Day 4-小土堆2.0日
只要在进步,就是好样的!
1. 科研进展
忙了一下比赛的事情,论文还剩下两个实验没做了。
2. 小土堆 6/10h
2.1 torchvision.datasets的使用
本节致力于学习将 transform 和数据集结合在一起,新建文件 P11_dataset_transform.py 用于学习
python
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
])
train_set = torchvision.datasets.CIFAR10(root='./dataset',train=True,transform=dataset_transform,download=True)
test_set = torchvision.datasets.CIFAR10(root='./dataset', train=False,transform=dataset_transform,download=True)
# print(test_set[0])
# print(test_set.classes)
#
# img, target = test_set[0]
# print(img)
# print(target)
# print(test_set.classes[target])
# img.show()
# print(train_set[0])
writer = SummaryWriter("P11")
for i in range(10):
img,target = train_set[i]
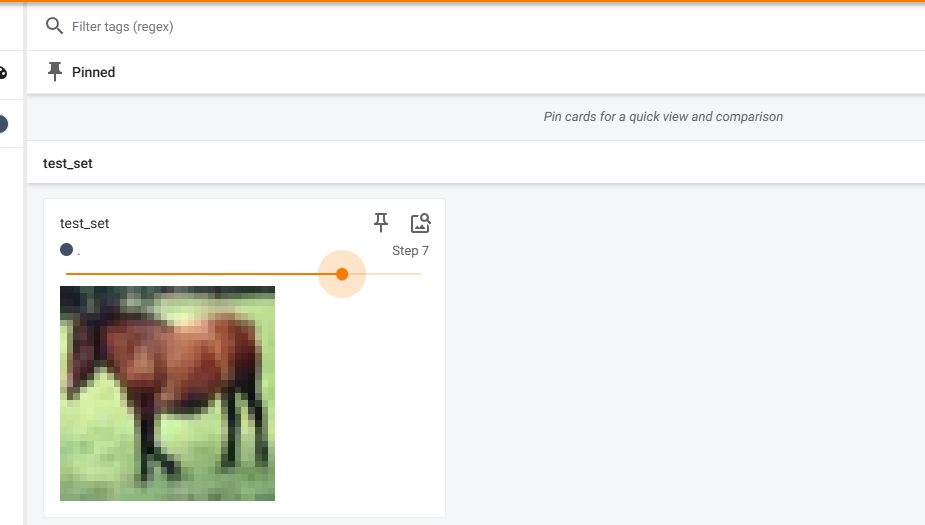
writer.add_image("test_set",img,i)
writer.close()
2.2 DataLoader的使用
新建文件 P11_dataloader.py,主要是学习如何加载数据集,学习DataLoader里面的一些参数。
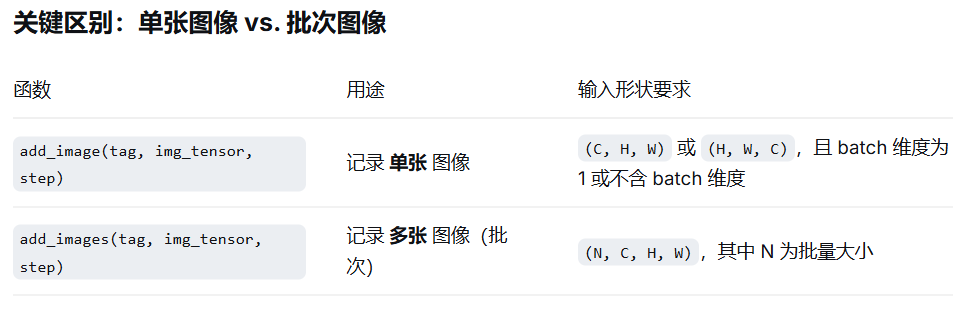
在遍历 DataLoader 时,使用 writer.add_image() 会报错,原因在于数据维度的不匹配。
python
import torchvision.datasets
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10(root='./dataset',train=False,transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
# 测试集中第一张图片及target
img,target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("DataLoader")
step = 0
for data in test_loader:
imgs,targets = data
