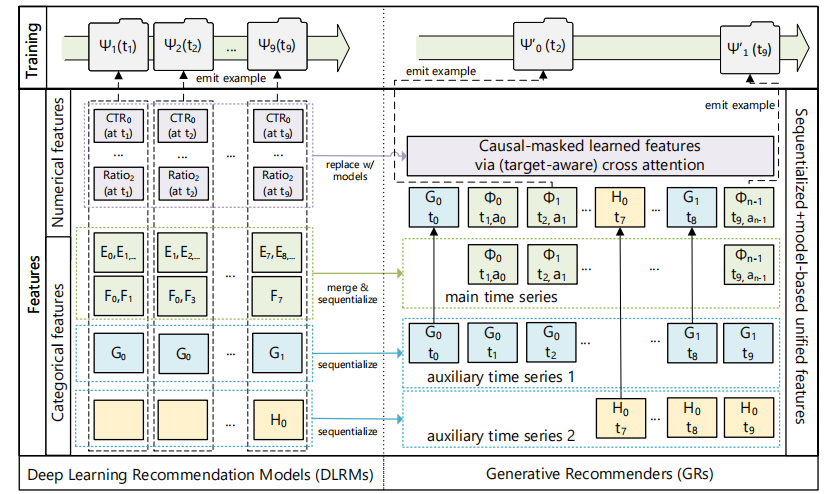
- 分类("稀疏")特征 :将这些特征顺序化为时间序列,选择最长的时间序列(通常是用户交互物品),然后将其余的慢变特征压缩并合并到主时间序列中。
e.g. 用户行为(如喜欢的物品、关注的创作者等)和静态信息(如语言、城市等) - 数值("密集")特征 :由于这些特征变化频繁,无法完全顺序化。通过将分类特征的顺序化处理与目标感知公式结合,GR能够捕捉 这些数值特征,并且可以省略直接处理这些数值特征的需要
- e.g. 计数器、比率、点击率
2.2. 将排序和检索问题重新表述为顺序转换任务
集合X包括所有属性,是个大混杂集合
- 按时间顺序排列的n个token列表x0,x1,...,xn−1,(xi∈X)x_0,x_1,...,x_{n-1} , (x_i \in X)x0,x1,...,xn−1,(xi∈X)
- 对应token观察时间t0,t1,...,tn−1t_0,t_1,...,t_{n-1}t0,t1,...,tn−1
- 输出yi∈X∪∅,y=∅y_i \in X ∪{\emptyset},y={\emptyset}yi∈X∪∅,y=∅表示未定义
- 系统向用户提供的内容ϕi∈Xc(Xc∈X)\phi_i \in X_c (X_c \in X)ϕi∈Xc(Xc∈X)
- 操作ai∈Xa_i \in Xai∈X
- 用户交互的内容总数ncn_cnc
XcX_cXc和XXX是非静态的。用户可以对ϕi\phi_iϕi(图片或视频)执行某些操作aia_iai(点赞、跳过、视频完成+分享等)
-
排序任务 :
输入序列为 xi=Φ0,a0,Φ1,a1,...,Φnc−1,anc−1x_i = \Phi_0, a_0, \Phi_1, a_1, \dots, \Phi_{n_c-1}, a_{n_c-1}xi=Φ0,a0,Φ1,a1,...,Φnc−1,anc−1,
输出序列为 yi=a0,∅,a1,∅,...,anc−1,∅y_i = a_0, \emptyset, a_1, \emptyset, \dots, a_{n_c-1}, \emptysetyi=a0,∅,a1,∅,...,anc−1,∅。
- 通过交替排列物品和操作来解决"目标感知"中交互需要早发生的问题
- 公式化为p(ai+1∣Φ0,a0,Φ1,a1,...,Φi+1)p(a_i+1|\Phi_0,a_0,\Phi_1,a_1,\ldots,\Phi_{i+1})p(ai+1∣Φ0,a0,Φ1,a1,...,Φi+1) (在分类特征之前)。
- 应用一个小型神经网络来将Φi+1\Phi_i+1Φi+1的输出转换为多任务预测。
- 能够在一次处理过程中对所有ncn_cnc次交互应用目标感知的交叉注意力。
-
检索任务 :
输入序列为 xi=(Φ0,a0),(Φ1,a1),...,(Φnc−1,anc−1)x_i = (\Phi_0, a_0), (\Phi_1, a_1), \dots, (\Phi_{n_c-1}, a_{n_c-1})xi=(Φ0,a0),(Φ1,a1),...,(Φnc−1,anc−1),
输出序列为 yi=Φ1′,Φ2′,...,Φnc−1′,∅y_i = \Phi'_1, \Phi'2, \dots, \Phi'{n_c-1}, \emptysetyi=Φ1′,Φ2′,...,Φnc−1′,∅,
其中 Φi′=Φi\Phi'_i = \Phi_iΦi′=Φi 如果 aia_iai 是正向操作,否则 Φi′=∅\Phi'_i = \emptysetΦi′=∅。
- 学习一个分布p(Φi+1∣ui)p(\Phi_{i+1}|u_i)p(Φi+1∣ui),其中Φi+1∈Xc\Phi_{i+1}\in X_cΦi+1∈Xc ,uiu_iui是用户在时刻iii的表示。典型目标是选择argmaxΦ∈Xcp(Φ∣ui)\arg\max_{\Phi\in X_c}p(\Phi|u_i)argmaxΦ∈Xcp(Φ∣ui)来最大化某个奖励。
- 这与标准的自回归设置有两点不同。
- xi,yix_i,y_ixi,yi的监督不一定是Φi+1\Phi_i+1Φi+1,因为用户可能对Φi+1\Phi_{i+1}Φi+1做出负面反应。
- 当xi+1x_{i+1}xi+1代表一个与交互无关的分类特征(如人口统计信息),yiy_iyi是未定义的。