【LLM】第二章:文本表示:词袋模型、小案例:基于文本的推荐系统(酒店推荐)
一、文本表示
上一个章节我们讲了如何分词 ,分完词下一步就是,如何把这些词(tokens)转化为计算机可以读懂的词向量 ,这个步骤也叫文本表示。
看过我其他系列文章的同学,对文本表示 不会陌生,其实很多地方一直在反反复复讨论这个话题及相关算法,比如在图神经网络 专栏中的:
https://blog.csdn.net/friday1203/article/details/146009277
https://blog.csdn.net/friday1203/article/details/146187876
https://blog.csdn.net/friday1203/article/details/146572210
还有NLP专栏 中的embedding层、transformer的编码器,等等,这些都是用来做文本特征的,也就是进行文本表示,或者说是生成词向量的。本章节可以看作是对前面知识点的查漏补缺,本篇讲词袋模型。
最后补充一句:为什么会有这么多眼花缭乱的文本表示方法(算法)呢?自然是适用场景不一样喽,不同任务、不同语料、不同场景,都需要其对应的文本表示方法,比如,有的任务是需要对词进行向量化,有的是对句子向量化,有的是对文档向量化,因此需要对应的文本表示方法,而且这些方法从思路到解决方案 都是大不相同的,所以我们也有必要都了解一下。本篇的词袋模型适用于将整段文本编码成一个向量的需求,其思路也是极其精妙的,是前人的智慧结晶。
二、提取文本特征:sklearn.feature_extraction模块详解
在NLP领域,文本表示的最简单、最直观方法就是用词袋 来表示。Bag of words(词袋),统计每个词在文档中出现的次数。
sklearn.feature_extraction 是scikit-learn库中用于特征提取的模块,它包含了各种用于从文本和图像数据中提取特征的工具。其中文本特征提取有CountVectorizer 、TfidfVectorizer 、HashingVectorizer 、DicVectorizer四个类,是不同算法的词袋模型。本部分详细讲解这四个类。
(一)CountVectorizer
先分词-->统计词频-->根据词频,生成词向量。
1、下面用一个小例子来说明CountVectorizer的使用方法 :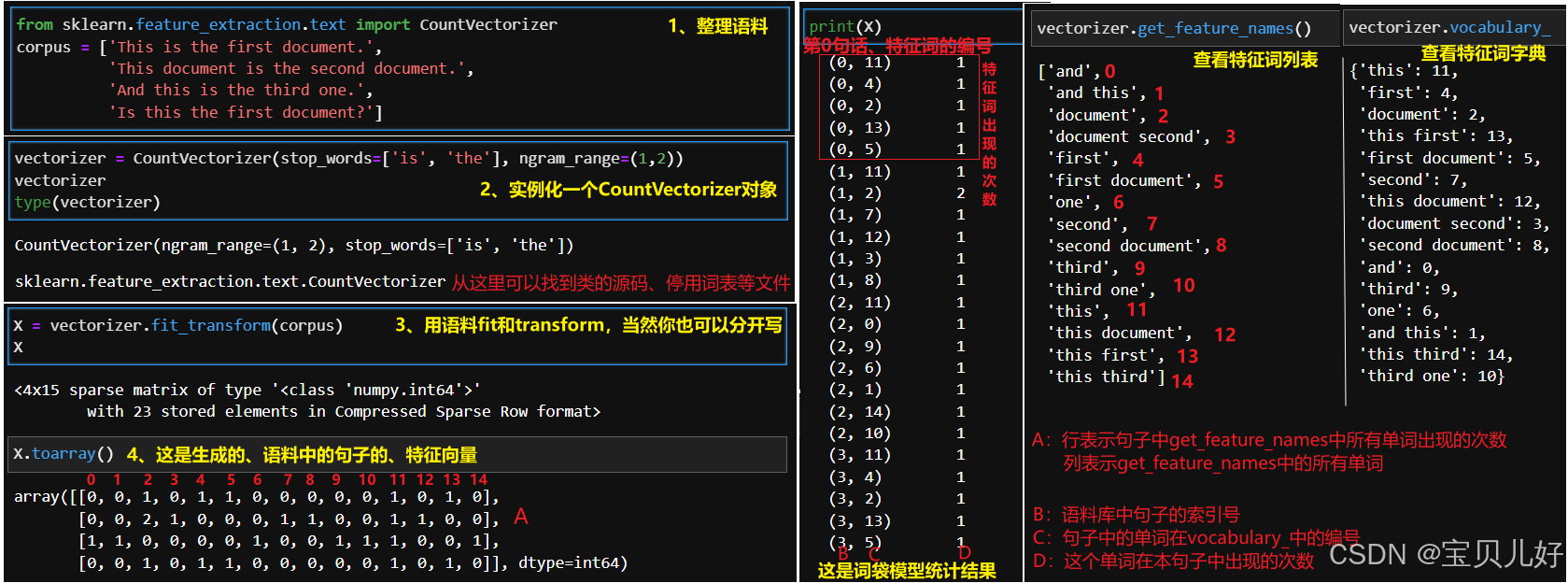 这里重点强调一下CountVectorizer类中的几个参数:
这里重点强调一下CountVectorizer类中的几个参数:
(1)stop_words:移除常见词、停用词等。
一是,使用CountVectorizer类自带的停用词表。
当你实例化CountVectorizer类的时候,加上参数stop_words='english',第一次使用CountVectorizer这个类,就会自动帮你下载一个停用词表到你的本地,这样你就可以使用这个词表了。你也可以直接修改这个词表中的词。
二是,自定义停用词表。不管是中文还是英文,你都可以用一个list来装你的所有停用词。还可以把你自己定义的停用词和CountVectorizer类提供的停用词表合并。 (2)ngram_range:设置单词对儿的范围。比如ngram_range=(1,2)表示一个单词和两个单词的都可以做为特征词,也就是都要放入字典中。ngram_range=(2,2)表示只要两两单词对儿的。这个参数就是n-gram算法的思想。
(2)ngram_range:设置单词对儿的范围。比如ngram_range=(1,2)表示一个单词和两个单词的都可以做为特征词,也就是都要放入字典中。ngram_range=(2,2)表示只要两两单词对儿的。这个参数就是n-gram算法的思想。
(3)max_features:仅保留出现频率最高的单词。
(4)analyzer:如果我们分析古诗、文言文这类的文本,我们希望单个单子汉字的分析,此时把这个参数设为'char'就可以了。
python
from sklearn.feature_extraction.text import CountVectorizer
corpus = ['This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?']
vectorizer = CountVectorizer(stop_words=['is', 'the'], ngram_range=(1,2))
vectorizer
type(vectorizer)
X = vectorizer.fit_transform(corpus)
X
X.toarray()
print(X)
vectorizer.get_feature_names()
vectorizer.vocabulary_2、中文处理要更复杂一些 :
直接用CountVectorizer处理中文语料,效果非常不好。
一是,因为CountVectorizer本身不直接处理中文分词,它默认按空格 或标点分割文本,而中文句子没有天然空格分隔,因此不能直接使用原始中文文本,还需结合中文分词工具(如jieba)进行预处理。