# print(imgs.shape)
# print(targets)
writer.add_images("test_data",imgs,step)
step += 1
writer.close()

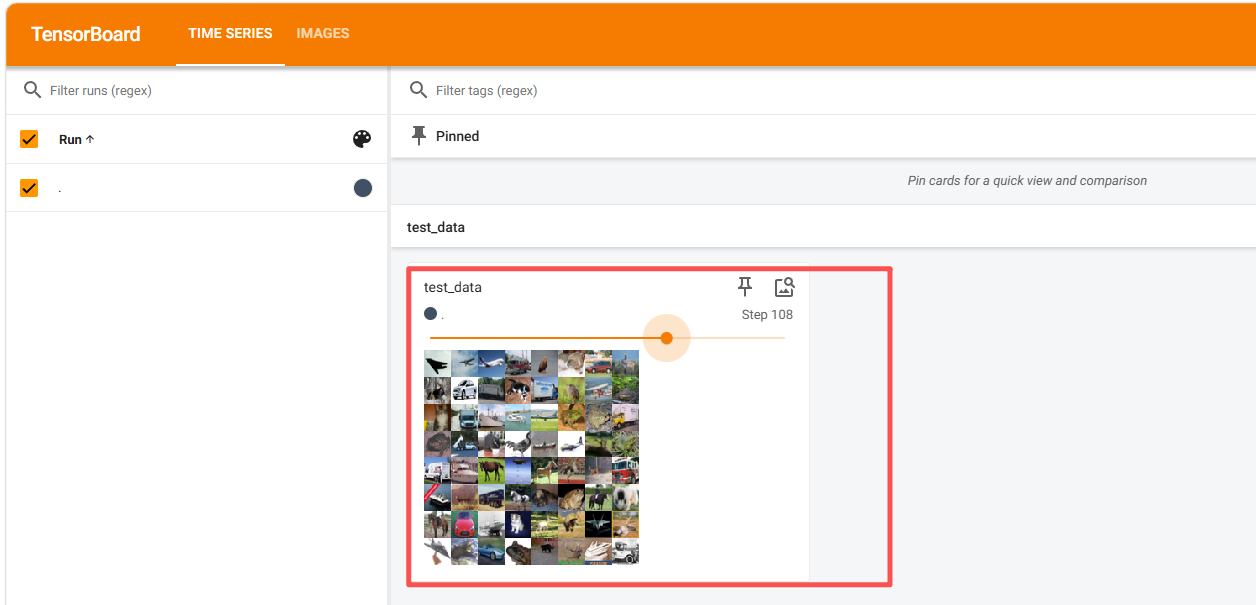
DataLoader 里面的 shuffle 参数:决定每个 epoch 运行的时候是否要打乱。
python
import torchvision.datasets
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10(root='./dataset',train=False,transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=False,num_workers=0,drop_last=False)
# 测试集中第一张图片及target
img,target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("DataLoader")
for epoch in range(2):
step = 0
for data in test_loader:
imgs,targets = data
# print(imgs.shape)
# print(targets)
writer.add_images("Epoch:{}".format(epoch),imgs,step)
step += 1
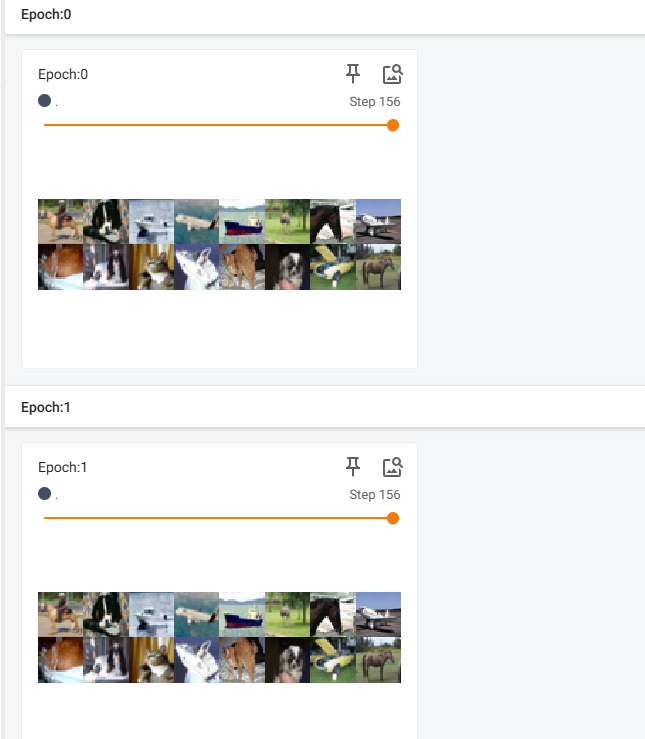
writer.close()此时再打开刷新 TensorBoard 会发现两轮运行结果是一样的。
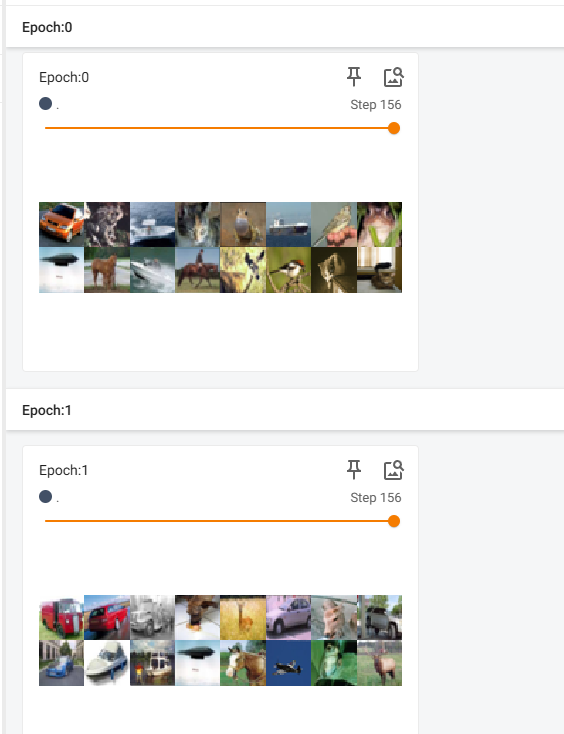
如果将 shuffle 改为 True 的话就会发现结果被打乱不一致了:
2.3 神经网络的基本骨架nn.Module的使用
常用的的包torch.nn,官方介绍:torch.nn --- PyTorch 2.11 documentation
nn 是Neural Network 的缩写。神经网络的基类Module,定义的模型都需要集成该类nn.Module。
自己定义的模型需要实现__init__和forward函数
新建文件 nn_moudle.py,用于本小节的学习。
python
import torch
from torch import nn
class Reina(nn.Module):
def __init__(self):
super(Reina,self).__init__()
def forward(self,input):
output = input + 1
return output
reina = Reina()
x = torch.tensor(1.0)
output = reina(x)
print(output)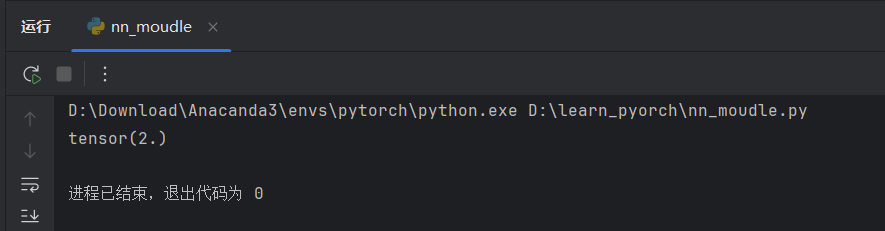
