【LLM】第一章:分词算法BPE、WordPiece、Unigram、分词工具jieba
大模型,具体说就是大语言模型,LLM,large language model,所以这个领域其实就是NLP,所以本专栏也是NLP专栏的延续。
在传统NLP领域,第一步就是分词 ,分完词后就可以对词进行文本表示 ,也就是把词变成特征向量 ,然后把特征向量喂入我们前面学的各种序列模型,训练模型,完成分类、回归、生成等任务。本章节讲分词,下一个章节讲特征向量。
一、NLP的常见任务、技术演进
(一)常见任务
NLP是研究如何让计算机理解、生成和处理人类语言(如中文、英文),从而实现人与机器之间的语言交互。所以自然语言处理的常见任务可以分为一下几类:
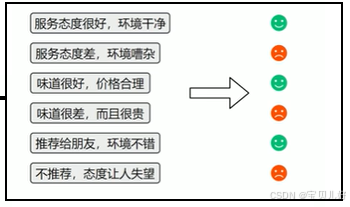
1、文本分类
对整段文本进行判断或归类。
常见应用 :情感分析(判断评价是正面还是负面)、垃圾邮件识别、新闻主题分类等。
技术实现:这其实就是句子级别的分类任务。
2、序列标注
对一段文本中的每个词或字打上标签。
常见应用 :命名实体识别(找出人名、地名、手机号码、邮箱地址等)。
技术实现 :其实就是先对这段文本进行分词,然后对每个词(Token)做分类任务。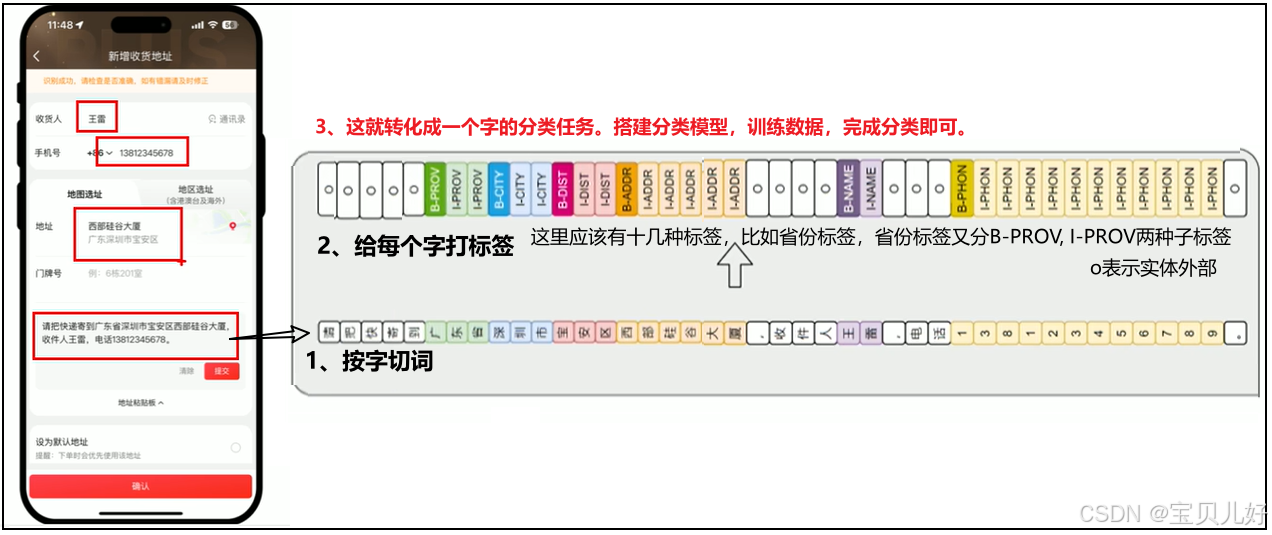
3、文本生成
根据已有内容生成新的文本。
常见应用 :自动写作、摘要生成、智能回复、对话系统等。
技术实现 :将提示词喂入模型,预测出一个token-->提示词+预测的token喂入模型,预测下下一个token-->如此不断重复,就生成了一段新的文本内容。这个过程也叫自回归生成。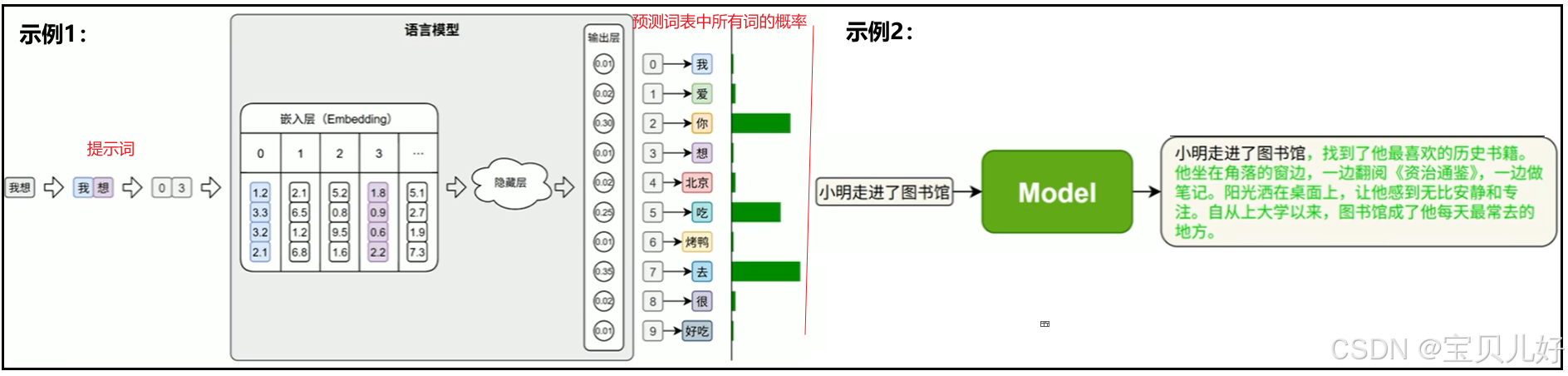
4、信息抽取
从文本中抽取结构化的信息。
常见应用 :给出一段文本和一个问题,从中抽取答案。比如问答系统。问答系统分生成式问答(小标题3)和抽取式问答。抽取式问答就要用到信息抽取。
技术实现 :预测一个序列中的起始位置和结束位置。
5、文本转换
将一种文本转换为另外一种形式。
常见应用 :机器翻译,摘要生成等。
技术实现 :用Transformer来实现。
(二)NLP技术演进历史
1、基于规则阶段
在20实际50年代到80年代初,自然语言处理主要依赖人工手动制定和编写的语言规则,大多都是用if else和一些正则表达式来制定。下面通过两个小例子直观理解一下: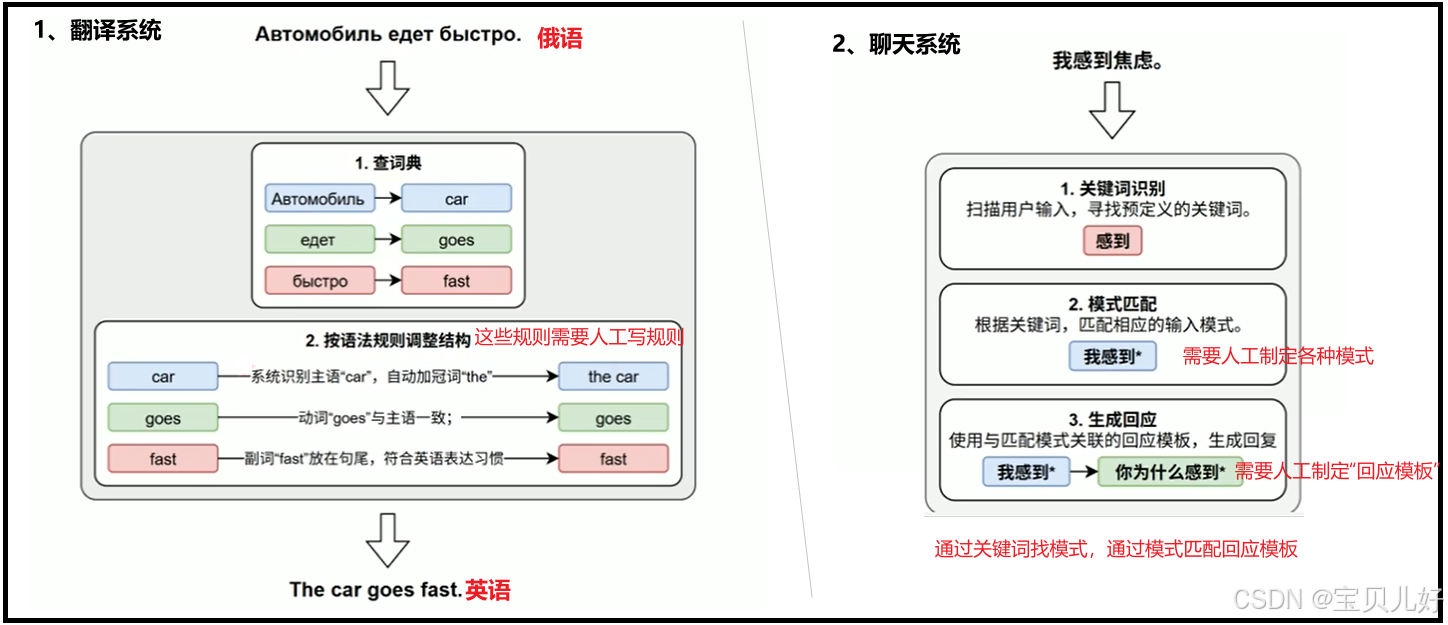
2、统计方法阶段
之所以出现统计方法是因为,到90年代,我们的计算机计算能力 的大幅提升和语料数据 的大量积累,使得统计方法变得可行。人们开始对大量文本数据进行概率建模,让系统学习 语言中的模式和规律。典型的方法有:N-gram模型 、隐马尔可夫模型HMM 、最大熵模型 。这一阶段标志着从专家经验 向数据驱动 方法的转变。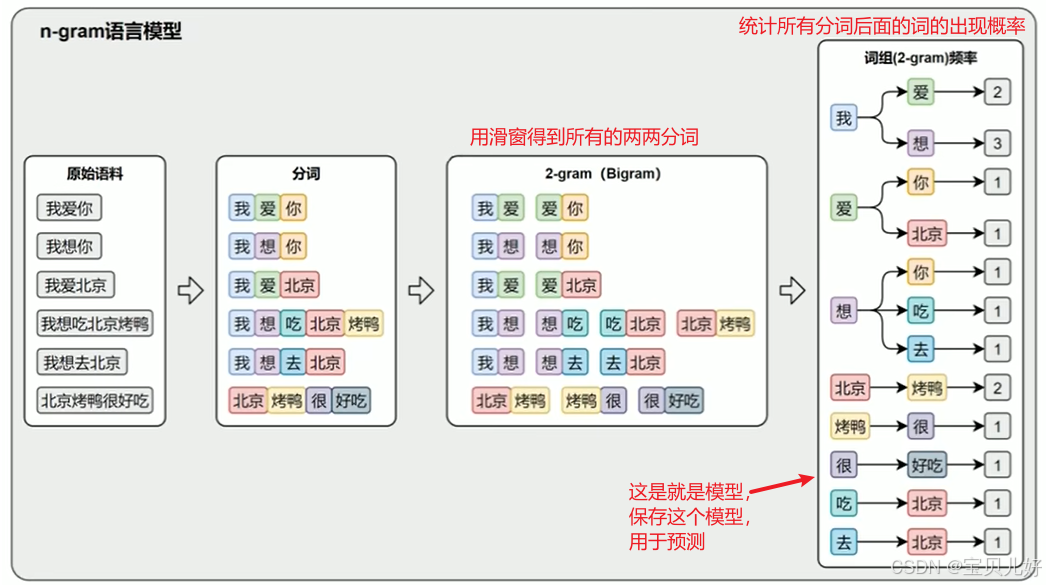 上图是一个2-gram语言模型,就是根据前面的一个词来预测下文的语言模型,根据训练好的下文词出现的概率来预测。3-gram是用滑窗得到所有的三元词组,然后统计所有二元词组后面的词的概率,用这个概率来预测。
上图是一个2-gram语言模型,就是根据前面的一个词来预测下文的语言模型,根据训练好的下文词出现的概率来预测。3-gram是用滑窗得到所有的三元词组,然后统计所有二元词组后面的词的概率,用这个概率来预测。
3、机器学习阶段
进入21世纪,机器学习兴起,比如逻辑回合、支持向量机SVM、决策树、条件随机场CRF等分类模型表现出强大的分类效果。人们将机器学习算法引入NLP,在命名实体识别、文本分类等分类任务上取得了非常好的表现。
但是文本数据在用这些机器学习模型进行分类前,是要先进行分词 、文本表示 后才能喂入模型进行分类的。所以此时特 征工程 成为了关键环节,此时的文本表示主要是词袋模型 :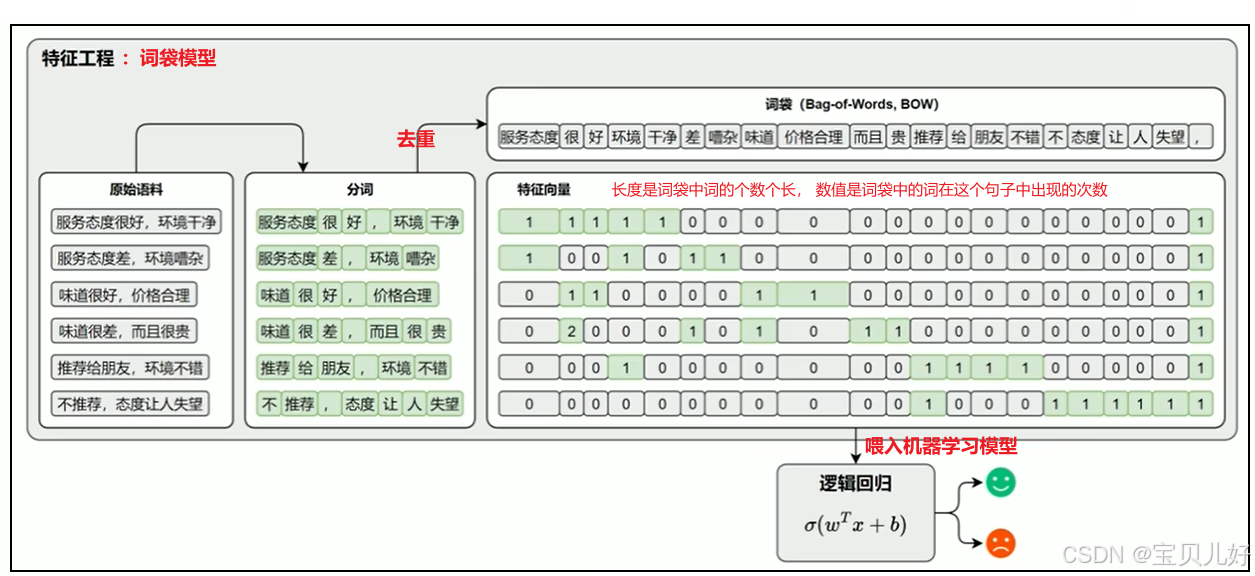 例子中的词袋模型是通过统计词频来表示文本,虽然简单直接,但致命的缺点就是忽略了词语的顺序 。为了解决这个问题,后人又引入了n-gram,就是词袋中不仅有上图中的Token,还有用滑窗得到的n个词组组成的T oken ,也就是增加特征向量的维度来表示更加准确的语义:
例子中的词袋模型是通过统计词频来表示文本,虽然简单直接,但致命的缺点就是忽略了词语的顺序 。为了解决这个问题,后人又引入了n-gram,就是词袋中不仅有上图中的Token,还有用滑窗得到的n个词组组成的T oken ,也就是增加特征向量的维度来表示更加准确的语义: 当然词袋模型后面还有进化,比如td-idf等,这些方法都是古人的智慧结晶,今天仍有价值,后面我会专门用一个篇章来讲词袋模型。
当然词袋模型后面还有进化,比如td-idf等,这些方法都是古人的智慧结晶,今天仍有价值,后面我会专门用一个篇章来讲词袋模型。
4、深度学习阶段
当下的NLP基本就都是深度学习了。前期的基于深度神经网络RNN、LSTM、GRU等模型,能够自动学习文本数据的特征向量。随后的Transformer架构极大的提升了文本数据的理解和生成能力,并推动了当下的预训练语言模型BERT、GPT等大语言模型和迁移学习的发展。
二、分词策略
在大模型领域,分词 是文本预处理中的一个关键步骤,分词的目的 是将文本分解成有意义的单元,以便大模型能够更好地理解和处理。也所以Tokenization是大模型 预处理的核心步骤,也所以分词算法的选择直接影响模型效果。
分词 ,Tokenization,就是将原始文本切分成若干具有独立语义的最小单元(即Token)的过程,是所有NLP任务的起点。
词表 ,Vocabulary, 是由语料库构建出的、包含模型可识别token的集合。词表中的每个token都分配有唯一的ID,并支持token与ID之间的双向映射。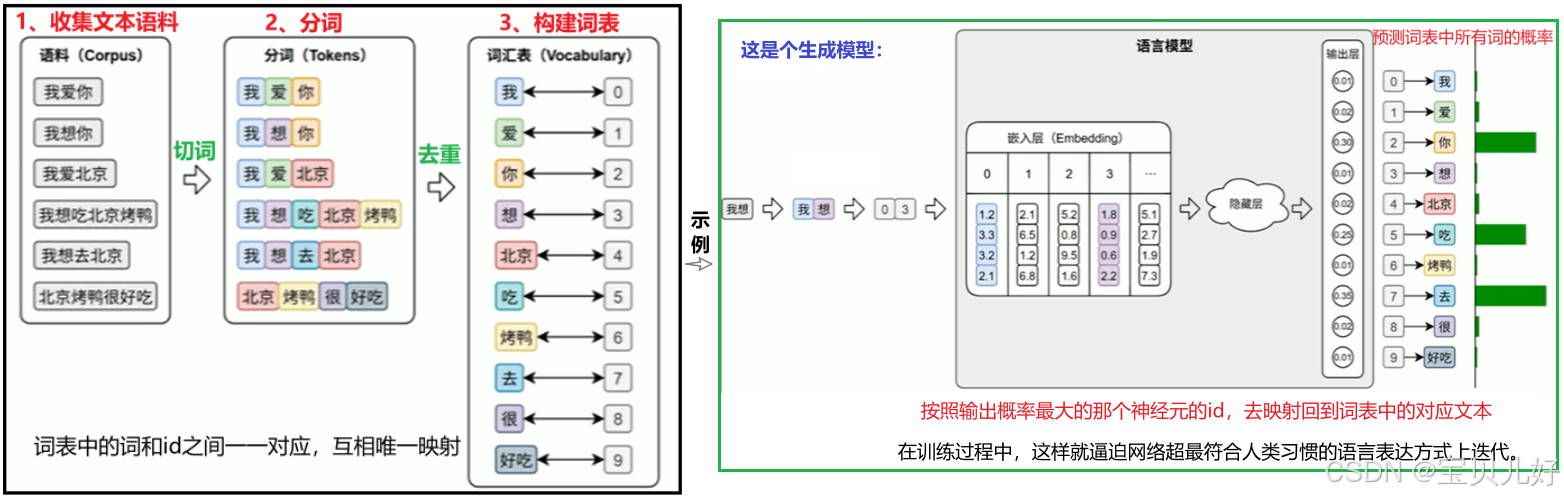 由于不同语言有不同的结构、不同的词边界,所以会有不同的分词策略和分词算法。本部分只介绍中文和英文的分词方式。
由于不同语言有不同的结构、不同的词边界,所以会有不同的分词策略和分词算法。本部分只介绍中文和英文的分词方式。
(一)英文分词
按照分词粒度的大小,可分为词级分词 (word-level)、字符级分词 (character-level)、子词级分词 (subword-level)三种策略,其效果如下: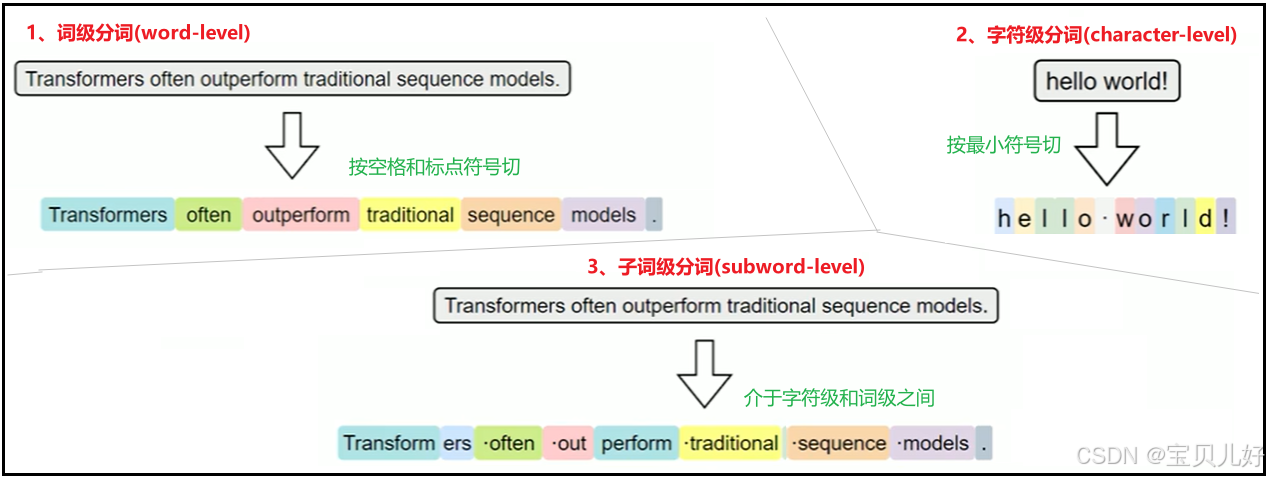 1、词级分词(word-level)
1、词级分词(word-level)
(1)是最简单、传统的分词方式。用空格、标点符号做为分隔符进行分割。
(2)缺点是容易出现OOV问题 (out-of-vocabulary,未登陆词)。什么是OOV问题?就是比如模型在训练阶段 使用的是词表A,但是当模型训练完毕后,模型开始预测 时,喂给模型的文本中有一些词却不在A中,比如一些新词、网络热词、专用名称、复合词等,就非常容易成为OOV。此时模型就无法识别这些词,这些词通常会被统一替换成<\UNK>这个特殊标记,以便模型可以正常跑通。但是如果未登录词较多,就会出现语义信息丢失,影响模型的语义理解和推理能力。
2、字符级分词(character-level)
(1)以单个字符为最小单位进行分词的方法。文本中的每一个字母、数字、标点、空格都会被视为一个独立的token。
(2)这种分词方法下,生成的词表由所有可能出现的字符 组成,因此词表 规模非常小、覆盖率极高,几乎不存在OOV问题 ,因为几乎没有人去重新发明新符号,所以无论什么样的新词,只要它的基本符号不变,它就都能被表示出来。但缺点是:一是单个字符本身携带的语义信息是非常非常少的;二是按找字符分词后的序列就会变得非常非常长。模型必须依赖更长的上下文来推断语义,而上下文序列又巨长,这不仅增加了模型的训练成本,更显著增加了建模难度和模型效果。所以也非常不可取。
3、子词级分词(subword-level)
(1)是介于词级分词和字符级分词之间的分词方法。他将词的词根、前缀、后缀或常见词片段和原词切分开来,形成子词(subword)。比如说单词"looked"和"looking"会被划分为"look","ed","ing",这种把词本身的意思和词的时态分开的做法,不仅在降低词表大小的同时,还能学到词的更多语意信息。