二是,CountVectorizer的参数token_pattern默认是保留2个或2个以上字母数字字符的词,所以,对中文来说,单个的字就又被丢弃了,所以还得用正则表达式来定义token_pattern参数,保留单个字。
下面展示一个中文的小李子: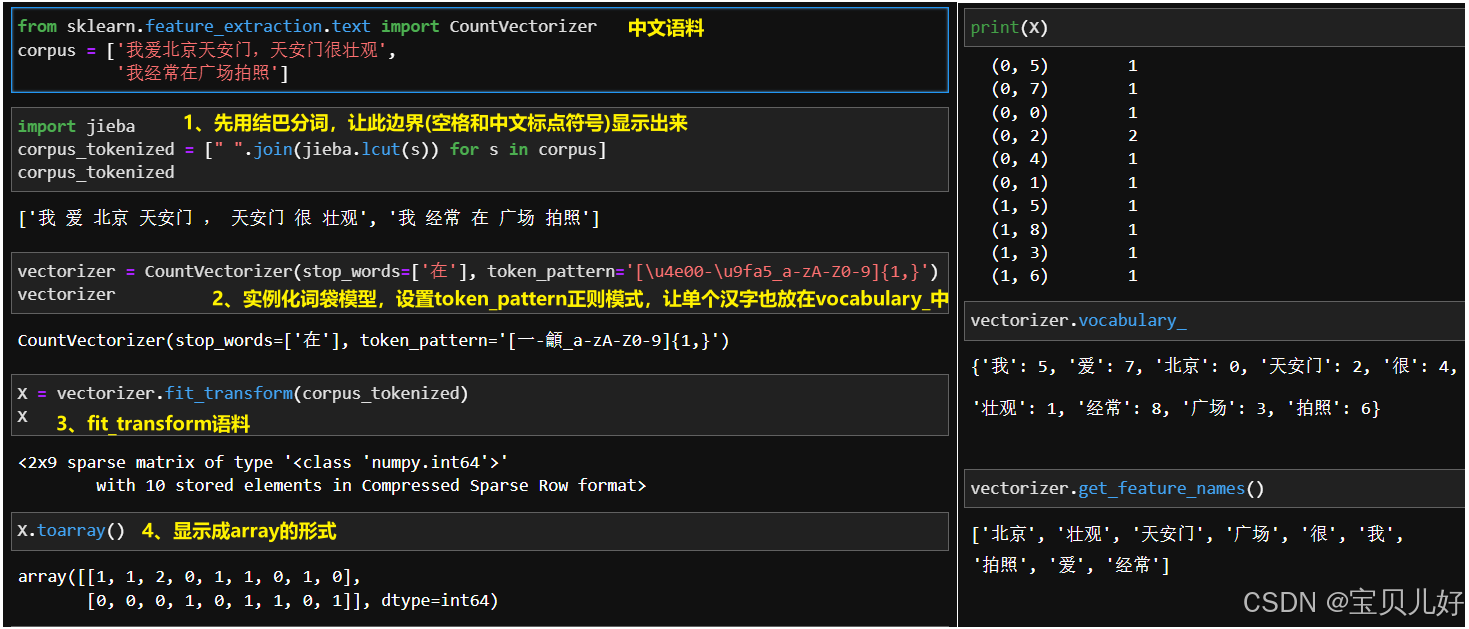
python
from sklearn.feature_extraction.text import CountVectorizer
corpus = ['我爱北京天安门,天安门很壮观',
'我经常在广场拍照']
import jieba
corpus_tokenized = [" ".join(jieba.lcut(s)) for s in corpus]
corpus_tokenized
vectorizer = CountVectorizer(stop_words=['在'], token_pattern='[\u4e00-\u9fa5_a-zA-Z0-9]{1,}')
vectorizer
X = vectorizer.fit_transform(corpus_tokenized)
X
X.toarray()
print(X)
vectorizer.vocabulary_
vectorizer.get_feature_names()(二)TfidfVectorizer
TF-IDF(词频-逆文档频率),是一种用于衡量文本中词语重要性 的方法,特别适用于信息检索和文本挖掘任务。
TF-IDF的计算过程可以分为两个主要部分:词频(TF)和逆文档频率(IDF): 如果一个词至于它所在的文档,经常出现,那tf计算出来它的重要性就越大,但是如果这个词在文档库中的其他文档中也经常出现,那这个词的idf值就会越小,如此以来,tf x idf的结果就不会很大,说明这个词不是这个文档的典型代表。如果这个词只在这个文档中出现,而且几乎没有在其他文档中出现,那这个词的idf就会很大,那tf x idf的结果就会很大,也就是这个词就是这个文档的典型代表。
如果一个词至于它所在的文档,经常出现,那tf计算出来它的重要性就越大,但是如果这个词在文档库中的其他文档中也经常出现,那这个词的idf值就会越小,如此以来,tf x idf的结果就不会很大,说明这个词不是这个文档的典型代表。如果这个词只在这个文档中出现,而且几乎没有在其他文档中出现,那这个词的idf就会很大,那tf x idf的结果就会很大,也就是这个词就是这个文档的典型代表。