reina(x)这种写法实际上是调用了reina.__call__(x)。nn.Module的__call__方法内部会执行一些前置和后置操作(例如注册 hook、处理梯度等),并最终调用用户定义的forward方法。- 因此,执行
reina(x)等效于执行reina.forward(x)(但不推荐直接调用forward,因为会绕过__call__提供的额外机制)。
代码的执行流程可通过Pycharm进行debug 使用Step into My Code进行查看。
2.4 卷积操作
补充一下基础还是很有必要的。。。

以上是torch.nn.functional.conv2d的参数要求
新建文件 nn_conv.py,按照这个表格写卷积代码。
python
import torch
import torch.nn.functional as F
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
kernel = torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
input = torch.reshape(input,(1,1,5,5)) # 变换input维度使其满足torch.nn.functional.conv2d的参数要求
kernel = torch.reshape(kernel,(1,1,3,3))
print(input.shape)
print(kernel.shape)
output = F.conv2d(input,kernel,stride=1)
print(output)
output2 = F.conv2d(input,kernel,stride=2)
print(output2)
output3 = F.conv2d(input,kernel,stride=1,padding=1)
print(output3)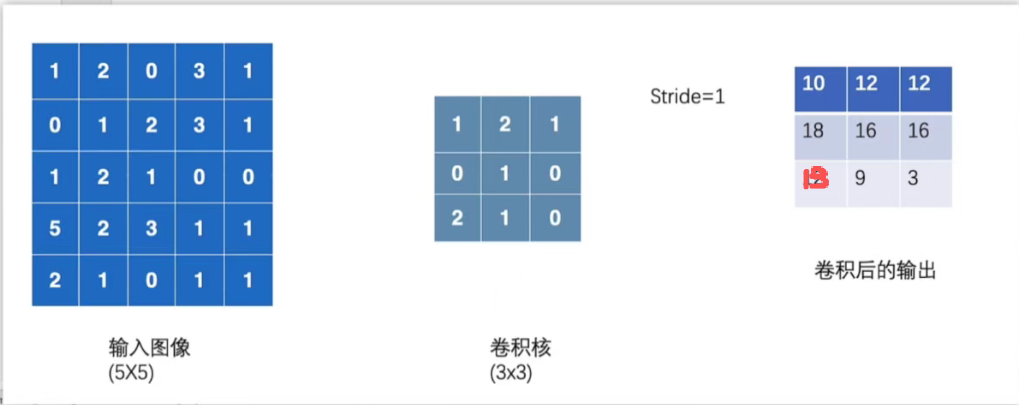
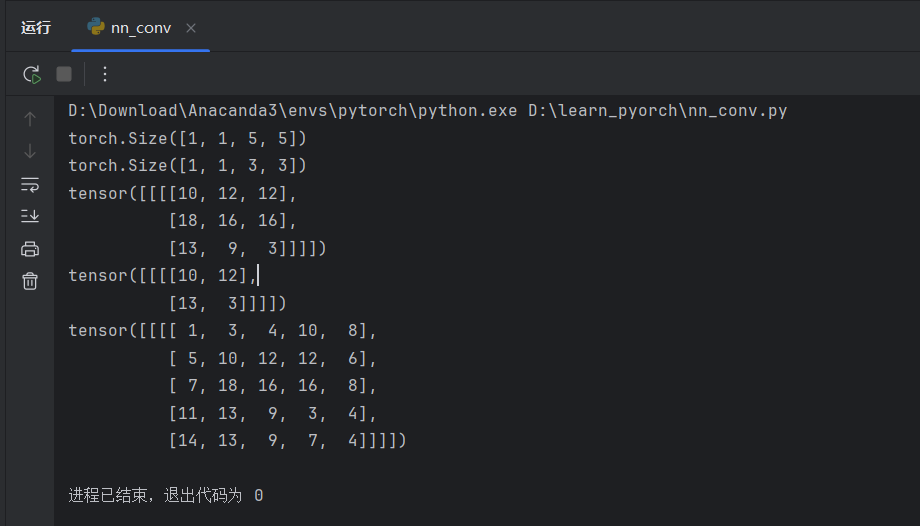
padding = 1 意味着四个边边都向外扩充一行/列,默认填充数值为0,所以最终计算得到的维度也变大了。
2.5 神经网络-卷积层
官网链接:torch.nn --- PyTorch 2.11 documentation
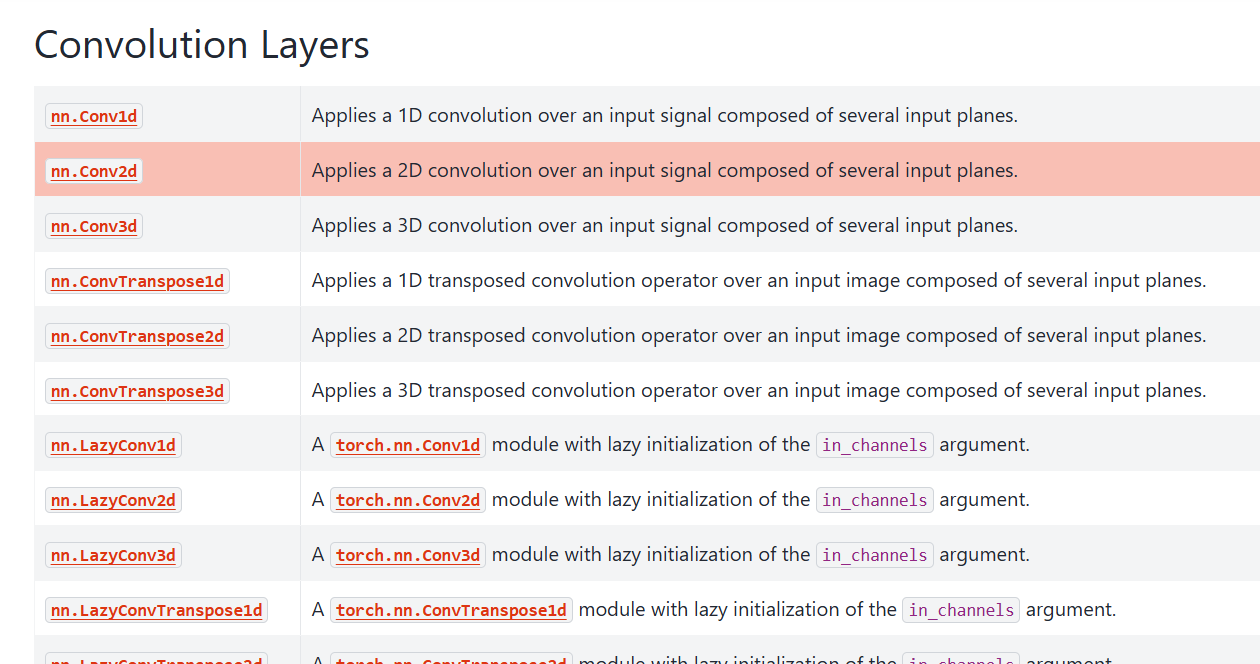
比较常用的其实只有 nn.Conv2d ,所以本节重点讲解它的使用。


进一步促进理解,建议直接去链接里面看动图:卷积操作可视化链接
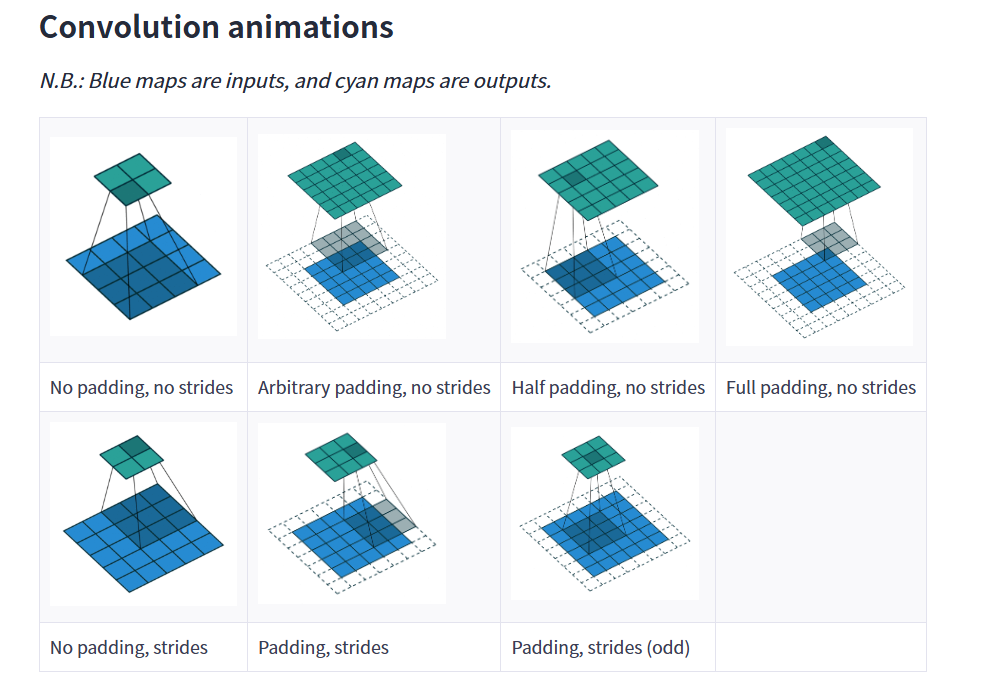
dilation是空洞卷积,默认值是1

接下来尝试理解 in_channels 和 out_channels :
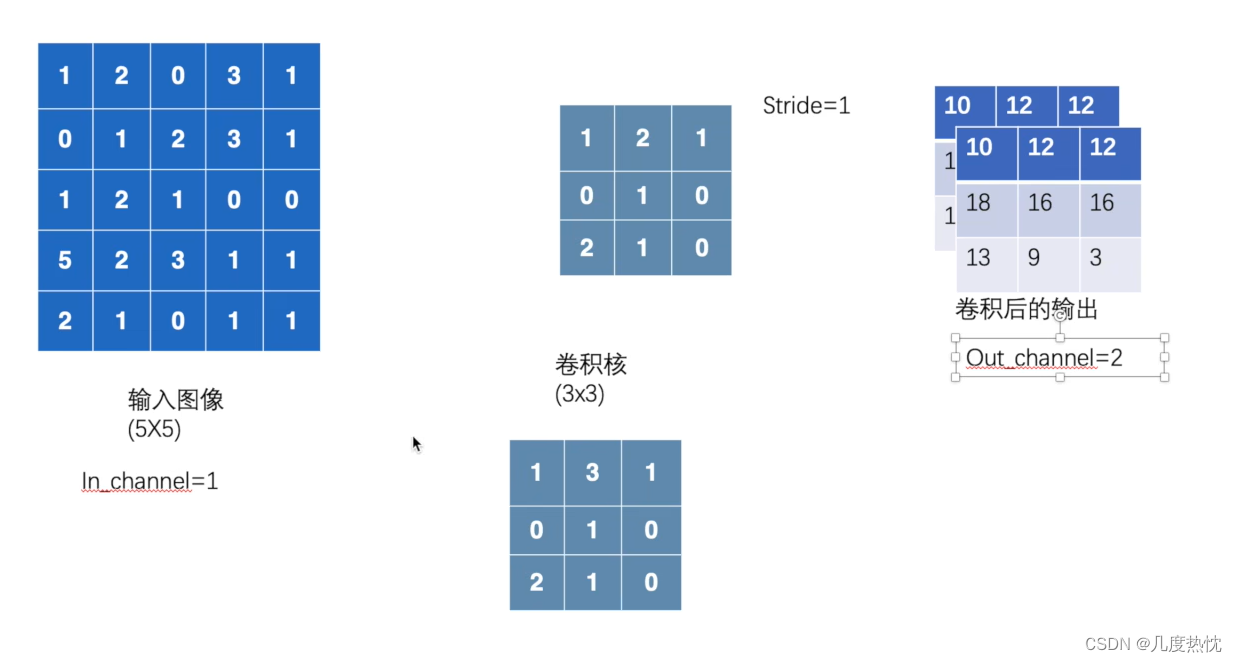
out_channels是指经过卷积核之后输出的特征图的通道数
输入特征图的通道数 = 卷积核的通道数
输出特征图的通道数 = 卷积核的个数