(2)与词级分词相比,子词分词可以显著缓解OOV问题。与字符级分词相比,分词后的序列不会过长。一个新词即使没有出现在词表中,但只要它可以被拆分成子词单元,就可以被模型识别和表示,从而避免了被整体替换成<\UNK>。所以现在的比如BERT、GPT等模型都采用的是子词分词。
(3)常见的子词分词算法有:BPE (Byte Pair Encoding,基于频率合并)、WordPiece (基于似然增益合并)、Unigram(自顶向下概率筛选)等。比如GPT2采用的是BPE算法、Bert采用的是WordPiece算法。下面先简单看一下BPE的效果:
网站 https://tiktokenizer.vercel.app/ 提供了一个名为Tiktokenizer 的工具。该工具是一个用于分词(tokenize)的应用程序,可以将输入的文本按照语言规则划分成单个的标记(tokens)。下面展示一下从这个网站查询的BPE算法的分词效果: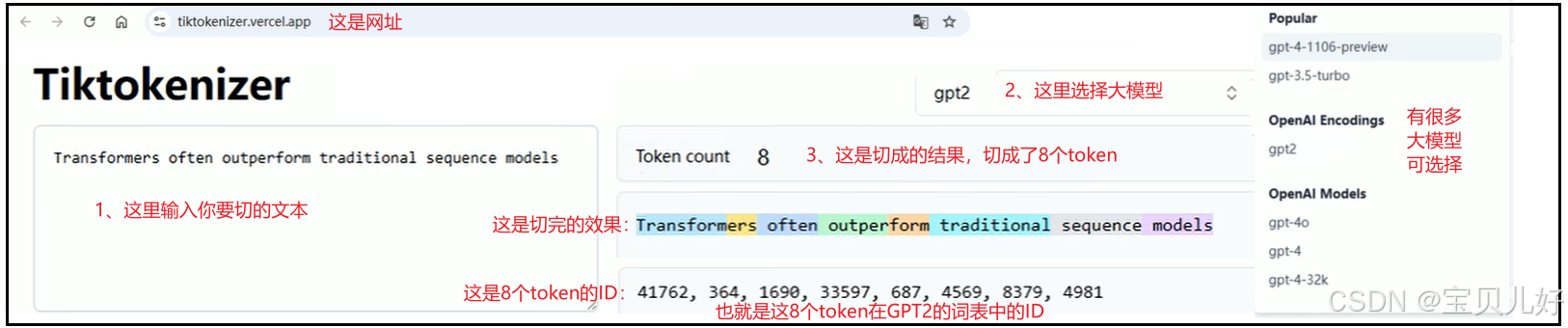 BPE是如何做到这么智能,能分清前缀、后缀、合成词等的?后面我们会对上面这些分词算法展开详细讲解。
BPE是如何做到这么智能,能分清前缀、后缀、合成词等的?后面我们会对上面这些分词算法展开详细讲解。
(二)中文分词 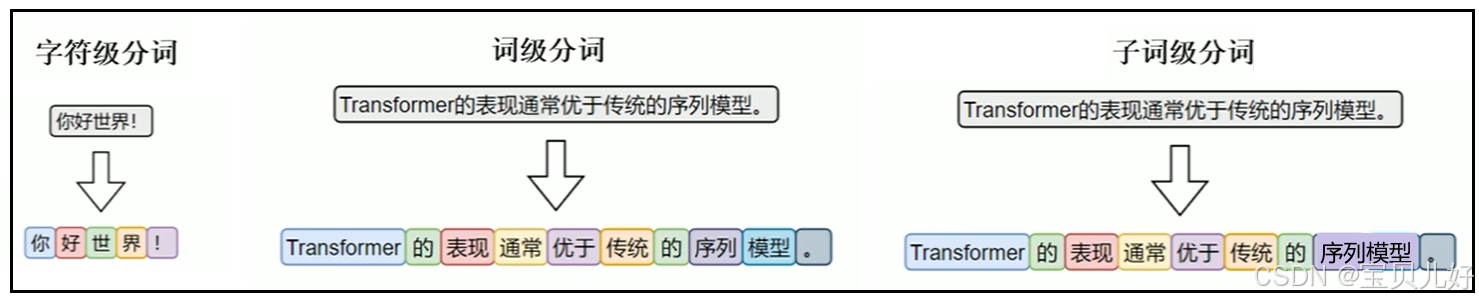 中文没有空格这种天然的词边界,所以分词方式和英文还是有些区别的。姑且按照英文的分类:
中文没有空格这种天然的词边界,所以分词方式和英文还是有些区别的。姑且按照英文的分类:
中文字符级分词,就是按照单个汉字进行切分,文本中每个汉字都被视作一个token。这种方法最简单,而且某些场合下非常有用,比如古诗词,比较适合这样分词,因为汉字本身就具有独立语义。
中文的词级分词 和子词级分词 其实是一样的,因为中文没有前缀后缀词根等这种字词结构。所以中文的词级分词和子词级分词通常依赖提前整理的字典、规则或模型来识别词语边界。
但是BPE算法是可以直接应用于中文的。以汉字为基本单位,通过学习语料中高频的字组合(比如'自然'、'语言'、'处理'),自动构建字词词表。这种方式无需人工字典,具有较强的适应能力。当前主流的中文大模型,比如通义千问、DeepSeek等,都采用的是子词分词策略。
三、分词算法
1、BPE (Byte Pair Encoding)
BPE,字节对编码,最初被开发为一种压缩文本的算法,随后在预训练PGT模型时被OpenAI用于tokenization。许多Transforer模型都使用它,包括GPT、BERT、BART、RoBERTa、DeBERTa。其核心思想是从最小的词元(如字符)开始,逐步合并出现频率最高的连续词元对,直到达到预定的词表大小 或不再有可 以合并的连续对 。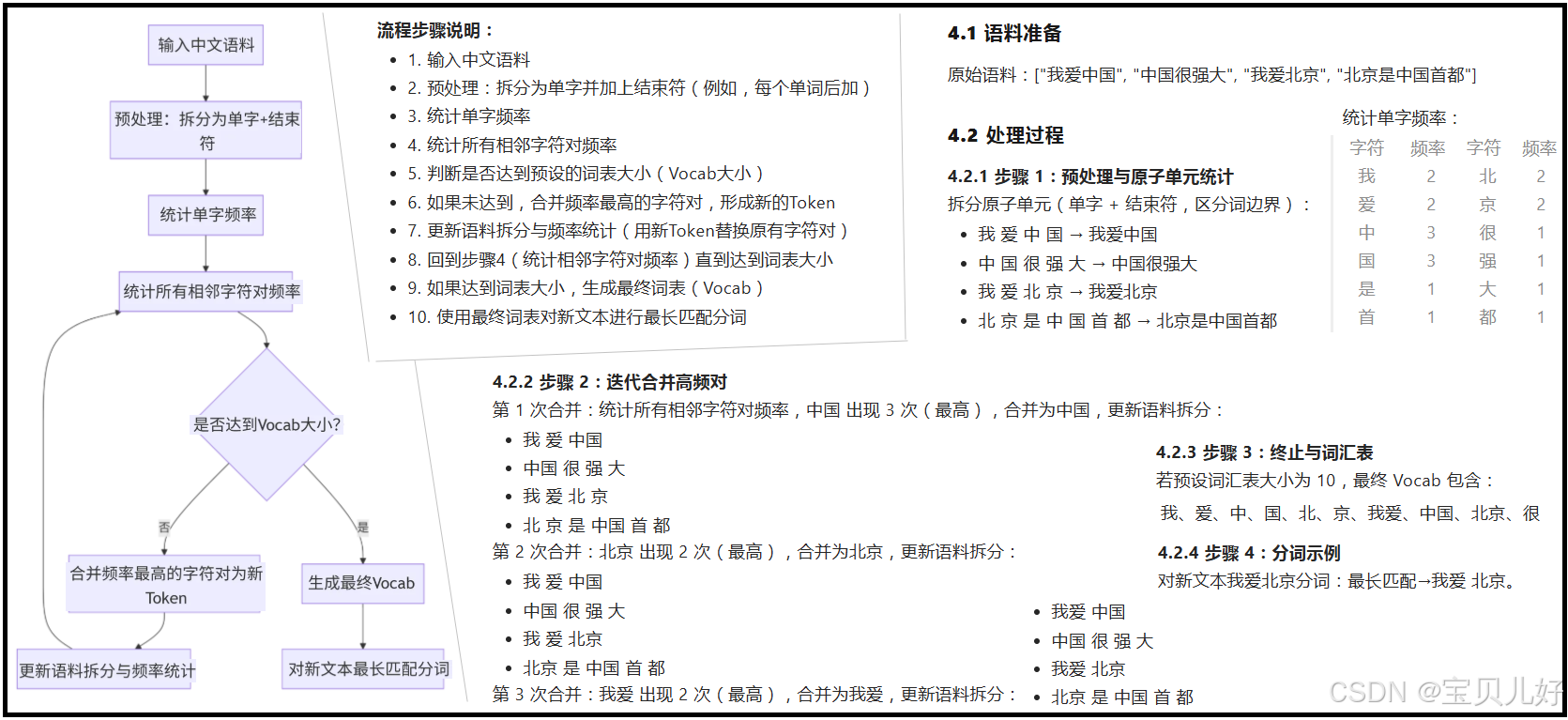
python
import re
from collections import defaultdict, Counter
class BPEChineseTokenizer:
def __init__(self, vocab_size=10):
self.vocab_size = vocab_size # 目标词汇表大小
self.vocab = {} # 最终词汇表
self.merge_rules = {} # 合并规则((a,b) → ab)
def preprocess(self, corpus):
"""预处理:拆分为单字+结束符,统一格式"""
processed = []
for sentence in corpus:
# 中文单字拆分,每个字后加</w>,词之间用空格分隔(这里按句子拆分)
tokens = [char + '</w>' for char in sentence]
processed.append(' '.join(tokens))
return processed
def get_pair_freq(self, corpus):
"""统计相邻字符对的频率"""
pair_freq = defaultdict(int)
for sentence in corpus:
tokens = sentence.split()