下面还是用前面的例子,展示一下TfidfVectorizer的用法: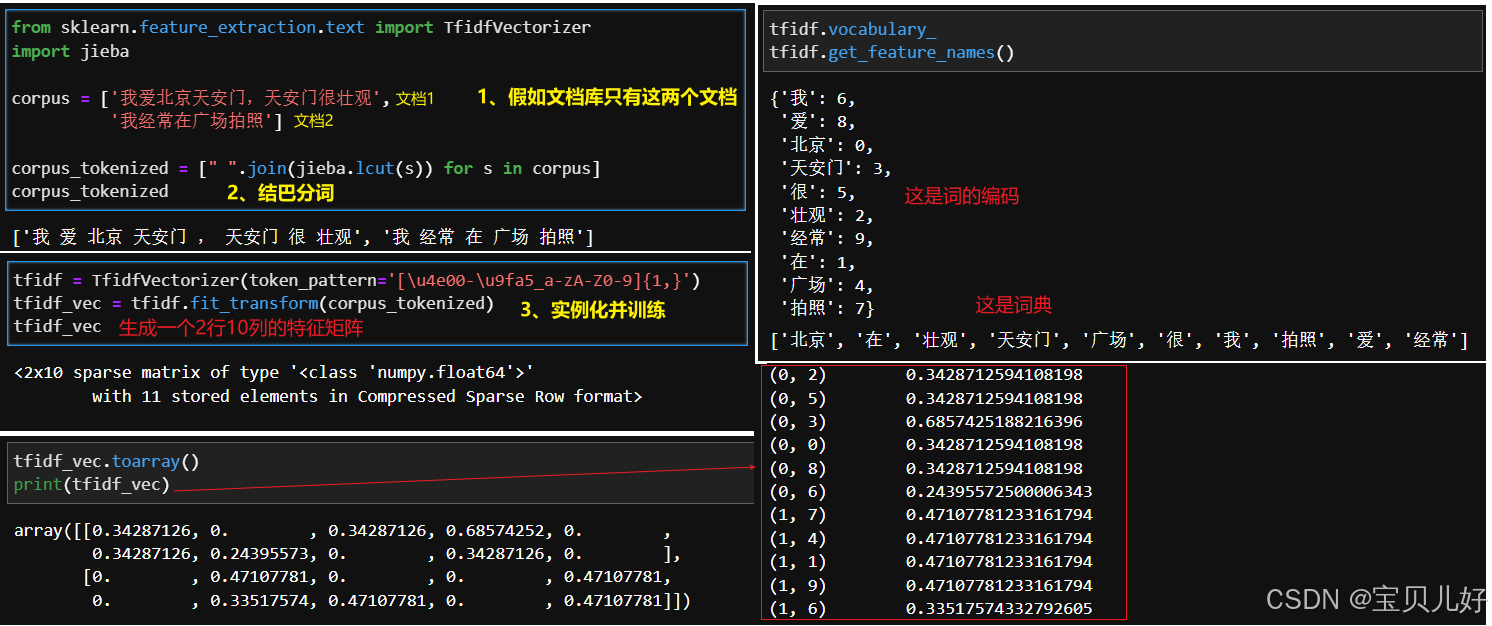
python
from sklearn.feature_extraction.text import TfidfVectorizer
import jieba
corpus = ['我爱北京天安门,天安门很壮观',
'我经常在广场拍照']
corpus_tokenized = [" ".join(jieba.lcut(s)) for s in corpus]
corpus_tokenized
tfidf = TfidfVectorizer(token_pattern='[\u4e00-\u9fa5_a-zA-Z0-9]{1,}')
tfidf_vec = tfidf.fit_transform(corpus_tokenized)
tfidf_vec
tfidf_vec.toarray()
print(tfidf_vec)
tfidf.vocabulary_
tfidf.get_feature_names()(三)HashingVectorizer
待续。。。
补充:画词云
python
# 画词云
from wordcloud import WordCloud
import jieba.posseg as pseg
import jieba
corpus = ['我爱北京天安门,天安门很壮观',
'我经常在广场拍照']
corpus_tokenized = [" ".join(jieba.lcut(s)) for s in corpus]
corpus_tokenized
keywords_str = ' '.join(corpus_tokenized)
keywords_str
font_path = r'C:/Windows/Fonts/simhei.ttf'
wordcloud = WordCloud(width=400, height=200, background_color='black',font_path=font_path).generate(keywords_str)
_ = plt.figure(figsize=(10, 5))
_ = plt.imshow(wordcloud, interpolation='bilinear')
_ = plt.axis('off')
_ = plt.title(f'wordcloud')
plt.show()