解释:卷积核的通道数一定和输入的通道数相等,输入对应的每个通道与卷积核对应的每个通道进行计算再求和得到 一个通道的卷积输出;而输出特征图的通道数与卷积核的个数相关,有多少个卷积核最终就有多少个输出通道
接下来开始练习代码,创建文件 nn_conv2d.py。
- 输入通道
in_channels=3:CIFAR-10 中的图片是 RGB 三通道 彩色图像,因此卷积层的输入必须匹配图像的通道数,即 3。 - 输出通道
out_channels=6:表示使用 6 个不同的卷积核 (滤波器),每个卷积核会对输入的三通道进行卷积并求和,最终输出 6 张特征图。 - 卷积核尺寸
kernel_size=3:3×3 卷积核 是卷积神经网络中最常用的尺寸之一,现代深度学习框架对 3×3 卷积有专门优化。
python
import torch
import torchvision
from torch import nn
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root='./dataset', train=False, download=True, transform=torchvision.transforms.ToTensor())
dataloader = torch.utils.data.DataLoader(dataset, batch_size=64)
class Reina(nn.Module):
def __init__(self):
super(Reina, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
reina = Reina()
# print(reina)
writer = SummaryWriter("./conve2d")
step = 0
for data in dataloader:
imgs,targets = data
output = reina(imgs)
print(imgs.shape)
print(output.shape)
writer.add_images("input",imgs,step)
writer.add_images("output",output,step)
step += 1
writer.close()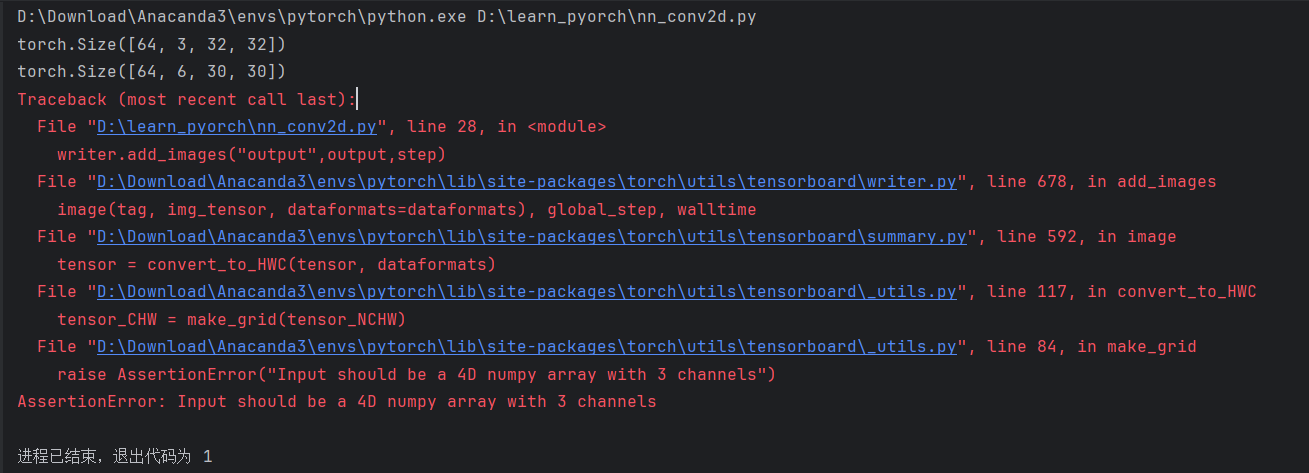
报错原因: TensorBoard 的 add_images 要求输入图像的通道数必须是 1(灰度)、3(RGB)或 4(RGBA),而卷积输出张量形状为 64, 6, 30, 30,即 6 通道的特征图,不符合图像显示的常规格式,因此触发了 AssertionError。
**解决方案:**将形状为 64, 6, 30, 30 的张量强制变形为 -1, 3, 30, 30。
- 原始形状:output.shape = 64, 6, 30, 30
- -1 的含义:让 PyTorch 自动计算该维度的大小,使得总元素数保持不变。