for i in range(len(tokens)-1):
pair = (tokens[i], tokens[i+1])
pair_freq[pair] += 1
return pair_freq
def merge_pair(self, corpus, pair, new_token):
"""合并语料中的指定字符对"""
merged_corpus = []
pattern = re.escape(f' {pair[0]} {pair[1]} ')
replacement = f' {new_token} '
for sentence in corpus:
# 替换所有匹配的字符对
merged_sentence = re.sub(pattern, replacement, f' {sentence} ').strip()
merged_corpus.append(merged_sentence)
return merged_corpus
def train(self, corpus):
"""训练BPE分词器"""
# 预处理语料
processed_corpus = self.preprocess(corpus)
# 初始化词汇表:所有单字
all_tokens = []
for sentence in processed_corpus:
all_tokens.extend(sentence.split())
initial_vocab = list(set(all_tokens))
self.vocab = {token: idx for idx, token in enumerate(initial_vocab)}
# 迭代合并直到达到词汇表大小
while len(self.vocab) < self.vocab_size:
# 统计字符对频率
pair_freq = self.get_pair_freq(processed_corpus)
if not pair_freq:
break # 无可用合并对
# 找频率最高的对
best_pair = max(pair_freq, key=pair_freq.get)
# 生成新Token
new_token = ''.join(best_pair).replace('</w>', '') + '</w>'
# 记录合并规则
self.merge_rules[best_pair] = new_token
# 合并语料中的该对
processed_corpus = self.merge_pair(processed_corpus, best_pair, new_token)
# 更新词汇表
if new_token not in self.vocab:
self.vocab[new_token] = len(self.vocab)
print("BPE训练完成!")
print("合并规则:", self.merge_rules)
print("最终词汇表:", self.vocab)
def tokenize(self, text):
"""对新文本分词"""
# 预处理文本为单字
tokens = [char + '</w>' for char in text]
# 应用合并规则(从长到短匹配)
# 先将合并规则按新Token长度降序排序
sorted_merges = sorted(self.merge_rules.items(),
key=lambda x: len(x[1]), reverse=True)
# 迭代合并
while True:
merged = False
for (pair, new_token) in sorted_merges:
if pair[0] in tokens and pair[1] in tokens:
# 找到相邻的pair
idx = tokens.index(pair[0])
if idx + 1 < len(tokens) and tokens[idx+1] == pair[1]:
# 合并
tokens = tokens[:idx] + [new_token] + tokens[idx+2:]
merged = True
break
if not merged:
break
# 转换为词汇表ID
token_ids = [self.vocab.get(token, -1) for token in tokens]
return tokens, token_ids
# 测试代码
if __name__ == "__main__":
# 中文语料
corpus = ["我爱中国", "中国很强大", "我爱北京", "北京是中国首都"]
# 初始化并训练BPE分词器
bpe_tokenizer = BPEChineseTokenizer(vocab_size=15)
bpe_tokenizer.train(corpus)
# 分词测试
test_text = "我爱北京"
tokens, token_ids = bpe_tokenizer.tokenize(test_text)
print(f"\n测试文本:{test_text}")
print(f"分词结果:{tokens}")
print(f"Token ID:{token_ids}")2、WordPiece分词
WordPiece与BPE类似,也是从字符开始,迭代合并子词。但合并的标准不是频率,而是合并后对语言模型似然的提升,即合并后的 Token 能最大程度提升整体语料的概率。具体来说,每次选择合并后能最大程度增加语言模型似然的词元对。 WordPiece的合并标准是增益最大化,对增益这个指标的理解可以参考我曾写过的一篇博文: https://blog.csdn.net/friday1203/article/details/135084711 ,这篇博文是讲决策树算法的,其核心指标就是信息增益,看完后你就会豁然开朗的。
WordPiece的合并标准是增益最大化,对增益这个指标的理解可以参考我曾写过的一篇博文: https://blog.csdn.net/friday1203/article/details/135084711 ,这篇博文是讲决策树算法的,其核心指标就是信息增益,看完后你就会豁然开朗的。
python
import re
import math
from collections import defaultdict, Counter
class WordPieceChineseTokenizer:
def __init__(self, vocab_size=10):
self.vocab_size = vocab_size
self.vocab = {}
self.merge_rules = {}
self.token_freq = defaultdict(int) # Token频率
def preprocess(self, corpus):
"""预处理:拆分为单字+结束符"""
processed = []
total_tokens = 0
for sentence in corpus:
tokens = [char + '</w>' for char in sentence]
processed.append(' '.join(tokens))
# 统计初始Token频率
for token in tokens:
self.token_freq[token] += 1
total_tokens += len(tokens)
self.total_tokens = total_tokens # 总Token数
return processed
def calculate_gain(self, a, b, corpus):
"""计算合并(a,b)的对数似然增益"""
# 统计a、b、ab的频率
a_freq = self.token_freq.get(a, 0)
b_freq = self.token_freq.get(b, 0)
# 统计ab的共现频率
ab_freq = 0
for sentence in corpus:
tokens = sentence.split()
for i in range(len(tokens)-1):
if tokens[i] == a and tokens[i+1] == b:
ab_freq += 1
if a_freq == 0 or b_freq == 0 or ab_freq == 0:
return -float('inf') # 无增益
# 计算概率
p_a = a_freq / self.total_tokens
p_b = b_freq / self.total_tokens
p_ab = ab_freq / (self.total_tokens - ab_freq) # 合并后总Token数减少ab_freq
# 对数似然增益
gain = math.log(p_ab) - math.log(p_a) - math.log(p_b)
return gain
def merge_pair(self, corpus, pair, new_token):
"""合并语料中的指定字符对"""
merged_corpus = []
pattern = re.escape(f' {pair[0]} {pair[1]} ')
replacement = f' {new_token} '
for sentence in corpus:
merged_sentence = re.sub(pattern, replacement, f' {sentence} ').strip()
merged_corpus.append(merged_sentence)
# 更新Token频率
a, b = pair
ab_freq = self.token_freq.get(a, 0) + self.token_freq.get(b, 0) - (self.token_freq.get(new_token, 0))
self.token_freq[new_token] = ab_freq
del self.token_freq[a]
del self.token_freq[b]
self.total_tokens -= ab_freq # 总Token数减少
return merged_corpus
def train(self, corpus):
"""训练WordPiece分词器"""
processed_corpus = self.preprocess(corpus)
# 初始化词汇表
initial_vocab = list(self.token_freq.keys())
self.vocab = {token: idx for idx, token in enumerate(initial_vocab)}
while len(self.vocab) < self.vocab_size:
# 生成所有候选字符对
candidate_pairs = set()
for sentence in processed_corpus:
tokens = sentence.split()
for i in range(len(tokens)-1):
candidate_pairs.add((tokens[i], tokens[i+1]))
if not candidate_pairs:
break
# 计算每个候选对的增益
gains = {}
for pair in candidate_pairs:
gain = self.calculate_gain(pair[0], pair[1], processed_corpus)
gains[pair] = gain
# 找增益最高的对
best_pair = max(gains, key=gains.get)
best_gain = gains[best_pair]
if best_gain <= 0:
break # 增益≤0,停止合并
# 生成新Token
new_token = ''.join(best_pair).replace('</w>', '') + '</w>'
self.merge_rules[best_pair] = new_token
# 合并语料
processed_corpus = self.merge_pair(processed_corpus, best_pair, new_token)
# 更新词汇表
if new_token not in self.vocab:
self.vocab[new_token] = len(self.vocab)
print("WordPiece训练完成!")