- 变形后形状:128, 3, 30, 30
- 新张量被解释为 128 张三通道的 30×30 图像。
python
import torch
import torchvision
from torch import nn
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root='./dataset', train=False, download=True, transform=torchvision.transforms.ToTensor())
dataloader = torch.utils.data.DataLoader(dataset, batch_size=64)
class Reina(nn.Module):
def __init__(self):
super(Reina, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
reina = Reina()
# print(reina)
writer = SummaryWriter("./conve2d")
step = 0
for data in dataloader:
imgs,targets = data
output = reina(imgs)
print(imgs.shape)
print(output.shape)
writer.add_images("input",imgs,step)
output = torch.reshape(output,(-1,3,30,30)) # #不严谨操作 ---对output进行reshape 增大batchsize的数量 减少通道数
writer.add_images("output",output,step)
step += 1
writer.close()
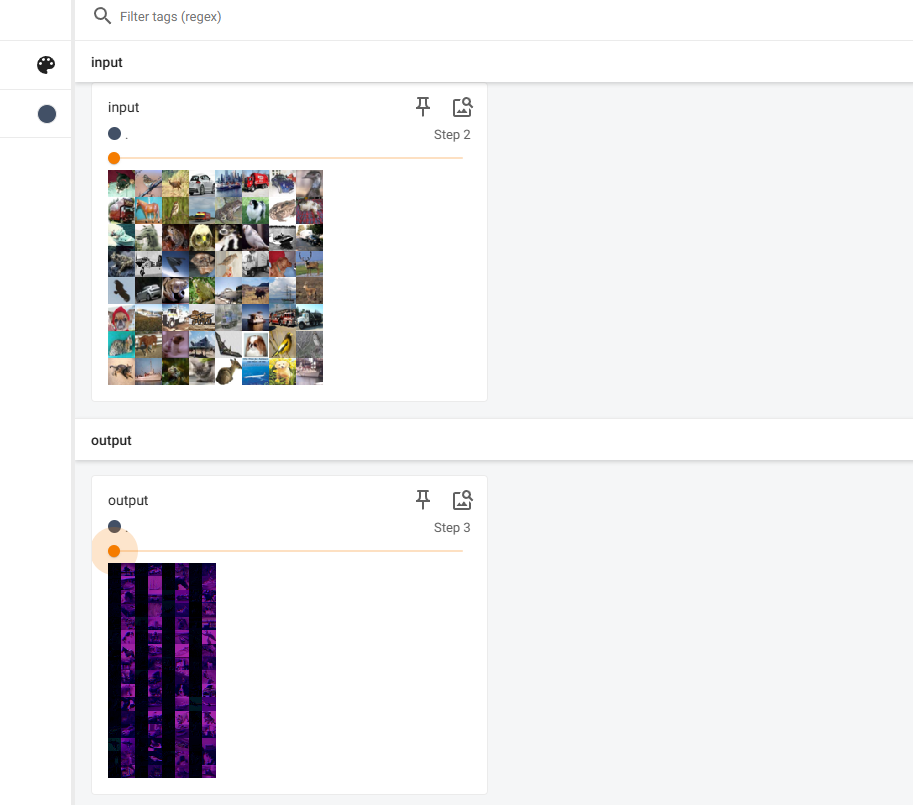
注意: reshape 技巧仅是为了让程序不报错而进行的欺骗性操作,它会让 TensorBoard 上显示的"output"图像变成一堆无意义的乱码。
2.6 神经网络-最大池化层
官方文档:torch.nn --- PyTorch 2.11 documentation
说来惭愧,我的文档中还用到了部分卷积和池化的知识,可是我都没怎么认真理解底层原理。。。
最大池化层 :保留输入的特征,同时减少数据量 加快训练速度
最常用的:MaxPool2d


最大池化层的步长默认大小为kernel_size
ceil_mode: ceil向上取整,floor向下取整
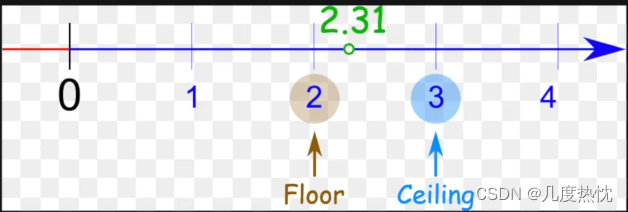
ceil 允许有出界部分;floor 不允许
ceil_mode =True时 为ceil

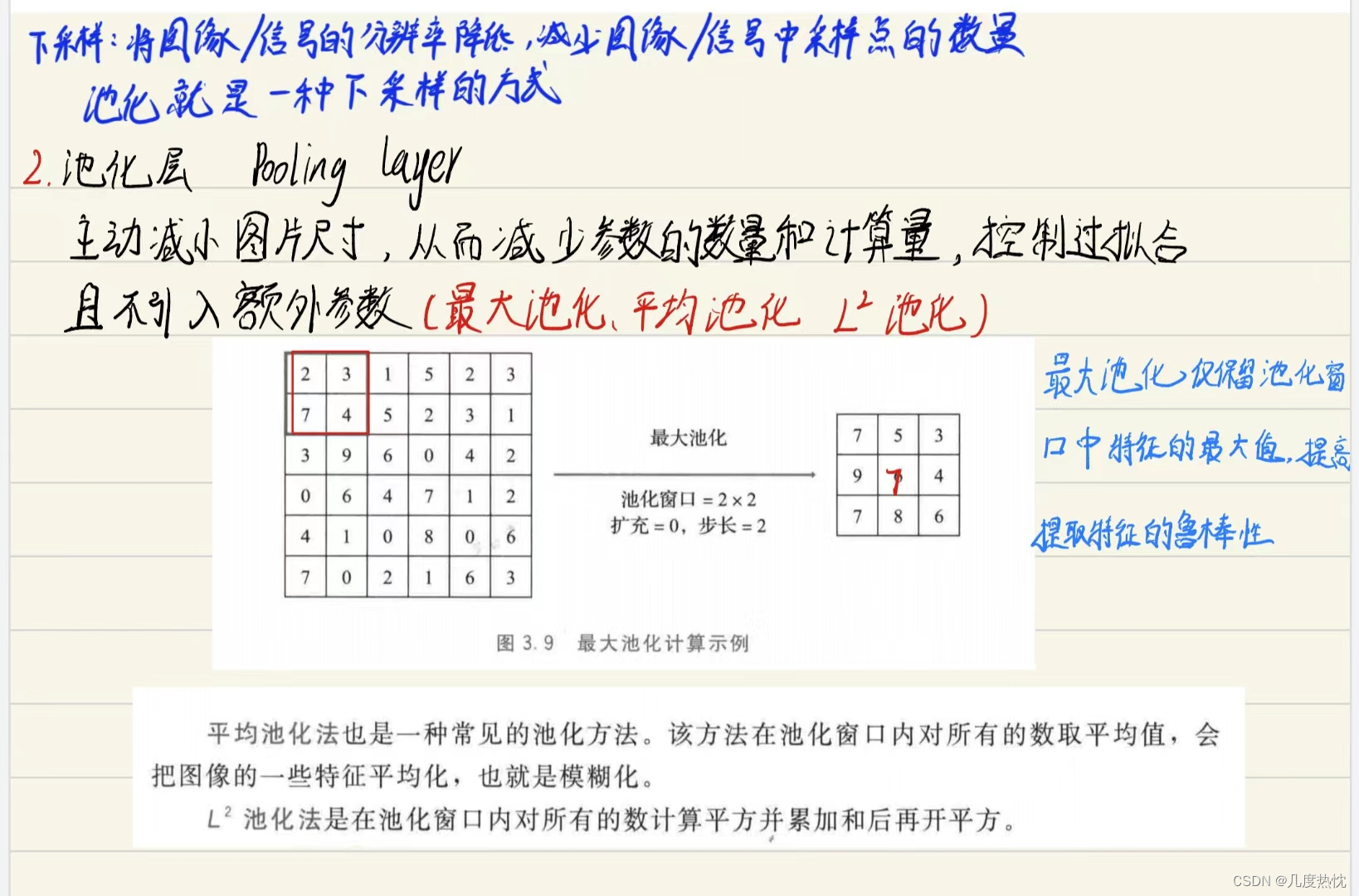
池化层有三个特点:1.没有需要学习的参数;2.通道数保持不变;3.对微小位置的变化具有鲁棒性
理论学完,开始练习代码,新建文件 nn_maxpool.py。
2.6.1 ceil_mode=True 的运行结果
python
import torch
from torch import nn
from torch.nn import MaxPool2d
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
input = torch.reshape(input, (-1, 1, 5, 5)) # nn.Conv2d 和 nn.MaxPool2d 等二维操作层的输入要求必须是 4 维张量
print(input.shape)
class Reina(nn.Module):
def __init__(self):
super(Reina, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool1(input)
return output
reina = Reina()
output = reina(input)
print(output)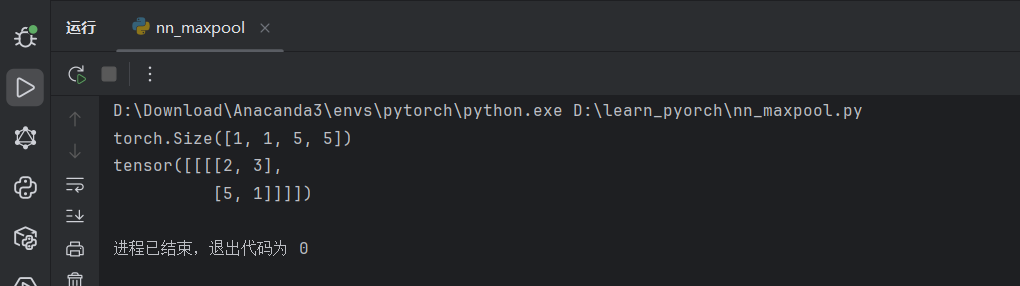
2.6.2 ceil_mode=False 的运行结果
python
import torch
from torch import nn
from torch.nn import MaxPool2d
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
input = torch.reshape(input, (-1, 1, 5, 5)) # nn.Conv2d 和 nn.MaxPool2d 等二维操作层的输入要求必须是 4 维张量
print(input.shape)
class Reina(nn.Module):
def __init__(self):
super(Reina, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=False)
def forward(self, input):
output = self.maxpool1(input)
return output
reina = Reina()
output = reina(input)
print(output)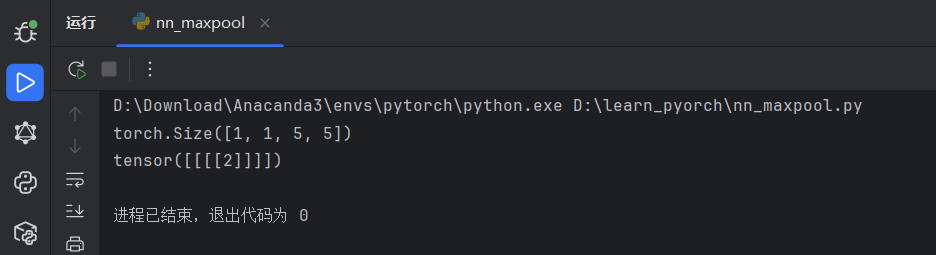
两种结果和之前手动计算的结果都对上了,最大池化参数部分学习完毕。
最大池化的目的:保留输入数据主要特征的同时减少参数和计算量,增强模型鲁棒性,防止过拟合
2.6.3 结合图片处理的展示效果
池化是纯空间维度的降采样操作,设计目标就是压缩特征图的分辨率(减少计算量、增大感受野),而不改变特征的种类(通道数)。如果需要改变通道数,必须使用卷积层(1×1 卷积)或全连接层。

- 卷积:像一台调色板,把 RGB 三通道的像素按不同权重混合成多个新颜色通道(例如 6 个)。
- 池化:像一台缩小复印机,把每张单色图纸(每个通道)单独缩小,颜色数量不变。
python