print("合并规则:", self.merge_rules)
print("最终词汇表:", self.vocab)
def tokenize(self, text):
"""分词(最长匹配)"""
tokens = [char + '</w>' for char in text]
# 按新Token长度降序应用合并规则
sorted_merges = sorted(self.merge_rules.items(),
key=lambda x: len(x[1]), reverse=True)
while True:
merged = False
for (pair, new_token) in sorted_merges:
if pair[0] in tokens and pair[1] in tokens:
idx = tokens.index(pair[0])
if idx + 1 < len(tokens) and tokens[idx+1] == pair[1]:
tokens = tokens[:idx] + [new_token] + tokens[idx+2:]
merged = True
break
if not merged:
break
token_ids = [self.vocab.get(token, -1) for token in tokens]
return tokens, token_ids
# 测试代码
if __name__ == "__main__":
corpus = ["我爱中国", "中国很强大", "我爱北京", "北京是中国首都"]
wp_tokenizer = WordPieceChineseTokenizer(vocab_size=10)
wp_tokenizer.train(corpus)
# 分词测试
test_text = "中国很强大"
tokens, token_ids = wp_tokenizer.tokenize(test_text)
print(f"\n测试文本:{test_text}")
print(f"分词结果:{tokens}")
print(f"Token ID:{token_ids}")3、Unigram分词
Unigram分词与BPE和WordPiece相反,它从一个大的种子词表开始,然后逐步删除词元,直到达到目标词表大小。它基于一个假设:所有词元的出现是独立的,并且通过最大化句子的似然来优化词表。

python
import math
from collections import defaultdict, Counter
from itertools import combinations
class UnigramChineseTokenizer:
def __init__(self, vocab_size=10):
self.vocab_size = vocab_size
self.vocab = {}
self.token_prob = defaultdict(float) # Token概率
def generate_candidates(self, corpus, max_len=3):
"""生成候选Token(单字、双字、三字)"""
candidates = set()
for sentence in corpus:
# 生成所有长度≤max_len的连续子串
for i in range(len(sentence)):
for j in range(1, min(max_len+1, len(sentence)-i+1)):
token = sentence[i:i+j]
candidates.add(token)
return list(candidates)
def calculate_token_freq(self, corpus, candidates):
"""统计候选Token的频率"""
freq = defaultdict(int)
total = 0
for sentence in corpus:
# 统计每个候选Token的出现次数
for token in candidates:
token_len = len(token)
for i in range(len(sentence)-token_len+1):
if sentence[i:i+token_len] == token:
freq[token] += 1
total += 1
return freq, total
def calculate_perplexity(self, corpus, vocab, token_prob):
"""计算语料的困惑度"""
total_log_prob = 0
total_tokens = 0
for sentence in corpus:
# 找到最优切分(概率最高)
best_log_prob = -float('inf')
# 简单实现:最长匹配找切分
tokens = self._longest_match(sentence, vocab)
# 计算该切分的对数概率
log_prob = sum([math.log(token_prob.get(t, 1e-10)) for t in tokens])
total_log_prob += log_prob
total_tokens += len(tokens)
# 困惑度 = exp(-平均对数概率)
avg_log_prob = total_log_prob / total_tokens
perplexity = math.exp(-avg_log_prob)
return perplexity
def _longest_match(self, text, vocab):
"""最长匹配切分(用于简化困惑度计算)"""
tokens = []
i = 0
vocab_sorted = sorted(vocab, key=len, reverse=True) # 按长度降序
while i < len(text):
matched = False
for token in vocab_sorted:
token_len = len(token)
if i + token_len <= len(text) and text[i:i+token_len] == token:
tokens.append(token)
i += token_len
matched = True
break
if not matched:
# 匹配失败,取单字
tokens.append(text[i])
i += 1
return tokens
def train(self, corpus):
"""训练Unigram分词器"""
# 步骤1:生成候选Token
candidates = self.generate_candidates(corpus, max_len=3)
# 步骤2:统计频率,初始化概率
freq, total = self.calculate_token_freq(corpus, candidates)
# 初始化Vocab(过滤掉频率为0的Token)
initial_vocab = [t for t in candidates if freq[t] > 0]
current_vocab = initial_vocab.copy()
# 步骤3:迭代删除Token直到达到目标大小
while len(current_vocab) > self.vocab_size:
# 计算当前Token概率
current_freq, current_total = self.calculate_token_freq(corpus, current_vocab)
current_prob = {t: current_freq[t]/current_total for t in current_vocab}
# 计算当前困惑度
current_pp = self.calculate_perplexity(corpus, current_vocab, current_prob)
# 计算删除每个Token后的困惑度
pp_dict = {}
for token in current_vocab:
# 临时删除该Token
temp_vocab = [t for t in current_vocab if t != token]
if not temp_vocab:
pp_dict[token] = float('inf')
continue
# 计算临时概率
temp_freq, temp_total = self.calculate_token_freq(corpus, temp_vocab)
temp_prob = {t: temp_freq[t]/temp_total for t in temp_vocab}
# 计算临时困惑度
temp_pp = self.calculate_perplexity(corpus, temp_vocab, temp_prob)
pp_dict[token] = temp_pp
# 找到困惑度上升最小的Token(即pp_dict最小的)
best_token_to_remove = min(pp_dict, key=pp_dict.get)
current_vocab.remove(best_token_to_remove)
# 最终Vocab和概率
final_freq, final_total = self.calculate_token_freq(corpus, current_vocab)
self.token_prob = {t: final_freq[t]/final_total for t in current_vocab}
self.vocab = {t: idx for idx, t in enumerate(current_vocab)}
print("Unigram训练完成!")