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root='./dataset',train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=64)
# input = torch.tensor([[1, 2, 0, 3, 1],
# [0, 1, 2, 3, 1],
# [1, 2, 1, 0, 0],
# [5, 2, 3, 1, 1],
# [2, 1, 0, 1, 1]])
# input = torch.reshape(input, (-1, 1, 5, 5)) # nn.Conv2d 和 nn.MaxPool2d 等二维操作层的输入要求必须是 4 维张量
# print(input.shape)
class Reina(nn.Module):
def __init__(self):
super(Reina, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=False)
def forward(self, input):
output = self.maxpool1(input)
return output
reina = Reina()
# output = reina(input)
# print(output)
writer = SummaryWriter("maxpool")
step = 0
for data in dataloader:
imgs,targets = data
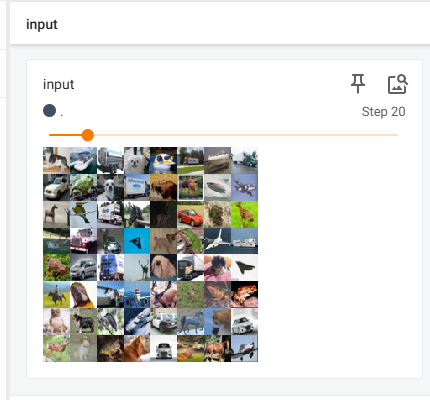
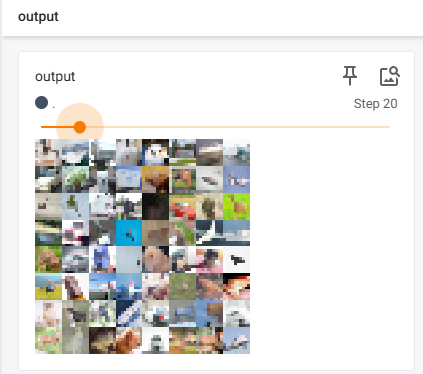
writer.add_images("input",imgs,step)
output = reina(imgs)
writer.add_images("output",output,step) # 池化不改变channel数
step += 1
writer.close()
2.7 神经网络-非线性激活
非线性激活层:引入非线性的特性,使得神经网络具有更强的表达能力和适应能力
padding层的使用概率是比较低的,主要是用于填充数据的,所以跳过这里直接开始学习非线性激活层:torch.nn --- PyTorch 2.11 documentation
比较常用的就是ReLU,Sigmod,确实,这两个我的论文里面也都有涉及。。。
2.7.1 ReLU 的使用

**inplace参数的含义:**为True时对原输入进行激活函数的计算,计算结果赋给原输入;为False时,返回对原输入进行激活函数的计算的结果,原输入不发生改变,保留原始数据,默认为False

python
import torch
from torch import nn
from torch.nn import ReLU
input = torch.tensor([[1, -0.5],
[-1, 3]])
input = torch.reshape(input, (-1, 1, 2, 2)) # 增加一个batchsize维
print(input.shape)
class Reina(nn.Module):
def __init__(self):
super(Reina, self).__init__()
self.relu1 = ReLU()
def forward(self, input):
output = self.relu1(input)
return output
reina = Reina()
output = reina(input)
print(output)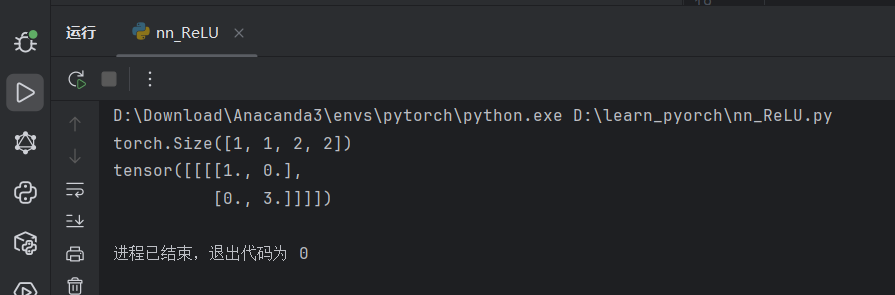
2.7.2 Sigmoid的使用
python
import torch
import torchvision
from torch import nn
from torch.nn import ReLU
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from P8_Tensorboard import writer
input = torch.tensor([[1, -0.5],
[-1, 3]])
input = torch.reshape(input, (-1, 1, 2, 2)) # 增加一个batchsize维
print(input.shape)
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Reina(nn.Module):
def __init__(self):
super(Reina, self).__init__()
self.relu1 = ReLU()
self.sigmoid = nn.Sigmoid()
def forward(self, input):
output = self.sigmoid(input)
return output
reina = Reina()
# output = reina(input)
# print(output)
writer = SummaryWriter("./logs_ReLU")
step = 0
for data in dataloader:
imgs,targets = data
writer.add_images("input",imgs,step)
output = reina(imgs)
writer.add_images("output",output,step)
step += 1
writer.close()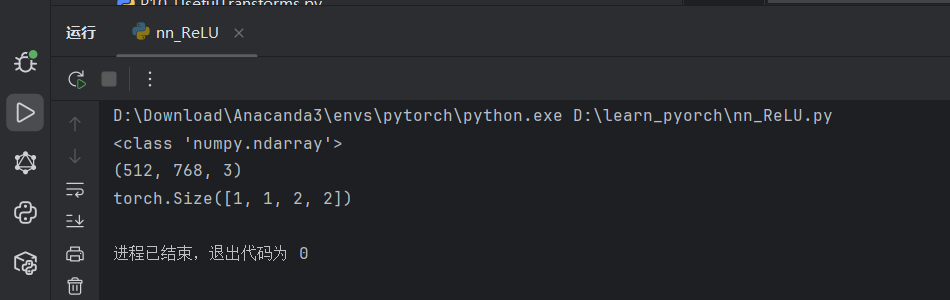

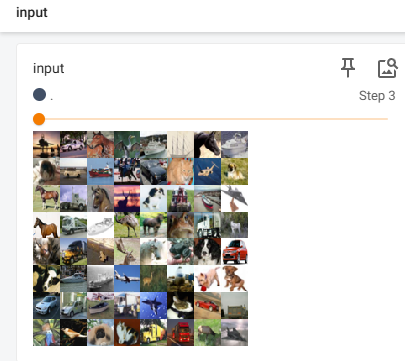
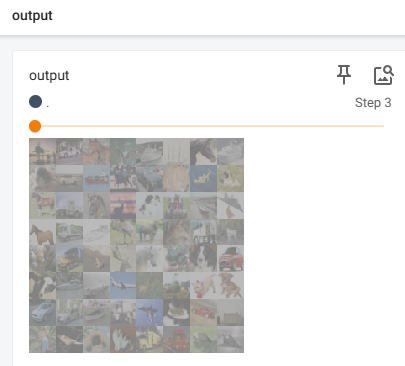
好啦,今天小土堆就学到这里,感觉很多原理的知识还是要去看一下吴恩达老师的视频,后面有时间再补充吧。
3. 灵神算法
刷几节灵神的课醒醒脑就睡觉啦~撒花!