print("最终词汇表:", self.vocab)
print("Token概率:", self.token_prob)
def tokenize(self, text):
"""最优概率切分"""
# 动态规划找最优切分
n = len(text)
# dp[i]:前i个字符的最大对数概率
dp = [-float('inf')] * (n+1)
dp[0] = 0.0
# prev[i]:前i个字符的最优切分位置
prev = [0] * (n+1)
for i in range(1, n+1):
for j in range(max(0, i-3), i): # 最多匹配3字
token = text[j:i]
if token in self.token_prob:
log_prob = math.log(self.token_prob[token])
if dp[j] + log_prob > dp[i]:
dp[i] = dp[j] + log_prob
prev[i] = j
# 回溯找切分结果
tokens = []
i = n
while i > 0:
j = prev[i]
tokens.append(text[j:i])
i = j
tokens = tokens[::-1]
token_ids = [self.vocab.get(t, -1) for t in tokens]
return tokens, token_ids
# 测试代码
if __name__ == "__main__":
corpus = ["我爱中国", "中国很强大", "我爱北京", "北京是中国首都"]
unigram_tokenizer = UnigramChineseTokenizer(vocab_size=10)
unigram_tokenizer.train(corpus)
# 分词测试
test_text = "北京是中国首都"
tokens, token_ids = unigram_tokenizer.tokenize(test_text)
print(f"\n测试文本:{test_text}")
print(f"分词结果:{tokens}")
print(f"Token ID:{token_ids}")四、分词工具:jieba分词器
目前市面上用于中文分词的工具大致分两类:
-
基于词典或模型的传统方法,主要以"词"为单位进行切分。常用工具有jieba 、HanLP,常用于传统NLP任务中。
-
基于子词建模算法(如BPE)的方式,从数据中自动学习高频字组合,构建子词词表。常用工具有Hugging Face Tokenizer 、SentencePice 、tiktoken 等,常用于大模型预训练语言模型中,我们直接调用接口就可以使用,因为每个预训练模型都有自己配对的分词器,我们也是必须用人家的分词器,这样才能按照人家的词表ID去生成文本,因为人家的模型就是基于它们自己的词表来训练的。
(1)jieba的分词模式 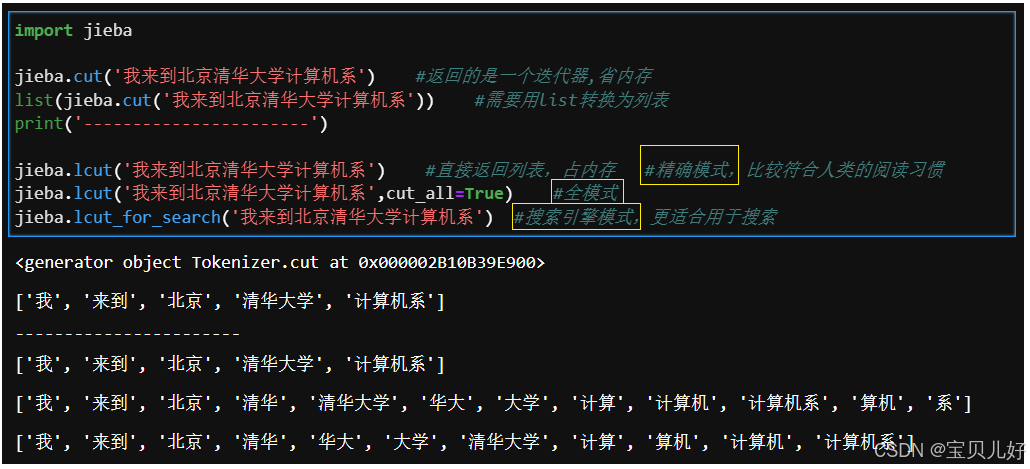
(2)如何自定义词典
之所以要自定义词典是因为,你处理的文本中的字词可能jieba的词表中没有,此时就无法识别,所以需要自定义词典。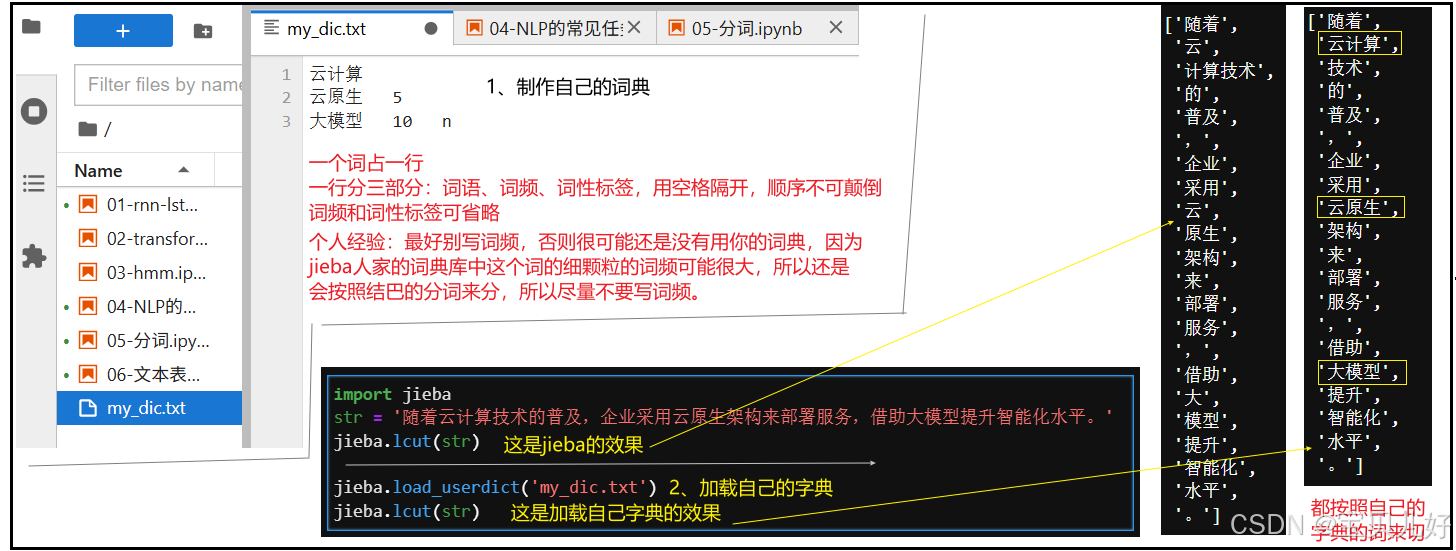
本篇完。 上面的算法主要是参考:https://developer.aliyun.com/article/1709785 ,感兴趣的同学可以自行查阅。